

डिजिटल मुद्रा सट्टेबाजी का विश्लेषण करने के लिए डेटा-संचालित दृष्टिकोण
बिटकॉइन की कीमत कैसा प्रदर्शन कर रही है? क्रिप्टोकरेंसी की कीमतों में उछाल और गिरावट का क्या कारण है? क्या विभिन्न ऑल्टकॉइनों के बाजार मूल्य एक दूसरे से अभिन्न रूप से जुड़े हुए हैं या वे काफी हद तक स्वतंत्र हैं? हम कैसे अनुमान लगा सकते हैं कि आगे क्या होगा?
बिटकॉइन और एथेरियम जैसी डिजिटल मुद्राओं के बारे में लेख अब अटकलों से भरे पड़े हैं, जिसमें सैकड़ों स्वयंभू विशेषज्ञ उन रुझानों की वकालत कर रहे हैं जिनके उभरने की उन्हें उम्मीद है। इनमें से अधिकांश विश्लेषणों में अंतर्निहित डेटा और सांख्यिकीय मॉडल का ठोस आधार नहीं है।
इस लेख का लक्ष्य पायथन का उपयोग करके क्रिप्टोकरेंसी विश्लेषण का एक सरल परिचय प्रदान करना है। हम विभिन्न क्रिप्टोकरेंसी के लिए डेटा को पुनः प्राप्त करने, विश्लेषण करने और विज़ुअलाइज़ करने के लिए एक सरल पायथन स्क्रिप्ट का उपयोग करेंगे। इस दौरान, हम इन अस्थिर बाजारों के व्यवहार और उनके विकास में दिलचस्प रुझानों की खोज करेंगे।
यह क्रिप्टोकरेंसी के बारे में व्याख्या करने वाला लेख नहीं है, न ही यह इस बारे में राय देने वाला लेख है कि कौन सी विशिष्ट मुद्राएं बढ़ेंगी और कौन सी गिरेंगी। इसके बजाय, इस ट्यूटोरियल में हमारा ध्यान केवल कच्चे डेटा को लेना और संख्याओं में छिपी कहानियों की खोज करना है।
चरण 1: अपना डेटा कार्य वातावरण बनाएं
यह ट्यूटोरियल सभी कौशल स्तरों के उत्साही, इंजीनियरों और डेटा वैज्ञानिकों के लिए डिज़ाइन किया गया है। चाहे आप उद्योग विशेषज्ञ हों या प्रोग्रामिंग के नौसिखिए, आपको केवल पायथन प्रोग्रामिंग भाषा की बुनियादी समझ और कमांड लाइन संचालन का पर्याप्त ज्ञान होना चाहिए। (बस एक डेटा विज्ञान परियोजना स्थापित करने में सक्षम हो)।
1.1 इन्वेंटर क्वांट होस्ट स्थापित करें और एनाकोंडा सेट अप करें
- क्वांटिफाइड कस्टोडियन सिस्टम के आविष्कारक
प्रमुख मुख्यधारा एक्सचेंजों से उच्च गुणवत्ता वाले डेटा स्रोत प्रदान करने के अलावा, इन्वेंटर क्वांटिटेटिव प्लेटफॉर्म FMZ.COM हमें डेटा विश्लेषण पूरा करने के बाद स्वचालित लेनदेन करने में मदद करने के लिए API इंटरफेस का एक समृद्ध सेट भी प्रदान करता है। इंटरफेस के इस सेट में व्यावहारिक उपकरण शामिल हैं जैसे खाता जानकारी की क्वेरी करना, उच्च, प्रारंभिक, निम्न, समापन मूल्य, ट्रेडिंग वॉल्यूम, विभिन्न मुख्यधारा के एक्सचेंजों के विभिन्न आमतौर पर इस्तेमाल किए जाने वाले तकनीकी विश्लेषण संकेतक आदि की क्वेरी करना, विशेष रूप से वास्तविक समय में प्रमुख मुख्यधारा के एक्सचेंजों से जुड़ने के लिए। ट्रेडिंग प्रक्रियाएं। सार्वजनिक एपीआई इंटरफ़ेस शक्तिशाली तकनीकी सहायता प्रदान करता है।
ऊपर बताए गए सभी फ़ंक्शन Docker जैसी ही एक प्रणाली में समाहित हैं। हमें बस इतना करना है कि अपनी खुद की क्लाउड कंप्यूटिंग सेवा खरीदनी है या किराए पर लेनी है और फिर Docker सिस्टम को तैनात करना है।
इन्वेंटर क्वांटिटेटिव प्लेटफॉर्म के आधिकारिक नाम में, इस डॉकर सिस्टम को होस्ट सिस्टम कहा जाता है।
होस्ट और रोबोट को तैनात करने के तरीके के बारे में अधिक जानकारी के लिए, कृपया मेरा पिछला लेख देखें: https://www.fmz.com/bbs-topic/4140
जो पाठक अपना स्वयं का क्लाउड कंप्यूटिंग सर्वर परिनियोजन होस्ट खरीदना चाहते हैं, वे इस लेख का संदर्भ ले सकते हैं: https://www.fmz.com/bbs-topic/2848
क्लाउड कंप्यूटिंग सेवा और होस्ट सिस्टम को सफलतापूर्वक तैनात करने के बाद, हम सबसे शक्तिशाली पायथन टूल स्थापित करेंगे: एनाकोंडा
इस आलेख के लिए आवश्यक सभी प्रासंगिक प्रोग्राम वातावरण (आश्रित लाइब्रेरीज़, संस्करण प्रबंधन, आदि) को प्राप्त करने के लिए, सबसे आसान तरीका एनाकोंडा का उपयोग करना है। यह एक पैकेज्ड पायथन डेटा विज्ञान पारिस्थितिकी तंत्र और निर्भरता प्रबंधक है।
चूंकि हम एनाकोंडा को क्लाउड सेवा पर स्थापित कर रहे हैं, इसलिए हम अनुशंसा करते हैं कि आप लिनक्स सिस्टम के साथ-साथ एनाकोंडा का कमांड लाइन संस्करण भी क्लाउड सर्वर पर स्थापित करें।
एनाकोंडा की स्थापना विधि के लिए, कृपया एनाकोंडा की आधिकारिक मार्गदर्शिका देखें: https://www.anaconda.com/distribution/
यदि आप एक अनुभवी पायथन प्रोग्रामर हैं और एनाकोंडा का उपयोग करने की आवश्यकता महसूस नहीं करते हैं, तो यह बिल्कुल ठीक है। मैं यह मानूंगा कि आपको आवश्यक निर्भरताएं स्थापित करने में सहायता की आवश्यकता नहीं है और आप सीधे भाग 2 पर जा सकते हैं।
1.2 एनाकोंडा डेटा विश्लेषण परियोजना वातावरण बनाएँ
एनाकोंडा स्थापित होने के बाद, हमें अपने निर्भरता पैकेजों को प्रबंधित करने के लिए एक नया वातावरण बनाने की आवश्यकता है। लिनक्स कमांड लाइन इंटरफ़ेस में, हम दर्ज करते हैं:
conda create --name cryptocurrency-analysis python=3
आइए अपने प्रोजेक्ट के लिए एक नया एनाकोंडा वातावरण बनाएं।
इसके बाद, दर्ज करें
source activate cryptocurrency-analysis (linux/MacOS操作)
或者
activate cryptocurrency-analysis (windows操作系统)
इस वातावरण को सक्रिय करने के लिए
इसके बाद, दर्ज करें:
conda install numpy pandas nb_conda jupyter plotly
इस परियोजना के लिए आवश्यक विभिन्न निर्भरता पैकेजों को स्थापित करने के लिए।
