
1.介绍
上一篇文章介绍了使用LSTM网络预测比特币价格 https://www.fmz.com/digest-topic/4035 ,正如文章提到的,只是一个练手的小项目,用来熟悉RNN以及pytorch。本文将介绍使用强化学习的方法,直接训练交易策略。强化学习的模型为OpenAI开源的PPO,环境则参考了gym的样式。为了方便理解和测试,LSTM的PPO模型和回测的gym环境都直接编写未使用现成的包。
PPO,全称Proximal Policy Optimization,是对Policy Graident,即策略梯度的一种优化改进。gym也是由OpenAI发布,可以与策略网络交互,反馈目前环境的状态和奖励,就像强化学习的练习用使用LSTM的PPO模型直接根据比特币的行情信息做出买入、卖出或不操作的指令,由回测环境给出反馈,通过训练不断优化模型,达到策略盈利的目的。
阅读本文需要一定的Python、pytorch、DRL深度强化学习的基础。但不会关系也不大,结合本文给出的代码,很容易学习入门。本文FMZ发明者数字货币量化交易平台出品(www.fmz.com),欢迎入QQ群:863946592 交流。
2.数据和学习参考资料
比特币价格数据来源自FMZ发明者量化交易平台:https://www.quantinfo.com/Tools/View/4.html
一篇使用DRL+gym来训练交易策略的文章:https://towardsdatascience.com/visualizing-stock-trading-agents-using-matplotlib-and-gym-584c992bc6d4
入门pytorch的一些例子:https://github.com/yunjey/pytorch-tutorial
本文将直接使用这个LSTM-PPO模型的简短实现:https://github.com/seungeunrho/minimalRL/blob/master/ppo-lstm.py
有关PPO的文章:https://zhuanlan.zhihu.com/p/38185553
有关DRL更多的文章:https://www.zhihu.com/people/flood-sung/posts
关于gym,本文并不需要安装,但是强化学习很常用:https://gym.openai.com/
3.LSTM-PPO
关于PPO的深入讲解,可以学习前面的参考资料,这里只是简单理念的介绍。上一期LSTM网络只是预测了一个价格,如何根据这个预测价格买卖交易还要另外实现,自然可以想到,直接输出买卖动作不是更加直接吗?Policy Graident就是如此,可以根据输入的环境信息s,给出一个各种动作action的概率。LSTM的损失是预测价格和实际价格之间的差别,而PG的损失为-log(p)*Q,其中p为输出的某个动作的概率,Q为这个动作的价值(如奖励得分),直观的解释是如果一个动作的价值越高,网络要输出更高的概率来减小损失。PPO虽然复杂了很多,但原理也类似,关键在于如何更好的评价每个动作的价值以及如何更好的更新参数。
下面将给出LSTM-PPO的源码,结合前面的资料还是可以理解的:
python
import time
import requests
import json
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.distributions import Categorical
from itertools import count
#模型的超参数
learning_rate = 0.0005
gamma = 0.98
lmbda = 0.95
eps_clip = 0.1
K_epoch = 3
device = torch.device('cpu') # 也可以改为GPU版本
class PPO(nn.Module):
def __init__(self, state_size, action_size):
super(PPO, self).__init__()
self.data = []
self.fc1 = nn.Linear(state_size,10)
self.lstm = nn.LSTM(10,10)
self.fc_pi = nn.Linear(10,action_size)
self.fc_v = nn.Linear(10,1)
self.optimizer = optim.Adam(self.parameters(), lr=learning_rate)
def pi(self, x, hidden):
#输出各个动作的概率,由于是LSTM网络还要包含hidden层的信息,可以参考上一期文章
x = F.relu(self.fc1(x))
x = x.view(-1, 1, 10)
x, lstm_hidden = self.lstm(x, hidden)
x = self.fc_pi(x)
prob = F.softmax(x, dim=2)
return prob, lstm_hidden
def v(self, x, hidden):
#价值函数,用于评价当前局面的好坏,所以只有一个输出
x = F.relu(self.fc1(x))
x = x.view(-1, 1, 10)
x, lstm_hidden = self.lstm(x, hidden)
v = self.fc_v(x)
return v
def put_data(self, transition):
