Machine Learning pour le plaisir : le guide le plus simple pour débutants
 3
3605
3
3605
Machine Learning pour le plaisir : le guide le plus simple pour débutants
Quand vous entendez parler d’apprentissage automatique, avez-vous seulement une vague compréhension de ce que cela signifie ? Êtes-vous fatigué d’avoir à hocher la tête quand vous parlez à vos collègues ?
Ce guide s’adresse à tous les lecteurs qui sont curieux de connaître l’apprentissage automatique, mais qui ne savent pas comment commencer. Je suppose que beaucoup d’entre vous ont déjà lu l’article de Wikipedia sur l’apprentissage automatique et ont été déçus de ne pas pouvoir trouver d’explication de haut niveau.
L’objectif de cet article est d’être accessible, ce qui signifie qu’il y a beaucoup de généralisations. Mais qui s’en soucie ?
- ### Pourquoi l’apprentissage automatique ?
Le concept d’apprentissage automatique suppose que vous n’avez pas besoin d’écrire de code de programmation spécial pour résoudre un problème et que les algorithmes génétiques (algorithmes génériques) peuvent vous donner des réponses intéressantes sur un ensemble de données. Pour les algorithmes génétiques, il n’est pas nécessaire de coder, mais d’importer des données, il construira sa propre logique sur les données.
Par exemple, il existe une classe d’algorithmes appelés algorithmes de classification qui peuvent diviser les données en différents groupes. Un algorithme de classification utilisé pour identifier les chiffres manuscrits peut être utilisé pour diviser les e-mails en spam et en courrier ordinaire sans modifier une ligne de code. L’algorithme n’a pas changé, mais la formation des données entrées a changé, de sorte qu’il a une logique de classification différente.
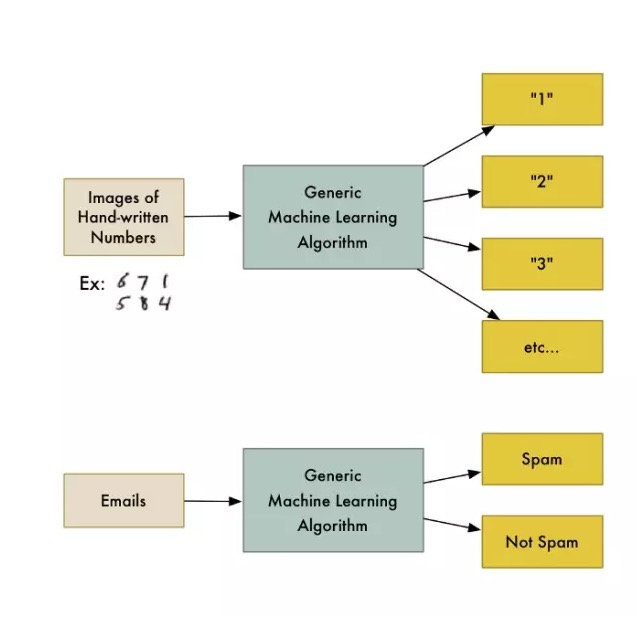
Les algorithmes d’apprentissage automatique sont une boîte noire qui peut être réutilisée pour résoudre de nombreux problèmes de classification différents.
L’apprentissage automatique est un terme générique qui englobe un grand nombre d’algorithmes génétiques similaires.
- ### Les deux types d’algorithmes d’apprentissage automatique
Vous pouvez voir les algorithmes d’apprentissage automatique en deux grandes catégories: l’apprentissage supervisé et l’apprentissage non supervisé. La distinction entre les deux est simple, mais très importante.
-
L’apprentissage supervisé
Supposons que vous soyez un agent immobilier, que votre entreprise grandisse et que vous ayez donc engagé un groupe de stagiaires pour vous aider. Mais le problème est que vous pouvez voir à quel point la maison vaut la peine, et que les stagiaires n’ont aucune expérience et ne savent pas comment l’évaluer.
