

Utilisons l'apprentissage par renforcement en intelligence artificielle pour créer un robot de trading de crypto-monnaie
Dans cet article, nous allons créer et appliquer un cadre d'apprentissage par renforcement pour apprendre à créer un bot de trading Bitcoin. Dans ce tutoriel, nous utiliserons la salle de sport d'OpenAI et le robot PPO de la bibliothèque stable-baselines, qui est un fork de la bibliothèque OpenAI baselines.
Un grand merci à OpenAI et DeepMind pour avoir fourni des logiciels open source aux chercheurs en apprentissage profond au cours des dernières années. Si vous n’avez pas vu les incroyables réalisations qu’ils ont réalisées avec des technologies comme AlphaGo, OpenAI Five et AlphaStar, vous avez peut-être vécu isolé au cours de la dernière année, mais vous devriez les découvrir.
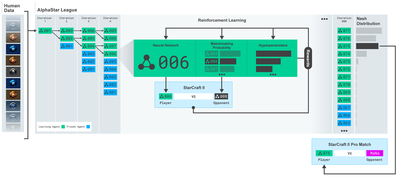
Formation AlphaStar https://deepmind.com/blog/alphastar-mastering-real-time-strategy-game-starcraft-ii/
Même si nous ne créerons rien d’impressionnant, le trading de robots Bitcoin n’est toujours pas une tâche facile dans le trading quotidien. Cependant, comme l’a dit un jour Teddy Roosevelt,
Les choses qui viennent trop facilement n’ont aucune valeur.
Alors, non seulement apprenez à trader pour vous-même… mais laissez également les robots trader pour nous.
plan

-
Créez un environnement de gymnastique pour que notre robot puisse effectuer un apprentissage automatique
-
Rendre un environnement de visualisation simple et élégant
-
Entraînez notre robot à apprendre une stratégie de trading rentable
Si vous ne savez pas encore comment créer des environnements de salle de sport à partir de zéro, ou comment simplement restituer des visualisations de ces environnements. N'hésitez pas à rechercher un article comme celui-ci sur Google avant de continuer. Ces deux actions ne seront pas difficiles même pour les programmeurs les plus débutants.
commencer
Dans ce tutoriel, nous utiliserons l'ensemble de données Kaggle généré par Zielak. Si vous souhaitez télécharger le code source, il est disponible dans mon dépôt Github, avec le fichier de données .csv. Ok, commençons.
Tout d’abord, importons toutes les bibliothèques nécessaires. Assurez-vous d'installer toutes les bibliothèques manquantes à l'aide de pip.
import gym
import pandas as pd
import numpy as np
from gym import spaces
from sklearn import preprocessing
Ensuite, créons notre classe pour l’environnement. Nous devons transmettre un dataframe pandas, ainsi qu'un initial_balance facultatif et un lookback_window_size qui dicteront le nombre d'étapes de temps passées que le robot observera à chaque étape. Nous définissons par défaut la commission par transaction à 0,075 %, le taux actuel sur Bitmex, et le paramètre série par défaut à faux, ce qui signifie que notre dataframe sera parcouru en morceaux aléatoires par défaut.
Nous appelons également dropna() et reset_index() sur les données, d'abord pour supprimer les lignes avec des valeurs NaN, puis pour réinitialiser l'index du numéro de trame puisque nous avons supprimé les données.
class BitcoinTradingEnv(gym.Env):
"""A Bitcoin trading environment for OpenAI gym"""
metadata = {'render.modes': ['live', 'file', 'none']}
scaler = preprocessing.MinMaxScaler()
viewer = None
def __init__(self, df, lookback_window_size=50,
commission=0.00075,
initial_balance=10000
serial=False):
super(BitcoinTradingEnv, self).__init__()
self.df = df.dropna().reset_index()
self.lookback_window_size = lookback_window_size
self.initial_balance = initial_balance
self.commission = commission
self.serial = serial
# Actions of the format Buy 1/10, Sell 3/10, Hold, etc.
self.action_space = spaces.MultiDiscrete([3, 10])
# Observes the OHCLV values, net worth, and trade history
self.observation_space = spaces.Box(low=0, high=1, shape=(10, lookback_window_size + 1), dtype=np.float16)
Notre espace d'action est représenté ici comme un ensemble de 3 options (acheter, vendre ou conserver) et un autre ensemble de 10 montants (1/10, 2/10, 3/10 etc). Lors du choix de l'action d'achat, nous achèterons le montant * notre propre solde de BTC. Pour la vente, nous vendrons un montant * self.btc_held de BTC. Bien entendu, l’action de maintien ignore le montant et ne fait rien.
