Siete técnicas de regresión que debes dominar
 0
3362
0
3362
Siete técnicas de regresión que debes dominar
**Este artículo explica el análisis de la regresión y sus ventajas, resumiendo los elementos clave de las siete técnicas de regresión más usadas y los elementos clave para elegir el modelo de regresión correcto, como son la regresión lineal, la regresión lógica, la regresión múltiple, la regresión gradual, la regresión de columnas, la regresión de lazo y la regresión de ElasticNet. ** ** El análisis de regresión de botones de codificador es una herramienta importante para modelar y analizar datos. Este artículo explica el significado y las ventajas del análisis de regresión, resumiendo los siete métodos de regresión más utilizados y sus elementos clave, como la regresión lineal, la regresión lógica, la regresión múltiple, la regresión gradual, la regresión de lazo, la regresión de lazo y la regresión de ElasticNet, y los elementos clave para elegir el modelo de regresión correcto.**
- ### ¿Qué es el análisis de regresión?
El análisis de regresión es una técnica de modelado predictivo que estudia la relación entre la variable de causalidad (el objetivo) y la propia variable (el predictor). Esta técnica se utiliza generalmente para el análisis predictivo, los modelos de secuencias temporales y las relaciones de causalidad entre las variables descubiertas. Por ejemplo, la relación entre la conducción imprudente de los conductores y el número de accidentes de tráfico en la carretera, el mejor método de estudio es la regresión.
El análisis de la regresión es una herramienta importante para modelar y analizar datos. Aquí, usamos curvas/líneas para adaptar estos puntos de datos, de esta manera, la diferencia de distancia desde la curva o la línea hasta el punto de datos es mínima. Lo explicaré en detalle en la siguiente sección.
- ### ¿Por qué usamos el análisis de regresión?
Como se mencionó anteriormente, el análisis de regresión estima la relación entre dos o más variables. A continuación, vamos a dar un ejemplo simple para entenderlo:
Por ejemplo, en las condiciones económicas actuales, si quieres estimar el crecimiento de las ventas de una empresa. Ahora, tienes los últimos datos de la empresa, que muestran que el crecimiento de las ventas es aproximadamente 2,5 veces el crecimiento económico. Entonces, usando el análisis de regresión, podemos predecir las ventas futuras de la empresa en base a la información actual y pasada.
El uso del análisis de regresión tiene muchas ventajas.
Muestra una relación significativa entre la variable propia y la variable causante;
Muestra la intensidad de la influencia de varias variables de origen sobre una variable de causa.
El análisis de regresión también nos permite comparar las interacciones entre variables que miden diferentes escalas, como la relación entre los cambios en los precios y el número de actividades promocionales. Estos son útiles para ayudar a los investigadores de mercado, analistas de datos y científicos de datos a excluir y estimar el mejor conjunto de variables para construir modelos de predicción.
- ### ¿Cuántas tecnologías de regresión tenemos?
Existen diversas técnicas de regresión para la predicción. Estas técnicas tienen tres dimensiones principales: el número de variables, el tipo de variables y la forma de la línea de regresión. Las discutiremos en detalle en la siguiente sección.
Para aquellos que son creativos, si sienten la necesidad de usar una combinación de los parámetros anteriores, pueden incluso crear un modelo de regresión que no se haya utilizado. Pero antes de comenzar, conozca los métodos de regresión más utilizados:
-
1. Regresión Lineal
Es una de las técnicas de modelado más conocidas. La regresión lineal suele ser una de las técnicas preferidas para aprender modelos de predicción. En esta técnica, la línea de regresión es lineal, ya que las variables son continuas, las variables pueden ser continuas o separadas.
La regresión lineal utiliza la recta de la mejor conjugación ((es decir, la línea de regresión) para establecer una relación entre la variable de causalidad ((Y) y una o varias variables de la propia variable ((X)).
Se puede representar en una ecuación, y es Y = a + b.*X + e, donde a representa la intersección, b representa la pendiente de la línea recta y e es el error. Esta ecuación puede predecir el valor de la variable objetivo en función de una variable de predicción dada (s).
