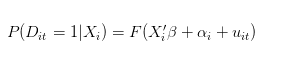Lorsque nous prédisons des probabilités, que prédisons-nous ?
J'ai participé à une entrevue il y a longtemps, et le sujet de l'entrevue me rappelle quelque chose.
L'intervieweur: Vous connaissez Logistic Regression ?
Moi: Bien sûr que oui, c'est très courant.
Intervieweur: Alors, comment expliquer la probabilité d'une prédiction de régression logistique comme étant la probabilité de réussite d'un individu ?
Moi: Certainement pas. Si on ne fait qu'une seule observation, la probabilité d'un individu n'est pas estimée. Cela devrait être interprété comme étant le fait que, pour N individus ayant les mêmes caractéristiques, le taux de réussite est égal à la probabilité d'une estimation.
Eh bien, il n'y avait pas d'intervieweurs à l'époque, et bien sûr, le résultat final de l'entrevue était que j'avais été écrasé (peut-être en raison de mon expérience en économie plutôt qu'en statistique et informatique).
Si vous trouvez cela un peu contradictoire et difficile à comprendre, lorsque nous estimons le retour logistique, nous estimons:
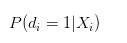
N'est-ce pas la probabilité de réussite individuelle qui devrait être interprétée ?
-
Je pense que cette affirmation est quelque peu problématique.
Lorsque nous parlons de probabilité de réussite d'une personne seule, nous devrions parler du nombre moyen de réussites d'une même personne dans 100 répétitions dans les mêmes conditions. Si t est le nombre de tentatives d'une personne, alors notre modèle idéal (le processus de génération de données) devrait être le suivant:
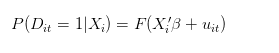
Alternativement, cependant, le processus de génération de données réelles pourrait être le suivant: