मशीन लर्निंग को समझने के लिए तीन तस्वीरें: बुनियादी अवधारणाएँ, पाँच प्रमुख स्कूल और नौ सामान्य एल्गोरिदम
 0
2546
0
2546
मशीन लर्निंग को समझने के लिए तीन तस्वीरें: बुनियादी अवधारणाएँ, पाँच प्रमुख स्कूल और नौ सामान्य एल्गोरिदम
- #### 1. मशीन लर्निंग अवलोकन

मशीन लर्निंग क्या है?
मशीनें बड़ी मात्रा में डेटा का विश्लेषण करके सीखती हैं। उदाहरण के लिए, उन्हें बिल्ली या चेहरे को पहचानने के लिए प्रोग्रामिंग की आवश्यकता नहीं होती है, वे चित्रों का उपयोग करके प्रशिक्षित हो सकते हैं ताकि वे विशेष लक्ष्यों को जोड़ सकें और पहचान सकें।
मशीन सीखने और कृत्रिम बुद्धि का संबंध
मशीन लर्निंग (अंग्रेज़ीः Machine learning) एक प्रकार का शोध और एल्गोरिथ्म है जो डेटा में पैटर्न को खोजने और भविष्यवाणी करने के लिए इन पैटर्न का उपयोग करने के बारे में है। मशीन लर्निंग आर्टिफिशियल इंटेलिजेंस (एआई) के क्षेत्र का एक हिस्सा है, और यह ज्ञान की खोज और डेटा खनन के साथ मिलकर काम करता है।
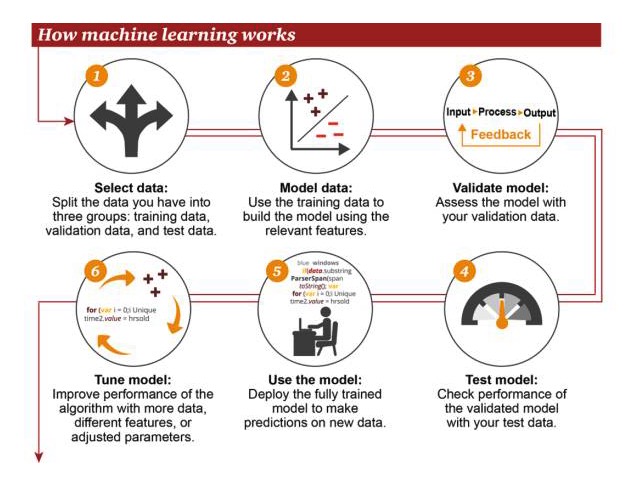
मशीन लर्निंग कैसे काम करता है
1 डेटा चुनें: अपने डेटा को तीन समूहों में विभाजित करें: प्रशिक्षण डेटा, सत्यापन डेटा और परीक्षण डेटा 2 मॉडल डेटाः प्रशिक्षण डेटा का उपयोग संबंधित विशेषताओं का उपयोग करने वाले मॉडल बनाने के लिए करें 3 सत्यापन मॉडल: अपने सत्यापन डेटा का उपयोग करके अपने मॉडल तक पहुँचें 4 परीक्षण मॉडलः आपके परीक्षण डेटा का उपयोग करके सत्यापित मॉडल के प्रदर्शन की जांच करें 5 मॉडल का उपयोग करेंः नए डेटा पर भविष्यवाणी करने के लिए पूरी तरह से प्रशिक्षित मॉडल का उपयोग करें 6 ट्यूनिंग मॉडलः एल्गोरिदम के प्रदर्शन को बढ़ाने के लिए अधिक डेटा, अलग-अलग विशेषताओं या संशोधित मापदंडों का उपयोग करना