Afin d’aider votre stagiaire (et peut-être de vous libérer pour partir en vacances), vous avez décidé de créer un petit logiciel qui permettrait d’évaluer la valeur des maisons dans votre région en fonction de facteurs tels que la taille des maisons, le terrain et le prix d’achat de maisons similaires.
Vous avez noté toutes les transactions de maisons de la ville pendant trois mois, et vous avez noté une longue liste de détails sur le nombre de chambres à coucher, la taille de la maison, le terrain, etc. Mais surtout, vous avez noté le prix final de la transaction:
Voici les données de notre entraînement au yoga.
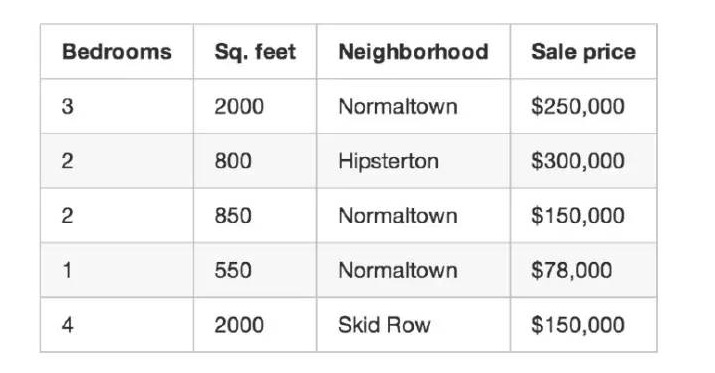
Nous allons utiliser ces données de formation pour écrire un programme pour estimer la valeur d’autres maisons dans la région:

C’est ce qu’on appelle l’apprentissage supervisé. Vous connaissez déjà le prix de vente de chaque maison, c’est-à-dire que vous connaissez la réponse à la question et que vous pouvez inverser la logique pour trouver la solution.
Pour écrire le logiciel, vous allez introduire les données d’entraînement de chaque ensemble de propriété dans votre algorithme d’apprentissage automatique. L’algorithme essaie de trouver quelles opérations doivent être utilisées pour obtenir le nombre de prix.
C’est un peu comme un exercice d’arithmétique, où les symboles de l’arithmétique sont effacés:
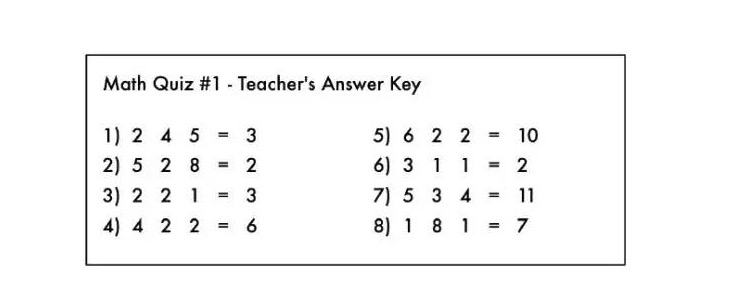
Mon Dieu ! un étudiant sournois a effacé tous les symboles mathématiques des réponses de son professeur.
Vous savez, vous devriez faire quelque chose avec la colonne à gauche de l’algorithme pour obtenir la réponse à la droite de l’algorithme.
Dans l’apprentissage supervisé, vous demandez à un ordinateur de calculer pour vous les relations entre les nombres. Et une fois que vous connaissez les méthodes mathématiques nécessaires pour résoudre ce type de problème particulier, vous pouvez résoudre d’autres problèmes similaires.
-
Apprentissage non supervisé
Revenons à l’exemple du courtier immobilier que nous avons cité au début. Si vous ne savez pas comment vendre chaque maison, vous pouvez faire des choses intéressantes, même si vous ne savez que la taille de la maison, son emplacement, etc. C’est ce qu’on appelle l’apprentissage non supervisé.
