Orderbuch-Hochfrequenzhandelsstrategie basierend auf maschinellem Lernen
 1
8025
1
8025
Orderbuch-Hochfrequenzhandelsstrategie basierend auf maschinellem Lernen
- ### 1. Theorie
Die Handelsmechanismen der Wertpapiermärkte können in zwei Arten unterteilt werden: Angebots- und Auftragsmarkt. Bei den ersten handelt es sich um die Bereitstellung von Liquidität durch die Marktteilnehmer. Bei den anderen handelt es sich um die Bereitstellung von Liquidität durch die Begrenzung der Preise.
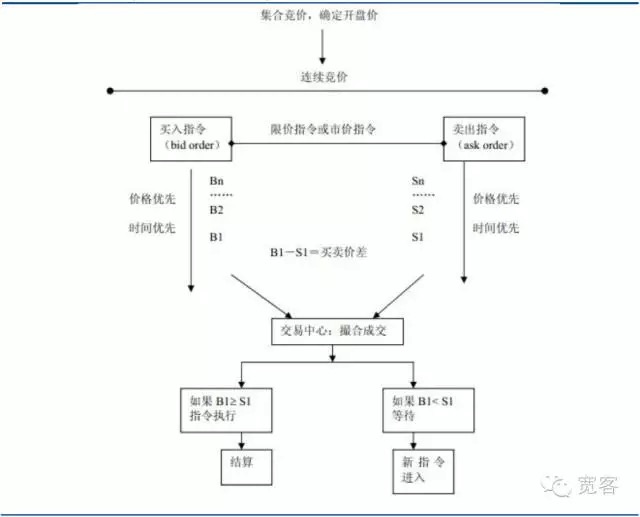 Abbildung 1 - Auftragsgetriebene Märkte
Abbildung 1 - Auftragsgetriebene Märkte
-
(i) Beschreibung des Bestellbuchs mit dem Preislimit
Die Theorie der Marktmikrostruktur stützt sich auf die Preistheorie und die Herstellertheorie der Mikroökonomie. In ihrer Analyse der Prozesse und Ursachen der Preissteigerung von Finanzanlagen, der allgemeinen Gleichgewicht, der lokalen Gleichgewicht, der Marginalertrag, der Marginalkosten, der Marktkontinuität, der Lagerhaltungstheorie, der Spieltheorie und der Informationsökonomie werden verschiedene Theorien und Methoden verwendet.
Ausländische Forschungsfortschritte zeigen, dass O’Hara im Bereich der Marktmikrostruktur vertreten ist. Die meisten Theorien basieren auf Marktmeistermärkten (d.h. angebotsgetriebenen Märkten), wie Lagermodellen und Informationsmodellen. In diesem Jahr hat der Auftragsgetriebene in den tatsächlichen Handelsmärkten nach und nach den oberen Platz eingenommen, aber es gibt noch weniger Studien, die sich speziell auf den Auftragsgetriebenen konzentrieren.
Im Inland gehören die Wertpapier- und die Futures-Märkte zu den ordnungsgetriebenen Märkten. Unten ist ein Screenshot des Level_1-Trend-Orderbuchs des IF1312-Index-Futures-Kontrakts. Von oben wird nicht viel Informationen direkt erhalten. Die grundlegenden Informationen umfassen einen Kaufpreis, einen Verkaufspreis, eine Kaufmenge und eine Verkaufsmenge.
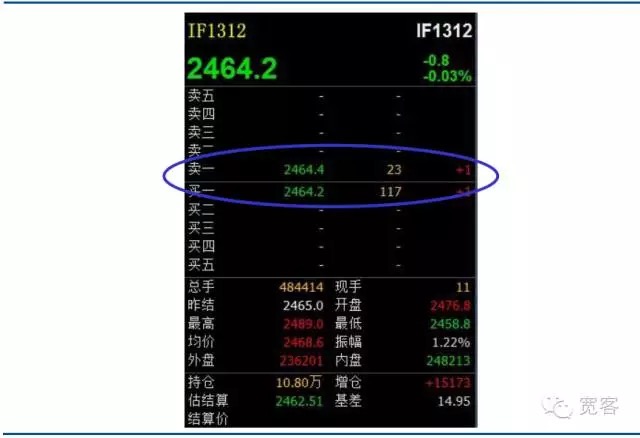 Abbildung 2 Aktienindex-Futures-Level-1-Hauptschwerverträge Auftragsbuch
Abbildung 2 Aktienindex-Futures-Level-1-Hauptschwerverträge Auftragsbuch -
(ii) Fortschritte bei der Erforschung von Hochfrequenztransaktionen in Auftragsbüchern
Die dynamische Modellierung von Auftragsbüchern erfolgt in zweierlei Hinsicht: in der klassischen Methode der Messwirtschaft und in der Methode des maschinellen Lernens. Die Messwirtschaft ist eine der klassischen und gängigen Forschungsmethoden, wie z. B. die MRR-Auflösung für die Preisdifferenzanalyse, die Huang- und Stoll-Auflösung, die ACD-Modelle für die Auftragsdauer und die Logistic-Modelle für die Preisprognose.
