सात रिग्रेशन तकनीकें जिनमें आपको महारत हासिल करनी चाहिए
 0
3362
0
3362
सात रिग्रेशन तकनीकें जिनमें आपको महारत हासिल करनी चाहिए
**इस लेख में रिग्रेशन विश्लेषण और इसके लाभों की व्याख्या की गई है, जिसमें सात सबसे अधिक उपयोग की जाने वाली रिग्रेशन तकनीकों और उनके प्रमुख तत्वों को संक्षेप में प्रस्तुत किया गया है, जैसे कि रैखिक रिग्रेशन, लॉजिक रिग्रेशन, बहुपद रिग्रेशन, क्रमिक रिग्रेशन, स्टैम्प रिग्रेशन, टोपी रिग्रेशन, इलास्टिकनेट रिग्रेशन, और अंत में सही रिग्रेशन मॉडल चुनने के लिए महत्वपूर्ण तत्वों का परिचय दिया गया है। ** ** एडिटर-बटन रिग्रेशन एनालिसिस डेटा मॉडलिंग और विश्लेषण के लिए एक महत्वपूर्ण उपकरण है। इस लेख में रिग्रेशन एनालिसिस के अर्थ और इसके लाभों की व्याख्या की गई है, जिसमें सात सबसे अधिक उपयोग की जाने वाली रिग्रेशन तकनीकों और उनके प्रमुख तत्वों को संक्षेप में प्रस्तुत किया गया है, जैसे कि रैखिक रिग्रेशन, लॉजिक रिग्रेशन, बहुपद रिग्रेशन, क्रमिक रिग्रेशन, फ्यूज रिग्रेशन, कॉर्ड रिग्रेशन, और ElasticNet रिग्रेशन। अंत में, सही रिग्रेशन मॉडल चुनने के लिए महत्वपूर्ण तत्वों का परिचय दिया गया है।**
- ### क्या है रिग्रेशन एनालिसिस?
रिग्रेशन विश्लेषण एक भविष्य कहनेवाला मॉडलिंग तकनीक है जो कारक (उद्देश्य) और कारक (प्रत्याशांक) के बीच संबंधों का अध्ययन करती है। यह तकनीक आमतौर पर पूर्वानुमान विश्लेषण, समय-क्रम मॉडल और पाया गया चर के बीच कारण-संबंधों के लिए उपयोग की जाती है। उदाहरण के लिए, ड्राइवरों के लापरवाह ड्राइविंग और सड़क यातायात दुर्घटनाओं की संख्या के बीच संबंध का अध्ययन करने का सबसे अच्छा तरीका रिग्रेशन है।
Regression analysis एक महत्वपूर्ण tool है जो data को modeling और analysis करने के लिए उपयोग किया जाता है. यहाँ हम curve/line का उपयोग कर data points को fit करते हैं और इस तरह curve या line से data point तक की दूरी में अंतर कम से कम होता है. मैं इसे अगले भाग में विस्तार से समझाऊंगा.
- ### हम रिग्रेशन एनालिटिक्स का उपयोग क्यों करते हैं?