self.data.append(transition)
def make_batch(self):
#准备训练数据
s_lst, a_lst, r_lst, s_prime_lst, prob_a_lst, hidden_lst, done_lst = [], [], [], [], [], [], []
for transition in self.data:
s, a, r, s_prime, prob_a, hidden, done = transition
s_lst.append(s)
a_lst.append([a])
r_lst.append([r])
s_prime_lst.append(s_prime)
prob_a_lst.append([prob_a])
hidden_lst.append(hidden)
done_mask = 0 if done else 1
done_lst.append([done_mask])
s,a,r,s_prime,done_mask,prob_a = torch.tensor(s_lst, dtype=torch.float), torch.tensor(a_lst), \
torch.tensor(r_lst), torch.tensor(s_prime_lst, dtype=torch.float), \
torch.tensor(done_lst, dtype=torch.float), torch.tensor(prob_a_lst)
self.data = []
return s,a,r,s_prime, done_mask, prob_a, hidden_lst[0]
def train_net(self):
s,a,r,s_prime,done_mask, prob_a, (h1,h2) = self.make_batch()
first_hidden = (h1.detach(), h2.detach())
for i in range(K_epoch):
v_prime = self.v(s_prime, first_hidden).squeeze(1)
td_target = r + gamma * v_prime * done_mask
v_s = self.v(s, first_hidden).squeeze(1)
delta = td_target - v_s
delta = delta.detach().numpy()
advantage_lst = []
advantage = 0.0
for item in delta[::-1]:
advantage = gamma * lmbda * advantage + item[0]
advantage_lst.append([advantage])
advantage_lst.reverse()
advantage = torch.tensor(advantage_lst, dtype=torch.float)
pi, _ = self.pi(s, first_hidden)
pi_a = pi.squeeze(1).gather(1,a)
ratio = torch.exp(torch.log(pi_a) - torch.log(prob_a)) # a/b == log(exp(a)-exp(b))
surr1 = ratio * advantage
surr2 = torch.clamp(ratio, 1-eps_clip, 1+eps_clip) * advantage
loss = -torch.min(surr1, surr2) + F.smooth_l1_loss(v_s, td_target.detach()) #同时训练了价值网络和决策网络
self.optimizer.zero_grad()
loss.mean().backward(retain_graph=True)
self.optimizer.step()
4.比特币回测环境
仿照了gym的格式,有一个reset初始化方法,step输入动作,返回的结果为(下一个状态, 动作收益, 是否结束, 额外的信息),整个回测环境也就60行,可自行修改出更复杂的版本,具体代码:
python
class BitcoinTradingEnv:
def __init__(self, df, commission=0.00075, initial_balance=10000, initial_stocks=1, all_data = False, sample_length= 500):
self.initial_stocks = initial_stocks #初始的比特币数量
self.initial_balance = initial_balance #初始的资产
self.current_time = 0 #回测的时间位置
self.commission = commission #易手续费
self.done = False #回测是否结束
self.df = df
self.norm_df = 100*(self.df/self.df.shift(1)-1).fillna(0) #标准化方法,简单的收益率标准化
self.mode = all_data # 是否为抽样回测模式
self.sample_length = 500 # 抽样长度
def reset(self):
self.balance = self.initial_balance