Auch in der Finanzwelt ist die wissenschaftliche Forschung mit Machine Learning sehr aktiv, wie zum Beispiel bei der Vorhersage von Trends von high_frequency KOSPI200 index data using learning classifiers im Jahr 2012. Es ist eine gängige Forschungsidee, die übliche Indikatoren der technischen Analyse (MA, EMA, RSI usw.) zu verwenden, um die Marktprognose durch die Einführung einer Klassifizierungsmethode aus Machine Learning zu erstellen. Diese Methode ist jedoch unzureichend, um die dynamischen Informationen der Auftragsbücher zu nutzen.
-
2. Anwendung von Machine Learning im Hochfrequenzhandel im Auftragsbuch
- #### (a) Systemarchitektur
Die folgende Grafik zeigt die Systemarchitektur einer typischen maschinellen Lern-Handelsstrategie, die mehrere Hauptmodule umfasst, darunter Auftragsbuchdaten, Merkmalserkennung, Modellbildung und Validierung und Handelschancen. Es ist erwähnenswert, dass der Handelsprozess durch Tick-Trade-Ereignisse ausgelöst wird, wobei die Ankunft eines Tick-Trade-Ereignisses eine dieser Ereignisse ist.
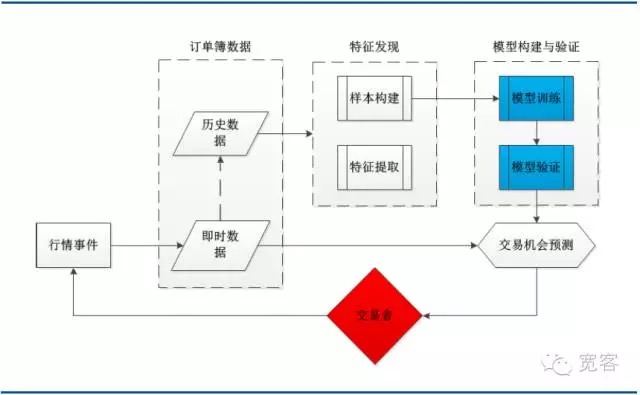 Abbildung 3: Systemarchitektur für die Modellierung von Auftragsbüchern auf Basis von Machine Learning
Abbildung 3: Systemarchitektur für die Modellierung von Auftragsbüchern auf Basis von Machine Learning- #### (ii) Unterstützung der Vektor-Beschreibung
In den 1970er Jahren begann Wapnik et al. mit der Erstellung eines vergleichsweise vollständigen theoretischen Systems zur statistischen Lerntheorie (SLT), das zur Erforschung statistischer Regeln und der Eigenschaften von Lernmethoden in begrenzten Stichprobenbedingungen verwendet wird. Es schafft einen guten theoretischen Rahmen für die Probleme des maschinellen Lernens mit begrenzten Stichproben und befasst sich besser mit praktischen Problemen wie kleinen Stichproben, Nichtlinearität, hoher Dimension und lokalen Minimalpunkten.
SVM entwickelt sich aus einer optimalen Klassifizierung der Überfläche in linear teilbaren Fällen. Für Klassifizierungsfragen in zwei Kategorien wird die Trainings-Sample-Sammlung als ((xi,yi), i = 1,2…l, l die Zahl der Trainings-Samples, xi die Zahl der Trainings-Samples, yi gehört zu {-1,+1} und ist die Klassenmarkierung für die Eingabe der Probe xi ((erwartete Ausgabe)). Der Ausgangspunkt der SVM-Algorithmen ist die Suche nach einer optimalen Klassifizierung der Überfläche.
