阿尔法狗的利器:蒙特卡洛算法,看完就懂了!(附代码实例)--转载
 0
23882
0
23882
阿尔法狗的利器:蒙特卡洛算法,看完就懂了!
在今年3月9日-15日,围棋界发生了一件大事,一场总计五轮的人与机器的大战在韩国首尔上演。 这场比赛的结果是人类完败,世界围棋冠军李世石以1比4最终败给了谷歌公司的人工智能程序AlphaGo。 那么AlphaGo是什么,获胜的关键又在哪里呢?这里我们就要来了解一个算法:蒙特卡洛算法。
- ### AlphaGo和蒙特卡洛算法 根据新华社的报道,AlphaGo程序是美国谷歌公司旗下DeepMind团队开发的一款人机对弈的围棋程序,被中国棋迷们戏称为“阿尔法狗”。
在上一次的文章中,我们提到过有关谷歌所正在开发的神经网络算法,让机器进行自主的学习,AlphaGo也是类似的产物。
中国自动化协会副理事长、秘书长王飞跃表示,程序设计者们不需要精通围棋,只需要懂得围棋的基本规则即可。AlphaGo背后是一群杰出的计算机科学家,确切地说,是机器学习领域的专家。科学家利用神经网络算法,将棋类专家的比赛记录输入给计算机,并让计算机自己与自己进行比赛,在这个过程中不断学习训练。某种程度上可以这么说,AlphaGo的棋艺不是开发者教给它的,而是“自学成才”的。
那么可以让AlphaGo“自学成才”的关键在哪里?那就是蒙特卡洛算法。
什么是蒙特卡洛算法? 我们通俗的来解释一下蒙特卡洛算法: 假如篮子里有1000个苹果,让你每次闭着眼睛找一个最大的,可以不限制挑选次数。于是,你可以闭着眼随机拿了一个,然后再随机拿一个与第一个比,留下大的,再随机拿一个,与前次留下的比较,又可以留下大的。循环往复这样,拿的次数越多,挑出最大苹果的可能性也就越大,但除非你把1000个苹果都挑一遍,否则你无法肯定最终挑出来的就是最大的一个。
也就是说,蒙特卡洛算法是样本越多,越能找到最佳的解决办法,不过不保证是最好的,因为如果有10000个苹果的话,说不定就能找到更大的。
可以和他形成对比的是拉斯维加斯算法: 通俗的说,假如有一把锁,有1000把钥匙进行选择,但只有1把是对的。于是每次随机拿1把钥匙去试,打不开就再换1把。试的次数越多,打开最优解的机会就越大,但在打开之前,那些错的钥匙都是没有用的。
所以拉斯维加斯算法就是尽量最好的解决办法,但是未必能找到。假设1000把钥匙中,不能有任何一把打开锁,真正的钥匙是第1001把,但是在样本并没有第1001种算法,拉斯维加斯算法就不能找到打开锁的钥匙。
AlphaGo的蒙特卡洛算法 围棋的难度对于人工智能来说尤其的大,因为围棋的落子方式太多,计算机很难进行分辨。 王飞跃说:“首先,围棋的可能性太多。围棋每一步的可能下法非常多,棋手起手时就有19×19=361种落子选择。一局150回合的围棋可能出现的局面多达10170种。其次,是规律太微妙,在某种程度上落子选择依靠的是经验积累而形成的直觉。此外,在围棋的棋局中,计算机很难分辨当下棋局的优势方和弱势方。因此,围棋挑战被称作人工智能的‘阿波罗计划’。”
而AlphaGo也不只是一个仅仅只有蒙特卡洛算法,更确切说他是蒙特卡洛算法的升级版。
AlphaGo通过蒙特卡洛树搜索算法和两个深度神经网络合作来完成下棋。在与李世石对阵之前,谷歌首先用人类对弈的近3000万种走法来训练“阿尔法狗”的神经网络,让它学会预测人类专业棋手怎么落子。然后更进一步,让AlphaGo自己跟自己下棋,从而又产生规模庞大的全新的棋谱。谷歌工程师曾宣称AlphaGo每天可以尝试百万量级的走法。
“它们的任务在于合作‘挑选’出那些比较有前途的棋步,抛弃明显的差棋,从而将计算量控制在计算机可以完成的范围内。在本质上,这和人类棋手所做的是一样的。”中国科学院自动化研究所博士研究生刘加奇说。
中国科学院自动化研究所研究员易建强说,“传统的棋类软件,一般采用暴力搜索,包括深蓝计算机,它是对所有可能结果建立搜索树(每个结果是树上的一个果实),根据需要进行遍历搜索。这种方法在象棋、跳棋等方面还具有一定可实现性,但对于围棋就无法实现,因为围棋横竖各19条线,落子的可能性大到计算机无法构建这棵树(果子太多了)来实现遍历搜索。而AlphaGo采用了很聪明的方法,完美解决了这个问题。它利用深度学习的方法降低了搜索树的复杂性,搜索空间得到有效降低。比如,策略网络负责指挥计算机搜索出更像人类高手该落子的位置,而估值网络负责指挥计算机搜索出后续更有可能获胜的一个落子位置。”
