Comparaison de 8 algorithmes d'apprentissage automatique
 0
6946
0
6946
Comparaison de 8 algorithmes d’apprentissage automatique
L’article présente principalement les scénarios d’adaptation des algorithmes les plus couramment utilisés et leurs avantages et inconvénients.
Il y a tellement d’algorithmes d’apprentissage automatique, de classification, de régression, de regroupement, de recommandation, de reconnaissance d’images, etc., qu’il n’est pas facile de trouver un algorithme adapté, donc dans les applications réelles, nous utilisons généralement l’apprentissage inspiré pour expérimenter.
En général, au début, nous choisissons des algorithmes que nous reconnaissons généralement, tels que SVM, GBDT, Adaboost, l’apprentissage en profondeur est en vogue, et les réseaux neuronaux sont un bon choix.
Si vous vous souciez de l’exactitude, la meilleure façon de procéder est de tester et de comparer les algorithmes un par un, en procédant à une validation croisée, puis d’ajuster les paramètres pour s’assurer que chaque algorithme atteint la solution optimale, et de choisir la meilleure solution.
Mais si vous cherchez simplement un algorithme qui soit assez bon pour résoudre votre problème, ou si vous avez des astuces à suivre, nous allons analyser les avantages et les inconvénients de chaque algorithme, afin de vous aider à choisir celui qui vous convient le mieux.
- ## Écarts et disparités
En statistique, un modèle est une mesure de la qualité ou de la qualité d’une variance, donc nous allons d’abord généraliser la variance et la variance:
Écarts: décrivent l’écart entre les valeurs de prévision (valeur estimée) des valeurs E et les valeurs réelles Y. Plus l’écart est grand, plus les données sont éloignées.
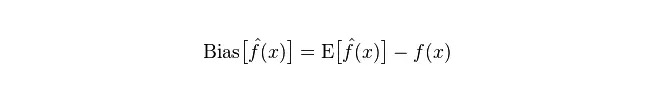
Le décalage, qui décrit la variation de la valeur prévue de P, est le décalage de la valeur prévue, c’est-à-dire sa distance de la valeur attendue de E. Plus le décalage est grand, plus la distribution des données est dispersée.
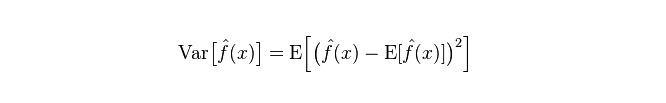
L’erreur réelle du modèle est la somme des deux, comme le montre le graphique suivant:
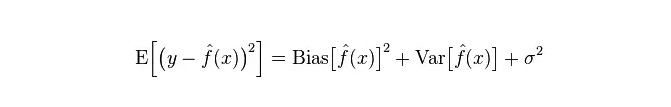
Si c’est un petit ensemble d’entraînement, un classificateur à haute déviance/à faible écart (par exemple, un simple Bayesian NB) est plus avantageux qu’un classificateur à faible déviance/à grande écart (par exemple, un KNN), car ce dernier est suradapté.
Cependant, à mesure que votre ensemble d’entraînement augmente, les modèles deviennent de meilleures prédictions sur les données initiales, et le biais diminue, au point que les classificateurs bas/haut-différences commencent à montrer leur avantage (parce qu’ils ont une plus faible erreur de rapprochement), et les classificateurs haut-différenciés ne sont plus suffisants pour fournir un modèle précis.
Bien sûr, on peut aussi considérer que c’est une différence entre le modèle de génération (NB) et le modèle de jugement (KNN).
- ## Pourquoi la simplicité de Bayes est-elle une haute divergence ou une faible divergence ?
Le message suivant est tiré de:
Tout d’abord, supposons que vous connaissiez la relation entre les ensembles d’entraînement et les ensembles de test. En termes simples, nous allons apprendre un modèle sur les ensembles d’entraînement, puis utiliser les ensembles de test.
Mais bien souvent, nous pouvons seulement supposer que les ensembles de test et d’entraînement correspondent à la même distribution de données, mais nous n’obtenons pas de véritables données de test. Alors pourquoi mesurer le taux d’erreur de test en ne voyant que le taux d’erreur d’entraînement ?
