

Der Artikel befasst sich mit den Hochfrequenzhandelsstrategien digitaler Währungen, einschließlich der Gewinnquellen (hauptsächlich aus Marktschwankungen und Rückerstattungen von Börsengebühren), den Problemen der Auftragserteilung und Positionskontrolle sowie der Methode zur Modellierung des Handelsvolumens mithilfe der Pareto-Verteilung. Darüber hinaus wurden die von Binance bereitgestellten Transaktions- und optimalen Auftragsdaten für Backtests verwendet. Weitere Aspekte der Hochfrequenzhandelsstrategien sollen in nachfolgenden Artikeln ausführlich erörtert werden.
Ich habe bereits zwei Artikel über den Hochfrequenzhandel mit digitalen Währungen geschrieben. Eine detaillierte Einführung in Hochfrequenz-Strategien für digitale Währungen, Verdienen Sie 80 Mal in 5 Tagen, die Macht der Hochfrequenzstrategie. Es kann jedoch lediglich als Erfahrungsaustausch und allgemeines Gespräch betrachtet werden. Dieses Mal plane ich, eine Reihe von Artikeln zu schreiben, um die Ideen des Hochfrequenzhandels von Anfang an vorzustellen. Ich hoffe, so präzise und klar wie möglich zu sein. Aufgrund meines begrenzten Niveaus und meines tiefgreifenden Verständnisses von Hochfrequenz Handel, dieser Artikel ist nur ein Ausgangspunkt. Ich hoffe, die Experten können mich korrigieren.
Hochfrequente Gewinnquellen
Wie bereits in früheren Artikeln erwähnt, eignen sich Hochfrequenzstrategien besonders für Märkte mit extrem volatilen Höhen und Tiefen. Untersuchen Sie die Preisänderungen eines Handelsprodukts in einem kurzen Zeitraum, einschließlich allgemeiner Trends und Schwankungen. Wenn wir die Veränderungen der Trends genau vorhersagen können, können wir sicherlich Geld verdienen, aber das ist auch am schwierigsten. Dieser Artikel stellt hauptsächlich Hochfrequenz-Maker-Strategien vor und wird sich nicht mit diesem Thema befassen. Wenn in einem volatilen Markt die Strategie der Platzierung von Auf- und Ab-Aufträgen häufig genug ausgeführt wird und die Gewinnspanne groß genug ist, kann sie die möglichen Verluste, die durch den Trend entstehen, decken, so dass Sie einen Gewinn erzielen können, ohne den Markt vorhersagen zu müssen. Derzeit erhalten alle Maker-Transaktionen an Börsen Rabatte auf die Transaktionsgebühren, was ebenfalls ein Bestandteil des Gewinns ist. Je intensiver der Wettbewerb, desto höher sollte der Anteil der Rabatte sein.
Zu lösendes Problem
-
Die Strategie platziert gleichzeitig Kauf- und Verkaufsaufträge. Die erste Frage ist, wo die Aufträge platziert werden sollen. Je näher die Order am Markt ist, desto höher ist die Wahrscheinlichkeit einer Transaktion. In einem volatilen Markt kann der momentane Transaktionspreis jedoch weit vom Markt entfernt sein. Wenn die Order zu nah am Markt platziert wird, können Sie nicht genug Gewinn machen. Die Wahrscheinlichkeit der Ausführung zu weit im Voraus erteilter Aufträge ist gering. Dies ist ein Problem, das optimiert werden muss.
-
Kontrollieren Sie Ihre Position. Um die Risiken zu kontrollieren, können im Rahmen der Strategie nicht über einen längeren Zeitraum zu viele Positionen aufgebaut werden. Dies kann durch die Kontrolle der Bestelldistanz, der Bestellmenge, des Gesamtpositionslimits usw. gelöst werden.
Um die oben genannten Ziele zu erreichen, ist es notwendig, die Transaktionswahrscheinlichkeit, den Transaktionsgewinn, die Markteinschätzung und andere Aspekte zu modellieren und zu schätzen. Es gibt viele Artikel und Aufsätze in diesem Bereich, die mit Schlagwörtern wie Hochfrequenzhandel gefunden werden können. , Auftragsbuch usw. Im Internet gibt es zahlreiche Empfehlungen, auf die ich hier aber nicht näher eingehen möchte. Darüber hinaus ist es am besten, ein zuverlässiges und schnelles Backtesting-System einzurichten. Obwohl Hochfrequenzstrategien durch realen Handel leicht auf ihre Wirksamkeit überprüft werden können, kann Backtesting dennoch weitere Ideen liefern und die Kosten für Versuch und Irrtum senken.
