मनोरंजन के लिए मशीन लर्निंग: शुरुआती लोगों के लिए सबसे सरल गाइड
 3
3605
3
3605
मनोरंजन के लिए मशीन लर्निंग: शुरुआती लोगों के लिए सबसे सरल गाइड
जब आप लोगों को मशीन लर्निंग के बारे में बात करते हुए सुनते हैं, तो क्या आप इसके बारे में कुछ अस्पष्ट समझते हैं? क्या आप अपने सहकर्मियों से बात करते हुए केवल सिर हिलाते हुए थक गए हैं? चलो इसे बदलते हैं!
इस गाइड के पाठकों के लिए, मैं उन सभी लोगों को संबोधित करता हूं जो मशीन सीखने के बारे में उत्सुक हैं, लेकिन यह नहीं जानते कि कैसे शुरू करना है। मुझे लगता है कि बहुत से लोगों ने पहले से ही विकिपीडिया के बारे में पढ़ा है, जो मशीन सीखने के बारे में है, और निराश महसूस करते हैं कि कोई भी उच्च स्तर की व्याख्या नहीं कर सकता है।
इस आलेख का उद्देश्य सरलता है, जिसका अर्थ है कि इसमें बहुत सारे सामान्यीकरण हैं। लेकिन इससे कौन परवाह करता है?
- ### मशीन लर्निंग क्यों?
मशीन लर्निंग की अवधारणा यह मानती है कि आपको हल करने के लिए किसी विशेष प्रोग्राम कोड को लिखने की आवश्यकता नहीं है, आनुवांशिक एल्गोरिदम (जेनेरिक एल्गोरिदम) डेटासेट पर आपके लिए दिलचस्प उत्तर प्राप्त कर सकते हैं। आनुवांशिक एल्गोरिदम के लिए, कोडिंग की आवश्यकता नहीं है, लेकिन डेटा इनपुट करें, यह डेटा के ऊपर अपना तर्क बनाएगा।
उदाहरण के लिए, एक प्रकार का एल्गोरिथ्म जिसे वर्गीकरण एल्गोरिथ्म कहा जाता है, जो डेटा को विभिन्न समूहों में विभाजित कर सकता है। एक वर्गीकरण एल्गोरिथ्म जो हस्तलिखित संख्याओं को पहचानता है, को कोड की एक पंक्ति को संशोधित किए बिना ईमेल को स्पैम और सामान्य मेल में विभाजित करने के लिए इस्तेमाल किया जा सकता है। एल्गोरिथ्म नहीं बदला है, लेकिन इनपुट डेटा को प्रशिक्षित किया गया है, इसलिए यह एक अलग वर्गीकरण तर्क देता है।
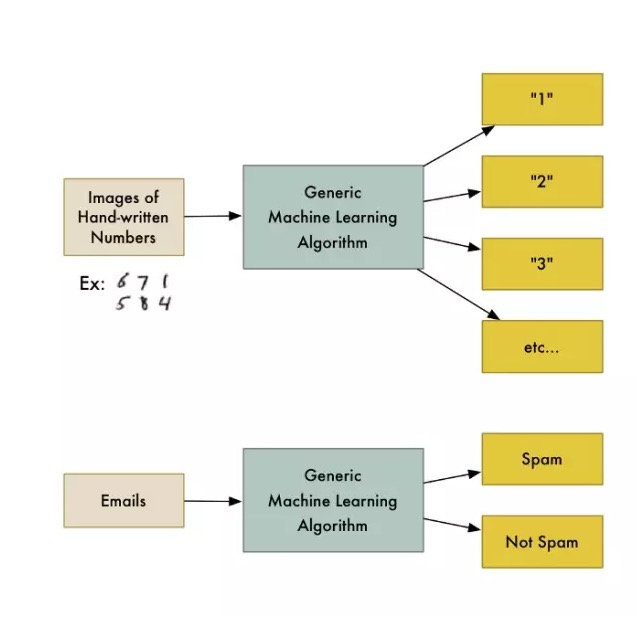
मशीन लर्निंग एल्गोरिदम एक ब्लैक बॉक्स है जिसका उपयोग कई अलग-अलग वर्गीकरण समस्याओं को हल करने के लिए किया जा सकता है।
मशीन लर्निंग एक व्यापक शब्द है जो कई समान आनुवंशिक एल्गोरिदम को कवर करता है
- ### दो प्रकार के मशीन सीखने के एल्गोरिदम
आप मशीन लर्निंग एल्गोरिदम को दो श्रेणियों में विभाजित कर सकते हैं: पर्यवेक्षित लर्निंग और अनसुरीक्षित लर्निंग। दोनों के बीच का अंतर सरल है, लेकिन यह बहुत महत्वपूर्ण है।
-
पर्यवेक्षित शिक्षा
