
Eine Tour durch die Algorithmen des maschinellen Lernens
Nachdem wir verstanden haben, welche Probleme wir lösen müssen (http://machinelearningmastery.com/practical-machine-learning-problems/), können wir darüber nachdenken, welche Daten wir sammeln müssen und welche Algorithmen wir verwenden können.
Es gibt viele Algorithmen im Bereich des maschinellen Lernens, und es gibt viele Erweiterungen für jeden Algorithmus, so dass es schwierig ist, für eine bestimmte Aufgabe zu bestimmen, welcher der richtige Algorithmus ist. In diesem Artikel möchte ich Ihnen zwei Möglichkeiten geben, die Algorithmen, die in der Realität auftreten, zu reduzieren.
-
Wie man lernt
Algorithmen werden in verschiedene Kategorien eingeteilt, je nachdem, wie sie mit Erfahrungen, Umgebungen oder irgendwelchen Daten, die wir als Eingaben bezeichnen, umgehen. In Lehrbüchern über maschinelles Lernen und künstliche Intelligenz wird in der Regel zunächst die Art und Weise betrachtet, wie Algorithmen lernen können.
Hier werden nur einige der wichtigsten Lernstile oder Lernmodelle diskutiert, und es gibt einige grundlegende Beispiele. Diese Art der Klassifizierung oder Organisation ist gut, weil sie Sie dazu zwingt, über die Rolle der Eingabedaten und die Vorbereitung des Modells nachzudenken und dann einen Algorithmus zu wählen, der am besten zu Ihrem Problem passt, um die besten Ergebnisse zu erzielen.
Überwachung des Lernens: Die Eingabedaten werden als Trainingsdaten bezeichnet und mit bekannten Ergebnissen oder Kennzeichnungen versehen. Zum Beispiel wird gesagt, ob eine E-Mail Spam ist oder ob der Aktienpreis über einen bestimmten Zeitraum liegt. Das Modell macht Vorhersagen, die korrigiert werden, wenn sie falsch sind, und dieser Prozess wird so lange fortgesetzt, bis es einen bestimmten Standard für die richtigen Trainingsdaten erreicht.
Unüberwachtes Lernen: Die Eingaben werden nicht markiert und es gibt keine ermittelten Ergebnisse. Das Modell führt die Struktur und die Werte der Daten an. Beispiele für Probleme umfassen Assoziationsregellernen und Clustering-Probleme.
Halbüberwachtes Lernen: Die Eingabedaten sind eine Mischung aus markierten und unmarkierten Daten, es gibt einige Vorhersageprobleme, aber die Modelle müssen auch die Struktur und Zusammensetzung der Daten lernen. Beispiele für Probleme umfassen Klassifizierungs- und Regressionsprobleme, die Algorithmusbeispiele sind im Wesentlichen eine Erweiterung der unüberwachten Lernalgorithmen.
Verstärktes Lernen: Die Eingabe von Daten kann das Modell stimulieren und es dazu bringen, zu reagieren. Die Feedback wird nicht nur aus dem Lernprozess des überwachten Lernens, sondern auch aus der Belohnung oder Bestrafung in der Umgebung gewonnen.Bei der Integration von Data Simulation in Geschäftsentscheidungen werden meistens Methoden des überwachten Lernens und des unüberwachten Lernens eingesetzt. Ein nächstes aktuelles Thema ist halbüberwachtes Lernen, zum Beispiel Bildklassifizierungsprobleme, bei denen es eine große Datenbank gibt, aber nur ein kleiner Teil der Bilder markiert ist.
-
Algorithmische Ähnlichkeit
Algorithmen werden grundsätzlich funktional oder formal klassifiziert. Zum Beispiel Algorithmen, die auf Bäumen basieren, oder Algorithmen, die auf neuronalen Netzwerken basieren. Dies ist eine nützliche Klassifizierung, die jedoch nicht perfekt ist.