Comme il y a peu d’échantillons d’entraînement (ou du moins pas assez), le modèle obtenu par l’ensemble d’entraînement n’est pas toujours vraiment correct. Même s’il est correct à 100% sur l’ensemble d’entraînement, cela ne signifie pas qu’il trace une distribution de données réelle.
De plus, dans la pratique, les échantillons d’entraînement ont tendance à avoir une certaine erreur de bruit, de sorte que si vous cherchez trop la perfection dans les ensembles d’entraînement et que vous utilisez un modèle très complexe, le modèle prend toutes les erreurs dans les ensembles d’entraînement comme de véritables caractéristiques de distribution de données, ce qui donne une estimation erronée de la distribution de données.
Dans ce cas, il y a une erreur flagrante dans les vrais ensembles de test (ce phénomène s’appelle l’adaptation). Cependant, il ne faut pas utiliser de modèles trop simples, sinon les modèles ne suffiront pas à représenter la distribution des données lorsque la distribution des données est plus complexe (ce phénomène est moins adapté, même dans les ensembles d’entraînement, car le taux d’erreur est élevé).
La suradaptation indique que le modèle utilisé est plus complexe que la distribution des données réelles, tandis que la sousadaptation indique que le modèle utilisé est plus simple que la distribution des données réelles.
Dans le cadre de l’apprentissage statistique, on considère que l’erreur = Bias + Variance lorsque l’on dessine la complexité d’un modèle. L’erreur peut être comprise comme le taux d’erreur de prédiction d’un modèle. Elle est composée de deux parties, l’une est l’inexactitude de l’estimation due au fait que le modèle est trop simple (Bias) et l’autre est l’espace de variation et l’incertitude plus grande due au fait que le modèle est trop complexe (Variance).
Ainsi, il est facile d’analyser un Bayesian simple. Son simple hypothèse que les données sont sans rapport entre elles est un modèle fortement simplifié. Ainsi, pour un modèle aussi simple, le partiel de Bias est plus grand que le partiel de Variance dans la plupart des cas, c’est-à-dire le partiel de haute variance et le partiel de basse variance.
En pratique, pour que l’erreur soit la plus petite possible, nous devons équilibrer le rapport entre le biais et la variance lors de la sélection du modèle, c’est-à-dire équilibrer le sur-ajustement et le sous-ajustement.
La relation entre l’écart et la différence carrées et la complexité du modèle est illustrée par le graphique suivant:
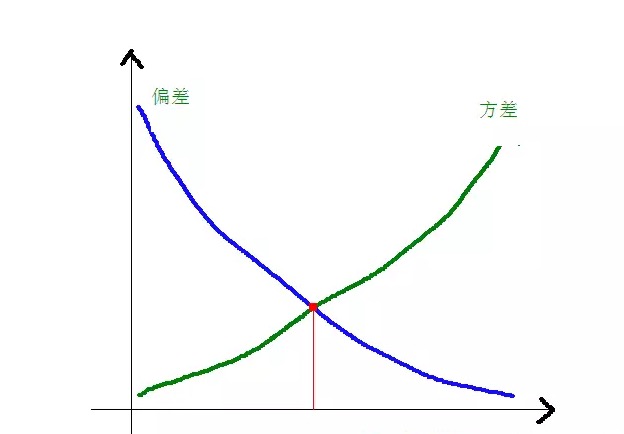
L’écart diminue progressivement et l’écart augmente progressivement à mesure que la complexité du modèle augmente.
-
Avantages et inconvénients des algorithmes courants
- ### 1. La petite Bayes
Les Bayes simplistes appartiennent aux modèles génératifs (en ce qui concerne les modèles génératifs et les modèles discriminatifs, il s’agit principalement de savoir s’il faut une distribution conjointe), très simple, vous faites juste une pile de calculs.
