

Prefacio
El sistema de backtesting de la plataforma de negociación cuantitativa Inventor es un sistema de backtesting que se itera, actualiza y mejora constantemente. A partir de las funciones de backtesting básicas iniciales, se van añadiendo funciones de forma gradual y se optimiza el rendimiento. A medida que la plataforma se desarrolle, el sistema de backtesting se seguirá optimizando y actualizando. Hoy trataremos un tema basado en el sistema de backtesting: "Pruebas de estrategia basadas en condiciones aleatorias del mercado".
necesidad
En el campo del trading cuantitativo, el desarrollo y la optimización de estrategias no pueden separarse de la verificación de datos reales del mercado. Sin embargo, en aplicaciones reales, debido al complejo y cambiante entorno del mercado, confiar en datos históricos para realizar pruebas retrospectivas puede tener deficiencias, como la falta de cobertura de condiciones extremas del mercado o escenarios especiales. Por lo tanto, diseñar un generador de mercado aleatorio eficiente se convierte en una herramienta eficaz para los desarrolladores de estrategias cuantitativas.
Cuando necesitamos realizar pruebas retrospectivas de la estrategia en un determinado exchange o moneda utilizando datos históricos, podemos utilizar la fuente de datos oficial de la plataforma FMZ para realizar pruebas retrospectivas. A veces también queremos ver cómo funciona una estrategia en un mercado completamente "desconocido". En ese momento, podemos "fabricar" algunos datos para probar la estrategia.
La importancia de utilizar datos aleatorios del mercado es:
-
- Evaluación de la solidez de la estrategia
El generador de mercado aleatorio puede crear una variedad de posibles escenarios de mercado, incluida volatilidad extrema, baja volatilidad, mercados de tendencia y mercados volátiles. Probar una estrategia en estos entornos simulados puede ayudar a evaluar si su desempeño es estable en diferentes condiciones de mercado. Por ejemplo:
¿Puede la estrategia adaptarse a cambios de tendencias y shocks?
¿La estrategia resultará en pérdidas sustanciales en condiciones de mercado extremas? - Evaluación de la solidez de la estrategia
-
- Identificar posibles debilidades en su estrategia
Al simular algunas situaciones anormales del mercado (como hipotéticos eventos de cisne negro), se pueden descubrir y mejorar posibles debilidades en la estrategia. Por ejemplo:
¿La estrategia depende demasiado de una estructura de mercado particular?
¿Existe el riesgo de sobreajustar los parámetros? - Identificar posibles debilidades en su estrategia
-
- Optimización de parámetros de estrategia
Los datos generados aleatoriamente proporcionan un entorno de prueba más diverso para ajustar los parámetros de la estrategia sin tener que depender completamente de datos históricos. Esto permite una gama más amplia de parámetros de estrategia y evita limitarse a patrones de mercado específicos en datos históricos.
- Optimización de parámetros de estrategia
-
- Llenando el vacío en los datos históricos
En algunos mercados (como los mercados emergentes o los mercados que negocian monedas pequeñas), los datos históricos pueden no ser suficientes para cubrir todas las posibles condiciones del mercado. El aleatorizador puede proporcionar una gran cantidad de datos complementarios para facilitar pruebas más completas.
- Llenando el vacío en los datos históricos
-
- Desarrollo iterativo rápido
El uso de datos aleatorios para realizar pruebas rápidas puede acelerar la iteración del desarrollo de una estrategia sin depender de las condiciones del mercado en tiempo real ni de una limpieza y organización de datos que consume mucho tiempo.
- Desarrollo iterativo rápido
Sin embargo, también es necesario evaluar racionalmente la estrategia. En el caso de los datos de mercado generados aleatoriamente, tenga en cuenta lo siguiente:
-
- Aunque los generadores de mercados aleatorios son útiles, su importancia depende de la calidad de los datos generados y del diseño del escenario objetivo:
-
- La lógica de generación debe ser cercana al mercado real: si las condiciones del mercado generadas aleatoriamente están completamente fuera de contacto con la realidad, los resultados de las pruebas pueden carecer de valor de referencia. Por ejemplo, el generador puede diseñarse en combinación con características estadísticas reales del mercado (como distribución de volatilidad, relación de tendencia).