self.stocks = self.initial_stocks
self.last_profit = 0
if self.mode:
self.start = 0
self.end = self.df.shape[0]-1
else:
self.start = np.random.randint(0,self.df.shape[0]-self.sample_length)
self.end = self.start + self.sample_length
self.initial_value = self.initial_balance + self.initial_stocks*self.df.iloc[self.start,4]
self.stocks_value = self.initial_stocks*self.df.iloc[self.start,4]
self.stocks_pct = self.stocks_value/self.initial_value
self.value = self.initial_value
self.current_time = self.start
return np.concatenate([self.norm_df[['o','h','l','c','v']].iloc[self.start].values , [self.balance/10000, self.stocks/1]])
def step(self, action):
#action即策略采取的动作,这里将更新账户和计算reward
done = False
if action == 0: #持有
pass
elif action == 1: #买入
buy_value = self.balance*0.5
if buy_value > 1: #余钱不足,不操作账户
self.balance -= buy_value
self.stocks += (1-self.commission)*buy_value/self.df.iloc[self.current_time,4]
elif action == 2: #卖出
sell_amount = self.stocks*0.5
if sell_amount > 0.0001:
self.stocks -= sell_amount
self.balance += (1-self.commission)*sell_amount*self.df.iloc[self.current_time,4]
self.current_time += 1
if self.current_time == self.end:
done = True
self.value = self.balance + self.stocks*self.df.iloc[self.current_time,4]
self.stocks_value = self.stocks*self.df.iloc[self.current_time,4]
self.stocks_pct = self.stocks_value/self.value
if self.value < 0.1*self.initial_value:
done = True
profit = self.value - (self.initial_balance+self.initial_stocks*self.df.iloc[self.current_time,4])
reward = profit - self.last_profit # 每回合的reward是新增收益
self.last_profit = profit
next_state = np.concatenate([self.norm_df[['o','h','l','c','v']].iloc[self.current_time].values , [self.balance/10000, self.stocks/1]])
return (next_state, reward, done, profit)
5.几个值得注意的细节
初始账户为什么有币?
回测环境计算收益的公式为:当前收益 = 当前账户价值 - 初始账户当前价值。这意味着,如果比特币价格下跌,而策略做出了卖币操作,即使总账户价值减少了,实际上也应该给与策略奖励。如果回测的时间很长,初始账户可能影响不大,但刚开始时还是影响很大的。计算相对收益保证了每次正确的操作都获取了正向的reward。
训练时行情为什么抽样?
总的数据量有一万多根K线,如果每次都是全量的跑一个循环,所需要的时间很长,并且策略每次面对的情况的一模一样,可能更容易过拟合。每次抽取500根作为一次回测数据,虽然仍有可能过拟合,但策略面临了一万多次不同的可能开局。
没有币或没有钱了怎么办?
回测环境里没有考虑这种情况,如果币已经卖光了或者达不到最小交易量,此时执行卖出操作其实相当于执行不操作,如果价格下跌,根据相对收益的计算方式,仍然基于了策略正向的reward。这种情况的影响是在策略判断行情下跌并且账户余币无法卖出时,无法区分卖出动作和不操作动作,但对策略本身对行情的判断没有影响。
为什么要把账户信息返回作为状态?
PPO模型有一个价值网络用于评价当前状态的价值,显然如果策略判断价格要上涨,只有当前账户持有比特币时整个状态才有正向价值,反之亦然。所以账户信息是价值网络判断的重要依据。注意到并未把过去的动作信息作为状态返回,个人认为这对判断价值无用。
什么情况下会返回不操作?