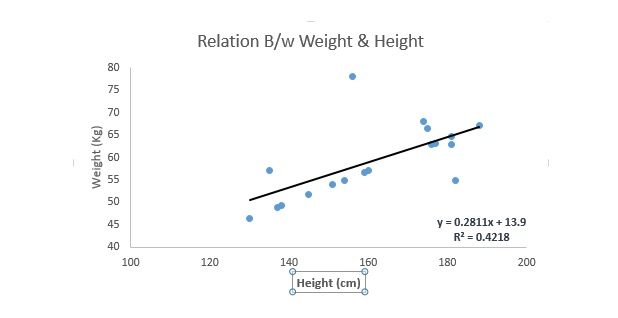
La diferencia entre la regresión unilineal y la regresión lineal múltiple es que la regresión lineal múltiple tiene ((>1) variables propias, mientras que la regresión unilineal generalmente tiene solo una variable propia. Ahora la pregunta es ¿cómo obtenemos una línea de ajuste óptima?
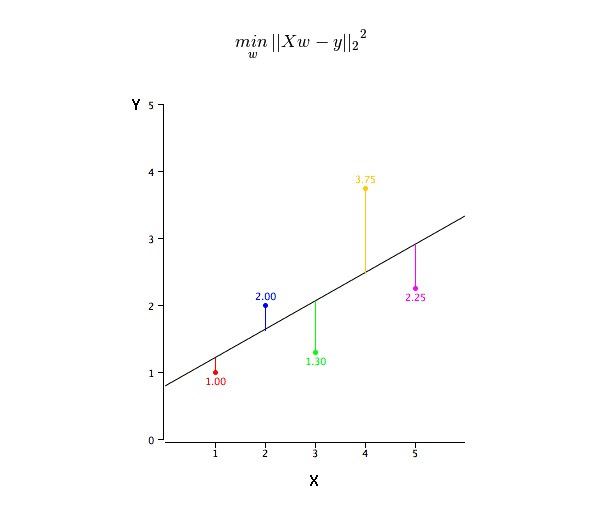
¿Cómo se obtiene el valor de la línea de mejor ajuste (a y b)?
Este problema se puede resolver fácilmente con el método de la multiplicación de los dos mínimos. El método de la multiplicación de los dos mínimos es también el método más común para la asimilación de líneas de regresión. Para los datos de observación, se calcula la línea de la asimilación óptima minimizando la suma de los cuadrados de la desviación vertical de cada punto de datos a la línea.
Podemos usar los indicadores de R-square para evaluar el rendimiento del modelo. Para obtener más información sobre estos indicadores, consulte: Indicadores de rendimiento del modelo Part 1, Part 2 .
El punto es:
- Debe haber una relación lineal entre la variable propia y la variable causante
- La regresión múltiple tiene múltiples conlinealidades, auto-relaciones y divergencias.
- La regresión lineal es muy sensible a los valores de excepción. Puede afectar gravemente a la línea de regresión y, finalmente, a los valores de predicción.
- La convectividad múltiple aumenta la diferencia entre las estimaciones de los coeficientes, lo que hace que las estimaciones sean muy sensibles a cambios leves en el modelo. El resultado es que las estimaciones de los coeficientes son inestables.
- En el caso de varias variables, podemos usar la selección hacia adelante, la eliminación hacia atrás y la selección gradual para seleccionar la variable más importante.
-
2. Regresión Logística
La regresión lógica es la que se utiliza para calcular la probabilidad de que Success=Success y Failure=Failure. Cuando el tipo de la variable de causalidad es binario ((1⁄0, verdadero/falso, sí/no), entonces deberíamos usar Regresión lógica. Aquí, el valor de Y es de 0 a 1, que se puede expresar con la siguiente ecuación:
odds= p/ (1-p) = probability of event occurrence / probability of not event occurrence ln(odds) = ln(p/(1-p)) logit(p) = ln(p/(1-p)) = b0+b1X1+b2X2+b3X3....+bkXkEn la fórmula anterior, p representa la probabilidad de que tenga alguna característica. Deberías hacer la pregunta: ¿por qué usamos logaritmos en la fórmula?
