

El trading con pares es un gran ejemplo de desarrollo de una estrategia de trading basada en análisis matemático. En este artículo, demostraremos cómo aprovechar los datos para crear y automatizar una estrategia de trading con pares.
Principios básicos
Supongamos que tiene un par de inversiones X e Y que tienen alguna correlación subyacente, como por ejemplo que ambas empresas producen el mismo producto, como Pepsi y Coca-Cola. Quiere que la relación de precios o base (también llamada diferencial) entre ambos permanezca constante a lo largo del tiempo. Sin embargo, el diferencial entre los dos pares puede divergir de vez en cuando debido a cambios temporales en la oferta y la demanda, como grandes órdenes de compra/venta para un objetivo de inversión, reacción a noticias importantes sobre una de las empresas, etc. En este caso, una inversión se mueve hacia arriba y la otra hacia abajo, una respecto de la otra. Si espera que esta divergencia se normalice con el tiempo, puede detectar una oportunidad comercial (o una oportunidad de arbitraje). Estas oportunidades de arbitraje existen en todas partes en el mercado de divisas digitales o en el mercado de futuros de materias primas nacionales, como la relación entre BTC y los activos de refugio seguro; la relación entre la harina de soja, el aceite de soja y las variedades de soja en futuros.
Cuando hay una diferencia temporal de precios, el operador venderá la inversión con mejor rendimiento (la inversión que ha subido) y comprará la inversión con peor rendimiento (la inversión que ha bajado). Puede estar seguro de que existe una diferencia entre las dos inversiones. El diferencial se verá reflejado en que la inversión con mejor rendimiento retrocederá o que la inversión con peor rendimiento volverá a subir, o en ambas situaciones. Su operación generará ganancias en todos estos escenarios. Si las inversiones suben o bajan juntas sin cambiar la diferencia entre ellas, no ganarás ni perderás dinero.
Por lo tanto, el trading de pares es una estrategia de trading neutral en el mercado que permite a los traders obtener beneficios de casi cualquier condición del mercado: tendencia alcista, tendencia bajista o lateral.
Explique el concepto: dos objetivos de inversión hipotéticos
- Desarrollamos nuestro entorno de investigación en la plataforma cuantitativa Inventor
En primer lugar, para que funcione sin problemas, necesitamos crear nuestro entorno de investigación. En este artículo, utilizamos Inventor Quantitative Platform (FMZ.COM) para crear el entorno de investigación, principalmente para que podamos utilizar la API rápida y conveniente. Interfaz y encapsulamiento de esta plataforma posteriormente. Sistema Docker completo.
En el nombre oficial de Inventor Quantitative Platform, este sistema Docker se denomina sistema host.
Para obtener más información sobre cómo implementar hosts y robots, consulte mi artículo anterior: https://www.fmz.com/bbs-topic/4140
Los lectores que quieran comprar su propio servidor de implementación de computación en la nube pueden consultar este artículo: https://www.fmz.com/bbs-topic/2848
Después de implementar con éxito el servicio de computación en la nube y el sistema host, instalaremos la herramienta Python más poderosa: Anaconda
Para lograr todos los entornos de programa relevantes necesarios para este artículo (bibliotecas dependientes, gestión de versiones, etc.), la forma más sencilla es utilizar Anaconda. Es un ecosistema de ciencia de datos Python empaquetado y un administrador de dependencias.
Para conocer el método de instalación de Anaconda, consulte la guía oficial de Anaconda: https://www.anaconda.com/distribution/
Este artículo también utilizará numpy y pandas, dos bibliotecas muy populares e importantes en la computación científica de Python.
Para el trabajo básico mencionado anteriormente, también puede consultar mi artículo anterior, que presenta cómo configurar el entorno de Anaconda y las dos bibliotecas numpy y pandas. Para obtener más detalles, consulte: https://www.fmz.com/digest- tema/4169
A continuación, usemos el código para implementar "dos objetivos de inversión hipotéticos".
import numpy as np
import pandas as pd
import statsmodels
from statsmodels.tsa.stattools import coint
# just set the seed for the random number generator
np.random.seed(107)
import matplotlib.pyplot as plt
Sí, también usaremos matplotlib, una biblioteca de gráficos muy famosa en Python.
Generemos un activo de inversión hipotético X y simulemos el gráfico de sus rendimientos diarios utilizando una distribución normal. Luego realizamos una suma acumulativa para obtener el valor X diario.
