

这篇文章的灵感来自于我在发明者量化平台进行数据研究期间,尝试将机器学习技术应用于交易问题后对一些常见警告和陷阱的观察。
如果你还没有阅读我以前的文章,我们建议你在本文之前阅读我之前在发明者量化平台建立的自动化数据研究环境指南和制定交易策略的系统方法。
地址在这里: https://www.fmz.com/digest-topic/4187 以及 https://www.fmz.com/digest-topic/4169 这两篇文章.
关于研究环境的搭建
本教程旨在为各个段位技能水平的爱好者,工程师和数据科学家使用,无论你是行业大牛还是编程小白,你需要的唯一技能是对Python编程语言的基本了解以及命令行操作的足够知识(能设置一个数据科学项目即可)
- 安装发明者量化托管者和设置Anaconda
发明者量化平台FMZ.COM除了提供优质的各大主流交易所的数据源,还提供一套丰富的API接口以帮助我们在完成数据的分析后进行自动化交易。这套接口包括查询账户信息,查询各个主流交易所的高,开,低,收价格,成交量,各种常用技术分析指标等实用工具,特别是对于实际交易过程中连接各大主流交易所的公共API接口,提供了强大的技术支持。
所有上边提到的这些特征,都被封装到一个类似Docker的系统当中,我们要做的,就是购买或者租赁好自己的云计算服务后,把这个Docker系统部署完成即可。
在发明者量化平台的官方称呼中,这个Docker系统被称为托管者系统。
关于如何部署托管者和机器人,请参考我之前的文章:https://www.fmz.com/bbs-topic/4140
想购买自己云计算服务器部署托管者的读者,可以参考这篇文章:https://www.fmz.com/bbs-topic/2848
在成功部署好云计算服务与托管者系统后,接下来,我们要安装Python目前最大的神器:Anaconda
为了实现本文所需的所有相关程序环境(依赖库,版本管理等),最简单的办法就是用Anaconda。它是一个打包的Python数据科学生态系统和依赖库管理器。
由于我们是在云服务上安装Anaconda,因此我们推荐云服务器安装Linux系统加命令行版本的Anaconda。
关于Anaconda的安装方法,请查看Anaconda官方指南:https://www.anaconda.com/distribution/
如果你是一个经验丰富的Python程序员,觉得不需要使用Anaconda,那也完全没有问题。我会假设你在安装必须的依赖环境时不需要帮助,你可以直接跳过这个部分。
制定交易策略
交易策略的最终输出应回答以下问题:
-
方向:确定资产是否便宜,昂贵或者价值公允.
-
开仓条件:如果资产价格便宜或者昂贵,你应该做多或者做空.
-
平仓交易:如果资产价格合理且我们在该资产中持有仓位(先前的买入或卖出),你是否应平仓
-
价格范围:进行开仓交易的价格(或范围)
-
数量:交易资金的数量(例如数字货币的数量或者商品期货的手数)
机器学习可用于回答以上每个问题,但对于本文的其余部分,我们将重点回答第一个问题,即交易方向。
策略方法
构建策略,有两种类型的方法,一种为基于模型;另一种为基于数据挖掘。这二者基本上是互为相反的方法。
在基于模型的策略构建中,我们从市场低效率模型开始着手,构建数学表达式(例如价格,收益)并在较长的时间周期内测试其有效性。该模型通常是真实复杂模型的简化版本,需要验证其长周期的意义和稳定性。通常的趋势跟随,均值回归和套利策略都属于这一类。
另一方面,我们首先寻找价格模式,并尝试在数据挖掘方法中使用算法。导致这些模式的原因并不重要,因为只有确定的模式将来会继续重复。这是一种盲目的分析方法,我们需要严格检查以从随机模式中识别真实模式。"反复试验法","k线图模式"和"特征大量回归"属于这一类。
显然,机器学习很容易适用于数据挖掘方法。让我们看一下如何使用机器学习通过数据挖掘创建交易信号。
代码示例使用基于发明者量化平台的回测工具和自动化交易API接口。在以上部分部署完托管者和安装完Anaconda后, 你只需要安装我们需要的数据科学分析库以及著名的机器学习模型scikit-learn. 关于这部分的内容我们不再敖述.
pip install -U scikit-learn
使用机器学习创建交易策略信号
- 数据挖掘
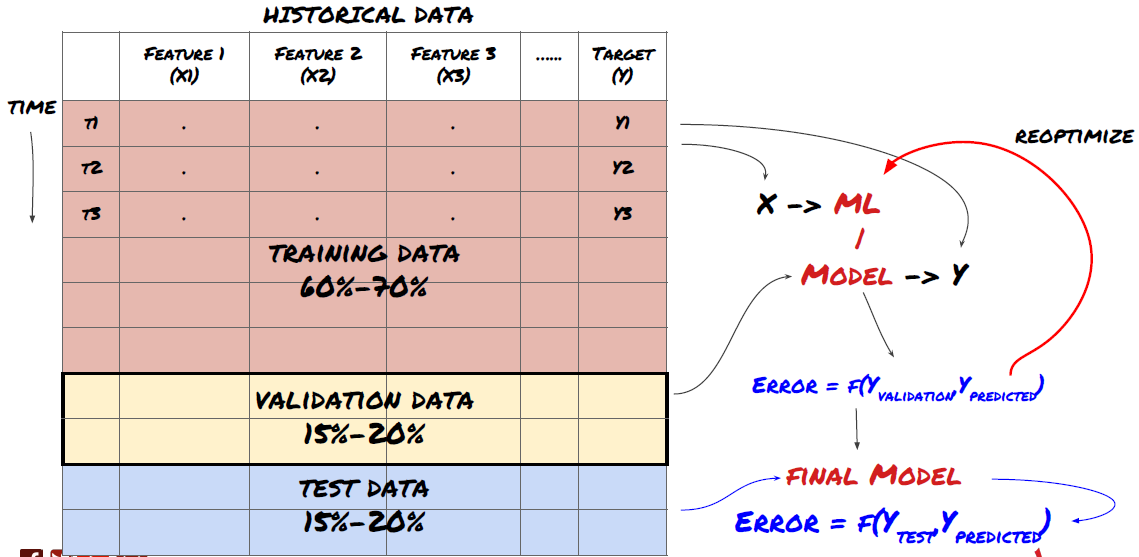
在我们开始之前,一个标准的机器学习问题体系如下图所示:
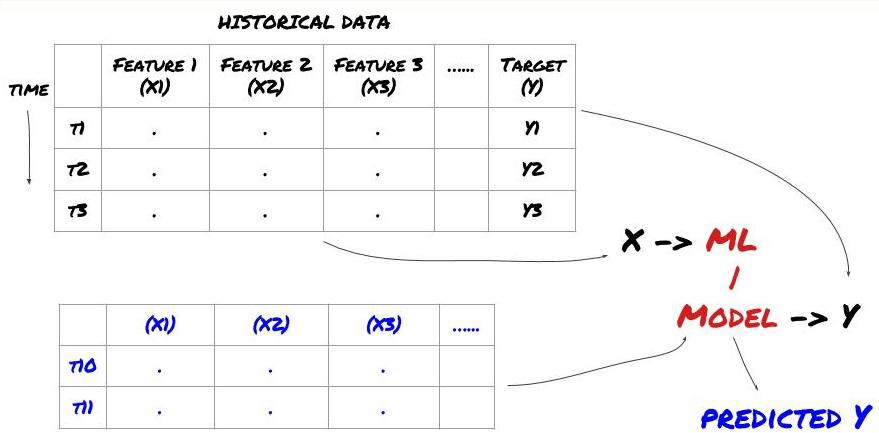
机器学习问题体系
我们将要创建的特征必须具有一些预测能力(X),我们想要预测目标变量(Y),并使用历史数据来训练可以预测Y尽可能接近实际值的ML模型。最后,我们使用此模型对Y未知的新数据进行预测。这指引我们来到了第一步:
第一步: 设置你的问题
- 你想要预测什么?什么是好的预测?你如何评价预测结果?