当策略判断买卖带来的收益无法覆盖手续费时,应该返回不操作。虽然前面的描述反复用了策略判断价格趋势,但只是为了方便理解,实际上这个PPO模型并没有对行情做出预测,只是输出了三个动作的概率而已。
6.数据的获取和训练
和上一篇文章一样,数据的获取方式和格式如下,Bitfinex交易所BTC_USD交易对 2018/5/7到2019/6/27 的一小时周期K线:
python
resp = requests.get('https://www.quantinfo.com/API/m/chart/history?symbol=BTC_USD_BITFINEX&resolution=60&from=1525622626&to=1561607596')
data = resp.json()
df = pd.DataFrame(data,columns = ['t','o','h','l','c','v'])
df.index = df['t']
df = df.dropna()
df = df.astype(np.float32)
由于使用了LSTM网络,训练的时间很长,我又改了个GPU版本的,大约快了3倍。
python
env = BitcoinTradingEnv(df)
model = PPO()
total_profit = 0 #记录总收益
profit_list = [] #记录每次训练收益
for n_epi in range(10000):
hidden = (torch.zeros([1, 1, 32], dtype=torch.float).to(device), torch.zeros([1, 1, 32], dtype=torch.float).to(device))
s = env.reset()
done = False
buy_action = 0
sell_action = 0
while not done:
h_input = hidden
prob, hidden = model.pi(torch.from_numpy(s).float().to(device), h_input)
prob = prob.view(-1)
m = Categorical(prob)
a = m.sample().item()
if a==1:
buy_action += 1
if a==2:
sell_action += 1
s_prime, r, done, profit = env.step(a)
model.put_data((s, a, r/10.0, s_prime, prob[a].item(), h_input, done))
s = s_prime
model.train_net()
profit_list.append(profit)
total_profit += profit
if n_epi%10==0:
print("# of episode :{:<5}, profit : {:<8.1f}, buy :{:<3}, sell :{:<3}, total profit: {:<20.1f}".format(n_epi, profit, buy_action, sell_action, total_profit))