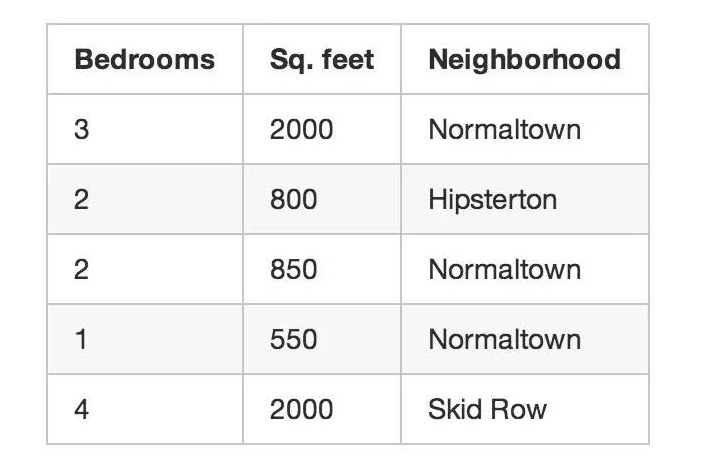
Même si vous n’avez pas l’intention de prédire des données inconnues (comme les prix), vous pouvez utiliser l’apprentissage automatique pour faire quelque chose d’intéressant.
C’est un peu comme si quelqu’un vous donnait un morceau de papier sur lequel il y avait beaucoup de chiffres, et qu’il vous disait: “Oh, je ne sais pas ce que ces chiffres signifient, mais peut-être que vous pourrez en trouver une règle ou les classer, ou quelque chose comme ça - bonne chance!”
D’abord, vous pouvez utiliser un algorithme pour classer automatiquement les différents segments de marché à partir de ces données. Vous pourriez trouver que les acheteurs de maisons près des universités préfèrent les maisons plus petites mais avec plus de chambres à coucher, alors que les acheteurs de maisons dans les banlieues préfèrent les grandes maisons de trois chambres à coucher.
Vous pouvez aussi faire quelque chose d’assez cool, trouver automatiquement des valeurs d’exagération dans les prix des maisons, c’est-à-dire des valeurs qui diffèrent des autres données. Les maisons qui sont dans ces groupes de points peuvent être des immeubles de grande hauteur, et vous pouvez concentrer les meilleurs vendeurs dans ces zones parce qu’ils ont des commissions plus élevées.
Nous parlerons principalement de l’apprentissage supervisé dans le reste de cet article, mais ce n’est pas parce que l’apprentissage non supervisé est inutile ou sans intérêt. En fait, avec l’amélioration des algorithmes, l’apprentissage non supervisé devient de plus en plus important sans avoir à associer les données aux bonnes réponses.
Il y a beaucoup d’autres types d’algorithmes d’apprentissage automatique. Mais c’est une bonne idée pour les débutants.
C’est cool, mais est-ce qu’évaluer les prix de l’immobilier peut vraiment être considéré comme une leçon de yoga ?
En tant qu’être humain, votre cerveau est capable de faire face à la plupart des situations et d’apprendre à les gérer sans aucune instruction précise. Si vous êtes un agent immobilier depuis longtemps, vous avez un instinct de curiosité pour savoir quel est le bon prix d’un bien immobilier, comment le commercialiser au mieux, quels clients seront intéressés, etc. L’objectif de la recherche sur l’IA forte est de pouvoir reproduire cette capacité avec un ordinateur.
Mais les algorithmes d’apprentissage automatique actuels ne sont pas encore assez bons pour se concentrer sur des problèmes très spécifiques et limités. Peut-être que dans ce cas, la meilleure définition d’une machine d’apprentissage automatique est de trouver une équation pour résoudre un problème spécifique sur la base d’une petite quantité de données d’exemple.
Malheureusement, le nom de la machine à coudre est trop mauvais pour trouver une équation pour résoudre un problème spécifique sur la base d’un petit nombre de données d’exemples. Nous avons donc fini par remplacer le nom de la machine à coudre par le nom d’apprentissage de la coudre.
Bien sûr, si vous lisez cet article dans 50 ans, nous aurons développé des algorithmes d’intelligence artificielle puissants, et ce texte ressemblera à un vieux classique.
Il y a des gens qui ne savent pas écrire.