也就是,在我们上面的框架中,Y是什么?
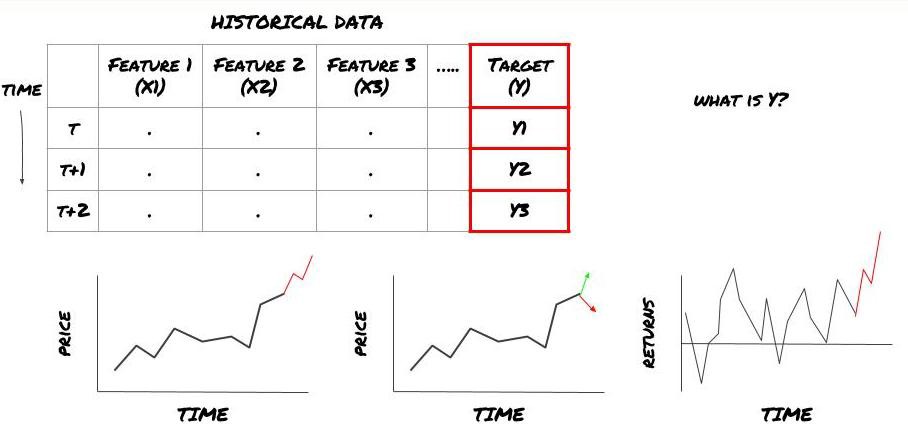
你想要预测什么?
你是否想要预测未来的价格,未来的回报/Pnl,买/卖信号,优化投资组合分配和尝试高效执行交易等?
假设我们试图在下一个时间戳上预测价格。在这种情况下,Y(t)= 价格(t + 1)。现在我们可以用历史数据完成我们的框架
注意Y(t)仅在回测中是已知的,但是当我们使用我们的模型时,我们将不知道时间t的价格(t + 1)。我们使用我们的模型进行预测Y(预测到的,t),并仅在时间t + 1将其与实际值进行比较。这意味着你不能将Y用作预测模型中的特征。
一旦我们知道了目标Y,我们也可以决定如何评估我们的预测。这对于区分我们将尝试数据的不同模型非常重要。根据我们正在解决的问题,选择一个衡量我们模型效率的指标。例如,如果我们预测价格,我们可以使用均方根误差作为指标。一些常用指标(均线,MACD和方差分数等)在发明者量化的工具箱中已经预编码过,你可以在全局通过API接口调用这些指标。
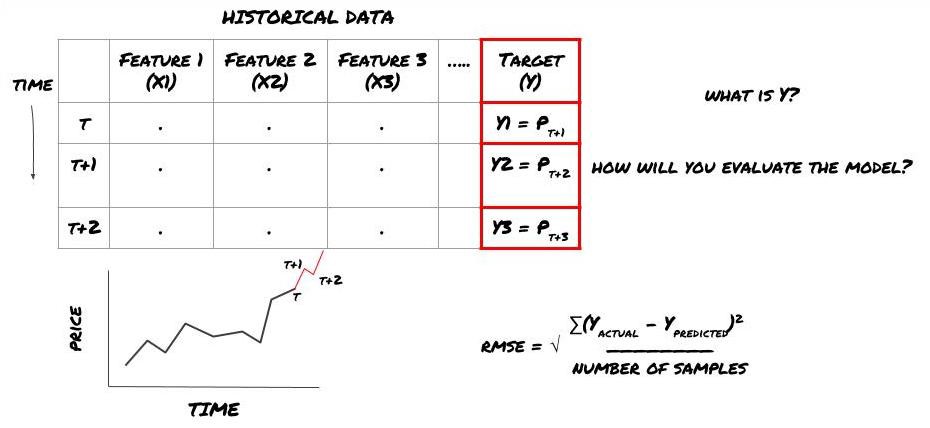
用于预测未来价格的ML框架
为了演示,我们将创建一个预测模型来预测一个假设投资标的的未来预期基准(basis)价值,其中:
basis = Price of Stock — Price of Future
basis(t)=S(t)−F(t)
Y(t) = future expected value of basis = Average(basis(t+1),basis(t+2),basis(t+3),basis(t+4),basis(t+5))
由于这是回归问题,我们将在RMSE(均方根误差)上评估模型。我们还将使用Total Pnl作为评估标准
注意:关于RMSE的相关数学知识,请参考百度百科相关内容
- 我们的目标:创建一个模型,使预测值尽可能接近Y.
第二步:收集可靠数据
收集并清理可帮助你解决手头问题的数据
你需要考虑哪些数据对目标变量Y具有预测能力?如果我们预测价格,你可以使用投资标的价格数据,投资标的交易量数据,相关投资标的的类似数据,投资标的指数水平等整体市场指标,其他相关资产的价格等。
你需要为此数据设置数据访问权限,并确保你的数据准确无误,并解决丢失的数据(非常常见的问题)。同时确保你的数据不偏不倚并充分代表所有市场条件(例如,相同数量的盈亏情景),以避免模型中出现偏差。你可能还需要清理数据以获得股息,投资标的分割,连续等。
如果你使用的是发明者量化平台(FMZ.COM),我们可以访问来自Google,Yahoo,NSE和Quandl的免费全球数据;CTP和易盛等国内商品期货的深度数据;Binance,OKEX,Huobi和BitMex等主流数字货币交易所的数据.发明者量化平台还预先清理和过滤了这些数据,比如投资标的拆分和深度行情数据,并以量化工作者容易理解的格式呈现给策略开发者。
为了方便本文的演示,我们使用以下数据作为虚拟投资标的'MQK',我们还讲用到一个非常方便的量化工具叫做Auquan’s Toolbox, 更多信息,请参阅: https://github.com/Auquan/auquan-toolbox-python
# Load the data
from backtester.dataSource.quant_quest_data_source import QuantQuestDataSource
cachedFolderName = '/Users/chandinijain/Auquan/qq2solver-data/historicalData/'
dataSetId = 'trainingData1'
instrumentIds = ['MQK']
ds = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
def loadData(ds):
data = None
for key in ds.getBookDataByFeature().keys():
if data is None:
data = pd.DataFrame(np.nan, index = ds.getBookDataByFeature()[key].index, columns=[])
data[key] = ds.getBookDataByFeature()[key]
data['Stock Price'] = ds.getBookDataByFeature()['stockTopBidPrice'] + ds.getBookDataByFeature()['stockTopAskPrice'] / 2.0
data['Future Price'] = ds.getBookDataByFeature()['futureTopBidPrice'] + ds.getBookDataByFeature()['futureTopAskPrice'] / 2.0
data['Y(Target)'] = ds.getBookDataByFeature()['basis'].shift(-5)
del data['benchmark_score']
del data['FairValue']
return data
data = loadData(ds)
通过以上代码,Auquan’s Toolbox已经下载并将数据加载到数据帧字典中。我们现在需要以我们喜欢的格式准备数据。函数ds.getBookDataByFeature()返回数据帧的字典,每个特征一个数据帧。我们为具有所有特征的股票创建新的数据帧。
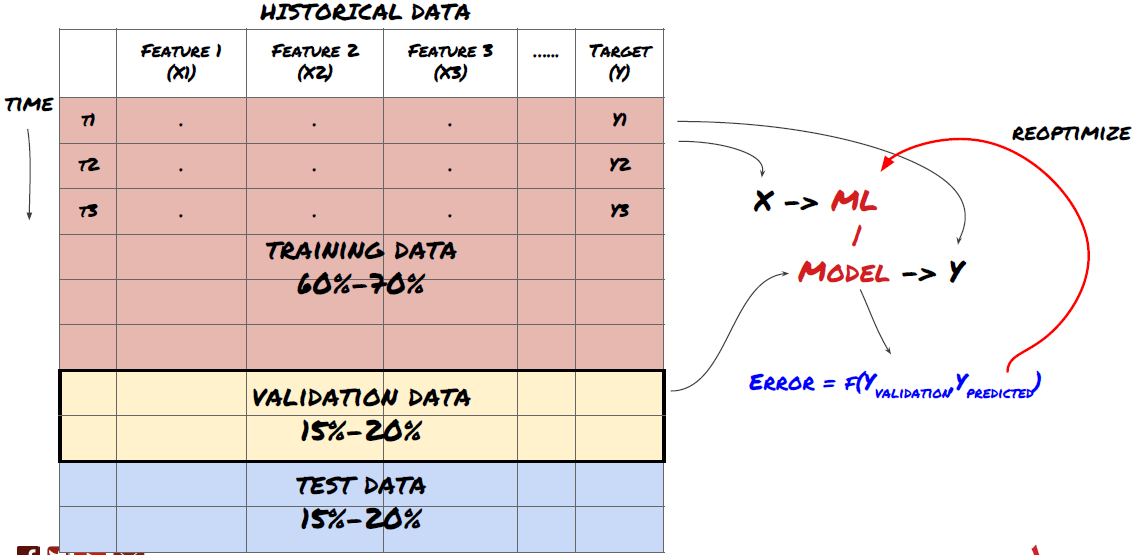
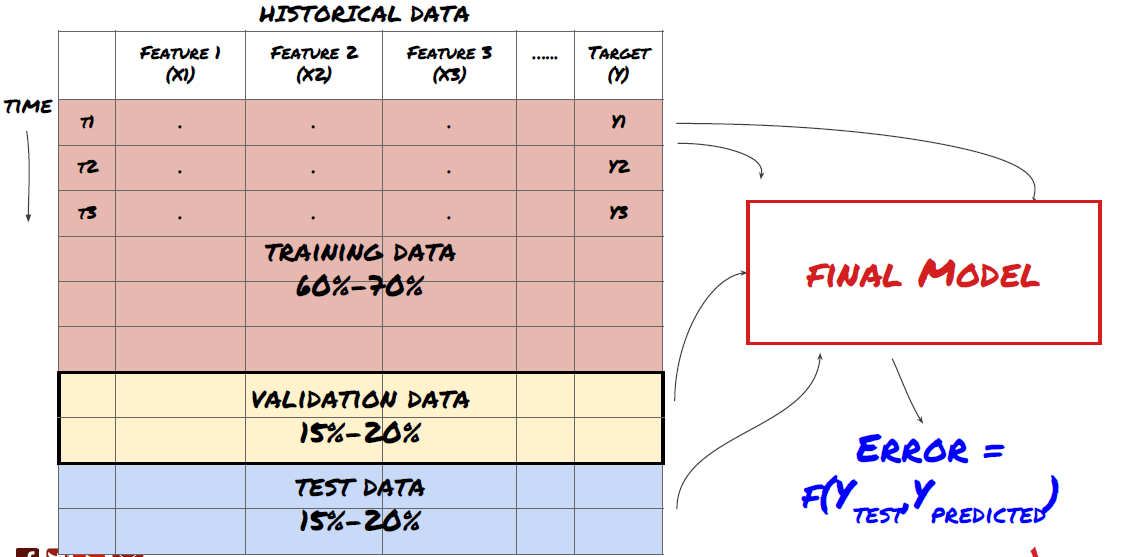
第三步:拆分数据
- 从数据创建训练集,交叉验证和测试这些数据集
这是非常重要的一步! 在我们继续进行之前,我们应该将数据分成训练数据集,以训练你的模型;测试数据集以用来评估模型性能。建议拆分为:60-70%的训练集和30-40%的测试集
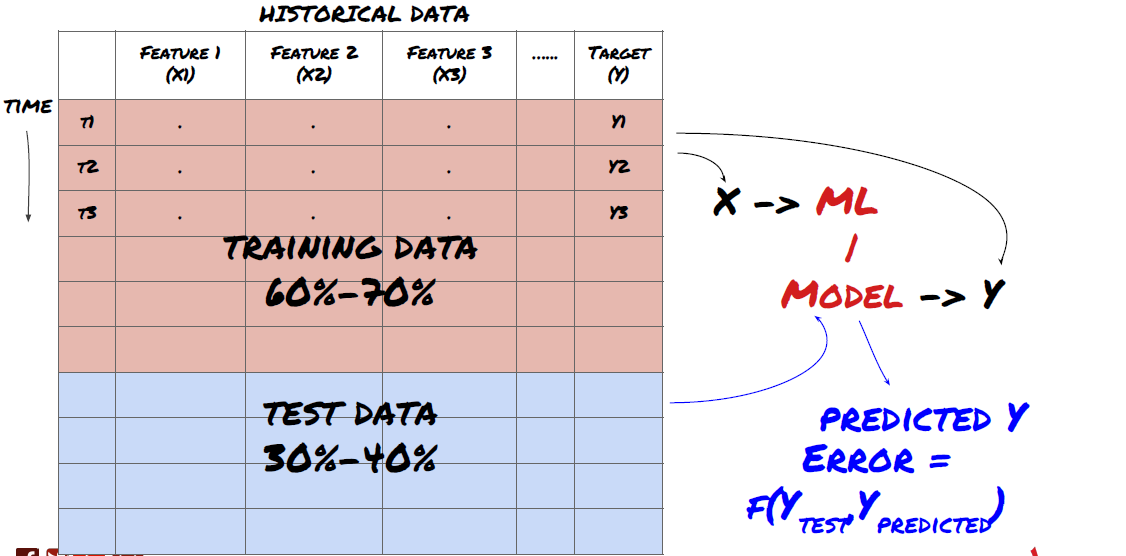
将数据拆分为训练集和测试集