नोट: एनाकोंडा वातावरण का उपयोग क्यों करें? यदि आप अपने कंप्यूटर पर कई पायथन प्रोजेक्ट चलाने की योजना बना रहे हैं, तो टकराव से बचने के लिए विभिन्न प्रोजेक्ट की निर्भरताओं (लाइब्रेरी और पैकेज) को अलग करना उपयोगी होगा। एनाकोंडा प्रत्येक परियोजना के निर्भरता पैकेज के लिए एक विशेष वातावरण निर्देशिका बनाता है ताकि सभी पैकेजों को उचित रूप से प्रबंधित और विभेदित किया जा सके।
1.3 ज्यूपिटर नोटबुक बनाएं
वातावरण और निर्भरता पैकेज स्थापित होने के बाद, चलाएँ
jupyter notebook
iPython कर्नेल को प्रारंभ करने के लिए, फिर अपने ब्राउज़र को http://localhost:8888/ पर इंगित करें और एक नया पायथन नोटबुक बनाएं, यह सुनिश्चित करते हुए कि यह उपयोग करता है:
Python [conda env:cryptocurrency-analysis]
गुठली

1.4 आश्रित पैकेज आयात करना
एक नया खाली ज्यूपिटर नोटबुक बनाएं, और पहली चीज जो हमें करने की ज़रूरत है वह है आवश्यक निर्भरता पैकेजों को आयात करना।
import os
import numpy as np
import pandas as pd
import pickle
from datetime import datetime
हमें प्लॉटली को आयात करने और ऑफ़लाइन मोड को सक्षम करने की भी आवश्यकता है
import plotly.offline as py
import plotly.graph_objs as go
import plotly.figure_factory as ff
py.init_notebook_mode(connected=True)
चरण 2: डिजिटल मुद्रा की कीमत की जानकारी प्राप्त करें
अब चूंकि तैयारियां पूरी हो गई हैं, हम विश्लेषण हेतु डेटा एकत्र करना शुरू कर सकते हैं। सबसे पहले, हमें बिटकॉइन मूल्य डेटा प्राप्त करने के लिए इन्वेंटर क्वांटिटेटिव प्लेटफॉर्म के एपीआई इंटरफ़ेस का उपयोग करना होगा।
यह GetTicker फ़ंक्शन का उपयोग करेगा। इन दो फ़ंक्शन के उपयोग के विवरण के लिए, कृपया देखें: https://www.fmz.com/api
2.1 क्वांडल डेटा संग्रह फ़ंक्शन लिखें
डेटा अधिग्रहण को सुविधाजनक बनाने के लिए, हमें क्वांडल (quandl.com) से डेटा डाउनलोड करने और सिंक्रनाइज़ करने के लिए एक फ़ंक्शन लिखने की आवश्यकता है। यह एक निःशुल्क वित्तीय डेटा इंटरफ़ेस है जो विदेशों में बहुत प्रसिद्ध है। इन्वेंटर क्वांटिटेटिव प्लेटफ़ॉर्म भी एक समान डेटा इंटरफ़ेस प्रदान करता है, जिसका उपयोग मुख्य रूप से वास्तविक समय के व्यापार के लिए किया जाता है। चूंकि यह लेख मुख्य रूप से डेटा विश्लेषण के लिए है, इसलिए हम अभी भी यहाँ क्वांडल के डेटा का उपयोग करते हैं।
वास्तविक समय में ट्रेडिंग करते समय, आप मूल्य डेटा प्राप्त करने के लिए सीधे पायथन में GetTicker और GetRecords फ़ंक्शन को कॉल कर सकते हैं। उनके उपयोग के लिए, कृपया देखें: https://www.fmz.com/api
def get_quandl_data(quandl_id):
# 下载和缓冲来自Quandl的数据列
cache_path = '{}.pkl'.format(quandl_id).replace('/','-')
try:
f = open(cache_path, 'rb')
df = pickle.load(f)
print('Loaded {} from cache'.format(quandl_id))
except (OSError, IOError) as e:
print('Downloading {} from Quandl'.format(quandl_id))
df = quandl.get(quandl_id, returns="pandas")
df.to_pickle(cache_path)
print('Cached {} at {}'.format(quandl_id, cache_path))
return df
यहां डेटा को क्रमबद्ध करने और डाउनलोड किए गए डेटा को फ़ाइल के रूप में सहेजने के लिए पिकल लाइब्रेरी का उपयोग किया जाता है, ताकि प्रोग्राम हर बार चलने पर समान डेटा को पुनः डाउनलोड न करे। यह फ़ंक्शन पांडा डेटाफ़्रेम प्रारूप में डेटा लौटाएगा। यदि आप डेटा फ़्रेम की अवधारणा से परिचित नहीं हैं, तो इसे एक शक्तिशाली एक्सेल स्प्रेडशीट के रूप में सोचें।
2.2 क्रैकेन एक्सचेंज से क्रिप्टोकरेंसी मूल्य डेटा प्राप्त करना
आइए क्रैकेन बिटकॉइन एक्सचेंज को एक उदाहरण के रूप में उपयोग करें और इसकी बिटकॉइन कीमत प्राप्त करके शुरुआत करें।
# 获取Kraken比特币交易所的价格
btc_usd_price_kraken = get_quandl_data('BCHARTS/KRAKENUSD')
डेटा फ़्रेम की पहली पाँच पंक्तियों को देखने के लिए head() विधि का उपयोग करें।
btc_usd_price_kraken.head()
परिणाम यह है:
| BTC | Open | High | Low | Close | Volume (BTC) | Volume (Currency) | Weighted Price |
|---|---|---|---|---|---|---|---|
| 2014-01-07 | 874.67040 | 892.06753 | 810.00000 | 810.00000 | 15.622378 | 13151.472844 | 841.835522 |
| 2014-01-08 | 810.00000 | 899.84281 | 788.00000 | 824.98287 | 19.182756 | 16097.329584 | 839.156269 |
| 2014-01-09 | 825.56345 | 870.00000 | 807.42084 | 841.86934 | 8.158335 | 6784.249982 | 831.572913 |
| 2014-01-10 | 839.99000 | 857.34056 | 817.00000 | 857.33056 | 8.024510 | 6780.220188 | 844.938794 |
| 2014-01-11 | 858.20000 | 918.05471 | 857.16554 | 899.84105 | 18.748285 | 16698.566929 | 890.671709 |
इसके बाद, हमें विज़ुअलाइज़ेशन के माध्यम से डेटा की शुद्धता को सत्यापित करने के लिए एक सरल तालिका बनाने की आवश्यकता है।
# 做出BTC价格的表格
btc_trace = go.Scatter(x=btc_usd_price_kraken.index, y=btc_usd_price_kraken['Weighted Price'])
py.iplot([btc_trace])
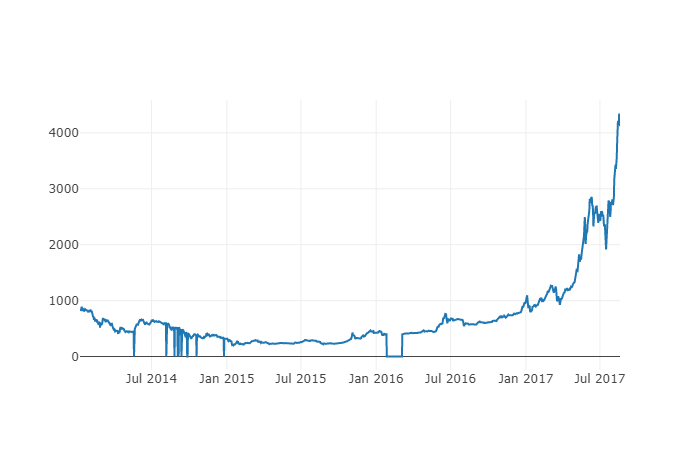
यहां, हम विज़ुअलाइज़ेशन भाग को पूरा करने के लिए प्लॉटली का उपयोग करते हैं। प्लॉटली, मैटप्लॉटलिब जैसे कुछ अधिक परिपक्व पायथन डेटा विज़ुअलाइज़ेशन लाइब्रेरीज़ की तुलना में कम सामान्य विकल्प है, लेकिन यह एक अच्छा विकल्प है क्योंकि यह पूरी तरह से इंटरैक्टिव चार्ट के लिए D3.js पर कॉल कर सकता है। चार्ट में बहुत अच्छी डिफ़ॉल्ट सेटिंग्स हैं, उन्हें खोजना आसान है, और वेब पेजों में एम्बेड करना बहुत सुविधाजनक है।