जैसा कि ऊपर बताया गया है, रिग्रेशन विश्लेषण दो या दो से अधिक चरों के बीच संबंधों का अनुमान लगाता है. इसे समझने के लिए, आइए एक सरल उदाहरण देखेंः
उदाहरण के लिए, वर्तमान आर्थिक परिस्थितियों में, आप एक कंपनी की बिक्री में वृद्धि का अनुमान लगाते हैं। अब, आपके पास नवीनतम कंपनी के आंकड़े हैं, जो दिखाते हैं कि बिक्री में वृद्धि लगभग 2.5 गुना आर्थिक वृद्धि है। तो वापसी विश्लेषण का उपयोग करके, हम वर्तमान और अतीत की जानकारी के आधार पर भविष्य की कंपनी की बिक्री का अनुमान लगा सकते हैं।
रिग्रेशन विश्लेषण के उपयोग के कई लाभ हैं। विशेष रूप से निम्नलिखित हैंः
यह स्व-परिवर्तकों और कारक-परिवर्तकों के बीच एक महत्वपूर्ण संबंध को दर्शाता है।
यह एक कारक पर कई स्वयं-परिवर्तकों के प्रभाव की तीव्रता को दर्शाता है।
रिग्रेशन विश्लेषण हमें विभिन्न मापों पर मापने वाले चर के बीच परस्पर प्रभावों की तुलना करने की भी अनुमति देता है, जैसे कि मूल्य परिवर्तन और प्रचार गतिविधियों की संख्या के बीच संबंध। ये बाजार शोधकर्ताओं, डेटा विश्लेषकों और डेटा वैज्ञानिकों को भविष्यवाणी मॉडल बनाने के लिए सबसे अच्छे चर के एक समूह को बाहर निकालने और अनुमान लगाने में मदद करने के लिए उपयोगी हैं।
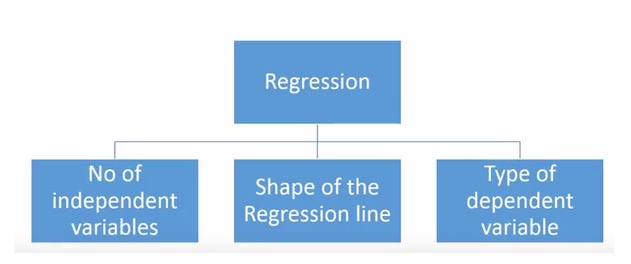
- ### हमारे पास कितनी प्रकार की वापसी तकनीकें हैं?
विभिन्न प्रकार की प्रत्यावर्तन तकनीकें हैं जिनका उपयोग भविष्यवाणी करने के लिए किया जाता है। इन तकनीकों में मुख्य रूप से तीन माप हैं: स्वयं-परिवर्तन की संख्या, स्वयं-परिवर्तन का प्रकार और प्रत्यावर्तन रेखा का आकार। हम उन्हें नीचे दिए गए भाग में विस्तार से चर्चा करेंगे।
उन लोगों के लिए जो रचनात्मक हैं, यदि आपको लगता है कि उपरोक्त मापदंडों के संयोजन का उपयोग करना आवश्यक है, तो आप एक ऐसा प्रतिगमन मॉडल भी बना सकते हैं जिसका उपयोग नहीं किया गया है। लेकिन इससे पहले कि आप शुरू करें, सबसे अधिक उपयोग किए जाने वाले प्रतिगमन विधियों के बारे में जानेंः
-
1. रैखिक प्रतिगमन
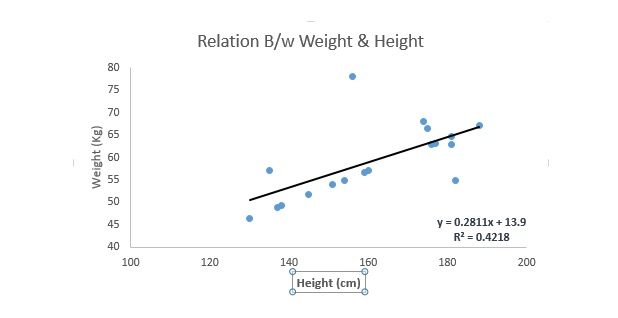
यह सबसे प्रसिद्ध मॉडलिंग तकनीकों में से एक है। रैखिक रिग्रेशन आमतौर पर उन तकनीकों में से एक है जिन्हें लोग भविष्यवाणी मॉडल सीखने के लिए चुनते हैं। इस तकनीक में, रिग्रेशन लाइनों की प्रकृति रैखिक है, क्योंकि चर निरंतर हैं, स्वयं-परिवर्तकों को निरंतर या अलग-थलग किया जा सकता है।
रैखिक रिग्रेशन में सबसे अच्छा समरूपता रेखा ((यानी रिग्रेशन लाइन) का उपयोग किया जाता है, जिसके माध्यम से एक संबंध बनाया जाता है, जिसके परिणामस्वरूप एक या एक से अधिक स्वयं-परिवर्तकों ((Y) और एक या एक से अधिक स्वयं-परिवर्तकों ((X)) के बीच संबंध स्थापित किया जाता है।
हम इसे एक समीकरण के रूप में लिखते हैं, y=a+b*X + e, जहां a का मतलब है अंतर, b का मतलब है एक सीधी रेखा की तिरछाई, और e त्रुटि है. यह समीकरण लक्ष्य चर के मानों की भविष्यवाणी करने के लिए दिए गए पूर्वानुमान चर (s) के आधार पर काम कर सकता है.