Si l’hypothèse d’indépendance conditionnelle est retenue (une condition plus stricte), le classificateur Bayesian simpliste converge plus rapidement que le modèle de discrimination, comme la régression logique, de sorte que vous n’avez besoin que de moins de données de formation. Même si l’hypothèse d’indépendance conditionnelle du NB n’est pas établie, le classificateur NB fonctionne toujours très bien dans la pratique.
Son principal inconvénient est qu’il ne peut pas apprendre l’interaction entre les personnages, et le R dans mRMR est la redondance des personnages. Pour citer un exemple plus classique, par exemple, même si vous aimez les films de Brad Pitt et Tom Cruise, il ne peut pas apprendre que vous n’aimez pas les films dans lesquels ils sont ensemble.
Les avantages:
Les modèles simplistes de Bayes sont basés sur la théorie mathématique classique, avec une base mathématique solide et une efficacité de classification stable. Il est très performant sur des données de petite taille, capable de gérer plusieurs types de tâches individuellement et adapté à l’entraînement additionnel. L’algorithme est moins sensible aux données manquantes et est plus simple. Il est souvent utilisé pour la classification de texte. Les défauts:
Il est nécessaire de calculer la probabilité initiale. Le taux d’erreur dans les décisions de classification; La forme d’expression des données d’entrée est sensible.
- ### 2. Retour logique
Il existe de nombreuses méthodes de modélisation de la régularisation (L0, L1, L2, etc.) et vous n’avez pas à vous soucier de la pertinence de vos caractéristiques comme vous le feriez avec un simple Bayesian.
Vous obtiendrez également une bonne interprétation des probabilités par rapport aux arbres de décision et aux machines SVM, et vous pourrez même facilement utiliser les nouvelles données pour mettre à jour le modèle (en utilisant un algorithme de descente de gradient en ligne).
Si vous avez besoin d’une architecture de probabilité (par exemple, pour ajuster simplement les seuils de classification, indiquer l’incertitude ou obtenir des intervalles de confiance), ou si vous souhaitez intégrer rapidement plus de données de formation dans le modèle ultérieurement, utilisez-la.
Fonction sigmoïde:
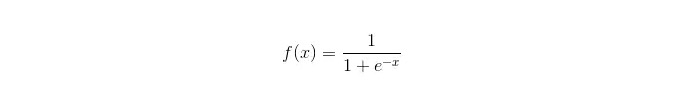
Les avantages: La réalisation d’une application simple et généralisée pour les problèmes industriels; Le classement est très petit, très rapide et manque de ressources de stockage. Un score de probabilité de l’échantillon d’observation est facilement obtenu. Pour la régression logique, la collinearité multiple n’est pas un problème, elle peut être résolue en combinaison avec la normalisation L2; Les défauts: La régression logique ne fonctionne pas très bien lorsque l’espace de caractéristiques est grand. Facile à manquer, généralement peu précis Une mauvaise gestion d’un grand nombre de traits ou variables multicolores; ne peut traiter que deux problèmes de classification (le softmax dérivé peut être utilisé pour plusieurs classes) et doit être divisible de manière linéaire; Pour les caractéristiques non linéaires, une conversion est nécessaire.
- ### 3. régression linéaire
La régression linéaire est utilisée pour la régression, contrairement à la régression logistique qui est utilisée pour la classification. L’idée de base est d’optimiser les fonctions d’erreur sous forme de plus petit quadratique en utilisant la régression en gradient décroissant, et bien sûr de trouver directement les paramètres de la solution avec l’équation normale, qui donne:
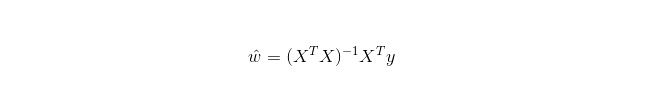
Dans la régression linéaire à pondération locale (LWLR), l’expression calculée du paramètre est:
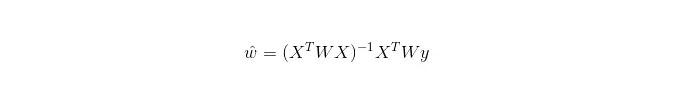
On peut ainsi voir que, contrairement au LR, le LWLR est un modèle non paramétrique, car chaque calcul de régression doit traverser l’échantillon d’entraînement au moins une fois.
