Mesin vektor pendukung di otak
 0
2106
0
2106
Mesin vektor pendukung di otak
Support Vector Machine (SVM) adalah klasifikasi pembelajaran mesin yang penting, yang menggunakan transformasi non-linear yang cerdik untuk memproyeksikan karakteristik dimensi rendah ke dimensi tinggi, yang dapat melakukan tugas klasifikasi yang lebih kompleks. SWM tampaknya menggunakan trik matematika, tetapi kebetulan sesuai dengan mekanisme pengkodean otak, yang dapat kita baca dari sebuah makalah Nature tahun 2013 untuk memahami hubungan mendalam antara pembelajaran mesin dan prinsip kerja otak. Judul artikel: The importance of mixed selectivity in complex cognitive tasks (by Omri Barak al. )
- #### SVM
Dari mana kita bisa melihat hubungan yang luar biasa ini? Pertama kita bicara tentang sifat dari neurokoding: hewan menerima sinyal tertentu dan melakukan tindakan tertentu berdasarkannya, salah satunya adalah mengubah sinyal eksternal menjadi sinyal elektro-neural, yang lainnya adalah mengubah sinyal elektro-neural menjadi sinyal keputusan, proses sebelumnya disebut pengkodean, proses selanjutnya disebut dekodean. Dan tujuan sebenarnya dari neurokoding adalah untuk kemudian melakukan dekodean untuk membuat keputusan. Oleh karena itu, dengan menggunakan mata untuk melihat kode pembelajaran mesin, cara termudah untuk melakukannya adalah dengan melihat klasifikasi, bahkan klasifikasi linier dari model logistic, untuk memasukkan sinyal masuk ke dalam klasifikasi berdasarkan karakteristik tertentu.
Jadi mari kita lihat bagaimana neuron dikodekan. Pertama, neuron dapat dilihat sebagai sebuah sirkuit RC yang menyesuaikan resistansi dan kapasitansinya dengan tegangan eksternal. Jika sinyal eksternal cukup besar, sinyal akan diarahkan, jika tidak, sinyal akan ditutup.
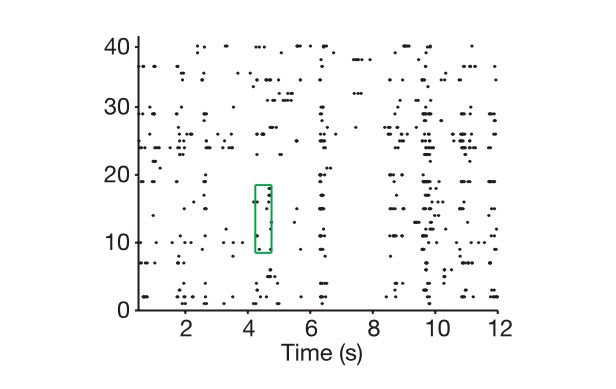
Gambar: Sel di sisi kanan, waktu di sisi kiri, menunjukkan bagaimana kita mengambil kode saraf.
Tentu saja ada perbedaan antara dimensi nyata dari N-dimensional vector dan neurokode, bagaimana mendefinisikan dimensi nyata dari neurokode? Pertama, kita masuk ke dalam ruang N-dimensional yang ditandai dengan N-dimensional vector, lalu kita memberikan semua kombinasi tugas yang mungkin, seperti menunjukkan kepada Anda seribu gambar, misalkan gambar-gambar ini mewakili seluruh dunia, dan setiap neurokode yang kita dapatkan ditandai sebagai satu titik di ruang ini, dan akhirnya kita menggunakan pemikiran aljabar vektor untuk melihat dimensi dari ruang-ruang kecil yang terdiri dari seribu titik, yang dikenal sebagai dimensi nyata dari representasi saraf.