刘加奇进一步解释,深度神经网络最基础的一个单元就类似我们人类大脑的神经元,很多层连接起来就好比是人类大脑的神经网络。AlphaGo的两个神经网络“大脑”分别是策略网络和估值网络。
“策略网络主要是用来生成落子策略的。在下棋的过程中,它不是考虑自己应该怎么下,而是想人类的高手会怎么下。也就是说,它会根据输入棋盘当前的一个状态,预测人类下一步棋会下在哪儿,提出最符合人类思维的几种可行的下法。”
然而,策略网络并不知道自己要下出的这步棋到底下得好还是不好,它只知道这步棋是否跟人类下的是一样的,这时候就需要估值网络来发挥作用了。
刘加奇说:“估值网络会为各个可行的下法评估整个盘面的情况,然后给出一个‘胜率’。这些值会反馈到蒙特卡洛树搜索算法中,通过反复如上过程推演出‘胜率’最高的走法。蒙特卡洛树搜索算法决定了策略网络仅会在‘胜率’较高的地方继续推演,这样就可以抛弃某些路线,不用一条道算到黑。”
AlphaGo利用这两个工具来分析局面,判断每种下子策略的优劣,就像人类棋手会判断当前局面以及推断未来的局面一样。在利用蒙特卡洛树搜索算法分析了比如未来20步的情况下,就能判断在哪里下子赢的概率会高。
不过毫无疑问,蒙特卡洛算法是AlphaGo的核心之一。
两个小实验 最后看看蒙特卡洛算法的两个小实验。
- ### 1.计算圆周率pi。 原理:先画一个正方形,画出其内切圆,然后这个正方形内随机的画点,设点落在圆内的概为P,则P=圆面积/正方形面积。 P=(Pi*R*R)/(2R*2R)= Pi/4 ,即 Pi=4P
步骤: 1.将圆心设在原点,以R为半径做圆,则第一象限的1/4圆面积为Pi*R*R/4 2.做该1/4圆的外接正方形, 坐标为(0,0)(0,R)(R,0)(R,R),则该正方形面积为R*R 3.随即取点(X,Y),使得0<=X<=R并且0<=Y<=R,即点在正方形内 4.通过公式 X*X+Y*Y*R判断点是否在1/4圆周内。 5.设所有点(也就是实验次数)的个数为N,落在1/4圆内的点(满足步骤4的点)的个数为M,则
P=M/N 于是Pi=4*N/M
 图片1
图片1
M_C(10000)运行结果为3.1424
- ### 2.蒙特卡洛模拟求函数极值,可避免陷入局部极值
#在区间[-2,2]上随机生成一个数,求出其对应的y,找出里面最大的认为是函数在[-2,2]上的极大值
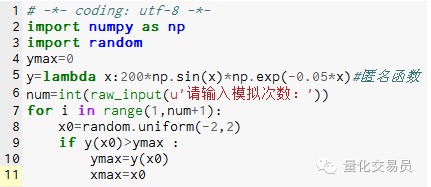 图片2
图片2
模拟1000次后发现极大值为 185.12292832389875(非常准确)
看到这儿,大伙明白了吧。代码可以动手写写啊,很有意思!(python 语言) 转载自微信公众号
- 2.3 下市价单 交易
- 2.2 下限价单 交易
- 2.1 使用API 获取账户信息、 获取行情数据、 获取K线数据、 获取市场深度信息
- 其它功能
- 1.3.4 机器人与策略
- 1.3.2 认识托管者
- 1.3.1 主界面概览及架构
- 1.1 认识什么是量化交易、程序化交易。
- 量化必读:Tick 数据到底是什么?为什么很难找到可靠的交易数据?
- btc策略模拟回测, 为什么没有poloniex选项???
- 用SVM向量机下注(交易),能跑得过大猩猩吗?
- 简单的SVM 分类算法
- 回测实盘级tick有问题
- 关于交易软件的接口
- Python 2.x.x 与 Python 3.x.x 的改动 & Python 2.x.x 转换为 Python 3.x.x 的方法
- 冰与火:实盘与回测
- 干货 -高频交易在怎么挣钱?(转载)
- X 分钟速成 Python
- 思考方法比高频算法更重要
- 开源发明者量化的TA库, 学习使用(含Javascript/Python/C++版本)