मान लीजिए कि आप एक रियल एस्टेट एजेंट हैं, और आपका व्यवसाय बड़ा हो रहा है, इसलिए आपने अपने लिए एक इंटर्नशिप ली है। लेकिन समस्या यह है कि आप एक घर को देख सकते हैं और यह पता लगा सकते हैं कि यह कितना लायक है, और इंटर्नशिप के पास कोई अनुभव नहीं है, वे नहीं जानते कि कैसे मूल्यांकन करना है।
अपने इंटर्न की मदद करने के लिए (शायद अपने आप को छुट्टी पर जाने के लिए मुक्त करने के लिए), आपने एक छोटा सा सॉफ्टवेयर बनाने का फैसला किया है जो आपके क्षेत्र में घरों के मूल्य का आकलन करेगा जैसे कि घरों के आकार, इलाके और समान घरों के लिए लेनदेन की कीमत।
आप तीन महीने में शहर में हुए हर घर के सौदे को लिखते हैं, और हर एक के बारे में आप विस्तार से लिखते हैं - बेडरूम की संख्या, घर का आकार, जमीन, आदि। लेकिन सबसे महत्वपूर्ण बात यह है कि आप अंतिम सौदे की कीमत लिखते हैंः
यह हमारे प्रशिक्षण का डेटा है।
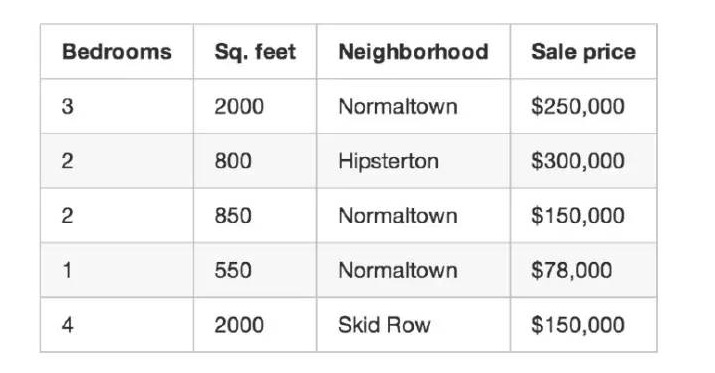
हम इस प्रशिक्षण डेटा का उपयोग करके एक प्रोग्राम लिखेंगे जो इस क्षेत्र में अन्य घरों के मूल्य का अनुमान लगाएगाः

इसे ही हम Supervised Learning कहते हैं आप पहले से ही जानते हैं कि प्रत्येक घर की बिक्री मूल्य क्या है दूसरे शब्दों में, आप जानते हैं कि प्रश्न का उत्तर क्या है और आप इसके उत्तर को उलटा समझ सकते हैं
सॉफ़्टवेयर लिखने के लिए, आप अपने मशीन लर्निंग एल्गोरिथ्म में प्रत्येक संपत्ति के प्रशिक्षण डेटा को इनपुट करेंगे। एल्गोरिथ्म यह पता लगाने की कोशिश करता है कि मूल्य संख्या प्राप्त करने के लिए किस प्रकार का संचालन किया जाना चाहिए।
यह एक अंकगणित अभ्यास प्रश्न की तरह है, जिसमें अंकगणित के सभी संकेतक मिटा दिए गए हैंः
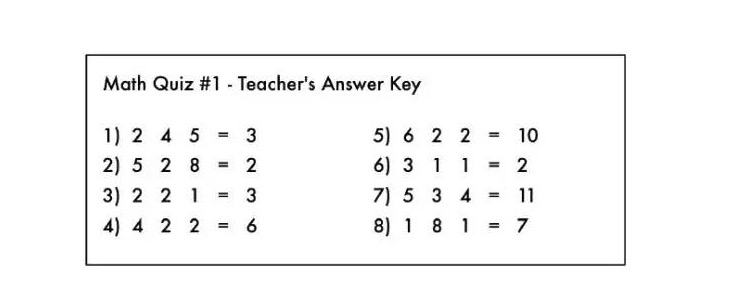
हे भगवान! एक चालाक छात्र ने टीचर के जवाब पर अंकगणित के सभी चिह्नों को मिटा दिया।
क्या आप समझ सकते हैं कि इन परीक्षणों में कौन सी गणित की समस्याएं हैं? आप जानते हैं कि आपको क्या करना चाहिए, और आपको क्या करना चाहिए, और आपको क्या करना चाहिए, और आपको क्या करना चाहिए, और आपको क्या करना चाहिए, और आपको क्या करना चाहिए, और आपको क्या करना चाहिए, और आपको क्या करना चाहिए, और आपको क्या करना चाहिए, और आपको क्या करना चाहिए, और आपको क्या करना चाहिए, और आपको क्या करना चाहिए, और आपको क्या करना चाहिए, और आपको क्या करना चाहिए।