Selain dimensi sebenarnya dari kode, kita juga memiliki konsep yang lain yaitu dimensi sebenarnya dari sinyal eksternal, di mana sinyal adalah sinyal eksternal yang diekspresikan oleh jaringan saraf, tentu saja Anda harus mengulangi semua detail dari sinyal eksternal itu adalah masalah yang tak terbatas, namun dasar dari klasifikasi dan keputusan kita selalu merupakan karakteristik kunci, sebuah proses redimensionalisasi, dan itu juga adalah gagasan dari PCA. Di sini kita bisa melihat variabel kunci dalam tugas nyata sebagai dimensi sebenarnya dari tugas, misalnya Anda ingin mengontrol gerakan lengan, Anda biasanya hanya perlu mengontrol sudut putaran sendi, jika Anda menganggapnya sebagai masalah dinamika solid, dimensi mungkin tidak akan lebih dari 10, kita sebut K. Bahkan jika itu adalah masalah untuk membedakan wajah seperti ini, dimensi masalah masih jauh lebih rendah dari jumlah sel saraf individu.
Jadi, para ilmuwan menghadapi pertanyaan utama, mengapa menggunakan dimensi koding dan jumlah neuron yang jauh lebih besar daripada masalah yang sebenarnya?
Neuroscience komputasi dan pembelajaran mesin bersama-sama memberi tahu kita bahwa sifat-sifat dimensi tinggi dari representasi neural adalah dasar dari kemampuan belajar yang kuat. Perhatikan di sini bahwa kita bahkan tidak mulai melibatkan jaringan kedalaman.
Perhatikan bahwa pengkodean saraf yang dibahas di sini terutama mengacu pada pengkodean saraf pusat saraf yang lebih tinggi, seperti Prefrontal Cortex (PFC) yang dibahas dalam artikel ini, karena aturan pengkodean pusat saraf tingkat rendah tidak terlalu terlibat dalam klasifikasi dan pengambilan keputusan.
Bagian otak yang lebih tinggi yang diwakili oleh PFC
Pertama, kita asumsikan bahwa kita tidak akan dapat menangani masalah klasifikasi non-linear dengan menggunakan klasifikasi linier ketika dimensi pengkodean kita sama dengan dimensi variabel kunci dalam tugas nyata (misalnya, jika Anda ingin memisahkan melon dari melon, Anda tidak dapat memisahkan melon dari melon dengan batas linier), yang juga merupakan masalah khas yang sulit untuk kita selesaikan ketika pembelajaran mendalam dan SVM tidak masuk ke dalam pembelajaran mesin.
SVM ((support vector machine):
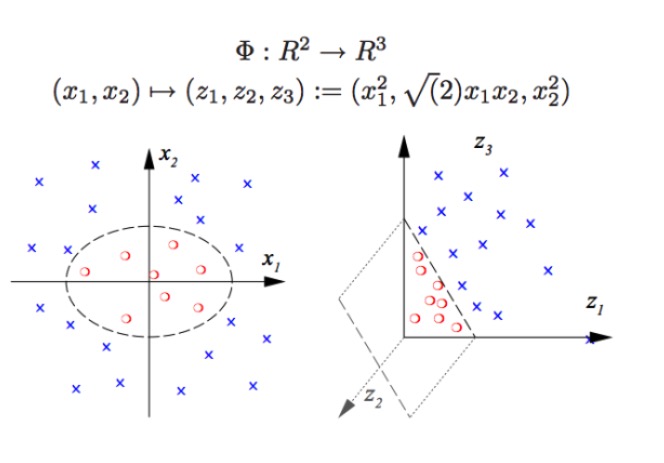
SVM dapat melakukan klasifikasi non-linear, misalnya memisahkan titik merah dan titik biru dalam gambar, dengan batas linier kita tidak dapat memisahkan titik merah dan titik biru (gambar kiri), sehingga cara SVM digunakan adalah meningkatkan dimensi. Namun, hanya menambahkan bilangan variabel tidak dapat dilakukan, seperti memetakan (x1, x2) ke (x1, x2, x1 + x2) Sistem sebenarnya adalah ruang linier dua dimensi (gambar individu adalah titik merah dan titik biru berada di satu bidang), hanya menggunakan fungsi non-linear (x1 ^ 2, x1)*x2, x2^2) kita akan memiliki transisi dari dimensi rendah ke dimensi tinggi, dan saat ini Anda akan melemparkan titik biru ke udara, dan kemudian Anda akan menggambar sebuah bidang di udara yang akan memisahkan titik biru dari titik merah, seperti gambar di sebelah kanan.