Debido a que aquí estamos usando la distribución binaria de {\displaystyle \mathbb {R} } } , necesitamos elegir una función de conexión que sea la mejor para esta distribución. Es la función Logit. En la ecuación anterior, los parámetros se seleccionan mediante la observación de la probabilidad máxima de la muestra, en lugar de minimizar el cuadrado y el error (como se usa en la regresión ordinaria).
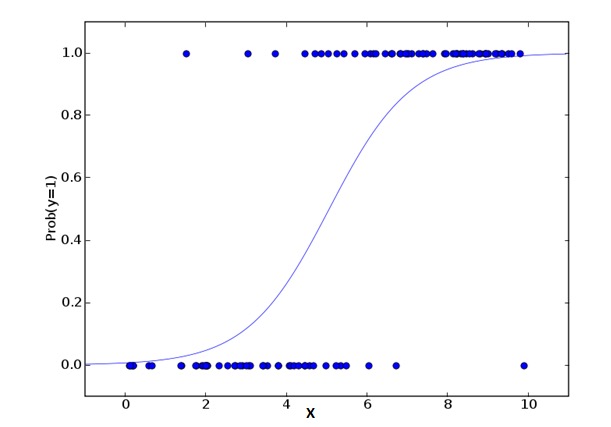
El punto es:
- Se utiliza ampliamente en cuestiones de clasificación.
- La regresión lógica no requiere que la relación entre la variable propia y la variable de causalidad sea lineal. Puede manejar todo tipo de relaciones, ya que utiliza una conversión de log no lineal para el índice de riesgo relativo OR de la predicción.
- Para evitar sobreajustes y no ajustes, deberíamos incluir todas las variables importantes. Hay una buena manera de asegurar que esto ocurra, es usar un método de selección gradual para estimar la regresión lógica.
- Se requiere una gran cantidad de muestras, ya que en el caso de un número menor de muestras, el efecto de la estimación de probabilidad máxima es inferior al mínimo de la normalidad.
- Las variables automáticas no deben estar relacionadas entre sí, es decir, no tienen una co-linealidad múltiple. Sin embargo, en el análisis y la modelación, podemos optar por incluir la interacción de las variables de clasificación.
- Si el valor de la variable de derivación es una variable de orden, se le llama regresión lógica de orden.
- Si la variable de derivación es de varias clases, se llama regresión lógica múltiple.
-
3. Regresión polinomial
Para una ecuación de regresión, si el índice de la variable es mayor que 1, entonces es una ecuación de regresión polinomial. La ecuación siguiente lo muestra:
y=a+b*x^2En esta técnica de regresión, la línea de mejor ajuste no es una línea recta, sino una curva utilizada para ajustar los puntos de datos.
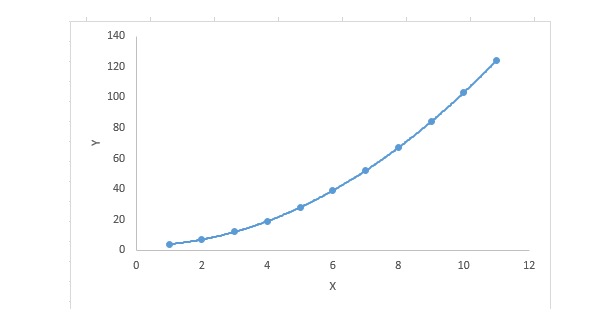
Enfoque:
- Si bien hay una inducción que puede ajustar un polinomio de grado alto y obtener un error menor, esto puede conducir a una sobregestión. Necesitará dibujar regularmente un diagrama de relación para ver si la combinación es correcta, y centrarse en garantizar que la combinación sea razonable, no sobregresa ni no es deficiente. A continuación se muestra un gráfico que puede ayudar a entender:
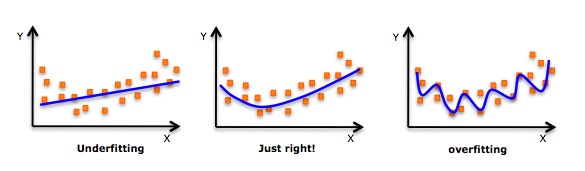
- Obviamente, busque puntos de la curva en ambos extremos para ver si estas formas y tendencias tienen sentido. Las polinomias de mayor grado pueden terminar produciendo extrañas conclusiones.