Notre espace d'observation est défini comme un ensemble de flottants continus entre 0 et 1, de forme (10, lookback_window_size + 1). + 1 est utilisé pour calculer le pas de temps actuel. Pour chaque pas de temps dans la fenêtre, nous observerons la valeur OHCLV. Notre valeur nette est égale au montant de BTC acheté ou vendu et au montant total en USD que nous avons dépensé ou reçu sur ces BTC.
Ensuite, nous devons écrire la méthode de réinitialisation pour initialiser l’environnement.
def reset(self):
self.balance = self.initial_balance
self.net_worth = self.initial_balance
self.btc_held = 0
self._reset_session()
self.account_history = np.repeat([
[self.net_worth],
[0],
[0],
[0],
[0]
], self.lookback_window_size + 1, axis=1)
self.trades = []
return self._next_observation()
Ici, nous utilisons self._reset_session et self._next_observation, nous ne les avons pas encore définis. Commençons par les définir.
Séance de négociation
Une partie importante de notre environnement est le concept de séance de négociation. Si nous déployions ce bot en dehors du marché, nous ne le ferions probablement jamais fonctionner plus de quelques mois à la fois. Pour cette raison, nous allons limiter le nombre d'images consécutives dans self.df, c'est-à-dire le nombre d'images que notre robot peut voir à la fois.
Dans notre méthode _reset_session, nous réinitialisons d’abord current_step à 0. Ensuite, nous allons définir steps_left sur un nombre aléatoire compris entre 1 et MAX_TRADING_SESSION, que nous définirons en haut du programme.
MAX_TRADING_SESSION = 100000 # ~2个月
Ensuite, si nous voulons parcourir les trames en continu, nous devons le configurer pour parcourir la trame entière, sinon nous définissons frame_start sur un point aléatoire dans self.df et créons une nouvelle trame de données appelée active_df qui est juste self. Une tranche de df de frame_start à frame_start + steps_left.
def _reset_session(self):
self.current_step = 0
if self.serial:
self.steps_left = len(self.df) - self.lookback_window_size - 1
self.frame_start = self.lookback_window_size
else:
self.steps_left = np.random.randint(1, MAX_TRADING_SESSION)
self.frame_start = np.random.randint(self.lookback_window_size, len(self.df) - self.steps_left)
self.active_df = self.df[self.frame_start - self.lookback_window_size:self.frame_start + self.steps_left]
Un effet secondaire important de l’itération sur le nombre de trames de données dans le découpage aléatoire est que notre robot disposera de données plus uniques à utiliser lors d’un entraînement de longue durée. Par exemple, si nous parcourions simplement le nombre de trames de données de manière sérielle (c'est-à-dire dans l'ordre de 0 à len(df)), nous n'aurions alors qu'autant de points de données uniques qu'il y a dans le nombre de trames de données. Notre espace d’observation ne peut même adopter qu’un nombre discret d’états à chaque pas de temps.
Cependant, en effectuant une itération aléatoire sur des tranches de l'ensemble de données, nous pouvons créer un ensemble plus significatif de résultats commerciaux pour chaque pas de temps dans l'ensemble de données initial, c'est-à-dire une combinaison d'actions commerciales et d'actions de prix précédemment observées pour créer des données plus uniques. Laissez-moi vous expliquer cela avec un exemple.
À un pas de temps de 10 après la réinitialisation de l'environnement série, notre robot fonctionnera toujours simultanément dans l'ensemble de données et aura 3 choix après chaque pas de temps : Acheter, Vendre ou Conserver. Pour chacune de ces trois options, il existe une autre option : 10 %, 20 %, ... ou 100 % du montant spécifique de mise en œuvre. Cela signifie que notre robot pourrait rencontrer 103 situations à la puissance 10, pour un total de 1030 situations.
Revenons maintenant à notre environnement de découpage aléatoire. À un pas de temps de 10, notre robot peut être à n'importe quel pas de temps len(df) dans le nombre de trames de données. En supposant que le même choix soit fait après chaque pas de temps, cela signifie que le robot peut passer par n'importe quel état unique de len(df)30 dans les mêmes 10 pas de temps.