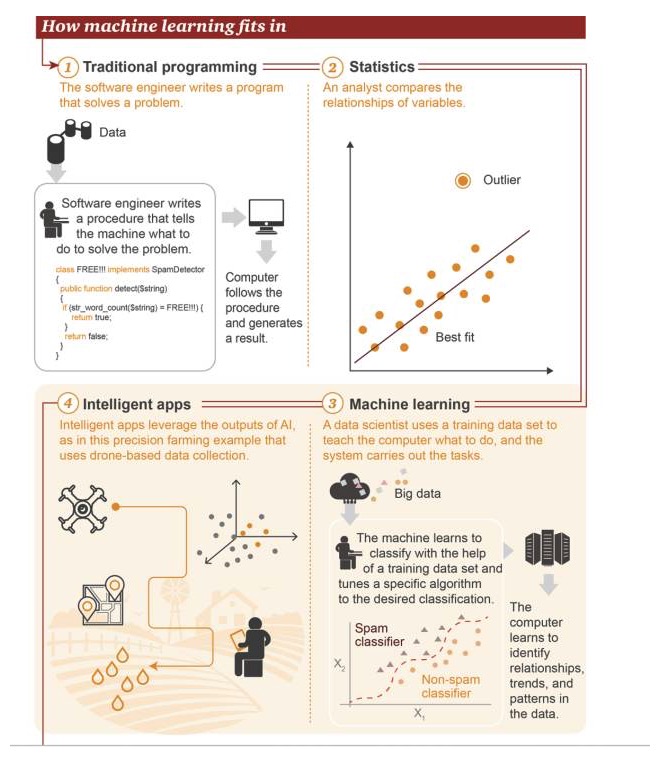
मशीन लर्निंग कहाँ है
1 पारंपरिक प्रोग्रामिंग: सॉफ्टवेयर इंजीनियर एक समस्या को हल करने के लिए एक प्रोग्राम लिखते हैं। पहले कुछ डेटा होता है→ एक समस्या को हल करने के लिए, सॉफ्टवेयर इंजीनियर एक प्रक्रिया लिखते हैं जो मशीन को बताती है कि इसे क्या करना चाहिए→ कंप्यूटर इस प्रक्रिया का पालन करता है, और फिर परिणाम देता है 2 सांख्यिकीः विश्लेषकों ने चरों के बीच संबंधों की तुलना की 3 मशीन लर्निंगः डेटा वैज्ञानिक प्रशिक्षण डेटासेट का उपयोग कंप्यूटर को यह बताने के लिए करते हैं कि उन्हें क्या करना चाहिए, और फिर सिस्टम उस कार्य को निष्पादित करता है। सबसे पहले, बिग डेटा मौजूद है।→ मशीन वर्गीकरण के लिए प्रशिक्षण डेटासेट का उपयोग करना सीखती है, और लक्ष्य वर्गीकरण को प्राप्त करने के लिए विशिष्ट एल्गोरिदम को समायोजित करती है।→ कंप्यूटर डेटा में संबंधों, रुझानों और पैटर्न को पहचानना सीखता है। 4 स्मार्ट एप्लीकेशनः स्मार्ट एप्लीकेशन कृत्रिम बुद्धिमत्ता का उपयोग करके प्राप्त परिणाम, चित्र एक सटीक कृषि अनुप्रयोग का एक उदाहरण है, जो ड्रोन द्वारा एकत्र किए गए डेटा पर आधारित है

मशीन लर्निंग के व्यावहारिक अनुप्रयोग
मशीन लर्निंग के कई अनुप्रयोग हैं, यहाँ कुछ उदाहरण दिए गए हैं, आप इसे कैसे उपयोग करेंगे?
