用SVM向量机下注(交易),能跑得过大猩猩吗?
 3
3843
3
3843
用SVM向量机下注(交易),能跑得过大猩猩吗?
女士们先生们,投下你们的赌注。今天,我们要尽最大的努力去击败一只猩猩,它被看作是在金融界最可怕的对手之一。 我们要试着预测“货币交易品种的隔日收益”。我向你保证:即使想击败一只随机投注、并获得50%的胜率的猩猩,都是一件很难的事情。 我们将用一个现成的机器学习算法,它是支持向量分类器。SVM向量机对于解决回归和分类任务是一种令人难以置信的强大方法。
- SVM支持向量机
SVM向量机是基于这样的一个想法:我们可以使用超平面对p维特征空间分类。SVM向量机算法使用一个超平面和一个辨识Margin来创造分类决策边界,如下图。
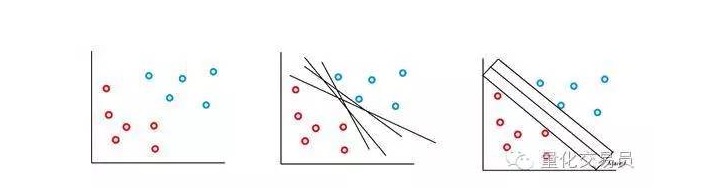
在最简单的情况下,线性分类是可能的。算法选择了决策边界,它可以最大化类间的距离。
在你面对的大多数金融时间序列中,你不太会遇到简单的、线性可分开的集合,不可分开的情况倒是经常出现。SVM向量机通过实施一种被成为“软间距”(soft margin method)的方法解决了这个问题。
在这个案例中,一些错误分类情况被允许,但是它们自己执行函数,为了把与C(成本或预算的错误可以被允许)成正比的因子和错误到边界的距离减少到最小。
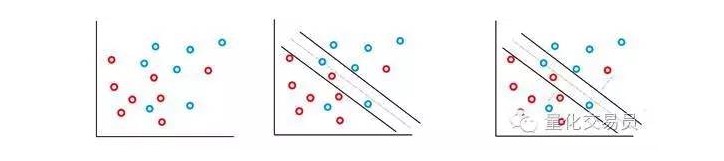
基本来说,机器会尽量最大化分类之间的间隔,同时尽量减少其被C加权的惩罚项。
SVM分类器有一个很棒的特征是分类决策边界的位置和尺寸仅由部分数据决定,即离决策边界最近的那部分数据。这种算法的特性使得它能够对抗远离间隔的异常值的干扰。比如在上图中,最右上的蓝色点,对决策边界影响很小。
是不是太复杂了?好吧,我认为乐趣才刚刚开始。
考虑以下情况(把红点和其它颜色的点分开):
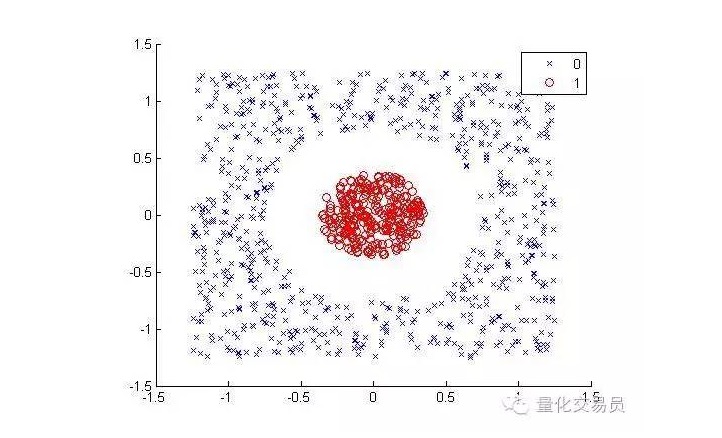
在人类看来,它分类起来很简单(一条椭圆线即可)。但是对机器来说不一样。很显然,它不能做成直线(一条直线无法将红色的点分离出来)。这里我们可以尝试“内核技巧”(kernel trick)。
