

Une approche basée sur les données pour analyser la spéculation sur les monnaies numériques
Comment évolue le prix du Bitcoin ? Quelles sont les causes de la montée et de la chute des prix des cryptomonnaies ? Les prix du marché des différents altcoins sont-ils inextricablement liés ou sont-ils largement indépendants ? Comment pouvons-nous prédire ce qui va se passer ensuite ?
Les articles sur les monnaies numériques, telles que Bitcoin et Ethereum, regorgent désormais de spéculations, avec des centaines d’experts autoproclamés défendant les tendances qu’ils s’attendent à voir émerger. Ce qui manque à bon nombre de ces analyses, c’est une base solide de données sous-jacentes et de modèles statistiques.
L’objectif de cet article est de fournir une introduction simple à l’analyse des crypto-monnaies à l’aide de Python. Nous allons parcourir un script Python simple pour récupérer, analyser et visualiser des données pour différentes crypto-monnaies. En chemin, nous découvrirons des tendances intéressantes dans le comportement de ces marchés volatils et comment ils évoluent.
Il ne s’agit pas d’un article expliquant les crypto-monnaies, ni d’un article d’opinion sur les devises spécifiques qui vont augmenter et celles qui vont baisser. Au lieu de cela, notre objectif dans ce tutoriel est simplement de prendre les données brutes et de découvrir les histoires cachées dans les chiffres.
Étape 1 : Construire notre environnement de travail de données
Ce didacticiel est conçu pour les passionnés, les ingénieurs et les data scientists de tous niveaux. Que vous soyez un expert du secteur ou un novice en programmation, les seules compétences dont vous avez besoin sont une compréhension de base du langage de programmation Python et une connaissance suffisante des opérations en ligne de commande. (Juste être capable de mettre en place un projet de science des données).
1.1 Installer Inventor Quant Host et configurer Anaconda
- Inventeur du système de conservation quantifiée
En plus de fournir des sources de données de haute qualité provenant des principales bourses grand public, la plateforme quantitative Inventor FMZ.COM fournit également un riche ensemble d'interfaces API pour nous aider à effectuer des transactions automatisées après avoir terminé l'analyse des données. Cet ensemble d'interfaces comprend des outils pratiques tels que l'interrogation des informations de compte, l'interrogation des prix les plus élevés, d'ouverture, les plus bas et les prix de clôture, le volume des transactions, divers indicateurs d'analyse technique couramment utilisés de diverses bourses traditionnelles, etc., en particulier pour se connecter aux principales bourses traditionnelles en temps réel. processus de trading. L'interface API publique fournit un support technique puissant.
Toutes les fonctions mentionnées ci-dessus sont encapsulées dans un système similaire à Docker. Il suffit d'acheter ou de louer notre propre service de cloud computing, puis de déployer le système Docker.
Dans le nom officiel de la plateforme quantitative Inventor, ce système Docker est appelé système hôte.
Pour plus d'informations sur la manière de déployer des hôtes et des robots, veuillez vous référer à mon article précédent : https://www.fmz.com/bbs-topic/4140
Les lecteurs qui souhaitent acheter leur propre hébergeur de déploiement de serveur de cloud computing peuvent se référer à cet article : https://www.fmz.com/bbs-topic/2848
Après avoir déployé avec succès le service de cloud computing et le système hôte, nous installerons l'outil Python le plus puissant : Anaconda
Afin d'obtenir tous les environnements de programme pertinents requis pour cet article (bibliothèques dépendantes, gestion des versions, etc.), le moyen le plus simple est d'utiliser Anaconda. Il s'agit d'un écosystème de science des données Python packagé et d'un gestionnaire de dépendances.
Étant donné que nous installons Anaconda sur un service cloud, nous vous recommandons d’installer le système Linux ainsi que la version en ligne de commande d’Anaconda sur le serveur cloud.
Pour la méthode d'installation d'Anaconda, veuillez vous référer au guide officiel d'Anaconda : https://www.anaconda.com/distribution/
Si vous êtes un programmeur Python expérimenté et que vous ne ressentez pas le besoin d'utiliser Anaconda, c'est tout à fait normal. Je suppose que vous n’avez pas besoin d’aide pour installer les dépendances requises et que vous pouvez passer à la partie 2.
1.2 Créer un environnement de projet d'analyse de données Anaconda
Une fois Anaconda installé, nous devons créer un nouvel environnement pour gérer nos packages de dépendances. Dans l'interface de ligne de commande Linux, nous entrons :
conda create --name cryptocurrency-analysis python=3
Créons un nouvel environnement Anaconda pour notre projet.
Ensuite, entrez
source activate cryptocurrency-analysis (linux/MacOS操作)
或者
activate cryptocurrency-analysis (windows操作系统)
Pour activer cet environnement
Ensuite, entrez :
conda install numpy pandas nb_conda jupyter plotly
Pour installer les différents packages de dépendances requis pour ce projet.
Remarque : Pourquoi utiliser l’environnement Anaconda ? Si vous prévoyez d'exécuter de nombreux projets Python sur votre ordinateur, il est utile de séparer les dépendances (bibliothèques et packages) des différents projets pour éviter les conflits. Ananconda crée un répertoire d'environnement spécial pour le package de dépendances de chaque projet afin que tous les packages puissent être correctement gérés et distingués.