अनुरक्षित सीखने में, आप कंप्यूटर को आपके लिए संख्याओं के बीच संबंधों की गणना करने देते हैं। और एक बार जब आप जानते हैं कि इस तरह की विशेष समस्या को हल करने के लिए आवश्यक गणितीय तरीके हैं, तो आप अन्य प्रकार की समस्याओं को हल कर सकते हैं।
-
गैर-निगरानी वाली शिक्षा
अब, चलो उस रियल एस्टेट एजेंट के उदाहरण पर वापस जाते हैं, जो हमने शुरू में दिया था। अगर आपको नहीं पता कि हर घर की बिक्री मूल्य क्या है, तो आप बहुत अच्छे तरीके से सीख सकते हैं, भले ही आप केवल घर के आकार, स्थान आदि के बारे में जानते हों। यह अनसुनीकृत सीखने के रूप में जाना जाता है।
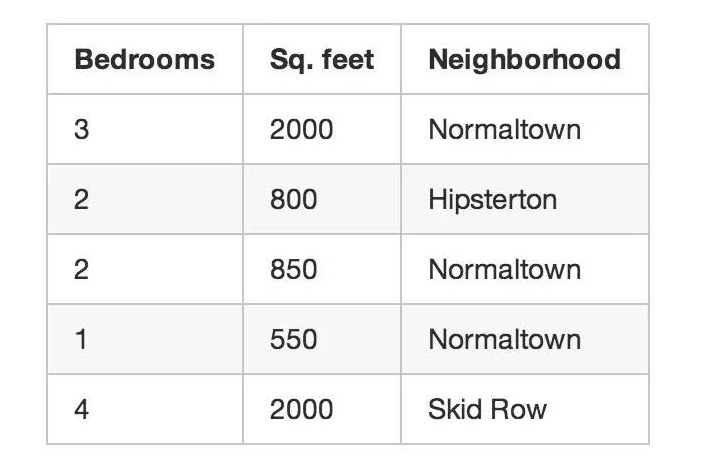
यदि आप किसी अज्ञात डेटा (जैसे कि कीमत) की भविष्यवाणी नहीं करना चाहते हैं, तो भी आप मशीन लर्निंग का उपयोग करके कुछ दिलचस्प कर सकते हैं।
यह कुछ इस तरह है जैसे किसी ने आपको एक कागज दिया हो जिस पर बहुत सारे नंबर लिखे हों, और वह आपसे कहे, “मुझे नहीं पता कि इन नंबरों का क्या मतलब है, लेकिन शायद आप इन नंबरों से नियम निकाल सकते हैं या उन्हें वर्गीकृत कर सकते हैं, या कुछ और - आपको शुभकामनाएं! “
आप इस डेटा के साथ क्या कर सकते हैं? सबसे पहले, आप एक एल्गोरिथ्म का उपयोग कर सकते हैं जो स्वचालित रूप से डेटा से अलग-अलग बाजार खंडों को अलग करता है। शायद आप पाएंगे कि कॉलेज के पास के घर खरीदार छोटे लेकिन अधिक बेडरूम वाले घरों को पसंद करते हैं, जबकि उपनगरीय घर खरीदार तीन बेडरूम वाले घरों को पसंद करते हैं। यह जानकारी सीधे आपके विपणन में मदद कर सकती है।
और आप कुछ ऐसा भी कर सकते हैं जो बहुत ही अच्छा है, और आप अपने आप ही घरों की कीमतों के बारे में अलग-अलग आंकड़े पा सकते हैं, जो अन्य आंकड़ों से अलग हैं। और ये अलग-अलग घरों के बारे में अलग-अलग आंकड़े हो सकते हैं, और आप इन क्षेत्रों में अपने सबसे अच्छे विक्रेताओं को केंद्रित कर सकते हैं, क्योंकि वे अधिक कमीशन लेते हैं।
इस लेख के बाद के भाग में हम मुख्य रूप से पर्यवेक्षित सीखने के बारे में बात करेंगे, लेकिन यह इसलिए नहीं है क्योंकि गैर-निरीक्षित सीखने की उपयोगिता कम है या यह बेकार है। वास्तव में, गैर-निरीक्षित सीखने के लिए महत्वपूर्ण हो रहा है क्योंकि एल्गोरिदम में सुधार के साथ, डेटा को सही उत्तरों से जोड़ना आवश्यक नहीं है।
पुराने सीखने के लिएः वहाँ कई अन्य प्रकार के मशीन सीखने के एल्गोरिदम हैं. लेकिन यह एक शुरुआती के लिए समझने के लिए अच्छा है.