7.训练结果和分析
经过漫长的等待:

首先看一下训练数据的行情,总的来说,前半段是漫长的下跌,后半段是强劲的反弹。
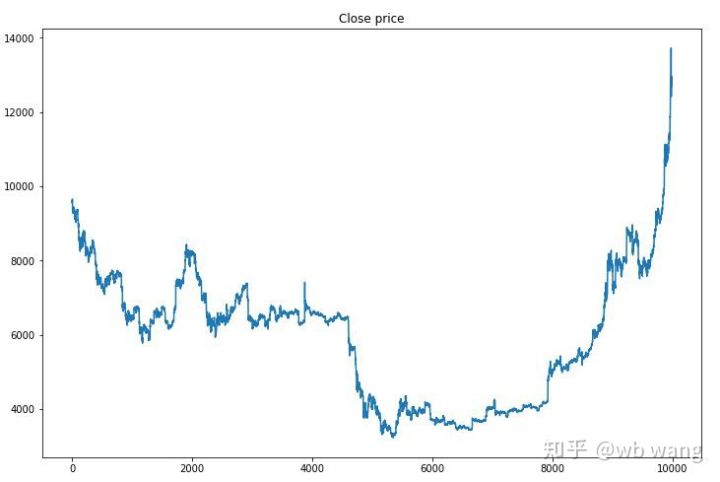
训练前期买入操作很多,基本上没有盈利的回合。到训练中期买入操作逐渐减少,盈利的概率也越来越大,但任然有很大的几率亏损。
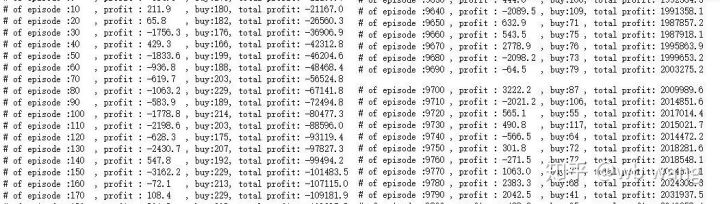
将每回合收益平滑一下,结果如下:
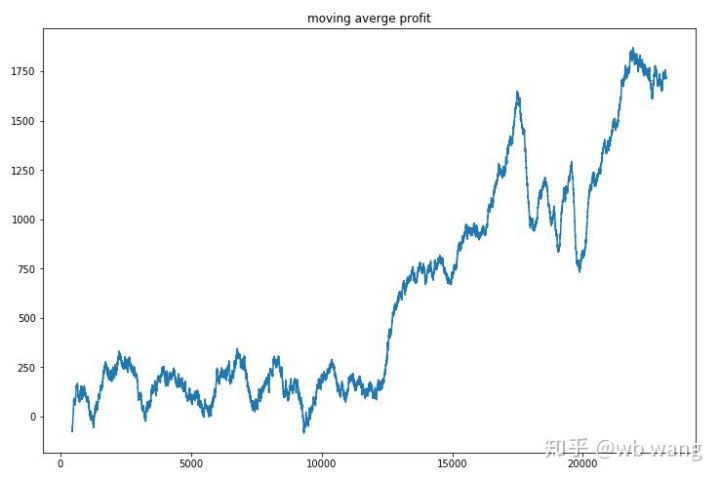
策略很快摆脱了前期收益为负的情况,但起伏较大,直到10000回合之后,收益才迅速增长了起来,总的来说,模型训练的很艰难。
最终训练结束后,再让模型跑一次全部数据,看看表现如何,期间记录下账户的总市值、持有比特币数量、比特币价值占比、总收益。
首先是总市值,总收益和其类似,就不贴了:
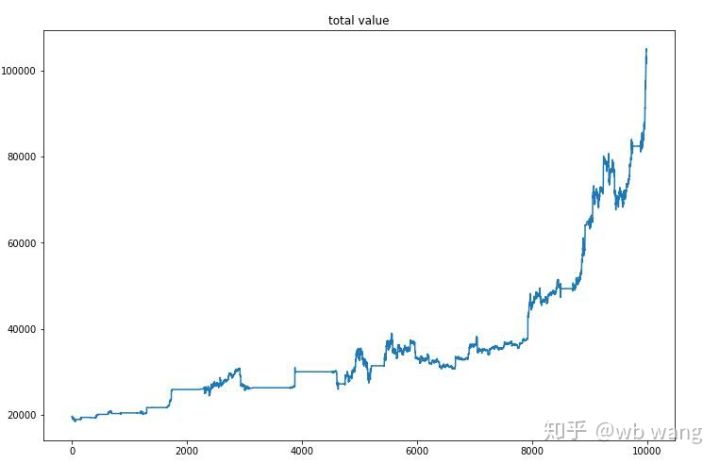
总市值在前期熊市时,缓慢增加,在后期牛市时也跟上了上涨,但还是出现了阶段性的亏损。
最后看一下持仓占比,图的左轴是持仓占比,右轴是行情,可以初步判断模型出现了过拟合,在前期熊市时持仓频率低,在行情底部时持仓频率很高。还可以看到模型并没有学会长期持仓,总是很快的卖出。
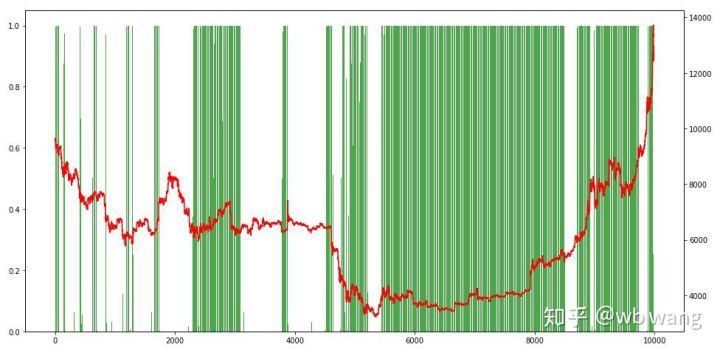
8.测试数据分析
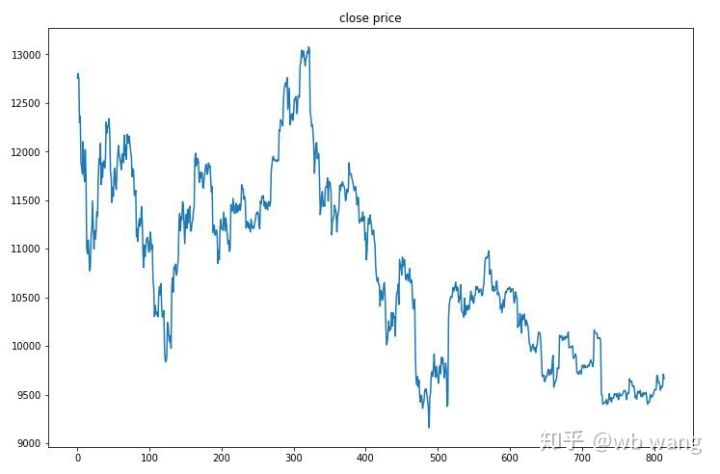
测试数据取得时2019/6/27至今的比特币一小时行情。图中可以看到价格从开始的13000美元跌倒如今的9000多美元,对模型可以说考验很大。
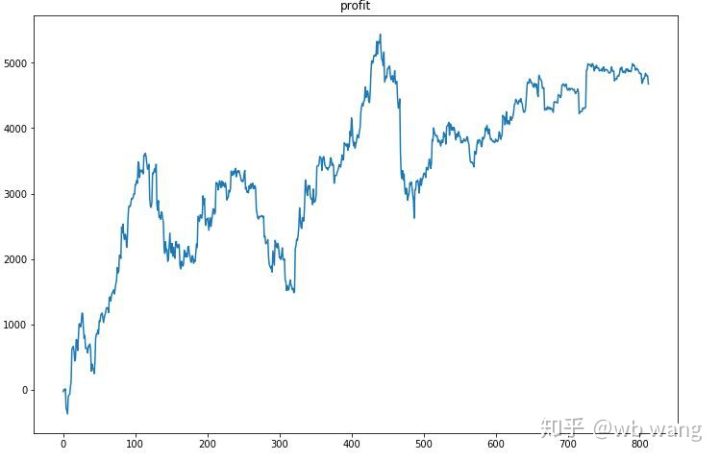
首先最终相对收益,表现差强人意,但也没有亏损。
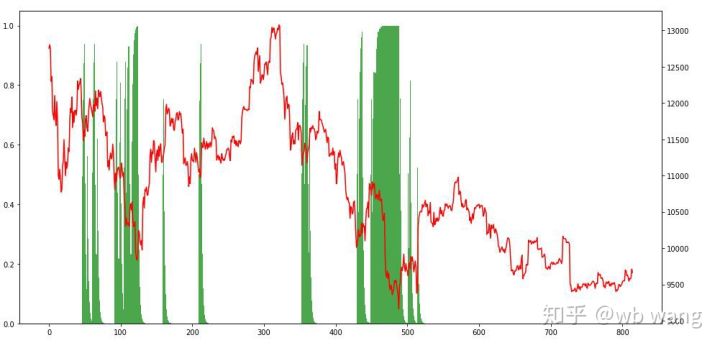
再看持仓情况,可以猜测模型倾向于急跌后买入等反弹卖出,最近一段时间比特币行情波动很小,模型一直处于空仓状态。
9.总结
本文借助于深度强化学习方法PPO训练了一个比特币自动交易机器人,还算得到了一些结论。由于时间有限,模型还有一些可完善的地方,欢迎大家讨论。其中最大的教训是数据标准化是的方法,不要采用缩放之类的方法,否则模型会很快记住价格和行情的关系,陷入过拟合。变化率标准化后是相对数据,让模型很难记住和行情的关系,被迫寻找变化率和涨跌的联系。
往期文章介绍:
FMZ发明者量化平台上一些公开的策略分享:https://zhuanlan.zhihu.com/p/64961672
网易云课堂的数字货币量化交易课程,只要20元:https://study.163.com/course/courseMain.htm?courseId=1006074239&share=2&shareId=400000000602076
我公开的一个曾经很赚钱的高频策略:https://www.fmz.com/bbs-topic/1211


profit = self.value - (self.initial_balance+self.initial_stocks * self.df.iloc[self.current_time,4]) 有bug