-
- No puede reemplazar por completo las pruebas con datos reales: los datos aleatorios solo pueden complementar el desarrollo y la optimización de las estrategias. La estrategia final aún debe verificarse para comprobar su eficacia con datos reales del mercado.
Dicho todo esto, ¿cómo podemos “fabricar” algunos datos? ¿Cómo podemos “fabricar” datos de forma cómoda, rápida y sencilla para utilizarlos en un sistema de backtesting?
Ideas de diseño
Este artículo está diseñado para proporcionar un punto de partida para la discusión y proporciona un cálculo de generación de mercado aleatorio relativamente simple. De hecho, existe una variedad de algoritmos de simulación, modelos de datos y otras tecnologías que se pueden aplicar. Debido al espacio limitado de la discusión No utilizaremos métodos de simulación de datos particularmente complejos.
Combinando la función de fuente de datos personalizada del sistema de backtesting de la plataforma, escribimos un programa en Python.
-
- Genere aleatoriamente un conjunto de datos de la línea K y escríbalos en un archivo CSV para un registro persistente, de modo que los datos generados se puedan guardar.
-
- Luego, cree un servicio para proporcionar soporte de fuente de datos para el sistema de backtesting.
-
- Muestre los datos de la línea K generados en el gráfico.
Para algunos estándares de generación y almacenamiento de archivos de datos de la línea K, se pueden definir los siguientes controles de parámetros:
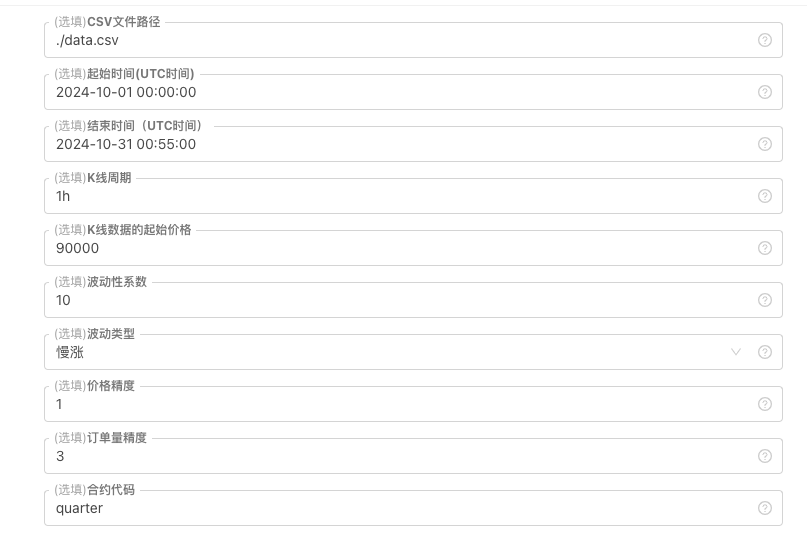
-
Patrón de datos generados aleatoriamente
Para simular el tipo de fluctuación de los datos de la línea K, simplemente utilizamos las diferentes probabilidades de números aleatorios positivos y negativos para crear un diseño simple. Cuando los datos generados no son muchos, es posible que no puedan reflejar el patrón de mercado requerido. Si hay una manera mejor, puedes reemplazar esta parte del código.
Basándose en este diseño simple, ajustar el rango de generación de números aleatorios y algunos coeficientes en el código puede afectar el efecto de los datos generados. -
Verificación de datos
También es necesario verificar la racionalidad de los datos de la línea K generados, para verificar si los precios de apertura altos y de cierre bajos violan la definición, para verificar la continuidad de los datos de la línea K, etc.
