

Données de séries chronologiques
Une série chronologique est une séquence de données obtenues à des périodes consécutives régulièrement espacées. Dans l’investissement quantitatif, ces données se manifestent principalement sous la forme du mouvement des prix et des points de données des cibles d’investissement suivies. Par exemple, les cours des actions et les données de séries chronologiques enregistrées régulièrement sur une période donnée peuvent être visualisés dans la figure suivante, ce qui donnera aux lecteurs une compréhension plus claire :
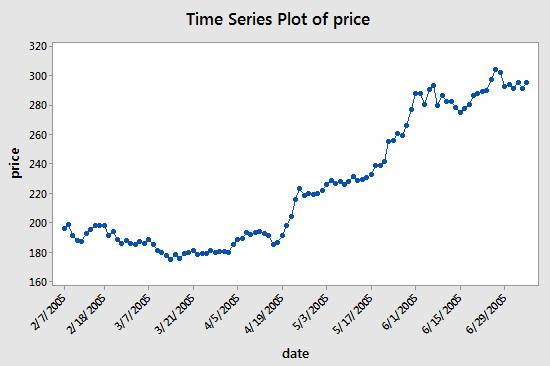
Comme vous pouvez le voir, la date est sur l’axe des x et le prix est sur l’axe des y. Dans ce cas, « intervalles consécutifs » signifie que les jours sur l'axe des x sont espacés de 14 jours : Notez la différence entre le 7 mars 2005 et le point suivant, le 31 mars 2005 et le 5 avril 2005.
Cependant, lorsque vous travaillez avec des données de séries chronologiques, vous verrez souvent plus que de simples colonnes de date et de prix. La plupart du temps, vous travaillerez avec des données contenant cinq colonnes : Période de données, Ouverture, Plus haut, Plus bas et Clôture. Cela signifie que si votre période de données est définie au niveau quotidien, les variations de prix les plus élevées, les plus basses et les plus basses de la journée seront reflétées dans les données de cette série chronologique.
Qu'est-ce que Tick Data ?
Les données de ticks constituent la structure de données de transaction la plus détaillée de l'échange. Il s’agit également d’une forme étendue des données de séries chronologiques mentionnées ci-dessus, comprenant : le prix d’ouverture, le prix le plus élevé, le prix le plus bas, le dernier prix, le volume des transactions et le montant de la transaction. Si les données commerciales sont comparées à une rivière, les données de ticks sont les données d’une certaine section transversale de la rivière.
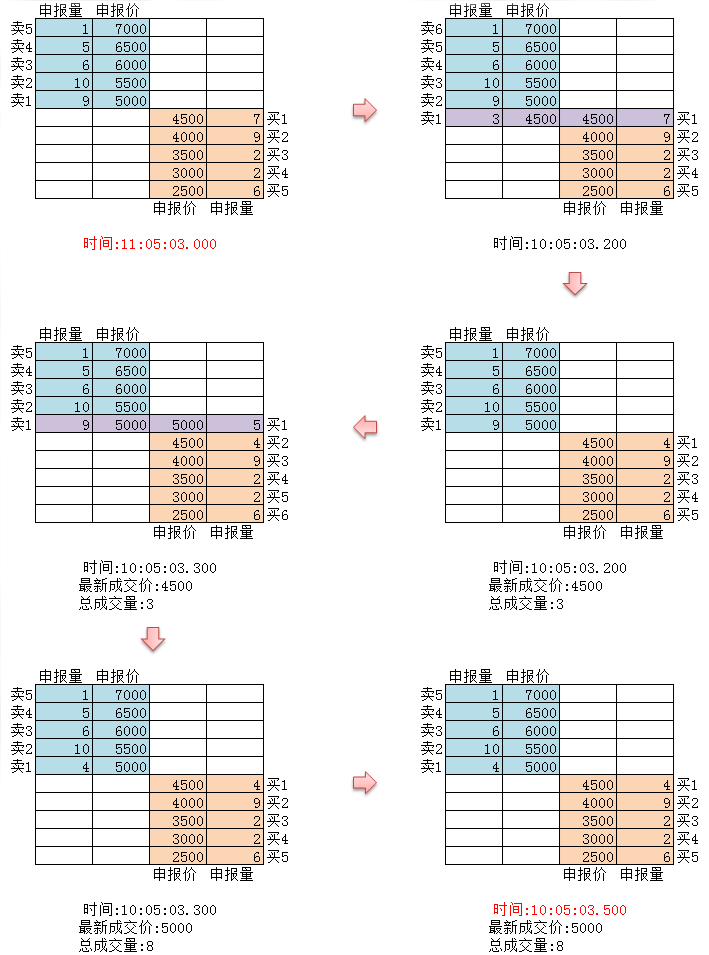
Comme le montre la figure ci-dessus, chaque action des bourses étrangères sera transmise au marché en temps réel. Les échanges nationaux sont vérifiés deux fois par seconde. Si une action se produit pendant cette période, un instantané est généré et diffusé. En comparaison, le push de données ne peut être considéré que comme OnTime au mieux, et ne peut pas être appelé OnTick.