In diesem Abschnitt beschreibe ich die Algorithmen, die ich für die intuitivste Methode halte. Ich habe keine Liste der Algorithmen oder Klassifizierungsmethoden, aber ich denke, dass es hilfreich ist, den Leser eine Übersicht zu geben.
-
Regression
Regression beschäftigt sich mit der Beziehung zwischen Variablen. Sie verwendet statistische Methoden. Beispiele für Algorithmen sind:
Ordinary Least Squares
Logistic Regression
Stepwise Regression
Multivariate Adaptive Regression Splines (MARS)
Locally Estimated Scatterplot Smoothing (LOESS) -
Instance-based Methods
Instanzbasiertes Lernen simuliert eine Entscheidungsfrage, wobei die verwendeten Beispiele oder Beispiele für das Modell von großer Bedeutung sind. Diese Methode erstellt eine Datenbank mit vorhandenen Daten, fügt neue Daten hinzu und verwendet dann eine Methode zur Ähnlichkeitsmessung, um eine optimale Übereinstimmung in der Datenbank zu finden und eine Vorhersage zu treffen. Aus diesem Grund wird diese Methode auch als Gewinner-für-König-Methode und als Speicherbasierte Methode bezeichnet.
k-Nearest Neighbour (kNN)
Learning Vector Quantization (LVQ)
Self-Organizing Map (SOM) -
Regularization Methods
Es ist eine Erweiterung anderer Methoden (in der Regel der Regressionsmethode), und diese Erweiterung ist günstiger für die einfachen Modelle und ist besser in der Induktion. Ich liste sie hier auf, weil sie beliebt und stark ist.
Ridge Regression
Least Absolute Shrinkage and Selection Operator (LASSO)
Elastic Net -
Decision Tree Learning
Entscheidungsbaum-Methoden (Decision tree methods) erstellen ein Modell für die Entscheidungsfindung anhand der tatsächlichen Werte in den Daten. Entscheidungsbäume dienen zur Lösung von Inklusions- und Regressionsproblemen.
Classification and Regression Tree (CART)
Iterative Dichotomiser 3 (ID3)
C4.5
Chi-squared Automatic Interaction Detection (CHAID)
Decision Stump
Random Forest
Multivariate Adaptive Regression Splines (MARS)
Gradient Boosting Machines (GBM) -
Bayesian
Bayesische Methode ist eine Methode, die Bayes' Theorie anwendet, um Klassifizierungs- und Regressionsprobleme zu lösen.
Naive Bayes
Averaged One-Dependence Estimators (AODE)
Bayesian Belief Network (BBN) -
Kernel Methods
Die Kernel-Methode ist bekannt für die Unterstützung von Vektormaschinen. Diese Methode erleichtert die Modellierung einiger Klassifizierungs- und Regressionsprobleme, indem sie die Eingabedaten in eine höhere Dimension abbildet.
Support Vector Machines (SVM)
Radial Basis Function (RBF)
Linear Discriminate Analysis (LDA) -
Clustering Methods
Clustering ist eine Methode, mit der man Probleme und Methoden zusammenfasst. Clustering-Methoden werden in der Regel durch Modellierungsmethoden klassifiziert. Alle Clustering-Methoden sind in einer einheitlichen Datenstruktur organisiert, so dass die Daten in jeder Gruppe möglichst viele Gemeinsamkeiten haben.
K-Means
Expectation Maximisation (EM) -
Association Rule Learning
Association rule learning ist eine Methode, um Regeln zwischen Daten zu extrahieren, durch die Verbindungen zwischen riesigen Datenmengen in mehrdimensionalen Räumen gefunden werden können, und diese wichtigen Verbindungen können von Organisationen verwendet werden.
Apriori algorithm
Eclat algorithm -
Artificial Neural Networks
Artificial Neural Networks sind von der Struktur und Funktion von biologischen Neuronen inspiriert. Sie gehören zur Kategorie der Modellmatching und werden häufig für Regressions- und Klassifikationsprobleme verwendet, aber es gibt Hunderte von Algorithmen und Varianten.