Dans l’exemple précédent, comment allez-vous écrire le processus d’évaluation des prix de l’immobilier ? Réfléchissez-y avant d’aller plus loin.
Si vous ne connaissez rien à l’apprentissage automatique, il y a de fortes chances que vous essayez d’écrire quelques règles de base pour évaluer le prix d’une maison, comme ceci:
def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood): price = 0 # In my area, the average house costs $200 per sqft price_per_sqft = 200 if neighborhood == "hipsterton": # but some areas cost a bit more price_per_sqft = 400 elif neighborhood == "skid row": # and some areas cost less price_per_sqft = 100 # start with a base price estimate based on how big the place is price = price_per_sqft * sqft # now adjust our estimate based on the number of bedrooms if num_of_bedrooms == 0: # Studio apartments are cheap price = price — 20000 else: # places with more bedrooms are usually # more valuable price = price + (num_of_bedrooms * 1000) return priceSi vous vous dépêchez comme ça pendant quelques heures, vous obtiendrez peut-être un peu de résultats, mais votre programme ne sera jamais parfait et il sera difficile de le maintenir quand les prix changent.
Si on pouvait faire en sorte que les ordinateurs trouvent une façon d’accomplir ces fonctions, qui se soucierait de savoir ce que ces fonctions faisaient, tant que les valeurs de la maison étaient correctes ?
def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood): price = <computer, plz do some math for me> return priceUne façon de considérer cette question est de considérer le prix d’une maison comme un plat de riz délicieux, dont les ingrédients sont le nombre de chambres à coucher, la surface et le terrain. Si vous pouvez calculer l’influence de chaque ingrédient sur le prix final, vous pourriez peut-être obtenir un certain pourcentage de ces ingrédients mélangés pour former le prix final.
Cela réduit votre programme d’origine (toute une phrase folle d’if-else) à quelque chose comme ceci:
def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood): price = 0 # a little pinch of this price += num_of_bedrooms * .841231951398213 # and a big pinch of that price += sqft * 1231.1231231 # maybe a handful of this price += neighborhood * 2.3242341421 # and finally, just a little extra salt for good measure price += 201.23432095 return priceNotez les nombres magiques en gras: 841231951398213, 1231.1231231, 2.3242341421, et 201.23432095. Ils sont appelés poids. Si nous pouvions trouver le poids parfait qui s’applique à chaque maison, notre fonction pourrait prédire tous les prix !
Voici une méthode simple pour déterminer le poids idéal:
Première étape
Tout d’abord, on donne à chacun une pondération de 1.0:
def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood): price = 0 # a little pinch of this price += num_of_bedrooms * 1.0 # and a big pinch of that price += sqft * 1.0 # maybe a handful of this price += neighborhood * 1.0 # and finally, just a little extra salt for good measure price += 1.0 return priceLa deuxième étape
Pour chaque maison, introduisez une fonction qui vérifie si la valeur estimée correspond au prix correct:
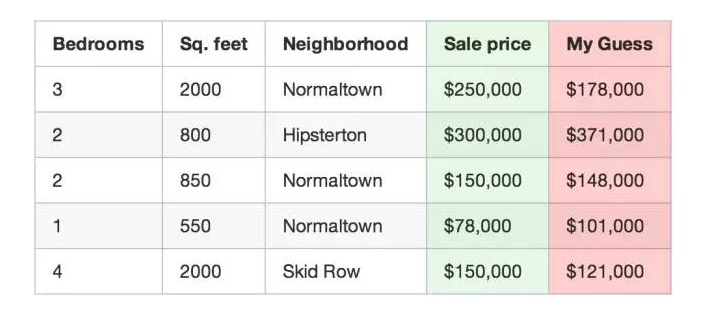
Utilisez votre logiciel pour prévoir le prix des maisons.
Par exemple: le premier immeuble de la liste ci-dessus a un prix de vente réel de 250 000 \(, votre fonction a une estimation de 178 000 \), ce qui vous fait perdre 72 000 $.