Même si cela peut introduire un bruit considérable dans les grands ensembles de données, je pense que cela devrait permettre aux robots d’en apprendre davantage à partir de la quantité limitée de données dont nous disposons. Nous continuerons à parcourir nos données de test de manière sérielle pour obtenir les données les plus récentes, apparemment « en temps réel », afin d’acquérir une compréhension plus précise de l’efficacité de l’algorithme.
À travers les yeux d'un robot
Il est souvent utile d’avoir un bon aperçu visuel de l’environnement pour comprendre les types de fonctions que notre robot utilisera. Par exemple, voici une visualisation de l'espace observable rendue à l'aide d'OpenCV.

Observation de l'environnement de visualisation OpenCV
Chaque ligne de l’image représente une ligne dans notre espace d’observation. Les 4 premières lignes de fréquences similaires rouges représentent les données OHCL, et les points orange et jaunes juste en dessous représentent le volume. La barre bleue fluctuante ci-dessous représente l’équité du bot, tandis que les barres plus claires en dessous représentent les transactions du bot.
Si vous regardez attentivement, vous pouvez même créer votre propre graphique en chandeliers. Sous la barre de volume se trouve une interface de type code Morse affichant l'historique des transactions. Il semble que notre bot devrait être capable d’apprendre correctement à partir des données de notre espace d’observation, alors continuons. Ici, nous allons définir la méthode _next_observation où nous mettrons à l'échelle les données observées de 0 à 1.
- Il est important d'étendre uniquement les données que le robot a observées jusqu'à présent pour éviter tout biais d'anticipation.
def _next_observation(self):
end = self.current_step + self.lookback_window_size + 1
obs = np.array([
self.active_df['Open'].values[self.current_step:end],
self.active_df['High'].values[self.current_step:end],
self.active_df['Low'].values[self.current_step:end],
self.active_df['Close'].values[self.current_step:end],
self.active_df['Volume_(BTC)'].values[self.current_step:end],])
scaled_history = self.scaler.fit_transform(self.account_history)
obs = np.append(obs, scaled_history[:, -(self.lookback_window_size + 1):], axis=0)
return obs
Passer à l'action
Maintenant que notre espace d'observation est configuré, il est temps d'écrire notre fonction étape, puis d'effectuer les actions que le robot a l'intention d'effectuer. Chaque fois que self.steps_left == 0 pour notre session de trading en cours, nous vendrons nos avoirs en BTC et appellerons reset session(). Sinon, nous définissons la récompense sur le capital actuel, ou définissons « Done » sur True si nous sommes à court de fonds.
def step(self, action):
current_price = self._get_current_price() + 0.01
self._take_action(action, current_price)
self.steps_left -= 1
self.current_step += 1
if self.steps_left == 0:
self.balance += self.btc_held * current_price
self.btc_held = 0
self._reset_session()
obs = self._next_observation()
reward = self.net_worth
done = self.net_worth <= 0
return obs, reward, done, {}
Effectuer une action de trading est aussi simple que d'obtenir le prix actuel, de déterminer l'action à effectuer et le montant à acheter ou à vendre. Écrivons rapidement _take_action pour pouvoir tester notre environnement.
def _take_action(self, action, current_price):
action_type = action[0]
amount = action[1] / 10
btc_bought = 0
btc_sold = 0
cost = 0
sales = 0
if action_type < 1:
btc_bought = self.balance / current_price * amount
cost = btc_bought * current_price * (1 + self.commission)
self.btc_held += btc_bought
self.balance -= cost
elif action_type < 2:
btc_sold = self.btc_held * amount
sales = btc_sold * current_price * (1 - self.commission)
self.btc_held -= btc_sold
self.balance += sales
Enfin, selon la même méthode, nous ajouterons la transaction à self.trades et mettrons à jour nos capitaux propres et l’historique de notre compte.
if btc_sold > 0 or btc_bought > 0:
self.trades.append({
'step': self.frame_start+self.current_step,
'amount': btc_sold if btc_sold > 0 else btc_bought,
'total': sales if btc_sold > 0 else cost,
'type': "sell" if btc_sold > 0 else "buy"
})
self.net_worth = self.balance + self.btc_held * current_price
self.account_history = np.append(self.account_history, [
[self.net_worth],
[btc_bought],
[cost],
[btc_sold],
[sales]
], axis=1)
Notre robot peut désormais lancer un nouvel environnement, le parcourir et effectuer des actions qui affectent l'environnement. Il est temps de les regarder échanger.
