Maschinelles Lernen zum Spaß: Der einfachste Leitfaden für Anfänger
 3
3605
3
3605
Maschinelles Lernen zum Spaß: Der einfachste Leitfaden für Anfänger
Sind Sie es leid, mit Ihren Kollegen zu reden und nur mit dem Kopf zu nicken? Lassen Sie uns das ändern!
Die Leser dieses Leitfadens sind alle, die sich für Machine Learning interessieren, aber nicht wissen, wie man anfängt. Ich denke, viele von Ihnen haben schon Wikipedia-Bezeichnungen zu Machine Learning gelesen und sind enttäuscht, dass niemand eine hochwertige Erklärung dafür geben kann.
Das Ziel dieses Artikels ist es, einfach und zugänglich zu sein, was bedeutet, dass es eine große Menge an Verallgemeinerungen gibt. Aber wen kümmert das?
- ### Warum maschinelles Lernen?
Das Konzept des maschinellen Lernens besagt, dass man für die zu lösenden Probleme keinen speziellen Programmierkode schreiben muss, sondern dass genetische Algorithmen (generic algorithms) auf dem Datensatz interessante Antworten für einen erzeugen können. Bei genetischen Algorithmen wird kein Code verwendet, sondern Daten eingegeben, die ihre eigene Logik auf den Daten aufbauen.
Zum Beispiel gibt es eine Klasse von Algorithmen, die als Klassifikationsalgorithmen bezeichnet werden und die Daten in verschiedene Gruppen unterteilen können. Ein Klassifikationsalgorithmus, der handschriftliche Zahlen erkennt, kann verwendet werden, um E-Mails in Spam und Normalpost zu unterteilen, ohne eine Zeile des Codes zu ändern. Der Algorithmus ist unverändert, aber das Training der eingegebenen Daten hat sich verändert, so dass er eine andere Klassifizierungslogik hervorbringt.
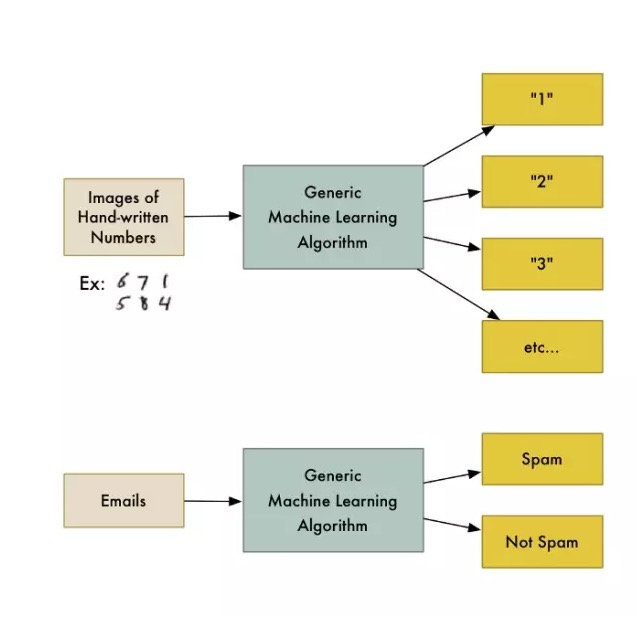
Maschinelle Lernalgorithmen sind eine schwarze Box, die für viele verschiedene Klassifikationsprobleme verwendet werden kann.
Der Begriff “Machine Learning” ist ein umfassender Begriff, der viele ähnliche genetische Algorithmen umfasst.
- ### Zwei Arten von Algorithmen für maschinelles Lernen
Man kann Machine Learning-Algorithmen in zwei große Kategorien unterteilen: Supervised Learning und Unsupervised Learning. Die Unterscheidung zwischen den beiden ist einfach, aber sehr wichtig.
-
Überwachte Lernen
Angenommen, Sie sind ein Immobilienmakler, und Ihr Geschäft wird größer, und Sie haben eine Gruppe von Praktikanten eingestellt, die Ihnen helfen. Aber das Problem ist, dass Sie mit einem Blick auf das Haus wissen, wie viel es wert ist, und die Praktikanten haben keine Erfahrung und wissen nicht, wie sie es bewerten sollen.