内核技巧是一种非常聪明的数学技术,它使我们能够在(升维到)高维空间求解线性分类问题。现在我们来看它是怎么样做的。
我们将通过升维映射把二维特征空间转换到三维,完成分类后回到二维。
下面分别是升维映射和完成分类后的图:
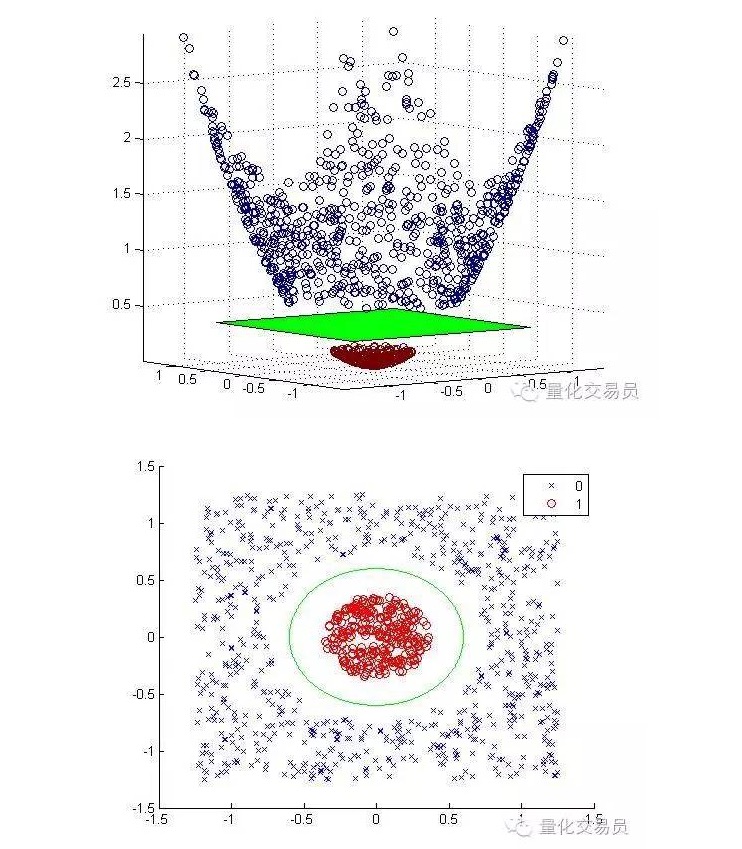
一般来说,如果有d输入,你可以从d维输入空间到p维特征空间使用一个映射。运行上述最小化算法将产生的解决方案,然后映射回你原来的输入空间p维超平面。
上述数学解决方案的重要前提,它取决于如何在特征空间中生成好的点样本集。
你只需要这些点样本集来执行边界优化,映射不需要明确,输入空间在高维特征空间的点可以通过核函数(和一点Mercer 定理的帮助)被安全地计算。
例如,你想在一个超大的特征空间解决你的分类问题,假设是100000维。你能想象你所需要的计算能力吗?我对你是否能完成它表示非常怀疑。好了,内核现在可以让你计算这些点样本,因此,这个边缘是来自于你低纬度的舒适输入空间。
- 挑战和大猩猩
现在我们正准备面对击败杰夫的预测能力的挑战。让我们看看杰夫:
杰夫是货币市场的专家,他通过随机投注能够获得50%的预测准确度,这个准确度是指预测下个交易日收益率的信号。
我们将使用不同的基本时间序列,包括现货价格时间序列,每个时间序列高达10lags的收益,一共有55个features。
我们准备打造的SVM向量机是使用3度的内核。你可以想到选择一个合适的内核是另一项非常艰难的任务,为了校准C和Γ参数,3倍交叉验证在可能的参数组合的网格上运行,并且最好的一组将会被选择。
结果并不十分令人鼓舞:
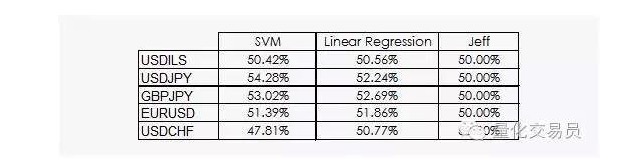
我们可以看到,无论线性回归还是SVM向量机都能够击败杰夫。虽然结果并不乐观,我们也可以从数据中提取一些信息,这已经是个好消息,因为在数据学科中,金融时间序列每日的收益不是最有用的
在交叉验证后,数据集将被训练和测试,我们记录了训练的SVM的预测能力,为了有一个稳定的表现,我们重复每种货币随机分裂1000次。
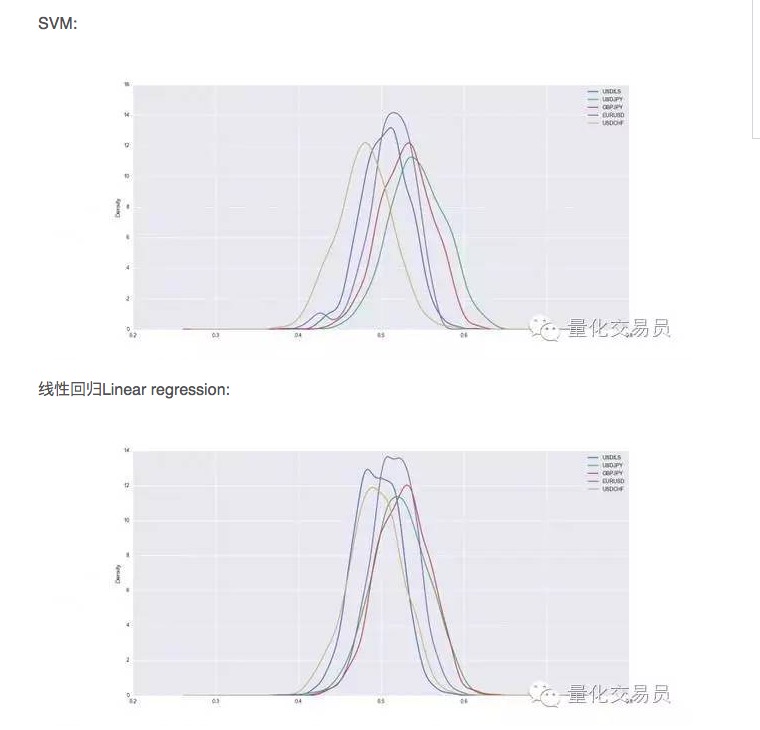