1.3 Créer un bloc-notes Jupyter
Une fois l'environnement et les packages de dépendances installés, exécutez
jupyter notebook
pour démarrer le noyau iPython, pointez votre navigateur vers http://localhost:8888/ et créez un nouveau bloc-notes Python, en vous assurant qu'il utilise :
Python [conda env:cryptocurrency-analysis]
Noyau

1.4 Importation de packages dépendants
Créez un nouveau notebook Jupyter vide et la première chose que nous devons faire est d’importer les packages de dépendances requis.
import os
import numpy as np
import pandas as pd
import pickle
from datetime import datetime
Nous devons également importer Plotly et activer le mode hors ligne
import plotly.offline as py
import plotly.graph_objs as go
import plotly.figure_factory as ff
py.init_notebook_mode(connected=True)
Étape 2 : Obtenir des informations sur le prix de la monnaie numérique
Maintenant que les préparatifs sont terminés, nous pouvons commencer à acquérir les données à analyser. Tout d’abord, nous devons utiliser l’interface API de la plateforme quantitative Inventor pour obtenir les données de prix du Bitcoin.
Cela utilisera la fonction GetTicker. Pour plus de détails sur l'utilisation de ces deux fonctions, veuillez consulter : https://www.fmz.com/api
2.1 Écrire la fonction de collecte de données Quandl
Pour faciliter l'acquisition de données, nous devons écrire une fonction pour télécharger et synchroniser les données depuis Quandl (quandl.com). Il s’agit d’une interface de données financières gratuite et très connue à l’étranger. La plateforme quantitative Inventor propose également une interface de données similaire, principalement utilisée pour le trading en temps réel. Étant donné que cet article est principalement destiné à l'analyse des données, nous utilisons ici les données de Quandl.
Lors de transactions en temps réel, vous pouvez appeler directement les fonctions GetTicker et GetRecords en Python pour obtenir des données de prix. Pour leur utilisation, veuillez vous référer à : https://www.fmz.com/api
def get_quandl_data(quandl_id):
# 下载和缓冲来自Quandl的数据列
cache_path = '{}.pkl'.format(quandl_id).replace('/','-')
try:
f = open(cache_path, 'rb')
df = pickle.load(f)
print('Loaded {} from cache'.format(quandl_id))
except (OSError, IOError) as e:
print('Downloading {} from Quandl'.format(quandl_id))
df = quandl.get(quandl_id, returns="pandas")
df.to_pickle(cache_path)
print('Cached {} at {}'.format(quandl_id, cache_path))
return df
La bibliothèque pickle est utilisée ici pour sérialiser les données et enregistrer les données téléchargées sous forme de fichier, afin que le programme ne retélécharge pas les mêmes données à chaque exécution. Cette fonction renverra les données au format Pandas Dataframe. Si vous n’êtes pas familier avec le concept de bloc de données, considérez-le comme une puissante feuille de calcul Excel.
2.2 Obtention des données sur les prix des crypto-monnaies à partir de la bourse Kraken
Prenons l’exemple de l’échange Bitcoin Kraken et commençons par obtenir son prix Bitcoin.
# 获取Kraken比特币交易所的价格
btc_usd_price_kraken = get_quandl_data('BCHARTS/KRAKENUSD')
Utilisez la méthode head() pour afficher les cinq premières lignes du bloc de données.
btc_usd_price_kraken.head()
Le résultat est :
| BTC | Open | High | Low | Close | Volume (BTC) | Volume (Currency) | Weighted Price |
|---|---|---|---|---|---|---|---|
| 2014-01-07 | 874.67040 | 892.06753 | 810.00000 | 810.00000 | 15.622378 | 13151.472844 | 841.835522 |
| 2014-01-08 | 810.00000 | 899.84281 | 788.00000 | 824.98287 | 19.182756 | 16097.329584 | 839.156269 |
| 2014-01-09 | 825.56345 | 870.00000 | 807.42084 | 841.86934 | 8.158335 | 6784.249982 | 831.572913 |
| 2014-01-10 | 839.99000 | 857.34056 | 817.00000 | 857.33056 | 8.024510 | 6780.220188 | 844.938794 |
| 2014-01-11 | 858.20000 | 918.05471 | 857.16554 | 899.84105 | 18.748285 | 16698.566929 | 890.671709 |
Ensuite, nous devons créer un tableau simple pour vérifier l’exactitude des données grâce à la visualisation.
# 做出BTC价格的表格
btc_trace = go.Scatter(x=btc_usd_price_kraken.index, y=btc_usd_price_kraken['Weighted Price'])
py.iplot([btc_trace])
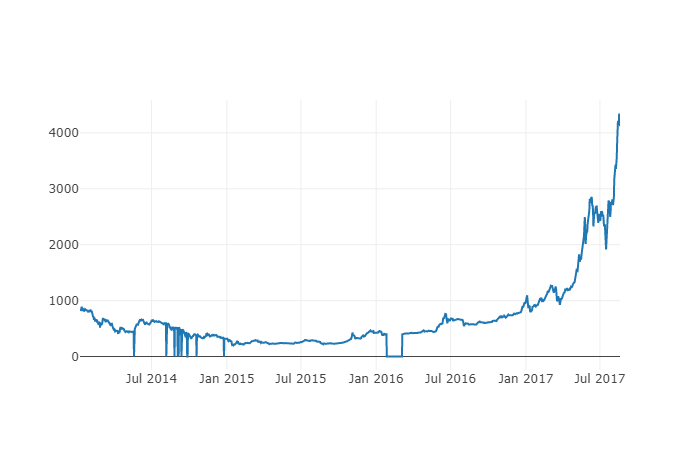
Ici, nous utilisons Plotly pour compléter la partie visualisation. Plotly est un choix moins courant que l'utilisation de certaines des bibliothèques de visualisation de données Python les plus matures, telles que Matplotlib, mais c'est un bon choix car il peut faire appel à D3.js pour des graphiques entièrement interactifs. Les graphiques ont des paramètres par défaut très intéressants, sont faciles à explorer et sont très pratiques à intégrer dans les pages Web.