टिप: आप डाउनलोड किए गए डेटा के लगभग सुसंगत होने की पुष्टि करने के लिए एक त्वरित जांच के रूप में उत्पन्न चार्ट की तुलना किसी प्रमुख एक्सचेंज (जैसे OKEX, Binance, या Huobi) से बिटकॉइन मूल्य चार्ट के साथ कर सकते हैं।
2.3 प्रमुख बिटकॉइन एक्सचेंजों से मूल्य डेटा प्राप्त करना
सावधान पाठकों ने देखा होगा कि उपरोक्त आंकड़ों में कुछ डेटा गायब हैं, विशेष रूप से 2014 के अंत और 2016 के प्रारंभ में। यह डेटा अंतर क्रैकेन एक्सचेंज में विशेष रूप से स्पष्ट है। हम निश्चित रूप से नहीं चाहते कि यह अनुपलब्ध डेटा हमारे मूल्य विश्लेषण को प्रभावित करे।
डिजिटल मुद्रा एक्सचेंजों की विशेषता यह है कि मुद्रा की कीमत आपूर्ति और मांग से निर्धारित होती है। इसलिए, कोई भी लेनदेन मूल्य बाजार का "मुख्यधारा मूल्य" नहीं बन सकता है। इस समस्या के समाधान के लिए, साथ ही साथ अभी बताई गई डेटा की कमी की समस्या (संभवतः तकनीकी खराबी और डेटा त्रुटियों के कारण) के समाधान के लिए, हम दुनिया के तीन प्रमुख बिटकॉइन एक्सचेंजों से डेटा डाउनलोड करेंगे और औसत बिटकॉइन मूल्य की गणना करेंगे।
आइए प्रत्येक एक्सचेंज के डेटा को एक शब्दकोश प्रकार वाले डेटाफ़्रेम में डाउनलोड करके शुरू करें।
# 下载COINBASE,BITSTAMP和ITBIT的价格数据
exchanges = ['COINBASE','BITSTAMP','ITBIT']
exchange_data = {}
exchange_data['KRAKEN'] = btc_usd_price_kraken
for exchange in exchanges:
exchange_code = 'BCHARTS/{}USD'.format(exchange)
btc_exchange_df = get_quandl_data(exchange_code)
exchange_data[exchange] = btc_exchange_df
2.4 सभी डेटा को एक डेटा फ़्रेम में एकीकृत करें
इसके बाद, हम प्रत्येक डेटा फ़्रेम से सामान्य कॉलम को एक नए डेटा फ़्रेम में मर्ज करने के लिए एक विशेष फ़ंक्शन परिभाषित करेंगे। आइए इसे merge_dfs_on_column फ़ंक्शन कहते हैं
def merge_dfs_on_column(dataframes, labels, col):
'''Merge a single column of each dataframe into a new combined dataframe'''
series_dict = {}
for index in range(len(dataframes)):
series_dict[labels[index]] = dataframes[index][col]
return pd.DataFrame(series_dict)
अब, प्रत्येक डेटासेट के "भारित मूल्य" कॉलम के आधार पर सभी डेटाफ़्रेम को एक साथ संयोजित करें।
# 整合所有数据帧
btc_usd_datasets = merge_dfs_on_column(list(exchange_data.values()), list(exchange_data.keys()), 'Weighted Price')
अंत में, हम मर्ज किए गए डेटा की अंतिम पांच पंक्तियों को देखने के लिए “tail()” विधि का उपयोग करते हैं ताकि यह सुनिश्चित किया जा सके कि डेटा सही और पूर्ण है।
btc_usd_datasets.tail()
परिणाम यह है:
| BTC | BITSTAMP | COINBASE | ITBIT | KRAKEN |
|---|---|---|---|---|
| 2017-08-14 | 4210.154943 | 4213.332106 | 4207.366696 | 4213.257519 |
| 2017-08-15 | 4101.447155 | 4131.606897 | 4127.036871 | 4149.146996 |
| 2017-08-16 | 4193.426713 | 4193.469553 | 4190.104520 | 4187.399662 |
| 2017-08-17 | 4338.694675 | 4334.115210 | 4334.449440 | 4346.508031 |
| 2017-08-18 | 4182.166174 | 4169.555948 | 4175.440768 | 4198.277722 |
जैसा कि आप ऊपर दी गई तालिका से देख सकते हैं, ये डेटा हमारी अपेक्षाओं के अनुरूप हैं। डेटा रेंज लगभग समान है, लेकिन प्रत्येक एक्सचेंज की विलंबता या विशेषताओं के आधार पर इसमें थोड़ा अंतर है।
2.5 मूल्य डेटा विज़ुअलाइज़ेशन प्रक्रिया
विश्लेषणात्मक तर्क के दृष्टिकोण से, अगला चरण विज़ुअलाइज़ेशन के माध्यम से इन आंकड़ों की तुलना करना है। ऐसा करने के लिए, हमें सबसे पहले एक हेल्पर फ़ंक्शन को परिभाषित करना होगा जो एक सिंगल लाइन कमांड प्रदान करके डेटा का उपयोग करके चार्ट बनाता है। चलिए इसे df_scatter फ़ंक्शन कहते हैं।
def df_scatter(df, title, seperate_y_axis=False, y_axis_label='', scale='linear', initial_hide=False):
'''Generate a scatter plot of the entire dataframe'''
label_arr = list(df)
series_arr = list(map(lambda col: df[col], label_arr))
layout = go.Layout(
title=title,
legend=dict(orientation="h"),
xaxis=dict(type='date'),
yaxis=dict(
title=y_axis_label,
showticklabels= not seperate_y_axis,
type=scale
)
)
y_axis_config = dict(
overlaying='y',
showticklabels=False,
type=scale )
visibility = 'visible'
if initial_hide:
visibility = 'legendonly'
# 每个系列的表格跟踪
trace_arr = []
for index, series in enumerate(series_arr):
trace = go.Scatter(
x=series.index,
y=series,
name=label_arr[index],
visible=visibility
)
# 为系列添加单独的轴
if seperate_y_axis:
trace['yaxis'] = 'y{}'.format(index + 1)
layout['yaxis{}'.format(index + 1)] = y_axis_config
trace_arr.append(trace)
fig = go.Figure(data=trace_arr, layout=layout)
py.iplot(fig)
आपकी आसान समझ के लिए, इस आलेख में इस सहायक फ़ंक्शन के तार्किक सिद्धांत पर विस्तार से चर्चा नहीं की जाएगी। यदि आप अधिक जानना चाहते हैं, तो पांडा और प्लॉटली के आधिकारिक दस्तावेज़ देखें।
अब हम आसानी से बिटकॉइन मूल्य डेटा का ग्राफ बना सकते हैं!
