ड्यूश बैंक की रिपोर्ट में अध्ययन नोट, मात्रात्मक रणनीतियों में कई सामान्य गलतियों को सूचीबद्ध करता है
 0
2399
0
2399
ड्यूश बैंक की रिपोर्ट में अध्ययन नोट, मात्रात्मक रणनीतियों में कई सामान्य गलतियों को सूचीबद्ध करता है
- ### उत्तरजीविता पूर्वाग्रह
उत्तरजीविता विचलन निवेशकों के लिए सबसे आम समस्याओं में से एक है, और बहुत से लोग जानते हैं कि उत्तरजीविता विचलन मौजूद है, लेकिन बहुत कम लोग इसके प्रभावों को महत्व देते हैं। हम केवल वर्तमान में मौजूद कंपनियों का उपयोग करते हैं, जिसका अर्थ है कि हम उन कंपनियों के प्रभावों को बाहर कर देते हैं जो दिवालियापन और पुनर्गठन के कारण बंद हो गई हैं।
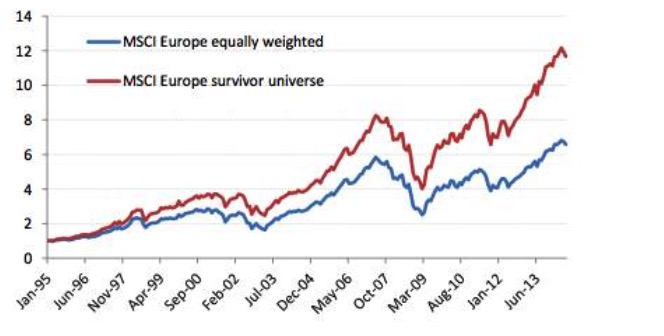
कुछ दिवालिया, बहिष्कृत और खराब प्रदर्शन करने वाले शेयरों को समय-समय पर हटा दिया जाता है जब आप ऐतिहासिक डेटा को समायोजित करते हैं। और ये हटाए गए शेयर आपकी रणनीति के स्टॉक पूल में नहीं दिखाई देते हैं, यानी, अतीत के बारे में केवल वर्तमान घटक शेयरों की जानकारी का उपयोग किया जाता है, जो कि भविष्य में खराब प्रदर्शन या शेयर मूल्य के कारण घटकों के शेयरों को हटा दिया जाता है। नीचे दिए गए चित्र में एमएससीआई यूरोपीय सूचकांक के घटकों जैसे शेयरों का एक निवेश पोर्टफोलियो के रूप में अतीत में प्रदर्शन दिखाया गया है। नीली रेखा सही पोर्टफोलियो है, और लाल रेखा जीवित बचे लोगों के पक्षपाती पोर्टफोलियो के लिए है। लाल रेखा में निवेश पर रिटर्न स्पष्ट रूप से नीले रेखा से अधिक पाया जा सकता है, जिससे पोर्टफोलियो के रिटर्न को उच्च मूल्यांकन किया जा सकता है। और इससे भी अधिक आश्चर्यजनक बात यह है कि जब भूकंपीय विश्लेषण किया जाता है, तो इसका परिणाम बिल्कुल विपरीत हो सकता है।