Pada kenyataannya, apa yang dilakukan oleh jaringan neural yang sebenarnya adalah hal yang serupa. Dengan adanya klasifikasi yang dilakukan oleh klasifikasi linear seperti decoder, kita mendapatkan kemampuan untuk mengenali pola yang jauh lebih baik daripada sebelumnya. Di sini, dimensi tinggi berarti energi tinggi, dan pukulan dimensi tinggi adalah kebenaran.
Jadi, bagaimana kita mendapatkan kode neuron yang berdimensi tinggi? Tidak ada gunanya memiliki banyak neuron optik. Karena kita tahu dari aljabar linier bahwa jika kita memiliki banyak neuron N, dan masing-masing memiliki tingkat pelepasan yang hanya terkait secara linier dengan K fitur kunci, maka dimensi yang kita representasi akhirnya hanya akan sama dengan dimensi masalah itu sendiri, Anda tidak memiliki N neuron yang tidak berfungsi (N yang keluar adalah kombinasi linier dari K neuron). Untuk memecahkannya, Anda harus memiliki neuron yang terkait secara non-linear dengan K fitur, yang disebut neuron hibrida non-linear.
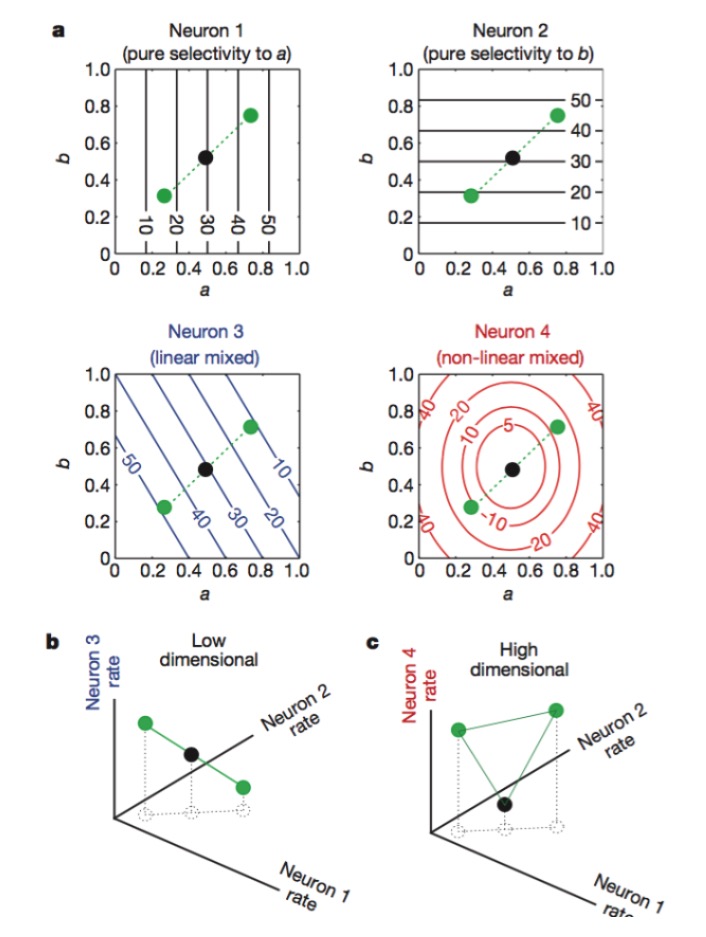
Gambar: Neuron 1 dan 2 hanya sensitif terhadap ciri-ciri a dan b, 3 terhadap campuran linier ciri-ciri a dan b, dan 4 terhadap campuran non-linier ciri-ciri. Pada akhirnya hanya kombinasi neuron 1, 2, dan 4 yang meningkatkan dimensi pengkodean saraf.
Dalam sistem saraf sekitar, neuron berfungsi sebagai sensor untuk mengekstrak dan mengenali karakteristik sinyal yang berbeda. Fungsi masing-masing sel saraf cukup spesifik, seperti rods dan cones pada retina yang bertanggung jawab untuk menerima foton, dan kemudian sel Gangelion melanjutkan pengkodean, dan setiap neuron adalah seperti sentinel yang terlatih secara khusus. Di daerah otak yang lebih tinggi, pengkodean yang jelas ini sulit untuk dilihat, dan kami menemukan bahwa neuron yang sama mungkin sensitif terhadap berbagai karakteristik, dan ini bukan sensitivitas linier.