应该是:profit = self.value - (self.initial_balance+self.initial_stocks * self.df.iloc[self.start,4])
profit = self.value - (self.initial_balance+self.initial_stocksself.df.iloc[self.current_time,4]) 有bug
应该是:profit = self.value - (self.initial_balance+self.initial_stocksself.df.iloc[self.start,4])




GPU版
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
class PPO(nn.Module):
def __init__(self):
super(PPO, self).__init__()
self.data = []
self.fc1 = nn.Linear(8,64)
self.lstm = nn.LSTM(64,32)
self.fc_pi = nn.Linear(32,3)
self.fc_v = nn.Linear(32,1)
self.optimizer = optim.Adam(self.parameters(), lr=learning_rate)
def pi(self, x, hidden):
x = F.relu(self.fc1(x))
x = x.view(-1, 1, 64)
x, lstm_hidden = self.lstm(x, hidden )
x = self.fc_pi(x)
prob = F.softmax(x, dim=2)
return prob, lstm_hidden
def v(self, x, hidden):
x = F.relu(self.fc1(x))
x = x.view(-1, 1, 64)
x, lstm_hidden = self.lstm(x, hidden)
v = self.fc_v(x)
return v
def put_data(self, transition):
self.data.append(transition)
def make_batch(self):
s_lst, a_lst, r_lst, s_prime_lst, prob_a_lst, hidden_lst, done_lst = [], [], [], [], [], [], []
for transition in self.data:
s, a, r, s_prime, prob_a, hidden, done = transition
s_lst.append(s)
a_lst.append([a])
r_lst.append([r])
s_prime_lst.append(s_prime)
prob_a_lst.append([prob_a])
hidden_lst.append(hidden)
done_mask = 0 if done else 1
done_lst.append([done_mask])