एकवचन रैखिक प्रतिगमन और बहुवचन रैखिक प्रतिगमन के बीच अंतर यह है कि बहुवचन रैखिक प्रतिगमन में ((>1) एक चर होता है, जबकि एकवचन रैखिक प्रतिगमन में आमतौर पर केवल एक चर होता है। अब सवाल यह है कि हम एक इष्टतम मिलान रेखा कैसे प्राप्त कर सकते हैं?
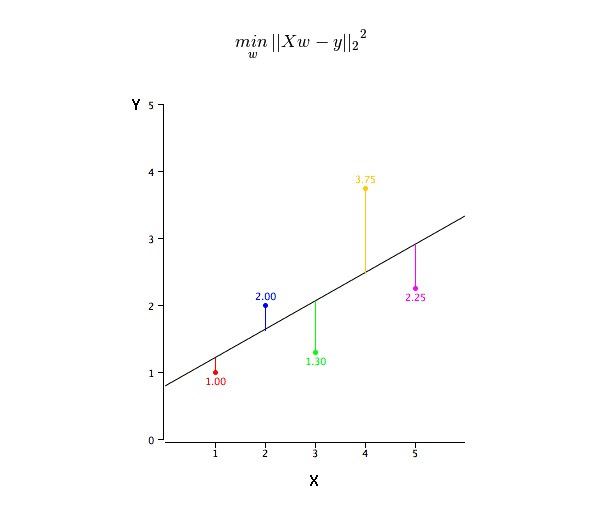
सबसे अच्छा मिलान लाइन (a और b) के मान कैसे प्राप्त करें?
इस समस्या को न्यूनतम द्विगुणन द्वारा आसानी से पूरा किया जा सकता है। न्यूनतम द्विगुणन भी वापसी रेखा को संरेखित करने के लिए सबसे अधिक उपयोग की जाने वाली विधि है। अवलोकन डेटा के लिए, यह प्रत्येक डेटा बिंदु को लाइन में लंबवत विचलन के वर्गों के योग को कम करके सबसे अच्छा संरेखण रेखा की गणना करता है। चूंकि जोड़ने पर, विचलन पहले वर्ग होता है, इसलिए सकारात्मक और नकारात्मक मानों को ऑफसेट नहीं किया जाता है।
हम मॉडल के प्रदर्शन का आकलन करने के लिए आर-स्क्वायर सूचकांकों का उपयोग कर सकते हैं। इन सूचकांकों के बारे में अधिक जानकारी के लिए, मॉडल प्रदर्शन सूचकांक भाग 1, भाग 2 पढ़ें।
क्या आप जानते हैं?