Tous les codes et données de séries chronologiques de ce didacticiel sont obtenus sur la plateforme quantitative Inventor.
L'inventeur a quantifié les données sur les ticks
Bien que les données sur les ticks domestiques ne soient pas de véritables ticks, l'utilisation de ces données pour les tests rétrospectifs peut au moins se rapprocher infiniment de la réalité et la restaurer. Chaque tick affiche les principaux paramètres du produit sur le marché à ce moment-là, et sur le marché réel, notre code est calculé en fonction du taux de tick théorique de 2 fois par seconde.
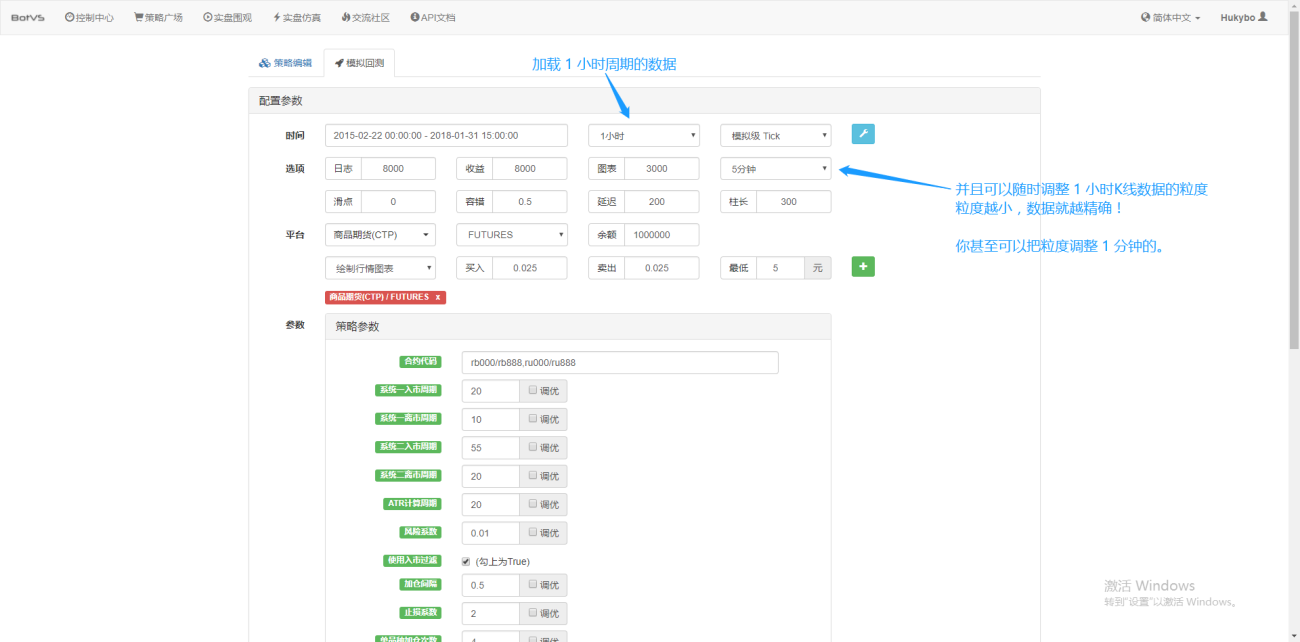
De plus, dans Inventor Quantification, même si vous chargez des données pour une période d'une heure, vous pouvez toujours ajuster la granularité des données, par exemple en ajustant la granularité des données à 1 minute. À l’heure actuelle, la ligne K d’une heure est composée de données d’une minute. Bien entendu, plus la taille des particules est petite, plus la précision est élevée. Ce qui est encore plus puissant, c’est que si vous basculez les données vers des ticks en temps réel, vous pouvez restaurer de manière transparente l’environnement en temps réel. Autrement dit, les données réelles de l'échange sont vérifiées deux fois par seconde.