Avantages: Simplicité de réalisation et de calcul.
Inconvénients: Ne peut pas être adapté à des données non linéaires.
- ### 4. Algorithme de voisinage le plus proche
KNN est l’algorithme de voisinage le plus proche, dont le processus principal est:
Calculer la distance de chaque point de l’échantillon d’entraînement et de l’échantillon de test (les mesures de distance les plus courantes sont la distance en euros, la distance en mars, etc.);
Sortir toutes les distances ci-dessus;
les k échantillons les plus éloignés;
Le classement final est obtenu par un vote sur la base de ces k échantillons de labels.
Le choix d’une valeur de K optimale dépend des données. En général, une valeur de K plus élevée lors de la classification réduit l’impact du bruit, mais les limites entre les catégories deviennent floues.
Une meilleure valeur de K peut être obtenue par diverses techniques de type enrichissement, telles que la vérification croisée. De plus, la présence de facteurs de caractéristiques de bruit et de non-corrélation réduit la précision des algorithmes de proximité de K.
L’algorithme de proximité a un résultat de cohérence plus fort. Avec des données allant à l’infini, l’algorithme est assuré que le taux d’erreur ne dépassera pas deux fois le taux d’erreur de l’algorithme de Bayes. Pour quelques bonnes valeurs de K, le taux d’erreur de proximité de K ne dépassera pas le taux d’erreur théorique de Bayes.
Les avantages de l’algorithme KNN
La théorie est mature, l’idée est simple, elle peut être utilisée à la fois pour la classification et pour la régression. Il peut être utilisé pour la classification non linéaire. la complexité du temps d’entraînement est O (n); Il n’y a pas d’hypothèses sur les données, la précision est élevée, et les outliers sont insensibles. défaut
Le calcul est lourd. Le problème du déséquilibre des échantillons (c’est-à-dire qu’il y a beaucoup d’échantillons pour certaines catégories et peu pour d’autres); La plupart d’entre eux ont été créés par des développeurs de logiciels.
- ### 5. Arbre de décision
Facile à interpréter. Il peut gérer sans stress les interactions entre les attributs et est non-paramétrique, de sorte que vous n’avez pas à vous soucier de l’anomalie ou de la linearité des données (par exemple, l’arbre de décision peut facilement gérer les cas où la catégorie A est à l’extrémité d’une certaine dimension de la fonction x, la catégorie B au milieu, puis la catégorie A apparaît à l’extrémité avant de la dimension de la fonction x).
L’un de ses inconvénients est qu’il ne prend pas en charge l’apprentissage en ligne, ce qui nécessite une reconstruction complète de l’arbre de décision lorsque de nouveaux échantillons arrivent.
Un autre inconvénient est la facilité d’une suradaptation, mais c’est aussi le point d’entrée d’une méthode d’intégration telle que la RF forêt aléatoire (ou l’amélioration d’un arbre boosté).
De plus, les forêts aléatoires sont souvent les gagnantes de nombreux problèmes de classification (généralement un peu plus que les machines à support vectoriel), elles sont entraînées rapidement et sont réglables, et vous n’avez pas à vous soucier de modifier une tonne de paramètres comme les machines à support vectoriel, donc elles ont toujours été populaires.
Il est important de choisir une branche d’un attribut dans un arbre de décision, donc attention à la formule de calcul de l’augmentation de l’information et à la comprendre en profondeur.
La formule de calcul de la boîte d’informations est la suivante:
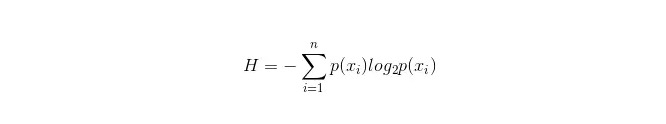
Dans ce cas, n représente n catégories de classification: (si, par exemple, il s’agit d’un problème de classe 2, alors n = 2) ◄ . Calculer respectivement la probabilité p1 et p2 que ces deux types d’échantillons apparaissent dans l’échantillon total, afin de pouvoir calculer la coquille d’informations avant la branche des attributs non sélectionnés ◄ .
