৭টি সাধারণভাবে ব্যবহৃত বাছাই অ্যালগরিদমের দৃশ্যত স্বজ্ঞাত অভিজ্ঞতা (সাধারণত লেখার কৌশলের জন্য ব্যবহৃত)
 2
2056
2
2056
ভিজ্যুয়াল ইন্সটিটিউশনঃ ৭টি সাধারণ সাজানোর অ্যালগরিদম
যখন আমরা কৌশল লিখতে থাকি, তখন আমাদের প্রোগ্রামের কোডের মধ্যে এমন পরিস্থিতির সম্মুখীন হতে হয় যেখানে আমাদের ডেটা বাছাই করতে হবে, তাই কিভাবে আমরা কমপক্ষে সিস্টেম খরচ (সময়, সিস্টেম রিসোর্স) দিয়ে একটি বৈজ্ঞানিক প্রোগ্রাম ডিজাইন করতে পারি?
- ### ১. দ্রুত সাজান
গল্পের শুরুঃ
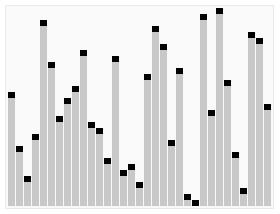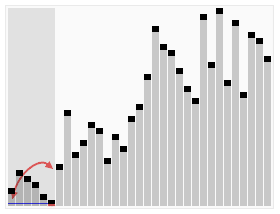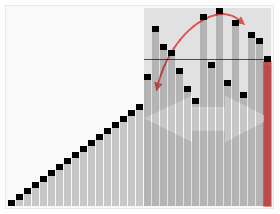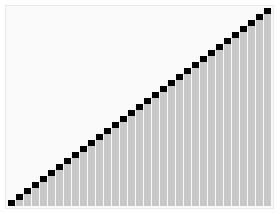
দ্রুত বাছাই হল একটি বাছাই পদ্ধতি যা টনি হল দ্বারা বিকাশ করা হয়েছে। গড় পরিস্থিতিতে, n টি প্রজেক্টের বাছাই করার জন্য Ο (n log n) বার তুলনা করা প্রয়োজন। সবচেয়ে খারাপ পরিস্থিতিতে, এটির জন্য Ο (n log n) বার তুলনা করা প্রয়োজন, তবে এটি অস্বাভাবিক। প্রকৃতপক্ষে, দ্রুত বাছাই সাধারণত অন্যান্য Ο (n log n) অ্যালগরিদমের তুলনায় উল্লেখযোগ্যভাবে দ্রুত হয়, কারণ এর অভ্যন্তরীণ চক্রটি (inner loop) বেশিরভাগ আর্কিটেকচারে কার্যকরভাবে কার্যকর করা যায় এবং বেশিরভাগ বাস্তব-বিশ্বের ডেটাতে, নকশার পছন্দগুলি নির্ধারণ করা যায়, যা প্রয়োজনীয় সময় দ্বিপাক্ষিক সম্ভাবনা হ্রাস করে।
পদক্ষেপঃ
একটি অ্যারে থেকে একটি উপাদান বেছে নিন, যাকে বলা হয় বেঞ্চমার্ক পয়েন্ট (পিভট) ।
পুনরায় সাজানো অ্যারে, সমস্ত উপাদান যা বেঞ্চমার্কের চেয়ে ছোট, বেঞ্চমার্কের সামনে রাখা হয়, এবং সমস্ত উপাদান যা বেঞ্চমার্কের চেয়ে বড়, বেঞ্চমার্কের পিছনে রাখা হয়। একই সংখ্যা যে কোনও দিকে যেতে পারে। এই বিভাজনটি প্রস্থান করার পরে, বেঞ্চমার্কটি অ্যারের মাঝখানে অবস্থিত। এটি বিভাজন (বিভাজন) অপারেশন হিসাবে পরিচিত।
পুনরাবৃত্তিমূলকভাবে (recursive) বেঞ্চমার্কের উপাদান থেকে ছোট এবং বেঞ্চমার্কের উপাদান থেকে বড় সাব-অ্যারেগুলিকে সাজানো হয়েছে।
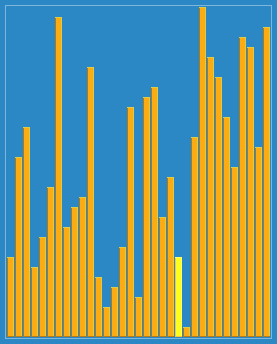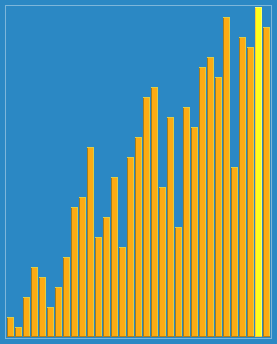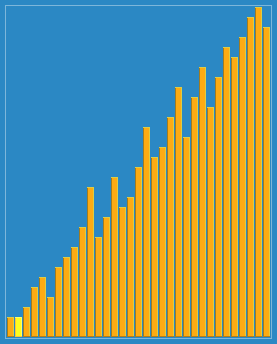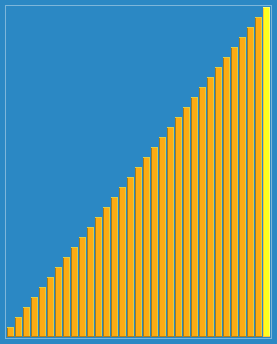
সোর্টিং এফেক্টঃ
- ### ২. পুনর্বিন্যাস
গল্পের শুরুঃ
মার্জ সোর্ট (Merge sort) হল একটি কার্যকর সোর্টিং অ্যালগরিদম যা মার্জ অপারেশনের উপর ভিত্তি করে তৈরি করা হয়েছে। এটি ডিভাইড এন্ড কনকার পদ্ধতির একটি খুব সাধারণ প্রয়োগ।
পদক্ষেপঃ