Erforderliche Daten
Binance stellt Transaktionsdaten und Best-Order-Daten bereitherunterladen,Deep Data muss mithilfe der API in der Whitelist heruntergeladen werden, oder Sie können sie selbst erfassen. Für Backtesting-Zwecke können Sie einfach die gesammelten Transaktionsdaten verwenden. Dieser Artikel verwendet die Daten von HOOKUSDT-aggTrades-2023-01-27 als Beispiel.
python
from datetime import date,datetime
import time
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
Die Transaktionsspalten lauten wie folgt:
- agg_trade_id: die ID der aggregierten Transaktionsreihenfolge,
- Preis: Transaktionspreis
- Menge: Die Anzahl der Transaktionen
- first_trade_id: Es können mehrere Transaktionen gleichzeitig in der Sammlung vorhanden sein, es wird nur ein Datum gezählt, dies ist die ID der ersten Transaktion
- last_trade_id: die ID der letzten Transaktion
- transact_time: Transaktionszeit
- is_buyer_maker: Transaktionsrichtung, True bedeutet, dass die Kauforder vom Maker und die Verkaufsorder vom Taker gehandelt wird
Es ist ersichtlich, dass an diesem Tag 660.000 Transaktionsdaten vorlagen und dass die Transaktionen sehr aktiv waren. Die CSV-Datei wird im Kommentarbereich angehängt.
python
trades = pd.read_csv('COMPUSDT-aggTrades-2023-07-02.csv')
trades
664475 rows × 7 columns
| agg_trade_id | price | quantity | first_trade_id | last_trade_id | transact_time | is_buyer_maker |
|---|---|---|---|---|---|---|
| 120719552 | 52.42 | 22.087 | 207862988 | 207862990 | 1688256004603 | False |
| 120719553 | 52.41 | 29.314 | 207862991 | 207863002 | 1688256004623 | True |
| 120719554 | 52.42 | 0.945 | 207863003 | 207863003 | 1688256004678 | False |
| 120719555 | 52.41 | 13.534 | 207863004 | 207863006 | 1688256004680 | True |
| ... | ... | ... | ... | ... | ... | ... |
| 121384024 | 68.29 | 10.065 | 210364899 | 210364905 | 1688342399863 | False |
| 121384025 | 68.30 | 7.078 | 210364906 | 210364908 | 1688342399948 | False |
| 121384026 | 68.29 | 7.622 | 210364909 | 210364911 | 1688342399979 | True |
Modellierung einzelner Transaktionsvolumina
Verarbeiten Sie zunächst die Daten und unterteilen Sie die ursprünglichen Trades in aktive Kaufauftrags-Transaktionsgruppen und aktive Verkaufsauftrags-Transaktionsgruppen. Darüber hinaus sind die ursprünglichen aggregierten Transaktionsdaten ein Datenelement zur gleichen Zeit, zum gleichen Preis und in die gleiche Richtung. Es kann eine aktive Kauforder von 100 geben. Wenn sie in mehrere Transaktionen mit unterschiedlichen Preisen aufgeteilt wird, wie Es werden zwei Daten wie 60 und 40 generiert, die sich auf die Schätzung des Kaufauftragsvolumens auswirken. Daher ist eine erneute Aggregation basierend auf der Transaktionszeit erforderlich. Nach der Aggregation reduzierte sich die Datenmenge um 140.000 Datensätze.
