
মেশিন লার্নিং অ্যালগরিদমের একটি সফর
আমাদের যে মেশিন লার্নিং সমস্যাগুলি সমাধান করতে হবে তা বোঝার পরে, আমরা কী ডেটা সংগ্রহ করতে হবে এবং আমরা কী অ্যালগরিদম ব্যবহার করতে পারি তা নিয়ে ভাবতে পারি। এই নিবন্ধে, আমরা সর্বাধিক জনপ্রিয় মেশিন লার্নিং অ্যালগরিদমগুলি ঘুরে দেখব এবং কী কী পদ্ধতি ব্যবহার করা যেতে পারে তার একটি সাধারণ ধারণা পেতে সহায়তা করব।
মেশিন লার্নিং এর ক্ষেত্রে অনেকগুলি অ্যালগরিদম রয়েছে, এবং প্রতিটি অ্যালগরিদমের অনেকগুলি এক্সটেনশন রয়েছে, তাই একটি নির্দিষ্ট সমস্যার জন্য সঠিক অ্যালগরিদমটি কীভাবে নির্ধারণ করা যায় তা কঠিন। এই নিবন্ধে আমি আপনাকে দুটি পদ্ধতিতে সংক্ষিপ্ত করতে চাই যা বাস্তবে দেখা যায়।
-
শেখার পদ্ধতি
অভিজ্ঞতা, পরিবেশ বা যে কোন তথ্যকে আমরা ইনপুট বলি তার উপর ভিত্তি করে অ্যালগরিদমকে বিভিন্ন শ্রেণীতে ভাগ করা হয়। মেশিন লার্নিং এবং এআই পাঠ্যপুস্তকে সাধারণত অ্যালগরিদমের সাথে সামঞ্জস্যপূর্ণ শেখার পদ্ধতিগুলি বিবেচনা করা হয়।
এখানে শুধুমাত্র কয়েকটি প্রধান শেখার শৈলী বা শেখার মডেল নিয়ে আলোচনা করা হয়েছে এবং কয়েকটি মৌলিক উদাহরণ দেওয়া হয়েছে। এই শ্রেণিবদ্ধকরণ বা সংগঠনের পদ্ধতিটি ভাল, কারণ এটি আপনাকে ইনপুট ডেটার ভূমিকা এবং মডেল প্রস্তুতির প্রক্রিয়া সম্পর্কে চিন্তা করতে বাধ্য করে এবং আপনার সমস্যার জন্য সবচেয়ে উপযুক্ত একটি অ্যালগরিদম বেছে নিতে বাধ্য করে, যার ফলে সেরা ফলাফল পাওয়া যায়।
মনিটরিং লার্নিংঃ ইনপুট ডেটাকে প্রশিক্ষণ ডেটা বলা হয় এবং এর ফলাফল জানা থাকে বা এটিকে চিহ্নিত করা হয়। উদাহরণস্বরূপ, একটি ইমেল স্প্যাম কিনা বা সময়ের মধ্যে শেয়ারের দাম কিনা। মডেলটি ভবিষ্যদ্বাণী করে, যদি ভুল হয় তবে সংশোধন করা হয়, এবং এই প্রক্রিয়াটি অব্যাহত থাকে যতক্ষণ না এটি প্রশিক্ষণ ডেটার জন্য একটি নির্দিষ্ট সঠিক মানদণ্ড অর্জন করতে পারে। সমস্যা উদাহরণগুলির মধ্যে শ্রেণিবদ্ধকরণ এবং পুনরাবৃত্তি সমস্যা অন্তর্ভুক্ত রয়েছে এবং অ্যালগরিদমের উদাহরণগুলির মধ্যে রয়েছে লজিকাল রিগ্রেশন এবং বিপরীত নিউরাল নেটওয়ার্ক।
তত্ত্বাবধানহীন শিক্ষাঃ ইনপুট ডেটা চিহ্নিত করা হয় না এবং ফলাফলও নিশ্চিত করা হয় না। মডেলগুলি ডেটার কাঠামো এবং মানকে অন্তর্ভুক্ত করে। সমস্যাগুলির উদাহরণগুলির মধ্যে রয়েছে অ্যাসোসিয়েশন রুল লার্নিং এবং ক্লাস্টারিং সমস্যা, এবং অ্যালগরিদমের উদাহরণগুলির মধ্যে রয়েছে অ্যাপ্রিওরি অ্যালগরিদম এবং কে-ভিত্তিক অ্যালগরিদম।