Die optimale Klassifizierung der Überfläche erlaubt nicht nur die richtige Trennung aller Proben (Trainingsfehler-Score 0), sondern auch die größtmögliche Grenze (Margin) zwischen den beiden Klassen. Die Grenze ist definiert als die Summe der kleinsten Entfernungen des Trainingsdatensatzes von der Klassifizierung der Überfläche. Die optimale Klassifizierung der Überfläche bedeutet, dass der durchschnittliche Klassifizierungsfehler der Testdaten gering ist.
Wenn eine Superfläche in einem d-dimensionalen Vektorraum vorhanden ist:
F(x)=w*x+b=0
Eine Hyperfläche, die die beiden Datenarten voneinander trennt, wird als Interface bezeichnet.*x ist das Innenvolumen zweier Vektoren w und x in einem d-dimensionalen Vektorraum.
Wenn die Schnittstelle:
w*x+b=0
Die optimale Schnittstelle ist die, die den größten Abstand zwischen den beiden nahegelegenen Proben dieser Schnittstelle (Margin) erreicht.
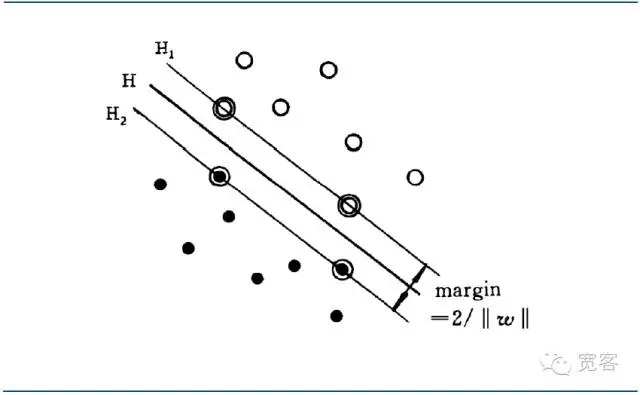 Grafik 4 Diagramm der optimalen Interfaces der SVM-Klassifizierung
Grafik 4 Diagramm der optimalen Interfaces der SVM-KlassifizierungDie Vereinheitlichung der optimale Differential-Interface-Gleichung ermöglicht, dass die Entfernung zwischen zwei Arten von Proben
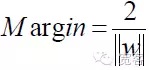
Also, für jede beliebige Stichprobe gibt es
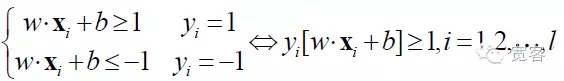
Um eine optimale Interface zu erhalten, muss man die oben genannte Formel erfüllen und auch minimieren.
Das mathematische Modell für die SVM-Frage lautet:
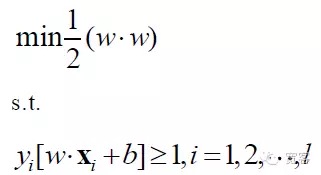
SVM wurde schließlich zu einem optimierten Planungsproblem, dessen Forschung in der akademischen Welt hauptsächlich auf schnelle Lösungen und die Verbreitung in mehrere Kategorien, praktische Anwendungen und so weiter konzentriert ist.
SVM wurde ursprünglich für Zweiklassenprobleme entwickelt, um diese nach den aktuellen Anwendungsbedürfnissen auf Mehrklassenprobleme auszuweiten. Die bereits existierenden Mehrklassenalgorithmen umfassen ein- und mehrere Paare, ein-und-ein-Paare, Fehlerbehebungen, DAG-SVM und Multi-i-class SVM-Klassifikatoren usw.