Setiap detail dari alam adalah sebuah latar belakang, banyak redundansi dan kode campuran yang tampaknya tidak profesional, sinyal yang tampak berantakan, akhirnya mendapatkan kemampuan komputasi yang lebih baik. Dengan prinsip ini, kita dapat dengan mudah menangani beberapa tugas seperti:
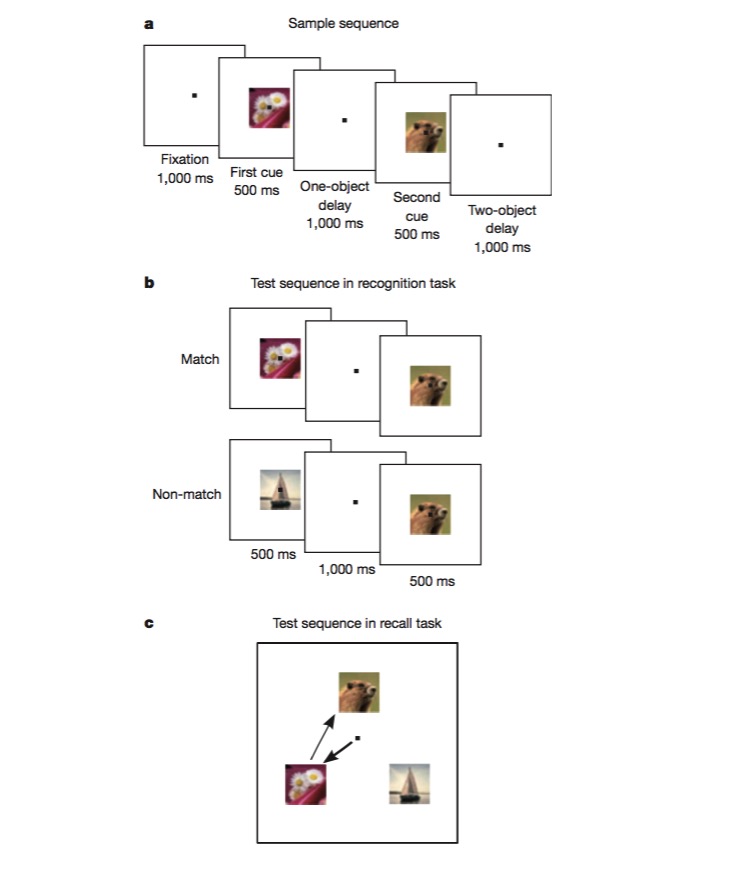
Dalam tugas ini, monyet pertama dilatih untuk membedakan apakah sebuah gambar sama dengan yang sebelumnya (recognition), kemudian dilatih untuk menilai urutan munculnya dua gambar yang berbeda (recall). Untuk menyelesaikan tugas seperti ini, monyet harus mampu mengkodekan berbagai sisi tugas, seperti jenis tugas (recall or recognition), jenis gambar, dan lain-lain, dan ini adalah tes yang sangat baik untuk menguji apakah ada mekanisme pengkodean non-linear campuran.
Setelah membaca artikel ini, kita tahu bahwa mendesain jaringan saraf akan meningkatkan kemampuan untuk mengenali pola dengan memasukkan beberapa unit non-linear, dan SVM justru menerapkan hal ini untuk mengatasi masalah klasifikasi non-linear.
Kami mempelajari fungsi dari area otak, pertama dengan menggunakan metode pembelajaran mesin untuk memproses data, misalnya dengan mencari dimensi kunci dari masalah dengan PCA, kemudian dengan pola pembelajaran mesin untuk mengenali pemikiran untuk memahami pengkodean dan dekodean saraf, dan akhirnya jika kita mendapat inspirasi baru, kita dapat memperbaiki metode pembelajaran mesin. Untuk otak atau algoritma pembelajaran mesin, yang paling penting adalah mendapatkan representasi informasi yang paling tepat, dan dengan representasi yang baik, semuanya menjadi lebih mudah.
Dikutip dari Xinhua, teknologi kapal perang