Regardez nos robots trader
Notre méthode de rendu pourrait être aussi simple que d'appeler print(self.net_worth) , mais cela ne serait pas assez intéressant. Au lieu de cela, nous allons dessiner un graphique en chandelier simple avec une barre de volume et un graphique séparé pour nos capitaux propres.
Nous prendrons le code de StockTradingGraph.py de mon article précédent et le retravaillerons pour l'adapter à l'environnement Bitcoin. Vous pouvez obtenir le code depuis mon Github.
Le premier changement que nous allons faire est de modifier self.df[ ['Date'] Mise à jour de self.df[['Timestamp'] et supprimez tous les appels à date2num puisque nos dates sont déjà au format d'horodatage Unix. Ensuite, dans notre méthode de rendu, nous mettrons à jour l’étiquette de date pour imprimer une date lisible par l’homme au lieu d’un nombre.
from datetime import datetime
Tout d'abord, nous allons importer la bibliothèque datetime, puis nous utiliserons utcfromtimestampmethod pour obtenir la chaîne UTC de chaque horodatage et strftime pour en faire une chaîne au format Y-m-d H:M .
date_labels = np.array([datetime.utcfromtimestamp(x).strftime('%Y-%m-%d %H:%M') for x in self.df['Timestamp'].values[step_range]])
Enfin, nous utiliserons self.df[['Volume'] est changé en self.df['Volume_(BTC)'] pour correspondre à notre ensemble de données, et une fois cela fait, nous sommes prêts à partir. De retour à notre BitcoinTradingEnv, nous pouvons maintenant écrire la méthode de rendu pour afficher le graphique.
def render(self, mode='human', **kwargs):
if mode == 'human':
if self.viewer == None:
self.viewer = BitcoinTradingGraph(self.df,
kwargs.get('title', None))
self.viewer.render(self.frame_start + self.current_step,
self.net_worth,
self.trades,
window_size=self.lookback_window_size)
Regarder! Nous pouvons maintenant regarder notre robot trader des Bitcoins.

Visualiser les transactions de notre robot avec Matplotlib
Les étiquettes fantômes vertes représentent l'achat de BTC, et les étiquettes fantômes rouges représentent la vente. L’étiquette blanche dans le coin supérieur droit correspond à la valeur nette actuelle du robot, et l’étiquette dans le coin inférieur droit correspond au prix actuel du Bitcoin. Simple et élégant. Maintenant, il est temps d’entraîner notre bot et de voir combien d’argent nous pouvons gagner !
Temps de formation
L’une des critiques que j’ai reçues dans mon article précédent concernait le manque de validation croisée et le fait de ne pas diviser les données en ensembles d’entraînement et de test. Le but est de tester la précision du modèle final sur de nouvelles données qu’il n’a jamais vues auparavant. Bien que ce ne soit pas le sujet de cet article, c’est certainement important. Étant donné que nous travaillons avec des données de séries chronologiques, nous n’avons pas beaucoup de choix en matière de validation croisée.
Par exemple, une forme courante de validation croisée est appelée validation k-fold, dans laquelle vous divisez les données en k groupes égaux, séparez l'un des groupes comme groupe de test et utilisez le reste des données comme groupe d'entraînement. . Cependant, les données de séries chronologiques dépendent fortement du temps, ce qui signifie que les données ultérieures dépendent fortement des données antérieures. Ainsi, le k-fold ne fonctionnera pas car notre robot apprendra à partir des données futures avant de trader, ce qui constitue un avantage injuste.
Les mêmes défauts s’appliquent à la plupart des autres stratégies de validation croisée lorsqu’elles sont appliquées aux données de séries chronologiques. Par conséquent, nous devons uniquement utiliser une partie du nombre total de trames de données comme ensemble d’apprentissage, en commençant par le début du numéro de trame jusqu’à un index arbitraire, et utiliser le reste des données comme ensemble de test.
slice_point = int(len(df) - 100000)
train_df = df[:slice_point]
test_df = df[slice_point:]
Ensuite, étant donné que notre environnement est uniquement configuré pour gérer une seule trame de données, nous allons créer deux environnements, un pour les données de formation et un pour les données de test.