Generador de cotizaciones aleatorias del sistema de backtesting
python
import _thread
import json
import math
import csv
import random
import os
import datetime as dt
from http.server import HTTPServer, BaseHTTPRequestHandler
from urllib.parse import parse_qs, urlparse
arrTrendType = ["down", "slow_up", "sharp_down", "sharp_up", "narrow_range", "wide_range", "neutral_random"]
def url2Dict(url):
query = urlparse(url).query
params = parse_qs(query)
result = {key: params[key][0] for key in params}
return result
class Provider(BaseHTTPRequestHandler):
def do_GET(self):
global filePathForCSV, pround, vround, ct
try:
self.send_response(200)
self.send_header("Content-type", "application/json")
self.end_headers()
dictParam = url2Dict(self.path)
Log("自定义数据源服务接收到请求,self.path:", self.path, "query 参数:", dictParam)
eid = dictParam["eid"]
symbol = dictParam["symbol"]
arrCurrency = symbol.split(".")[0].split("_")
baseCurrency = arrCurrency[0]
quoteCurrency = arrCurrency[1]
fromTS = int(dictParam["from"]) * int(1000)
toTS = int(dictParam["to"]) * int(1000)
priceRatio = math.pow(10, int(pround))
amountRatio = math.pow(10, int(vround))
data = {
"detail": {
"eid": eid,
"symbol": symbol,
"alias": symbol,
"baseCurrency": baseCurrency,
"quoteCurrency": quoteCurrency,
"marginCurrency": quoteCurrency,
"basePrecision": vround,
"quotePrecision": pround,
"minQty": 0.00001,
"maxQty": 9000,
"minNotional": 5,
"maxNotional": 9000000,
"priceTick": 10 ** -pround,
"volumeTick": 10 ** -vround,
"marginLevel": 10,
"contractType": ct
},
"schema" : ["time", "open", "high", "low", "close", "vol"],
"data" : []
}
listDataSequence = []
with open(filePathForCSV, "r") as f:
reader = csv.reader(f)
header = next(reader)
headerIsNoneCount = 0
if len(header) != len(data["schema"]):
Log("CSV文件格式有误,列数不同,请检查!", "#FF0000")
return
for ele in header:
for i in range(len(data["schema"])):
if data["schema"][i] == ele or ele == "":
if ele == "":
headerIsNoneCount += 1
if headerIsNoneCount > 1:
Log("CSV文件格式有误,请检查!", "#FF0000")
return
listDataSequence.append(i)
break
while True:
record = next(reader, -1)
if record == -1:
break
index = 0
arr = [0, 0, 0, 0, 0, 0]
for ele in record:
arr[listDataSequence[index]] = int(ele) if listDataSequence[index] == 0 else (int(float(ele) * amountRatio) if listDataSequence[index] == 5 else int(float(ele) * priceRatio))
index += 1
data["data"].append(arr)
Log("数据data.detail:", data["detail"], "响应回测系统请求。")
self.wfile.write(json.dumps(data).encode())
except BaseException as e:
Log("Provider do_GET error, e:", e)
return
def createServer(host):
try:
server = HTTPServer(host, Provider)
Log("Starting server, listen at: %s:%s" % host)
server.serve_forever()
except BaseException as e:
Log("createServer error, e:", e)
raise Exception("stop")
class KlineGenerator:
def __init__(self, start_time, end_time, interval):
self.start_time = dt.datetime.strptime(start_time, "%Y-%m-%d %H:%M:%S")
self.end_time = dt.datetime.strptime(end_time, "%Y-%m-%d %H:%M:%S")
self.interval = self._parse_interval(interval)
self.timestamps = self._generate_time_series()
def _parse_interval(self, interval):
unit = interval[-1]
value = int(interval[:-1])
if unit == "m":
return value * 60
elif unit == "h":
return value * 3600
elif unit == "d":
return value * 86400
else:
raise ValueError("不支持的K线周期,请使用 'm', 'h', 或 'd'.")