Astuce : vous pouvez comparer le graphique généré avec un graphique de prix Bitcoin provenant d'une bourse majeure (comme celui d'OKEX, Binance ou Huobi) afin de vérifier rapidement que les données téléchargées sont à peu près cohérentes.
2.3 Obtention de données sur les prix auprès des principales bourses Bitcoin
Les lecteurs attentifs ont peut-être remarqué qu’il manque des données dans les données ci-dessus, en particulier fin 2014 et début 2016. Cette lacune dans les données est particulièrement évidente sur l’échange Kraken. Nous ne voulons certainement pas que ces données manquantes affectent notre analyse des prix.
La caractéristique des échanges de devises numériques est que le prix de la devise est déterminé par l’offre et la demande. Par conséquent, aucun prix de transaction ne peut devenir le « prix dominant » du marché. Pour résoudre ce problème, ainsi que le problème de données manquantes mentionné ci-dessus (peut-être en raison de pannes techniques et d'erreurs de données), nous téléchargerons les données des trois principales bourses Bitcoin du monde et calculerons le prix moyen du Bitcoin.
Commençons par télécharger les données de chaque échange dans un dataframe composé d’un type de dictionnaire.
# 下载COINBASE,BITSTAMP和ITBIT的价格数据
exchanges = ['COINBASE','BITSTAMP','ITBIT']
exchange_data = {}
exchange_data['KRAKEN'] = btc_usd_price_kraken
for exchange in exchanges:
exchange_code = 'BCHARTS/{}USD'.format(exchange)
btc_exchange_df = get_quandl_data(exchange_code)
exchange_data[exchange] = btc_exchange_df
2.4 Intégrer toutes les données dans un seul bloc de données
Ensuite, nous définirons une fonction spéciale pour fusionner les colonnes communes de chaque trame de données dans une nouvelle trame de données. Appelons-la fonction merge_dfs_on_column
def merge_dfs_on_column(dataframes, labels, col):
'''Merge a single column of each dataframe into a new combined dataframe'''
series_dict = {}
for index in range(len(dataframes)):
series_dict[labels[index]] = dataframes[index][col]
return pd.DataFrame(series_dict)
Combinez maintenant tous les cadres de données ensemble en fonction de la colonne « prix pondéré » de chaque ensemble de données.
# 整合所有数据帧
btc_usd_datasets = merge_dfs_on_column(list(exchange_data.values()), list(exchange_data.keys()), 'Weighted Price')
Enfin, nous utilisons la méthode « tail() » pour afficher les cinq dernières lignes des données fusionnées afin de garantir que les données sont correctes et complètes.
btc_usd_datasets.tail()
Le résultat est :
| BTC | BITSTAMP | COINBASE | ITBIT | KRAKEN |
|---|---|---|---|---|
| 2017-08-14 | 4210.154943 | 4213.332106 | 4207.366696 | 4213.257519 |
| 2017-08-15 | 4101.447155 | 4131.606897 | 4127.036871 | 4149.146996 |
| 2017-08-16 | 4193.426713 | 4193.469553 | 4190.104520 | 4187.399662 |
| 2017-08-17 | 4338.694675 | 4334.115210 | 4334.449440 | 4346.508031 |
| 2017-08-18 | 4182.166174 | 4169.555948 | 4175.440768 | 4198.277722 |
Comme le montre le tableau ci-dessus, ces données sont conformes à nos attentes et la plage de données est à peu près la même, mais il existe de légères différences en fonction de la latence ou des caractéristiques de chaque échange.
2.5 Processus de visualisation des données de prix
Du point de vue de la logique analytique, l’étape suivante consiste à comparer ces données grâce à la visualisation. Pour ce faire, nous devons d'abord définir une fonction d'assistance qui utilise les données pour créer un graphique en fournissant une commande sur une seule ligne. Appelons-la fonction df_scatter.
def df_scatter(df, title, seperate_y_axis=False, y_axis_label='', scale='linear', initial_hide=False):
'''Generate a scatter plot of the entire dataframe'''
label_arr = list(df)
series_arr = list(map(lambda col: df[col], label_arr))
layout = go.Layout(
title=title,
legend=dict(orientation="h"),
xaxis=dict(type='date'),
yaxis=dict(
title=y_axis_label,
showticklabels= not seperate_y_axis,
type=scale
)
)
y_axis_config = dict(
overlaying='y',
showticklabels=False,
type=scale )
visibility = 'visible'
if initial_hide:
visibility = 'legendonly'
# 每个系列的表格跟踪
trace_arr = []
for index, series in enumerate(series_arr):
trace = go.Scatter(
x=series.index,
y=series,
name=label_arr[index],
visible=visibility
)
# 为系列添加单独的轴
if seperate_y_axis:
trace['yaxis'] = 'y{}'.format(index + 1)
layout['yaxis{}'.format(index + 1)] = y_axis_config
trace_arr.append(trace)
fig = go.Figure(data=trace_arr, layout=layout)
py.iplot(fig)
Pour votre facilité de compréhension, cet article ne traitera pas en détail du principe logique de cette fonction auxiliaire. Si vous souhaitez en savoir plus, consultez la documentation officielle de Pandas et Plotly.
Nous pouvons désormais créer facilement des graphiques de données de prix Bitcoin !