त्वरित 3 डी मानचित्रण और मॉडलिंगः एक रेलवे पुल के निर्माण के लिए, पीडब्ल्यूसी के डेटा वैज्ञानिकों और क्षेत्र के विशेषज्ञों ने मशीन लर्निंग को ड्रोन द्वारा एकत्र किए गए डेटा पर लागू किया। इस संयोजन से काम की सफलता में सटीक निगरानी और तेजी से प्रतिक्रिया प्राप्त होती है।
जोखिम को कम करने के लिए एनालिटिक्स को बढ़ाएंः आंतरिक लेनदेन का पता लगाने के लिए, पीडब्ल्यूसी मशीन सीखने और अन्य विश्लेषणात्मक तकनीकों को जोड़ती है, जिससे अधिक व्यापक उपयोगकर्ता प्रोफाइल विकसित होती है और जटिल संदिग्ध व्यवहार की गहरी समझ प्राप्त होती है।
सर्वश्रेष्ठ प्रदर्शन का अनुमान लगाने के लिए लक्ष्यः पीडब्ल्यूसी मेलबर्न कप में विभिन्न घोड़ों की क्षमता का आकलन करने के लिए मशीन सीखने और अन्य विश्लेषणात्मक तरीकों का उपयोग करता है।
- #### 2. मशीन लर्निंग का विकास

दशकों से, एआई शोधकर्ताओं के विभिन्न ‘जनजातियों’ ने एक-दूसरे के साथ प्रभुत्व के लिए संघर्ष किया है। क्या अब समय आ गया है कि वे एकजुट हों? और उन्हें ऐसा करना पड़ सकता है, क्योंकि सहयोग और एल्गोरिथ्म एकीकरण वास्तव में सामान्य एआई (एजीआई) को प्राप्त करने का एकमात्र तरीका है। यहां बताया गया है कि मशीन सीखने के तरीके कैसे विकसित हुए हैं और भविष्य में क्या हो सकता है।
पांच प्रमुख शैलियों
