
Penjelasan lengkap tentang kelebihan dan kekurangan tiga kategori utama dan enam algoritma utama pembelajaran mesin
Dalam pembelajaran mesin, tujuannya adalah untuk memprediksi (prediction) atau untuk mengelompokkan (clustering). Pada artikel ini, kita akan membahas tentang prediksi. Prediksi adalah proses untuk memperkirakan nilai variabel output dari sekumpulan variabel input. Sebagai contoh, kita dapat memprediksi harga jual dari sekumpulan karakteristik tentang sebuah rumah.
Setelah memahami hal ini, mari kita lihat algoritma yang paling menonjol dan paling sering digunakan dalam pembelajaran mesin. Kami membagi algoritma ini menjadi 3 kategori: model linier, model berbasis pohon, dan jaringan neural, dengan fokus pada 6 algoritma yang paling sering digunakan:
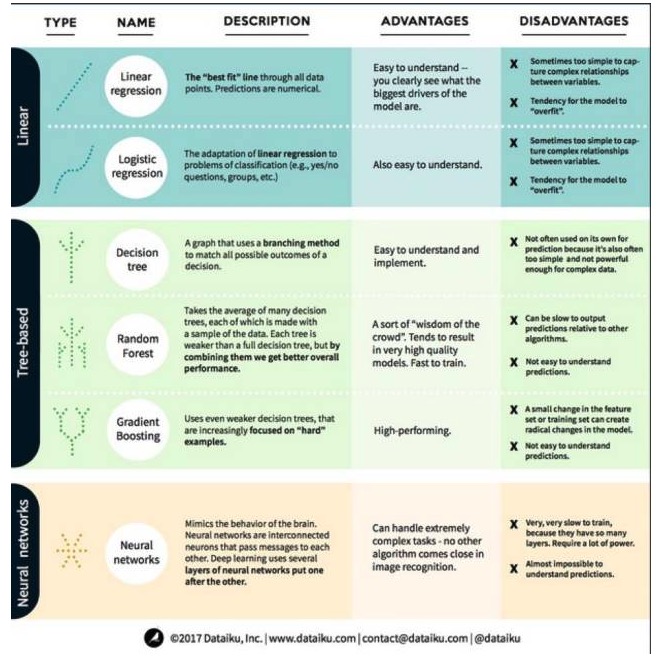
Algoritma model linier: model linier menggunakan rumus sederhana untuk menemukan baris yang paling cocok dengan satu set titik data. Metode ini dapat ditelusuri lebih dari 200 tahun yang lalu dan telah banyak digunakan di bidang statistik dan pembelajaran mesin.
-
1. Regresi linier
Regressi linier, atau lebih tepatnya regresi dua kali lipat minimal, adalah bentuk paling standar dari model linier. Regressi linier adalah model linier yang paling sederhana untuk masalah regresi. Kekurangannya adalah bahwa model mudah overadaptasi, yaitu, model sepenuhnya beradaptasi dengan data yang telah dilatih, dengan mengorbankan kemampuan untuk menyebarkan ke data baru. Oleh karena itu, regresi linier dalam pembelajaran mesin (dan juga regresi logis yang akan kita bicarakan di bawah ini) biasanya berupa simulasi yang tepat, yang berarti bahwa model memiliki hukuman tertentu untuk mencegah overadaptasi.
Kelemahan lain dari model linier adalah bahwa karena mereka sangat sederhana, mereka tidak dapat dengan mudah memprediksi perilaku yang lebih kompleks ketika input variabel tidak independen.
-
Regressi Logis 2.
Regresi logis adalah adaptasi regresi linier untuk masalah klasifikasi. Regresi logis memiliki kelemahan yang sama dengan regresi linier. Fungsi logis sangat baik untuk masalah klasifikasi karena memperkenalkan efek threshold.
Dua, algoritma model pohon
-
1. Pohon Keputusan
Pohon keputusan adalah diagram yang menggunakan metode percabangan untuk menunjukkan setiap hasil yang mungkin dari keputusan. Misalnya, Anda memutuskan untuk memesan salad, dan keputusan pertama Anda mungkin adalah jenis sayur, kemudian hidangan, dan kemudian jenis salad. Kita dapat menunjukkan semua hasil yang mungkin dalam satu pohon keputusan.
Untuk melatih pohon keputusan, kita perlu menggunakan set data pelatihan dan mencari atribut yang paling berguna untuk tujuan. Misalnya, dalam kasus penggunaan deteksi penipuan, kita mungkin menemukan bahwa atribut yang paling berpengaruh terhadap prediksi risiko penipuan adalah negara. Setelah melakukan pembagian dengan atribut pertama, kita mendapatkan dua subset, yang paling dapat diprediksi dengan akurat jika kita hanya tahu atribut pertama.
-
2. Hutan acak
Hutan acak adalah rata-rata dari banyak pohon keputusan, di mana setiap pohon keputusan dilatih dengan sampel data acak. Setiap pohon di hutan acak lebih lemah dari pohon keputusan yang utuh, tetapi menempatkan semua pohon bersama-sama, kita bisa mendapatkan kinerja keseluruhan yang lebih baik karena keunggulan keragaman.
Hutan acak adalah algoritma yang sangat populer dalam pembelajaran mesin saat ini. Hutan acak mudah dilatih dan berkinerja cukup baik. Kekurangannya adalah bahwa perkiraan output hutan acak mungkin lambat dibandingkan dengan algoritma lain, sehingga mungkin tidak memilih hutan acak ketika perkiraan cepat diperlukan.
-
3. Tingkatkan
Peningkatan gradien, seperti hutan acak, juga terdiri dari pohon keputusan yang lemah dan lemah. Perbedaan terbesar antara peningkatan gradien dan hutan acak adalah bahwa dalam peningkatan gradien, pohon dilatih satu demi satu.
Pelatihan untuk meningkatkan gradien juga sangat cepat dan berkinerja sangat baik. Namun, perubahan kecil pada set data pelatihan dapat menyebabkan perubahan mendasar pada model, sehingga hasil yang dihasilkan mungkin bukan yang paling layak.
Jaringan saraf adalah fenomena biologis yang terdiri dari neuron yang saling berhubungan dalam otak untuk bertukar informasi satu sama lain. Gagasan ini sekarang diterapkan pada bidang pembelajaran mesin, yang disebut ANN (artificial neural network). Pembelajaran mendalam adalah jaringan saraf berlapis yang saling bertumpuk.
Dikutip dari Big Data Land
- 1