Si vous avez 500 transactions immobilières dans votre base de données, la somme de ces estimations est de 86 123 373 dollars. Cela reflète le degré d’exactitude de votre fonction.
Maintenant, on divise le total par 500 et on obtient l’estimation de chaque propriété qui s’écarte de la moyenne. On appelle cette moyenne l’erreur du coût de votre fonction.
Si vous pouvez ajuster le poids pour que ce coût soit égal à 0, votre fonction est parfaite. Cela signifie que votre programme a une estimation de chaque transaction immobilière basée sur les données qu’il a entrées. Et c’est notre objectif: essayer différentes valeurs de poids pour que le coût soit aussi bas que possible.
Étape 3:
Répétez continuellement l’étape 2, essayez toutes les combinaisons de poids possibles. Quelle combinaison rend le coût le plus proche de zéro, c’est celle que vous voulez utiliser, et si vous trouvez une telle combinaison, le problème est résolu !
Les pensées qui perturbent le temps
C’est trop simple, n’est-ce pas ? Réfléchissez à ce que vous venez de faire. Vous obtenez des données, vous les introduisez dans trois étapes simples et générales, et vous obtenez une fonction qui peut évaluer les maisons dans votre région. Mais les faits suivants pourraient vous troubler:
-
- Au cours des 40 dernières années, de nombreuses recherches dans des domaines tels que la linguistique / la traduction ont montré que les algorithmes d’apprentissage de la coquille de données dynamiques universelles (les mots que j’ai inventés) ont été supérieurs aux méthodes nécessitant l’utilisation de règles explicites de personnes réelles.
-
- la dernière fonction que vous avez écrite est vraiment stupide, elle ne sait même pas ce qu’est le nombre de chambres à coucher et la superficie de la chambre à coucher. Tout ce qu’elle sait, c’est faire des mouvements et changer les chiffres pour obtenir la bonne réponse.
-
- il est probable que vous n’ayez aucune idée de la raison pour laquelle un ensemble particulier de valeurs de poids fonctionne. Donc vous avez simplement écrit une fonction que vous ne comprenez pas mais que vous pouvez prouver.
-
- Imaginez que votre programme n’accepte pas de paramètres tels que le nombre de piles d’acier et le nombre de piles de chambre à coucher, mais plutôt un ensemble de chiffres. Supposons que chaque chiffre représente un pixel de l’image capturée par la caméra installée sur votre toit, et que la sortie prévue ne soit pas appelée piles de prix d’acier mais piles de vitesse de volant d’acier, et que vous ayez un programme qui manipule automatiquement votre voiture !
C’est vraiment dingue, pas vrai ?
Dans l’étape 3, essayez chaque chiffre, et qu’en est-il ?
Eh bien, bien sûr, vous ne pouvez pas essayer toutes les valeurs possibles pour trouver la meilleure combinaison. Cela prendrait beaucoup de temps, car les nombres à essayer pourraient être infinis. Pour éviter cela, les mathématiciens ont trouvé de nombreuses façons intelligentes de trouver rapidement des valeurs de poids excellentes sans trop d’effort. Voici l’une d’entre elles: Tout d’abord, écrivez une équation simple pour les 2 étapes ci-dessus:
C’est votre fonction de coût.
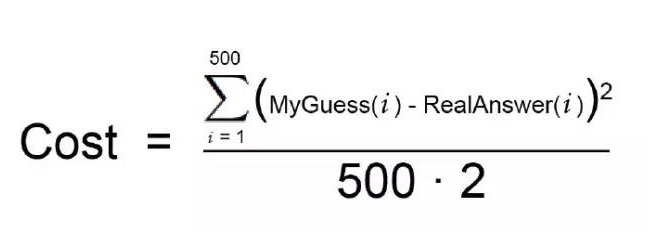
Maintenant, réécrivons cette même équation avec les termes mathématiques de l’apprentissage automatique (pour l’instant, vous pouvez les ignorer):
θ représente la valeur pondérée actuelle. J ((θ) représente le coût correspondant à la valeur pondérée actuelle de l’or.