1 प्रतीकवाद: ज्ञान को चिह्नित करने और तर्कसंगत तर्क करने के लिए प्रतीकों, नियमों और तर्क का उपयोग करना, सबसे पसंदीदा एल्गोरिदमः नियम और निर्णय पेड़ 2 बेय्सवादी: घटना की संभावनाओं को प्राप्त करने के लिए संभाव्यता परिकल्पना करना, पसंदीदा एल्गोरिदमः सरल बेय्स या मार्कोव 3 संयोजकवाद: संभाव्यता मैट्रिक्स और भारित न्यूरॉन्स का उपयोग करके गतिशील रूप से पहचान और पुनरावृत्ति पैटर्न, पसंदीदा एल्गोरिदमः तंत्रिका नेटवर्क 4 विकासवाद: परिवर्तन उत्पन्न करना और फिर किसी विशेष उद्देश्य के लिए उनमें से सर्वोत्तम को प्राप्त करना, पसंदीदा एल्गोरिदमः आनुवंशिक एल्गोरिदम 5Analogizer: बाध्यकारी शर्तों के अनुसार फ़ंक्शन को अनुकूलित करने के लिए ((जितना संभव हो उतना ऊंचा जाओ, लेकिन साथ ही सड़क से बाहर न निकलें), पसंदीदा एल्गोरिदमः वेक्टर मशीन का समर्थन करें
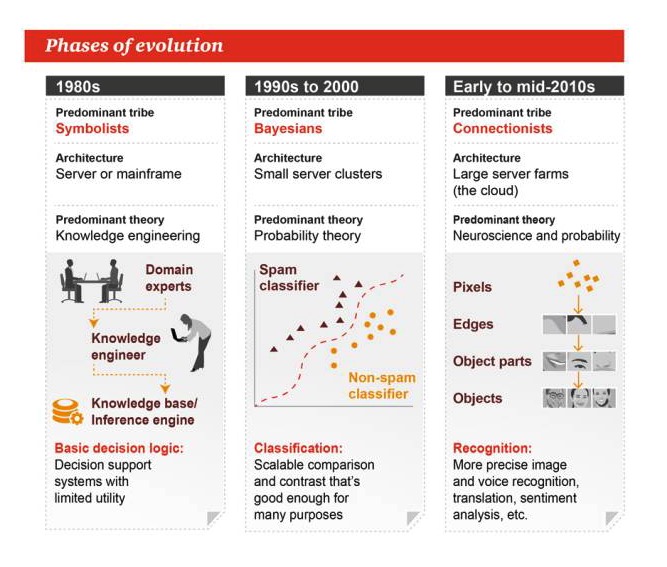
विकास के चरण
१९८० के दशक
प्रमुख शैलियोंः प्रतीकवाद आर्किटेक्चरः सर्वर या लार्ज मशीन मुख्य सिद्धांत: ज्ञान इंजीनियरिंग बुनियादी निर्णय तर्कः निर्णय समर्थन प्रणाली, सीमित उपयोगिता
1990 से 2000 तक
प्रमुख शैलियोंः बेयज़ वास्तुकलाः छोटे सर्वर क्लस्टर प्रमुख सिद्धांत: संभाव्यता सिद्धांत वर्गीकरणः विस्तार योग्य तुलना या तुलना, कई कार्यों के लिए पर्याप्त है
2010 के दशक की शुरुआत और मध्य
प्रमुख शैलियोंः संघवाद वास्तुकला: एक विशाल सर्वर फ़ार्म प्रमुख सिद्धांत: तंत्रिका विज्ञान और संभावना पहचानः अधिक सटीक छवि और ध्वनि पहचान, अनुवाद, भावनात्मक विश्लेषण आदि
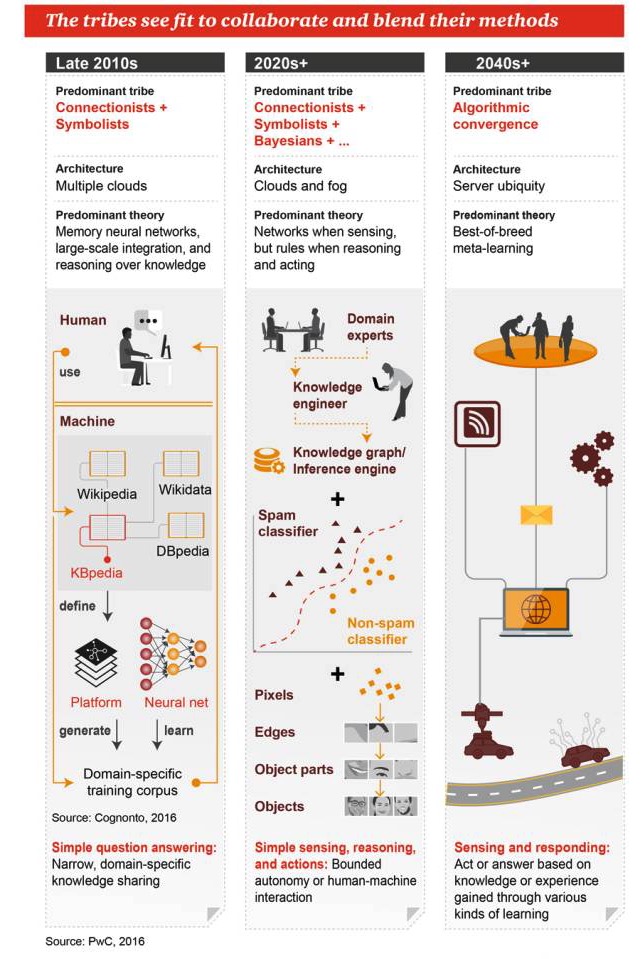
इन शैलियों को एक साथ काम करने और अपने तरीकों को एक साथ जोड़ने की उम्मीद है