Maintenant, sélectionnez un attribut xixi pour brancher. La règle de branche est la suivante: si xi = vxi = v, divisez l’échantillon dans une branche de l’arbre; si elle n’est pas égale, entrez dans une autre branche.
Il est évident que l’échantillon de branches comprend très probablement deux catégories, en calculant respectivement les branches H1 et H2 de ces branches, en calculant le total d’informations après la branche H = p1 H1 + p2 H2, le gain d’information ΔH = H - H. En utilisant le gain d’information comme principe, en testant toutes les propriétés d’un côté, choisissez l’une des propriétés qui augmente le plus comme propriété de la branche.
Les avantages de l’arbre de décision
Les calculs sont simples, faciles à comprendre et interprétables. les échantillons les plus appropriés pour traiter les attributs manquants; La capacité à traiter des traits non pertinents; La capacité à produire des résultats viables et efficaces sur de grandes sources de données en un temps relativement court. défaut
La suradaptation est fréquente (les forêts aléatoires peuvent réduire considérablement la suradaptation); Le problème est qu’il n’y a pas de lien entre les données. Pour les données dont le nombre de échantillons est incohérent dans les différentes catégories, les résultats de l’augmentation de l’information dans l’arbre de décision sont orientés vers ceux qui ont plus de caractéristiques de valeur numérique (ce défaut existe tant que l’augmentation de l’information est utilisée, comme RF).
- ### 5.1 Adaboosting
Adaboost est un modèle d’addition, où chaque modèle est construit sur la base du taux d’erreur du modèle précédent, en se concentrant sur les échantillons qui ont fait des erreurs, et en se concentrant moins sur les échantillons correctement classés. Après une iteration progressive, on obtient un modèle relativement meilleur.
avantage
Adaboost est un classificateur de haute précision. Il est possible de construire des sous-classificateurs par différentes méthodes, la structure étant fournie par l’algorithme Adaboost. Les résultats des calculs sont compréhensibles lorsqu’on utilise un classificateur simple, et la construction d’un classificateur faible est extrêmement simple. Il n’y a pas de filtrage des caractéristiques. Les surmontages sont rares. Pour les algorithmes combinés tels que les forêts aléatoires et les GBDT, voir l’article: Machine learning - Summary of combined algorithms
Inconvénients: plus sensible à l’outlier
- ### 6. Le support vectoriel SVM
Sa précision est élevée, ce qui fournit une bonne garantie théorique pour éviter les surcorrespondances, et même si les données sont indivisibles dans l’espace linéaire de la caractéristique initiale, elle fonctionne très bien si elle est donnée à une fonction de noyau appropriée.
Il est particulièrement populaire dans les problèmes de classification de texte dynamique et ultra-haut de gamme. Malheureusement, la mémoire consomme beaucoup, il est difficile de l’interpréter, l’exécution et le parallélisme sont un peu gênants, alors que la forêt aléatoire évite ces inconvénients et est plus pratique.
avantage Il est possible de résoudre des problèmes en haute dimension, c’est-à-dire dans un grand espace caractéristique. La capacité à traiter les interactions de traits non linéaires; Il n’est pas nécessaire de se fier à l’ensemble des données. La généralisation peut être améliorée.
défaut La plupart des observations sont effectuées sur des échantillons de la même espèce, mais il n’y a pas d’efficacité. Il n’y a pas de solution universelle à un problème non linéaire et il est parfois difficile de trouver une fonction nucléaire appropriée. La sensibilité aux données manquantes; Le libsvm est doté de quatre fonctions de noyau: noyau linéaire, noyau polynomial, noyau RBF et noyau sigmoïde:
Premièrement, si le nombre d’échantillons est inférieur au nombre de caractéristiques, il n’est pas nécessaire de choisir un noyau non linéaire, il suffit d’utiliser un noyau linéaire.
Deuxièmement, si le nombre d’échantillons est plus grand que le nombre de traits, un noyau non linéaire peut être utilisé pour cartographier l’échantillon dans une dimension plus élevée, ce qui donne généralement de meilleurs résultats.