# Generate daily returns
Xreturns = np.random.normal(0, 1, 100)
# sum them and shift all the prices up
X = pd.Series(np.cumsum(
Xreturns), name='X')
+ 50
X.plot(figsize=(15,7))
plt.show()
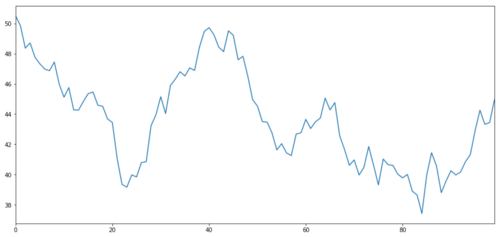
Objetivo de inversión X, simular y dibujar su retorno diario a través de una distribución normal
Ahora generamos Y que está fuertemente correlacionado con X, por lo que el precio de Y debería moverse de manera muy similar a los cambios en X. Modelamos esto tomando X, desplazándolo hacia arriba y agregando algo de ruido aleatorio extraído de una distribución normal.
noise = np.random.normal(0, 1, 100)
Y = X + 5 + noise
Y.name = 'Y'
pd.concat([X, Y], axis=1).plot(figsize=(15,7))
plt.show()
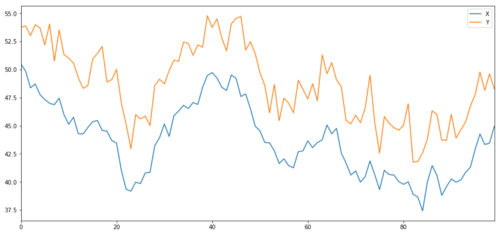
Cointegración de los objetivos de inversión X e Y
Cointegración
La cointegración es muy similar a la correlación, lo que significa que la relación entre dos series de datos variará en torno a la media. Las dos series Y y X siguen el siguiente patrón:
Y = ⍺ X + e
donde ⍺ es una relación constante y e es el ruido.
Para un par comercial entre dos series de tiempo, el valor esperado de la relación a lo largo del tiempo debe converger a la media, es decir, deben estar cointegrados. Las series de tiempo que construimos arriba están cointegradas. Ahora dibujaremos la escala entre los dos para que podamos ver cómo se verá.
(Y/X).plot(figsize=(15,7))
plt.axhline((Y/X).mean(), color='red', linestyle='--')
plt.xlabel('Time')
plt.legend(['Price Ratio', 'Mean'])
plt.show()
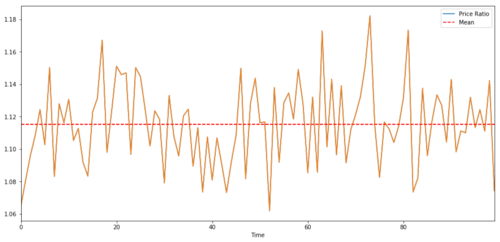
La relación y el promedio de los precios de dos inversiones cointegradas
Prueba de cointegración
Una forma conveniente de probar esto es utilizar statsmodels.tsa.stattools. Deberíamos ver un valor p muy bajo porque creamos artificialmente dos series de datos que están lo más cointegradas posible.
# compute the p-value of the cointegration test
# will inform us as to whether the ratio between the 2 timeseries is stationary
# around its mean
score, pvalue, _ = coint(X,Y)
print pvalue
El resultado es: 1.81864477307e-17
Nota: Correlación y cointegración
Aunque la correlación y la cointegración son similares en teoría, no son lo mismo. Veamos ejemplos de series de datos que están correlacionadas pero no cointegradas, y viceversa. Primero verifiquemos la correlación de la serie que acabamos de generar.
X.corr(Y)
El resultado es: 0,951
Como esperábamos, este número es muy alto. ¿Pero qué pasa con dos series que están correlacionadas pero no cointegradas? Un ejemplo sencillo son dos series de datos que divergen.
ret1 = np.random.normal(1, 1, 100)
ret2 = np.random.normal(2, 1, 100)
s1 = pd.Series( np.cumsum(ret1), name='X')
s2 = pd.Series( np.cumsum(ret2), name='Y')
pd.concat([s1, s2], axis=1 ).plot(figsize=(15,7))
plt.show()
print 'Correlation: ' + str(X_diverging.corr(Y_diverging))
score, pvalue, _ = coint(X_diverging,Y_diverging)
print 'Cointegration test p-value: ' + str(pvalue)
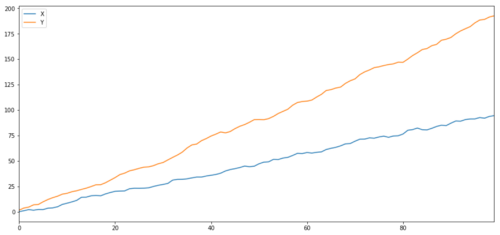
Dos series relacionadas (no cointegradas)
Coeficiente de correlación: 0,998
Valor p de la prueba de cointegración: 0,258
Ejemplos simples de cointegración sin correlación son una serie distribuida normalmente y una onda cuadrada.