- #### (iii) Entnahme von Bestellbuchindizes
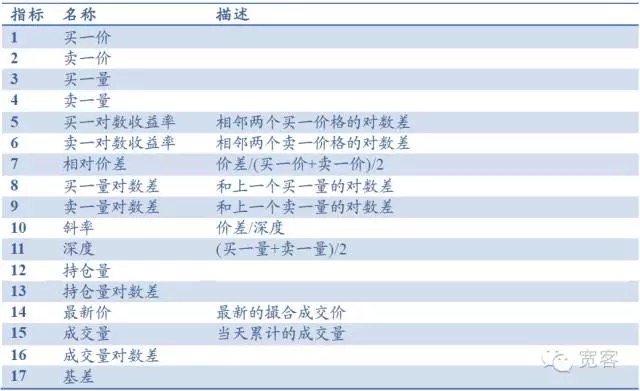
Die Bestellbücher umfassen hauptsächlich Basisindikatoren wie Kaufpreis, Verkaufpreis, Kaufmenge und Verkaufmenge. Sie können auch Indikatoren wie Tiefe, Verlauf und Relativpreisdifferenz erzeugen. Andere Indikatoren umfassen Positionsvolumen, Transaktionsvolumen und Basisdifferenz.
Tabelle 1 Index-Basis auf Basis der Level-Kundenbücher
- #### (iv) Bewegungscharakteristiken der Auftragsbücher und Handelsmöglichkeiten
In der Marktmikroskopie gibt es zwei Methoden, um die kurzfristige Preisbewegung zu messen, eine ist die mittlere Preisbewegung, die andere ist die Differenzkreuzung. In diesem Artikel werden die einfacheren und intuitiveren mittleren Preisbewegung ausgewählt.
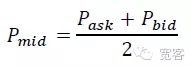
Die Größe der Veränderung des Mittelpreises ΔP innerhalb von Δt in der Auftragsbücherei unterteilt sich in drei Kategorien:
Die nachstehende Grafik zeigt die Verteilung der mittleren Kursdynamik des Haupttrages IF1311 am 29. Oktober mit 32400 tick-Tagesdaten.
Bei Δt=1tick variieren die Mittelwert-Absolute etwa 6000 mal um 0,2 und 1500 mal um 0,4, 150 mal um 0,6, 50 mal um 0,8 und 10 mal um 1 und mehr.
Bei Δt=2tick variieren die Mittelwert-Absolute etwa 7000 mal um den Wert 0.2, die Absolute etwa 3000 mal um den Wert 0.4, die Absolute etwa 550 mal um den Wert 0.6, die Absolute etwa 205 mal um den Wert 0.8 und die Absolute größer als oder gleich 1 etwa 10 mal.
Wir betrachten Veränderungen mit einem absoluten Wert größer als oder gleich 0,4 als potenzielle Handelschancen. Bei Δt = 1 tick gibt es etwa 1700 Gelegenheiten pro Tag; bei Δt = 2 tick etwa 4000 Gelegenheiten pro Tag.
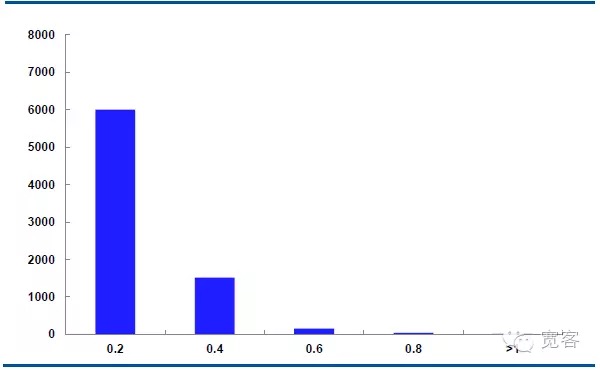
Abbildung 5 IF1311 Verteilung der Mittelpreisänderung am 29. Oktober
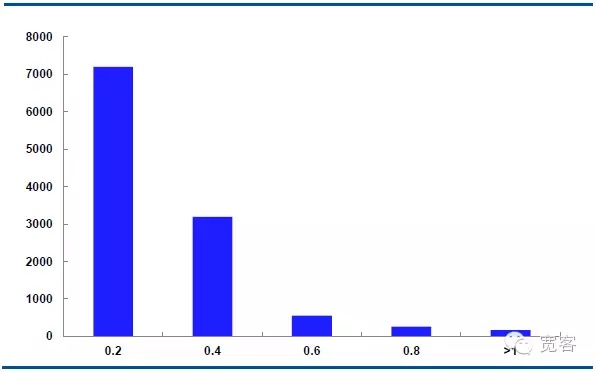
Abbildung 6 IF1311 Verteilung der Mittelpreisänderung am 29. Oktober
-
Drei: Strategie und Praxis
Da das SVM-Modell in großen Stichproben mit einer relativ hohen Trainingskomplexität und langen Trainingszeiten ausgestattet ist, wählen wir die relativ kurzen Zeiträume der historischen Praxisdaten, um die Effektivität des Modells anhand der Level_1-Praxisdaten des IF1311-Vertrags im Oktober zu überprüfen.