由于训练数据用于评估模型参数,因此你的模型可能会过度拟合这些训练的数据,并且训练数据会误导模型性能。如果你没有保留任何单独的测试数据并使用所有数据进行训练,你将不知道你的模型对新的看不见的数据执行得有多好或多坏。这是训练有素的ML模型在实时数据上失败的主要原因之一:人们训练所有可用数据并因训练数据指标而兴奋,但该模型无法对未经过训练的实时数据做出任何有意义的预测。
将数据拆分为训练集,验证集和测试集
这种方法存在问题。如果我们反复训练训练数据,评估测试数据的性能并优化我们的模型,直到我们对性能感到满意为止,我们隐含地将测试数据作为训练数据的一部分。最终,我们的模型可能对这组训练和测试数据表现良好,但无法保证它能够很好地预测新数据。
为了解决这个问题,我们可以创建一个单独的验证数据集。现在,你可以训练数据,评估验证数据的性能,优化直到你对性能满意,最后测试测试数据。这样,测试数据不会受到污染,我们不会使用测试数据中的任何信息来改进我们的模型。
请记住,一旦检查了测试数据的性能,就不要再回过头来尝试进一步优化模型。如果你发现你的模型没有给出好的结果,则完全丢弃该模型并重新开始。建议拆分可以是60%的训练数据,20%的验证数据和20%的测试数据。
对于我们的问题,我们有三个可用的数据集,我们将使用一个作为训练集,第二个作为验证集,第三个作为我们的测试集。
# Training Data
dataSetId = 'trainingData1'
ds_training = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
training_data = loadData(ds_training)
# Validation Data
dataSetId = 'trainingData2'
ds_validation = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
validation_data = loadData(ds_validation)
# Test Data
dataSetId = 'trainingData3'
ds_test = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
out_of_sample_test_data = loadData(ds_test)
对于这些中的每一个,我们添加目标变量Y,定义为接下来五个basis值的平均值
def prepareData(data, period):
data['Y(Target)'] = data['basis'].rolling(period).mean().shift(-period)
if 'FairValue' in data.columns:
del data['FairValue']
data.dropna(inplace=True)
period = 5
prepareData(training_data, period)
prepareData(validation_data, period)
prepareData(out_of_sample_test_data, period)
第四步:特征工程
分析数据的行为并创建具有预测能力的特征
现在开始真正的工程构建了。特征选择的黄金法则是预测能力主要来自特征,而不是来自模型。 你会发现,特征的选择对性能的影响远远大于模型的选择。特征选择的一些注意事项:
-
在还没有探索与目标变量的关系的情况下,不要随意选择一大组特征
-
与目标变量很少或没有关系可能会导致过度拟合
-
你选择的特征可能彼此高度相关,在这种情况下,较少数量的特征也可以解释目标
-
我通常会创建一些具有直观意义的特征,查看目标变量与这些特征的相关性,以及它们之间的相关性以决定使用哪些
-
你还可以尝试根据最大信息系数(MIC),执行主成分分析(PCA)和其他方法对候选特征进行排序
特征转换/规范化:
ML模型往往在标准化方面表现良好。但是,在处理时间序列数据时,规范化很棘手,因为未来的数据范围是未知的。你的数据可能超出标准化范围,导致模型错误。但是你仍然可以尝试强制某种程度的平稳性:
-
缩放:按标准差或四分位数范围划分特征
-
居中:从当前值中减去历史平均值
-
归一化:上述(x - mean)/ stdev的两个回溯期
-
常规归一化:在回溯期(x-min)/(max-min)内将数据标准化为-1到+1的范围并重新确定中心
注意,由于我们使用历史连续平均值,标准偏差,最大值或最小值超过回溯期,因此特征的归一标准化值将表示在不同时间的不同实际值。例如,如果特征的当前值为5,连续30周期平均值为4.5,则在居中后将转换为0.5。之后,如果连续30周期均值变为3,则值3.5将变为0.5。这可能是模型错误的原因. 因此,规范化是棘手的,你必须弄清楚实际上是什么改善了模型的性能(如果有的话)。
对于我们问题中的第一次迭代,我们使用混合参数创建了大量特征。稍后我们将尝试查看是否可以减少特征的数量
def difference(dataDf, period):
return dataDf.sub(dataDf.shift(period), fill_value=0)
def ewm(dataDf, halflife):
return dataDf.ewm(halflife=halflife, ignore_na=False,
min_periods=0, adjust=True).mean()
def rsi(data, period):
data_upside = data.sub(data.shift(1), fill_value=0)
data_downside = data_upside.copy()
data_downside[data_upside > 0] = 0
data_upside[data_upside < 0] = 0
avg_upside = data_upside.rolling(period).mean()
avg_downside = - data_downside.rolling(period).mean()
rsi = 100 - (100 * avg_downside / (avg_downside + avg_upside))
rsi[avg_downside == 0] = 100
rsi[(avg_downside == 0) & (avg_upside == 0)] = 0
return rsi