আধা-নিরীক্ষিত শিক্ষাঃ ইনপুট ডেটা হল ট্যাগ করা এবং অ-ট্যাগ করা ডেটার মিশ্রণ, কিছু ভবিষ্যদ্বাণীমূলক সমস্যা আছে কিন্তু মডেলগুলিকে ডেটার গঠন এবং রচনাও শিখতে হবে। সমস্যা উদাহরণগুলি শ্রেণিবদ্ধকরণ এবং রিগ্রেশন সমস্যাগুলি অন্তর্ভুক্ত করে, অ্যালগরিদম উদাহরণগুলি মূলত নিরীক্ষণহীন শেখার অ্যালগরিদমের প্রসারিত।
বর্ধিত শিক্ষাঃ ইনপুট ডেটা মডেলকে উদ্দীপিত করতে পারে এবং মডেলকে প্রতিক্রিয়া জানাতে পারে। প্রতিক্রিয়া কেবল তত্ত্বাবধানে শেখার শেখার প্রক্রিয়া থেকে নয়, পরিবেশের পুরষ্কার বা শাস্তি থেকেও পাওয়া যায়। সমস্যা উদাহরণ রোবট নিয়ন্ত্রণ, অ্যালগরিদমের উদাহরণগুলির মধ্যে রয়েছে কিউ-লার্নিং এবং সাময়িক পার্থক্য শেখার।ডেটা সিমুলেশন ব্যবসায়িক সিদ্ধান্তের সাথে সংযুক্ত করার সময়, বেশিরভাগই তদারকি করা শেখার এবং তত্ত্বাবধানহীন শেখার পদ্ধতি ব্যবহার করে। পরবর্তী একটি জনপ্রিয় বিষয় হ'ল আধা-নিরীক্ষামূলক শিক্ষা, যেমন চিত্র শ্রেণিবদ্ধকরণ সমস্যা, যেখানে সমস্যার একটি বড় ডাটাবেস রয়েছে তবে চিত্রগুলির একটি ছোট অংশই চিহ্নিত করা হয়েছে। বর্ধিত শিক্ষার বেশিরভাগ অংশই রোবোটিক নিয়ন্ত্রণ এবং অন্যান্য নিয়ন্ত্রণ সিস্টেমের বিকাশে ব্যবহৃত হয়।
-
অ্যালগরিদমের মিল
অ্যালগরিদমগুলি মূলত কার্যকারিতা বা ফর্মের ভিত্তিতে শ্রেণিবদ্ধ করা হয়। উদাহরণস্বরূপ, গাছ-ভিত্তিক অ্যালগরিদম, নিউরাল নেটওয়ার্ক অ্যালগরিদম। এটি একটি দরকারী শ্রেণিবদ্ধকরণ, তবে এটি নিখুঁত নয়। অনেকগুলি অ্যালগরিদম সহজেই দুটি শ্রেণিতে বিভক্ত করা যায়, যেমন লার্নিং ভেক্টর কোয়ানটাইজেশন একই সাথে নিউরাল নেটওয়ার্ক শ্রেণীর অ্যালগরিদম এবং উদাহরণ-ভিত্তিক পদ্ধতি। মেশিন লার্নিং অ্যালগরিদমের নিজস্ব কোনও নিখুঁত মডেল নেই, অ্যালগরিদমের শ্রেণিবদ্ধকরণের পদ্ধতিও নিখুঁত নয়।
এই অংশে আমি শ্রেণিবদ্ধকরণের অ্যালগরিদমের একটি তালিকা দিয়েছি যা আমি মনে করি সবচেয়ে স্বজ্ঞাত পদ্ধতি। আমি অ্যালগরিদম বা শ্রেণিবদ্ধকরণের পদ্ধতিগুলি শেষ করতে পারি না, তবে পাঠকদের একটি সাধারণ ধারণা দেওয়ার জন্য এটি সহায়ক বলে মনে করি। যদি আপনি জানেন যে আমি এটি তালিকাভুক্ত করি নি, তবে মন্তব্যে স্বাগতম। এখন আমরা শুরু করছি!