# 绘制所有BTC交易价格
df_scatter(btc_usd_datasets, 'Bitcoin Price (USD) By Exchange')
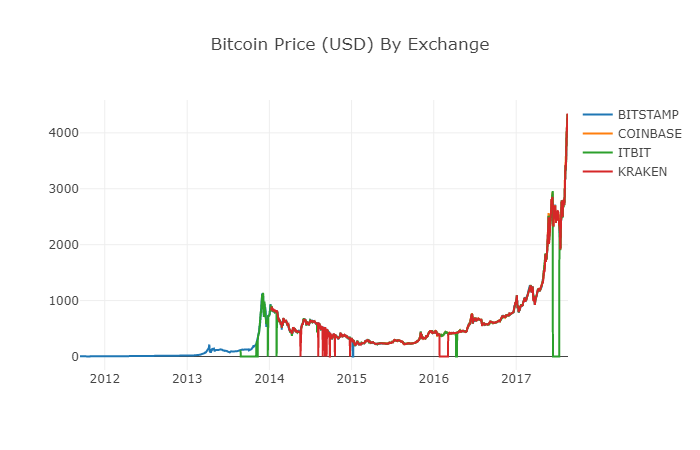
2.6 स्वच्छ एवं समग्र मूल्य डेटा
जैसा कि आप उपरोक्त ग्राफ से देख सकते हैं, यद्यपि चारों श्रृंखलाएं मोटे तौर पर एक ही पथ का अनुसरण करती हैं, फिर भी उनमें कुछ अनियमितताएं हैं, जिन्हें हम स्पष्ट करने का प्रयास करेंगे।
2012-2017 की अवधि में, हम जानते हैं कि बिटकॉइन की कीमत कभी भी शून्य के बराबर नहीं रही है, इसलिए हम पहले डेटा फ़्रेम में सभी शून्य मान हटाते हैं।
# 清除"0"值
btc_usd_datasets.replace(0, np.nan, inplace=True)
डेटाफ्रेम के पुनर्निर्माण के बाद, हम बिना किसी लुप्त डेटा के साथ अधिक स्पष्ट ग्राफ देख सकते हैं।
# 绘制修订后的数据框
df_scatter(btc_usd_datasets, 'Bitcoin Price (USD) By Exchange')
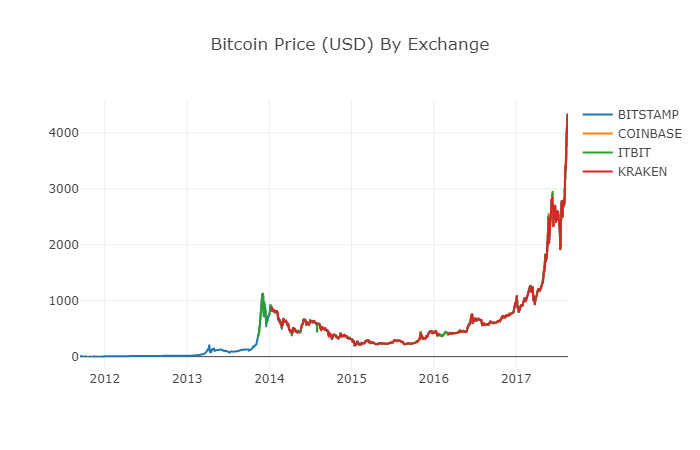
अब हम एक नया कॉलम गणना कर सकते हैं: सभी एक्सचेंजों में बिटकॉइन की औसत दैनिक कीमत।
# 将平均BTC价格计算为新列
btc_usd_datasets['avg_btc_price_usd'] = btc_usd_datasets.mean(axis=1)
नया कॉलम बिटकॉइन मूल्य सूचकांक है! आइए इसे पुनः प्लॉट करें और जाँचें कि क्या डेटा में कुछ गड़बड़ है।
# 绘制平均BTC价格
btc_trace = go.Scatter(x=btc_usd_datasets.index, y=btc_usd_datasets['avg_btc_price_usd'])
py.iplot([btc_trace])
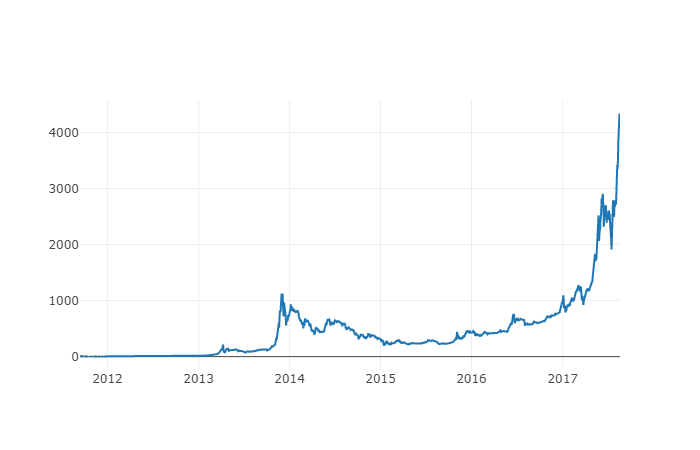
ऐसा लगता है कि इसमें कोई समस्या नहीं है, और हम बाद में अन्य क्रिप्टोकरेंसी और अमेरिकी डॉलर के बीच विनिमय दर निर्धारित करने के लिए इस समेकित मूल्य श्रृंखला डेटा का उपयोग करना जारी रखेंगे।
चरण 3: ऑल्टकॉइन की कीमतें एकत्रित करें
अब तक हमारे पास बिटकॉइन की कीमतों का समय श्रृंखला डेटा है। इसके बाद, आइए गैर-बिटकॉइन डिजिटल मुद्राओं, यानी ऑल्टकॉइन पर कुछ डेटा देखें। बेशक, ऑल्टकॉइन शब्द थोड़ा ज़्यादा ज़ोरदार हो सकता है, लेकिन डिजिटल मुद्राओं के मौजूदा विकास के लिए, बाज़ार पूंजीकरण रैंकिंग के अलावा ज़्यादातर शीर्ष दस (जैसे बिटकॉइन, एथेरियम, ईओएस, यूएसडीटी, आदि) को ऑल्टकॉइन कहा जा सकता है। इसमें कोई समस्या नहीं है। हमें व्यापार करते समय इन मुद्राओं से दूर रहने की कोशिश करनी चाहिए क्योंकि वे बहुत भ्रामक और भ्रामक हैं।
3.1 पोलोनीक्स एक्सचेंज एपीआई के माध्यम से सहायक कार्यों को परिभाषित करना
सबसे पहले, हम डिजिटल मुद्रा लेनदेन पर डेटा जानकारी प्राप्त करने के लिए पोलोनीक्स एक्सचेंज के एपीआई का उपयोग करते हैं। हमने altcoins के प्रासंगिक डेटा प्राप्त करने के लिए दो सहायक फ़ंक्शन परिभाषित किए हैं। ये दो फ़ंक्शन मुख्य रूप से API के माध्यम से JSON डेटा डाउनलोड और कैश करते हैं।
सबसे पहले, हम get_json_data फ़ंक्शन को परिभाषित करते हैं, जो किसी दिए गए URL से JSON डेटा को डाउनलोड और कैश करेगा।
def get_json_data(json_url, cache_path):
'''Download and cache JSON data, return as a dataframe.'''