# 绘制所有BTC交易价格
df_scatter(btc_usd_datasets, 'Bitcoin Price (USD) By Exchange')
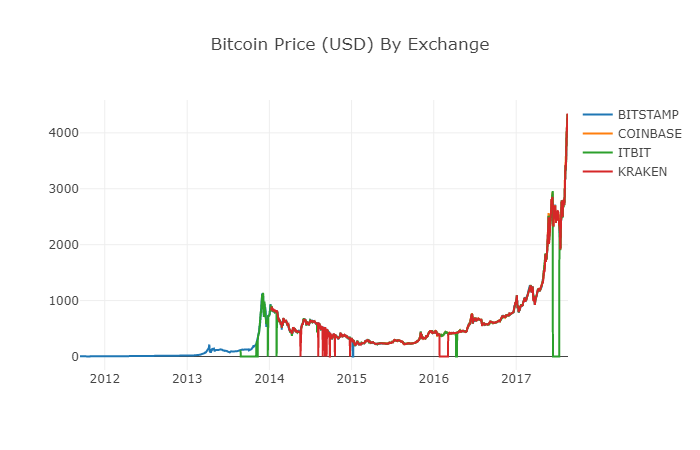
2.6 Données de prix propres et agrégées
Comme vous pouvez le voir sur le graphique ci-dessus, bien que les quatre séries suivent à peu près le même chemin, elles présentent quelques irrégularités que nous allons essayer d’éclaircir.
Au cours de la période 2012-2017, nous savons que le prix du Bitcoin n'a jamais été égal à zéro, nous supprimons donc d'abord toutes les valeurs nulles dans la trame de données.
# 清除"0"值
btc_usd_datasets.replace(0, np.nan, inplace=True)
Après avoir reconstruit le dataframe, nous pouvons voir un graphique beaucoup plus clair sans données manquantes.
# 绘制修订后的数据框
df_scatter(btc_usd_datasets, 'Bitcoin Price (USD) By Exchange')
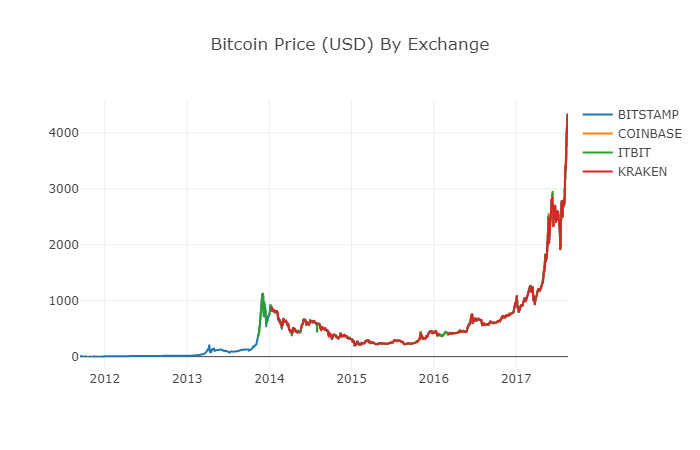
Nous pouvons désormais calculer une nouvelle colonne : le prix quotidien moyen du Bitcoin sur toutes les bourses.
# 将平均BTC价格计算为新列
btc_usd_datasets['avg_btc_price_usd'] = btc_usd_datasets.mean(axis=1)
La nouvelle colonne est l'indice des prix du Bitcoin ! Représentons-le à nouveau pour vérifier s'il semble y avoir un problème avec les données.
# 绘制平均BTC价格
btc_trace = go.Scatter(x=btc_usd_datasets.index, y=btc_usd_datasets['avg_btc_price_usd'])
py.iplot([btc_trace])
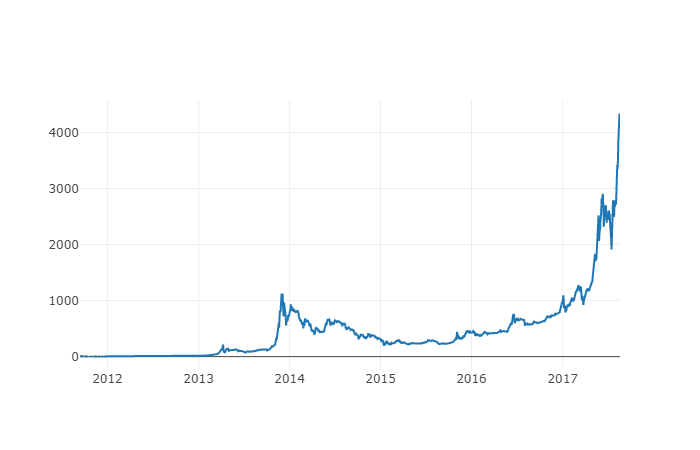
Il semble qu’il n’y ait pas de problème et nous continuerons à utiliser ces données de séries de prix agrégées plus tard pour pouvoir déterminer le taux de change entre d’autres crypto-monnaies et le dollar américain.
Étape 3 : Collecter les prix des altcoins
Jusqu’à présent, nous disposons de données de séries chronologiques sur les prix du Bitcoin. Ensuite, examinons quelques données sur les monnaies numériques non-Bitcoin, à savoir la situation des altcoins. Bien sûr, le terme altcoin est peut-être un peu trop fort, mais en ce qui concerne le développement actuel des monnaies numériques, outre le classement par capitalisation boursière La plupart des dix premières cryptomonnaies (comme Bitcoin, Ethereum, EOS, USDT, etc.) peuvent être appelées altcoins. Il n'y a aucun problème. Nous devrions essayer de rester à l'écart de ces devises lors de nos transactions, car elles sont trop déroutantes et trompeuses.
3.1 Définition des fonctions auxiliaires via l'API d'échange Poloniex
Tout d’abord, nous utilisons l’API de la bourse Poloniex pour obtenir des informations sur les données relatives aux transactions en monnaie numérique. Nous définissons deux fonctions auxiliaires pour obtenir les données pertinentes des altcoins. Ces deux fonctions téléchargent et mettent en cache principalement les données JSON via l'API.