Y2 = pd.Series(np.random.normal(0, 1, 800), name='Y2') + 20
Y3 = Y2.copy()
Y3[0:100] = 30
Y3[100:200] = 10
Y3[200:300] = 30
Y3[300:400] = 10
Y3[400:500] = 30
Y3[500:600] = 10
Y3[600:700] = 30
Y3[700:800] = 10
Y2.plot(figsize=(15,7))
Y3.plot()
plt.ylim([0, 40])
plt.show()
# correlation is nearly zero
print 'Correlation: ' + str(Y2.corr(Y3))
score, pvalue, _ = coint(Y2,Y3)
print 'Cointegration test p-value: ' + str(pvalue)
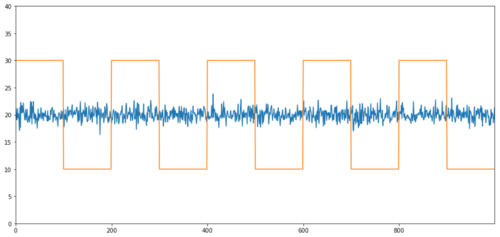
Correlación: 0,007546
Valor p de la prueba de cointegración: 0,0
La correlación es muy baja, pero el valor p muestra una cointegración perfecta.
¿Cómo hacer trading con pares?
Debido a que dos series de tiempo cointegradas (como X e Y mencionadas anteriormente) se acercan y se alejan una de la otra, hay momentos en que hay una base alta y una base baja. Realizamos operaciones de pares comprando una inversión y vendiendo otra. De esta forma, si los dos objetivos de inversión caen o suben simultáneamente, ni ganamos ni perdemos dinero, es decir, somos neutrales respecto del mercado.
Volviendo a X e Y en Y = ⍺ X + e anterior, ganamos dinero haciendo que la relación (Y/X) se mueva alrededor de su media ⍺. Para ello, observamos que cuando X Cuando el valor de ⍺ es demasiado alto o demasiado bajo, el valor de ⍺ es demasiado alto o demasiado bajo:
-
Ratio largo: es cuando el ratio ⍺ es pequeño y esperamos que se haga más grande. En el ejemplo anterior, abrimos una posición comprando Y y vendiendo X.
-
Ratio corto: es cuando el ratio ⍺ es grande y esperamos que se vuelva más pequeño. En el ejemplo anterior, abrimos una posición vendiendo en corto Y y comprando en largo X.
Tenga en cuenta que siempre tenemos una “posición cubierta”: si la posición larga subyacente pierde valor, la posición corta gana dinero, y viceversa, por lo que somos inmunes a los movimientos generales del mercado.
A medida que los activos X e Y se mueven uno respecto del otro, ganamos o perdemos dinero.
Utilice datos para encontrar transacciones con comportamiento similar
La mejor manera de hacerlo es comenzar con las operaciones que sospecha que pueden estar cointegradas y realizar pruebas estadísticas. Si realiza una prueba estadística en todos los pares comerciales, podrá:Sesgo de comparaciones múltiplesvíctima de.
Sesgo de comparaciones múltiplesse refiere a la situación en la que la probabilidad de generar falsamente un valor p significativo aumenta cuando se ejecutan muchas pruebas, porque necesitamos ejecutar una gran cantidad de pruebas. Si ejecutamos esta prueba 100 veces con datos aleatorios, deberíamos ver 5 valores p por debajo de 0,05. Si está comparando n instrumentos para la cointegración, realizará n(n-1)/2 comparaciones y verá muchos valores p incorrectos, que aumentarán a medida que aumente el tamaño de la muestra de prueba. Y aumentará. Para evitar esto, seleccione algunos pares comerciales que crea que es probable que estén cointegrados y luego pruébelos individualmente. Esto reducirá en gran medidaSesgo de comparaciones múltiples。
Así que, tratemos de encontrar algunos instrumentos que muestren cointegración. Tomemos una canasta de acciones tecnológicas estadounidenses de gran capitalización en el S&P 500. Estos instrumentos operan en segmentos de mercado similares y muestran cointegración. Escaneamos la lista de instrumentos comerciales y probamos la cointegración entre todos los pares.
Se incluyen la matriz de puntuación de la prueba de cointegración devuelta, la matriz de valor p y todas las coincidencias por pares con un valor p menor que 0,05.Este método es propenso a sesgos de comparación múltiple, por lo que en la práctica es necesario realizar una segunda validación. En este artículo, para facilitar nuestra explicación, decidimos ignorar esto en los ejemplos.