Troisièmement, si le nombre d’échantillons et le nombre de traits sont égaux, on peut utiliser un noyau non linéaire, le principe étant le même que dans le second cas.
Dans le premier cas, on peut aussi réduire la dimension des données avant d’utiliser un noyau non linéaire, ce qui est une autre méthode.
- ### 7. Les avantages et les inconvénients des réseaux de neurones artificiels
Les avantages des réseaux neuronaux artificiels: La classification est très précise. La capacité de traitement distribué parallèle, de stockage distribué et d’apprentissage est forte. Il a une forte robustesse et une forte tolérance au bruit nerveux, ce qui lui permet de s’approcher de relations non linéaires complexes. Il est doté d’une mémoire de rappel.
Les réseaux neuronaux artificiels ont des inconvénients: Les réseaux neuronaux nécessitent un grand nombre de paramètres, tels que la topographie du réseau, les valeurs de pondération et les valeurs initiales des seuils; L’absence d’observation entre les processus d’apprentissage et la difficulté d’interprétation des résultats de sortie affecte la crédibilité et l’acceptabilité des résultats; L’apprentissage est trop long et peut même ne pas atteindre l’objectif.
- ### 8 K-Means groupe
J’ai écrit un article précédent sur le cluster K-Means, et il y a une puissante pensée EM à propos de la déduction de K-Means.
avantage L’algorithme est simple et facile à mettre en œuvre. Pour traiter de grands ensembles de données, l’algorithme est relativement évolutif et efficace, car sa complexité est d’environ O{\displaystyle O} nkt, où n est le nombre total d’objets, k le nombre de verges et t le nombre d’itérations. L’algorithme est généralement localisé. L’algorithme essaie de trouver la division k la plus petite de la fonction d’erreur carrée. L’agglomération est plus efficace lorsque le silicium est dense, sphérique ou globuleux, et que la distinction entre silicium et silicium est évidente.
défaut une plus grande exigence de type de données, adaptée aux données numériques; Peut converger à des valeurs minimales locales, mais plus lentement sur des données à grande échelle Les valeurs K sont plus difficiles à extraire; sensibles aux valeurs initiales de concentration, qui peuvent conduire à des résultats de regroupement différents pour des valeurs initiales différentes; Il n’est pas adapté pour la découverte d’une forme non convexe, ou d’une grande variété de tailles. Pour les données sensibles au bruit et aux points d’isolement, une petite quantité de données de ce type peut avoir un impact considérable sur la moyenne.
Algorithme de sélection de référence
L’un d’entre eux, qui a déjà traduit des articles en provenance de l’étranger, a donné une astuce simple pour choisir un algorithme:
La première chose à faire est de choisir la régression logique, qui, si elle n’est pas très efficace, peut être utilisée comme référence et comparée à d’autres algorithmes.
Ensuite, essayez les arbres de décision (forêts aléatoires) pour voir si vous pouvez améliorer considérablement les performances de votre modèle. Même si vous ne le considérez pas comme le modèle final, vous pouvez utiliser les forêts aléatoires pour supprimer les variables de bruit et faire des choix de caractéristiques.
Si le nombre de caractéristiques et d’échantillons observés est particulièrement élevé, alors l’utilisation de la SVM est une option lorsque les ressources et le temps sont suffisants (ce qui est important).
L’apprentissage en profondeur est très populaire, il est utilisé dans de nombreux domaines, il est basé sur des réseaux neuronaux, je suis moi-même en train d’apprendre, mais la connaissance théorique n’est pas très solide, la compréhension n’est pas assez profonde, je ne fais pas d’introduction ici.
L’algorithme est important, mais les bonnes données l’emportent sur les bonnes algorithmes, et les bonnes caractéristiques de conception sont très utiles. Si vous avez un ensemble de données très volumineux, le type d’algorithme que vous utilisez peut avoir peu d’impact sur les performances de classification (à ce moment-là, vous pouvez faire un choix basé sur la vitesse et la facilité d’utilisation).
-
Références