Tout d’abord, nous définissons la fonction get_json_data, qui téléchargera et mettra en cache les données JSON à partir d’une URL donnée.
def get_json_data(json_url, cache_path):
'''Download and cache JSON data, return as a dataframe.'''
try:
f = open(cache_path, 'rb')
df = pickle.load(f)
print('Loaded {} from cache'.format(json_url))
except (OSError, IOError) as e:
print('Downloading {}'.format(json_url))
df = pd.read_json(json_url)
df.to_pickle(cache_path)
print('Cached {} at {}'.format(json_url, cache_path))
return df
Ensuite, nous définissons une nouvelle fonction qui fera une requête HTTP à l'API Poloniex et appellera la fonction get_json_data que nous venons de définir pour enregistrer le résultat de l'appel.
base_polo_url = 'https://poloniex.com/public?command=returnChartData¤cyPair={}&start={}&end={}&period={}'
start_date = datetime.strptime('2015-01-01', '%Y-%m-%d') # 从2015年开始获取数据
end_date = datetime.now() # 直到今天
pediod = 86400 # pull daily data (86,400 seconds per day)
def get_crypto_data(poloniex_pair):
'''Retrieve cryptocurrency data from poloniex'''
json_url = base_polo_url.format(poloniex_pair, start_date.timestamp(), end_date.timestamp(), pediod)
data_df = get_json_data(json_url, poloniex_pair)
data_df = data_df.set_index('date')
return data_df
La fonction ci-dessus extraira le code de chaîne de la paire de crypto-monnaie (comme « BTC_ETH ») et renverra une trame de données contenant les prix historiques des deux devises.
3.2 Téléchargement des données sur les prix des transactions depuis Poloniex
La plupart des altcoins ne peuvent pas être achetés directement en dollars américains. Si les particuliers souhaitent obtenir ces devises numériques, ils doivent généralement d'abord acheter des bitcoins, puis les échanger contre des altcoins en fonction du rapport de prix entre eux. Par conséquent, nous devons télécharger le taux de change de chaque monnaie numérique en Bitcoin, puis utiliser les données de prix Bitcoin existantes pour convertir en dollars américains. Nous téléchargerons les données de transaction pour les 9 principales crypto-monnaies : Ethereum, Litecoin, Ripple, EthereumClassic, Stellar, Dash, Siacoin, Monero et NEM.
altcoins = ['ETH','LTC','XRP','ETC','STR','DASH','SC','XMR','XEM']
altcoin_data = {}
for altcoin in altcoins:
coinpair = 'BTC_{}'.format(altcoin)
crypto_price_df = get_crypto_data(coinpair)
altcoin_data[altcoin] = crypto_price_df
Nous disposons désormais d'un dictionnaire contenant 9 trames de données, chacune contenant des données historiques sur les prix moyens quotidiens entre les altcoins et Bitcoin.
Nous pouvons déterminer si les données sont correctes en examinant les dernières lignes du tableau des prix d’Ethereum.
altcoin_data['ETH'].tail()
| ETH | Open | High | Low | Close | Volume (BTC) | Volume (Currency) | Weighted Price |
|---|---|---|---|---|---|---|---|
| 2017-08-18 | 0.070510 | 0.071000 | 0.070170 | 0.070887 | 17364.271529 | 1224.762684 | 0.070533 |
| 2017-08-18 | 0.071595 | 0.072096 | 0.070004 | 0.070510 | 26644.018123 | 1893.136154 | 0.071053 |
| 2017-08-18 | 0.071321 | 0.072906 | 0.070482 | 0.071600 | 39655.127825 | 2841.549065 | 0.071657 |
| 2017-08-19 | 0.071447 | 0.071855 | 0.070868 | 0.071321 | 16116.922869 | 1150.361419 | 0.071376 |
| 2017-08-19 | 0.072323 | 0.072550 | 0.071292 | 0.071447 | 14425.571894 | 1039.596030 | 0.072066 |
3.3 Toutes les données de prix doivent être exprimées en dollars américains
Nous pouvons désormais combiner les données de taux de change BTC en altcoin avec notre indice de prix Bitcoin pour calculer directement le prix historique de chaque altcoin en USD.
# 将USD Price计算为每个altcoin数据帧中的新列
for altcoin in altcoin_data.keys():
altcoin_data[altcoin]['price_usd'] = altcoin_data[altcoin]['weightedAverage'] * btc_usd_datasets['avg_btc_price_usd']
Ici, nous ajoutons une nouvelle colonne au dataframe pour chaque altcoin afin de stocker son prix USD correspondant.
Ensuite, nous pouvons réutiliser la fonction merge_dfs_on_column que nous avons définie précédemment pour créer un dataframe fusionné qui intègre le prix en USD de chaque crypto-monnaie.
# 将每个山寨币的美元价格合并为单个数据帧
combined_df = merge_dfs_on_column(list(altcoin_data.values()), list(altcoin_data.keys()), 'price_usd')
Fait!
Ajoutons maintenant également le prix du Bitcoin comme dernière colonne du dataframe fusionné.
# 将BTC价格添加到数据帧
combined_df['BTC'] = btc_usd_datasets['avg_btc_price_usd']
Nous disposons désormais d’un dataframe unique qui contient les prix quotidiens en USD pour les dix crypto-monnaies que nous validons.