2010 के दशक के अंत में
प्रमुख शैलियोंः लिंक्डइनवाद + प्रतीकवाद वास्तुकलाः कई बादल प्रमुख सिद्धांत: स्मृति तंत्रिका नेटवर्क, बड़े पैमाने पर एकीकरण, ज्ञान आधारित तर्क सरल प्रश्न और उत्तरः संकीर्ण, क्षेत्र-विशिष्ट ज्ञान साझा करना
2020 के दशक +
प्रमुख शैलियोंः लिंक्डइनवाद + प्रतीकवाद + बेयज़ + … वास्तुकलाः क्लाउड और मिस्ट प्रमुख सिद्धांतः जब धारणा होती है तो नेटवर्क होता है, जब तर्क होता है तो नियम होते हैं और जब काम होता है सरल धारणा, तर्क और कार्यः सीमित स्वचालन या मानव-मशीन बातचीत
2040 के दशक+
प्रमुख शैलियोंः एल्गोरिदम का एकीकरण वास्तुकलाः सर्वव्यापी सर्वर प्रमुख सिद्धांत: सबसे अच्छा संयोजन मेटा-लर्निंग अनुभूति और प्रतिक्रिया: ज्ञान या अनुभवों के आधार पर कार्रवाई या जवाब देना जो विभिन्न प्रकार के सीखने के माध्यम से प्राप्त होते हैं
- #### तीसरा, मशीन लर्निंग एल्गोरिदम

यह काफी हद तक उपलब्ध डेटा की प्रकृति और मात्रा और प्रत्येक विशिष्ट उपयोग के मामले में आपके प्रशिक्षण उद्देश्यों पर निर्भर करता है। सबसे जटिल एल्गोरिदम का उपयोग न करें, जब तक कि परिणाम महंगे खर्च और संसाधनों के लायक न हों। यहां कुछ सबसे आम एल्गोरिदम दिए गए हैं, जो उपयोग में आसानी से क्रमबद्ध हैं।
निर्णय वृक्षः चरणबद्ध प्रतिक्रिया के दौरान, एक विशिष्ट निर्णय वृक्ष विश्लेषण एक स्तरित चर या निर्णय नोड का उपयोग करता है, उदाहरण के लिए, किसी दिए गए उपयोगकर्ता को क्रेडिट विश्वसनीय या अविश्वसनीय के रूप में वर्गीकृत करना।