try:
f = open(cache_path, 'rb')
df = pickle.load(f)
print('Loaded {} from cache'.format(json_url))
except (OSError, IOError) as e:
print('Downloading {}'.format(json_url))
df = pd.read_json(json_url)
df.to_pickle(cache_path)
print('Cached {} at {}'.format(json_url, cache_path))
return df
इसके बाद, हम एक नया फ़ंक्शन परिभाषित करते हैं जो Poloniex API को HTTP अनुरोध करेगा और कॉल के परिणाम को सहेजने के लिए हमारे द्वारा परिभाषित get_json_data फ़ंक्शन को कॉल करेगा।
base_polo_url = 'https://poloniex.com/public?command=returnChartData¤cyPair={}&start={}&end={}&period={}'
start_date = datetime.strptime('2015-01-01', '%Y-%m-%d') # 从2015年开始获取数据
end_date = datetime.now() # 直到今天
pediod = 86400 # pull daily data (86,400 seconds per day)
def get_crypto_data(poloniex_pair):
'''Retrieve cryptocurrency data from poloniex'''
json_url = base_polo_url.format(poloniex_pair, start_date.timestamp(), end_date.timestamp(), pediod)
data_df = get_json_data(json_url, poloniex_pair)
data_df = data_df.set_index('date')
return data_df
उपरोक्त फ़ंक्शन क्रिप्टोकरेंसी जोड़ी के स्ट्रिंग कोड (जैसे "BTC_ETH") को निकालेगा और दोनों मुद्राओं की ऐतिहासिक कीमतों वाले डेटा फ़्रेम को वापस करेगा।
3.2 पोलोनीक्स से लेनदेन मूल्य डेटा डाउनलोड करना
अधिकांश ऑल्टकॉइन सीधे अमेरिकी डॉलर का उपयोग करके नहीं खरीदे जा सकते हैं। यदि व्यक्ति इन डिजिटल मुद्राओं को प्राप्त करना चाहते हैं, तो उन्हें आमतौर पर पहले बिटकॉइन खरीदना होगा और फिर उनके बीच मूल्य अनुपात के आधार पर उन्हें ऑल्टकॉइन के लिए एक्सचेंज करना होगा। इसलिए, हमें प्रत्येक डिजिटल मुद्रा के लिए बिटकॉइन की विनिमय दर डाउनलोड करनी होगी, और फिर अमेरिकी डॉलर में बदलने के लिए मौजूदा बिटकॉइन मूल्य डेटा का उपयोग करना होगा। हम 9 शीर्ष क्रिप्टोकरेंसी के लिए लेनदेन डेटा डाउनलोड करेंगे: एथेरियम, लाइटकोइन, रिपल, एथेरियम क्लासिक, स्टेलर, डैश, सियाकोइन, मोनेरो और एनईएम।
altcoins = ['ETH','LTC','XRP','ETC','STR','DASH','SC','XMR','XEM']
altcoin_data = {}
for altcoin in altcoins:
coinpair = 'BTC_{}'.format(altcoin)
crypto_price_df = get_crypto_data(coinpair)
altcoin_data[altcoin] = crypto_price_df
अब हमारे पास 9 डेटा फ़्रेमों वाला एक शब्दकोष है, जिनमें से प्रत्येक में ऑल्टकॉइन और बिटकॉइन के बीच ऐतिहासिक दैनिक औसत मूल्य डेटा शामिल है।
हम इथेरियम मूल्य तालिका की अंतिम कुछ पंक्तियों को देखकर यह निर्धारित कर सकते हैं कि डेटा सही है या नहीं।
altcoin_data['ETH'].tail()
| ETH | Open | High | Low | Close | Volume (BTC) | Volume (Currency) | Weighted Price |
|---|---|---|---|---|---|---|---|
| 2017-08-18 | 0.070510 | 0.071000 | 0.070170 | 0.070887 | 17364.271529 | 1224.762684 | 0.070533 |
| 2017-08-18 | 0.071595 | 0.072096 | 0.070004 | 0.070510 | 26644.018123 | 1893.136154 | 0.071053 |
| 2017-08-18 | 0.071321 | 0.072906 | 0.070482 | 0.071600 | 39655.127825 | 2841.549065 | 0.071657 |
| 2017-08-19 | 0.071447 | 0.071855 | 0.070868 | 0.071321 | 16116.922869 | 1150.361419 | 0.071376 |
| 2017-08-19 | 0.072323 | 0.072550 | 0.071292 | 0.071447 | 14425.571894 | 1039.596030 | 0.072066 |
3.3 सभी मूल्य डेटा अमेरिकी डॉलर में व्यक्त किए जाने चाहिए
अब हम बिटकॉइन मूल्य सूचकांक के साथ बीटीसी से ऑल्टकॉइन विनिमय दर के आंकड़ों को संयोजित कर प्रत्येक ऑल्टकॉइन के ऐतिहासिक मूल्य की सीधे अमेरिकी डॉलर में गणना कर सकते हैं।
# 将USD Price计算为每个altcoin数据帧中的新列
for altcoin in altcoin_data.keys():
altcoin_data[altcoin]['price_usd'] = altcoin_data[altcoin]['weightedAverage'] * btc_usd_datasets['avg_btc_price_usd']
यहां, हम प्रत्येक altcoin के लिए डेटाफ्रेम में एक नया कॉलम जोड़ते हैं ताकि उसके संबंधित USD मूल्य को संग्रहीत किया जा सके।
इसके बाद, हम पहले से परिभाषित merge_dfs_on_column फ़ंक्शन का पुनः उपयोग कर सकते हैं, ताकि एक मर्ज किया गया डेटाफ़्रेम बनाया जा सके जो प्रत्येक क्रिप्टोकरेंसी के USD मूल्य को एकीकृत करता है।
# 将每个山寨币的美元价格合并为单个数据帧
combined_df = merge_dfs_on_column(list(altcoin_data.values()), list(altcoin_data.keys()), 'price_usd')
हो गया!