-
4. Regresión paso a paso
En esta técnica, la selección de las variables automáticas se realiza en un proceso automático, que incluye operaciones no humanas.
Esta hazaña consiste en identificar las variables importantes mediante la observación de valores estadísticos, como R-square, t-stats y el indicador AIC. La regresión progresiva se ajusta al modelo mediante la simultánea adición/eliminación de co-variables basados en criterios especificados.
- La regresión gradual estándar hace dos cosas: añade y elimina las predicciones necesarias para cada paso.
- La selección hacia adelante comienza con las predicciones más destacadas del modelo, y luego se añade una variable para cada paso.
- El método de eliminación de retroceso comienza al mismo tiempo que todas las predicciones del modelo, y luego elimina las variables de menor importancia en cada paso.
- El objetivo de esta técnica de modelado es maximizar la capacidad de predicción utilizando el mínimo número de variables de predicción. Esta es una de las formas de procesar conjuntos de datos de alta dimensión.
-
5. Regresión de la cresta
El análisis de la regresión aluminosa es una técnica utilizada para datos en los que existe una alta correlación entre varias variables. En el caso de la regresión aluminosa, aunque el método de la multiplicación mínima por dos (OLS) es justo para cada variable, sus diferencias son grandes, lo que hace que los valores de observación se desvíen y se alejen del valor real. La regresión aluminosa reduce el error estándar al agregar una desviación a la estimación de la regresión.
Por ejemplo, la ecuación de regresión lineal que vimos arriba, ¿recuerdas?
y=a+ b*xEsta ecuación también tiene un elemento de error. La ecuación completa es:
y=a+b*x+e (error term), [error term is the value needed to correct for a prediction error between the observed and predicted value] => y=a+y= a+ b1x1+ b2x2+....+e, for multiple independent variables.En una ecuación lineal, el error de predicción puede dividirse en dos subpartidas. Una es la desviación y la otra es la diferencia. El error de predicción puede ser causado por estas dos partes o por cualquiera de ellas.
La regresión de Cube resuelve el problema de la covalencia múltiple mediante el parámetro de contracción λ{\displaystyle \lambda } . Ver la siguiente fórmula
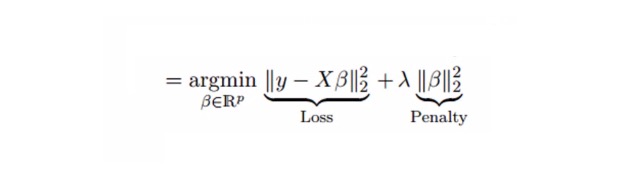
En esta fórmula hay dos componentes: el primero es el bímetro mínimo, y el otro es el multiplicador λ de β2 (β-cuadrado), donde β es el coeficiente correspondiente. Para reducir el parámetro, añadirlo al bímetro mínimo da una diferencia muy baja.
El punto es:
- La regresión es similar a la regresión de la decima mínima, excepto en términos constantes.
- Se comprime el valor de los coeficientes relevantes, pero no llega a cero, lo que indica que no tiene la función de selección de características
- Este es un método de regularización, y se utiliza la regularización L2.