 चित्र 1
चित्र 1
उत्तरजीविता विचलन निवेशकों के लिए सबसे आम समस्याओं में से एक है, और बहुत से लोग जानते हैं कि उत्तरजीविता विचलन मौजूद है, लेकिन बहुत कम लोग इसके प्रभावों को महत्व देते हैं। हम केवल वर्तमान में मौजूद कंपनियों का उपयोग करते हैं, जिसका अर्थ है कि हम उन कंपनियों के प्रभावों को बाहर कर देते हैं जो दिवालियापन और पुनर्गठन के कारण बंद हो गई हैं।
कुछ दिवालिया, बहिष्कृत और खराब प्रदर्शन करने वाले शेयरों को समय-समय पर हटा दिया जाता है जब आप ऐतिहासिक डेटा को समायोजित करते हैं। और ये हटाए गए शेयर आपकी रणनीति के स्टॉक पूल में नहीं दिखाई देते हैं, यानी, अतीत के बारे में केवल वर्तमान घटक शेयरों की जानकारी का उपयोग किया जाता है, जो कि भविष्य में खराब प्रदर्शन या शेयर मूल्य के कारण घटकों के शेयरों को हटा दिया जाता है। नीचे दिए गए चित्र में एमएससीआई यूरोपीय सूचकांक के घटकों जैसे शेयरों का एक निवेश पोर्टफोलियो के रूप में अतीत में प्रदर्शन दिखाया गया है। नीली रेखा सही पोर्टफोलियो है, और लाल रेखा जीवित बचे लोगों के पक्षपाती पोर्टफोलियो के लिए है। लाल रेखा में निवेश पर रिटर्न स्पष्ट रूप से नीले रेखा से अधिक पाया जा सकता है, जिससे पोर्टफोलियो के रिटर्न को उच्च मूल्यांकन किया जा सकता है। और इससे भी अधिक आश्चर्यजनक बात यह है कि जब भूकंपीय विश्लेषण किया जाता है, तो इसका परिणाम बिल्कुल विपरीत हो सकता है।
 चित्र 2
चित्र 2
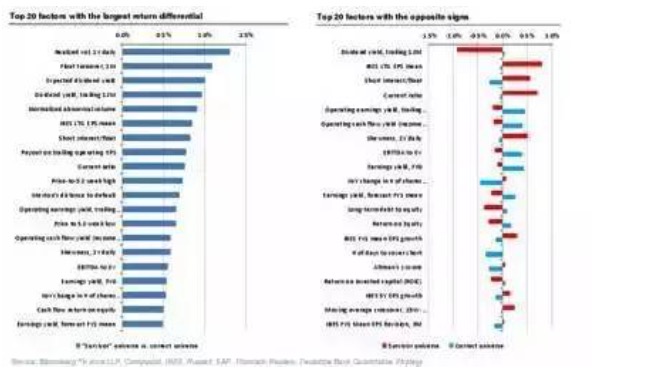