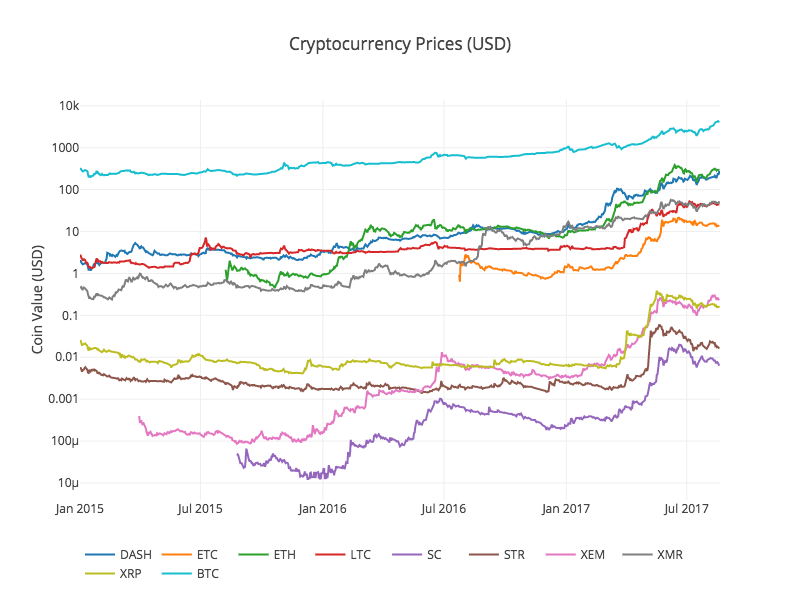
Nous appelons à nouveau la fonction précédente df_scatter pour afficher les prix correspondants de tous les altcoins sous la forme d'un graphique.
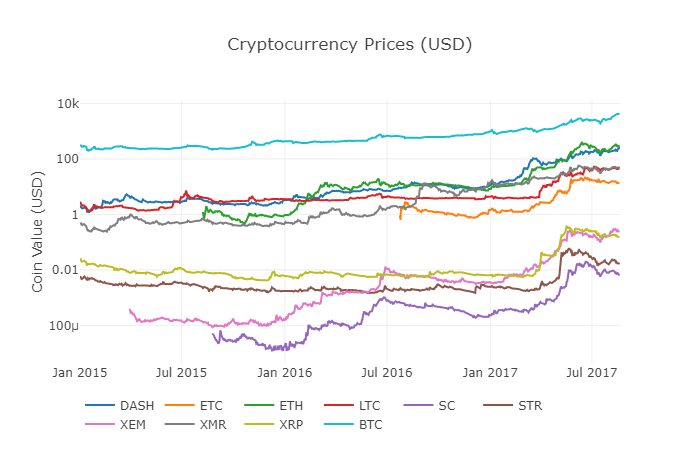
Le graphique semble correct et nous donne une image complète de l’évolution du prix de change de chaque crypto-monnaie au cours des dernières années.
Remarque : ici, nous avons utilisé un axe y logarithmique pour comparer toutes les crypto-monnaies sur le même graphique. Vous pouvez également essayer différentes valeurs de paramètres (telles que scale='linear') pour comprendre les données sous différents angles.
3.4 Démarrer l'analyse de corrélation
Les lecteurs attentifs ont peut-être remarqué que les prix des monnaies numériques semblent être corrélés, même si leurs valeurs monétaires varient considérablement et sont très volatiles. Surtout depuis la hausse rapide d’avril 2017, même de nombreuses petites fluctuations semblent se produire en synchronisation avec les fluctuations de l’ensemble du marché.
Bien sûr, les conclusions appuyées par des données sont plus convaincantes que l’intuition basée sur des images.
Nous pouvons utiliser la fonction Pandas corr() pour vérifier l’hypothèse de corrélation ci-dessus. Ce test calcule le coefficient de corrélation de Pearson pour chaque colonne du cadre de données avec chaque autre colonne.
2017.8.22 Note de révision : Cette section a été modifiée pour utiliser les rendements quotidiens au lieu des prix absolus lors du calcul des coefficients de corrélation.
Un calcul direct basé sur une série temporelle non solide (comme des données de prix brutes) peut entraîner des écarts dans le coefficient de corrélation. Notre solution à ce problème consiste à utiliser la méthode pct_change() pour convertir la valeur absolue de chaque prix dans le cadre de données en taux de rendement quotidien correspondant.
Par exemple, calculons le coefficient de corrélation pour 2016.
# 计算2016年数字货币的皮尔森相关系数
combined_df_2016 = combined_df[combined_df.index.year == 2016]
combined_df_2016.pct_change().corr(method='pearson')
| Name | DASH | ETC | ETH | LTC | SC | STR | XEM | XMR | XRP | BTC |
|---|---|---|---|---|---|---|---|---|---|---|
| DASH | 1.000000 | 0.003992 | 0.122695 | -0.012194 | 0.026602 | 0.058083 | 0.014571 | 0.121537 | 0.088657 | -0.014040 |
| ETC | 0.003992 | 1.000000 | -0.181991 | -0.131079 | -0.008066 | -0.102654 | -0.080938 | -0.105898 | -0.054095 | -0.170538 |
| ETH | 0.122695 | -0.181991 | 1.000000 | -0.064652 | 0.169642 | 0.035093 | 0.043205 | 0.087216 | 0.085630 | -0.006502 |
| LTC | -0.012194 | -0.131079 | -0.064652 | 1.000000 | 0.012253 | 0.113523 | 0.160667 | 0.129475 | 0.053712 | 0.750174 |
| SC | 0.026602 | -0.008066 | 0.169642 | 0.012253 | 1.000000 | 0.143252 | 0.106153 | 0.047910 | 0.021098 | 0.035116 |
| STR | 0.058083 | -0.102654 | 0.035093 | 0.113523 | 0.143252 | 1.000000 | 0.225132 | 0.027998 | 0.320116 | 0.079075 |
| XEM | 0.014571 | -0.080938 | 0.043205 | 0.160667 | 0.106153 | 0.225132 | 1.000000 | 0.016438 | 0.101326 | 0.227674 |
| XMR | 0.121537 | -0.105898 | 0.087216 | 0.129475 | 0.047910 | 0.027998 | 0.016438 | 1.000000 | 0.027649 | 0.127520 |
| XRP | 0.088657 | -0.054095 | 0.085630 | 0.053712 | 0.021098 | 0.320116 | 0.101326 | 0.027649 | 1.000000 | 0.044161 |
| BTC | -0.014040 | -0.170538 | -0.006502 | 0.750174 | 0.035116 | 0.079075 | 0.227674 | 0.127520 | 0.044161 | 1.000000 |
Le graphique ci-dessus montre les coefficients de corrélation. Un coefficient proche de 1 ou -1 signifie que la séquence est respectivement corrélée positivement ou inversement. Un coefficient de corrélation proche de 0 signifie que les objets correspondants ne sont pas corrélés et que leurs fluctuations sont indépendantes les unes des autres.