def _generate_time_series(self):
timestamps = []
current_time = self.start_time
while current_time <= self.end_time:
timestamps.append(int(current_time.timestamp() * 1000))
current_time += dt.timedelta(seconds=self.interval)
return timestamps
def generate(self, initPrice, trend_type="neutral", volatility=1):
data = []
current_price = initPrice
angle = 0
for timestamp in self.timestamps:
angle_radians = math.radians(angle % 360)
cos_value = math.cos(angle_radians)
if trend_type == "down":
upFactor = random.uniform(0, 0.5)
change = random.uniform(-0.5, 0.5 * upFactor) * volatility * random.uniform(1, 3)
elif trend_type == "slow_up":
downFactor = random.uniform(0, 0.5)
change = random.uniform(-0.5 * downFactor, 0.5) * volatility * random.uniform(1, 3)
elif trend_type == "sharp_down":
upFactor = random.uniform(0, 0.5)
change = random.uniform(-10, 0.5 * upFactor) * volatility * random.uniform(1, 3)
elif trend_type == "sharp_up":
downFactor = random.uniform(0, 0.5)
change = random.uniform(-0.5 * downFactor, 10) * volatility * random.uniform(1, 3)
elif trend_type == "narrow_range":
change = random.uniform(-0.2, 0.2) * volatility * random.uniform(1, 3)
elif trend_type == "wide_range":
change = random.uniform(-3, 3) * volatility * random.uniform(1, 3)
else:
change = random.uniform(-0.5, 0.5) * volatility * random.uniform(1, 3)
change = change + cos_value * random.uniform(-0.2, 0.2) * volatility
open_price = current_price
high_price = open_price + random.uniform(0, abs(change))
low_price = max(open_price - random.uniform(0, abs(change)), random.uniform(0, open_price))
close_price = open_price + change if open_price + change < high_price and open_price + change > low_price else random.uniform(low_price, high_price)
if (high_price >= open_price and open_price >= close_price and close_price >= low_price) or (high_price >= close_price and close_price >= open_price and open_price >= low_price):
pass
else:
Log("异常数据:", high_price, open_price, low_price, close_price, "#FF0000")
high_price = max(high_price, open_price, close_price)
low_price = min(low_price, open_price, close_price)
base_volume = random.uniform(1000, 5000)
volume = base_volume * (1 + abs(change) * 0.2)
kline = {
"Time": timestamp,
"Open": round(open_price, 2),
"High": round(high_price, 2),
"Low": round(low_price, 2),
"Close": round(close_price, 2),
"Volume": round(volume, 2),
}
data.append(kline)
current_price = close_price
angle += 1
return data
def save_to_csv(self, filename, data):
with open(filename, mode="w", newline="") as csvfile:
writer = csv.writer(csvfile)
writer.writerow(["", "open", "high", "low", "close", "vol"])
for idx, kline in enumerate(data):
writer.writerow(
[kline["Time"], kline["Open"], kline["High"], kline["Low"], kline["Close"], kline["Volume"]]
)
Log("当前路径:", os.getcwd())
with open("data.csv", "r") as file:
lines = file.readlines()
if len(lines) > 1:
Log("文件写入成功,以下是文件内容的一部分:")
Log("".join(lines[:5]))
else:
Log("文件写入失败,文件为空!")
def main():
Chart({})
LogReset(1)
try:
# _thread.start_new_thread(createServer, (("localhost", 9090), ))
_thread.start_new_thread(createServer, (("0.0.0.0", 9090), ))
Log("开启自定义数据源服务线程,数据由CSV文件提供。", ", 地址/端口:0.0.0.0:9090", "#FF0000")
except BaseException as e:
Log("启动自定义数据源服务失败!")