इसका मतलब यह है कि जब हम उन कंपनियों का उपयोग करते हैं जो पिछले 30 वर्षों में सबसे अच्छा प्रदर्शन कर रही हैं, और जब हम उन कंपनियों का उपयोग करते हैं जो उच्च क्रेडिट जोखिम पर हैं, और जब आप जानते हैं कि कौन जीवित रहेगा, तो जब आप उच्च क्रेडिट जोखिम या संकट में खरीदते हैं, तो रिटर्न बहुत अधिक होता है। और जब आप उन शेयरों को शामिल करते हैं जो दिवालिया हो गए हैं, बंद हो गए हैं, और खराब प्रदर्शन कर रहे हैं, तो इसका विपरीत निष्कर्ष निकलता है कि उच्च क्रेडिट जोखिम वाली कंपनियों में निवेश करने से दीर्घकालिक रिटर्न बहुत कम है।
और बहुत सारे कारक हैं जो जीवित बचे लोगों के विचलन को ध्यान में रखते हुए विपरीत परिणाम देते हैं।
 चित्र 3
चित्र 3
- ### 2. आगे की ओर देखने की प्रवृत्ति
 चित्र 4
चित्र 4
सात गुनाहों में से एक के रूप में, उत्तरजीवी विचलन यह है कि हम अतीत के समय पर खड़े नहीं हो सकते हैं कि कौन सी कंपनियां बच जाएंगी और आज के सूचकांक के घटक हैं, और उत्तरजीवी विचलन केवल पूर्वानुमान विचलन का एक विशेष उदाहरण है। पूर्वानुमान विचलन यह है कि पूर्वानुमान में सबसे आम गलती यह है कि पूर्वानुमान उस समय उपलब्ध नहीं थे या सार्वजनिक नहीं थे।
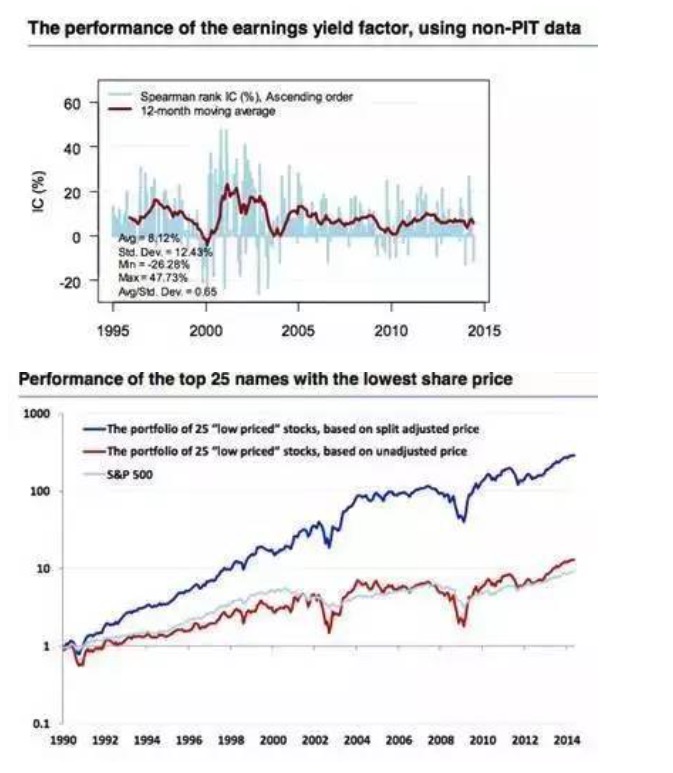
एक स्पष्ट उदाहरण वित्तीय आंकड़ों पर दिखाई देता है, जबकि वित्तीय आंकड़ों में संशोधन के लिए अधिक संभावना है कि यह मुश्किल से पाया जा सकता है। आम तौर पर, प्रत्येक कंपनी के वित्तीय आंकड़ों को जारी करने का समय अलग होता है, और अक्सर देरी होती है। और जब हम वापस जाते हैं, तो हम अक्सर प्रत्येक कंपनी के डेटा के प्रकाशन के समय के आधार पर कंपनी की वित्तीय स्थिति का मूल्यांकन करते हैं।
हालांकि, जब प्वाइंट-इन-टाइम डेटा (पीआईटी डेटा) उपलब्ध नहीं होता है, तो वित्तीय रिपोर्ट में देरी की धारणा अक्सर गलत होती है। नीचे दी गई तस्वीर पीआईटी डेटा और गैर-पीआईटी डेटा के उपयोग के कारण होने वाले अंतर को प्रमाणित करती है। साथ ही, हम ऐतिहासिक मैक्रो डेटा