अब आइए मर्ज किए गए डेटाफ़्रेम में अंतिम कॉलम के रूप में बिटकॉइन की कीमत भी जोड़ें।
# 将BTC价格添加到数据帧
combined_df['BTC'] = btc_usd_datasets['avg_btc_price_usd']
अब हमारे पास एक अद्वितीय डेटाफ्रेम है जिसमें उन दस क्रिप्टोकरेंसी के दैनिक यूएसडी मूल्य शामिल हैं जिनका हम सत्यापन कर रहे हैं।
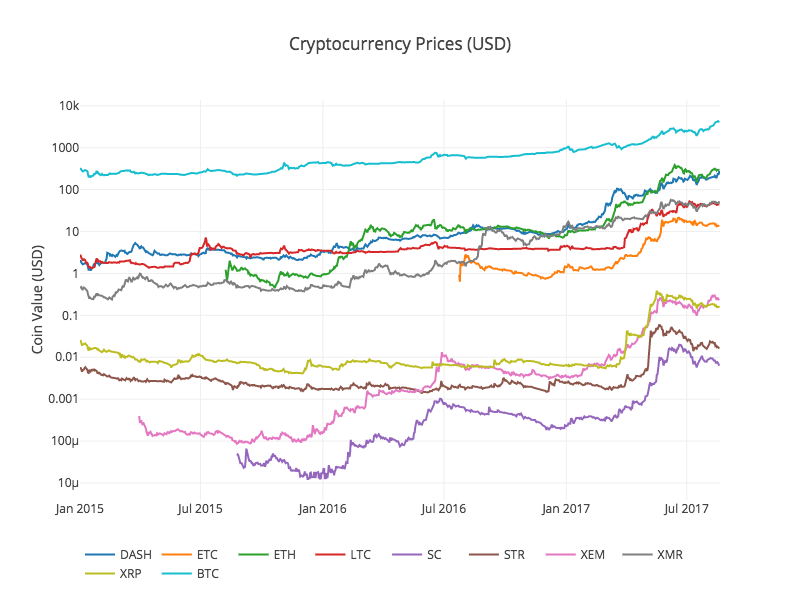
हम चार्ट के रूप में सभी altcoins की संबंधित कीमतों को प्रदर्शित करने के लिए पिछले फ़ंक्शन df_scatter को फिर से कॉल करते हैं।
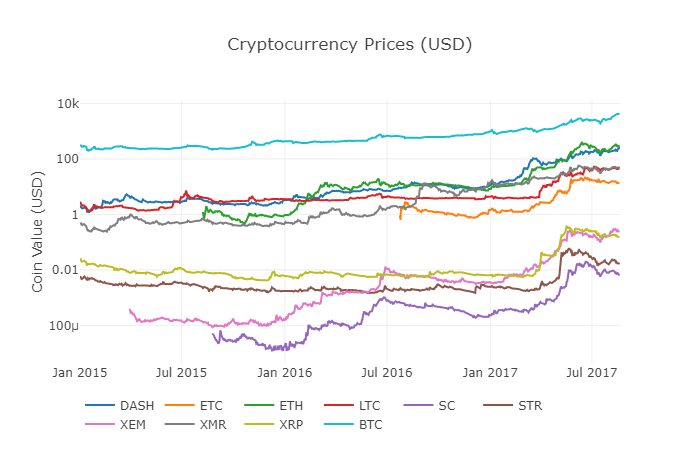
चार्ट अच्छा दिखता है, और यह हमें पूरी तस्वीर देता है कि पिछले कुछ वर्षों में प्रत्येक क्रिप्टोकरेंसी का विनिमय मूल्य कैसे बदला है।
नोट: यहां हमने एक ही ग्राफ पर सभी क्रिप्टोकरेंसी की तुलना करने के लिए लघुगणक y-अक्ष का उपयोग किया है। आप डेटा को विभिन्न दृष्टिकोणों से समझने के लिए विभिन्न पैरामीटर मान (जैसे स्केल='रैखिक') भी आज़मा सकते हैं।
3.4 सहसंबंध विश्लेषण प्रारंभ करें
सावधान पाठकों ने देखा होगा कि डिजिटल मुद्राओं की कीमतें परस्पर संबंधित प्रतीत होती हैं, भले ही उनके मौद्रिक मूल्य व्यापक रूप से भिन्न होते हैं और अत्यधिक अस्थिर होते हैं। विशेषकर अप्रैल 2017 में आई तीव्र वृद्धि के बाद से, कई छोटे उतार-चढ़ाव भी पूरे बाजार के उतार-चढ़ाव के साथ तालमेल बिठाते हुए प्रतीत होते हैं।
निस्संदेह, आंकड़ों द्वारा समर्थित निष्कर्ष, छवियों पर आधारित अंतर्ज्ञान की तुलना में अधिक विश्वसनीय होते हैं।
हम उपरोक्त सहसंबंध परिकल्पना को सत्यापित करने के लिए पांडा corr() फ़ंक्शन का उपयोग कर सकते हैं। यह परीक्षण डेटा फ्रेम के प्रत्येक कॉलम के लिए अन्य प्रत्येक कॉलम के साथ पियर्सन सहसंबंध गुणांक की गणना करता है।
2017.8.22 संशोधन नोट: सहसंबंध गुणांक की गणना करते समय निरपेक्ष कीमतों के बजाय दैनिक रिटर्न का उपयोग करने के लिए इस अनुभाग को संशोधित किया गया था।
गैर-ठोस समय श्रृंखला (जैसे कि कच्चे मूल्य डेटा) पर आधारित प्रत्यक्ष गणना से सहसंबंध गुणांक में विचलन हो सकता है। इस समस्या का हमारा समाधान pct_change() विधि का उपयोग करके डेटा फ्रेम में प्रत्येक मूल्य के निरपेक्ष मान को संबंधित दैनिक रिटर्न दर में परिवर्तित करना है।
उदाहरण के लिए, आइए 2016 के लिए सहसंबंध गुणांक की गणना करें।
# 计算2016年数字货币的皮尔森相关系数
combined_df_2016 = combined_df[combined_df.index.year == 2016]
combined_df_2016.pct_change().corr(method='pearson')
| Name | DASH | ETC | ETH | LTC | SC | STR | XEM | XMR | XRP | BTC |
|---|---|---|---|---|---|---|---|---|---|---|
| DASH | 1.000000 | 0.003992 | 0.122695 | -0.012194 | 0.026602 | 0.058083 | 0.014571 | 0.121537 | 0.088657 | -0.014040 |
| ETC | 0.003992 | 1.000000 | -0.181991 | -0.131079 | -0.008066 | -0.102654 | -0.080938 | -0.105898 | -0.054095 | -0.170538 |
| ETH | 0.122695 | -0.181991 | 1.000000 | -0.064652 | 0.169642 | 0.035093 | 0.043205 | 0.087216 | 0.085630 | -0.006502 |
| LTC | -0.012194 | -0.131079 | -0.064652 | 1.000000 | 0.012253 | 0.113523 | 0.160667 | 0.129475 | 0.053712 | 0.750174 |
| SC | 0.026602 | -0.008066 | 0.169642 | 0.012253 | 1.000000 | 0.143252 | 0.106153 | 0.047910 | 0.021098 | 0.035116 |
| STR | 0.058083 | -0.102654 | 0.035093 | 0.113523 | 0.143252 | 1.000000 | 0.225132 | 0.027998 | 0.320116 | 0.079075 |
| XEM | 0.014571 | -0.080938 | 0.043205 | 0.160667 | 0.106153 | 0.225132 | 1.000000 | 0.016438 | 0.101326 | 0.227674 |
| XMR | 0.121537 | -0.105898 | 0.087216 | 0.129475 | 0.047910 | 0.027998 | 0.016438 | 1.000000 | 0.027649 | 0.127520 |
| XRP | 0.088657 | -0.054095 | 0.085630 | 0.053712 | 0.021098 | 0.320116 | 0.101326 | 0.027649 | 1.000000 | 0.044161 |
| BTC | -0.014040 | -0.170538 | -0.006502 | 0.750174 | 0.035116 | 0.079075 | 0.227674 | 0.127520 | 0.044161 | 1.000000 |