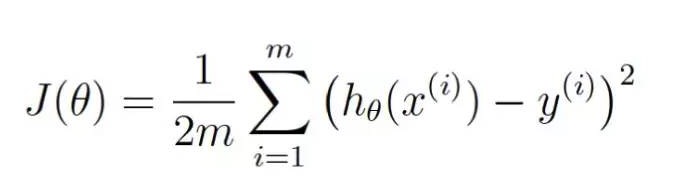
Cette équation représente la taille de l’écart de notre programme d’évaluation par rapport à la valeur pondérée actuelle.
Si l’on affiche graphiquement tous les poids possibles attribués au nombre et à la superficie des chambres à coucher, on obtient un graphique qui ressemble à celui ci-dessous:
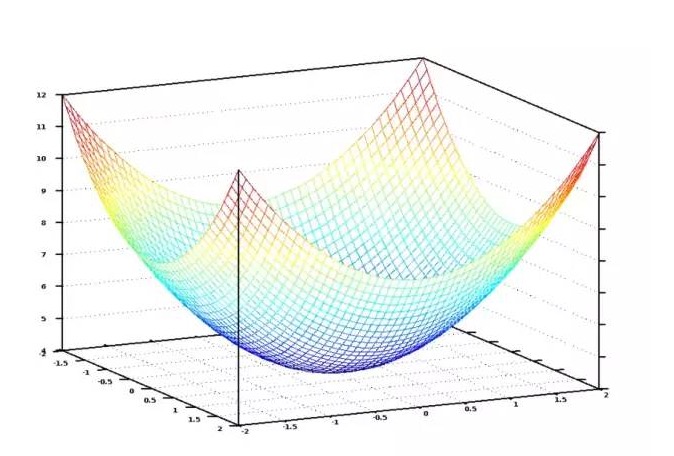
Le graphique de la fonction coût est un bol. L’axe vertical représente le coût.
Le point le plus bas en bleu sur le graphique est le point où le coût est le plus bas, c’est-à-dire que notre programme est le moins éloigné. Le point le plus haut signifie le plus éloigné. Donc, si nous pouvons trouver un ensemble de poids qui nous amène au point le plus bas sur le graphique, nous avons la réponse!
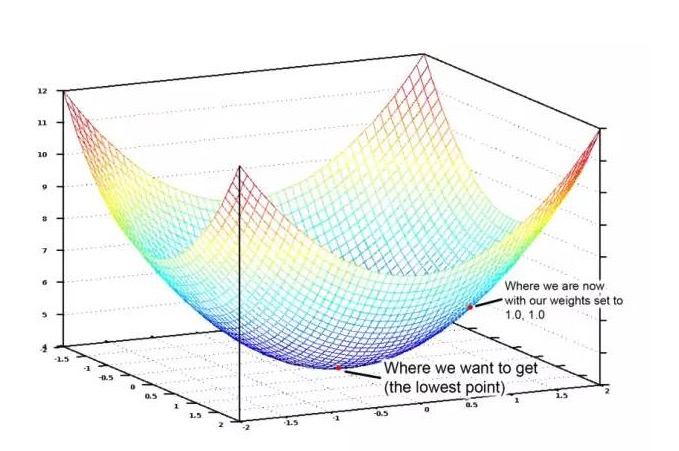
Donc, nous n’avons qu’à ajuster les poids pour que nous puissions gravir la pente vers le point le plus bas sur le graphique. Si de petits ajustements de poids nous permettent de continuer à nous déplacer vers le point le plus bas, nous pourrons finalement y arriver sans trop essayer de les mettre.
Si vous vous souvenez un peu de calcul, vous vous souviendrez peut-être que si vous demandez la direction d’une fonction, le résultat vous indique la pente de la fonction à n’importe quel point. En d’autres termes, pour un point donné sur le graphique, il nous indique que le chemin est en descente.