डाउनलोड करते समय अक्सर प्राप्त किए गए अंतिम संशोधनों को प्राप्त करते हैं, लेकिन कई विकसित देशों में जीडीपी डेटा जारी होने के बाद दो बार समायोजन किया जाता है, बड़ी कंपनियों के वित्तीय विवरणों में संशोधन अक्सर संशोधित किए जाते हैं। हम जिस बिंदु पर वापस जाते हैं, अंतिम मूल्य अक्सर अज्ञात होता है, केवल प्रारंभिक मूल्य विश्लेषण का उपयोग किया जा सकता है। कुछ लोगों का मानना है कि मामूली संशोधन निष्कर्ष को प्रभावित कर सकते हैं, लेकिन वास्तविकता यह दिखाती हैः कई मैक्रो डेटा प्रारंभिक मूल्य वापसी के आधार पर परिणामों को स्पष्ट नहीं करते हैं, वित्तीय डेटा के समायोजन से शेयरधारकों के परिणामों पर सीधा प्रभाव पड़ेगा।
 चित्र 5
चित्र 5
- ### तीन, कहानी कहने का पाप
 चित्र 6
चित्र 6
कुछ लोगों को बिना किसी डेटा के कहानियां सुनाना पसंद है, और कुछ लोगों को डेटा और परिणामों के साथ कहानियां सुनाना पसंद है। दोनों स्थितियों में कई समानताएं हैं, जो लोग कहानियों को बताने में अच्छे हैं या जो लोग डेटा परिणामों की व्याख्या करने में अच्छे हैं, वे अक्सर डेटा प्राप्त करने से पहले एक स्थापित स्क्रिप्ट के अंदर होते हैं, केवल डेटा का समर्थन करने के लिए डेटा ढूंढना आवश्यक है।
1997-2000 और 2000-2002 के लिए यूएस टेक्नोलॉजी कंपोनेंट्स और रसेल 3000 सूचकांक को देखते हुए, हम एक विपरीत निष्कर्ष पाते हैं। 1997-2000 के लिए यूएस टेक्नोलॉजी कंपोनेंट्स के लिए, लाभप्रदता एक अच्छा कारक है, और परिणाम बहुत विश्वसनीय हैं, लेकिन 2002 तक लंबी अवधि के लिए, हम पाते हैं कि लाभप्रदता का सूचकांक अब एक अच्छा कारक नहीं है।
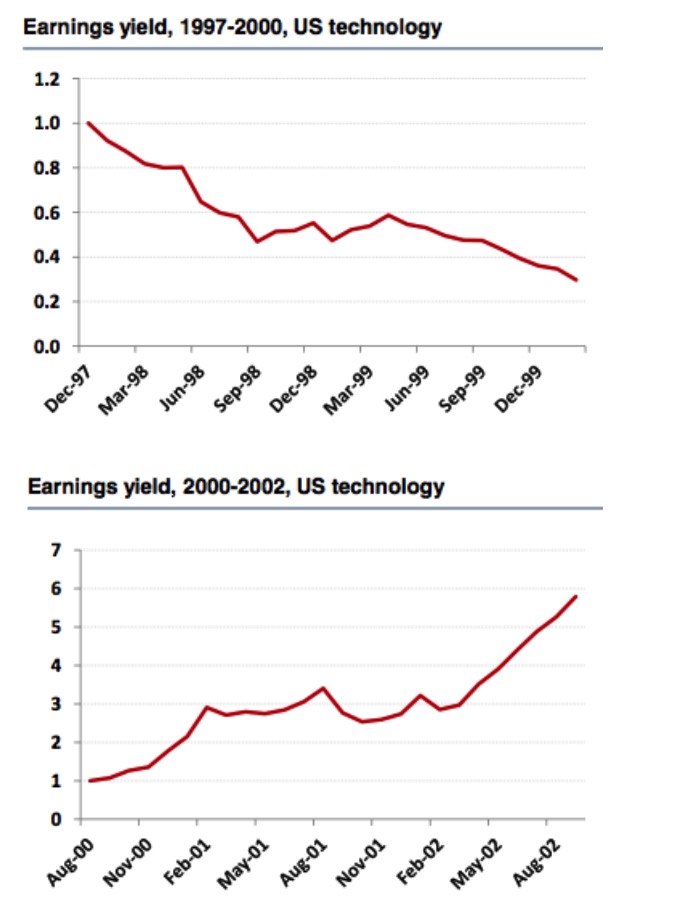 चित्र 7
चित्र 7
