
Une explication complète des avantages et des inconvénients des trois grandes catégories et des six principaux algorithmes de l'apprentissage automatique
Dans l'apprentissage automatique, l'objectif est soit la prédiction, soit le clustering. Le présent article se concentre sur la prédiction. La prédiction est le processus d'estimation de la valeur d'une variable de sortie à partir d'un ensemble de variables d'entrée. Par exemple, en obtenant un ensemble de caractéristiques sur une maison, nous pouvons prédire son prix de vente.
Pour cela, nous allons jeter un coup d'œil aux algorithmes les plus importants et les plus couramment utilisés dans l'apprentissage automatique. Nous les avons classés en 3 catégories: modèles linéaires, modèles basés sur des arbres et réseaux neuronaux.
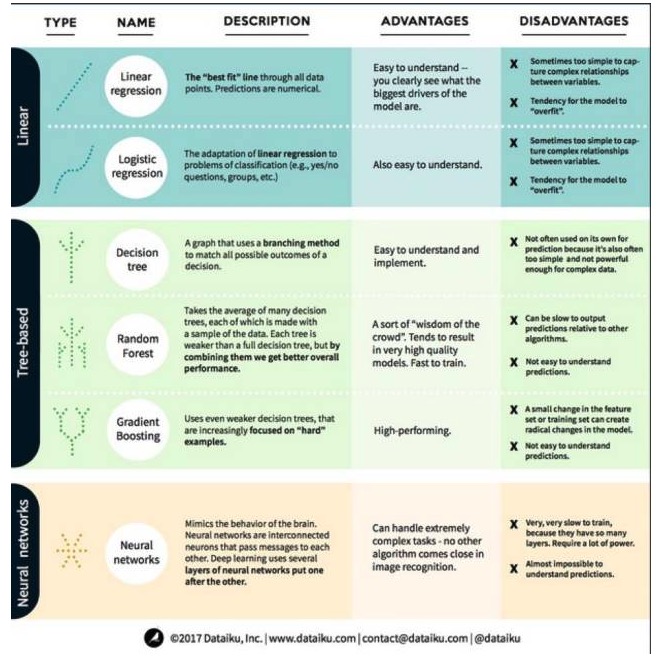
Les algorithmes de modélisation linéaire: les modèles linéaires utilisent des formules simples pour trouver la ligne qui correspond le mieux à un ensemble de points de données. Cette méthode remonte à plus de 200 ans et est largement utilisée dans les domaines de la statistique et de l'apprentissage automatique.
-
1. régression linéaire
La régression linéaire, ou plus précisément la régression linéaire à deux fois la plus petite, est la forme la plus standard d'un modèle linéaire. Pour les problèmes de régression, la régression linéaire est le modèle linéaire le plus simple. Son inconvénient est que le modèle est facilement suradapté, c'est-à-dire qu'il s'adapte parfaitement aux données déjà entraînées au détriment de sa capacité à se propager à de nouvelles données.
Un autre inconvénient des modèles linéaires est qu'ils sont si simples qu'ils ne prédisent pas facilement le comportement des variables plus complexes lorsque les entrées ne sont pas indépendantes.
-
2. Retour logique
La régression logique est l'adaptation de la régression linéaire aux problèmes de classification. Elle présente les mêmes inconvénients que la régression linéaire. La fonction logique est très bonne pour les problèmes de classification car elle introduit l'effet de seuil.
Deuxièmement, les algorithmes de modélisation d'arbres
-
1. Arbre décisionnel
Un arbre de décision est une représentation graphique de chaque résultat possible d'une décision utilisant une méthode de branche. Disons que vous décidez de commander une salade, votre première décision est probablement le type de légumes, puis le type de plats, puis le type de salade. Nous pouvons représenter tous les résultats possibles dans un arbre de décision.
Pour former un arbre de décision, nous avons besoin d'utiliser un ensemble de données d'entraînement et de trouver l'attribut le plus utile pour la cible. Par exemple, dans un cas d'utilisation de détection de fraude, nous pourrions trouver que l'attribut qui a le plus d'impact sur la prévision du risque de fraude est le pays. Après avoir branché avec la première propriété, nous obtenons deux sous-ensembles, ce qui est le plus prévisible si nous ne connaissions que la première propriété.
-
2 - La forêt au hasard
Une forêt aléatoire est une moyenne de plusieurs arbres de décision, chacun d'entre eux étant entraîné avec un échantillon de données aléatoires. Chaque arbre dans une forêt aléatoire est plus faible qu'un arbre de décision complet, mais en mettant tous les arbres ensemble, nous obtenons de meilleures performances globales en raison de l'avantage de diversité.
La forêt aléatoire est un algorithme très populaire dans l'apprentissage automatique d'aujourd'hui. La forêt aléatoire est facile à entraîner et fonctionne assez bien. Son inconvénient est que la prévision de la sortie de la forêt aléatoire peut être lente par rapport aux autres algorithmes, donc la forêt aléatoire peut ne pas être choisie lorsque des prévisions rapides sont nécessaires.
-
3e, une augmentation de la gradience
GradientBoosting, comme les forêts aléatoires, est composé d'arbres de décision qui se déforment. La plus grande différence avec les forêts aléatoires est que, dans le gradient, les arbres sont entraînés un par un. Chaque arbre arrière est principalement entraîné par les arbres avant qui identifient les données erronées. Cela rend le gradient moins attentif aux situations faciles à prévoir et plus attentif aux situations difficiles.
L'entraînement à l'élévation de la gradiente est rapide et très performant. Cependant, de petites modifications du jeu de données d'entraînement peuvent modifier radicalement le modèle, de sorte que les résultats qu'il produit peuvent ne pas être les plus viables.
Les réseaux neuronaux sont des phénomènes biologiques constitués de neurones interconnectés dans le cerveau qui échangent des informations entre eux. Cette idée est maintenant appliquée au domaine de l'apprentissage automatique, appelé ANN (réseau neuronal artificiel). L'apprentissage en profondeur est un réseau neuronal à plusieurs niveaux superposés.
Le projet a été lancé par le gouvernement de la République démocratique du Congo.
- 1