-
6. Lasso Regression regreso de la soga
Al igual que la regresión de cuerdas, el Lasso (Least Absolute Shrinkage and Selection Operator) también penaliza el tamaño absoluto del coeficiente de regresión. Además, reduce el grado de variación y mejora la precisión del modelo de regresión lineal. Ver la siguiente fórmula:
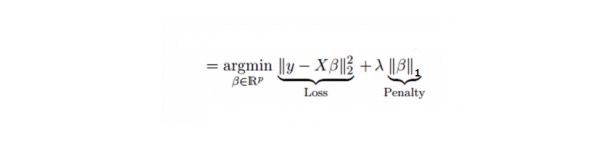
La regresión de Lasso es un poco diferente a la regresión de Ridge, ya que usa una función de penalización que es un valor absoluto, no un cuadrado. Esto hace que la penalización (o la suma de los valores absolutos que equivalen a la estimación de la restricción) de algunos parámetros resulte en una estimación de cero.
El punto es:
- La regresión es similar a la regresión de la decima mínima, excepto en términos constantes.
- Su coeficiente de contracción es cercano a cero, lo que realmente ayuda a la selección de características;
- Este es un método de regularización que utiliza la regularización L1;
- Si un conjunto de variables en la predicción es altamente correlacionado, Lasso escoge una de ellas y reduce las otras a cero.
-
7. Regreso de la red elástica
ElasticNet es un híbrido de las técnicas de regresión de Lasso y Ridge. Utiliza L1 para entrenar y L2 es priorizado como matriz de regularización. ElasticNet es útil cuando hay varias características relacionadas. Lasso elige al azar una de ellas, mientras que ElasticNet elige dos.
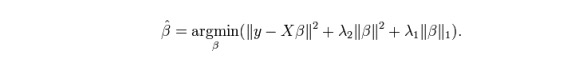
La ventaja real entre Lasso y Ridge es que permite a ElasticNet heredar algo de la estabilidad de Ridge en estado de ciclo.
El punto es:
- En el caso de variables altamente correlacionadas, produce un efecto de grupo;
- No hay límite en el número de variables a elegir.
- Puede soportar una doble contracción.
- Además de las 7 técnicas de regresión más usadas, puedes ver otros modelos, como la regresión bayesiana, ecológica y robusta.
¿Cómo elegir el modelo de regresión correcto?
La vida suele ser más fácil cuando solo conoces una o dos técnicas. Un instituto de formación que conozco les dijo a sus estudiantes que si los resultados eran continuos, usaran regresión lineal. Si eran binarios, usaran regresión lógica.
En un modelo de regresión múltiple, es muy importante elegir la técnica más adecuada en función del tipo de variable y de variable, la dimensión de los datos y otras características básicas de los datos. Los siguientes son los factores clave para elegir el modelo de regresión correcto:
La exploración de datos es una parte esencial de la construcción de modelos predictivos. Debe ser el primer paso en la selección de modelos adecuados, como la identificación de las relaciones y efectos de las variables.
Una comparación más adecuada para los diferentes modelos es la de que podemos analizar diferentes parámetros indicadores, como los parámetros de significación estadística, R-square, Adjusted R-square, AIC, BIC, y los términos de error, y la otra es la regla de Mallows’ Cp. Esto se hace principalmente comparando el modelo con todos los posibles submodelos (o seleccionándolos cuidadosamente) y examinando los posibles desviaciones en tu modelo.
La verificación cruzada es la mejor manera de evaluar el modelo de predicción. Aquí, divide tu conjunto de datos en dos partes: una para entrenamiento y otra para verificación. Utiliza una simple diferencia de equilibrio entre los valores de observación y los valores de predicción para medir la precisión de tu predicción.
Si tu conjunto de datos es de varias variables mixtas, entonces no deberías elegir el método de selección automática de modelos, ya que no deberías querer poner todas las variables en el mismo modelo al mismo tiempo.
También dependerá de su propósito. Puede haber situaciones en las que un modelo menos robusto es más fácil de implementar que uno con un alto significado estadístico.
Los métodos de regularización de regresión ((Lasso, Ridge y ElasticNet) funcionan bien en el caso de múltiples covalencias entre variables de alta dimensión y de un conjunto de datos.
Traducido de CSDN