- स्वयं चर और कारक चर के बीच एक रैखिक संबंध होना चाहिए
- मल्टीपल रिग्रेशन में कई सह-रैखिकता, स्व-संबंधिता और विषमताएं होती हैं।
- रैखिक प्रतिगमन असामान्यताओं के प्रति अतिसंवेदनशील होता है। यह प्रतिगमन रेखा को प्रभावित करता है और अंततः पूर्वानुमानों को प्रभावित करता है।
- मल्टीपल को-लाइनरता कारक अनुमानों के अंतर को बढ़ाता है, जिससे मॉडल में मामूली बदलावों के साथ अनुमान बहुत संवेदनशील हो जाते हैं। नतीजतन, कारक अनुमान अस्थिर होते हैं।
- कई चरों के साथ, हम सबसे महत्वपूर्ण चरों का चयन करने के लिए आगे का चयन, पीछे का हटाना और चरणबद्ध फ़िल्टरिंग का उपयोग कर सकते हैं।
-
2. लॉजिस्टिक रिग्रेशन
लॉजिकल रिग्रेशन की गणना करने के लिए उपयोग किया जाता है कि किस प्रकार की घटनाएं होती हैं = Success और किस प्रकार की घटनाएं होती हैं = Failure. जब एक प्रकार का चर द्विआधारी है (जैसे 1 / 0, true/false, yes/no) चर, तो हमें लॉजिकल रिग्रेशन का उपयोग करना चाहिए। यहाँ, Y का मान 0 से 1 तक है, जिसे निम्नलिखित समीकरण द्वारा दर्शाया जा सकता है।
odds= p/ (1-p) = probability of event occurrence / probability of not event occurrence ln(odds) = ln(p/(1-p)) logit(p) = ln(p/(1-p)) = b0+b1X1+b2X2+b3X3....+bkXkउपरोक्त सूत्रों में, p किसी विशेष गुण के लिए एक संभावना को दर्शाता है. आप एक सवाल पूछ सकते हैं कि हम सूत्रों में लॉगरिदम का उपयोग क्यों करते हैं?
चूंकि हम यहाँ एक द्विपद वितरण का उपयोग कर रहे हैं, इसलिए हमें इस वितरण के लिए सबसे अच्छा संयोजन फ़ंक्शन चुनना होगा। यह लॉजिट फ़ंक्शन है। उपरोक्त समीकरण में, पैरामीटर का चयन नमूने की अत्यधिक संभावना के अनुमान के आधार पर किया जाता है, न कि वर्ग और त्रुटि को कम करने के लिए, जैसा कि सामान्य वापसी में उपयोग किया जाता है।
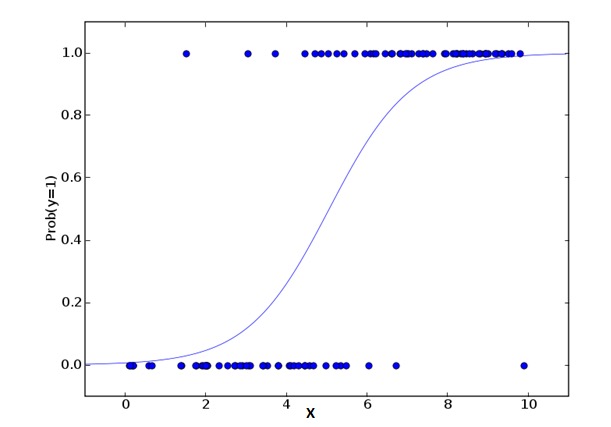
क्या आप जानते हैं?