-
Regression
Regression (রিগ্রেশন বিশ্লেষণ) ভেরিয়েবলের মধ্যে সম্পর্ক নিয়ে উদ্বিগ্ন। এটি পরিসংখ্যানগত পদ্ধতি প্রয়োগ করে। এর কয়েকটি উদাহরণ হলঃ
Ordinary Least Squares
Logistic Regression
Stepwise Regression
Multivariate Adaptive Regression Splines (MARS)
Locally Estimated Scatterplot Smoothing (LOESS) -
Instance-based Methods
Instance based learning একটি সিদ্ধান্ত গ্রহণের প্রশ্নের মডেলিং করে, যেখানে ব্যবহৃত উদাহরণ বা উদাহরণগুলি মডেলের জন্য অত্যন্ত গুরুত্বপূর্ণ। এই পদ্ধতিটি বিদ্যমান ডেটা নিয়ে একটি ডাটাবেস তৈরি করে এবং তারপরে নতুন ডেটা যুক্ত করে, তারপরে একটি অনুরূপতা পরিমাপ পদ্ধতি ব্যবহার করে যাতে ডাটাবেসে একটি সেরা মিল খুঁজে পাওয়া যায়, একটি ভবিষ্যদ্বাণী করা যায়। এই কারণে, এই পদ্ধতিটি বিজয়ী হিসাবে রাজা এবং মেমরি-ভিত্তিক পদ্ধতি হিসাবেও পরিচিত।
k-Nearest Neighbour (kNN)
Learning Vector Quantization (LVQ)
Self-Organizing Map (SOM) -
Regularization Methods
এটি অন্যান্য পদ্ধতির একটি প্রসারিত (সাধারণত একটি রিগ্রেশন পদ্ধতি) যা সহজ মডেলের জন্য উপকারী এবং আরও ভাল পুনরাবৃত্তি করে। আমি এখানে এটি তালিকাভুক্ত করেছি কারণ এটি জনপ্রিয় এবং শক্তিশালী।
Ridge Regression
Least Absolute Shrinkage and Selection Operator (LASSO)
Elastic Net -
Decision Tree Learning
Decision tree methods (ডিসিশন ট্রি মেথড) এমন একটি মডেল তৈরি করে যা ডেটাতে প্রকৃত মানের উপর ভিত্তি করে সিদ্ধান্ত নেয়। সিদ্ধান্ত গাছগুলি অন্তর্ভুক্তি এবং রিগ্রেশন সমস্যা সমাধানের জন্য ব্যবহৃত হয়।
Classification and Regression Tree (CART)
Iterative Dichotomiser 3 (ID3)
C4.5
Chi-squared Automatic Interaction Detection (CHAID)
Decision Stump
Random Forest
Multivariate Adaptive Regression Splines (MARS)
Gradient Boosting Machines (GBM) -
Bayesian
Bayesian method বা বেয়েসিয়ান পদ্ধতি বা বেয়েসিয়ান পদ্ধতি বা বেয়েসিয়ান পদ্ধতি বা বেয়েসিয়ান পদ্ধতি বা বেয়েসিয়ান পদ্ধতি বা বেয়েসিয়ান পদ্ধতি বা বেয়েসিয়ান পদ্ধতি বা বেয়েসিয়ান পদ্ধতি বা বেয়েসিয়ান পদ্ধতি বা বেয়েসিয়ান পদ্ধতি বা বেয়েসিয়ান পদ্ধতি বা বেয়েসিয়ান পদ্ধতি বা বেয়েসিয়ান পদ্ধতি বা বেয়েসিয়ান পদ্ধতি বা বেয়েসিয়ান পদ্ধতি বা বেয়েসিয়ান পদ্ধতি বা বেয়েসিয়ান পদ্ধতি বা বেয়েসিয়ান পদ্ধতি বা বেয়েসিয়ান পদ্ধতি বা বেয়েসিয়ান পদ্ধতি বা বেয়েসিয়ান পদ্ধতি।