Log("错误信息:", e)
raise Exception("stop")
while True:
cmd = GetCommand()
if cmd:
if cmd == "createRecords":
Log("生成器参数:", "起始时间:", startTime, "结束时间:", endTime, "K线周期:", KLinePeriod, "初始价格:", firstPrice, "波动类型:", arrTrendType[trendType], "波动性系数:", ratio)
generator = KlineGenerator(
start_time=startTime,
end_time=endTime,
interval=KLinePeriod,
)
kline_data = generator.generate(firstPrice, trend_type=arrTrendType[trendType], volatility=ratio)
generator.save_to_csv("data.csv", kline_data)
ext.PlotRecords(kline_data, "%s_%s" % ("records", KLinePeriod))
LogStatus(_D())
Sleep(2000)
Práctica en el sistema de backtesting
- Cree la instancia de política anterior, configure los parámetros y ejecútela.
- El mercado real (instancia de estrategia) debe ejecutarse en un host implementado en un servidor, porque se requiere una IP pública para que el sistema de backtesting acceda a él y obtenga datos.
- Haga clic en el botón interactivo y la estrategia comenzará a generar automáticamente datos de mercado aleatorios.

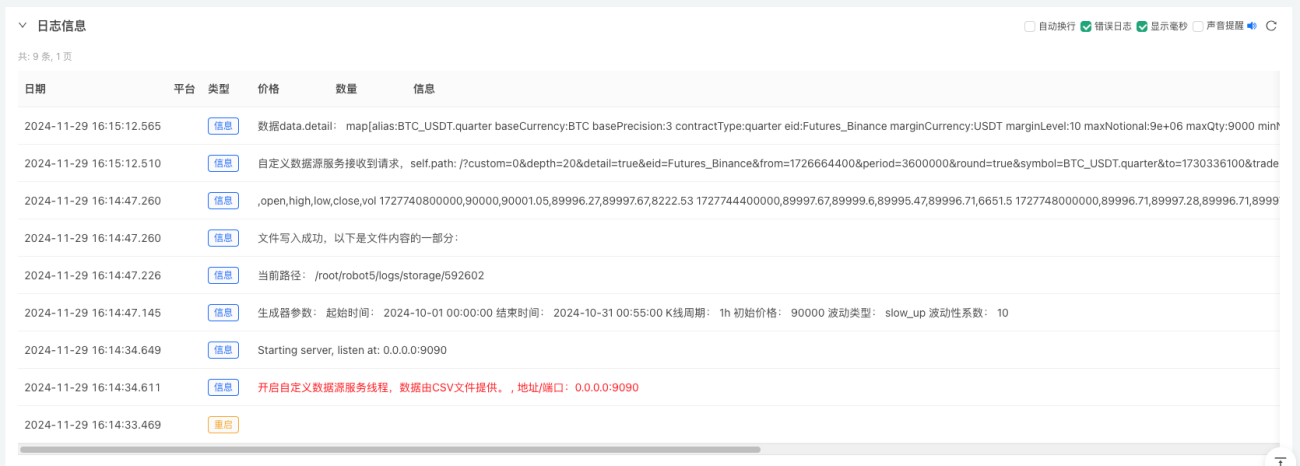
- Los datos generados se mostrarán en el gráfico para una fácil observación y se registrarán en el archivo data.csv local.