- यह व्यापक रूप से वर्गीकरण के लिए प्रयोग किया जाता है।
- लॉजिकल रिग्रेशन के लिए यह आवश्यक नहीं है कि स्वयं-परिवर्तकों और कारक-परिवर्तकों का संबंध रैखिक हो। यह विभिन्न प्रकार के संबंधों को संभाल सकता है क्योंकि यह अनुमानित सापेक्ष जोखिम सूचकांक OR के लिए एक गैर-रैखिक लॉग रूपांतरण का उपयोग करता है।
- ओवरफिट और डिसफिट से बचने के लिए, हमें सभी महत्वपूर्ण चरों को शामिल करना चाहिए। इस स्थिति को सुनिश्चित करने के लिए एक अच्छा तरीका है कि हम लॉजिकल रिटर्न को अनुमानित करने के लिए चरण-दर-चरण फ़िल्टरिंग विधि का उपयोग करें।
- इसके लिए बड़ी मात्रा में नमूने की आवश्यकता होती है, क्योंकि कम संख्या में नमूने के साथ, बहुत अधिक संभावना है कि अनुमानित प्रभाव सामान्य न्यूनतम द्विगुणित से खराब है।
- स्व-परिवर्तकों को एक दूसरे से संबंधित नहीं होना चाहिए, यानी बहु-सह-रैखिकता नहीं है। हालांकि, विश्लेषण और मॉडलिंग में, हम वर्गीकृत चर के बीच बातचीत के प्रभाव को शामिल करने का विकल्प चुन सकते हैं।
- यदि एक परिमेय चर का मान एक क्रमबद्ध चर है, तो इसे क्रमबद्ध लॉजिक रिटर्न कहा जाता है।
- यदि यह एक बहुपद है, तो इसे बहुपद लॉजिक रिटर्न कहा जाता है।
-
3. बहुपद प्रतिगमन
एक प्रतिगमन समीकरण के लिए, यदि स्वयं-परिवर्तकों का सूचकांक 1 से अधिक है, तो यह एक बहुपद प्रतिगमन समीकरण है। यह निम्न समीकरण द्वारा दर्शाया गया हैः
y=a+b*x^2इस प्रकार की रिग्रेशन तकनीक में, इष्टतम मिलान रेखा एक सीधी रेखा नहीं है, बल्कि एक वक्र है जिसका उपयोग डेटा बिंदुओं को मिलान करने के लिए किया जाता है।
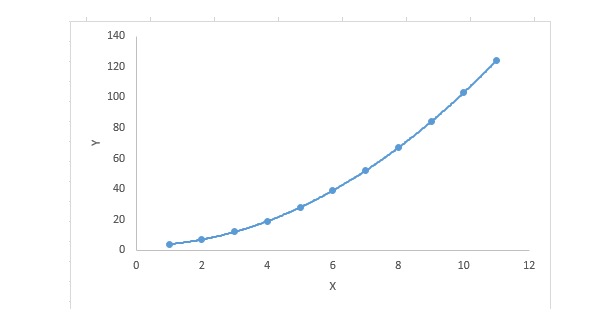
मुख्य बिंदु:
- हालांकि एक प्रेरण एक उच्च-स्तरीय बहुपद के लिए फिट हो सकता है और कम त्रुटि प्राप्त कर सकता है, यह ओवरफिट का कारण बन सकता है। आपको अक्सर एक संबंध आरेख बनाने की आवश्यकता होती है ताकि आप मिलान देख सकें, और यह सुनिश्चित करने पर ध्यान केंद्रित करें कि एक उचित मिलान न तो ओवरफिट और न ही खराब है। नीचे एक उदाहरण दिया गया है जो समझ में मदद कर सकता हैः
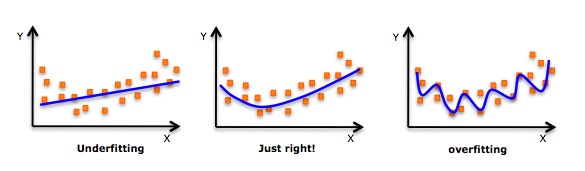
- स्पष्ट रूप से दोनों छोरों पर वक्र के बिंदुओं की तलाश करें और देखें कि क्या इन आकारों और रुझानों का कोई मतलब है। उच्च-स्तरीय बहुपदों के अंत में अजीब निष्कर्ष हो सकते हैं।
-
4. चरणबद्ध प्रतिगमन
हम इस प्रकार के रिग्रेशन का उपयोग कर सकते हैं जब हम कई चरों के साथ काम करते हैं। इस तकनीक में, चरों का चयन एक स्वचालित प्रक्रिया में किया जाता है, जिसमें गैर-मानव संचालन शामिल है।