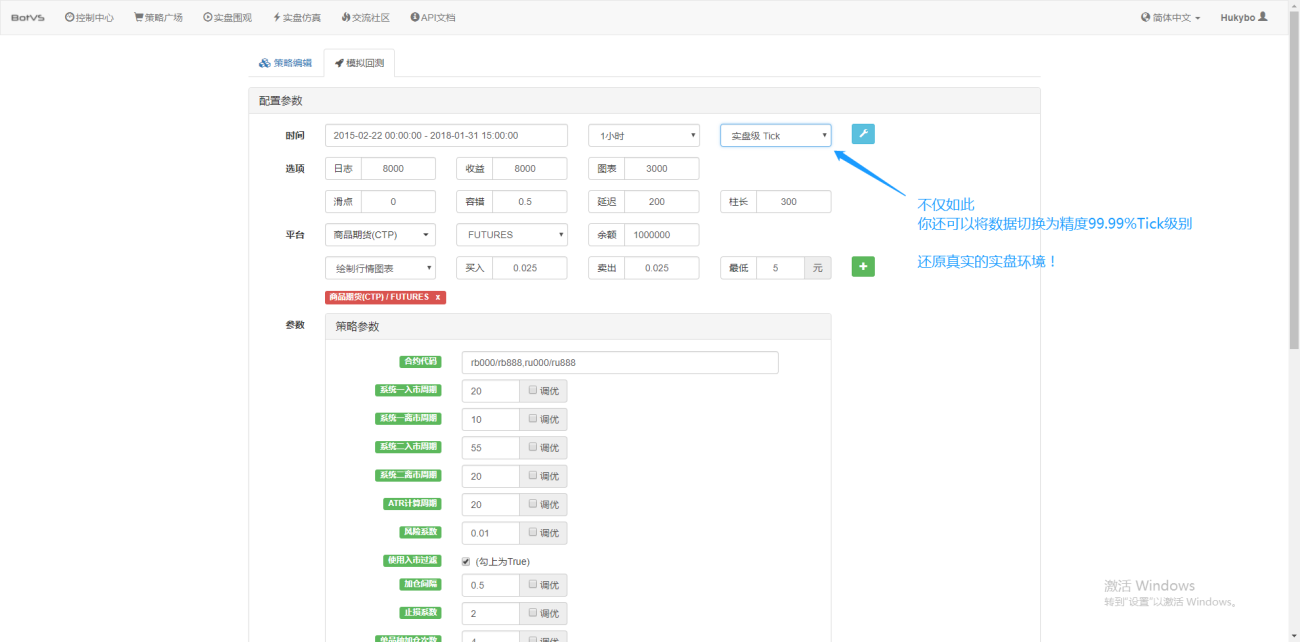
Vous avez maintenant une compréhension des concepts de base que vous devez connaître pour terminer ce didacticiel. Nous reviendrons sur ces concepts sous peu, et vous en apprendrez davantage à leur sujet plus tard dans ce tutoriel.