उपरोक्त ग्राफ सहसंबंध गुणांक दर्शाता है। 1 या -1 के करीब गुणांक का मतलब है कि अनुक्रम क्रमशः सकारात्मक रूप से सहसंबंधित या व्युत्क्रम रूप से सहसंबंधित है। 0 के करीब सहसंबंध गुणांक का मतलब है कि संबंधित वस्तुएं सहसंबंधित नहीं हैं और उनके उतार-चढ़ाव एक दूसरे से स्वतंत्र हैं।
परिणामों को बेहतर ढंग से देखने के लिए, हम एक नया विज़ुअलाइज़ेशन सहायक फ़ंक्शन बनाते हैं।
def correlation_heatmap(df, title, absolute_bounds=True):
'''Plot a correlation heatmap for the entire dataframe'''
heatmap = go.Heatmap(
z=df.corr(method='pearson').as_matrix(),
x=df.columns,
y=df.columns,
colorbar=dict(title='Pearson Coefficient'),
)
layout = go.Layout(title=title)
if absolute_bounds:
heatmap['zmax'] = 1.0
heatmap['zmin'] = -1.0
fig = go.Figure(data=[heatmap], layout=layout)
py.iplot(fig)
correlation_heatmap(combined_df_2016.pct_change(), "Cryptocurrency Correlations in 2016")
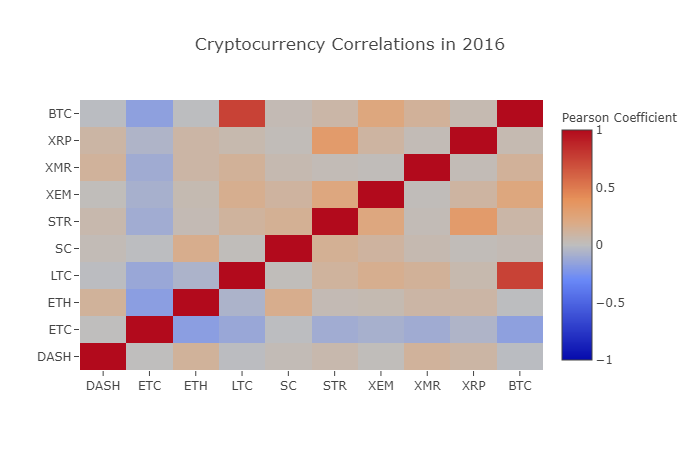
यहां, गहरे लाल रंग के मान मजबूत सहसंबंध का प्रतिनिधित्व करते हैं (प्रत्येक सिक्का स्पष्ट रूप से अपने आप से अत्यधिक सहसंबंधित है), और गहरे नीले रंग के मान व्युत्क्रम सहसंबंध का प्रतिनिधित्व करते हैं। बीच के सभी रंग - हल्का नीला/नारंगी/ग्रे/भूरा - के मान अलग-अलग डिग्री के कमजोर सहसंबंध या बिना सहसंबंध को दर्शाते हैं।
यह चित्र हमें क्या बताता है? बुनियादी स्तर पर, यह दर्शाता है कि 2016 में विभिन्न क्रिप्टोकरेंसी की कीमतों में उतार-चढ़ाव आया, जिसमें सांख्यिकीय रूप से महत्वपूर्ण सहसंबंध बहुत कम था।
अब, अपनी परिकल्पना को सत्यापित करने के लिए कि "क्रिप्टोकरेंसी हाल के महीनों में अधिक सहसंबद्ध हो गई हैं", हम 2017 के डेटा का उपयोग करके उसी परीक्षण को दोहराएंगे।
combined_df_2017 = combined_df[combined_df.index.year == 2017]
combined_df_2017.pct_change().corr(method='pearson')
| Name | DASH | ETC | ETH | LTC | SC | STR | XEM | XMR | XRP | BTC |
|---|---|---|---|---|---|---|---|---|---|---|
| DASH | 1.000000 | 0.384109 | 0.480453 | 0.259616 | 0.191801 | 0.159330 | 0.299948 | 0.503832 | 0.066408 | 0.357970 |
| ETC | 0.384109 | 1.000000 | 0.602151 | 0.420945 | 0.255343 | 0.146065 | 0.303492 | 0.465322 | 0.053955 | 0.469618 |
| ETH | 0.480453 | 0.602151 | 1.000000 | 0.286121 | 0.323716 | 0.228648 | 0.343530 | 0.604572 | 0.120227 | 0.421786 |
| LTC | 0.259616 | 0.420945 | 0.286121 | 1.000000 | 0.296244 | 0.333143 | 0.250566 | 0.439261 | 0.321340 | 0.352713 |
| SC | 0.191801 | 0.255343 | 0.323716 | 0.296244 | 1.000000 | 0.417106 | 0.287986 | 0.374707 | 0.248389 | 0.377045 |
| STR | 0.159330 | 0.146065 | 0.228648 | 0.333143 | 0.417106 | 1.000000 | 0.396520 | 0.341805 | 0.621547 | 0.178706 |
| XEM | 0.299948 | 0.303492 | 0.343530 | 0.250566 | 0.287986 | 0.396520 | 1.000000 | 0.397130 | 0.270390 | 0.366707 |
| XMR | 0.503832 | 0.465322 | 0.604572 | 0.439261 | 0.374707 | 0.341805 | 0.397130 | 1.000000 | 0.213608 | 0.510163 |
| XRP | 0.066408 | 0.053955 | 0.120227 | 0.321340 | 0.248389 | 0.621547 | 0.270390 | 0.213608 | 1.000000 | 0.170070 |
| BTC | 0.357970 | 0.469618 | 0.421786 | 0.352713 | 0.377045 | 0.178706 | 0.366707 | 0.510163 | 0.170070 | 1.000000 |
क्या ये आंकड़े अधिक प्रासंगिक हैं? क्या यह निवेश के लिए एक मानदंड के रूप में पर्याप्त है? इसका उत्तर है, नहीं।
हालांकि, यह ध्यान देने योग्य है कि लगभग सभी क्रिप्टोकरेंसी तेजी से आपस में जुड़ गई हैं।
correlation_heatmap(combined_df_2017.pct_change(), "Cryptocurrency Correlations in 2017")
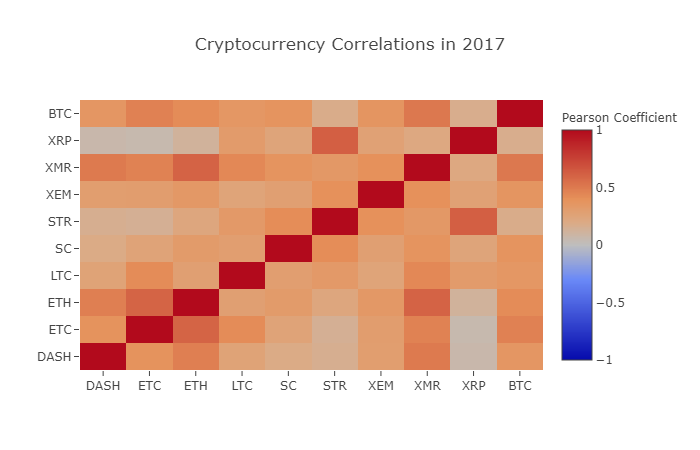
जैसा कि आप ऊपर दिए गए चित्र में देख सकते हैं, चीज़ें दिन-प्रतिदिन दिलचस्प होती जा रही हैं।
ऐसा क्यूँ होता है?