यह बहुत अच्छा है, लेकिन क्या वास्तव में मूल्य निर्धारण को सीखने की कुंजी के रूप में देखा जा सकता है?
एक मानव के रूप में, आपका मस्तिष्क ज्यादातर स्थितियों का सामना कर सकता है और बिना किसी स्पष्ट निर्देश के सीख सकता है कि उन्हें कैसे संभालना है। यदि आप एक रियल एस्टेट एजेंट हैं, तो लंबे समय तक, आपके पास संपत्ति की उचित कीमत, इसका सबसे अच्छा विपणन, और कौन से ग्राहकों को दिलचस्पी होगी, आदि के बारे में एक सहज ज्ञान होगा। मजबूत एआई अनुसंधान का लक्ष्य कंप्यूटर द्वारा इस क्षमता की नकल करना है।
लेकिन वर्तमान मशीन सीखने के एल्गोरिदम बहुत अच्छे नहीं हैं, वे केवल बहुत ही विशिष्ट और सीमित समस्याओं पर ध्यान केंद्रित कर सकते हैं। शायद इस मामले में, एक सीखने की कुंडली की एक अधिक उपयुक्त परिभाषा यह है कि एक विशेष समस्या को हल करने के लिए एक समीकरण का पता लगाने के लिए, उदाहरण डेटा की एक छोटी मात्रा के आधार पर।
दुर्भाग्यवश, उदाहरण डेटा की एक छोटी राशि के आधार पर एक विशेष समस्या को हल करने के लिए एक समीकरण खोजने के लिए एक पिरोया मशीन को एक बुरा नाम दिया गया था। इसलिए अंत में हमने पिरोया मशीन सीखने के लिए पिरोया को बदल दिया।
बेशक, यदि आप 50 साल बाद इस लेख को पढ़ रहे हैं, तो हमारे पास एक मजबूत एआई एल्गोरिथ्म है, और यह एक प्राचीन वस्तु की तरह दिखता है। भविष्य के मानव, आप अभी भी इसे नहीं पढ़ते हैं, अपने मशीन नौकर को सैंडविच बनाने के लिए कहें।
चलो कोड लिखते हैं!
तो, यदि आप अपने घर के मूल्य निर्धारण की प्रक्रिया को पहले उदाहरण में लिखते हैं, तो आप क्या लिखेंगे? नीचे जाने से पहले सोचें।
यदि आप मशीन लर्निंग के बारे में कुछ भी नहीं जानते हैं, तो संभावना है कि आप घरों की कीमतों का आकलन करने के लिए कुछ बुनियादी नियम लिखने की कोशिश करेंगे, जैसे किः
def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood): price = 0 # In my area, the average house costs $200 per sqft price_per_sqft = 200 if neighborhood == "hipsterton": # but some areas cost a bit more price_per_sqft = 400 elif neighborhood == "skid row": # and some areas cost less price_per_sqft = 100 # start with a base price estimate based on how big the place is price = price_per_sqft * sqft # now adjust our estimate based on the number of bedrooms if num_of_bedrooms == 0: # Studio apartments are cheap price = price — 20000 else: # places with more bedrooms are usually # more valuable price = price + (num_of_bedrooms * 1000) return priceयदि आप कुछ घंटों के लिए इस तरह से काम करते हैं, तो आप शायद कुछ हासिल कर सकते हैं, लेकिन आपका प्रोग्राम कभी भी सही नहीं होगा, और जब कीमतें बदलती हैं तो इसे बनाए रखना मुश्किल हो सकता है।
अगर कंप्यूटर को यह पता लगाने में मदद मिलती है कि यह कैसे कार्य करता है, तो क्या यह बेहतर नहीं होगा? जब तक कि यह सही घर की कीमत वापस करता है, तो कौन परवाह करता है कि यह क्या करता है?
def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood): price = <computer, plz do some math for me> return priceइस सवाल पर विचार करने का एक तरीका यह है कि घर की कीमतों को एक स्वादिष्ट व्यंजन के कटोरे के रूप में देखा जाए, और व्यंजन में घटक बेडरूम की संख्या, क्षेत्रफल और भूखंड हैं। यदि आप गणना कर सकते हैं कि प्रत्येक घटक अंतिम कीमत पर कितना प्रभाव डालता है, तो शायद आप विभिन्न सामग्रियों को मिश्रित कर सकते हैं और अंतिम मूल्य के लिए एक विशिष्ट अनुपात प्राप्त कर सकते हैं।
यह आपके मूल कार्यक्रम को सरल करता है (जो कि एक पागल if else कथन है) कुछ इस तरह दिखता हैः
def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood): price = 0 # a little pinch of this price += num_of_bedrooms * .841231951398213 # and a big pinch of that price += sqft * 1231.1231231 # maybe a handful of this price += neighborhood * 2.3242341421 # and finally, just a little extra salt for good measure price += 201.23432095 return price841231951398213, 1231.1231231, 2.3242341421, और 201.23432095. इनको भार कहते हैं. अगर हम हर घर पर लागू होने वाले सही भार को ढूंढ सकें, तो हमारा फंक्शन सभी घरों की कीमतों की भविष्यवाणी कर सकता है!