def create_features(data):
basis_X = pd.DataFrame(index = data.index, columns = [])
basis_X['mom3'] = difference(data['basis'],4)
basis_X['mom5'] = difference(data['basis'],6)
basis_X['mom10'] = difference(data['basis'],11)
basis_X['rsi15'] = rsi(data['basis'],15)
basis_X['rsi10'] = rsi(data['basis'],10)
basis_X['emabasis3'] = ewm(data['basis'],3)
basis_X['emabasis5'] = ewm(data['basis'],5)
basis_X['emabasis7'] = ewm(data['basis'],7)
basis_X['emabasis10'] = ewm(data['basis'],10)
basis_X['basis'] = data['basis']
basis_X['vwapbasis'] = data['stockVWAP']-data['futureVWAP']
basis_X['swidth'] = data['stockTopAskPrice'] -
data['stockTopBidPrice']
basis_X['fwidth'] = data['futureTopAskPrice'] -
data['futureTopBidPrice']
basis_X['btopask'] = data['stockTopAskPrice'] -
data['futureTopAskPrice']
basis_X['btopbid'] = data['stockTopBidPrice'] -
data['futureTopBidPrice']
basis_X['totalaskvol'] = data['stockTotalAskVol'] -
data['futureTotalAskVol']
basis_X['totalbidvol'] = data['stockTotalBidVol'] -
data['futureTotalBidVol']
basis_X['emabasisdi7'] = basis_X['emabasis7'] -
basis_X['emabasis5'] +
basis_X['emabasis3']
basis_X = basis_X.fillna(0)
basis_y = data['Y(Target)']
basis_y.dropna(inplace=True)
print("Any null data in y: %s, X: %s"
%(basis_y.isnull().values.any(),
basis_X.isnull().values.any()))
print("Length y: %s, X: %s"
%(len(basis_y.index), len(basis_X.index)))
return basis_X, basis_y
basis_X_train, basis_y_train = create_features(training_data)
basis_X_test, basis_y_test = create_features(validation_data)
第五步:模型选择
根据所选问题选择合适的统计/ML模型
模型的选择取决于问题的构成方式。你是在解决监督(特征矩阵中的每个点X映射到目标变量Y)还是无监督学习问题(没有给定映射,模型试图学习未知模式)? 你是在解决回归(预测未来时间的实际价格)还是分类问题(仅预测未来时间的价格方向(增加/减少))。

监督 or 无监督学习

回归 or 分类
一些常见的监督学习算法可以帮助你入门:
-
线性回归(参数,回归)
-
Logistic回归(参数,分类)
-
K近邻(KNN)算法(基于实例,回归)
-
SVM,SVR(参数,分类和回归)
-
决策树
-
决策森林
我建议从一个简单的模型开始,例如线性或逻辑回归,并根据需要从那里构建更复杂的模型。还建议你阅读模型背后的数学,而不是盲目地将其用作黑盒子。
第六步:训练,验证和优化(重复步骤4-6)
使用训练和验证数据集训练和优化你的模型
现在,你已准备好最终构建模型了。在这个阶段,你真的只是迭代模型和模型参数。在训练数据上训练你的模型,测量其在验证数据上的性能,然后再返回,优化,重新训练和评估。如果你对模型的性能不满意,请尝试使用其他模型。你多次循环这个阶段,直到你终于拥有一个你满意的模型。
只有当你拥有自己喜欢的模型后,然后继续执行下一步。
对于我们的演示问题,让我们从简单的线性回归开始
from sklearn import linear_model
from sklearn.metrics import mean_squared_error, r2_score
def linear_regression(basis_X_train, basis_y_train,
basis_X_test,basis_y_test):
regr = linear_model.LinearRegression()
# Train the model using the training sets
regr.fit(basis_X_train, basis_y_train)
# Make predictions using the testing set
basis_y_pred = regr.predict(basis_X_test)
# The coefficients
print('Coefficients: \n', regr.coef_)
# The mean squared error
print("Mean squared error: %.2f"
% mean_squared_error(basis_y_test, basis_y_pred))
# Explained variance score: 1 is perfect prediction
print('Variance score: %.2f' % r2_score(basis_y_test,
basis_y_pred))