यह उपलब्धि महत्वपूर्ण चरों की पहचान करने के लिए R-square, t-stats और AIC के रूप में सांख्यिकीय मानों को देखने के माध्यम से की गई थी। क्रमिक वापसी मॉडल को एक साथ जोड़ने / हटाने के साथ-साथ निर्दिष्ट मानदंडों के आधार पर सह-परिवर्तकों को फिट करती है। नीचे कुछ सबसे अधिक उपयोग किए जाने वाले क्रमिक वापसी विधियों को सूचीबद्ध किया गया हैः
- स्टैंडर्ड क्रमिक रिग्रेशन दो चीजें करता है: प्रत्येक चरण के लिए आवश्यक पूर्वानुमान को जोड़ना और हटाना।
- आगे का चयन मॉडल में सबसे प्रमुख भविष्यवाणियों से शुरू होता है और फिर प्रत्येक चरण के लिए चर जोड़ता है।
- पिछली ओर हटाने विधि मॉडल के सभी भविष्यवाणियों के साथ एक साथ शुरू होती है, और फिर प्रत्येक चरण में सबसे कम महत्वपूर्ण चर को हटा दिया जाता है।
- इस प्रकार की मॉडलिंग तकनीक का उद्देश्य न्यूनतम संख्या में भविष्यवाणी चरों का उपयोग करके भविष्यवाणी क्षमता को अधिकतम करना है। यह उच्च आयामी डेटासेट को संभालने के तरीकों में से एक है।
-
5. रिज रिग्रेशन
कंक्रीट रिग्रेशन विश्लेषण एक ऐसी तकनीक है जिसका उपयोग डेटा में किया जाता है जिसमें बहु-सहसंबद्धता होती है। बहु-सहसंबद्धता की स्थिति में, हालांकि न्यूनतम द्विगुणन (OLS) प्रत्येक चर के लिए उचित है, लेकिन उनके बीच बहुत अधिक अंतर होता है, जिससे अवलोकन मूल्य विचलित हो जाते हैं और वास्तविक मूल्य से दूर हो जाते हैं। कंक्रीट रिग्रेशन को एक मानक त्रुटि को कम करने के लिए, रिग्रेशन अनुमान पर एक विचलन जोड़कर दिया जाता है।
ऊपर, हमने एक रैखिक प्रतिगमन समीकरण देखा। याद है? इसे इस तरह दर्शाया जा सकता है:
y=a+ b*xइस समीकरण में भी एक त्रुटि है. पूर्ण समीकरण हैः
y=a+b*x+e (error term), [error term is the value needed to correct for a prediction error between the observed and predicted value] => y=a+y= a+ b1x1+ b2x2+....+e, for multiple independent variables.एक रैखिक समीकरण में, पूर्वानुमान त्रुटि को दो अंशों में विभाजित किया जा सकता है। एक विचलन है, और एक अंतर है। पूर्वानुमान त्रुटि इन दोनों अंशों या दोनों में से किसी एक के कारण हो सकती है। यहां, हम अंतर के कारण होने वाली संबंधित त्रुटियों पर चर्चा करेंगे।
रिग्रेशन बहु-सह-रैखिकता समस्या को संकुचन पैरामीटरλ{\displaystyle \lambda } द्वारा हल करता है। नीचे दिए गए सूत्र देखें
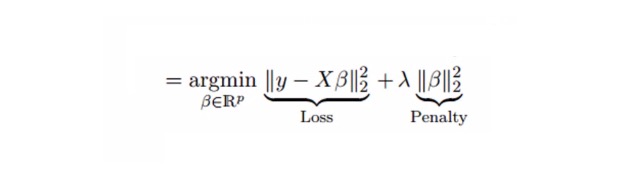
इस सूत्र में दो घटक होते हैं: पहला लघुतम द्विपद है और दूसरा β2 (β-वर्ग) का λ गुणांक है, जिसमें β प्रासंगिक कारक है। इसे लघुतम द्विपद में जोड़कर एक बहुत ही कम भिन्नता प्राप्त करने के लिए संकुचन पैरामीटर को जोड़ें।
क्या आप जानते हैं?