অনুরোধের স্থান, যার আকার দুইটি সাজানো ক্রমের সমষ্টি, যা সংযুক্ত ক্রমের জন্য ব্যবহৃত হয়
দুটি সূচক সেট করুন, যার প্রথম অবস্থানটি দুটি ইতিমধ্যে বাছাই করা ক্রমের শুরুতে রয়েছে
দুটি পয়েন্টার দ্বারা নির্দেশিত উপাদানগুলির তুলনা করুন, তুলনামূলকভাবে ছোট উপাদানগুলিকে সংযুক্ত স্থানে রাখুন এবং পয়েন্টারটিকে পরবর্তী স্থানে সরান
ধাপ 3 পুনরাবৃত্তি করুন যতক্ষণ না একটি পয়েন্টার ক্রমের শেষে পৌঁছে যায়
অন্য ক্রমের সমস্ত অবশিষ্ট উপাদানগুলিকে একত্রিত ক্রমের শেষে সরাসরি অনুলিপি করুন
সোর্টিং এফেক্টঃ

- ### ৩। স্ট্যাকের ক্রম
গল্পের শুরুঃ
হিপসোর্ট (Heapsort) হল একটি বাছাই পদ্ধতি যা হিপের ডেটা স্ট্রাকচার ব্যবহার করে ডিজাইন করা হয়েছে। হিপসোর্ট হল একটি সম্পূর্ণ ডাইভারজেন্ট গাছের মতো কাঠামো যা হিপসের বৈশিষ্ট্য পূরণ করেঃ যেহেতু একটি উপ-নোডের কী মান বা সূচক সর্বদা তার পিতা-মাতার চেয়ে ছোট (বা বড়) ।
পদক্ষেপঃ
(আরও জটিল, আপনি নিজেই অনলাইনে দেখুন)
সোর্টিং এফেক্টঃ
- ### ৪. নির্বাচন করুন
গল্পের শুরুঃ
নির্বাচন বাছাই (Selection sort) একটি সহজ এবং স্বজ্ঞাত বাছাই অ্যালগরিদম। এটি নিম্নরূপ কাজ করে। প্রথমে এটি একটি বাছাই করা বিন্যাসের মধ্যে সর্বনিম্ন উপাদানটি খুঁজে বের করে, এটিকে বাছাই করা বিন্যাসের শুরুতে সংরক্ষণ করে, তারপরে এটি অবশিষ্ট বাছাই করা উপাদানগুলি থেকে সর্বনিম্ন উপাদানটি সন্ধান করে এবং তারপরে এটিকে বাছাই করা বিন্যাসের শেষে রাখে। এবং তাই, যতক্ষণ না সমস্ত উপাদানগুলি বাছাই করা হয়।
সোর্টিং এফেক্টঃ

- ### ৫. বাষ্পীভবন বিন্যাস
গল্পের শুরুঃ
বুদ্বুদ বা বাষ্প বা বাষ্প বা বাষ্প বা বাষ্প বাষ্প বা বাষ্প বা বাষ্প বা বাষ্প বা বাষ্প বা বাষ্প বা বাষ্প বা বাষ্প বা বাষ্প বা বাষ্প বা বাষ্প বা বাষ্প বা বাষ্প বা বাষ্প বা বাষ্প বাষ্প বাষ্প বাষ্প বাষ্প বাষ্প বাষ্প বাষ্প বাষ্প বাষ্প বাষ্প বাষ্প বাষ্প বাষ্প বাষ্প বাষ্প বাষ্প বাষ্প বাষ্প বাষ্প বাষ্প বাষ্প বাষ্প বাষ্প বাষ্প বাষ্প বাষ্প বাষ্প বাষ্প বাষ্প বাষ্প বাষ্প বাষ্প বাষ্প বাষ্প বাষ্প বাষ্প বাষ্প বাষ্প বাষ্প বাষ্প বাষ্প বাষ্প বাষ্প বাষ্প বাষ্প বাষ্প বাষ্প বাষ্প বাষ্প বাষ্প বাষ্প বাষ্প বাষ্প বাষ্প বাষ্প বাষ্প বাষ্প বাষ্প বাষ্প
পদক্ষেপঃ
যদি প্রথমটি দ্বিতীয়টির চেয়ে বড় হয়, তবে তাদের দুটিকে বিনিময় করুন।
প্রতি জোড়া প্রতিবেশী উপাদানগুলির জন্য একই কাজ করুন, প্রথম জোড়া থেকে শুরু করে শেষ জোড়া পর্যন্ত। এই সময়ে, শেষ উপাদানটি সর্বাধিক সংখ্যক হওয়া উচিত।
সব উপাদানগুলির জন্য উপরের ধাপগুলি পুনরাবৃত্তি করুন, শেষটি বাদে