# Plot outputs
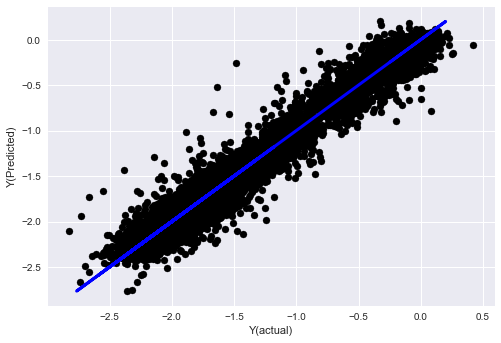
plt.scatter(basis_y_pred, basis_y_test, color='black')
plt.plot(basis_y_test, basis_y_test, color='blue', linewidth=3)
plt.xlabel('Y(actual)')
plt.ylabel('Y(Predicted)')
plt.show()
return regr, basis_y_pred
_, basis_y_pred = linear_regression(basis_X_train, basis_y_train,
basis_X_test,basis_y_test)
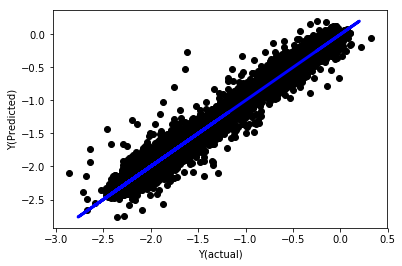
没有归一化的线性回归
('Coefficients: \n', array([ -1.0929e+08, 4.1621e+07, 1.4755e+07, 5.6988e+06, -5.656e+01, -6.18e-04, -8.2541e-05,4.3606e-02, -3.0647e-02, 1.8826e+07, 8.3561e-02, 3.723e-03, -6.2637e-03, 1.8826e+07, 1.8826e+07, 6.4277e-02, 5.7254e-02, 3.3435e-03, 1.6376e-02, -7.3588e-03, -8.1531e-04, -3.9095e-02, 3.1418e-02, 3.3321e-03, -1.3262e-06, -1.3433e+07, 3.5821e+07, 2.6764e+07, -8.0394e+06, -2.2388e+06, -1.7096e+07]))
Mean squared error: 0.02
Variance score: 0.96
看模型系数。我们不能真正地比较它们或者说哪些是重要的,因为它们都属于不同的规模。让我们尝试归一化以使它们符合相同的比例并且还强制执行一些平稳性。
def normalize(basis_X, basis_y, period):
basis_X_norm = (basis_X - basis_X.rolling(period).mean())/
basis_X.rolling(period).std()
basis_X_norm.dropna(inplace=True)
basis_y_norm = (basis_y -
basis_X['basis'].rolling(period).mean())/
basis_X['basis'].rolling(period).std()
basis_y_norm = basis_y_norm[basis_X_norm.index]
return basis_X_norm, basis_y_norm
norm_period = 375
basis_X_norm_test, basis_y_norm_test = normalize(basis_X_test,basis_y_test, norm_period)
basis_X_norm_train, basis_y_norm_train = normalize(basis_X_train, basis_y_train, norm_period)
regr_norm, basis_y_pred = linear_regression(basis_X_norm_train, basis_y_norm_train, basis_X_norm_test, basis_y_norm_test)
basis_y_pred = basis_y_pred * basis_X_test['basis'].rolling(period).std()[basis_y_norm_test.index] + basis_X_test['basis'].rolling(period).mean()[basis_y_norm_test.index]
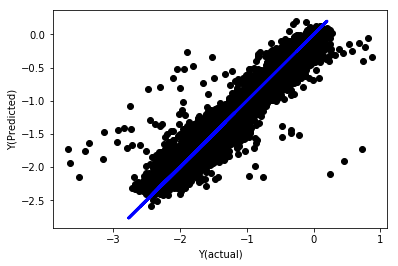
归一化的线性回归
Mean squared error: 0.05
Variance score: 0.90
该模型并没有改进以前的模型,但也没有更糟糕。现在我们可以实际比较系数,看看哪些系数实际上很重要。
我们来看看系数
for i in range(len(basis_X_train.columns)):
print('%.4f, %s'%(regr_norm.coef_[i], basis_X_train.columns[i]))
结果为:
19.8727, emabasis4
-9.2015, emabasis5
8.8981, emabasis7
-5.5692, emabasis10
-0.0036, rsi15
-0.0146, rsi10
0.0196, mom10
-0.0035, mom5
-7.9138, basis
0.0062, swidth
0.0117, fwidth
2.0883, btopask
2.0311, btopbid
0.0974, bavgask
0.0611, bavgbid
0.0007, topaskvolratio
0.0113, topbidvolratio
-0.0220, totalaskvolratio
0.0231, totalbidvolratio
我们可以清楚地看到,某些特征与其他特征相比具有更高的系数,并且可能具有更强的预测能力。
让我们看看不同特征之间的相关性。
import seaborn
c = basis_X_train.corr()
plt.figure(figsize=(10,10))
seaborn.heatmap(c, cmap='RdYlGn_r', mask = (np.abs(c) <= 0.8))
plt.show()
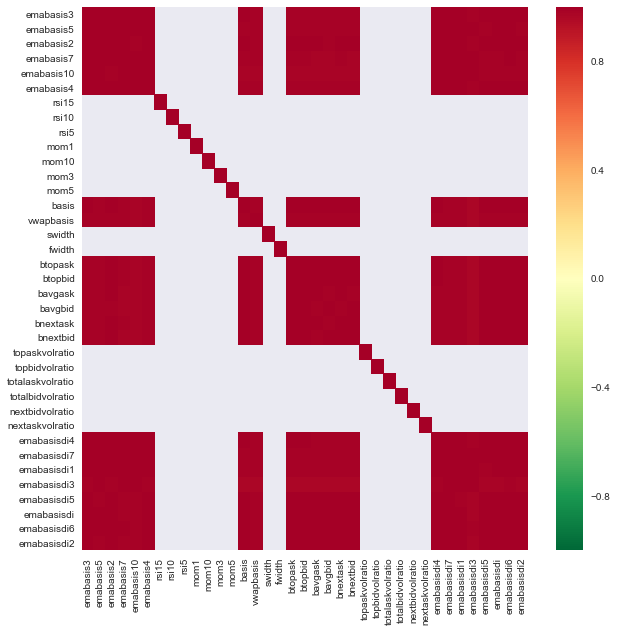
特征之间的相关性
暗红色区域表示高度相关的变量。让我们再次创建/修改一些特征,并尝试改进我们的模型。
例如,我可以轻松地丢弃像emabasisdi7这样的特征,这些特征只是其他特征的线性组合.