सबसे अच्छा वजन पता लगाने के लिए एक सरल तरीका इस प्रकार हैः
चरण 1:
सबसे पहले, प्रत्येक को 1.0 पर सेट करेंः
def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood): price = 0 # a little pinch of this price += num_of_bedrooms * 1.0 # and a big pinch of that price += sqft * 1.0 # maybe a handful of this price += neighborhood * 1.0 # and finally, just a little extra salt for good measure price += 1.0 return priceचरण 2:
प्रत्येक घर को अपने फंक्शनल ऑपरेशन में लाएं और जांचें कि अनुमानित मूल्य सही मूल्य से कितना अलग हैः
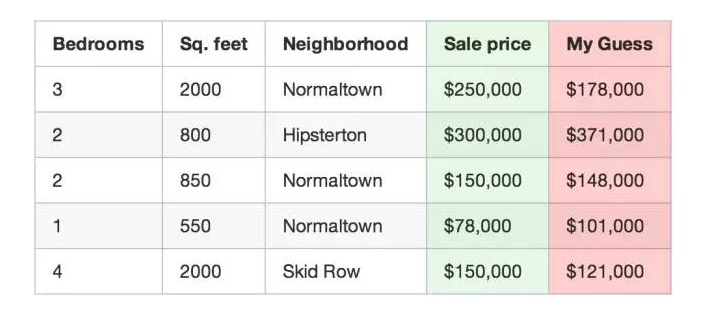
अपने प्रोग्राम का उपयोग करके घरों की कीमतों की भविष्यवाणी करें।
उदाहरण के लिए, पहली संपत्ति की वास्तविक बिक्री मूल्य \(250,000 है, और आपके फ़ंक्शन का अनुमान \)178,000 है, जो आपको $72,000 कम कर देता है।
और फिर अपने डेटासेट में प्रत्येक संपत्ति के मूल्यांकन के मूल्य वर्ग के बाद की गणना. मान लीजिए कि आपके डेटासेट में 500 संपत्ति के लेनदेन हैं, तो कुल $ 86,123,373 के मूल्य वर्ग की गणना. यह दर्शाता है कि आपके फ़ंक्शन अब कितना सही है.
अब, 500 द्वारा कुल मूल्य को विभाजित करें और प्रत्येक संपत्ति का अनुमान औसत से अलग है। इस औसत त्रुटि को आपके फ़ंक्शन की लागत कहें।
यदि आप इस मूल्य को 0 करने के लिए भार को समायोजित कर सकते हैं, तो आपका फ़ंक्शन सही है. इसका मतलब है कि आपके प्रोग्राम ने इनपुट डेटा के आधार पर प्रत्येक रियल एस्टेट लेनदेन का अनुमान लगाया है. और यही कारण है कि हमारा लक्ष्य विभिन्न भारों का प्रयास करना है ताकि कीमत कम हो सके.
चरण 3:
चरण 2 को बार-बार दोहराएं, सभी संभावित भारित संयोजनों को आज़माएं. जो संयोजन लागत को 0 के सबसे करीब लाता है, वह है जो आप उपयोग करना चाहते हैं, और जब तक आप इस तरह के संयोजनों को ढूंढते हैं, समस्या हल हो जाती है!