ধারাবাহিকভাবে, উপরে উল্লিখিত ধাপগুলোকে ক্রমবর্ধমান সংখ্যক উপাদানের সাথে পুনরাবৃত্তি করুন, যতক্ষণ না কোনও সংখ্যার জোড়া তুলনা করার প্রয়োজন হয় না।
সোর্টিং এফেক্টঃ

- ### ৬. ইনস্টল করুন
গল্পের শুরুঃ Insertion Sort (ইন্সট্রেশন সোর্ট) একটি সহজ এবং স্বজ্ঞাত সোর্টিং অ্যালগরিদম। এর কাজ হল একটি ক্রমিক ক্রম তৈরি করা। এটি অ-সোর্টেড ডেটা জন্য, সোর্টেড ক্রমের মধ্যে পিছন থেকে স্ক্যান করে, সংশ্লিষ্ট অবস্থান খুঁজে বের করে এবং সন্নিবেশ করে। সন্নিবেশ সোর্ট বাস্তবায়নের ক্ষেত্রে, সাধারণত ইন-প্লেস সোর্টিং ব্যবহার করা হয় (অর্থাৎ কেবলমাত্র O (১) এর অতিরিক্ত স্থান ব্যবহার করা হয়) । অতএব, পিছন থেকে এগিয়ে স্ক্যান করার সময়, সোর্টেড উপাদানগুলিকে ধীরে ধীরে পিছনে স্থানান্তরিত করা প্রয়োজন, যাতে নতুন উপাদানগুলির জন্য সন্নিবেশের স্থান সরবরাহ করা যায়। পদক্ষেপঃ প্রথম এলিমেন্ট থেকে শুরু করে, এলিমেন্টকে সাজানো বলে মনে করা যায় একটি নতুন উপাদান বের করে, এবং এটির মধ্যে একটি সোর্ড করা উপাদান থেকে পিছন থেকে এগিয়ে স্ক্যান করে যদি এই উপাদানটি [[:sorted:sorted:sorted:sorted:sorted:sorted:sorted:sorted:sorted:sorted:sorted:sorted:sorted:sorted:sorted:sorted:sorted:sorted:sorted:sorted:sorted:sorted:sorted:sorted:sorted:sorted:sorted:sorted:sorted:sorted:sorted:sorted:sorted:sorted:sorted]] নতুন উপাদানটির চেয়ে বড় হয়, তাহলে এই উপাদানটিকে পরবর্তী স্থানে সরান ধাপ 3 পুনরাবৃত্তি করুন যতক্ষণ না আপনি নতুন উপাদান থেকে ছোট বা সমান একটি স্থান খুঁজে বের করেছেন এই অবস্থানে নতুন উপাদান সন্নিবেশ ধাপ 2 পুনরাবৃত্তি করুন সোর্টিং এফেক্টঃ (কোন)
- ### ৭. হিলের ক্রম
গল্পের শুরুঃ
হিল বা ক্রমবর্ধমান ক্রমবর্ধমান ক্রমবর্ধমান ক্রমবর্ধমান ক্রমবর্ধমান ক্রমবর্ধমান ক্রমবর্ধমান ক্রমবর্ধমান ক্রমবর্ধমান ক্রমবর্ধমান ক্রমবর্ধমান ক্রমবর্ধমান ক্রমবর্ধমান ক্রমবর্ধমান ক্রমবর্ধমান ক্রমবর্ধমান ক্রমবর্ধমান ক্রমবর্ধমান ক্রমবর্ধমান ক্রমবর্ধমান ক্রমবর্ধমান।
হিল বাছাইয়ের পদ্ধতিটি উন্নত করার জন্য নিম্নলিখিত দুটি বৈশিষ্ট্যের উপর ভিত্তি করে প্রস্তাব করা হয়েছেঃ
১. ইনপুট বাছাই কার্যকরী হয় যখন প্রায় বাছাই করা ডেটা নিয়ে কাজ করা হয়, অর্থাৎ লিনিয়ার বাছাইয়ের দক্ষতা অর্জন করা যায়
২. কিন্তু ইন্সটল করা সোর্সিং সাধারণত কম কার্যকরী, কারণ ইন্সটল করা সোর্সিং প্রতিবার শুধুমাত্র একজনকে ডেটা স্থানান্তর করতে পারে
আমি সবচেয়ে বেশি ব্যবহার করি ফুঁকানোর পদ্ধতি (সবচেয়ে সহজ), আপনি?