Naive Bayes
Averaged One-Dependence Estimators (AODE)
Bayesian Belief Network (BBN) -
Kernel Methods
কার্নেল পদ্ধতির মধ্যে সবচেয়ে বিখ্যাত হল সাপোর্ট ভেক্টর মেশিন। এই পদ্ধতিটি ইনপুট ডেটাকে উচ্চতর মাত্রায় ম্যাপ করে, কিছু শ্রেণিবদ্ধকরণ এবং রিগ্রেশন সমস্যাগুলি মডেল করা সহজ।
Support Vector Machines (SVM)
Radial Basis Function (RBF)
Linear Discriminate Analysis (LDA) -
Clustering Methods
ক্লাস্টারিং (clustering) নিজেই একটি সমস্যা এবং পদ্ধতির বর্ণনা দেয়। ক্লাস্টারিং পদ্ধতিগুলি সাধারণত মডেলিং পদ্ধতি দ্বারা শ্রেণিবদ্ধ করা হয়। সমস্ত ক্লাস্টারিং পদ্ধতিগুলিকে একটি ইউনিফাইড ডেটা স্ট্রাকচার দিয়ে ডেটা সংগঠিত করা হয় যাতে প্রতিটি গ্রুপের মধ্যে সর্বাধিক মিল থাকে।
K-Means
Expectation Maximisation (EM) -
Association Rule Learning
Association rule learning (অ্যাসোসিয়েশন রুল লার্নিং) হচ্ছে এমন একটি পদ্ধতি যা তথ্যের মধ্যে নিয়মগুলি বের করার জন্য ব্যবহার করা হয়। এই নিয়মগুলির মাধ্যমে বিপুল সংখ্যক বহু-মাত্রিক স্থানিক তথ্যের মধ্যে সংযোগগুলি খুঁজে পাওয়া যায়, এবং এই গুরুত্বপূর্ণ সংযোগগুলি সংগঠন দ্বারা ব্যবহার করা যেতে পারে।
Apriori algorithm
Eclat algorithm -
Artificial Neural Networks
Artificial Neural Networks (আর্টিফিশিয়াল নিউরাল নেটওয়ার্ক) হল জীবজগতের নিউরাল নেটওয়ার্কের গঠন এবং কার্যকারিতার উপর ভিত্তি করে তৈরি করা হয়েছে। এটি মডেল-ম্যাচিংয়ের একটি শ্রেণীর অন্তর্গত, যা প্রায়শই রিগ্রেশন এবং শ্রেণিবদ্ধকরণ সমস্যার জন্য ব্যবহৃত হয়, তবে এটি শত শত অ্যালগরিদম এবং বৈকল্পিক দ্বারা গঠিত। এর মধ্যে কয়েকটি হল ক্লাসিকভাবে জনপ্রিয় অ্যালগরিদম (আমি গভীর শিক্ষণকে আলাদা করে তুলেছি):
Perceptron
Back-Propagation
Hopfield Network
Self-Organizing Map (SOM)
Learning Vector Quantization (LVQ) -
Deep Learning
গভীর শিক্ষা পদ্ধতি হল কৃত্রিম নিউরাল নেটওয়ার্কের একটি আধুনিক আপডেট। ঐতিহ্যবাহী নিউরাল নেটওয়ার্কের তুলনায় এটির আরো বেশি জটিল নেটওয়ার্ক গঠন রয়েছে। অনেক পদ্ধতি আধা-নিরীক্ষিত শেখার বিষয়ে উদ্বিগ্ন, এই ধরনের শেখার সমস্যাগুলির মধ্যে প্রচুর পরিমাণে ডেটা রয়েছে, তবে এর মধ্যে খুব কমই ট্যাগ করা ডেটা রয়েছে।
Restricted Boltzmann Machine (RBM)
Deep Belief Networks (DBN)
Convolutional Network
Stacked Auto-encoders -
Dimensionality Reduction