Afin de mieux visualiser les résultats, nous créons une nouvelle fonction d'aide à la visualisation.
def correlation_heatmap(df, title, absolute_bounds=True):
'''Plot a correlation heatmap for the entire dataframe'''
heatmap = go.Heatmap(
z=df.corr(method='pearson').as_matrix(),
x=df.columns,
y=df.columns,
colorbar=dict(title='Pearson Coefficient'),
)
layout = go.Layout(title=title)
if absolute_bounds:
heatmap['zmax'] = 1.0
heatmap['zmin'] = -1.0
fig = go.Figure(data=[heatmap], layout=layout)
py.iplot(fig)
correlation_heatmap(combined_df_2016.pct_change(), "Cryptocurrency Correlations in 2016")
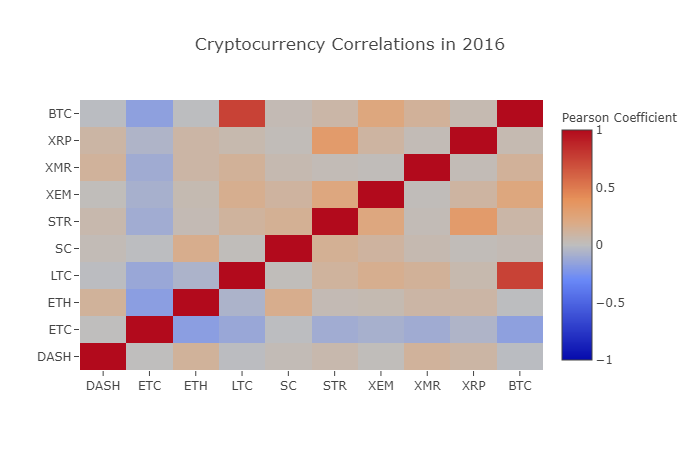
Ici, les valeurs rouge foncé représentent une forte corrélation (chaque pièce est évidemment fortement corrélée avec elle-même), et les valeurs bleu foncé représentent une corrélation inverse. Toutes les couleurs intermédiaires – bleu clair/orange/gris/marron – ont des valeurs qui représentent divers degrés de corrélation faible ou nulle.
Que nous dit cette image ? À un niveau basique, il montre comment les prix des différentes crypto-monnaies ont fluctué tout au long de 2016, avec peu de corrélation statistiquement significative.
Maintenant, pour vérifier notre hypothèse selon laquelle « les crypto-monnaies sont devenues plus corrélées ces derniers mois », nous allons répéter le même test en utilisant des données de 2017.
combined_df_2017 = combined_df[combined_df.index.year == 2017]
combined_df_2017.pct_change().corr(method='pearson')
| Name | DASH | ETC | ETH | LTC | SC | STR | XEM | XMR | XRP | BTC |
|---|---|---|---|---|---|---|---|---|---|---|
| DASH | 1.000000 | 0.384109 | 0.480453 | 0.259616 | 0.191801 | 0.159330 | 0.299948 | 0.503832 | 0.066408 | 0.357970 |
| ETC | 0.384109 | 1.000000 | 0.602151 | 0.420945 | 0.255343 | 0.146065 | 0.303492 | 0.465322 | 0.053955 | 0.469618 |
| ETH | 0.480453 | 0.602151 | 1.000000 | 0.286121 | 0.323716 | 0.228648 | 0.343530 | 0.604572 | 0.120227 | 0.421786 |
| LTC | 0.259616 | 0.420945 | 0.286121 | 1.000000 | 0.296244 | 0.333143 | 0.250566 | 0.439261 | 0.321340 | 0.352713 |
| SC | 0.191801 | 0.255343 | 0.323716 | 0.296244 | 1.000000 | 0.417106 | 0.287986 | 0.374707 | 0.248389 | 0.377045 |
| STR | 0.159330 | 0.146065 | 0.228648 | 0.333143 | 0.417106 | 1.000000 | 0.396520 | 0.341805 | 0.621547 | 0.178706 |
| XEM | 0.299948 | 0.303492 | 0.343530 | 0.250566 | 0.287986 | 0.396520 | 1.000000 | 0.397130 | 0.270390 | 0.366707 |
| XMR | 0.503832 | 0.465322 | 0.604572 | 0.439261 | 0.374707 | 0.341805 | 0.397130 | 1.000000 | 0.213608 | 0.510163 |
| XRP | 0.066408 | 0.053955 | 0.120227 | 0.321340 | 0.248389 | 0.621547 | 0.270390 | 0.213608 | 1.000000 | 0.170070 |
| BTC | 0.357970 | 0.469618 | 0.421786 | 0.352713 | 0.377045 | 0.178706 | 0.366707 | 0.510163 | 0.170070 | 1.000000 |
Ces données sont-elles plus pertinentes ? Est-ce suffisant pour servir de critère d’investissement ? La réponse est non.
