Expérience visuellement intuitive de 7 algorithmes de tri couramment utilisés (couramment utilisés pour les stratégies d'écriture)
 2
2056
2
2056
7 algorithmes de sélection couramment utilisés
Comment concevoir un programme scientifique avec le moins de dépense systémique possible (temps, ressources) alors qu’il est inévitable que le code d’un programme nécessite le tri des données lors de l’écriture de la stratégie ?
- ### 1. Sortir rapidement
Il a été arrêté en août.
Le tri rapide est un type d’algorithme de tri développé par Tony Hall. Dans le cas moyen, le tri de n objets nécessite ∞n log n) de comparaisons. Dans le cas le plus grave, ∞n2 de comparaisons sont nécessaires, mais ce n’est pas fréquent. En fait, le tri rapide est généralement nettement plus rapide que les autres algorithmes ∞n log n), car sa boucle interne ∞nner loop peut être réalisée avec une grande efficacité sur la plupart des architectures et sur la plupart des données du monde réel.
Les étapes:
Choisir un élément de l’arrêté, appelé pivot,
Réorganisez l’array de manière à ce que tous les éléments inférieurs à la valeur de référence soient placés devant la référence, et tous les éléments supérieurs à la valeur de référence soient placés derrière la référence (le même nombre peut aller de l’un ou de l’autre côté). Après cette sortie de partition, la référence est au milieu de l’array.
La récursivité (en anglais: recursive) ordonne les sous-ensembles inférieurs aux éléments de référence et les sous-ensembles supérieurs aux éléments de référence.
Effets de tri:
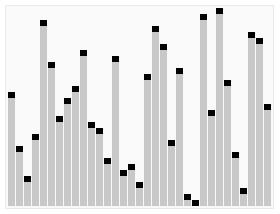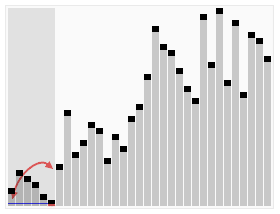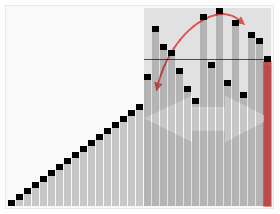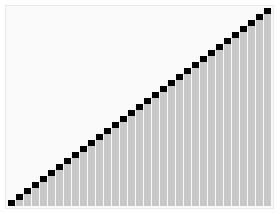
- ### 2. Résumé et séquence
Il a été arrêté en août.
Merge sort est un algorithme de tri efficace basé sur l’opération de fusion. Il s’agit d’une application très typique de la méthode Divide and Conquer.
Les étapes:
L’espace de requête, dont la taille est la somme de deux séquences déjà triées, est utilisé pour stocker les séquences fusionnées
Définition de deux pointeurs dont la position initiale correspond à la position initiale de deux séquences déjà triées
Comparer les éléments pointés par les deux pointeurs, choisir des éléments relativement petits à placer dans l’espace de fusion et déplacer le pointeur vers la position suivante
Répétez l’étape 3 jusqu’à ce qu’un pointeur atteigne la fin de la séquence
Copiez tous les éléments restants de l’autre séquence directement à la fin de la séquence de fusion
Effets de tri:

- ### 3. Sélection des piles
Il a été arrêté en août.
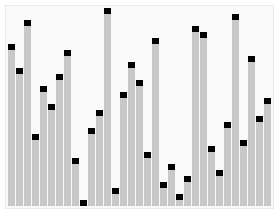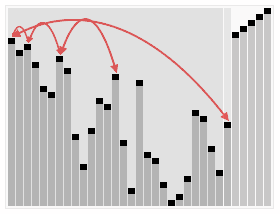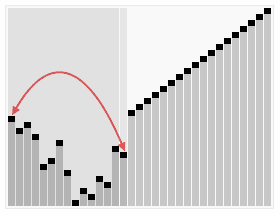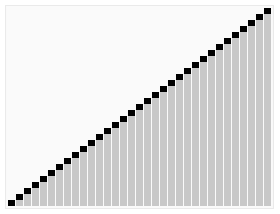
Le Heapsort est un algorithme de tri conçu à partir de la structure de l’en-tête. L’en-tête est une structure qui s’apparente à un arbre bissectrique complet, tout en respectant la propriété de l’en-tête: la valeur de la clé ou de l’index d’un sous-nœud est toujours inférieure à (ou supérieure à) son nœud parent.
Les étapes:
(C’est plus compliqué, allez voir vous-même sur Internet)
Effets de tri:
- ### 4. Sélectionnez la séquence
Il a été arrêté en août.
Selection sort est un algorithme de tri simple et intuitif. Il fonctionne comme suit: d’abord, on trouve le plus petit élément dans la séquence non triée, on le stocke à la position initiale de la séquence de tri, puis on continue à chercher le plus petit élément parmi les éléments non triés restants, puis on le place à la fin de la séquence de tri.
Effets de tri:

- ### 5. Sélection des bulles
Il a été arrêté en août.
Bubble Sort est un algorithme de tri simple. Il visite à plusieurs reprises les nombres que l’on veut trier, comparant à la fois les deux éléments, et les échangeant s’ils ont tort. Le travail de la colonne de visites se fait à plusieurs reprises jusqu’à ce qu’il n’y ait plus besoin d’échanger, c’est-à-dire que l’ordre est terminé.
Les étapes:
Comparez les éléments adjacents. Si le premier est plus grand que le second, échangez-en deux.
Faites la même chose pour chaque paire d’éléments adjacents, de la première paire au début jusqu’à la dernière paire à la fin. À ce stade, le dernier élément devrait être le plus grand nombre.
Répétez les étapes ci-dessus pour tous les éléments, sauf le dernier.
Répétez les étapes ci-dessus avec de moins en moins d’éléments jusqu’à ce qu’aucune paire de chiffres ne soit nécessaire.
Effets de tri:

- ### 6. Insérer une séquence
Il a été arrêté en août. L’Insertion Sort est un algorithme de tri simple et intuitif. Il fonctionne en construisant une séquence de données non triées, en les scannant de l’arrière vers l’avant dans la séquence triée, en trouvant la position correspondante et en les insérant. Le tri par insertion est généralement mis en œuvre en utilisant le tri en-place (c’est-à-dire le tri d’un espace supplémentaire de seulement O1), ce qui nécessite de déplacer progressivement les éléments triés vers l’arrière pour fournir un espace d’insertion pour les nouveaux éléments. Les étapes: À partir du premier élément, l’élément peut être considéré comme déjà trié. Prenez un élément et balayez d’avant en arrière dans une séquence d’éléments déjà triée Si l’élément est plus grand que le nouvel élément, déplacer l’élément à la position suivante Répétez l’étape 3 jusqu’à ce que vous trouviez un élément trié inférieur ou égal à la position du nouvel élément Insérer un nouvel élément dans cette position Répétez l’étape 2 Effets de tri: Il n’y en a pas.
- ### 7. Séquence de la colline
Il a été arrêté en août.
Le tri de Hill, aussi appelé algorithme de tri décroissant, est une version améliorée, rapide et stable, du tri par insertion.
La méthode de sélection de Hill est basée sur les deux propriétés suivantes de la sélection d’insertion:
1, l’insertion de tri est très efficace pour traiter des données presque triées, ce qui permet d’atteindre l’efficacité du tri linéaire
2/ Mais l’insertion est généralement inefficace car elle ne permet de déplacer les données qu’une seule fois.
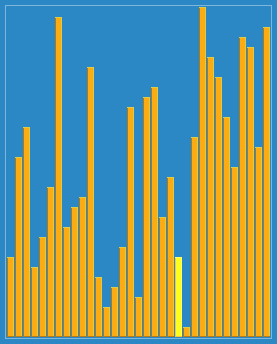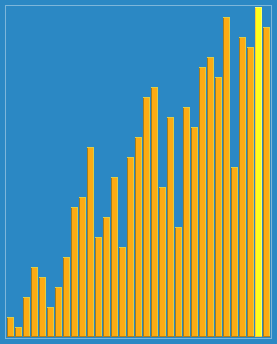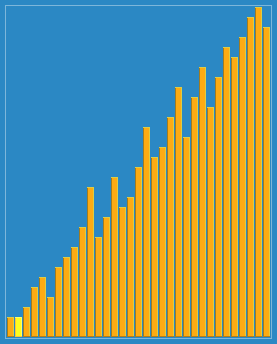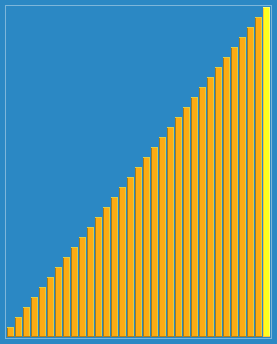
J’utilise le plus souvent la méthode de la mousse (la plus simple), et vous ?