这样看来,在某些情况下,SVM优于简单的线性回归,但表现的差异也略高。以美元兑日元为例,我们平均能预测到的信号占总次数的54%。这是一个相当不错的结果,但让我们来更加仔细看看!
Ted是Jeff的表弟,它当然也是一只大猩猩,但它比Jeff更加聪明。Ted着眼于训练样本集,而不是随机投注。他打赌信号总是从训练集的最常见输出中给出。让我们现在用聪明的Ted作为基准:
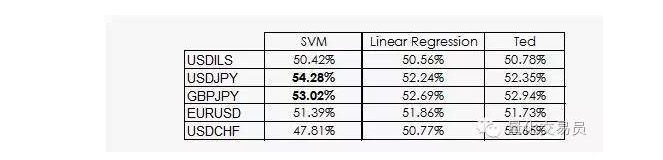
正如我们所看到的,大多数SVM的表现只是来自一个事实:机器学习到分类不太可能等于先验。事实上,线性回归不能够从特征空间中得到任何信息,但截距(intercept)在回归是有意义的,并且截距和“某个分类更表现更好”这个事实有关。
一个稍微好一点的消息,SVM向量机能够从数据中得到一些额外的非线性信息,这能使得我们将预言的精准度提示2%。
不幸的是,我们还不知道这可能是种什么信息,就像SVM向量机有自己主要的劣势,那也不是我们可以解释清楚的。
作者:P. López,发表于quantdare
转载自微信公众号

- 2.2 下限价单 交易
- 2.1 使用API 获取账户信息、 获取行情数据、 获取K线数据、 获取市场深度信息
- 其它功能
- 1.3.4 机器人与策略
- 1.3.2 认识托管者
- 1.3.1 主界面概览及架构
- 1.1 认识什么是量化交易、程序化交易。
- 量化必读:Tick 数据到底是什么?为什么很难找到可靠的交易数据?
- btc策略模拟回测, 为什么没有poloniex选项???
- 阿尔法狗的利器:蒙特卡洛算法,看完就懂了!(附代码实例)--转载
- 简单的SVM 分类算法
- 回测实盘级tick有问题
- 关于交易软件的接口
- Python 2.x.x 与 Python 3.x.x 的改动 & Python 2.x.x 转换为 Python 3.x.x 的方法
- 冰与火:实盘与回测
- 干货 -高频交易在怎么挣钱?(转载)
- X 分钟速成 Python
- 思考方法比高频算法更重要
- 开源发明者量化的TA库, 学习使用(含Javascript/Python/C++版本)
- 心理素质、创新能力、资金管理、策略