Il convient toutefois de noter que presque toutes les crypto-monnaies sont devenues de plus en plus interconnectées.
correlation_heatmap(combined_df_2017.pct_change(), "Cryptocurrency Correlations in 2017")
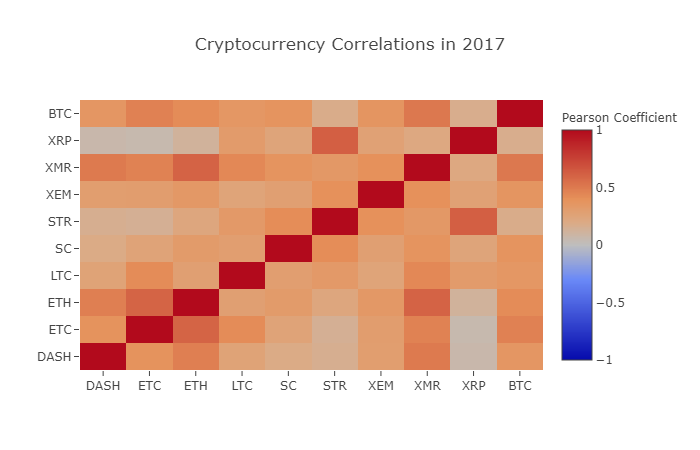
Comme vous pouvez le voir sur l’image ci-dessus, les choses deviennent de plus en plus intéressantes.
Pourquoi cela arrive-t-il ?
Bonne question ! Mais la vérité c'est que je n'en suis pas si sûr...
Ma première réaction a été que les fonds spéculatifs avaient récemment commencé à négocier publiquement sur les marchés des crypto-monnaies. Ces fonds détiennent beaucoup plus de capital que le trader moyen. Si un fonds couvre son capital d'investissement entre plusieurs crypto-monnaies et utilise ensuite des facteurs de risque similaires pour chaque devise en fonction d'une variable indépendante (par exemple, le marché boursier), il sera plus rentable. Trading stratégies. Si l’on considère cette perspective, la tendance à l’augmentation de la corrélation est logique.
Une compréhension plus approfondie du XRP et du STR
Par exemple, à partir du graphique ci-dessus, il est clair que XRP (le jeton de Ripple) est celui qui est le moins corrélé aux autres crypto-monnaies. Mais une exception notable ici est le STR (le jeton de Stellar, officiellement appelé « Lumens »), qui a une forte corrélation avec le XRP (coefficient de corrélation : 0,62).
Il est intéressant de noter que Stellar et Ripple sont des plateformes fintech très similaires qui visent toutes deux à réduire les étapes fastidieuses impliquées dans le transfert d’argent entre banques au-delà des frontières. Il est concevable que certains grands acteurs et fonds spéculatifs utilisent des stratégies de trading similaires pour leurs investissements dans Stellar et Ripple, étant donné la similitude des jetons utilisés par les services blockchain. C'est peut-être la raison pour laquelle XRP a une corrélation plus forte avec STR que d'autres crypto-monnaies.
Ok, c'est ton tour !
Les explications ci-dessus sont en grande partie spéculatives et vous pourrez peut-être faire mieux. En nous appuyant sur les bases que nous avons posées, il existe des centaines de façons différentes de continuer à explorer les histoires contenues dans vos données.
Voici quelques-unes de mes suggestions que les lecteurs pourraient prendre en compte dans leurs orientations de recherche :
- Ajout de données sur davantage de crypto-monnaies à l'analyse globale
- Ajustez la plage de temps et la granularité de l’analyse de corrélation pour obtenir des vues plus précises ou plus grossières des tendances.
- Trouvez les tendances en matière de volume de transactions ou d'exploration de données blockchain. Si vous souhaitez prédire les fluctuations de prix futures, vous aurez peut-être davantage besoin de données sur le ratio volume d'achat/vente que de données sur les prix bruts.
- Ajoutez des données de prix sur les actions, les matières premières et les monnaies fiduciaires pour déterminer lesquelles d’entre elles sont corrélées aux crypto-monnaies (mais rappelez-vous le vieil adage « la corrélation n’implique pas la causalité »)
- Utilisez Event Registry, GDELT et Google Trends pour quantifier le nombre de « mots clés » entourant une crypto-monnaie particulière.
- Utilisez les données pour former un modèle d’apprentissage automatique prédictif afin de prédire le prix de demain. Si vous vous sentez plus ambitieux, vous pouvez même envisager d’essayer de faire l’entraînement ci-dessus avec un réseau neuronal récurrent (RNN).
- Utilisez votre analyse pour créer un robot de trading automatisé qui peut être utilisé sur des sites Web d’échange tels que « Poloniex » ou « Coinbase » via l’interface de programmation d’application (API) correspondante. Soyez prudent : un bot peu performant peut facilement anéantir vos actifs en un instant. Il est recommandé d'utiliser la plateforme quantitative des inventeurs FMZ.COM.
L’avantage principal du Bitcoin, et des monnaies numériques en général, est leur nature décentralisée, qui le rend plus libre et plus démocratique que tout autre actif. Partagez votre analyse en open source, impliquez-vous dans la communauté ou écrivez un article de blog ! Nous espérons que vous disposez désormais des compétences nécessaires pour mener votre propre analyse et être capable de réfléchir de manière critique à tout article spéculatif sur les crypto-monnaies que vous lirez à l’avenir, en particulier les prédictions qui ne sont pas étayées par des données. Merci de votre lecture. Si vous avez des commentaires, des suggestions ou des critiques à propos de ce tutoriel, veuillez laisser un message sur https://www.fmz.com/bbs.

- 1