Pour plus d'informations sur cette partie, veuillez visiter : https://www.fmz.com/bbs-topic/1651
Aménager votre environnement de travail
Pour bien faire son travail, il faut d'abord affûter ses outils. Nous devons déployer un dépositaire sur la plateforme quantitative Inventor. Concernant le concept de dépositaire, les lecteurs ayant une expérience en programmation peuvent le considérer comme un système Docker officiellement packagé. Le système a encapsulé les interfaces API publiques de divers échanges grand public et les détails techniques détaillés pour la rédaction de stratégies et les tests rétrospectifs. L'objectif initial de la mise en place de ce système est de soulager les traders quantitatifs de la nécessité de se concentrer sur la rédaction et la conception de stratégies lors de l'utilisation de la plateforme quantitative Inventor. Ces détails techniques sont présentés aux auteurs de stratégies sous une forme packagée pour leur éviter de nombreux problèmes. temps et énergie.
- Déploiement du système de garde de la plateforme quantitative Inventor
Il existe deux manières de déployer l'hôte :
Méthode A : les utilisateurs louent ou achètent eux-mêmes des serveurs et les déploient sur les principales plateformes de cloud computing telles qu'AWS, Alibaba Cloud, Digital Ocean et Google Cloud. L'avantage est que la sécurité de la stratégie et du système est garantie. Pour la plateforme quantitative Inventor, les utilisateurs sont encouragés à utiliser cette méthode. Un tel déploiement distribué élimine le risque d'attaques du serveur (que ce soit pour les clients ou pour la plateforme elle-même).
Pour cette partie, les lecteurs peuvent se référer à : https://www.fmz.com/bbs-topic/2848
Méthode B : utilisez le déploiement du serveur public de la plateforme quantitative Inventor. La plateforme propose un déploiement à Hong Kong, Londres et Hangzhou. Les utilisateurs peuvent effectuer un déploiement selon le principe de proximité en fonction de l'emplacement de la bourse sur laquelle ils souhaitent effectuer des transactions. L'avantage de cet aspect est qu'il est simple et facile à réaliser, et qu'il peut être complété en un seul clic. Il est particulièrement adapté aux utilisateurs débutants. Ils n'ont pas besoin de comprendre de nombreux problèmes lors de l'achat d'un serveur Linux, et ils économisent également du temps et de l'énergie dans l'apprentissage des commandes Linux. Le prix est également relativement bon marché, ce qui convient aux utilisateurs disposant de petits fonds. Utilisateurs, la plateforme recommande d'utiliser cette méthode de déploiement.
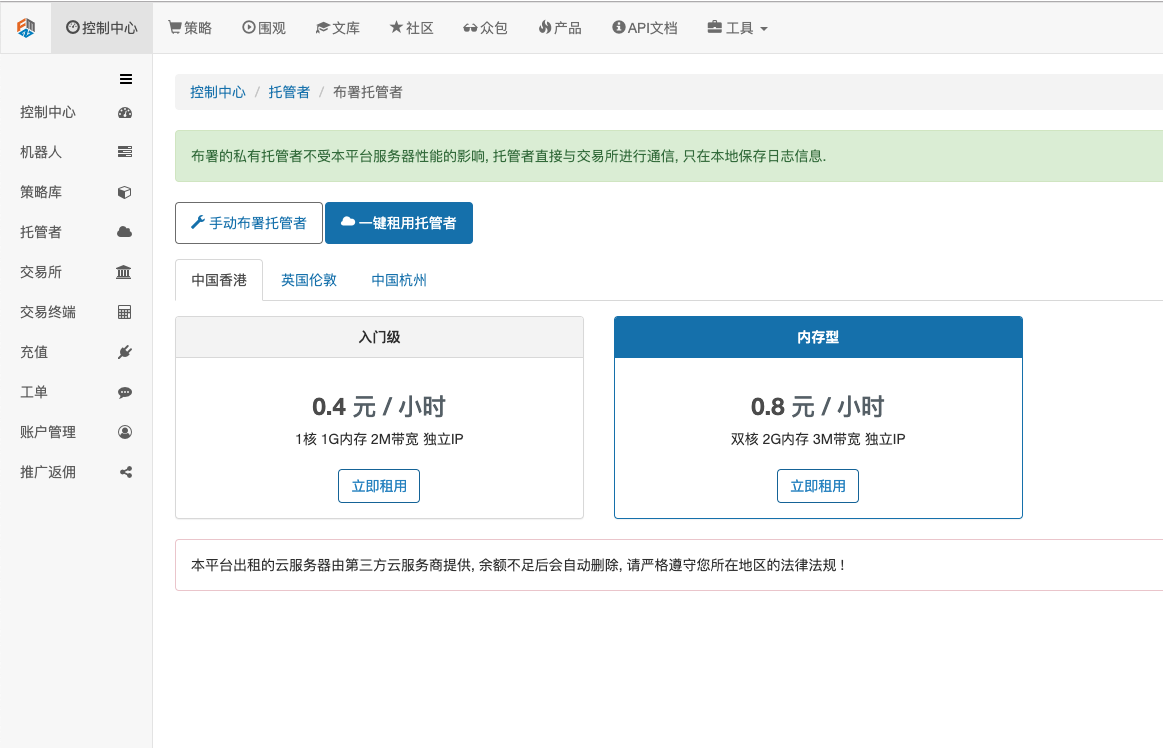
Afin de prendre soin de la compréhension des débutants, cet article adoptera la méthode B.