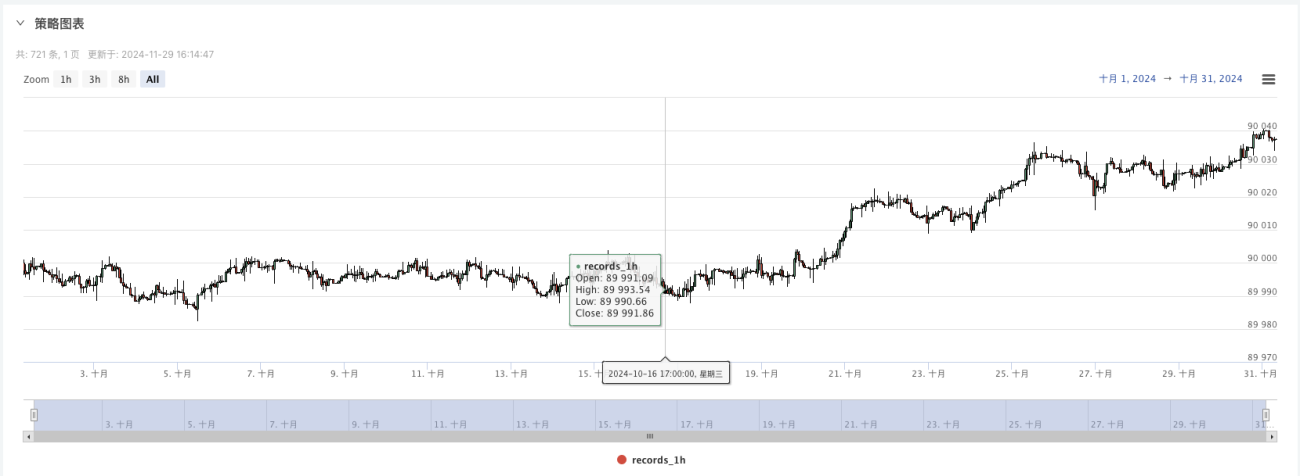
- Ahora podemos usar estos datos generados aleatoriamente y utilizar cualquier estrategia para realizar pruebas retrospectivas.
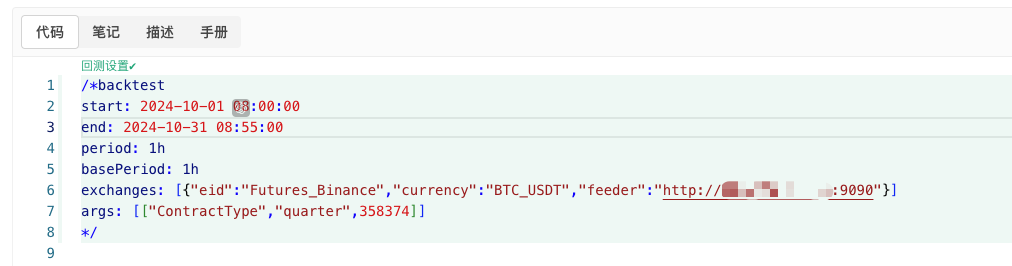
python
/*backtest
start: 2024-10-01 08:00:00
end: 2024-10-31 08:55:00
period: 1h
basePeriod: 1h
exchanges: [{"eid":"Futures_Binance","currency":"BTC_USDT","feeder":"http://xxx.xxx.xxx.xxx:9090"}]
args: [["ContractType","quarter",358374]]
*/
Configure según la información anterior y realice ajustes específicos.http://xxx.xxx.xxx.xxx:9090Es la dirección IP del servidor y el puerto abierto del disco real de estrategia de generación de mercado aleatorio.
Esta es una fuente de datos personalizada. Puede consultar la sección de fuentes de datos personalizadas en la documentación de la API de la plataforma para obtener más información.
- Después de que el sistema de backtest configure la fuente de datos, puede probar los datos aleatorios del mercado.