Um deinen Praktikanten zu helfen (und vielleicht um dich selbst zu befreien, um in den Urlaub zu gehen), hast du beschlossen, eine kleine Software zu erstellen, die den Wert von Häusern in deiner Gegend anhand von Faktoren wie Größe, Grundstück und Kaufpreisen für ähnliche Häuser beurteilt.
Sie haben jede Immobilienverhandlung in der Stadt in den letzten drei Monaten aufgeschrieben, jede einzelne mit einer langen Reihe von Details wie Anzahl der Schlafzimmer, Größe des Hauses, Grundstück usw. Aber vor allem haben Sie den endgültigen Kaufpreis aufgeschrieben:
Das ist unsere Katzen-Training-Datenbank.
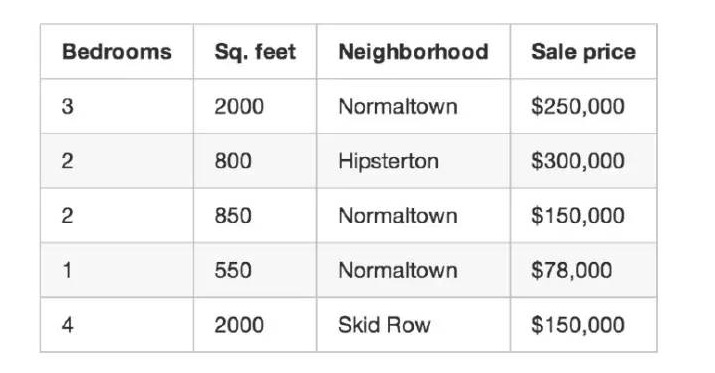
Wir werden diese Trainingsdaten nutzen, um ein Programm zu erstellen, mit dem wir den Wert der anderen Häuser in der Gegend schätzen können:

Das nennt man “supervised learning”. Du kennst bereits die Verkaufspreise für jedes Haus, das heißt, du kennst die Antwort auf die Frage und kannst die Logik der Lösung umkehren.
Um die Software zu schreiben, werden Sie die Trainingsdaten für jede Immobilie in Ihr Machine Learning-Algorithmus eingeben. Der Algorithmus versucht herauszufinden, welche Operationen verwendet werden sollen, um die Preissätze zu erhalten.
Es ist wie ein Arithmetik-Problem, in dem die Operatoren der Arithmetik gelöscht wurden:
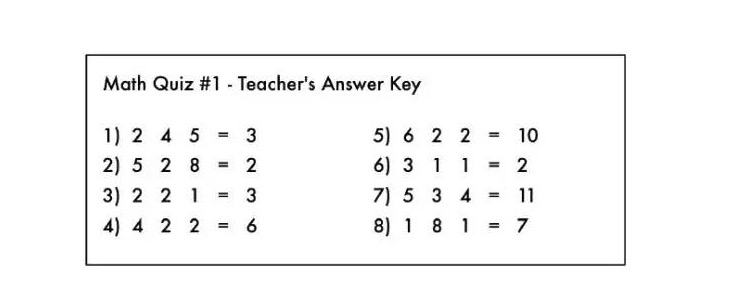
Oh mein Gott! Ein hinterlistiger Schüler hat die Arithmetikzeichen von der Antwort seines Lehrers gelöscht.
Wenn du diese Fragen siehst, kannst du verstehen, welche mathematischen Probleme in diesen Tests enthalten sind? Du weißt, was du mit den Ziffern auf der linken Seite der Berechnung machen solltest, um die Antwort auf die Rechte zu erhalten.
Im Supervised Learning lassen Sie den Computer die Beziehungen zwischen den Zahlen für Sie berechnen. Sobald Sie die mathematischen Methoden kennen, die für die Lösung dieser speziellen Probleme erforderlich sind, können Sie andere ähnliche Probleme lösen.
-
Unüberwachtes Lernen
Wenn Sie nicht wissen, wie viel jedes Haus kostet, können Sie eine tolle Idee entwickeln, auch wenn Sie nur die Größe und Lage des Hauses kennen. Das nennt man unsupervisiertes Lernen.