- इस प्रकार की प्रत्यावर्तन परिकल्पना न्यूनतम द्विगुणित प्रत्यावर्तन के समान है;
- यह प्रासंगिक गुणांक के मान को संकुचित करता है, लेकिन शून्य तक नहीं पहुंचता है, यह दर्शाता है कि इसमें कोई विशेषता चयन फ़ंक्शन नहीं है
- यह एक विधि है और L2 नियमितकरण का उपयोग किया जाता है.
-
6. लासो रिग्रेशन
कम से कम निरपेक्ष संकोचन और चयन ऑपरेटर (Lasso) के साथ, यह एक पहेली रिटर्न के समान है, जो रिटर्न गुणांक के निरपेक्ष मूल्य के आकार को दंडित करता है। इसके अलावा, यह परिवर्तन की डिग्री को कम करने और रैखिक रिटर्न मॉडल की सटीकता को बढ़ाने में सक्षम है। नीचे दिए गए सूत्र देखेंः
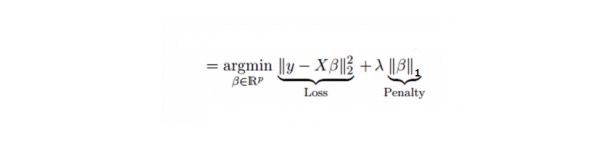
लासो रिग्रेशन और रिज रिग्रेशन के बीच थोड़ा अंतर है, क्योंकि इसमें एक दंडात्मक फलन का उपयोग किया जाता है जो एक पूर्ण मान है, न कि एक वर्ग है। इसके परिणामस्वरूप दंडात्मक (या बाध्यकारी अनुमान के पूर्ण मानों के योग के बराबर) मान कुछ पैरामीटर के अनुमान के परिणाम को शून्य के बराबर कर देता है। दंडात्मक मानों का उपयोग करने से, आगे का अनुमान शून्य के करीब छोटा हो जाता है। इससे हमें दिए गए n चरों में से एक चर चुनने की आवश्यकता होगी।
क्या आप जानते हैं?
- इस प्रकार की प्रत्यावर्तन परिकल्पना न्यूनतम द्विगुणित प्रत्यावर्तन के समान है;
- इसका संकुचन गुणांक शून्य के करीब है, जो वास्तव में विशेषता चयन में मदद करता है;
- यह एक नियमितकरण विधि है जो L1 नियमितकरण का उपयोग करती है;
- यदि भविष्यवाणियों में से एक समूह अत्यधिक प्रासंगिक है, तो लासो उनमें से एक को चुनता है और अन्य को शून्य कर देता है।
-
7. ElasticNet की वापसी
ElasticNet Lasso और Ridge regression तकनीक का एक मिश्रण है. यह प्रशिक्षण के लिए L1 का उपयोग करता है और L2 को नियमित मैट्रिक्स के रूप में प्राथमिकता देता है. ElasticNet तब उपयोगी होता है जब कई संबंधित विशेषताएं होती हैं. Lasso उनमें से एक को यादृच्छिक रूप से चुनता है, जबकि ElasticNet दो चुनता है।
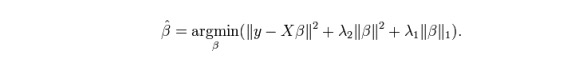
Lasso और Ridge के बीच का वास्तविक लाभ यह है कि यह ElasticNet को Ridge की कुछ स्थिरता को looped state में प्राप्त करने की अनुमति देता है।
क्या आप जानते हैं?
- यह समूह प्रभाव पैदा करता है जब अत्यधिक संबंधित चर होते हैं;
- चयनित चरों की संख्या पर कोई सीमा नहीं;
- यह डबल संकुचन का सामना कर सकता है।
- इन 7 सबसे आम वापसी तकनीकों के अलावा, आप अन्य मॉडलों को भी देख सकते हैं, जैसे कि बेयसियन, इकोलॉजिकल और रोबस्ट वापसी।
कैसे चुनें रिग्रेशन मॉडल?
जब आप केवल एक या दो तकनीकों को जानते हैं, तो जीवन बहुत आसान हो जाता है। एक प्रशिक्षण संस्थान जिसे मैं जानता हूं, अपने छात्रों को बताता है कि यदि परिणाम निरंतर है, तो रैखिक प्रतिगमन का उपयोग करें। यदि यह द्विआधारी है, तो तार्किक प्रतिगमन का उपयोग करें! हालांकि, हमारे निपटान में, अधिक विकल्प उपलब्ध हैं, सही एक को चुनना अधिक कठिन है। इसी तरह की स्थिति एक प्रतिगमन मॉडल में होती है।
एक बहु-प्रकार के प्रतिगमन मॉडल में, यह बहुत महत्वपूर्ण है कि डेटा के आयामों और डेटा की अन्य बुनियादी विशेषताओं के आधार पर सबसे उपयुक्त तकनीक का चयन किया जाए। सही प्रतिगमन मॉडल चुनने के लिए आपके पास निम्नलिखित महत्वपूर्ण कारक हैंः
डेटा अन्वेषण भविष्यवाणी मॉडल के निर्माण का एक अनिवार्य हिस्सा है। यह एक उपयुक्त मॉडल चुनने में एक प्राथमिकता कदम होना चाहिए, जैसे कि चर के संबंधों और प्रभावों की पहचान करना।
विभिन्न मॉडलों के लिए अधिक उपयुक्त, हम विभिन्न सूचक मापदंडों का विश्लेषण कर सकते हैं, जैसे कि सांख्यिकीय महत्व के लिए मापदंड, आर-स्क्वायर, समायोजित आर-स्क्वायर, एआईसी, बीआईसी और त्रुटि बिंदु, और एक अन्य मैलोव्स ‘सीपी नियम है। यह मुख्य रूप से सभी संभावित उप-मॉडलों के साथ मॉडल की तुलना करके किया जाता है (या उन्हें सावधानीपूर्वक चुनें) और आपके मॉडल में संभावित विचलन की जांच करें।
क्रॉस-वैलिडेशन भविष्यवाणी मॉडल का मूल्यांकन करने का सबसे अच्छा तरीका है। यहां, अपने डेटासेट को दो भागों में विभाजित करें (एक प्रशिक्षण और एक सत्यापन के लिए) । अपनी भविष्यवाणी की सटीकता को मापने के लिए, अवलोकन और भविष्यवाणी के बीच एक सरल समकक्ष अंतर का उपयोग करें।
यदि आपके डेटासेट में कई मिश्रित चर हैं, तो आपको स्वचालित मॉडल चयन विधि का चयन नहीं करना चाहिए, क्योंकि आप सभी चर को एक ही समय में एक ही मॉडल में नहीं रखना चाहते हैं।
यह आपके उद्देश्य पर भी निर्भर करता है. यह हो सकता है कि एक कम शक्तिशाली मॉडल एक उच्च सांख्यिकीय अर्थ वाले मॉडल की तुलना में अधिक आसानी से लागू हो।
रिवर्जन सामान्यीकरण विधियां ((लासो, रिज और इलास्टिकनेट) उच्च आयाम और डेटासेट चर के बीच कई सह-सीमाओं के साथ अच्छी तरह से काम करती हैं।
सीएसडीएन से पुनः प्राप्त