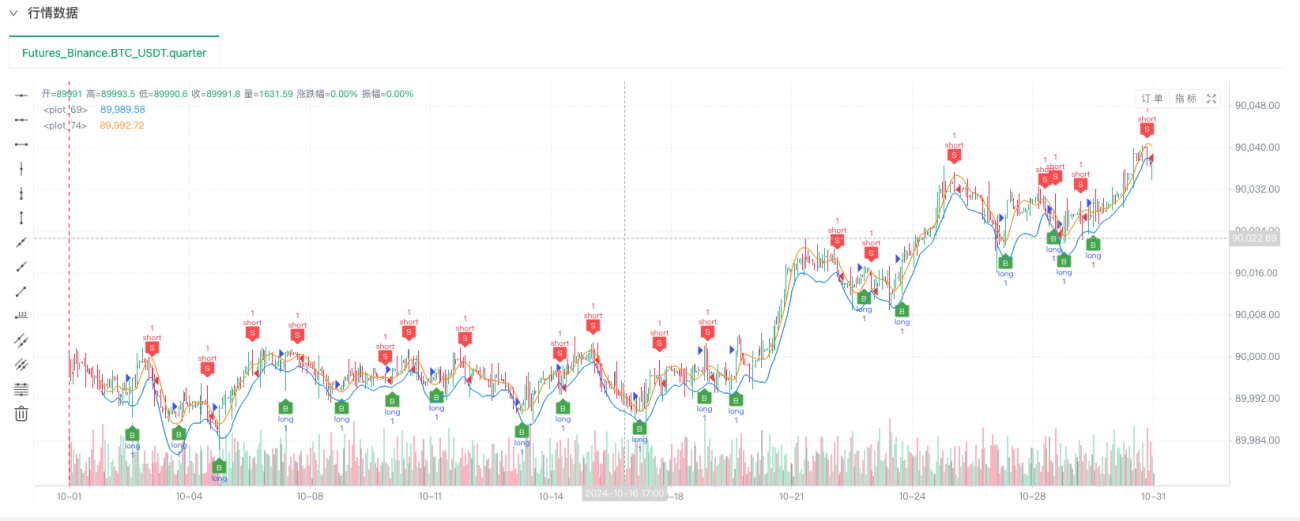
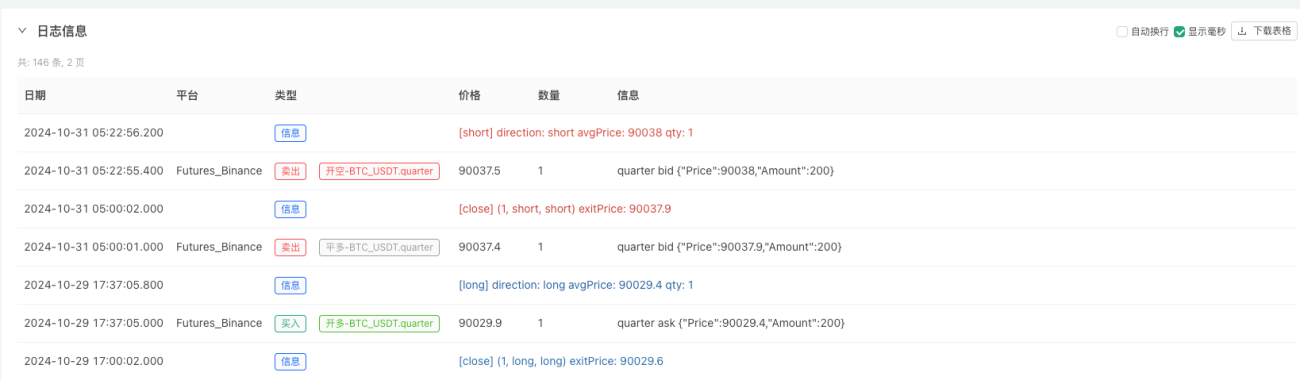
En este punto, el sistema de backtesting se prueba utilizando nuestros datos simulados "fabricados". Según los datos del gráfico de mercado durante el backtest, compare los datos del gráfico en tiempo real generado por condiciones de mercado aleatorias. La hora es las 17:00 del 16 de octubre de 2024. Los datos son los mismos.
- ¡Ah sí! ¡Casi me olvido de decirlo! La razón por la que este programa Python generador de mercado aleatorio crea un mercado real es para facilitar la demostración, operación y visualización de los datos de la línea K generados. En la aplicación real, puedes escribir un script de Python independiente, por lo que no tienes que ejecutar el disco real.
Código fuente de la estrategia:Generador de cotizaciones aleatorias del sistema de backtesting
Gracias por su apoyo y lectura.
- 1