लेकिन रसेल 3000 सूचकांक के बाजार के प्रदर्शन से, हम इसके विपरीत निष्कर्ष निकालते हैं, लाभ दर सूचकांक अभी भी एक प्रभावी कारक है, और यह देखा जा सकता है कि स्टॉक पूल के चयन और पुनः माप की लंबाई कारक की प्रभावशीलता पर बहुत अधिक प्रभाव डालती है। इसलिए कहानीकारों को सही निष्कर्ष नहीं मिल रहा है।
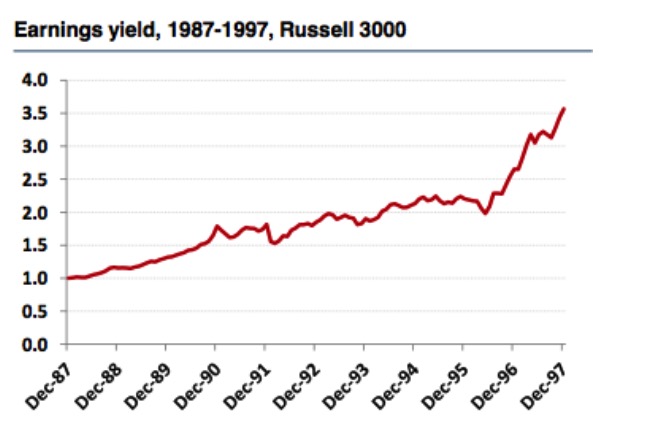 चित्र 8
चित्र 8
बाजारों में हर दिन नए अच्छे कारकों की खोज की जाती है, हमेशा के लिए प्रेरणा की तलाश की जाती है। जो रणनीति जारी की जा सकती है, वह अच्छी तरह से प्रदर्शन करती है। हालांकि कहानीकारों की व्याख्या इतिहास के लिए बहुत ही आकर्षक है, भविष्य की भविष्यवाणी के लिए यह लगभग बेकार है। वित्तीय अर्थव्यवस्था में संबंध और कारण को समझना अक्सर मुश्किल होता है, इसलिए जब हम सामान्य ज्ञान के विपरीत या मूल निर्णय के अनुरूप परिणाम बनाते हैं, तो बेहतर है कि कहानीकार न बनें।
- ### डेटा खनन और डेटा स्नोपिंग
 चित्र 9
चित्र 9
डेटा खनन वर्तमान में एक बहुत ही महत्वपूर्ण क्षेत्र है, जो कंप्यूटर की गणना शक्ति के साथ डेटा की एक बड़ी मात्रा के आधार पर है, लोगों को अक्सर यह देखने के लिए कि क्या अच्छा है या बुरा है, के बारे में उम्मीद है। लेकिन वित्तीय डेटा की एक बड़ी मात्रा अभी तक नहीं है, और लेनदेन डेटा कम शोर के लिए डेटा की आवश्यकता को पूरा नहीं करता है।
उदाहरण के लिए, हमने S&P 500 को दो अलग-अलग कारक-भारित एल्गोरिदम के साथ मॉडलिंग किया, 2009-2014 के आंकड़ों का चयन किया। परिणामों से पता चला है कि 2009-2014 के आंकड़ों का उपयोग करके 6 सर्वश्रेष्ठ प्रदर्शन करने वाले कारकों को छान लिया गया है, जबकि समान-वजन एल्गोरिदम का उपयोग करके परिणाम बहुत सही हैं, जबकि ऐतिहासिक डेटा का उपयोग करके आउट-ऑफ-नमूना परिणाम एक सीधी रेखा है।