def find_cointegrated_pairs(data):
n = data.shape[1]
score_matrix = np.zeros((n, n))
pvalue_matrix = np.ones((n, n))
keys = data.keys()
pairs = []
for i in range(n):
for j in range(i+1, n):
S1 = data[keys[i]]
S2 = data[keys[j]]
result = coint(S1, S2)
score = result[0]
pvalue = result[1]
score_matrix[i, j] = score
pvalue_matrix[i, j] = pvalue
if pvalue < 0.02:
pairs.append((keys[i], keys[j]))
return score_matrix, pvalue_matrix, pairs
Nota: Hemos incluido el índice de referencia del mercado (SPX) en nuestros datos: el mercado impulsa el flujo de muchos instrumentos y, a menudo, puede encontrar dos instrumentos que parecen estar cointegrados; pero, de hecho, no están cointegrados entre sí, sino cointegrados con el mercado. Esto se denomina variable de confusión. Es importante examinar la participación en el mercado en cualquier relación que encuentre.
from backtester.dataSource.yahoo_data_source import YahooStockDataSource
from datetime import datetime
startDateStr = '2007/12/01'
endDateStr = '2017/12/01'
cachedFolderName = 'yahooData/'
dataSetId = 'testPairsTrading'
instrumentIds = ['SPY','AAPL','ADBE','SYMC','EBAY','MSFT','QCOM',
'HPQ','JNPR','AMD','IBM']
ds = YahooStockDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds,
startDateStr=startDateStr,
endDateStr=endDateStr,
event='history')
data = ds.getBookDataByFeature()['Adj Close']
data.head(3)

Ahora intentemos encontrar pares comerciales cointegrados usando nuestro método.
# Heatmap to show the p-values of the cointegration test
# between each pair of stocks
scores, pvalues, pairs = find_cointegrated_pairs(data)
import seaborn
m = [0,0.2,0.4,0.6,0.8,1]
seaborn.heatmap(pvalues, xticklabels=instrumentIds,
yticklabels=instrumentIds, cmap=’RdYlGn_r’,
mask = (pvalues >= 0.98))
plt.show()
print pairs
[('ADBE', 'MSFT')]
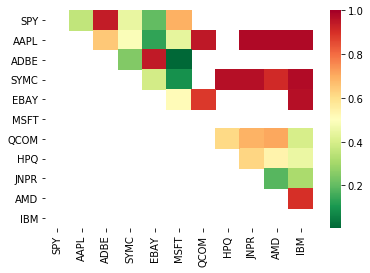
Parece que 'ADBE' y 'MSFT' están cointegrados. Echemos un vistazo al precio para asegurarnos de que realmente tenga sentido.
S1 = data['ADBE']
S2 = data['MSFT']
score, pvalue, _ = coint(S1, S2)
print(pvalue)
ratios = S1 / S2
ratios.plot()
plt.axhline(ratios.mean())
plt.legend([' Ratio'])
plt.show()
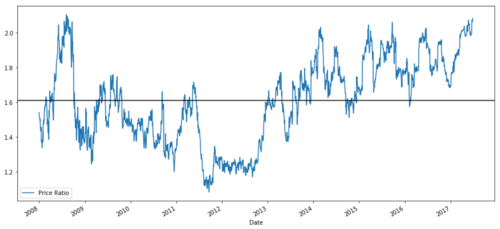
Gráfico de la relación de precios entre MSFT y ADBE de 2008 a 2017
Esta relación parece un promedio estable. Las razones absolutas no son muy útiles estadísticamente. Es más útil normalizar nuestra señal viéndola como una puntuación z. La puntuación Z se define como:
Z Score (Value) = (Value — Mean) / Standard Deviation
advertir
En la práctica, normalmente intentamos aplicar alguna expansión a los datos, pero sólo si estos se distribuyen normalmente. Sin embargo, muchos datos financieros no tienen una distribución normal, por lo que debemos tener mucho cuidado de no asumir simplemente la normalidad o alguna distribución particular al generar estadísticas. La verdadera distribución de los ratios puede tener colas gruesas, y los datos que tienden hacia los extremos pueden confundir nuestro modelo y dar lugar a enormes pérdidas.
def zscore(series):
return (series - series.mean()) / np.std(series)
zscore(ratios).plot()
plt.axhline(zscore(ratios).mean())
plt.axhline(1.0, color=’red’)
plt.axhline(-1.0, color=’green’)
plt.show()
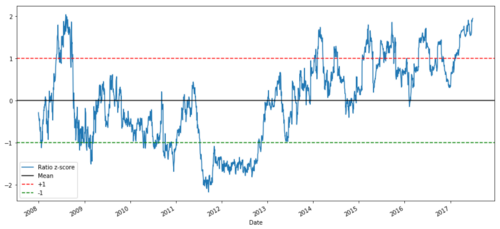
Relación precio-Z entre MSFT y ADBE de 2008 a 2017
Ahora es más fácil ver cómo la relación se mueve alrededor de la media, pero a veces tiende a tener grandes desviaciones de la media, que podemos explotar.