योग्यताः लोगों, स्थानों और चीजों के विभिन्न लक्षणों, गुणों और विशेषताओं का मूल्यांकन करने में कुशल परिदृश्य उदाहरणः नियम आधारित क्रेडिट मूल्यांकन, घोड़े के परिणामों की भविष्यवाणी
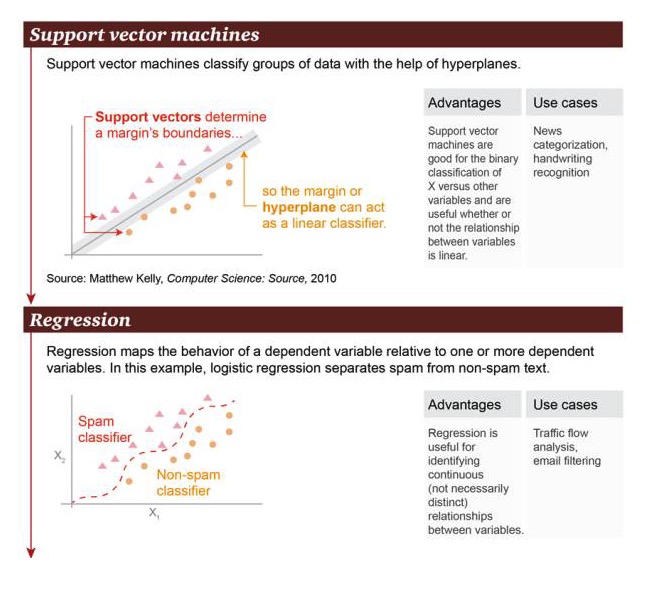
समर्थन वेक्टर मशीनः सुपरप्लेन के आधार पर, समर्थन वेक्टर मशीन डेटा समूहों को वर्गीकृत कर सकती है।
लाभः समर्थित वेक्टर मशीनें चर X और अन्य चरों के बीच द्विआधारी वर्गीकरण संचालन में कुशल हैं, चाहे उनके संबंध रैखिक हों या नहीं उदाहरण के लिए, समाचार वर्गीकरण, हस्तलिखित पहचान।
Regression: Regression एक या एक से अधिक कारक चरों के बीच एक राज्य संबंध को रेखांकित करता है। इस उदाहरण में, स्पैम और गैर-स्पैम मेल में अंतर किया गया है।
लाभः रिग्रेशन का उपयोग चर के बीच निरंतर संबंध की पहचान करने के लिए किया जा सकता है, भले ही यह संबंध बहुत स्पष्ट न हो उदाहरण: सड़क यातायात विश्लेषण, ईमेल फ़िल्टरिंग
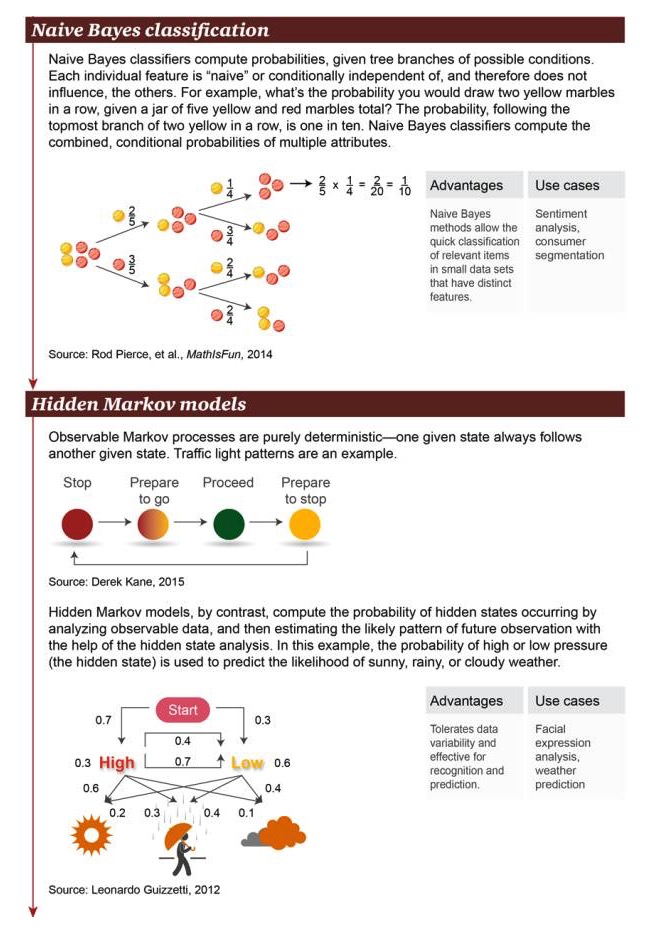
Naive Bayes Classification: Naive Bayes Classification: Naive Bayes Classification का उपयोग संभावित शर्तों की शाखाओं की संभावनाओं की गणना करने के लिए किया जाता है। प्रत्येक स्वतंत्र विशेषता “नाजुक” या सशर्त स्वतंत्र होती है, इसलिए वे अन्य वस्तुओं को प्रभावित नहीं करती हैं। उदाहरण के लिए, 5 पीले और लाल छोटे गेंदों के एक समूह में, लगातार दो पीले गेंदों को पकड़ने की संभावना क्या है?