विचार समय को बाधित करते हैं
यह बहुत सरल है, है ना? सोचिए कि आपने अभी क्या किया है. आपने कुछ आंकड़े प्राप्त किए हैं, उन्हें तीन सामान्य सरल चरणों में दर्ज किया है, और अंत में आपको एक ऐसा फ़ंक्शन मिलता है जो आपके क्षेत्र के घरों का मूल्यांकन कर सकता है. लेकिन निम्नलिखित तथ्य आपको परेशान कर सकते हैंः
-
- पिछले 40 वर्षों में, कई क्षेत्रों (जैसे भाषाविज्ञान / अनुवाद) में किए गए अध्ययनों से पता चलता है कि इस तरह के सामान्य गतिशील डेटा पिंजरे (जैसे कि मैंने जो शब्द बनाए हैं) सीखने के एल्गोरिदम ने वास्तविक लोगों के स्पष्ट नियमों का उपयोग करने की आवश्यकता वाले तरीकों को हरा दिया है। मशीन सीखने के पिंजरे के तरीकों ने अंततः मानव विशेषज्ञों को हरा दिया।
-
- आपके द्वारा लिखे गए अंतिम फ़ंक्शन वास्तव में एक पहेली है, यह नहीं जानता कि पहेली का क्षेत्रफल क्या है और पहेली के बेडरूम की संख्या क्या है। यह केवल यह जानता है कि सही उत्तर प्राप्त करने के लिए संख्याओं को हिलाएं और बदलें।
-
- यह संभव है कि आप यह नहीं जानते कि विशेष भारों का एक सेट क्यों काम करता है। तो आप बस एक ऐसा फ़ंक्शन लिखते हैं जिसे आप वास्तव में नहीं समझते हैं लेकिन आप इसे साबित कर सकते हैं।
-
- कल्पना कीजिये कि आपके प्रोग्राम में पिक्सेल के एक सेट को स्वीकार करने के बजाय पिक्सेल के क्षेत्रफल पिक्सेल और पिक्सेल के बेडरूम पिक्सेल जैसे पैरामीटर हैं। मान लीजिये कि प्रत्येक पिक्सेल आपके कार के छत पर लगे कैमरे द्वारा कैप्चर की गई छवि में से एक पिक्सेल का प्रतिनिधित्व करता है, और अनुमानित आउटपुट को पिक्सेल के मूल्य पिक्सेल के रूप में नहीं बल्कि पिक्सेल के स्टीयरिंग डिग्री पिक्सेल के रूप में जाना जाता है, तो आपके पास एक प्रोग्राम है जो आपकी कार को स्वचालित रूप से नियंत्रित कर सकता है!
पागलपन, है ना?
चरण 3 में प्रत्येक अंक के साथ क्या होता है?
ठीक है, निश्चित रूप से आप सभी संभावित भारों को आज़माने में सक्षम नहीं होंगे ताकि आप सबसे अच्छा संयोजन पा सकें। यह एक लंबा समय ले सकता है, क्योंकि यह अंतहीन हो सकता है। इस स्थिति से बचने के लिए, गणितज्ञों ने बहुत सारे चतुर तरीके खोजे हैं जो बहुत कोशिश किए बिना जल्दी से अच्छे वजन का पता लगा सकते हैं। नीचे एक है: सबसे पहले, एक सरल समीकरण लिखें जो चरण 2 को दर्शाता हैः
यह आपकी लागत है
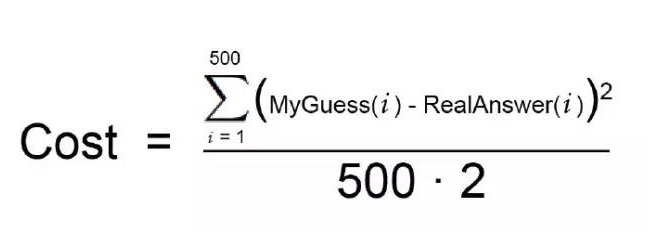
अब, आइए हम मशीन लर्निंग के साथ एक ही समीकरण को फिर से लिखें (अब आप उन्हें अनदेखा कर सकते हैं):
θ वर्तमान भार को दर्शाता है. J ((θ) का अर्थ है कि वर्तमान भार के लिए लागत है.
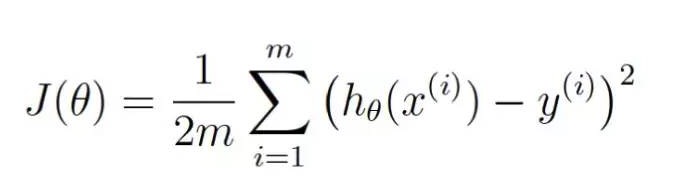
यह समीकरण वर्तमान भारित मूल्य पर हमारे मूल्यांकन प्रक्रिया के विचलन की मात्रा को दर्शाता है।
यदि हम बेडरूम की संख्या और क्षेत्रफल के लिए दिए गए सभी संभावित भारों को ग्राफिक रूप में प्रदर्शित करते हैं, तो हम नीचे दिए गए चित्र की तरह एक आरेख प्राप्त करते हैंः
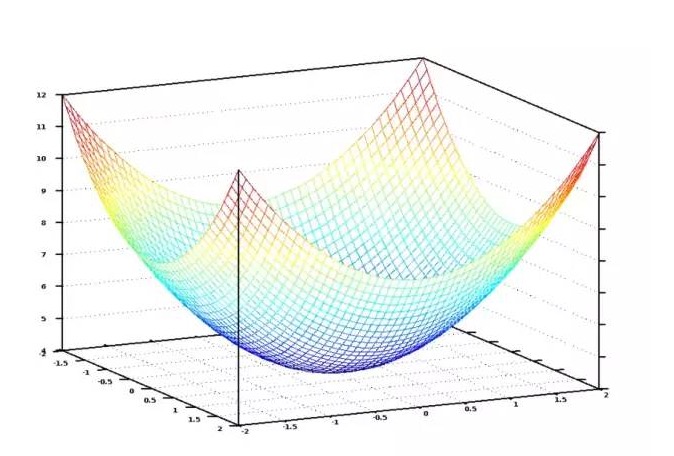
व्यय फ़ंक्शन का ग्राफ़िक चित्र एक कटोरा
नीले रंग का सबसे कम बिंदु वह है जहां लागत सबसे कम है, यानी हमारा प्रोग्राम सबसे कम विचलित है। उच्चतम बिंदु का अर्थ है कि यह सबसे अधिक विचलित है। इसलिए, यदि हम उन भारों का एक सेट ढूंढ सकते हैं जो हमें सबसे कम बिंदु तक ले जाते हैं, तो हमें इसका जवाब मिल गया है!