train_env = DummyVecEnv([lambda: BitcoinTradingEnv(train_df, commission=0, serial=False)])
test_env = DummyVecEnv([lambda: BitcoinTradingEnv(test_df, commission=0, serial=True)])
Désormais, entraîner notre modèle est aussi simple que de créer un robot avec notre environnement et d’appeler model.learn.
model = PPO2(MlpPolicy,
train_env,
verbose=1,
tensorboard_log="./tensorboard/")
model.learn(total_timesteps=50000)
Ici, nous utilisons tensorboard afin de pouvoir facilement visualiser notre graphique tensorflow et voir certaines mesures quantitatives sur notre robot. Par exemple, voici un graphique des récompenses actualisées pour de nombreux robots sur 200 000 pas de temps :
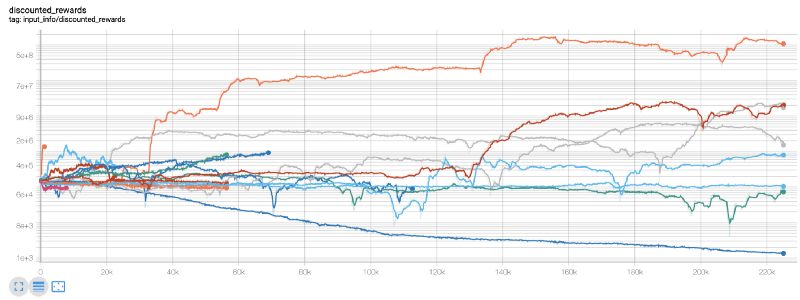
Wow, il semble que notre bot soit plutôt rentable ! Notre meilleur robot a même réussi à atteindre un équilibre 1000 fois meilleur au cours de 200 000 pas, et les autres ont enregistré une amélioration moyenne d'au moins 30 fois !
C'est à ce moment-là que j'ai réalisé qu'il y avait un bug dans l'environnement... Après avoir corrigé cela, voici la nouvelle carte de récompense :
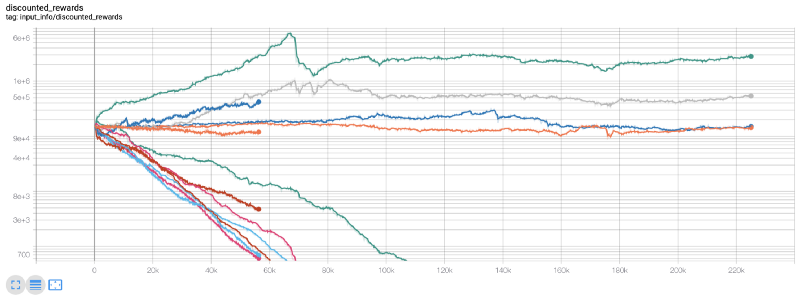
Comme vous pouvez le voir, certains de nos robots ont fait un excellent travail, et les autres ont fait faillite d'eux-mêmes. Cependant, un bot performant peut atteindre jusqu'à 10x voire 60x le solde initial. Je dois admettre que tous les robots rentables sont formés et testés sans commissions, il n'est donc pas réaliste que nos robots gagnent de l'argent réel. Mais au moins nous avons trouvé la direction !
Testons nos robots dans un environnement de test (avec de nouvelles données qu’ils n’ont jamais vues auparavant) et voyons comment ils fonctionnent.
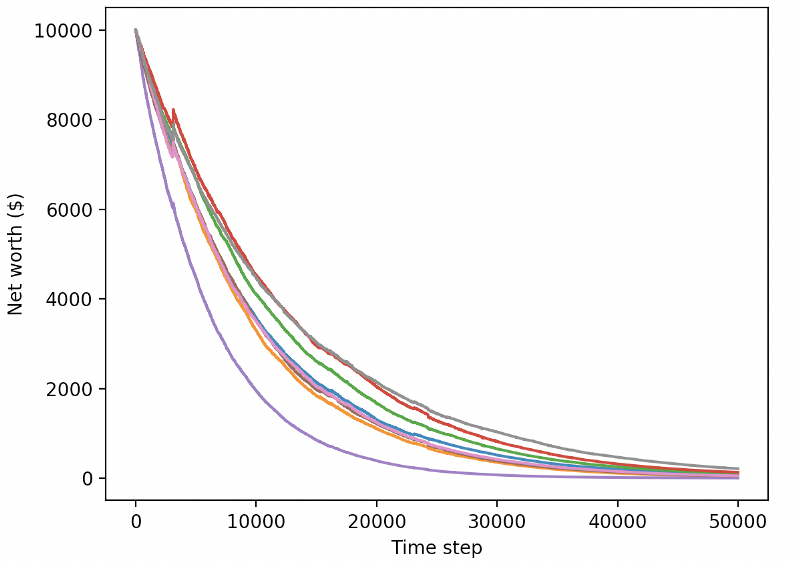
Notre robot formé fait faillite lors de l'échange de nouvelles données de test
Il est clair qu’il nous reste encore beaucoup de travail à faire. En changeant simplement le modèle pour utiliser une A2C de base stable, plutôt que le robot PPO2 actuel, nous pouvons améliorer considérablement nos performances sur cet ensemble de données. Enfin, en suivant la suggestion de Sean O'Gorman, nous pouvons légèrement mettre à jour notre fonction de récompense afin d'ajouter des récompenses à la valeur nette plutôt que de simplement atteindre une valeur nette élevée et de la laisser là.