-
(i) Modellwirksamkeitstests
Datenperiode: IF1311-Kontrakte im Oktober;
Δt-Bewertung: Je kleiner die Δt, desto höher ist die Anforderung an die Transaktionsdetails. Wenn Δt = 1 tick, ist es schwierig, einen Gewinn im tatsächlichen Handel zu erzielen. Um die Wirksamkeit des Modells zu vergleichen, werden hier 1 tick, 2 tick und 3 tick bewertet.
Modellbewertungsindikatoren: Probenachrichtigkeit, Prüfgenauigkeit, Prognosezeit.
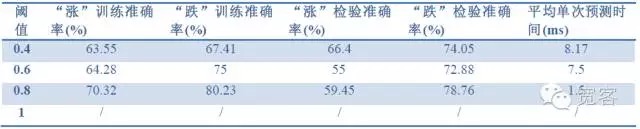 Tabelle 2 Prognose der Wirkung von 1 tick mit 1 tick Daten
Tabelle 2 Prognose der Wirkung von 1 tick mit 1 tick Daten Tabelle 3 Prognose der Wirkung von tick2 auf 1 tick
Tabelle 3 Prognose der Wirkung von tick2 auf 1 tick Tabelle 4 2tick-Daten zur Vorhersage der Wirkung von 2tick
Tabelle 4 2tick-Daten zur Vorhersage der Wirkung von 2tickAus den drei Tabellen können wir folgende Schlussfolgerungen ziehen: Die höchste Genauigkeit beträgt ungefähr 70%, bei einer Genauigkeit von 60% kann sie in eine Handelsstrategie umgewandelt werden.
-
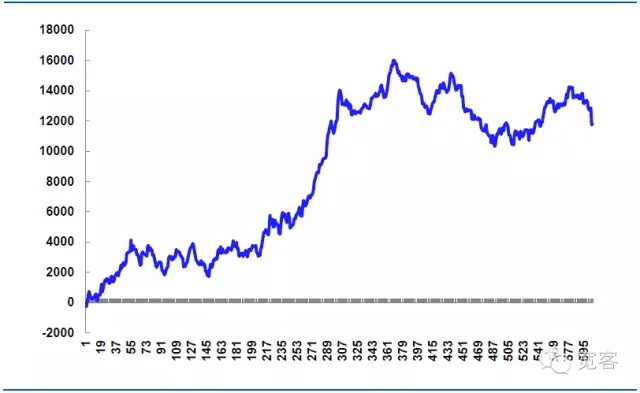
(ii) Strategie simulierte Gewinne
Nehmen wir zum Beispiel den 31. Oktober, wir machen einen Simulationshandel, die Aktienindex-Futures-Handelsgebühren der Institutionen sind im Allgemeinen die Aktienindex-Futures-Handelsgebühren der Institutionen sind im Allgemeinen 0,26⁄10000, wir nehmen an, dass die Anzahl der Geschäfte unbegrenzt ist, und nehmen wir an, dass der Preis pro Handel einseitig um 0,2 Punkte schwankt, und die Anzahl der Aufträge beträgt 1 Hand.
Tabelle 5 Simulationsstrategie am 31. Oktober

605 Trades am Tag, inklusive Handlungen, 339 Gewinne, 56% Gewinn, Netto-Gewinn von 11814,99 Yuan.
Der theoretische Kursverlust beträgt 14.520 Yuan, was zum Teil der Schlüssel für die Strategie ist. Wenn die Auftragsdetails besser kontrolliert werden, kann der Kursverlust reduziert und der Nettogewinn erhöht werden. Wenn die Auftragsdetails nicht richtig kontrolliert werden oder die Marktschwankungen ungewöhnlich sind, wird der Kursverlust größer sein, während der Nettogewinn reduziert wird.
Abbildung 7: Gewinne der Simulationsstrategie am 31. Oktober
Der Artikel wurde von der Autorin der Webseite www.youtube.com/watch?v=0k0k0k0w0f und wurde von der Webseite www.youtube.com/watch?v=0k0k0k0w0f übertragen.