Perceptron
Back-Propagation
Hopfield Network
Self-Organizing Map (SOM)
Learning Vector Quantization (LVQ) -
Deep Learning
Die Deep Learning-Methode ist eine moderne Erneuerung von künstlichen neuronalen Netzwerken. Sie hat eine viel komplexere Netzwerkkonstruktion als herkömmliche neuronale Netzwerke. Viele Methoden betreffen halbüberwachtes Lernen, bei dem es große Daten gibt, aber nur wenige markierte Daten.
Restricted Boltzmann Machine (RBM)
Deep Belief Networks (DBN)
Convolutional Network
Stacked Auto-encoders -
Dimensionality Reduction
Dimensionalitätsreduktion, wie die Clustering-Methode, strebt nach und nutzt die einheitliche Struktur in den Daten, aber sie verwendet weniger Informationen, um die Daten zu resümieren und zu beschreiben. Dies ist nützlich, um die Daten zu visualisieren oder zu vereinfachen.
Principal Component Analysis (PCA)
Partial Least Squares Regression (PLS)
Sammon Mapping
Multidimensional Scaling (MDS)
Projection Pursuit -
Ensemble Methods
Ensemble-Methoden bestehen aus vielen kleinen Modellen, die unabhängig voneinander trainiert werden, unabhängige Schlussfolgerungen ziehen und schließlich eine Gesamtvorhersage bilden. Viele Studien konzentrieren sich darauf, welche Modelle verwendet werden und wie diese Modelle zusammengestellt werden.
Boosting
Bootstrapped Aggregation (Bagging)
AdaBoost
Stacked Generalization (blending)
Gradient Boosting Machines (GBM)
Random Forest
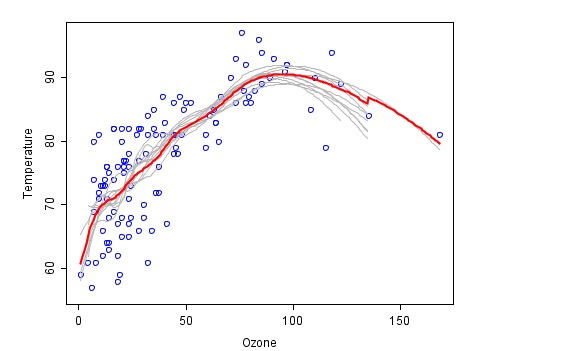
Dies ist ein Beispiel für eine Kombinationsmethode, bei der jeder Feuerwehrgesetz in Grau dargestellt wird, während die endgültige Prognose der letzten Kombination in Rot dargestellt wird.
-
Weitere Ressourcen
Diese Reise durch die Algorithmen des maschinellen Lernens soll Ihnen einen Überblick darüber geben, was Algorithmen sind und welche Werkzeuge für diese Algorithmen verwendet werden.
Hier sind einige weitere Ressourcen, die Sie sich nicht zu sehr vorstellen sollten, denn je mehr Sie über Algorithmen erfahren, desto besser wird es für Sie, aber es ist auch hilfreich, einige von ihnen zu verstehen.
- List of Machine Learning Algorithms: Das ist eine Ressource auf der Wiki, die zwar vollständig ist, aber ich finde, dass die Kategorisierung nicht sehr gut ist.
- Machine Learning Algorithms Category: Das ist auch eine Ressource auf der Wiki, die etwas besser ist als die obige, alphabetisch sortiert.
- CRAN Task View: Machine Learning & Statistical Learning: Die R-Sprach-Erweiterung für Machine-Learning-Algorithmen, um besser zu verstehen, was andere Leute benutzen.
- Top 10 Algorithms in Data Mining: Dies ist ein veröffentlichter Artikel, jetzt ein Buch, der die beliebtesten Algorithmen für die Datamining enthält. Eine andere grundlegende Algorithmenliste, die hier nur wenige Algorithmen auflistet, hilft Ihnen beim Lernen.
Übertragung von Berle Kolumne/Dafei Python Entwickler
- 1