Dimensionality Reduction (মাত্রা হ্রাস), যেমন একটি ক্লাস্টারিং পদ্ধতি, তথ্যের মধ্যে ইউনিফাইড কাঠামোর সন্ধান করে এবং ব্যবহার করে, তবে এটি কম তথ্য ব্যবহার করে ডেটা সংক্ষিপ্তকরণ এবং বর্ণনা করে। এটি ডেটা ভিজ্যুয়ালাইজ করার জন্য বা ডেটা সরল করার জন্য দরকারী।
Principal Component Analysis (PCA)
Partial Least Squares Regression (PLS)
Sammon Mapping
Multidimensional Scaling (MDS)
Projection Pursuit -
Ensemble Methods
Ensemble methods অনেকগুলো ছোট ছোট মডেল নিয়ে গঠিত, যেগুলো স্বাধীনভাবে প্রশিক্ষিত হয়, স্বাধীনভাবে সিদ্ধান্তে আসে, এবং শেষ পর্যন্ত একটি পূর্বাভাস দেয়। অনেক গবেষণা কি মডেল ব্যবহার করা হয় এবং কিভাবে এই মডেলগুলোকে একত্রিত করা হয় তার উপর দৃষ্টি নিবদ্ধ করে। এটি একটি অত্যন্ত শক্তিশালী এবং জনপ্রিয় কৌশল।
Boosting
Bootstrapped Aggregation (Bagging)
AdaBoost
Stacked Generalization (blending)
Gradient Boosting Machines (GBM)
Random Forest
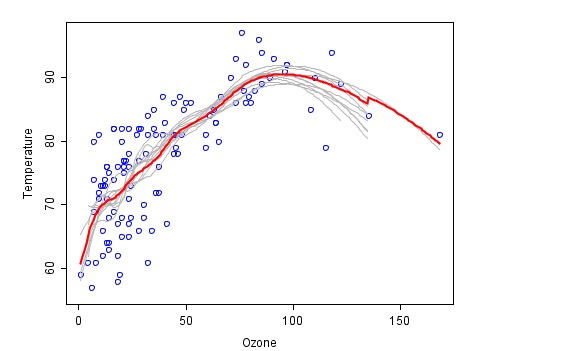
এটি একটি উদাহরণ যেখানে সমন্বিত পদ্ধতির মাধ্যমে সমন্বয় করা হয়েছে (উইকি থেকে নেওয়া), প্রতিটি ফায়ার কোডকে ধূসর রঙে উপস্থাপন করা হয়েছে এবং চূড়ান্ত সমন্বিত পূর্বাভাসকে লাল রঙে উপস্থাপন করা হয়েছে।
-
অন্যান্য সম্পদ
মেশিন লার্নিং অ্যালগরিদমের এই সফরটি আপনাকে কিছু সরঞ্জাম এবং সম্পর্কিত অ্যালগরিদম সম্পর্কে একটি সামগ্রিক ধারণা দেবে।
নিচে কিছু অন্যান্য সম্পদ দেওয়া হল, দয়া করে মনে করবেন না যে এটি অনেক বেশি, যত বেশি অ্যালগরিদম আপনি জানতে পারবেন ততই ভাল হবে, তবে কিছু অ্যালগরিদম সম্পর্কে গভীর জ্ঞান থাকাও সহায়ক হতে পারে।
- List of Machine Learning Algorithms: এটি উইকিপিডিয়ার একটি সম্পদ, যদিও এটি সম্পূর্ণ, কিন্তু আমি মনে করি এটি ভালভাবে শ্রেণীবদ্ধ করা হয়নি।
- মেশিন লার্নিং অ্যালগরিদমস বিষয়শ্রেণীঃউইকিতে আরো একটি সম্পদ, উপরের তুলনায় একটু ভাল, বর্ণানুক্রমিকভাবে সাজানো হয়েছে।
- CRAN Task View: Machine Learning & Statistical Learning: মেশিন লার্নিং অ্যালগরিদমের জন্য R ভাষা এক্সটেনশন প্যাকেজ, দেখুন অন্যরা কি ব্যবহার করছে তা আপনার জন্য আরও ভাল।
- Top 10 Algorithms in Data Mining: এটি একটি প্রকাশিত নিবন্ধ, এখন একটি বই, যা সর্বাধিক জনপ্রিয় ডেটা মাইনিং অ্যালগরিদমগুলি নিয়ে গঠিত। আরেকটি মৌলিক অ্যালগরিদমের তালিকা, এখানে তালিকাভুক্ত অ্যালগরিদমগুলি অনেক কম, যা আপনাকে আরও গভীরভাবে শিখতে সহায়তা করে।
বোরো পত্রিকা থেকে পুনর্নির্দেশিত
- 1