def create_features_again(data):
basis_X = pd.DataFrame(index = data.index, columns = [])
basis_X['mom10'] = difference(data['basis'],11)
basis_X['emabasis2'] = ewm(data['basis'],2)
basis_X['emabasis5'] = ewm(data['basis'],5)
basis_X['emabasis10'] = ewm(data['basis'],10)
basis_X['basis'] = data['basis']
basis_X['totalaskvolratio'] = (data['stockTotalAskVol']
- data['futureTotalAskVol'])/
100000
basis_X['totalbidvolratio'] = (data['stockTotalBidVol']
- data['futureTotalBidVol'])/
100000
basis_X = basis_X.fillna(0)
basis_y = data['Y(Target)']
basis_y.dropna(inplace=True)
return basis_X, basis_y
basis_X_test, basis_y_test = create_features_again(validation_data)
basis_X_train, basis_y_train = create_features_again(training_data)
_, basis_y_pred = linear_regression(basis_X_train, basis_y_train, basis_X_test,basis_y_test)
basis_y_regr = basis_y_pred.copy()
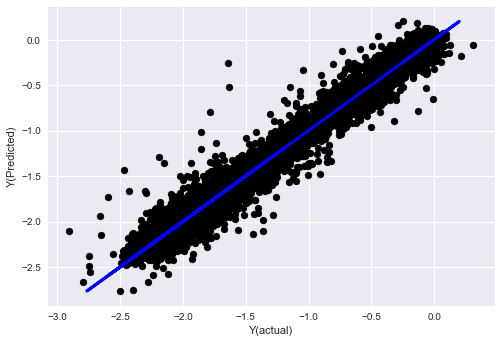
('Coefficients: ', array([ 0.03246139,
0.49780982, -0.22367172, 0.20275786, 0.50758852,
-0.21510795, 0.17153884]))
Mean squared error: 0.02
Variance score: 0.96
看,我们的模型性能没有变化,我们只需要一些特征来解释我们的目标变量。我建议你尝试更多上面的特征,尝试新的组合等,看看有什么可以改善我们的模型。
我们还可以尝试更复杂的模型,看看模型的变化是否可以提高性能.
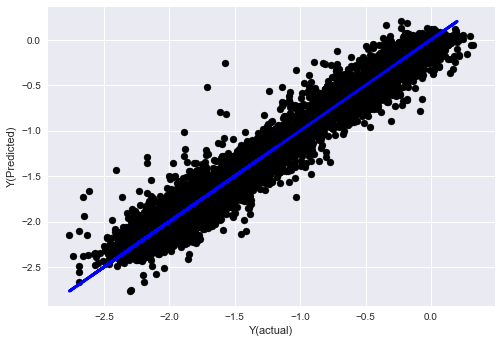
- K近邻(KNN)算法
from sklearn import neighbors
n_neighbors = 5
model = neighbors.KNeighborsRegressor(n_neighbors, weights='distance')
model.fit(basis_X_train, basis_y_train)
basis_y_pred = model.predict(basis_X_test)
basis_y_knn = basis_y_pred.copy()
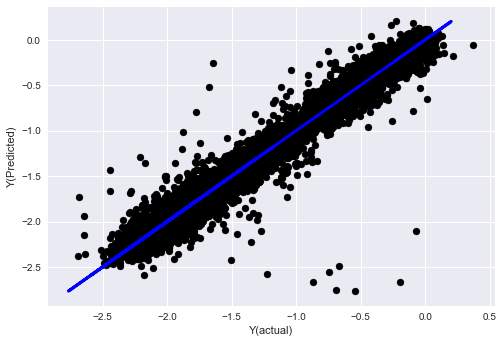
- SVR
from sklearn.svm import SVR
model = SVR(kernel='rbf', C=1e3, gamma=0.1)
model.fit(basis_X_train, basis_y_train)
basis_y_pred = model.predict(basis_X_test)
basis_y_svr = basis_y_pred.copy()
- 决策树
model=ensemble.ExtraTreesRegressor()
model.fit(basis_X_train, basis_y_train)
basis_y_pred = model.predict(basis_X_test)
basis_y_trees = basis_y_pred.copy()
第七步:对测试数据进行回测
检查实际样本数据的性能
在(尚未触及)测试数据集上的回测性能
这是关键时刻。我们从测试数据的最后一步开始运行我们最终的优化模型,我们在开始时就把它放在了一边,目前为止还未接触到的数据。
这为你提供了实际的期望,即当你开始实时交易时,你的模型将如何对新的和未看到的数据执行。因此,有必要确保你拥有一个未用于训练或验证模型的干净数据集。
如果你不喜欢测试数据的回测结果,请丢弃模型并重新开始。千万不要回去重新优化你的模型,这将导致过度拟合!(还建议创建一个新的测试数据集,因为这个数据集现在已被污染;在丢弃模型时,我们已经隐含地知道了有关数据集的内容)。
这里我们还是会用到Auquan’s Toolbox
import backtester
