系统地学习正则表达式(一):基础篇
 2
3118
2
3118
系统地学习正则表达式(一):基础篇
什么是正则表达式 正则表达式就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,用来表达对字符串的一种过滤逻辑。
通过正则表达式可以达到如下的目的:
给定的字符串是否符合正则表达式的过滤逻辑(称作“匹配”); 可以通过正则表达式,从字符串中获取我们想要的特定部分。为了让大家更方便地学习,先推荐一个验证正则表达式的软件Regextor,具体可以看我的这篇文章,里面还推荐了很多Mac上的好软件。
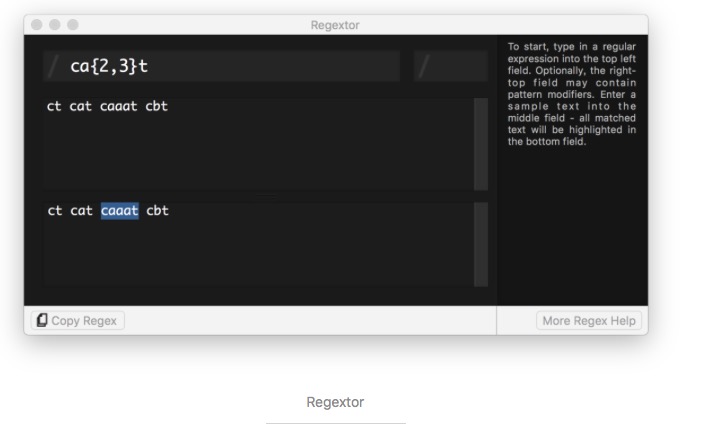
下面开始讲解正则表达式各种规则:
-
匹配普通文本字符
正则表达式可以只包含普通的文本,代表去精确匹配这个文本。例如:
正则表达式:
song待匹配文本:xiaosongge,xiaoSongge 匹配后结果:xiaosongge,xiaoSongge 正则表达式默认是区分大小写的,所以song不会匹配 “Song” 。但是大部分的正则表达式实现都提供了一个选项表示不区分大小写。
-
匹配任意字符
. 用来匹配一个任意字符,例如:
正则表达式:c.t 待匹配文本:cat cet caaat dog 匹配后结果:
catcetcaaat dog 分析:c.t会匹配以” c “开头,以” t “结尾,中间为任意字符的字符串。同理,多个连续的.可以匹配多个连续的任意字符:
正则表达式:c..t 待匹配文本:cat cet caat dog 匹配后结果:cat cet
caatdog
-
匹配特殊字符
.在正则表达式中含有特殊的意义,是一个特殊的字符。\也是特殊字符,可以对特殊字符起到转义作用。如果你想匹配的是一个真正的” . “字符,需要在.前面加上\对字符进行转义。所以,.表示真正的” . “字符。
正则表达式:c.t 待匹配文本:cat c.t dog 匹配后结果:cat
c.tdog 注意:因为\也是特殊字符,所以想要匹配一个真正的” \ “字符,需要使用两个反斜线\:正则表达式:c\t 待匹配文本:cat c\t dog 匹配后结果:cat
c\tdog
-
使用字符集合
上面说到.能匹配一个任意字符,但是如果我想匹配几个特定字符怎么办?匹配一组特定的字符可以使用[和]元字符。
正则表达式:c[ab]t 待匹配文本:cat cbt cet 匹配后结果:
catcbtcet 分析:[ab]会匹配” a “或者” b “。所以c[ab]t会匹配” cat “和” cbt “而不会匹配” cet “。
-
使用字符组区间
在上面的例子中,假如我想匹配cet怎么办,在[]里面多加一个吗?那如果我想匹配任意小写字母呢,往里面写几十个吗?虽然是可以的,但是太长了。这里我们可以用到[a-z]:
正则表达式:c[a-z]t 待匹配文本:cat cbt czt c2t 匹配后结果:
catcbtcztc2t 分析:c[a-z]t表示以” c “开头,” t “结尾,中间为字母 ” a “ - ” z “ 的任意一个字母。类似的区间还有:
[0-9] 和[0123456789]的功能一样。匹配所有的数字。 [A-F] 匹配A到F的大写字符。 [A-Z] 匹配所有的 A 到 Z 的大写字符。 [a-z] 匹配所有的 a 到 z 的小写字符。 [A-z] 匹配从 ASCII A 到 ASCII z 的所有字符(不仅仅匹配所有字母,还匹配在 ASCII 表中 A 到 z 中的字符,如 [ 和 ^ 等)。 [A-Za-z0-9] 匹配所有的大小写字母和数字。
-
非字符集的匹配
字符集合一般用于指定一组需要匹配的字符。但是有些时候,你想要排除一组你不想匹配的字符。可以通过对于字符集合的否定来实现。例如:
正则表达式:c[^a-z]t 待匹配文本:cat cbt czt c2t cAt 匹配后结果:cat cbt czt
c2tcAt分析:这个和前面一个例子完全相反。[a-z] 匹配所有的小写字母,而 [^a-z] 匹配所有的不是小写字母的字符。注意,^字符是将字符集合中的所有字符都取消匹配。
-
元字符
元字符在正则表达式中有特殊的意义,上面我们已经说了几个元字符,比如.、[和]。这些字符不能直接表示自己的含义,例如,不能直接使用[来匹配” [ “,使用.来匹配” . “。