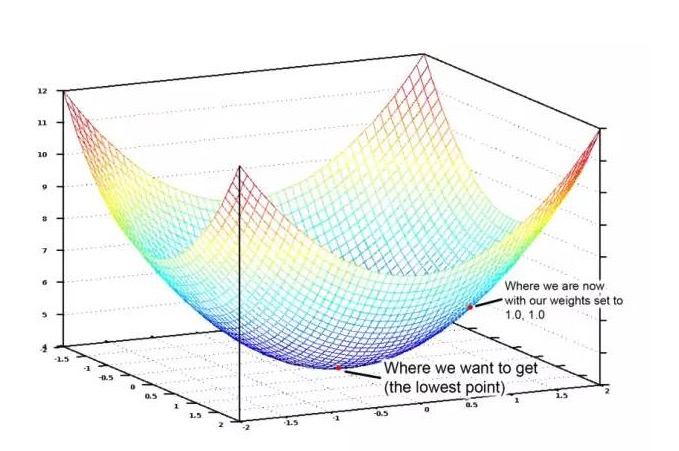
इसलिए, हमें केवल वजन को समायोजित करने की आवश्यकता है ताकि हम चार्ट पर निचले बिंदु की ओर एक ढलान पर चल सकें। यदि वजन के लिए छोटे समायोजन हमें निचले बिंदु की ओर चलते रहने की अनुमति देते हैं, तो अंततः हमें बहुत अधिक वजन के प्रयास के बिना वहां पहुंचने की आवश्यकता नहीं है।
अगर आपको कुछ याद है, तो आपको याद होगा कि अगर आप किसी फ़ंक्शन के बारे में पूछते हैं, तो यह आपको बताता है कि फ़ंक्शन किसी भी बिंदु पर कितना झुका हुआ है। दूसरे शब्दों में, यह हमें बताता है कि किसी दिए गए बिंदु के लिए, यह एक ढलान वाला रास्ता है। हम इस बिंदु का उपयोग कर सकते हैं और नीचे की ओर बढ़ सकते हैं।
तो, अगर हम हर वजन के बारे में लागत फ़ंक्शन के लिए पूर्वाग्रह करते हैं, तो हम प्रत्येक वजन से मूल्य को घटा सकते हैं। यह हमें नीचे की ओर ले जाता है। ऐसा करते रहें, और अंत में हम नीचे तक पहुंचेंगे और वजन का सबसे अच्छा मूल्य प्राप्त करेंगे। (यदि आप पढ़ नहीं सकते हैं, तो चिंता न करें, नीचे पढ़ें) ।
सबसे अच्छा वजन खोजने के लिए इस विधि को थोक अवरोही अवरोही कहा जाता है, और यह इसके बारे में एक उच्च-अवरोही है। यदि आप विवरण को समझना चाहते हैं, तो डरो मत, और गहराई से नीचे जाएं।
जब आप वास्तविक समस्याओं को हल करने के लिए मशीन लर्निंग एल्गोरिदम की लाइब्रेरी का उपयोग करते हैं, तो यह सब आपके लिए तैयार है। लेकिन कुछ विशिष्ट विवरणों को समझना हमेशा उपयोगी होता है।
क्या आप कुछ और छोड़ रहे हैं?