लाभः सरल बेयज़ विधि छोटे डेटासेट पर महत्वपूर्ण विशेषताओं वाले संबंधित वस्तुओं के लिए त्वरित वर्गीकरण प्रदान करती है उदाहरण: भावनात्मक विश्लेषण, उपभोक्ता वर्गीकरण
छिपे हुए मार्कोव मॉडल (Hidden Markov model): यह दिखाता है कि मार्कोव प्रक्रिया पूरी तरह से निश्चित है कि एक दी गई स्थिति अक्सर एक और स्थिति के साथ होती है। ट्रैफिक सिग्नल एक उदाहरण है। इसके विपरीत, एक छिपे हुए मार्कोव मॉडल दृश्य डेटा का विश्लेषण करके छिपे हुए राज्य की घटना की गणना करता है। इसके बाद, छिपे हुए राज्य विश्लेषण का उपयोग करके, एक छिपे हुए मार्कोव मॉडल संभावित भविष्य के अवलोकन पैटर्न का अनुमान लगा सकता है। इस मामले में, उच्च या निम्न वायु दबाव की संभावना (यह एक छिपी हुई स्थिति है) का उपयोग धूप, बारिश और बादल वाले दिनों की संभावना की भविष्यवाणी करने के लिए किया जा सकता है।
लाभः डेटा परिवर्तनशीलता की अनुमति देता है, मान्यता और पूर्वानुमान संचालन के लिए उपयुक्त है उदाहरण: चेहरे के भावों का विश्लेषण, मौसम का पूर्वानुमान
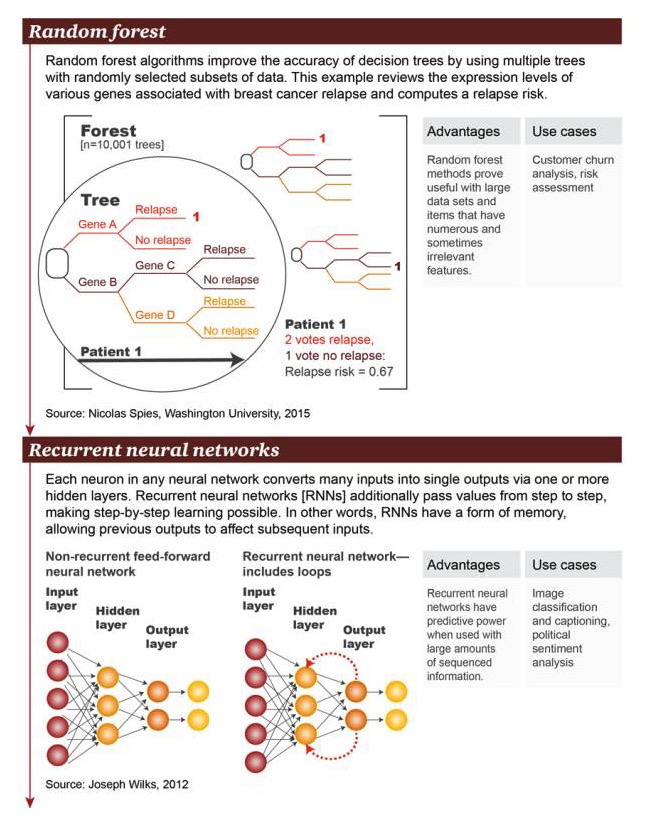
यादृच्छिक वन (Random forest): यादृच्छिक वन एल्गोरिथ्म ने निर्णय पेड़ों की सटीकता में सुधार किया है, जिसमें कई यादृच्छिक रूप से चयनित डेटा के उप-समूहों के साथ पेड़ों का उपयोग किया गया है। इस उदाहरण में स्तन कैंसर के पुनरावृत्ति के साथ जुड़े कई जीनों को जीन अभिव्यक्ति के स्तर पर देखा गया है और पुनरावृत्ति के जोखिम की गणना की गई है।
लाभः यादृच्छिक वन पद्धति बड़े पैमाने पर डेटासेट और बड़ी संख्या में और कभी-कभी असंबद्ध विशेषताओं वाली वस्तुओं के लिए उपयोगी साबित हुई है उदाहरण: उपयोगकर्ता प्रवाह विश्लेषण, जोखिम मूल्यांकन
पुनरावर्ती तंत्रिका नेटवर्क (recurrent neural network): एक वैकल्पिक तंत्रिका नेटवर्क में, प्रत्येक न्यूरॉन एक या अधिक छिपी हुई परतों के माध्यम से कई इनपुट को एक एकल आउटपुट में परिवर्तित करता है। पुनरावर्ती तंत्रिका नेटवर्क (RNN) मानों को और अधिक परतों में स्थानांतरित करता है, जिससे परतों में सीखने की अनुमति मिलती है। दूसरे शब्दों में, आरएनएन में कुछ प्रकार की स्मृति होती है, जो पिछले आउटपुट को बाद के इनपुट को प्रभावित करने की अनुमति देती है।