अच्छा प्रश्न! लेकिन सच तो यह है कि मैं इस बात पर निश्चित नहीं हूं...
मेरी पहली प्रतिक्रिया यह थी कि हेज फंडों ने हाल ही में क्रिप्टोकरेंसी बाज़ार में सार्वजनिक रूप से व्यापार करना शुरू कर दिया है। ये फंड औसत व्यापारी की तुलना में बहुत अधिक पूंजी रखते हैं। यदि कोई फंड अपनी निवेश पूंजी को कई क्रिप्टोकरेंसी के बीच हेज करता है और फिर एक स्वतंत्र चर (जैसे, शेयर बाजार) के आधार पर प्रत्येक मुद्रा के लिए समान जोखिम कारकों का उपयोग करता है, तो यह अधिक लाभदायक होगा। ट्रेडिंग रणनीतियाँ. यदि इस परिप्रेक्ष्य से देखा जाए तो बढ़ते सहसंबंध की प्रवृत्ति समझ में आती है।
XRP और STR की गहन समझ
उदाहरण के लिए, उपरोक्त चार्ट से यह स्पष्ट है कि XRP (रिपल का टोकन) अन्य क्रिप्टोकरेंसी के साथ सबसे कम सहसंबंधित है। लेकिन यहां एक उल्लेखनीय अपवाद एसटीआर (स्टेलर का टोकन, जिसे आधिकारिक तौर पर "ल्यूमेन्स" कहा जाता है) है, जिसका एक्सआरपी (सहसंबंध गुणांक: 0.62) के साथ एक मजबूत सहसंबंध है।
दिलचस्प बात यह है कि स्टेलर और रिपल बहुत ही समान फिनटेक प्लेटफॉर्म हैं, जिनका उद्देश्य सीमाओं के पार बैंकों के बीच धन हस्तांतरण में शामिल बोझिल चरणों को कम करना है। यह कल्पना की जा सकती है कि ब्लॉकचेन सेवाओं द्वारा उपयोग किए जाने वाले टोकनों की समानता को देखते हुए, कुछ बड़े खिलाड़ी और हेज फंड स्टेलर और रिपल में अपने निवेश के लिए समान व्यापारिक रणनीतियों का उपयोग कर सकते हैं। शायद यही कारण है कि XRP का अन्य क्रिप्टोकरेंसी की तुलना में STR के साथ अधिक मजबूत संबंध है।
ठीक है, अब आपकी बारी है!
उपरोक्त स्पष्टीकरण काफी हद तक काल्पनिक हैं, और हो सकता है कि आप बेहतर कर सकें। हमने जो नींव रखी है, उस पर निर्माण करते हुए, ऐसे सैकड़ों अलग-अलग तरीके हैं जिनसे आप अपने डेटा में कहानियों का अन्वेषण जारी रख सकते हैं।
पाठकों के लिए अपने शोध दिशा में विचार करने हेतु मेरे कुछ सुझाव यहां दिए गए हैं:
- समग्र विश्लेषण में अधिक क्रिप्टोकरेंसी पर डेटा जोड़ना
- प्रवृत्तियों के परिष्कृत या मोटे तौर पर दृश्य प्राप्त करने के लिए सहसंबंध विश्लेषण की समय सीमा और बारीकियों को समायोजित करें।
- लेन-देन की मात्रा या ब्लॉकचेन डेटा माइनिंग में रुझान का पता लगाएं। यदि आप भविष्य में मूल्य में उतार-चढ़ाव का पूर्वानुमान लगाना चाहते हैं, तो आपको कच्चे मूल्य डेटा की तुलना में खरीद/बिक्री मात्रा अनुपात डेटा की अधिक आवश्यकता हो सकती है।
- स्टॉक, कमोडिटीज और फिएट करेंसी पर मूल्य डेटा जोड़ें ताकि यह निर्धारित किया जा सके कि उनमें से कौन सी क्रिप्टोकरेंसी के साथ सहसंबंधित हैं (लेकिन पुरानी कहावत याद रखें "सहसंबंध का मतलब कार्य-कारण नहीं है")
- किसी विशेष क्रिप्टोकरेंसी के बारे में "हॉट वर्ड्स" की संख्या निर्धारित करने के लिए इवेंट रजिस्ट्री, जीडीईएलटी और गूगल ट्रेंड्स का उपयोग करें।
- कल की कीमत का अनुमान लगाने के लिए एक पूर्वानुमान मशीन लर्निंग मॉडल को प्रशिक्षित करने के लिए डेटा का उपयोग करें। यदि आप अधिक महत्वाकांक्षी महसूस कर रहे हैं, तो आप रिकरंट न्यूरल नेटवर्क (आरएनएन) के साथ उपरोक्त प्रशिक्षण करने का प्रयास करने पर भी विचार कर सकते हैं।
- अपने विश्लेषण का उपयोग एक स्वचालित ट्रेडिंग बॉट बनाने के लिए करें जिसका उपयोग संबंधित एप्लिकेशन प्रोग्रामिंग इंटरफ़ेस (एपीआई) के माध्यम से "पोलोनीक्स" या "कॉइनबेस" जैसी एक्सचेंज वेबसाइटों पर किया जा सकता है। सावधान रहें: खराब प्रदर्शन करने वाला बॉट आपकी संपत्ति को आसानी से एक पल में मिटा सकता है। आविष्कारक के मात्रात्मक मंच FMZ.COM का उपयोग करने की अनुशंसा की जाती है।
बिटकॉइन और सामान्य रूप से डिजिटल मुद्राओं के बारे में सबसे अच्छी बात यह है कि उनकी विकेन्द्रीकृत प्रकृति है, जो इसे किसी भी अन्य परिसंपत्ति की तुलना में अधिक स्वतंत्र और लोकतांत्रिक बनाती है। अपने विश्लेषण को खुले स्रोत के रूप में साझा करें, समुदाय में शामिल हों, या एक ब्लॉग पोस्ट लिखें! उम्मीद है कि अब आपके पास अपना स्वयं का विश्लेषण करने के लिए आवश्यक कौशल हैं और आप भविष्य में पढ़े जाने वाले किसी भी सट्टा क्रिप्टोकरेंसी लेख के बारे में गंभीरता से सोचने में सक्षम होंगे, विशेष रूप से उन भविष्यवाणियों के बारे में जो डेटा द्वारा समर्थित नहीं हैं। पढ़ने के लिए धन्यवाद। यदि आपके पास इस ट्यूटोरियल के बारे में कोई टिप्पणी, सुझाव या आलोचना है, तो कृपया https://www.fmz.com/bbs पर एक संदेश छोड़ें।

- 1