Ahora que hemos analizado los conceptos básicos de una estrategia de trading de pares e identificado objetivos de cointegración basados en el historial de precios, intentemos desarrollar una señal de trading. Primero, revisemos los pasos para desarrollar señales comerciales utilizando técnicas de datos:
-
Recopilación de datos fiables y limpieza de datos
-
Crear funciones a partir de datos para identificar señales/lógicas comerciales
-
Las características pueden ser promedios móviles o datos de precios, correlaciones o proporciones de señales más complejas: combínelas para crear nuevas características.
-
Utilice estas funciones para generar señales comerciales, es decir, qué señales son posiciones de compra, venta o cortas.
Afortunadamente, contamos con la plataforma cuantitativa Inventor (fmz.com) para completar los cuatro aspectos anteriores. Esto es una gran bendición para los desarrolladores de estrategias. Podemos dedicar nuestra energía y tiempo a la lógica de la estrategia, el diseño y la expansión funcional.
En la plataforma cuantitativa Inventor, hay interfaces empaquetadas de varios intercambios principales. Todo lo que tenemos que hacer es llamar a estas interfaces API. El resto de la lógica de implementación subyacente ha sido pulida por un equipo profesional.
En aras de la completitud lógica y la explicación de los principios, presentaremos estas lógicas subyacentes de manera detallada, pero en la operación real, los lectores pueden llamar directamente a la interfaz API de Inventor Quant para completar los cuatro aspectos anteriores.
Empecemos:
Paso 1: Configura tu problema
Aquí estamos intentando crear una señal que nos diga si la relación será de compra o de venta en el próximo momento, que es nuestra variable predictora Y:
Y = Ratio is buy (1) or sell (-1)
Y(t)= Sign(Ratio(t+1) — Ratio(t))
Tenga en cuenta que no necesitamos predecir el precio real del activo subyacente, o incluso el valor real de la relación (aunque podemos hacerlo), solo necesitamos predecir la dirección de la relación a continuación.
Paso 2: Recopilar datos fiables y precisos
¡Inventor Quant es tu amigo! Simplemente especifique los instrumentos que desea negociar y la fuente de datos que desea utilizar, y extraerá los datos necesarios y los limpiará para las divisiones de dividendos e instrumentos. Así que nuestros datos aquí ya están muy limpios.
Utilizamos los siguientes datos de Yahoo Finance para los días de negociación durante los últimos 10 años (aproximadamente 2500 puntos de datos): apertura, cierre, máximo, mínimo y volumen.
Paso 3: Dividir los datos
No olvides este paso tan importante: probar la precisión de tu modelo. Estamos utilizando la siguiente división de entrenamiento/validación/prueba de los datos
-
Training 7 years ~ 70%
-
Test ~ 3 years 30%
ratios = data['ADBE'] / data['MSFT']
print(len(ratios))
train = ratios[:1762]
test = ratios[1762:]
Lo ideal sería que también hiciéramos un conjunto de validación, pero no lo haremos por ahora.
Paso 4: Ingeniería de características
¿Cuales podrían ser las funciones relacionadas? Queremos predecir la dirección del cambio de relación. Hemos visto que nuestros dos instrumentos están cointegrados, por lo que esta relación tenderá a desplazarse y volver a la media. Parece que nuestra característica debería ser alguna medida de la media de la relación, y la diferencia entre el valor actual y la media puede generar nuestra señal comercial.
