
Dévoilement du Fonds Big Data
Dans cet article d'investissement scientifique d'aujourd'hui, nous allons parler des principes du Big Data Fund et de la façon dont les données d'Internet, telles que Taobao, Baidu et Sina, aident les gestionnaires de fonds à choisir leurs actions.
-
Avant de dévoiler le Big Data Fund, jetons un coup d'œil aux étapes de sélection d'actions pour un fonds de type actions typique:
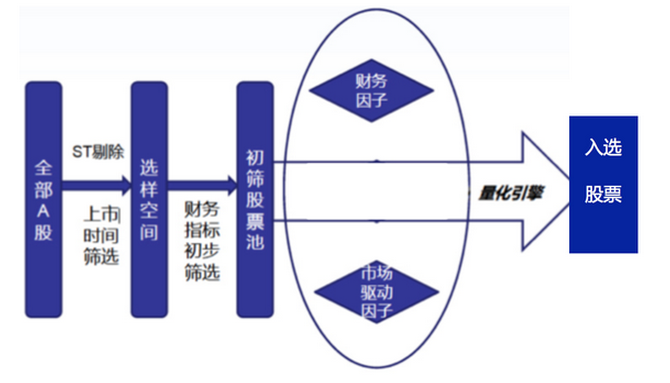
Les critères d'évaluation des premiers élus sont généralement basés sur des indicateurs plus basiques tels que la date de cotation, la valeur marchande, etc.
Les conditions de sélection utilisent généralement des données de l'industrie, des indicateurs financiers, de la rentabilité, etc. Les pools d'actions de première génération serviront d'échantillons pour le modèle de sélection multifactorielle.
Les facteurs utilisés dans les modèles multifactoriels traditionnels comprennent principalement les facteurs financiers (marginal, taux de marché net, taux de marché de vente, taux de valeur marchande d'actifs, taux de croissance du revenu de l'entreprise principale, taux de croissance des bénéfices nets, taux de croissance des EPS, taux de croissance des actifs totaux, etc.) et les facteurs moteurs du marché (taux de rendement à court terme, taux de rendement à long terme, taux de volatilité spécifique, variation du volume des transactions, valeur marchande libre). Le rendement historique et la stabilité à long terme de tous les facteurs ci-dessus sont calculés en fonction de l'effet de levier, et un score global est calculé pour une seule action.
Calculer la composition et le poids du fonds par apprentissage du moteur de quantification.Alors, quelle est la différence entre les fonds Big Data et les fonds traditionnels ?
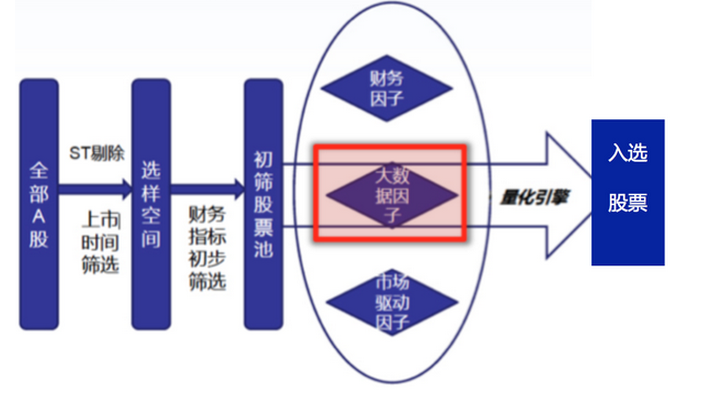
Auparavant, lorsque nous avons créé un modèle de sélection d'actions multi-facteurs, les facteurs utilisés provenaient de l'intérieur du marché, nous nous concentrions uniquement sur les attributs de l'action elle-même, mais l'introduction du facteur Big Data a apporté de nouvelles informations. Nous nous intéressons à la corrélation entre les variations du nombre de recherches par centaine et les variations des actions. Nous nous intéressons à la question de savoir si les ventes de Taobao dans un secteur influencent le prix des actions des entreprises de ce secteur.
Pour vous aider à mieux comprendre les facteurs du Big Data, nous vous donnons l'exemple d'un fonds de données réel.
L'exemple cité ci-dessous est celui de Taobao Big Data 100, lancé par la Fondation Bourse en collaboration avec la marque de vêtements Taobao.