Selbst wenn Sie keine unbekannten Daten (z.B. Preise) vorhersagen möchten, können Sie mit maschinellem Lernen etwas Interessantes tun.
Es ist ein bisschen so, als würde man dir ein Blatt Papier geben, auf dem viele Zahlen stehen, und dir sagen: “Oh, ich weiß nicht, was diese Zahlen bedeuten, aber vielleicht kannst du daraus eine Regel oder eine Klassifizierung oder etwas anderes finden - viel Glück!”
Zunächst einmal können Sie mit einem Algorithmus automatisch verschiedene Segmente des Marktes aus den Daten ablösen. Vielleicht finden Sie, dass Käufer in der Nähe von Universitäten kleine Häuser mit mehreren Schlafzimmern bevorzugen, während Käufer in den Vororten größere Häuser mit drei Schlafzimmern bevorzugen.
Man kann auch etwas Cooles tun, indem man automatisch die Ausgrenzung der Immobilienpreise erkennt, die sich von den anderen Daten unterscheidet. Die Immobilien in den Ausgrenzungsgruppen sind vielleicht Hochhäuser, und man kann die besten Verkäufer in diesen Gebieten konzentrieren, weil sie die höchsten Provisionen erhalten.
Im weiteren Verlauf dieses Artikels werden wir uns hauptsächlich mit dem Thema Supervised Learning beschäftigen, aber das ist nicht so, weil unsupervised learning nicht sehr nützlich oder uninteressant ist. In der Tat wird unsupervised learning mit der Verbesserung der Algorithmen immer wichtiger, da die Daten nicht mit den richtigen Antworten verknüpft werden müssen.
Es gibt viele andere Arten von Algorithmen für das maschinelle Lernen.
Das ist cool, aber kann die Bewertung von Immobilien wirklich als eine Art Lehrmethode angesehen werden?
Als Teil eines Menschen kann Ihr Gehirn die meisten Situationen bewältigen und lernen, wie man mit ihnen umgeht, ohne dass es irgendwelche eindeutigen Anweisungen gibt. Wenn Sie lange Zeit als Immobilienmakler gearbeitet haben, haben Sie ein instinktives Gefühl für die richtige Preisgestaltung einer Immobilie, wie sie am besten vermarktet werden kann und welche Kunden interessiert sind usw. Das Ziel der Forschung an starker KI ist es, diese Fähigkeit mit Computern zu replizieren.
Aber die aktuellen Algorithmen für maschinelles Lernen sind noch nicht so gut, dass sie sich nur auf sehr spezifische, begrenzte Probleme konzentrieren können. Vielleicht ist es in diesem Fall eine bessere Definition für eine Maschinelle Lernmaschine, eine Gleichung zu finden, um eine bestimmte Frage auf der Grundlage von wenigen Beispieldaten zu lösen.
Unglücklicherweise ist die Bearbeitung von Bearbeitungsmaschinen, die eine Gleichung für eine bestimmte Aufgabe auf der Grundlage von wenigen Beispieldaten finden, zu schlecht für den Namen Bearbeitung.
Natürlich, wenn Sie diesen Artikel in 50 Jahren lesen, dann haben wir bereits starke Algorithmen für künstliche Intelligenz entwickelt, und dieser Artikel sieht aus wie ein altes Artefakt.
Lasst uns Code schreiben!
Wie werden Sie das Verfahren für die Bewertung der Immobilienpreise im vorherigen Beispiel beschreiben? Denken Sie darüber nach, bevor Sie nach unten schauen.
Wenn Sie nichts über maschinelles Lernen wissen, versuchen Sie wahrscheinlich, einige Grundregeln zu schreiben, um die Preise zu bewerten, wie:
def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood): price = 0 # In my area, the average house costs $200 per sqft price_per_sqft = 200 if neighborhood == "hipsterton": # but some areas cost a bit more price_per_sqft = 400 elif neighborhood == "skid row": # and some areas cost less price_per_sqft = 100 # start with a base price estimate based on how big the place is price = price_per_sqft * sqft # now adjust our estimate based on the number of bedrooms if num_of_bedrooms == 0: # Studio apartments are cheap price = price — 20000 else: # places with more bedrooms are usually # more valuable price = price + (num_of_bedrooms * 1000) return priceWenn Sie sich ein paar Stunden lang so beschäftigen, werden Sie vielleicht etwas erreichen, aber Ihr Programm wird nie perfekt sein, und es ist schwierig, es zu pflegen, wenn sich die Preise ändern.
Wenn der Computer herausfinden könnte, wie er diese Funktionen umsetzen kann, wäre das nicht viel besser? Wen interessiert es, was die Funktion genau macht, solange sie die richtigen Hauspreise liefert?
def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood): price = <computer, plz do some math for me> return priceEin Blickwinkel, um das zu betrachten, ist, dass der Hauspreis wie eine Tüte leckeren Salz ist, dessen Bestandteile die Anzahl der Schlafzimmer, die Fläche und der Boden sind. Wenn man herausfindet, wie sehr jeder Bestandteil den Endpreis beeinflusst, kann man vielleicht die verschiedenen Bestandteile in einem bestimmten Verhältnis zum Endpreis mischen.
Das reduziert deine ursprüngliche Programmierung (mit den verrückten If-Also-Sätze) auf etwas wie:
def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood): price = 0 # a little pinch of this price += num_of_bedrooms * .841231951398213 # and a big pinch of that price += sqft * 1231.1231231 # maybe a handful of this price += neighborhood * 2.3242341421 # and finally, just a little extra salt for good measure price += 201.23432095 return priceBeachten Sie die magischen Zahlen, die in Großbuchstaben geschrieben sind: 841231951398213, 1231.1231231, 2.3242341421 und 201.23432095. Sie werden als Gewichte bezeichnet. Wenn wir das perfekte Gewicht für jedes Haus finden könnten, könnten wir alle Hauspreise vorhersagen!
Eine gute Methode, um das optimale Gewicht zu ermitteln, ist die folgende:
Schritt 1:
Zuerst wird jedes Gewicht auf 1.0 gesetzt:
def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood): price = 0 # a little pinch of this price += num_of_bedrooms * 1.0 # and a big pinch of that price += sqft * 1.0 # maybe a handful of this price += neighborhood * 1.0 # and finally, just a little extra salt for good measure price += 1.0 return priceSchritt zwei:
Bringen Sie jede Immobilie in Ihre Funktion und prüfen Sie, wie weit die Schätzung vom richtigen Preis abweicht:
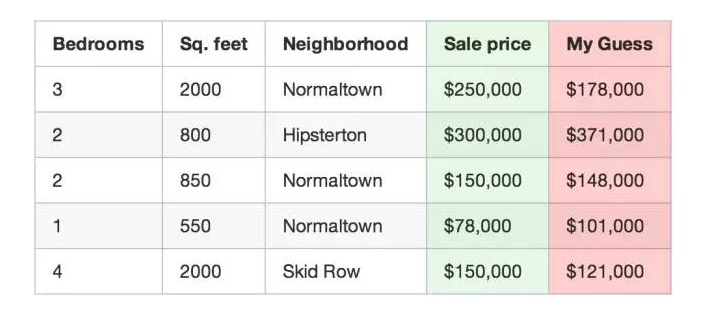
Verwenden Sie Ihr Programm, um die Preise Ihrer Häuser vorherzusagen.
Zum Beispiel: Die erste Immobilie in der Tabelle hat einen tatsächlichen Kaufpreis von 250.000 US-Dollar, Ihre Funktion schätzt 178.000 US-Dollar und Sie haben 72.000 US-Dollar für diese Immobilie.
Dann summieren Sie die Schätzungen für jedes Objekt in Ihrem Datensatz mit der Abweichung von der Quadratwert. Angenommen, es gibt 500 Immobilientransaktionen in Ihrem Datensatz, dann summieren Sie die Schätzungen mit der Abweichung von der Quadratwertwert summiert $86.123.373. Das zeigt, wie richtig Ihre Funktion jetzt ist.
Nun dividieren wir die Summe durch 500 und erhalten die Schätzungen für jede Immobilie, die vom Durchschnitt abweichen. Nennen wir diesen Durchschnittsfehler als die Kosten Ihrer Funktion.