from backtester.features.feature import Feature
from backtester.trading_system import TradingSystem
from backtester.sample_scripts.fair_value_params import FairValueTradingParams
class Problem1Solver():
def getTrainingDataSet(self):
return "trainingData1"
def getSymbolsToTrade(self):
return ['MQK']
def getCustomFeatures(self):
return {'my_custom_feature': MyCustomFeature}
def getFeatureConfigDicts(self):
expma5dic = {'featureKey': 'emabasis5',
'featureId': 'exponential_moving_average',
'params': {'period': 5,
'featureName': 'basis'}}
expma10dic = {'featureKey': 'emabasis10',
'featureId': 'exponential_moving_average',
'params': {'period': 10,
'featureName': 'basis'}}
expma2dic = {'featureKey': 'emabasis3',
'featureId': 'exponential_moving_average',
'params': {'period': 3,
'featureName': 'basis'}}
mom10dic = {'featureKey': 'mom10',
'featureId': 'difference',
'params': {'period': 11,
'featureName': 'basis'}}
return [expma5dic,expma2dic,expma10dic,mom10dic]
def getFairValue(self, updateNum, time, instrumentManager):
# holder for all the instrument features
lbInstF = instrumentManager.getlookbackInstrumentFeatures()
mom10 = lbInstF.getFeatureDf('mom10').iloc[-1]
emabasis2 = lbInstF.getFeatureDf('emabasis2').iloc[-1]
emabasis5 = lbInstF.getFeatureDf('emabasis5').iloc[-1]
emabasis10 = lbInstF.getFeatureDf('emabasis10').iloc[-1]
basis = lbInstF.getFeatureDf('basis').iloc[-1]
totalaskvol = lbInstF.getFeatureDf('stockTotalAskVol').iloc[-1] - lbInstF.getFeatureDf('futureTotalAskVol').iloc[-1]
totalbidvol = lbInstF.getFeatureDf('stockTotalBidVol').iloc[-1] - lbInstF.getFeatureDf('futureTotalBidVol').iloc[-1]
coeff = [ 0.03249183, 0.49675487, -0.22289464, 0.2025182, 0.5080227, -0.21557005, 0.17128488]
newdf['MQK'] = coeff[0] * mom10['MQK'] + coeff[1] * emabasis2['MQK'] +\
coeff[2] * emabasis5['MQK'] + coeff[3] * emabasis10['MQK'] +\
coeff[4] * basis['MQK'] + coeff[5] * totalaskvol['MQK']+\
coeff[6] * totalbidvol['MQK']
newdf.fillna(emabasis5,inplace=True)
return newdf
problem1Solver = Problem1Solver()
tsParams = FairValueTradingParams(problem1Solver)
tradingSystem = TradingSystem(tsParams)
tradingSystem.startTrading(onlyAnalyze=False,
shouldPlot=True,
makeInstrumentCsvs=False)