Utilizamos las siguientes funciones:
-
Promedio móvil de 60 días: una medida del promedio móvil
-
Promedio móvil de 5 días: una medida del valor actual del promedio
-
Desviación estándar de 60 días
-
Puntuación z: (media móvil de 5 días - media móvil de 60 días) / desviación estándar de 60 días
ratios_mavg5 = train.rolling(window=5,
center=False).mean()
ratios_mavg60 = train.rolling(window=60,
center=False).mean()
std_60 = train.rolling(window=60,
center=False).std()
zscore_60_5 = (ratios_mavg5 - ratios_mavg60)/std_60
plt.figure(figsize=(15,7))
plt.plot(train.index, train.values)
plt.plot(ratios_mavg5.index, ratios_mavg5.values)
plt.plot(ratios_mavg60.index, ratios_mavg60.values)
plt.legend(['Ratio','5d Ratio MA', '60d Ratio MA'])
plt.ylabel('Ratio')
plt.show()
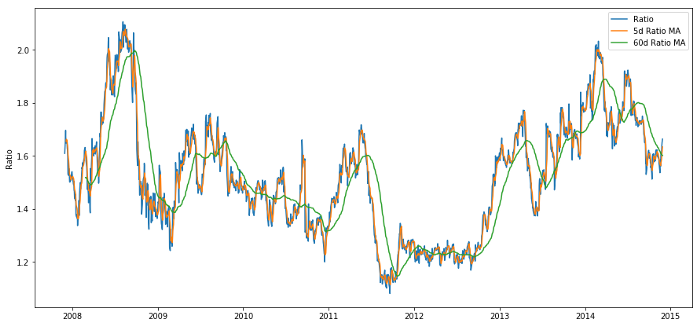
Relación de precios entre las medias móviles de 60 días y 5 días
plt.figure(figsize=(15,7))
zscore_60_5.plot()
plt.axhline(0, color='black')
plt.axhline(1.0, color='red', linestyle='--')
plt.axhline(-1.0, color='green', linestyle='--')
plt.legend(['Rolling Ratio z-Score', 'Mean', '+1', '-1'])
plt.show()
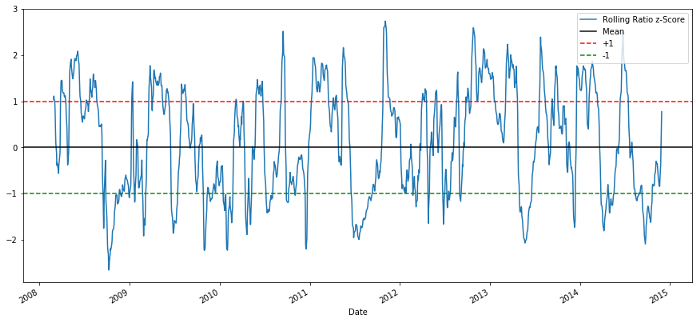
Relación precio-puntuación Z 60-5
¡La puntuación Z de la media móvil realmente resalta la naturaleza de reversión a la media de la relación!
Paso 5: Selección del modelo
Comencemos con un modelo muy simple. Al observar el gráfico de puntuación z, podemos ver que siempre que la puntuación z es demasiado alta o demasiado baja, retrocede. Utilicemos +1/-1 como nuestros umbrales para definir demasiado alto y demasiado bajo, luego podemos usar el siguiente modelo para generar señales comerciales:
-
Cuando z está por debajo de -1,0, la relación es de (1) porque esperamos que z vuelva a 0, por lo que la relación aumenta.
-
Cuando z está por encima de 1,0, la relación es de venta (-1) porque esperamos que z vuelva a 0, disminuyendo así la relación.
Paso 6: Capacitación, validación y optimización
Finalmente, ¿veamos el impacto real de nuestro modelo en los datos reales? Veamos cómo se comporta esta señal en proporciones reales.
# Plot the ratios and buy and sell signals from z score
plt.figure(figsize=(15,7))
train[60:].plot()
buy = train.copy()
sell = train.copy()
buy[zscore_60_5>-1] = 0
sell[zscore_60_5<1] = 0
buy[60:].plot(color=’g’, linestyle=’None’, marker=’^’)
sell[60:].plot(color=’r’, linestyle=’None’, marker=’^’)
x1,x2,y1,y2 = plt.axis()
plt.axis((x1,x2,ratios.min(),ratios.max()))
plt.legend([‘Ratio’, ‘Buy Signal’, ‘Sell Signal’])
plt.show()
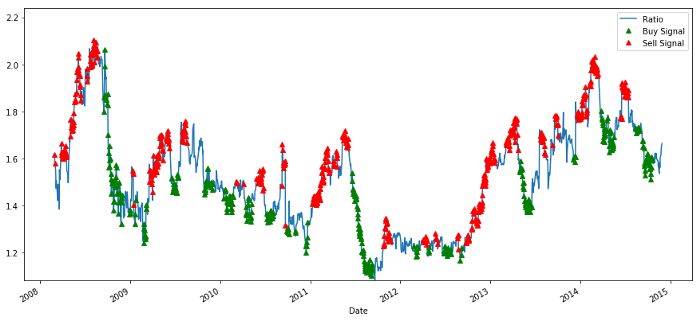
Señales de relación de precios de compra y venta
Esta señal parece razonable, parecemos vender la relación cuando es alta o está aumentando (puntos rojos) y volver a comprarla cuando es baja (puntos verdes) y está disminuyendo. ¿Qué significa esto para el objeto real de nuestras transacciones? vamos a ver
# Plot the prices and buy and sell signals from z score
plt.figure(figsize=(18,9))
S1 = data['ADBE'].iloc[:1762]
S2 = data['MSFT'].iloc[:1762]
S1[60:].plot(color='b')