Les opérations spécifiques sont : connectez-vous à FMZ.COM, cliquez sur le centre de contrôle, hébergez et cliquez sur la location en un clic de l'hôte sur la page de l'hôte.
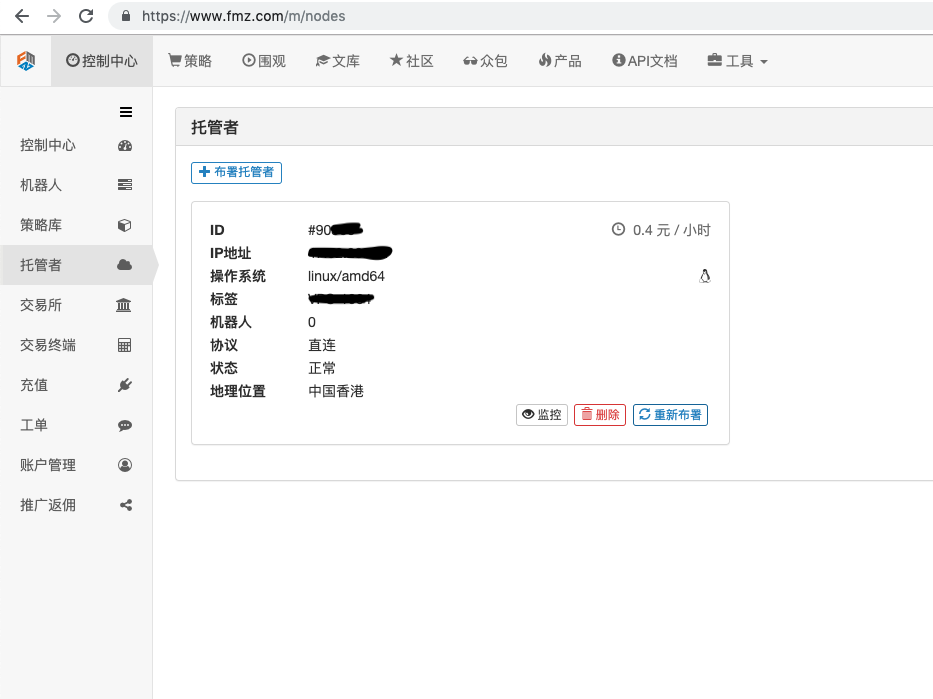
Entrez le mot de passe. Une fois le déploiement réussi, l'image suivante s'affiche :
- Le concept d'un système robotique et sa relation avec l'hôte
Comme mentionné ci-dessus, l'hôte est comme un système Docker, et un système Docker est comme un ensemble de normes. Après avoir déployé cet ensemble de normes, nous devons générer une « instance » pour cette norme, et cette « instance » est une robot.
Créer un robot est très simple. Après avoir déployé l'hôte, cliquez sur la colonne robot à gauche, cliquez sur Créer un robot, saisissez un nom dans le champ Nom du libellé et sélectionnez l'hôte que vous venez de déployer parmi les hôtes d'hébergement. La sélection des paramètres et la période de la ligne K dans la boîte de dialogue ci-dessous peuvent être sélectionnées en fonction de la situation spécifique, principalement pour coopérer avec la sélection de la stratégie de trading.