तीन चरणों में मैंने ऊपर वर्णित एल्गोरिथ्म को बहु-रेखीय वापसी कहा जाता है। आपका अनुमान समीकरण एक ऐसी सीधी रेखा है जो सभी घरों की कीमतों के डेटा बिंदुओं को फिट करती है। फिर, आप इस समीकरण का उपयोग उन घरों की कीमतों का अनुमान लगाने के लिए करते हैं जिन्हें आपने कभी नहीं देखा है, जहां घरों की कीमतें आपकी सीधी रेखा पर हो सकती हैं। यह एक शक्तिशाली विचार है जिसका उपयोग वास्तविक घरों की समस्या को हल करने के लिए किया जा सकता है।
लेकिन यह तरीका जो मैंने आपको दिखाया है, यह सरल परिस्थितियों में काम कर सकता है, और यह सभी परिस्थितियों में काम नहीं करेगा। इसका एक कारण यह है कि घरों की कीमतें हमेशा एक सीधी रेखा का पालन नहीं करती हैं।
लेकिन, सौभाग्य से, इस स्थिति से निपटने के लिए कई तरीके हैं। गैर-रैखिक डेटा के लिए, कई अन्य प्रकार के मशीन सीखने के एल्गोरिदम काम कर सकते हैं (जैसे कि न्यूरल नेटवर्क या न्यूक्लियर वेक्टर मशीन) । और कई तरीके हैं जो रैखिक प्रतिगमन को अधिक लचीले तरीके से लागू करते हैं, और अधिक जटिल लाइनों के साथ फिट करने के लिए सोचते हैं। सभी स्थितियों में, इष्टतम भारित मूल्य खोजने का मूल विचार अभी भी लागू होता है।
इसके अलावा, मैं मिलान की अवधारणा को अनदेखा करता हूं। यह बहुत आसान है कि वे आपके मूल डेटासेट में घर की कीमतों के लिए सही भविष्यवाणी कर सकते हैं, लेकिन मूल डेटासेट के बाहर किसी भी नए घर के लिए नहीं। इस स्थिति के लिए कई समाधान हैं (जैसे कि औपचारिककरण और क्रॉस-वैलिडेशन डेटासेट का उपयोग करना) । यह सीखना कि इस समस्या से कैसे निपटना है मशीन सीखने को सुचारू रूप से लागू करने के लिए महत्वपूर्ण है।
दूसरे शब्दों में, मूल अवधारणा बहुत सरल है, और यह कुछ कौशल और अनुभव की आवश्यकता है जो मशीन सीखने का उपयोग करने के लिए उपयोगी परिणाम प्राप्त करने के लिए किया जा सकता है। लेकिन यह एक कौशल है जिसे हर डेवलपर सीख सकता है।
-
-
क्या मशीन लर्निंग की कोई सीमा नहीं है?
एक बार जब आप यह समझने लगते हैं कि मशीन लर्निंग तकनीक को आसानी से लागू किया जा सकता है, तो आपको लगता है कि यदि आपके पास पर्याप्त डेटा है, तो आप मशीन लर्निंग का उपयोग करके किसी भी समस्या को हल कर सकते हैं। आपको बस डेटा डालना होगा और कंप्यूटर के लिए सही समीकरण ढूंढना होगा।
लेकिन यह याद रखना महत्वपूर्ण है कि मशीन लर्निंग केवल उन समस्याओं पर लागू होता है जो आपके पास मौजूद डेटा के साथ हल किए जा सकते हैं।
उदाहरण के लिए, यदि आप एक मॉडल बनाते हैं जो घरों के अंदर पौधों की संख्या के आधार पर घरों की कीमतों का अनुमान लगाता है, तो यह कभी सफल नहीं होगा। घरों में पौधों की संख्या और घरों की कीमतों के बीच कोई संबंध नहीं है। इसलिए, चाहे वह कितना भी कोशिश करे, कंप्यूटर दोनों के बीच संबंध का अनुमान नहीं लगा सकता।
आप केवल उन रिश्तों को मॉडल कर सकते हैं जो वास्तव में मौजूद हैं।
-
कैसे गहराई से सीखें
मुझे लगता है कि मशीन लर्निंग के साथ सबसे बड़ी समस्या यह है कि यह मुख्य रूप से अकादमिक और व्यावसायिक अनुसंधान संगठनों में सक्रिय है।
प्रोफेसर एंड्रयू एनजी: Coursera पर मुफ्त मशीन सीखने का कोर्स बहुत अच्छा है। मैं इसे शुरू करने की अत्यधिक अनुशंसा करता हूं।
इसके अलावा, आप SciKit-Learn को डाउनलोड और इंस्टॉल कर सकते हैं और इसका उपयोग हजारों मशीन लर्निंग एल्गोरिदम का परीक्षण करने के लिए कर सकते हैं। यह एक पायथन फ्रेमवर्क है, जिसमें सभी मानक एल्गोरिदम के लिए ब्लैक बॉक्स संस्करण हैं।
पायथन डेवलपर्स से पुनः प्राप्त किया गया