S2[60:].plot(color='c')
buyR = 0*S1.copy()
sellR = 0*S1.copy()
# When buying the ratio, buy S1 and sell S2
buyR[buy!=0] = S1[buy!=0]
sellR[buy!=0] = S2[buy!=0]
# When selling the ratio, sell S1 and buy S2
buyR[sell!=0] = S2[sell!=0]
sellR[sell!=0] = S1[sell!=0]
buyR[60:].plot(color='g', linestyle='None', marker='^')
sellR[60:].plot(color='r', linestyle='None', marker='^')
x1,x2,y1,y2 = plt.axis()
plt.axis((x1,x2,min(S1.min(),S2.min()),max(S1.max(),S2.max())))
plt.legend(['ADBE','MSFT', 'Buy Signal', 'Sell Signal'])
plt.show()
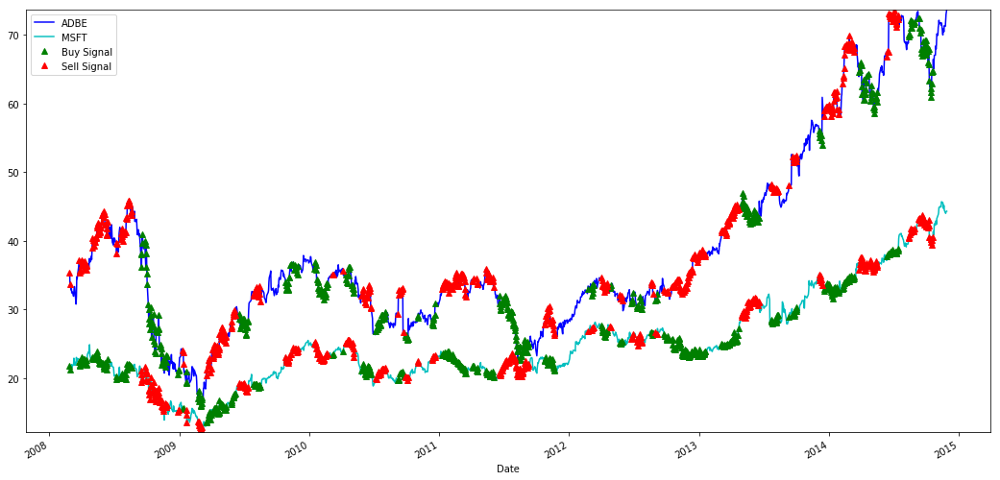
Señales para comprar y vender acciones de MSFT y ADBE
Observe cómo a veces ganamos dinero en la "pierna corta", a veces en la "pierna larga" y a veces en ambas.
Estamos contentos con la señal de los datos de entrenamiento. Veamos qué tipo de beneficio puede generar esta señal. Podemos hacer un backtester simple que compre 1 ratio (compre 1 acción de ADBE y venda ratio x acción de MSFT) cuando el ratio sea bajo y venda 1 ratio (venda 1 acción de ADBE y call ratio x acción de MSFT) y calcule las operaciones de PnL para estas proporciones.
# Trade using a simple strategy
def trade(S1, S2, window1, window2):
# If window length is 0, algorithm doesn't make sense, so exit
if (window1 == 0) or (window2 == 0):
return 0
# Compute rolling mean and rolling standard deviation
ratios = S1/S2
ma1 = ratios.rolling(window=window1,
center=False).mean()
ma2 = ratios.rolling(window=window2,
center=False).mean()
std = ratios.rolling(window=window2,
center=False).std()
zscore = (ma1 - ma2)/std
# Simulate trading
# Start with no money and no positions
money = 0
countS1 = 0
countS2 = 0
for i in range(len(ratios)):
# Sell short if the z-score is > 1
if zscore[i] > 1:
money += S1[i] - S2[i] * ratios[i]
countS1 -= 1
countS2 += ratios[i]
print('Selling Ratio %s %s %s %s'%(money, ratios[i], countS1,countS2))
# Buy long if the z-score is < 1
elif zscore[i] < -1:
money -= S1[i] - S2[i] * ratios[i]
countS1 += 1
countS2 -= ratios[i]
print('Buying Ratio %s %s %s %s'%(money,ratios[i], countS1,countS2))
# Clear positions if the z-score between -.5 and .5
elif abs(zscore[i]) < 0.75:
money += S1[i] * countS1 + S2[i] * countS2
countS1 = 0
countS2 = 0
print('Exit pos %s %s %s %s'%(money,ratios[i], countS1,countS2))
return money
trade(data['ADBE'].iloc[:1763], data['MSFT'].iloc[:1763], 60, 5)
El resultado es: 1783.375
¡Entonces esta estrategia parece ser rentable! Ahora, podemos optimizar aún más cambiando la ventana de tiempo del promedio móvil, cambiando los umbrales para las posiciones de compra/venta y cierre, etc. y verificar las mejoras de rendimiento en los datos de validación.
También podemos probar modelos más complejos como regresión logística, SVM, etc. para predicciones 1/-1.
Ahora, avancemos en este modelo, lo que nos lleva a
Paso 7: Realizar una prueba retrospectiva de los datos de prueba
Aquí me gustaría mencionar la plataforma cuantitativa Inventor. Utiliza un motor de backtesting QPS/TPS de alto rendimiento para reproducir fielmente el entorno histórico, eliminar las trampas comunes del backtesting cuantitativo y descubrir rápidamente las deficiencias de la estrategia, a fin de proporcionar una mejor información real. -Inversión de tiempo. Ofrezca ayuda.