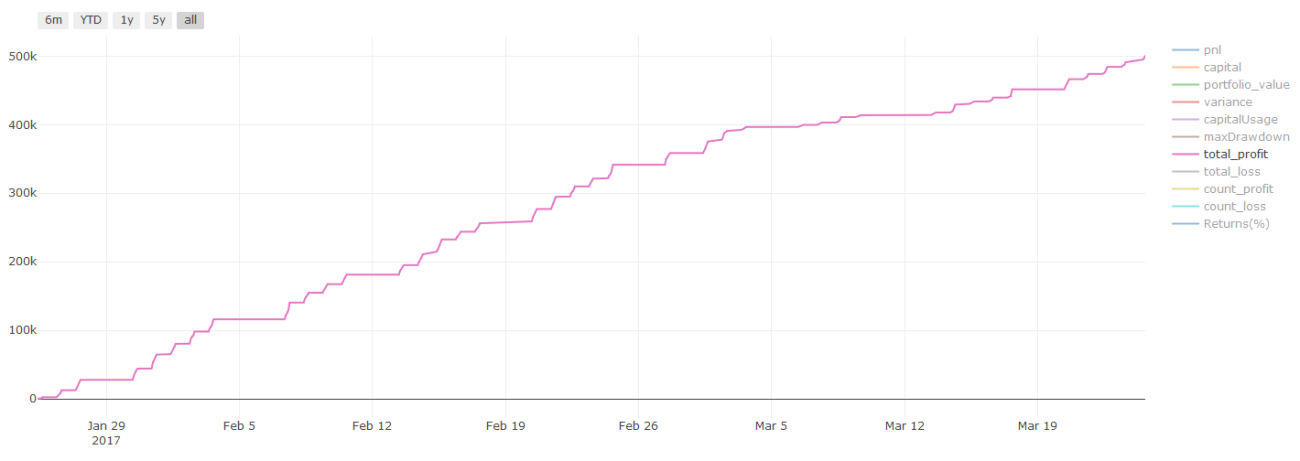
回测结果,Pnl以美元计算(Pnl不计入交易成本和其他费用)
第八步:改进模型的其他方法
滚动验证,集合学习,Bagging和Boosting
除了收集更多数据,创建更好的特征或尝试更多模型之外,这还有几点你可以尝试改进。
1. 滚动验证
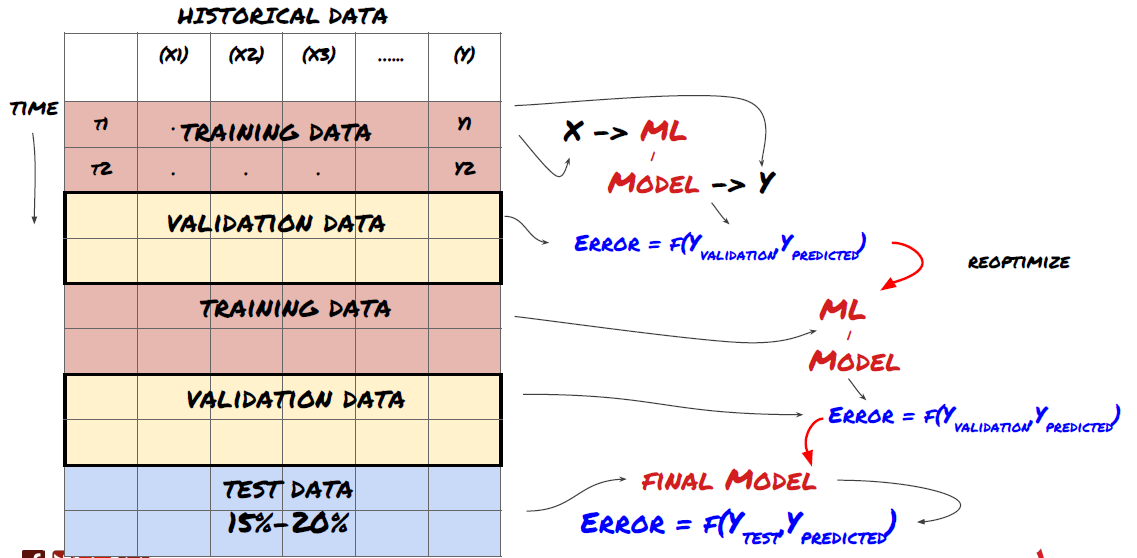
滚动验证
市场条件很少保持不变。假设你有一年的数据,并且你使用1月至8月的数据进行训练,并且使用9月至12月的数据来测试你的模型,你最终可能会针对一组非常具体的市场条件进行训练。也许上半年没有市场波动,一些极端消息导致市场在9月份大幅上涨,你的模型就无法学习这种模式,而且会给你带来垃圾的预测结果。
尝试前进滚动验证可能会更好,1月至2月的训练,3月的验证,4月至5月的重新训练,6月的验证等等。
2. 集合学习
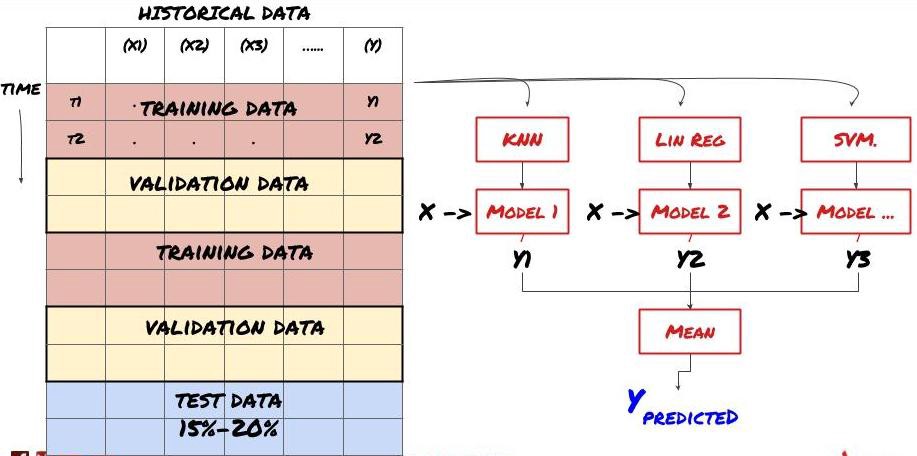
集合学习
某些模型在预测某些情景时可能效果很好,而在预测其他情景或者在某种情况下模型可能极度过度拟合。减少误差和过度拟合的一种方法是使用不同模型的集合。你的预测将会是是许多模型所做预测的平均值,不同模型的误差可能会被抵消或减少。一些常见的集合方法是Bagging和Boosting。
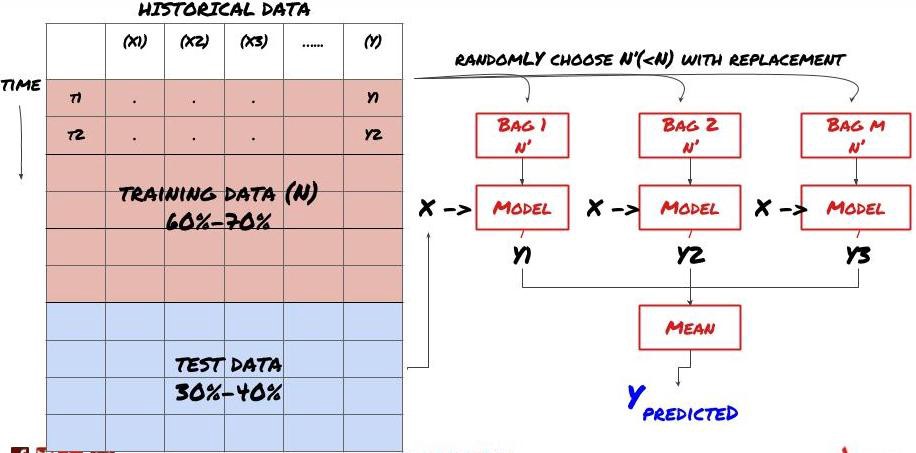
Bagging
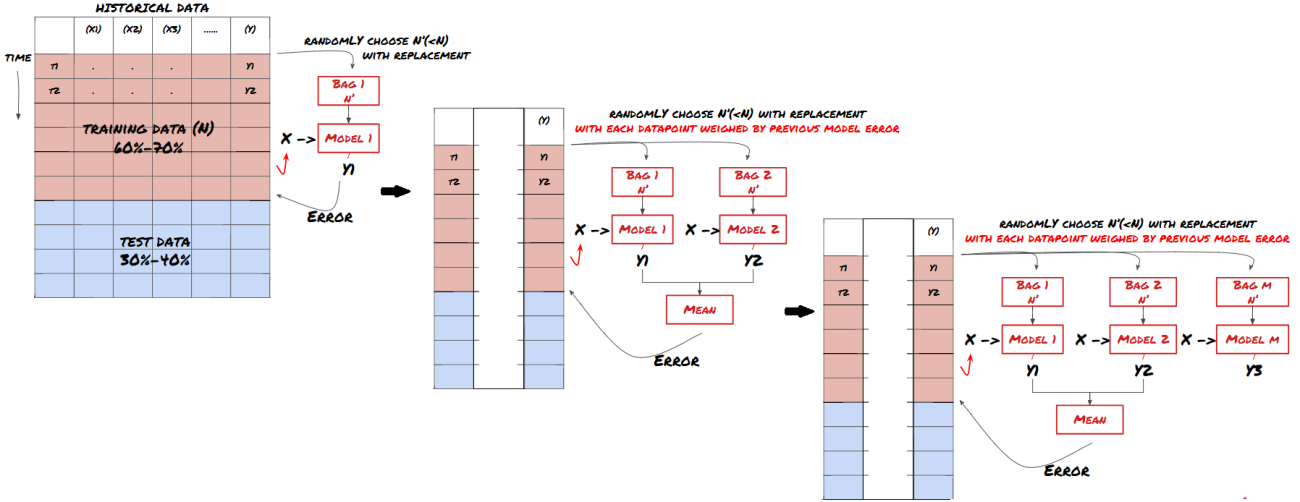
Boosting
为了简短起见,我将跳过这些方法,但你可以在网上寻找更多相关信息。
让我们为我们的问题尝试一个集合方法
basis_y_pred_ensemble = (basis_y_trees + basis_y_svr +
basis_y_knn + basis_y_regr)/4
Mean squared error: 0.02
Variance score: 0.95
到目前为止,我们已经积累了很多知识和信息.让我们快速回顾一下:
-
解决你的问题
-
收集可靠的数据和清理数据
-
将数据拆分为训练,验证和测试集
-
创建特征并分析其行为
-
根据行为选择合适的训练模型
-
使用训练数据训练你的模型并进行预测
-
检查验证集上的性能并重新优化
-
验证测试集的最终性能
很上头是不是?但还没完,你现在只有一个可靠的预测模型。还记得我们的策略中我们真正想要的吗? 所以你还不需要:
-
开发基于预测模型的信号以识别交易方向
-
开发识别开平仓的具体策略
-
执行系统以识别仓位和价格
以上这些就要用到发明者量化平台了(FMZ.COM),在发明者量化平台,有高度封装和完善的API接口,以及可以全局调用的下单与交易函数,不用你在逐个对接与添加不同交易所的API接口,在发明者量化平台的策略广场,有很多成熟完善的备选策略,配合这篇文章的机器学习方法,会让你的具体策略如虎添翼.策略广场位于: https://www.fmz.com/square
关于交易成本的重要说明:你的模型会告诉你所选资产何时是做多或做空。然而,它没有考虑费用/交易成本/可用交易量/止损等。交易成本通常会使有利可图的交易成为亏损。例如,预期价格上涨0.05美元的资产是买入,但如果你必须支付0.10美元进行此交易,你将最终获得净亏损$0.05。在你考虑经纪人佣金,交换费和点差后,我们上面看起来很棒的盈利图实际上是这样的:
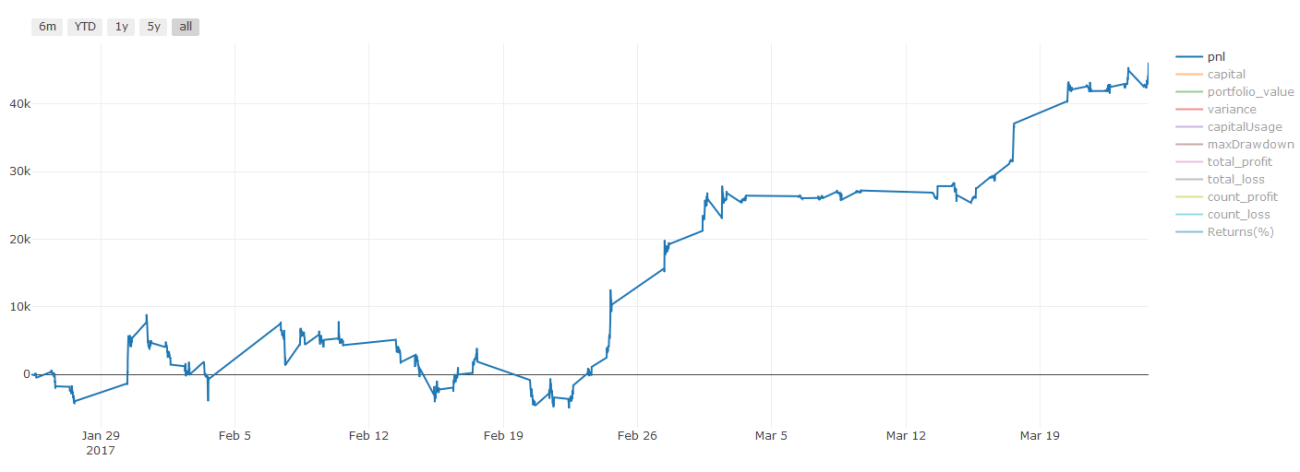
交易费和点差后的回测结果,Pnl为美元
交易费和差价占我们Pnl的90%以上!我们将在后续文章中详细讨论这些内容。
最后,我们来看看一些常见的陷阱。
该做什么和不该做什么
-
以所有力量避免过度拟合!
-
不要在每个数据点后重新训练:这是人们在机器学习开发中犯的常见错误。如果你的模型需要在每个数据点之后重新训练,那么它可能不是一个非常好的模型。也就是说,它需要定期重新训练,只需要以合理的频率进行训练(例如,如果进行日内预测,则在每周结束时重新训练)
-
避免偏差,尤其是前瞻性偏差:这是模型不起作用的另一个原因,确保你未使用未来的任何信息。大多数情况下,这意味着,不要使用目标变量Y作为模型中的特征。在回溯测试期间,你可以使用它,但在实际运行模型时将无法使用,这将使你的模型无法使用。
-
警惕数据挖掘偏差:由于我们正在尝试对我们的数据进行一系列建模以确定是否适合,如果没有其特殊的原因,请确保你运行严格的测试以将随机模式与可能发生的实际模式分开。例如,线性回归很好地解释了向上趋势模式,单很可能会成为较大随机游走的一小部分!
避免过度拟合
这非常重要,我觉得有必要再提一次。
-
过度拟合是交易策略中最危险的陷阱
-
一个复杂的算法可能在回测中表现非常出色,但在新的看不见的数据上却惨遭失败,这个算法并没有真正揭示数据的任何趋势,也没有真正的预测能力。它非常适合它所见的数据
-
让你的系统尽可能简单。如果你发现自己需要大量复杂功能来解释数据,那么你可能会过度拟合
-
将你的可用数据划分为训练和测试数据,并始终在使用模型进行实时交易之前验证真实的样本数据的性能。



- 1