Wenn Sie das Gewicht so anpassen, dass der Preis 0 ist, dann ist die Funktion perfekt. Das bedeutet, dass Ihr Programm jede Immobilientransaktion genau so beurteilt, wie es die eingegebenen Daten benötigt. Und das ist unser Ziel: Versuchen Sie, die verschiedenen Gewichte so zu verwenden, dass der Preis so niedrig wie möglich ist.
Schritt 3:
Wiederholen Sie Schritt 2 immer wieder und versuchen Sie alle möglichen Kombinationen von Gewichten. Welche Kombination die Kosten am nächsten an 0 bringt, ist es, was Sie verwenden möchten, und sobald Sie diese Kombination gefunden haben, ist das Problem gelöst!
Die Gedanken stören die Zeit
Es ist so einfach, nicht wahr? Denken Sie daran, was Sie gerade getan haben. Sie haben einige Daten, die Sie in drei einfache Schritte eingeben, und am Ende haben Sie eine Funktion, mit der Sie die Häuser in Ihrer Region bewerten können. Aber die folgenden Fakten könnten Sie verwirren:
-
- In den letzten 40 Jahren hat die Forschung in vielen Bereichen (z.B. Linguistik/Übersetzungswissenschaft) gezeigt, dass diese allgemein verbreiteten, dynamischen Lernalgorithmen (wie “Ich habe die Wörter erfunden”) die Methoden übertreffen, die die Regeln von echten Menschen benötigen. Die Methoden des Maschinellen Lernens schlagen letztendlich die menschlichen Experten.
-
- Die Funktion, die du am Ende schreibst, ist wirklich schräg, denn sie weiß nicht einmal, was die Fläche des Kamines und die Anzahl der Schlafzimmer sind. Sie weiß nur, wie man die Zahlen bewegt, um die richtige Antwort zu erhalten.
-
- Es ist sehr wahrscheinlich, dass Sie nicht wissen, warum eine bestimmte Gruppe von Gewichten funktioniert. Also schreiben Sie einfach eine Funktion, die Sie nicht verstehen, aber die Sie beweisen können.
-
- Stellen Sie sich vor, Sie hätten ein Programm, das keine Parameter wie die Platinenfläche und die Platinen-Schlafzimmer-Zahlen enthält, sondern eine Reihe von Zahlen. Angenommen, jede Zahl repräsentiert ein Pixel in einem Bild, das von Ihrer Dachkamera aufgenommen wurde, und die prognostizierte Ausgabe wird nicht als Platinenpreis-Zahlen, sondern als Platinenlenkrad-Drehzahl-Zahlen bezeichnet.
Das ist doch verrückt, oder?
Was passiert, wenn Sie in Schritt 3 jede Zahl ausprobieren?
Nun, natürlich können Sie nicht alle möglichen Gewichte ausprobieren, um die beste Kombination zu finden. Um dies zu vermeiden, haben Mathematiker viele schlaue Wege gefunden, um schnell und ohne zu viel zu versuchen, gute Gewichte zu finden. Hier ist einer von ihnen: Zuerst schreiben wir eine einfache Gleichung für diese beiden Schritte:
Das ist deine Kostenfunktion.
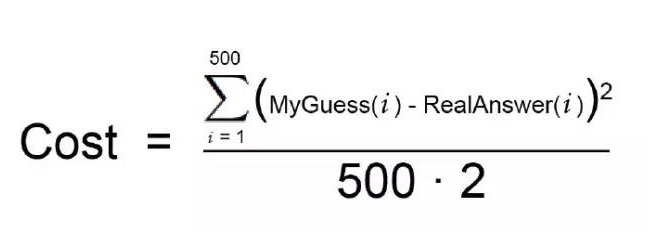
Lassen Sie uns nun die gleichen mathematischen Ausdrücke mit Hilfe von maschinellem Lernen (die Sie jetzt ignorieren können) umschreiben:
θ ist der aktuelle Gewichtswert. J ((θ) ist der Preis, der dem aktuellen Gewichtswert entspricht.