python
trades['date'] = pd.to_datetime(trades['transact_time'], unit='ms')
trades.index = trades['date']
buy_trades = trades[trades['is_buyer_maker']==False].copy()
sell_trades = trades[trades['is_buyer_maker']==True].copy()
buy_trades = buy_trades.groupby('transact_time').agg({
'agg_trade_id': 'last',
'price': 'last',
'quantity': 'sum',
'first_trade_id': 'first',
'last_trade_id': 'last',
'is_buyer_maker': 'last',
'date': 'last',
'transact_time':'last'
})
sell_trades = sell_trades.groupby('transact_time').agg({
'agg_trade_id': 'last',
'price': 'last',
'quantity': 'sum',
'first_trade_id': 'first',
'last_trade_id': 'last',
'is_buyer_maker': 'last',
'date': 'last',
'transact_time':'last'
})
buy_trades['interval']=buy_trades['transact_time'] - buy_trades['transact_time'].shift()
sell_trades['interval']=sell_trades['transact_time'] - sell_trades['transact_time'].shift()
python
print(trades.shape[0] - (buy_trades.shape[0]+sell_trades.shape[0]))
146181
Nehmen wir Kaufaufträge als Beispiel und zeichnen Sie zunächst ein Histogramm. Sie können sehen, dass der Long-Tail-Effekt sehr offensichtlich ist. Die meisten Daten konzentrieren sich ganz links, aber es gibt auch eine kleine Anzahl großer Transaktionen, die am Ende verteilt sind. .
python
buy_trades['quantity'].plot.hist(bins=200,figsize=(10, 5));
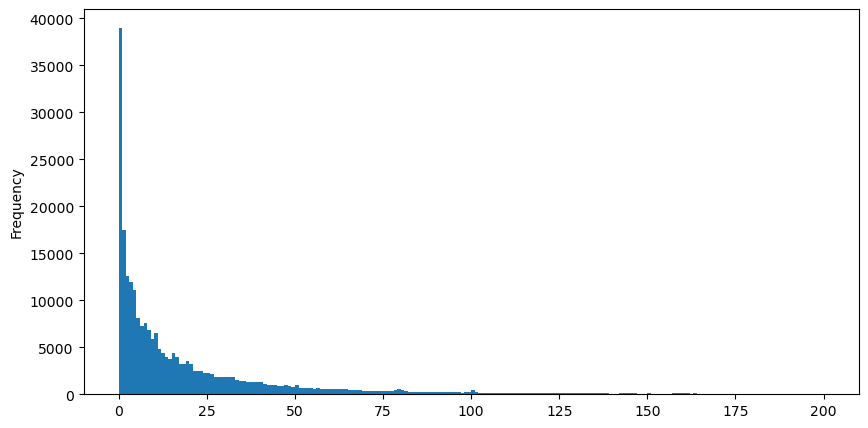
Um die Beobachtung zu vereinfachen, schneiden wir den Schwanz ab und beobachten. Wir können sehen, dass die Häufigkeit des Auftretens umso geringer ist und der Abwärtstrend umso schneller ist, je größer das Handelsvolumen ist.
python
buy_trades['quantity'][buy_trades['quantity']<200].plot.hist(bins=200,figsize=(10, 5));
Es gibt zahlreiche Studien zur Verteilung der Zufriedenheit mit der Lautstärke. Ihre Potenzgesetzverteilung wird auch Pareto-Verteilung genannt und ist eine gängige Form der Wahrscheinlichkeitsverteilung in der statistischen Physik und den Sozialwissenschaften. Bei einer Potenzgesetzverteilung ist die Wahrscheinlichkeit eines Ereignisses einer bestimmten Größe (oder Häufigkeit) proportional zu einem negativen Exponenten der Größe dieses Ereignisses. Das Hauptmerkmal dieser Verteilungsform besteht darin, dass große Ereignisse (d. h. solche, die weit vom Mittelwert abweichen) häufiger auftreten, als dies bei vielen anderen Verteilungen zu erwarten wäre. Dies ist die Eigenschaft der Handelsvolumenverteilung. Die Form der Pareto-Verteilung ist: P(x) = Cx^(-α). Im Folgenden wird dies verdeutlicht.