Para explicar el principio, este artículo opta por mostrar la lógica subyacente. En la práctica, se recomienda que los lectores utilicen la plataforma cuantitativa Inventor. Además de ahorrar tiempo, lo importante es mejorar la tasa de tolerancia a fallos.
El backtesting es sencillo. Podemos utilizar la función anterior para ver el PnL de los datos de prueba.
trade(data[‘ADBE’].iloc[1762:], data[‘MSFT’].iloc[1762:], 60, 5)
El resultado es: 5262.868
¡Este modelo está muy bien hecho! Se convirtió en nuestro primer modelo simple de trading de pares.
Evite el sobreajuste
Antes de terminar, quiero hablar específicamente sobre el sobreajuste. El sobreajuste es la trampa más peligrosa en las estrategias comerciales. Un algoritmo de sobreajuste puede funcionar extremadamente bien en pruebas retrospectivas, pero fallar con datos nuevos no vistos, lo que significa que en realidad no revela ninguna tendencia en los datos y no tiene poder predictivo real. Tomemos un ejemplo sencillo:
En nuestro modelo, utilizamos estimaciones de parámetros móviles y esperamos optimizar la duración de la ventana de tiempo. Podríamos decidir simplemente iterar sobre todas las posibilidades, longitudes de ventana de tiempo razonables, y elegir la longitud de tiempo en función de la cual nuestro modelo funcione mejor. A continuación, escribimos un bucle simple para puntuar las longitudes de las ventanas de tiempo en función del PNL de los datos de entrenamiento y encontrar el mejor bucle.
# Find the window length 0-254
# that gives the highest returns using this strategy
length_scores = [trade(data['ADBE'].iloc[:1762],
data['MSFT'].iloc[:1762], l, 5)
for l in range(255)]
best_length = np.argmax(length_scores)
print ('Best window length:', best_length)
('Best window length:', 40)
Ahora verificamos el rendimiento del modelo en los datos de prueba y vemos que esta ventana de tiempo está lejos de ser óptima. Esto se debe a que nuestra elección original claramente se ajusta demasiado a los datos de muestra.
# Find the returns for test data
# using what we think is the best window length
length_scores2 = [trade(data['ADBE'].iloc[1762:],
data['MSFT'].iloc[1762:],l,5)
for l in range(255)]
print (best_length, 'day window:', length_scores2[best_length])
# Find the best window length based on this dataset,
# and the returns using this window length
best_length2 = np.argmax(length_scores2)
print (best_length2, 'day window:', length_scores2[best_length2])
(40, 'day window:', 1252233.1395)
(15, 'day window:', 1449116.4522)
Es evidente que lo que funciona bien para nuestros datos de muestra no siempre produce buenos resultados en el futuro. Solo para probar, grafiquemos los puntajes de longitud calculados a partir de los dos conjuntos de datos.
plt.figure(figsize=(15,7))
plt.plot(length_scores)
plt.plot(length_scores2)
plt.xlabel('Window length')
plt.ylabel('Score')
plt.legend(['Training', 'Test'])
plt.show()
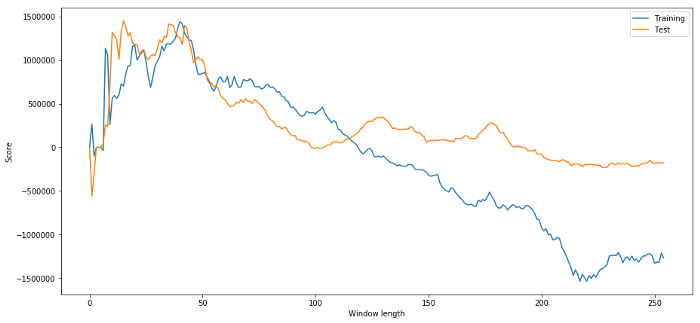
Podemos ver que cualquier valor entre 20 y 50 es una buena opción para la ventana de tiempo.
Para evitar el sobreajuste, podemos utilizar el razonamiento económico o las propiedades del algoritmo para elegir la longitud de la ventana de tiempo. También podemos utilizar un filtro Kalman, que no requiere que especifiquemos una longitud; este método se tratará más adelante en otro artículo.
Próximo paso
En este artículo, presentamos algunos métodos introductorios simples para demostrar el proceso de desarrollo de una estrategia comercial. En la práctica, se deben utilizar estadísticas más sofisticadas y se pueden considerar las siguientes opciones:
-
exponente de hurst
-
La vida media de reversión a la media inferida a partir del proceso de Ornstein-Uhlenbeck
-
Filtro Kalman