s,a,r,s_prime,done_mask,prob_a = torch.tensor(s_lst, dtype=torch.float).to(device), torch.tensor(a_lst).to(device).to(device), \
torch.tensor(r_lst).to(device), torch.tensor(s_prime_lst, dtype=torch.float).to(device), \
torch.tensor(done_lst, dtype=torch.float).to(device), torch.tensor(prob_a_lst).to(device)
self.data = []
return s,a,r,s_prime, done_mask, prob_a, hidden_lst[0]
def train_net(self):
s,a,r,s_prime,done_mask, prob_a, (h1,h2) = self.make_batch()
first_hidden = (h1.to(device).detach(), h2.to(device).detach())
for i in range(K_epoch):
v_prime = self.v(s_prime, first_hidden).squeeze(1)
td_target = r + gamma * v_prime * done_mask
v_s = self.v(s, first_hidden).squeeze(1)
delta = td_target - v_s
delta = delta.cpu().detach().numpy()
advantage_lst = []
advantage = 0.0
for item in delta[::-1]:
advantage = gamma * lmbda * advantage + item[0]
advantage_lst.append([advantage])
advantage_lst.reverse()
advantage = torch.tensor(advantage_lst, dtype=torch.float).to(device)
pi, _ = self.pi(s, first_hidden)
pi_a = pi.squeeze(1).gather(1,a)
ratio = torch.exp(torch.log(pi_a) - torch.log(prob_a)) # a/b == log(exp(a)-exp(b))
surr1 = ratio * advantage
surr2 = torch.clamp(ratio, 1-eps_clip, 1+eps_clip) * advantage
loss = -torch.min(surr1, surr2) + F.smooth_l1_loss(v_s, td_target.detach())
self.optimizer.zero_grad()
loss.mean().backward(retain_graph=True)
self.optimizer.step()
- 1