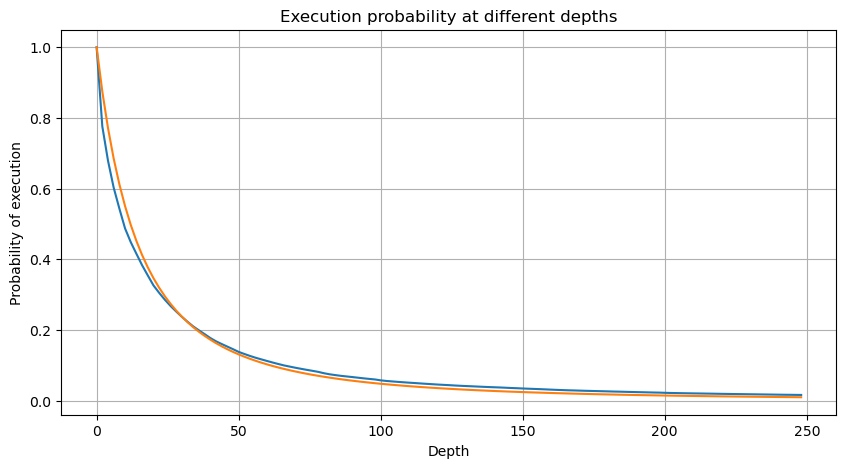
Die folgende Abbildung zeigt die Wahrscheinlichkeit, dass das Handelsvolumen größer als ein bestimmter Wert ist. Die blaue Linie ist die tatsächliche Wahrscheinlichkeit und die orange Linie ist die simulierte Wahrscheinlichkeit. Machen Sie sich hier keine Gedanken über die spezifischen Parameter. Sie können sehen, dass es erfüllen die Pareto-Verteilung. Da die Wahrscheinlichkeit, dass das Auftragsvolumen größer als 0 ist, 1 beträgt und um die Standardisierungsanforderungen zu erfüllen, sollte die Verteilungsgleichung wie folgt lauten:
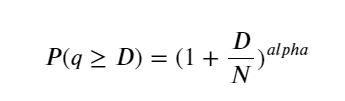
Wobei N der standardisierte Parameter ist. Hier wählen wir das durchschnittliche Volumen M und Alpha -2,06. Die konkrete Schätzung von Alpha kann durch die umgekehrte Berechnung des P-Werts für D=N ermittelt werden. Genauer gesagt: Alpha = log(P(d>M))/log(2) . Die Auswahl unterschiedlicher Punkte führt zu leicht unterschiedlichen Alphawerten.
python
depths = range(0, 250, 2)
probabilities = np.array([np.mean(buy_trades['quantity'] > depth) for depth in depths])
alpha = np.log(np.mean(buy_trades['quantity'] > mean_quantity))/np.log(2)
mean_quantity = buy_trades['quantity'].mean()
probabilities_s = np.array([(1+depth/mean_quantity)**alpha for depth in depths])
plt.figure(figsize=(10, 5))
plt.plot(depths, probabilities)
plt.plot(depths, probabilities_s)
plt.xlabel('Depth')
plt.ylabel('Probability of execution')
plt.title('Execution probability at different depths')
plt.grid(True)
python
plt.figure(figsize=(10, 5))
plt.grid(True)
plt.title('Diff')
plt.plot(depths, probabilities_s-probabilities);
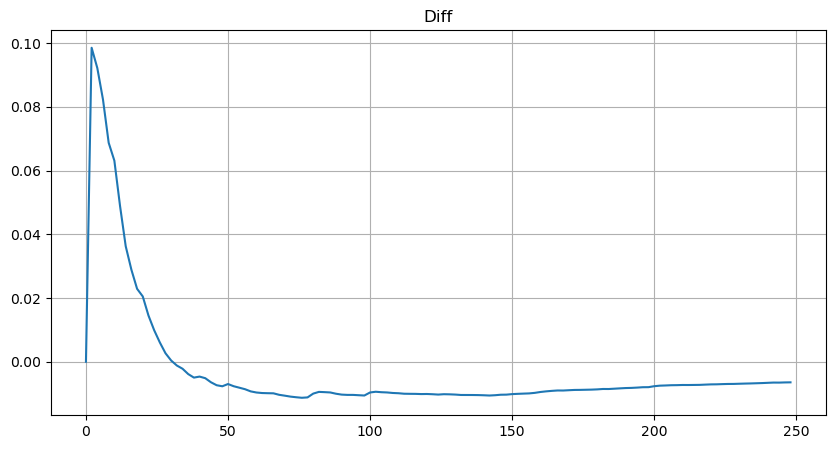
Aber diese Schätzung sieht nur so aus. In der obigen Abbildung stellen wir die Differenz zwischen dem simulierten Wert und dem tatsächlichen Wert dar. Bei geringem Handelsvolumen ist die Abweichung groß und liegt sogar bei fast 10 %. Die Wahrscheinlichkeit eines Punktes kann durch die Auswahl unterschiedlicher Punkte bei der Parameterschätzung präzisiert werden, das Abweichungsproblem wird dadurch jedoch nicht gelöst. Dies wird durch die Differenz zwischen der Potenzverteilung und der tatsächlichen Verteilung bestimmt. Um genauere Ergebnisse zu erhalten, muss die Gleichung der Potenzverteilung korrigiert werden. Auf den konkreten Ablauf will ich hier nicht näher eingehen, aber ich hatte eine Eingebung und fand, dass es eigentlich so ablaufen müsste:
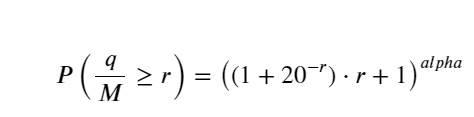
Der Einfachheit halber wird hier r = q/M verwendet, um das standardisierte Handelsvolumen darzustellen. Die Parameter können auf die gleiche Weise wie oben geschätzt werden. Die folgende Abbildung zeigt, dass die maximale Abweichung nach der Korrektur 2 % nicht überschreitet. Theoretisch kann die Korrektur fortgesetzt werden, aber diese Genauigkeit ist ausreichend.