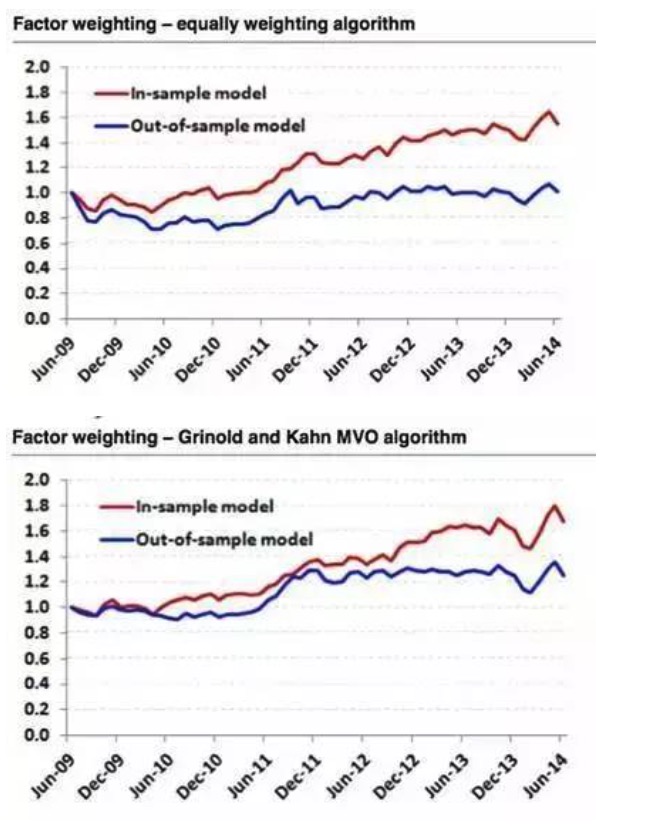 चित्र 10
चित्र 10
इसलिए, जब हम रणनीति बनाते हैं या अच्छे कारकों की तलाश करते हैं, तो हमें स्पष्ट तर्क और प्रेरणा होनी चाहिए, मात्रात्मक विश्लेषण केवल अपने तर्क या प्रेरणा को सत्यापित करने का एक उपकरण है, न कि तर्क के लिए शॉर्टकट की तलाश। आम तौर पर, हम रणनीति बनाने या कारकों की तलाश करने के लिए कई क्षेत्रों से प्रेरित होते हैं जैसे कि मौलिक वित्तीय सैद्धांतिक ज्ञान, बाजार की प्रभावशीलता, व्यवहारिक वित्त और अन्य। बेशक, हम मात्रात्मक क्षेत्र में डेटा खनन के उपयोग के मूल्य से इनकार नहीं करते हैं।
- ### सिग्नल क्षय, टर्नओवर, और लेनदेन लागत
 चित्र 11
चित्र 11
सिग्नल मंदी का अर्थ है एक कारक के होने के बाद भविष्य में स्टॉक रिटर्न की भविष्यवाणी करने की क्षमता। आम तौर पर, उच्च विनिमय दर और सिग्नल मंदी संबंधित हैं। विभिन्न स्टॉक चयन कारकों में अक्सर अलग-अलग सूचनात्मक मंदी विशेषताएं होती हैं। तेजी से सिग्नल मंदी का मतलब अक्सर अधिक विनिमय दर की आवश्यकता होती है। हालांकि, उच्च विनिमय दर का मतलब अक्सर अधिक लेनदेन लागत होता है। पोर्टफोलियो निर्माण में विनिमय दर को बाधित करना एक अपेक्षाकृत सरल तरीका है, लेकिन यह सबसे आदर्श तरीका नहीं है, क्योंकि विनिमय दर प्रतिबंध कभी-कभी हमें एक निश्चित पोर्टफोलियो के प्रदर्शन को बंद करने में मदद करते हैं और कभी-कभी इसे नुकसान पहुंचाते हैं। इसलिए, सिग्नल मंदी, लेनदेन लागत मॉडल और पूर्वानुमान को संतुलित करना पोर्टफोलियो निर्माण की कुंजी है।