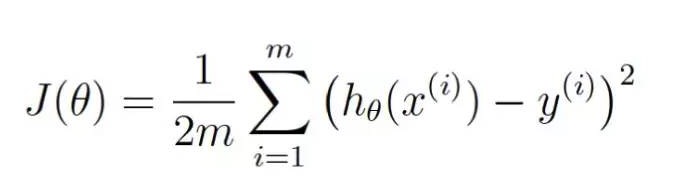
Diese Gleichung gibt die Größe an, wie weit unsere Bewertungsmethode von der aktuellen Gewichtung abweicht.
Wenn wir alle möglichen Gewichte für die Anzahl und Fläche der Schlafzimmer in einer Grafik darstellen, erhalten wir eine Grafik, die wie folgt aussieht:
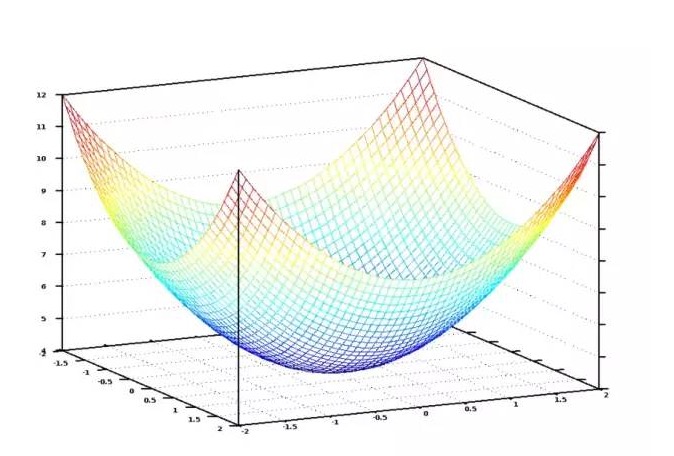
Die Grafik der Kostenfunktion zeigt eine Schale. Die Vertikale zeigt die Kosten.
Der blaue Minimum ist der Ort, an dem die Kosten am niedrigsten sind, also der Ort, an dem unser Programm am wenigsten abweicht. Der höchste Punkt bedeutet, dass wir am weitesten abweichen. Also, wenn wir eine Reihe von Gewichten finden, die uns zu dem Minimum in der Grafik führen, haben wir die Antwort!
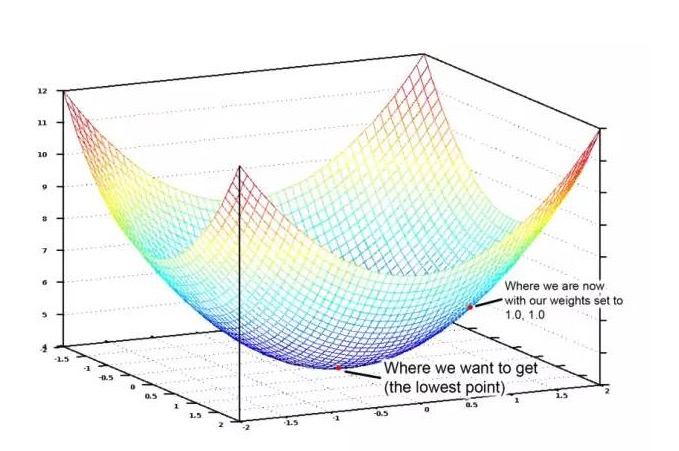
Daher müssen wir nur die Gewichte so anpassen, dass wir den Abhang zum Tiefpunkt des Diagramms hinuntersteigen können. Wenn wir die Gewichte so leicht anpassen, dass wir immer auf dem Weg zum Tiefpunkt sind, dann müssen wir nicht allzu viele Gewichte versuchen, um dort zu sein.
Wenn Sie sich noch ein bisschen an die Berechnung erinnern, dann erinnern Sie sich vielleicht, dass wenn Sie eine Funktion anfragen, die Ihnen sagt, wie weit die Funktion an einem beliebigen Punkt geneigt ist. In anderen Worten, für einen bestimmten Punkt auf dem Diagramm, sagt es uns, dass dieser Weg eine Steigung ist.
Wenn wir also die Kostenfunktion für jede Gewichtung abwenden, können wir diese von jeder Gewichtung abziehen. Das bringt uns näher an den Boden. Wenn wir so weitermachen, werden wir schließlich den Boden erreichen und den optimalen Wert der Gewichtung erhalten.
