KNN एल्गोरिथम पर आधारित बायेसियन क्लासिफायर
 0
1999
0
1999
KNN एल्गोरिथम पर आधारित बायेसियन क्लासिफायर
वर्गीकरण निर्णय लेने के लिए वर्गीकरणकर्ता डिजाइन करने के लिए सैद्धांतिक आधार
तुलना करें P ((ω i i ∈ x) ∈ जहां ω i वर्ग i है और x एक डेटा है जिसे देखा गया है और वर्गीकृत किया जाना है, P ((ω i ∈ x) यह दर्शाता है कि इस डेटा के ज्ञात वैक्टर की स्थिति में, यह निर्धारित करने की संभावना क्या है कि यह श्रेणी i में है, जो कि बाद की संभावना भी है। बेयज़ सूत्र के अनुसार, इसे इस प्रकार दर्शाया जा सकता हैः
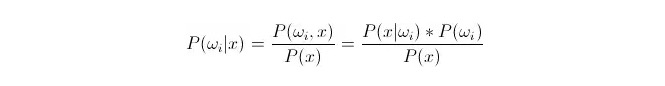
इनमें से, P (x) = \ (x\) = \ (i\) = \ (x\) = \ (i\) = \ (x\) = \ (i\) = \ (x\) = \ (i\) = \ (x\) = \ (i\) = \ (x\) = \ (i\) = \ (i\) = \ (x\) = \ (i\) = \ (x\) = \ (i\) = \ (i\) = \ (x\) = \) = \ (i\) = \ (i\) = \ (i\) = \ (i\) = \ (i\) = \ (i\) = \ (i\) = \ (i\) = \ (i\) = \ (i\) = \ (i\) = \ (i\) = \ (i\) = \ (i\) = \ (i\) = \ (i\) = \ (i\) = \ (i\) = \ (i\) = \ (i\) \) = \ (i\) = \)
वर्गीकरण के दौरान, दिए गए x को देखते हुए, उस श्रेणी को चुनें जो सबसे बड़ी पश्चाताप संभावना P ((ωiⴰⵙⴰⵙx) है। प्रत्येक श्रेणी के तहत P ((ωiⴰⵙx) की तुलना करते समय, ωi परिवर्तनीय है, जबकि x निश्चित है; इसलिए P ((x) को हटा दिया जा सकता है, इसे ध्यान में नहीं रखा जा सकता है।
तो यह P (x) = P (x) = P (x) =*पी ((ωi) प्रश्न पूर्वानुमान P ((ωi) की अपेक्षा करें, जब तक कि प्रत्येक वर्गीकरण के तहत आने वाले आंकड़ों का अनुपात सांख्यिकीय प्रशिक्षण केंद्रित हो।
इस प्रकार, संभावना P (x) की गणना करना व्यर्थ है, क्योंकि यह x परीक्षण समूह का डेटा है, जिसे सीधे प्रशिक्षण समूह से नहीं निकाला जा सकता है। फिर हमें प्रशिक्षण समूह के डेटा के वितरण नियम का पता लगाना होगा, और फिर हम P (x) प्राप्त करेंगे।
निम्नलिखित में k निकटवर्ती एल्गोरिथ्म (अंग्रेज़ी में KNN) है।
हम प्रशिक्षण केंद्र में डेटा x1, x2… xn (जिसमें से प्रत्येक डेटा m आयामी है) के आधार पर, श्रेणीωi के तहत, इन आंकड़ों के वितरण को फिट करते हैं। x को m आयामी स्थान में किसी भी बिंदु के रूप में सेट करें, तो P ((x)) की गणना कैसे करेंωi)?
हम जानते हैं कि जब डेटा पर्याप्त रूप से बड़ा होता है, तो अनुपातिक अनुमानित संभावनाओं का उपयोग किया जा सकता है। इस सिद्धांत का उपयोग करके, बिंदु x की परिधि में, बिंदु x से निकटतम k नमूना बिंदुओं को ढूंढें, जिनमें से कौन श्रेणी i का है। इस k नमूना बिंदु के आसपास के सबसे छोटे सुपरस्फीयर का आकार V की गणना करें; और सभी नमूना डेटा में ओआई श्रेणी के लिए संख्याओं की संख्या Ni को ढूंढें:
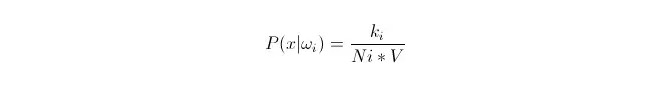
तो आप देख सकते हैं कि हमने जो गणना की है वह वास्तव में x पर वर्ग-सशर्त संभावना घनत्व है.
तो यह क्या है? उपरोक्त पद्धति के अनुसार, P (ωi) = Ni/N 。 जहाँ N कुल नमूनों की संख्या है。 और फिर P (x) = k (n)*V), जहाँ k इस सुपरस्फीयर के चारों ओर सभी नमूना बिंदुओं की संख्या है; N कुल नमूने की संख्या है। तो P{\displaystyle \mathrm {P} }
P(ωi|x)=ki/k
उपरोक्त समीकरण की व्याख्या करते हुए, एक V आकार के सुपरगोलाकार में, k नमूनों को घेर लिया गया है, जिनमें से i श्रेणी के कौन-कौन से हैं। इस प्रकार, कौन से प्रकार के नमूने सबसे अधिक हैं, हम यह निर्धारित करते हैं कि यहां x किस श्रेणी में होना चाहिए। यह k निकटवर्ती एल्गोरिथ्म के साथ डिज़ाइन किया गया वर्गीकरणकर्ता है।