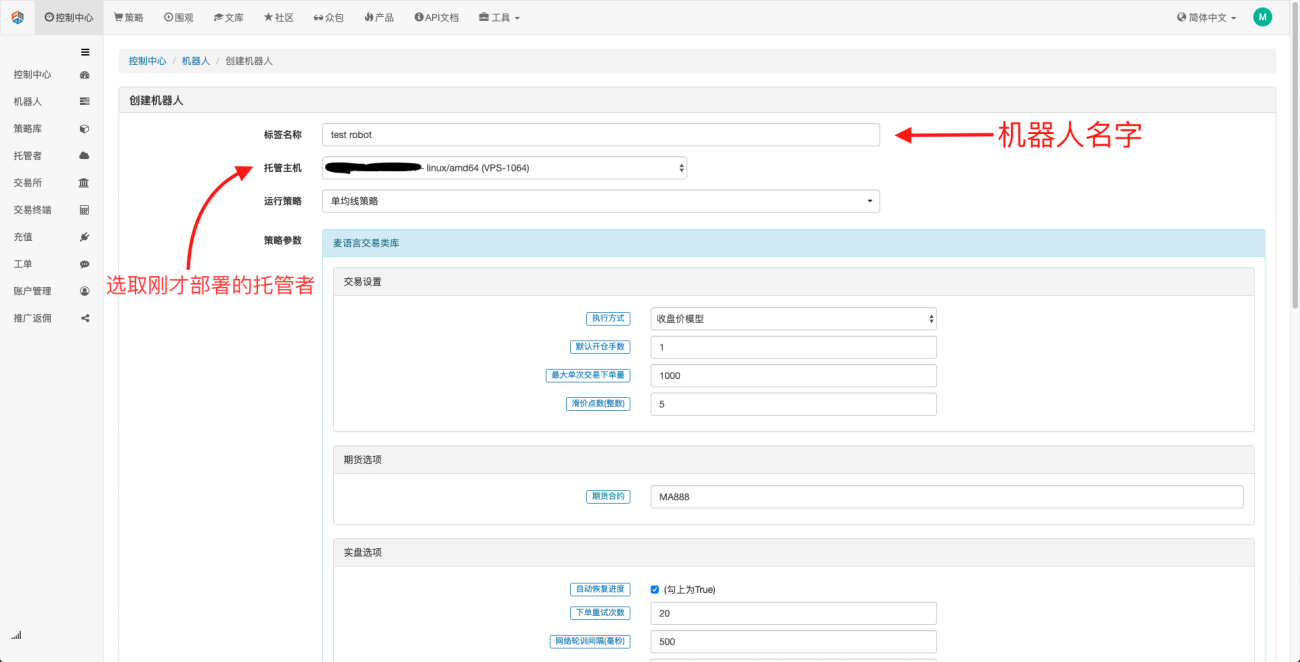
À ce stade, notre environnement de travail est mis en place. Comme vous pouvez le constater, il est très simple et efficace, et chaque fonction remplit ses fonctions respectives. Ensuite, nous commencerons à écrire des stratégies quantitatives.
Implémenter une stratégie de moyenne mobile simple avec Python
Nous avons évoqué ci-dessus les concepts de données de séries chronologiques et de données de ticks. Ensuite, nous utiliserons une stratégie de moyenne mobile simple pour relier ces deux concepts.
- Le principe de base de la stratégie de la moyenne mobile
Grâce à une moyenne mobile à période lente, telle que la moyenne mobile sur 7 jours, et une moyenne mobile à période rapide, telle que la moyenne mobile sur 3 jours. En les appliquant au même graphique K-line, lorsque la moyenne mobile rapide croise la moyenne mobile lente, nous l'appelons une croix d'or ; lorsque la moyenne mobile lente croise la moyenne mobile rapide, nous l'appelons une croix de la mort.
Le principe d'ouverture d'une position est d'ouvrir un ordre long lorsque la croix dorée apparaît et d'ouvrir un ordre court lorsque la croix dorée apparaît. Le même principe s'applique à la clôture d'une position.