Donc, si nous cherchons à orienter la fonction de coût par rapport à chaque pondération, nous pouvons alors soustraire cette valeur de chaque pondération. Cela nous rapproche du bas de la montagne. En faisant cela, nous finirons par atteindre le bas et obtenir la valeur optimale de la pondération.
Cette méthode pour déterminer le poids optimal est appelée gradient de descente en quantité, et voici une vue d’ensemble générale de celle-ci. Si vous voulez en savoir plus sur les détails, n’ayez pas peur d’aller plus loin. http://hbfs.wordpress.com/2012/04/24/introduction-to-gradient-descent/
Quand vous utilisez une bibliothèque d’algorithmes d’apprentissage automatique pour résoudre des problèmes concrets, tout est prêt pour vous.
Qu’est-ce que vous avez oublié ?
L’algorithme en trois étapes que j’ai décrit ci-dessus s’appelle la régression multilinéaire. Votre équation d’estimation consiste à trouver une ligne droite qui correspond à tous les points de données de prix de la maison. Ensuite, vous utilisez cette équation pour estimer le prix d’une maison que vous n’avez jamais vue, en fonction de l’emplacement possible de la maison sur votre ligne droite.
Cependant, la méthode que je vous montre peut fonctionner dans des cas simples, mais elle ne fonctionnera pas dans tous les cas. Une des raisons est que les prix ne suivent pas toujours une ligne droite.
Mais, heureusement, il existe de nombreuses façons de gérer cette situation. Pour les données non linéaires, de nombreux autres types d’algorithmes d’apprentissage automatique peuvent être utilisés (comme les réseaux de neurones ou les vecteurs nucléaires). Il existe de nombreuses façons d’utiliser la régression linéaire de manière plus flexible, en utilisant des lignes plus complexes.
De plus, j’ai négligé le concept d’appariement. Il est facile de tomber sur un ensemble de valeurs de poids qui prédisent parfaitement le prix d’une maison dans votre ensemble de données d’origine, mais pas pour une nouvelle maison en dehors de votre ensemble de données d’origine. Il existe de nombreuses solutions à cette situation (comme la normalisation et l’utilisation d’ensembles de données de validation croisée).
En d’autres termes, les concepts de base sont très simples, et il faut des compétences et de l’expérience pour obtenir des résultats utiles avec l’apprentissage automatique. Cependant, c’est une compétence que tout développeur peut apprendre.
-
-
L’apprentissage automatique est-il une force sans limites ?
Une fois que vous commencez à comprendre que les techniques d’apprentissage automatique peuvent facilement être appliquées à des problèmes apparemment difficiles (comme la reconnaissance de l’écriture manuscrite), vous avez le sentiment que si vous avez suffisamment de données, vous pouvez utiliser l’apprentissage automatique pour résoudre n’importe quel problème.
Mais il est important de garder à l’esprit que l’apprentissage automatique ne s’applique qu’aux problèmes que vous pouvez réellement résoudre avec les données que vous possédez.
Par exemple, si vous construisez un modèle pour prédire le prix d’un logement en fonction du nombre de plantes dans chaque maison, il ne réussira jamais. Il n’y a pas de relation entre le nombre de plantes dans la maison et le prix de la maison. Donc, peu importe comment il essaie, un ordinateur ne peut pas déduire la relation entre les deux.
Vous ne pouvez modéliser que des relations réelles.
-
L’apprentissage en profondeur
Je pense que le plus gros problème avec l’apprentissage automatique aujourd’hui est qu’il est principalement actif dans le milieu universitaire et dans les organisations de recherche commerciale. Il n’y a pas beaucoup de matériel d’apprentissage simple et facile à comprendre pour les personnes qui veulent avoir une compréhension générale et non pas devenir des experts.
Le cours gratuit d’apprentissage automatique sur Coursera est très bien. Je le recommande vivement. Toute personne ayant un diplôme en informatique et un peu de mathématiques à la mémoire devrait comprendre.
En outre, vous pouvez télécharger et installer SciKit-Learn pour tester des milliers d’algorithmes d’apprentissage automatique.
Partagé par les développeurs de Python