基于 KNN 算法的贝叶斯分类器
 0
1999
0
1999
基于 KNN 算法的贝叶斯分类器
设计分类器进行分类决策的理论基础——贝叶斯决策理论:
比较P(ωi|x)。其中ωi为第 i 类,x 为观测到并要分类的一个数据,P(ωi|x)表示在已知这个数据的特征向量的情况下,判断它属于第 i 类的概率是多少,这项也成为后验概率。根据贝叶斯公式,可以将其表示为:
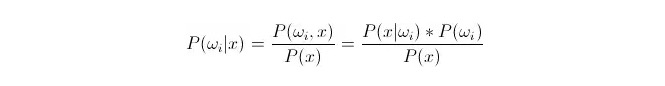
其中,P(x|ωi)称为似然概率或者类条件概率;P(ωi)称为先验概率,因为是与试验无关的,先于试验之前就可以知道的。
在分类时,给定 x,选择使得后验概率P(ωi|x)最大的那个类别即可。在比较每个类别下P(ωi|x)大小时,ωi是变元,而 x 是固定的;所以可以把 P(x)剔除掉,不加以考虑。
所以最终归结为计算P(x|ωi)*P(ωi)的问题。 先验概率 P(ωi)好求,只要统计训练集中每个分类下出现的数据的比例就可以了。
似然概率P(x|ωi)的计算就要破费周折了,因为这个 x是测试集中的数据,根据训练集没法直接得出。那么我们就需要找出训练集数据的分布规律,然后就可以得到P(x|ωi)。
下面介绍 k 近邻算法,英文是 KNN。
我们要根据训练集中的数据 x1,x2…xn (其中每个数据是 m 维),在类别ωi下,拟合这些数据的分布。设 x 为 m 维空间中的任意一点,怎样计算P(x|ωi)?
我们知道,当数据量足够大时,可以用比例近似概率。利用这个原理,在点 x 的周围,找出距离 点x 最近的 k 个样本点,其中属于类别 i 的有 ki 个。计算出这 k 个样本点包围的最小超球的体积V;另求出所有样本数据中属于ωi类的个数 Ni。则:
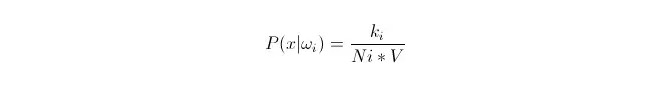
可以看到,我们计算出来的实际上是 点 x 处的类条件概率密度。
P(ωi)怎么算呢? 根据上面的方法,P(ωi)=Ni/N 。其中 N 是样本总数。 另外,P(x)=k/(N*V),其中 k为这个超球体包围的所有样本点的个数;N 为样本总数。 那么P(ωi|x)就可以计算了:带入公式,很容易得出:
P(ωi|x)=ki/k
再解释一下上式,在一个 V 大小的超球体内,包围了 k个样本,其中属于 i 类的有 ki 个。这样,包围的哪类样本最多,我们就判定这里的 x 应该属于哪一类。 这就是用 k 近邻算法设计的分类器。
- 数字货币交易所手续费相关汇总(2017.02.13更新)
- 期货交易年赚千万,他公开系统化及短线高频交易构建核心步骤
- 求助:如何获取一根k线的开盘价和收盘价
- 合成4小时K线的函数(先抛砖引玉,稍后会给出 合成任意周期的代码)
- 各大比特币交易平台取消融资融币功能
- 十大令人困惑不解的经济学“迷思”
- 比特币协议是怎样工作的(下)
- 比特币协议是怎样工作的(上)
- 3.5 策略框架模板
- 量化交易策略——KDJ指标
- 22张图片(鸡汤)
- 为什么说投资需要有战略思维?
- Python -- numpy 矩阵运算
- 算法交易策略
- 马丁格尔策略,孤注一掷的命运?
- JSLint检测Javascript语法规范
- 浅析部分平仓如何影响持仓均价
- 比特币交易网 错误 GetOrders: parameter error
- 炒单系统模式触发设计纲要十条
- 海龟系统交易法则之技术精华