तो, हम सबसे अच्छा समायोजन आवृत्ति कैसे निर्धारित कर सकते हैं? हम ध्यान देने की जरूरत है कि विनिमय दर को कम करने के लिए विनिमय दर को कम करने का मतलब यह नहीं है। उदाहरण के लिए, हम अक्सर इस तरह की बातें सुनते हैं कि हम लंबे समय तक मूल्य निवेशक हैं, हम शेयरों को 3-5 साल तक रखने की उम्मीद करते हैं। इसलिए, हम एक साल में एक बार विनिमय कर सकते हैं। लेकिन, जानकारी जल्दी से गुजरती है, हमें अपने मॉडल और अपेक्षाओं को समय पर समायोजित करने की आवश्यकता होती है। यहां तक कि अगर हमारी विनिमय दर बहुत तंग है, तो हमें अभी भी उचित समय पर विनिमय दर को तेज करने की आवश्यकता है।
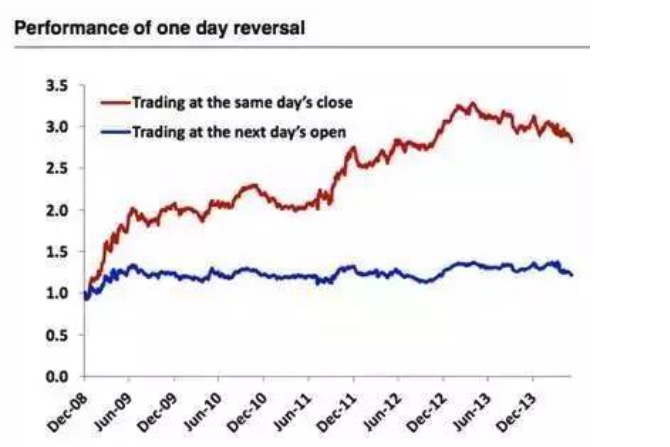 चित्र 12
चित्र 12
जब हम हर दिन बंद होते हैं तो उस दिन के सबसे खराब प्रदर्शन करने वाले 100 शेयरों को खरीदते हैं, पिछले होल्डिंग को बेचते हैं, दैनिक व्यापार जारी रखते हैं, बहुत अधिक रिटर्न मिलता है। यहां त्रुटि भी एक पूर्वानुमान विचलन है, और जब्त करने के लिए हम यह नहीं जानते हैं कि उस दिन कौन से शेयर सबसे खराब प्रदर्शन करेंगे, यानी प्रोग्रामेटिक ट्रेडिंग का उपयोग करना, यह रणनीति भी संभव नहीं है। हम केवल 100 शेयरों को खरीद सकते हैं जो कल सबसे खराब प्रदर्शन करते हैं। तुलना के माध्यम से, एक खुली कीमत पर खरीदने की रणनीति लगभग एक सीधी रेखा है।
- ### 6. असामान्यता (आउटलीयर)
 चित्र 13
चित्र 13
पारंपरिक असामान्यता नियंत्रण तकनीक में मुख्य रूप से winsorization और truncation शामिल हैं, डेटा का मानकीकरण भी असामान्यता नियंत्रण के तरीकों में से एक के रूप में देखा जा सकता है, मानकीकरण तकनीक मॉडल के प्रदर्शन पर महत्वपूर्ण प्रभाव डाल सकती है। उदाहरण के लिए, नीचे दिए गए चित्र में स्टैंडर्ड बीएमआई कोरियाई सूचकांक घटक स्टॉक की लाभप्रदता, औसत मूल्य, 1%, 2% चरम मूल्य आदि का उपयोग करने के तरीके के परिणाम बहुत भिन्न हैं। मैक्रो डेटा में अक्सर इस तरह की समस्याएं होती हैं, यदि कुछ चरम मूल्य पूर्व-प्रसंस्करण नहीं किए जाते हैं, तो परिणामों पर गंभीर प्रभाव पड़ सकता है।