Lors de la construction de l'espace d'échantillonnage, Taobao 100 a sélectionné des actions pertinentes de l'industrie de la troisième catégorie de titres de la Chine liées à la catégorie de marchandises des détaillants en ligne comme espace d'échantillonnage, comprenant les catégories suivantes:
- Produits ménagers durables
- Équipements et articles de loisirs
- Textiles et vêtements
- Hôtel, restaurants et loisirs
- Vente au détail de produits alimentaires et de produits de première nécessité
- Alimentation et boissons
- Produits ménagers
- Produits personnels
-
On peut voir que ces secteurs ressemblent beaucoup à la classification des produits de Taobao, car le facteur Big Data généré par les données Taobao fournit plus d'informations dans ces secteurs.
Basé sur l'espace d'échantillonnage des industries liées à Taobao, le Fonds Bourse et la société Changmin ont généré des actions choisies pour les facteurs de données volumineuses des fournisseurs de services électroniques de renommée mondiale pour les modèles de quantification multifonctionnelle. La plate-forme de services d'information financière Alipay fournit des données sur les tendances statistiques des consommateurs en ligne.
Enfin, le modèle de sélection quantitative des actions utilise des facteurs de données importantes, des facteurs financiers et des facteurs de dynamisation du marché pour classer les actions, déterminer la composition des actions et le poids des fonds de données importantes.
En plus de l'indice Taobao 100, les fonds de données utilisent également de nombreuses sources de données telles que Baidu, Snowball, Sina et Unilever pour générer des facteurs de données. Les facteurs utilisés par les fonds de données sont les suivants:
Les facteurs de recherche de l'indice 100
Pour les actions de l'espace de l'échantillon, calculer le nombre total de recherches et le nombre d'augmentations de recherches pour le mois le plus récent, respectivement, en tant que facteur de volume total et facteur d'augmentation; construire un modèle d'analyse de facteurs pour le facteur de volume total de recherches et le facteur d'augmentation, calculer le score global pour chaque action, enregistré en tant que facteur de recherche;
Le facteur de chaleur de 100 tonnes de boules de neige
Tout d'abord, la couverture du portefeuille d'options à sélectionner est calculée en fonction du portefeuille d'options de la boule de neige obtenu à la deuxième étape. Ensuite, les actions sont notées en fonction de la couverture du portefeuille d'options de chaque action et notées en tant que coefficient de chaleur de la boule de neige de chaque action.
Facteur de Big Data du Sinaï du Sud
Le nombre de pages visitées par les internautes sur Sina Finance, les articles positifs et négatifs sur Weibo, l'impact des reportages sur les médias.
Indice du Big Data de la Fed et facteur du Big Data dans l'industrie de la Fed
L'indicateur d'investissement sectoriel est obtenu après traitement des données caractéristiques des tendances statistiques de la catégorie de consommation de l'Union Bank; ensuite, le facteur de données importantes de l'industrie est obtenu en fonction de l'indicateur d'investissement sectoriel obtenu et de la dynamique économique de l'industrie, y compris: le montant de la consommation, le nombre de transactions, etc., en obtenant le classement de la dynamique économique de l'industrie; enfin, le facteur de données importantes de l'industrie est obtenu en fonction de la dynamique économique des actions de l'industrie.
Beaucoup de connaissances pensent que la performance des fonds de données est en fait médiocre, en fait, jusqu'à présent, plusieurs fonds de données n'ont pas atteint les attentes initiales, mais cela ne nous amène pas à conclure que les fonds de données sont dans le mauvais sens. Parce que l'application actuelle des données est encore conservatrice et expérimentale, nous n'avons ajouté que des facteurs de données sur la base de modèles multifactoriels traditionnels.
En fait, les applications du Big Data ont déjà touché tous les aspects de notre vie, dans lesquelles des trésors cachés de valeur d'investissement ont été cachés involontairement, et bien que les résultats des fonds de Big Data existants n'aient pas encore montré qu'ils avaient la capacité d'exploiter efficacement ces valeurs, le trésor du Big Data a toujours été là, peut-être que des personnes supérieures inconnues en profitent déjà.
Il s'agit d'un investissement scientifique qui a fait ses preuves.
- 1