reward = self.net_worth - prev_net_worth
Ces deux changements à eux seuls améliorent considérablement les performances sur l’ensemble de données de test et, comme vous pouvez le voir ci-dessous, nous sommes enfin en mesure d’atteindre la rentabilité sur de nouvelles données qui ne figuraient pas dans l’ensemble de formation.
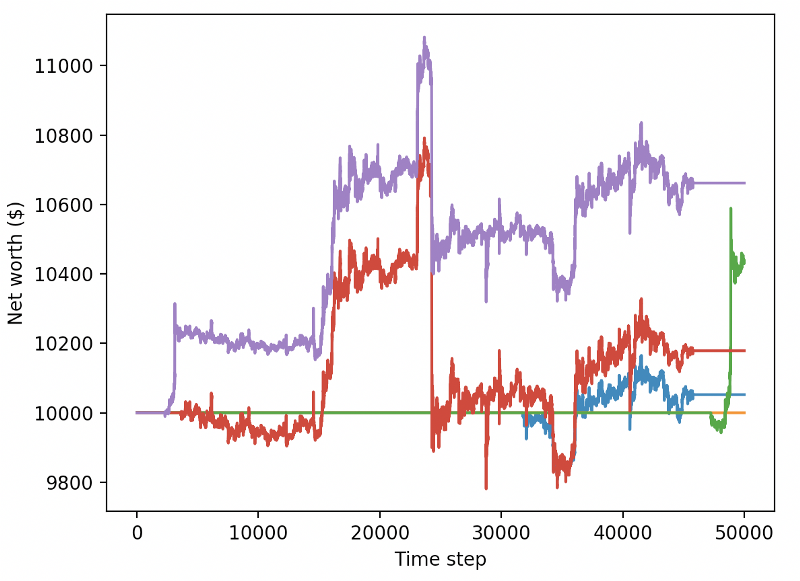
Mais nous pouvons faire mieux. Afin d’améliorer ces résultats, nous devons optimiser nos hyperparamètres et entraîner notre bot plus longtemps. Il est temps de faire fonctionner votre GPU à plein régime !
Cet article est devenu un peu long à ce stade, et nous avons encore beaucoup de détails à prendre en compte, nous allons donc faire une pause ici. Dans le prochain article, nous utiliserons l’optimisation bayésienne pour partitionner les meilleurs hyperparamètres pour notre espace de problèmes et préparer la formation/les tests sur les GPU à l’aide de CUDA.
en conclusion
Dans cet article, nous avons entrepris de créer un robot de trading Bitcoin rentable à partir de zéro en utilisant l'apprentissage par renforcement. Nous pouvons accomplir les tâches suivantes :
-
Créez un environnement de trading Bitcoin à partir de zéro en utilisant le gymnase d'OpenAI.
-
Utilisez Matplotlib pour créer une visualisation de l'environnement.
-
Entraînez et testez notre bot en utilisant une validation croisée simple.
-
Ajuster légèrement notre robot pour atteindre la rentabilité
Bien que notre robot de trading ne soit pas aussi rentable que nous le souhaiterions, nous allons dans la bonne direction. La prochaine fois, nous nous assurerons que notre bot peut battre le marché de manière cohérente et nous verrons comment notre bot de trading fonctionne sur des données en direct. Restez à l’écoute pour mon prochain article, et vive Bitcoin !
- 1