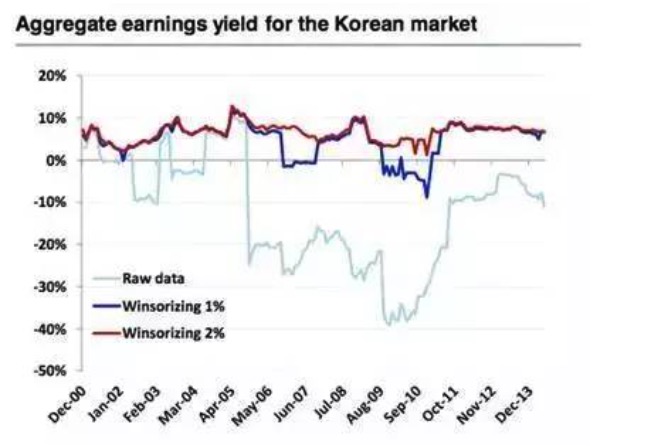 चित्र 14
चित्र 14
हालांकि असामान्यताओं में उपयोगी जानकारी हो सकती है, लेकिन ज्यादातर मामलों में, उनमें उपयोगी जानकारी नहीं होती है। बेशक, मूल्य गतिशीलता कारक के लिए अपवाद के रूप में। जैसा कि नीचे दी गई है, नीली रेखा असामान्यताओं को हटाने के बाद संयोजन प्रदर्शन है, लाल रेखा कच्चे डेटा है। हम देख सकते हैं कि कच्चे डेटा की गतिशीलता रणनीति असामान्यताओं को हटाने के बाद की रणनीति से बहुत बेहतर है।
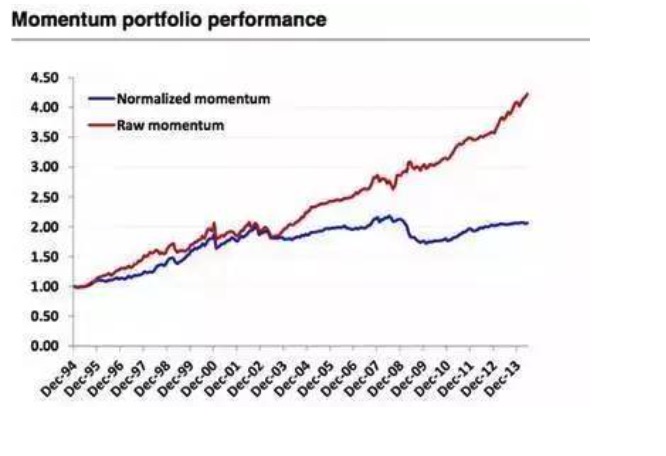 चित्र 15
चित्र 15
- ### सात, असममितता (The asymmetric payoff pattern and shorting)
 चित्र 16
चित्र 16
आम तौर पर, एक बहु-कारक रणनीति बनाने के लिए एक अधिक प्रचलित रणनीति एक बहु-स्थानिक रणनीति है, जो कि एक ही समय में कई अच्छे शेयरों को करने के लिए है। दुर्भाग्य से, सभी कारक समान नहीं हैं, अधिकांश कारकों के बहु-स्थानिक लाभ विशेषताएं असममित हैं, साथ ही संभावित लागत और वास्तविक व्यवहार्यता के साथ, यह भी मात्रात्मक निवेश के लिए काफी परेशानी पैदा करता है। नीचे दी गई तालिका में कारकों के बहु-स्थानिक लाभ विशेषताएं दिखाई देती हैं, जो अंतर के आकार के अनुसार क्रमबद्ध हैं। अधिक निर्भर कारक, अधिक मांग और उच्च लेनदेन लागत के कारण, अल्फा से अधिक कमाई करना मुश्किल होता है। साथ ही, हम देख सकते हैं कि मूल्य कारक अक्सर बहु-पक्षीय लाभ प्राप्त करता है, जबकि मूल्य प्रेरक कारक और गुणवत्ता कारक अधिक अल्फा-निर्भर होते हैं।
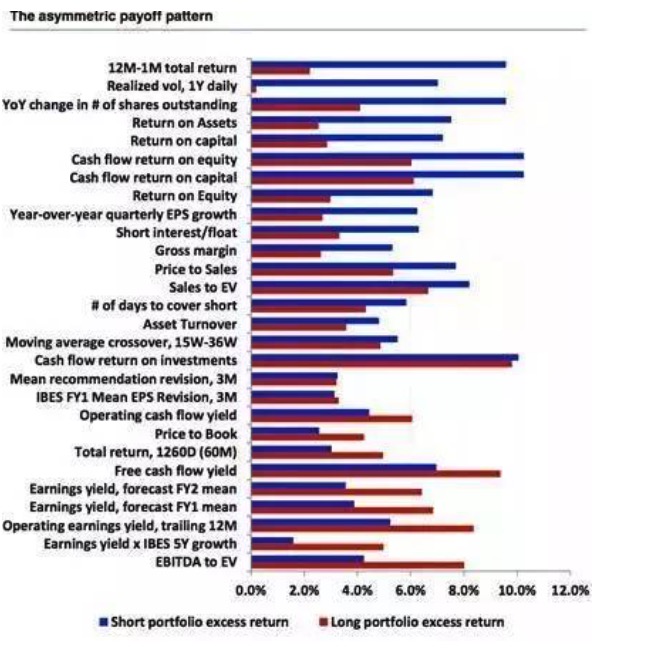 चित्र 17
चित्र 17
स्रोतः वॉल स्ट्रीट पर टहलना