Ouvrons FMZ.COM, connectons-nous au compte, au centre de contrôle, à la bibliothèque de stratégies, créons une nouvelle stratégie et sélectionnons Python dans le langage d'écriture de stratégie dans le coin supérieur gauche. Voici le code de cette stratégie. Chaque ligne contient des commentaires très détaillés. Veuillez prendre le temps de l'apprécier. Cette stratégie n'est pas une stratégie en direct, veuillez donc ne pas l'expérimenter avec de l'argent réel. Il s'agit principalement de donner à chacun une idée générale de la rédaction de stratégies et un modèle d'apprentissage.
import types # 导入Types模块库,这是为了应对代码中将要用到的各种数据类型
def main(): # 主函数,策略逻辑从这里开始
STATE_IDLE = -1 # 标记持仓状态变量
state = STATE_IDLE # 标记当前持仓状态
initAccount = ext.GetAccount() #这里用到了现货数字货币交易类库(python版),编写策略时记得勾选上,作用是获得账户初始信息
while True: # 进入循环
if state == STATE_IDLE : # 这里开始开仓逻辑
n = ext.Cross(FastPeriod,SlowPeriod) # 这里用到了指标交叉函数,详情请查看https://www.fmz.com/strategy/21104
if abs(n) >= EnterPeriod : # 如果n大于等于入市观察期,这里的入市观察期是为了防止一开盘就胡乱开仓。
opAmount = _N(initAccount.Stocks * PositionRatio,3) # 开仓量,关于_N的用法,请查看官方API文档
Dict = ext.Buy(opAmount) if n > 0 else ext.Sell(opAmount) # 建立一个变量,用于存储开仓状态,并执行开仓操作
if Dict : # 查看dict变量的情况,为下面的日志输出做准备
opAmount = Dict['amount']
state = PD_LONG if n > 0 else PD_SHORT # PD_LONG和PD_SHORT均为全局常量,分别用来表示多头和空头仓位。
Log("开仓详情",Dict,"交叉周期",n) # 日志信息
else: # 这里开始平仓逻辑
n = ext.Cross(ExitFastPeriod,ExitSlowPeriod) # 指标交叉函数,
if abs(n) >= ExitPeriod and ((state == PD_LONG and n < 0) or (state == PD_SHORT and n > 0)) : # 如果经过了离市观察期且当前账户状态为持仓状态,进而判断金叉或者死叉
nowAccount = ext.GetAccount() # 再次刷新和获取账户信息
Dict2 = ext.Sell(nowAccount.Stocks - initAccount.Stocks) if state == PD_LONG else ext.Buy(initAccount.Stocks - nowAccount.Stocks) # 平仓逻辑,是多头就平多头,是空头就平空头。
state = STATE_IDLE # 标记平仓后持仓状态。
nowAccount = ext.GetAccount() # 再次刷新和获取账户信息
LogProfit(nowAccount.Balance - initAccount.Balance,'钱:',nowAccount.Balance,'币:',nowAccount.Stocks,'平仓详情:',Dict2,'交叉周期:',n) # 日志信息
Sleep(Interval * 1000) # 循环暂停一秒,防止API访问频率过快导致账户被限制。
- Backtesting de la stratégie de moyenne mobile
Sur la page d'édition de la stratégie, nous avons terminé la rédaction de la stratégie. Ensuite, nous devons effectuer un backtest de cette stratégie pour voir comment elle se comporte dans les conditions historiques du marché. Le backtesting joue un rôle important dans le développement de toute stratégie quantitative, mais il ne s'agit que d'un élément clé de la stratégie quantitative. peut servir de référence importante. Le backtesting ne signifie pas une garantie de profit, car le marché est en constante évolution. Le backtesting n'est qu'un acte de rétrospection et appartient toujours à la catégorie de l'induction. Le marché est déductif.
Cliquez sur le backtest simulé et vous pourrez constater qu'il existe de nombreux paramètres ajustables, qui peuvent être modifiés directement dans celui-ci. À mesure que la stratégie devient de plus en plus complexe et que le nombre de paramètres augmente, cette méthode de modification peut aider les utilisateurs à éviter d'avoir à modifiez-les un par un dans le code. Le processus de modification est simple, rapide et clairement organisé.