所有的元字符都可以在前面加上反斜线转义,当转义后,字符将匹配自身而不是其特殊含义。例如,[将匹配” [ “:
正则表达式:a[b 待匹配文本:a[b ab a[[b 匹配后结果:
a[bab a[[b 注意:\用来转义元字符,这也意味着\也是一个元字符。所以如果需要匹配真正的” \ “,可以使用\:正则表达式:a\b 待匹配文本:a\b a\b a[[b 匹配后结果:a\b
a\ba[[b
-
空白字符
有时候你可能需要匹配文本中不能打印的空白字符。例如,你希望能够找到所有的 Tab 字符,或者是所有的换行符。你可以使用下表中的特殊元字符:
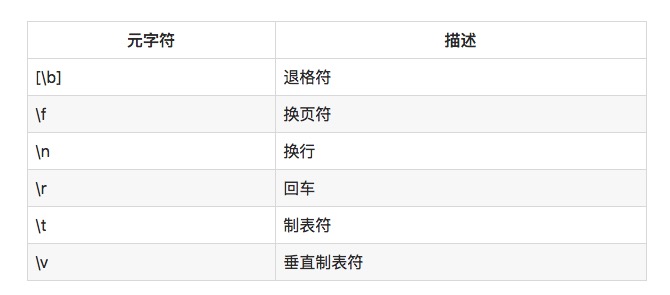
例如\r\n将匹配一个回车换行组合,在 Windows 中表示一个文件换行。在 Linux 和 Unix 系统中,只需要使用\n即可。
-
匹配特定的字符类型
有一些特殊的元字符可以用来匹配常用的字符集合。这些元字符被称为匹配字符类。你会发现使用它们是很方便的。
匹配数字或者非数字 上面说到,[0-9] 可以匹配所有的数字。如果不想匹配任何数字,则可以使用[^0-9]。下表中列出了数字和非数字的类元字符:

正则表达式:c\dt 待匹配文本:cat c2t czt c9t 匹配后结果:cat
c2tcztc9t正则表达式:c\Dt 待匹配文本:cat c2t czt c9t 匹配后结果:
catc2tcztc9t 匹配字母字符和非字母字符 另外一个常用的类元字符是\w和\W: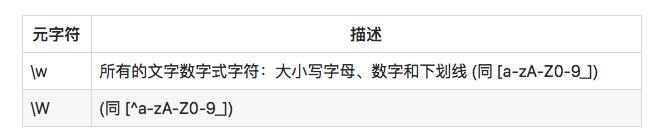
正则表达式:c\wt 待匹配文本:cat c2t czt c-t c\t 匹配后结果:
catc2tc-t c\t正则表达式:c\Wt 待匹配文本:cat c2t c-t c\t 匹配后结果:cat c2t
c-tc\t匹配空白和非空白 最后一个将要遇到的匹配类是空白类:
正则表达式:c\st 待匹配文本:cat c t c2t c\t 匹配后结果:cat
c tc2t c\t正则表达式:c\St 待匹配文本:cat c t c2t c\t 匹配后结果:
catc tc2tc\t
-
匹配一个或者更多字符
+元字符表示匹配一个或者多个字符。例如,a将匹配”a”,而a+则匹配一个或者多个”a”。
正则表达式:cat 待匹配文本:ct cat caat caaat 匹配后结果:ct
catcaat caaat正则表达式:ca+t 待匹配文本:ct cat caat caaat 匹配后结果:ct
catcaatcaaat当在字符集合上使用+的时候,需要将+符号放在集合外面:正则表达式:c[0-9]+t 待匹配文本:ct c0t cat c123t 匹配后结果:ct
c0tcatc123t分析:c[0-9]+t表示以” c “开头,以” t “结尾,中间为一个或多个数字的字符串。当然,[0-9+]也是一个合法的正则表达式,但它表示一个包含 ” 0 “ - ” 9 “ 和 ” + “ 符号的字符集合。
一般的,元字符如.和+等用于字符集合的时候是作为字面含义使用的,因此没有必要转义。但是对其进行转义也没错,所以,[0-9+]和[0-9+]的功能是一样的。
注意:+是一个元字符,匹配”+“需要使用转义+。
-
匹配零个或者更多字符
如果希望匹配零个或更多字符的时候,可以使用*元字符。
正则表达式:ca*t 待匹配文本:ct cat caat cbt 匹配后结果:
ctcatcaatcbt 注意:*符号是元字符。为了能够匹配” * “,需要进行转义*。
-
匹配零个或者一个字符
? 匹配零个或者一个字符。所以,?非常适合于在文本中匹配一个可选的字符。
正则表达式:ca?t 待匹配文本:ct cat caat cbt 匹配后结果:
ctcatcaat cbt 注意:?符号是元字符。为了能够匹配” ? “,需要进行转义\?。
-
使用匹配次数
正则表达式允许指定匹配的次数。次数可以在“ { ”和“ } ”之间指定。 注意:{和}也是元字符,在使用字面含义的时候需要转义。
精确次数匹配 为了指定匹配的次数,你可以在{和}之间输入数字。例如,{3}将匹配 3 次前面出现的字符或集合:
正则表达式:ca{3}t 待匹配文本:ct cat caaat cbt 匹配后结果:ct cat