पेशेवरों: प्रचुर मात्रा में व्यवस्थित जानकारी के साथ एक चक्रीय तंत्रिका नेटवर्क की पूर्वानुमान क्षमता उदाहरण: छवि वर्गीकरण और उपशीर्षक जोड़ना, राजनीतिक भावनात्मक विश्लेषण

लंबी अल्पकालिक स्मृति (LSTM) और द्वार नियंत्रित पुनरावर्ती इकाई तंत्रिका नेटवर्क (gated recurrent unit nerual network): आरएनएन के शुरुआती रूप में, हानि होती है। हालांकि इन शुरुआती पुनरावर्ती तंत्रिका नेटवर्क ने केवल कुछ प्रारंभिक जानकारी को बनाए रखने की अनुमति दी थी, हाल ही में लंबी अल्पकालिक स्मृति (LSTM) और द्वार नियंत्रित पुनरावर्ती इकाई (GRU) तंत्रिका नेटवर्क में दीर्घकालिक और अल्पकालिक स्मृति दोनों हैं। दूसरे शब्दों में, इन हालिया आरएनएन में बेहतर स्मृति नियंत्रण क्षमता है, जो पहले के मूल्यों को बनाए रखने की अनुमति देता है या जब कई चरणों की श्रृंखला को संभालना आवश्यक होता है, तो इन मूल्यों को पुनर्स्थापित किया जाता है, जो कि “अवमूल्य” या “चरणीय” स्तर पर पारित मूल्यों के अंतिम क्षरण से बचा जाता है। GRU के साथ, हम स्मृति या मॉड्यूल संरचना का उपयोग कर सकते हैं, जिसे “गेट” कहा जाता है, ताकि स्मृति को नियंत्रित किया जा सके।
लाभः दीर्घकालिक स्मृति और द्वार-नियंत्रण पुनरावर्ती न्यूरल नेटवर्क अन्य पुनरावर्ती न्यूरल नेटवर्क के समान फायदे हैं, लेकिन वे बेहतर स्मृति क्षमता के कारण अधिक बार उपयोग किए जाते हैं उदाहरण: प्राकृतिक भाषा प्रसंस्करण, अनुवाद
Convolutional neural network (कन्वोल्यूशनल न्यूरल नेटवर्क): कन्वोल्यूशनल न्यूरल नेटवर्क (कन्वोल्यूशनल न्यूरल नेटवर्क) एक ऐसा प्रकार का न्यूरल नेटवर्क है जो बाद की परतों से प्राप्त भारों के एकीकरण को दर्शाता है। इसका उपयोग आउटपुट परतों को चिह्नित करने के लिए किया जा सकता है।
पेशेवरों: जब बहुत बड़े डेटासेट, बहुत सारी विशेषताएं और जटिल वर्गीकरण कार्य होते हैं, तो घर्षण तंत्रिका नेटवर्क बहुत उपयोगी होते हैं उदाहरण के लिए, छवि पहचान, टेक्स्ट ट्रांसफ़र, वाणी, दवा की खोज
- #### मूल लेख के लिए लिंकः
http://usblogs.pwc.com/emerging-technology/a-look-at-machine-learning-infographic/
http://usblogs.pwc.com/emerging-technology/machine-learning-methods-infographic/
http://usblogs.pwc.com/emerging-technology/machine-learning-evolution-infographic/
बड़े डेटा क्षेत्र से पुनः प्राप्त