Diese Methode, um die optimale Gewichtung zu finden, wird als “Quantitative Gradient-Descent” bezeichnet, und hier ist eine Übersicht darüber. Wenn Sie die Details verstehen möchten, haben Sie keine Angst und gehen Sie weiter in die Tiefe.
Wenn Sie die Bibliothek der Algorithmen des maschinellen Lernens verwenden, um die praktischen Probleme zu lösen, ist all das für Sie bereit. Aber es ist immer hilfreich, einige Details zu verstehen.
Was hast du noch übersehen?
Die drei-Stufen-Algorithmus, den ich oben beschrieben habe, wird als Multilinear-Rückgang bezeichnet. Ihre Schätzungsgleichung besteht darin, eine Linie zu finden, die alle Datenpunkte der Immobilienpreise zusammenfasst. Dann schätzen Sie mit dieser Gleichung den Preis für ein Haus, das Sie noch nie gesehen haben, anhand der möglichen Position des Immobilienpreises auf Ihrer Linie.
Aber die Methode, die ich Ihnen gezeigt habe, könnte in einfachen Fällen funktionieren, und sie wird nicht in allen Fällen funktionieren.
Glücklicherweise gibt es jedoch viele Möglichkeiten, um mit dieser Situation umzugehen. Für nichtlineare Daten können viele andere Arten von Machine-Learning-Algorithmen eingesetzt werden (z. B. Neural Networks oder Kern-Vektor-Maschinen). Es gibt auch viele Möglichkeiten, die lineare Regression flexibler zu nutzen, um mit komplexeren Linien zu passen.
Außerdem habe ich das Konzept der Anpassung übersehen. Es ist sehr leicht, auf ein solches Set von Gewichten zu stoßen, die die Preise für die Häuser in Ihrem ursprünglichen Datensatz perfekt vorhersagen, aber nicht für neue Häuser außerhalb des ursprünglichen Datensatzes.
Mit anderen Worten, die grundlegenden Konzepte sind sehr einfach, und es erfordert einige Fähigkeiten und Erfahrungen, um mit Machine Learning nützliche Ergebnisse zu erzielen. Aber das ist etwas, das jeder Entwickler lernen kann.
-
-
Ist Maschinelles Lernen grenzenlos?
Sobald man beginnt zu verstehen, wie einfach es ist, maschinelle Lerntechniken zu verwenden, um anscheinend schwierige Probleme zu lösen (wie zum Beispiel die Handschrifterkennung), hat man das Gefühl, dass man mit maschinellen Lerntechniken jedes Problem lösen kann, wenn man genug Daten hat.
Aber es ist wichtig zu bedenken, dass Machine Learning nur für Probleme verwendet werden kann, die mit den Daten, die Sie besitzen, tatsächlich gelöst werden können.
Wenn Sie beispielsweise ein Modell erstellen, um die Immobilienpreise anhand der Anzahl der Pflanzen in jedem Haus zu prognostizieren, wird es niemals erfolgreich sein. Es gibt keine Beziehung zwischen der Anzahl der Pflanzen in einem Haus und dem Immobilienpreis.
Sie können nur die Beziehungen modellieren, die tatsächlich existieren.
-
Wie kann man maschinelles Lernen in die Tiefe bringen?
Ich denke, das größte Problem mit aktuellem maschinellem Lernen ist, dass es hauptsächlich in akademischen und kommerziellen Forschungsorganisationen aktiv ist. Es gibt nicht viele einfache und verständliche Lernmaterialien für Leute, die außerhalb des Kreises sind und ein allgemeines Verständnis haben möchten, anstatt Experten zu sein. Aber das verbessert sich jeden Tag.
Prof. Andrew Ng: Die kostenlosen Kurse für maschinelles Lernen auf Coursera sind sehr gut. Ich empfehle es dringend. Jeder, der einen Abschluss in Informatik hat und sich ein bisschen Mathematik merkt, sollte es verstehen.
Außerdem können Sie SciKit-Learn herunterladen und installieren, um mit ihm Tausende von Machine-Learning-Algorithmen auszuprobieren. Es ist ein Python-Framework, das für alle Standard-Algorithmen eine Black-Box-Version enthält.
Übertragung von Python Entwickler