python
depths = range(0, 250, 2)
probabilities = np.array([np.mean(buy_trades['quantity'] > depth) for depth in depths])
mean = buy_trades['quantity'].mean()
alpha = np.log(np.mean(buy_trades['quantity'] > mean))/np.log(2.05)
probabilities_s = np.array([(((1+20**(-depth/mean))*depth+mean)/mean)**alpha for depth in depths])
plt.figure(figsize=(10, 5))
plt.plot(depths, probabilities)
plt.plot(depths, probabilities_s)
plt.xlabel('Depth')
plt.ylabel('Probability of execution')
plt.title('Execution probability at different depths')
plt.grid(True)
python
plt.figure(figsize=(10, 5))
plt.grid(True)
plt.title('Diff')
plt.plot(depths, probabilities_s-probabilities);
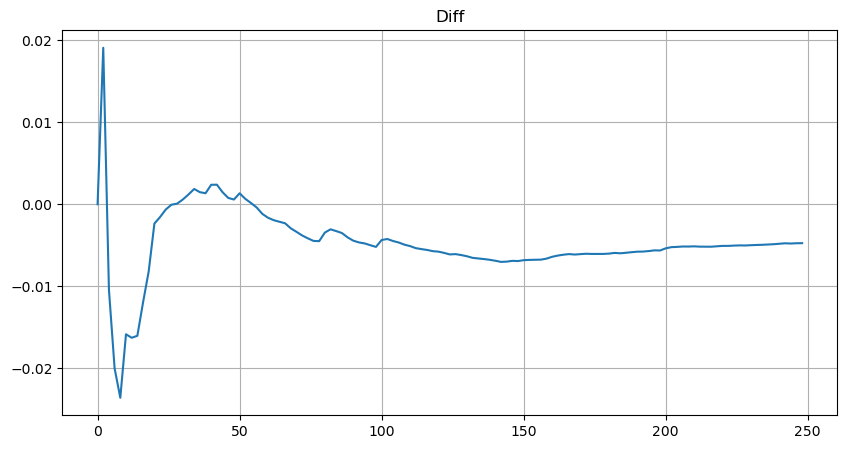
Bei der Schätzgleichung für die Mengenverteilung ist zu beachten, dass die Wahrscheinlichkeit der Gleichung nicht die wahre Wahrscheinlichkeit, sondern eine bedingte Wahrscheinlichkeit ist. An diesem Punkt können wir diese Frage beantworten: Wenn die nächste Bestellung eingeht, wie hoch ist die Wahrscheinlichkeit, dass diese Bestellung größer als ein bestimmter Wert ist? Mit anderen Worten: Wie hoch ist die Wahrscheinlichkeit der Ausführung von Aufträgen unterschiedlicher Tiefe (Idealfall, nicht so streng, theoretisch weist das Auftragsbuch neue Aufträge und Stornierungen sowie Warteschlangen mit gleicher Tiefe auf).
Der Artikel ist hier fast fertig, und es bleiben noch viele Fragen offen. Die folgende Artikelserie wird versuchen, Antworten zu geben.