caaatcbt 至少次数匹配 我们也可以只指定匹配的最小值。例如,{2,}意味着匹配 2次或者更多次:正则表达式:ca{1,}t 待匹配文本:ct cat caaat cbt 匹配后结果:ct
catcaaatcbt 次数区间匹配 我们还可以使用最小值和最大值来确定匹配的数量。例如,{2,3}意味着最少匹配 2次,最多匹配3次。正则表达式:ca{2,3}t 待匹配文本:ct cat caaat cbt 匹配后结果:ct cat
caaatcbt 所以?和{0,1}的功能是一样的,+和 {1,}的作用是一样的。
-
非贪婪匹配
先看看下面的例子:
正则表达式:s.*g 待匹配文本:xiao song xiao song 匹配后结果:xiao song xiao song 分析:s.*g并没像预想中的匹配两个” song “,而是匹配了第一个” s “和最后一个 ” g “之间的所有文本。
这是因为*和+都是贪婪匹配。也就是说,正则表达式总是寻找最大的匹配,而不是最小的,这是故意设计的。
但是如果你不希望贪婪匹配的时候就要使用这些量词的非贪婪匹配(匹配尽可能少的字符)。非贪婪量词是在量词后面加上?:

*?是的非贪婪版本,所以可以使用?来修改上面的例子:
正则表达式:s.?g 待匹配文本:xiao song xiao song 匹配后结果:xiao
songxiaosong分析:可以看到s.?g匹配到了两个” song “。
-
定义字符串边界
字符串边界匹配的元字符是^和$,分别用于字符串的开始和结束。
^用法如下:
正则表达式:^xiao
待匹配文本:xiaosong 匹配后结果:
xiaosong待匹配文本:axiaosong 匹配后结果:axiaosong 分析:^xiao匹配以” xiao “开头的字符串。
$用法如下:
正则表达式:song$
待匹配文本:xiaosong 匹配后结果:xiao
song待匹配文本:xiaosonga 匹配后结果:xiaosonga 分析:song$匹配以”song “结尾的字符串。
共同使用:
正则表达式:^[0-9a-zA-Z]{4,}$
待匹配文本:a1b234ABC 匹配后结果:
a1b234ABC待匹配文本:+a1b23=4ABC 匹配后结果:+a1b23=4ABC 分析:^[0-9a-zA-Z]{4,}$匹配用数字或者字母组成的,并且位数大于等于四位的字符串。
注意:^如果位于集合开始处的话,则表示否定;如果在集合外面,则将匹配字符串的开始位置。大家可以试试[^0-9]和^[0-9]的区别。
-
使用多行模式
但是(?m)可以启用多行模式。在多行模式下,正则表达式引擎将换行符作为字符串的分隔符,^将匹配文本的开始或者一行的开始,而$则可以匹配文本的结束或者是一行的结尾处。
修改下上个例子:
正则表达式:(?m)^[0-9a-zA-Z]{4,}$
待匹配文本:a1b234ABC +a1b23=4ABC ABC123456
匹配后结果:
a1b234ABC+a1b23=4ABCABC123456分析:(?m)^[0-9a-zA-Z]{4,}$会去匹配每行用数字或者字母组成的,并且位数大于等于四位的字符串。注意:如果使用多行模式的话,(?m)必须放置在正则表达式的开始。 (?m)在大部分的正则表达式实现中并不支持。有些正则表达式实现还支持使用\A匹配字符串的开始,\Z匹配字符串的结束。如果支持的话,则这些元字符的功能和^、$是一样的。但是这些元字符不能使用(?m)修饰,所以也不能用于多行模式。
这篇先讲基础,看完可以看下一篇《系统地学习正则表达式(二):进阶篇》。
转载自 简书 iOS_小松哥
- 主观与量化,相生与相克
- 顺势交易与借势交易
- 如何使用 “画线类库” 模板 画出 2 个 Y 轴
- 实盘进行程序化交易需要注意的7个问题
- 希望支持bitmex平台
- 求支持coinbase和itbit
- 求出的macd,请 @小小梦 看下
- 评价算法交易表现的指标---夏普比率
- 一种新型的网格交易法则
- 感觉韭菜都被你们割了 我还是持币好了
- Python 朴素贝叶斯 应用
- 螺纹钢、铁矿石比值交易策略的应用分析
- 要如何分析期权的波动率?
- 程序化在期权的应用
- 时间与周期
- 大脑中的支持向量机
- 聊聊做市商和对赌
- 世上最深的路,就是你的套路:深挖套利江湖的那些“坑”
- 读《概率统计超入门》及《万万没想到之最简单概率论的五个智慧》
- 资金管理三部曲:格局为先