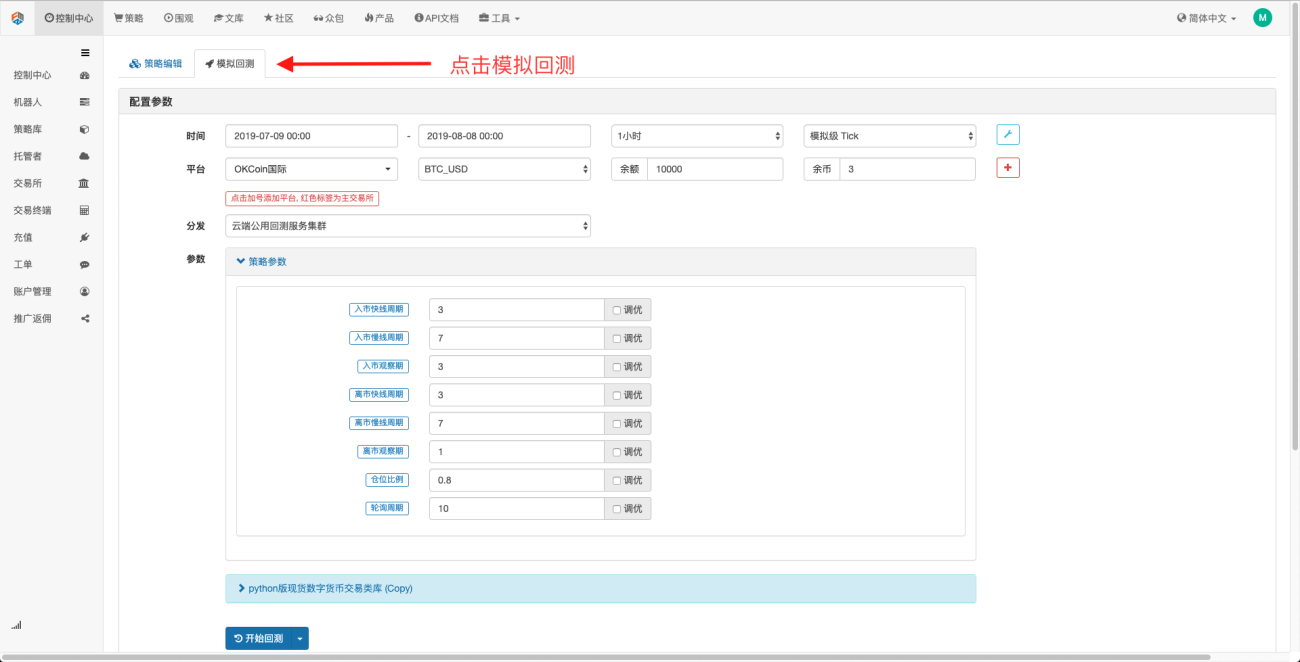
Les options de réglage suivantes peuvent optimiser automatiquement les paramètres définis. Le système essaiera différents paramètres optimaux pour aider les développeurs de stratégies à trouver le meilleur choix.
À partir des exemples ci-dessus, nous pouvons voir que la base du trading quantitatif est l'interaction entre l'analyse des données de séries chronologiques et le backtesting des données de ticks. Quelle que soit la complexité de la logique, elle est indissociable de ces deux éléments de base. La différence réside simplement dans la dimension. Par exemple, le trading haute fréquence nécessite des sections de données plus détaillées et des données de séries chronologiques plus riches. Par exemple, les opérations d'arbitrage nécessitent des échantillons de données relativement volumineux pour les tests rétrospectifs. Il peut être nécessaire de disposer de plus de dix ans de données approfondies et continues sur deux cibles de négociation pour trouver les résultats statistiques de l'expansion et de la contraction de leurs écarts de taux d'intérêt. Dans les prochains articles, je présenterai les stratégies de trading haute fréquence et d’arbitrage, alors restez à l’écoute.
- 1