Tiga gambar untuk memahami pembelajaran mesin: konsep dasar, lima sekolah utama, dan sembilan algoritma umum
 0
2546
0
2546
Tiga gambar untuk memahami pembelajaran mesin: konsep dasar, lima sekolah utama, dan sembilan algoritma umum
- #### 1. Gambaran umum tentang pembelajaran mesin

Apa itu Pembelajaran Mesin?
Mesin belajar dengan menganalisis data dalam jumlah besar. Misalnya, mereka tidak perlu diprogram untuk mengenali kucing atau wajah manusia, mereka dapat dilatih menggunakan gambar untuk mengintegrasikan dan mengidentifikasi target tertentu.
Hubungan antara pembelajaran mesin dan kecerdasan buatan
Pembelajaran mesin (Machine learning) adalah sebuah bidang penelitian dan algoritma yang berfokus pada mencari pola dalam data dan menggunakan pola tersebut untuk membuat prediksi. Pembelajaran mesin adalah bagian dari bidang kecerdasan buatan (AI) dan bercampur dengan penemuan pengetahuan dan penambangan data.
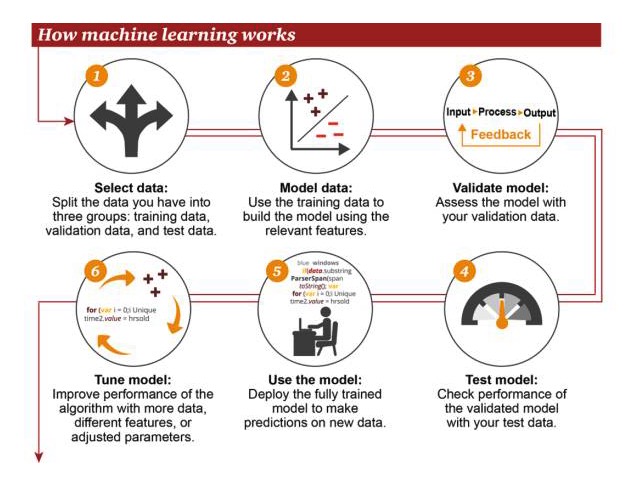
Cara Kerja Pembelajaran Mesin
1 Pilih data: bagi data Anda menjadi tiga kelompok: data pelatihan, data verifikasi, dan data pengujian 2 Data model: menggunakan data pelatihan untuk membangun model yang menggunakan fitur terkait 3 Validasi Model: Menggunakan data validasi Anda untuk mengakses model Anda 4 Model pengujian: Performa model yang telah diverifikasi dengan menggunakan data pengujian Anda 5 Menggunakan model: menggunakan model yang terlatih untuk membuat prediksi pada data baru 6 Model tuning: menggunakan lebih banyak data, karakteristik yang berbeda, atau parameter yang disesuaikan untuk meningkatkan kinerja algoritma
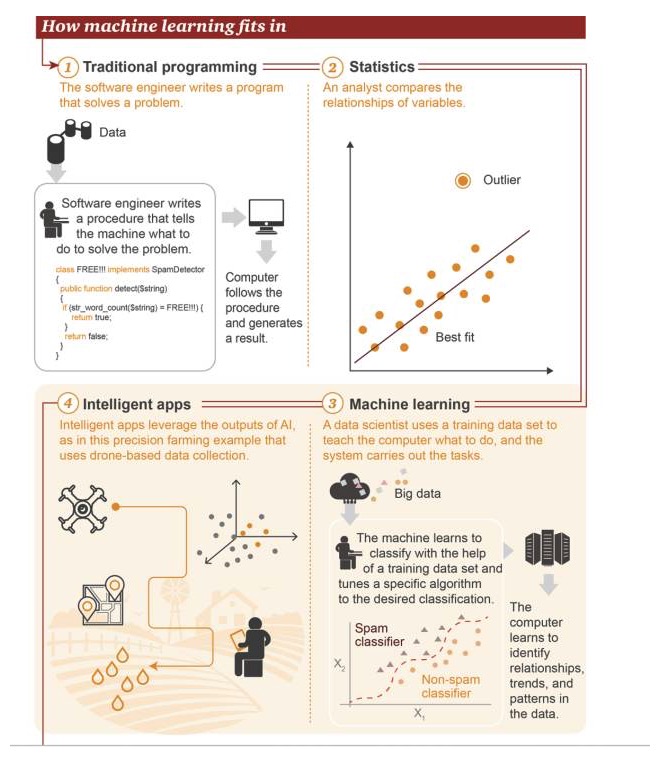
Di mana mesin belajar berada
1 Pemrograman tradisional: insinyur perangkat lunak menulis program untuk memecahkan masalah. Pertama, ada beberapa data→ Untuk memecahkan masalah, insinyur perangkat lunak menulis proses untuk memberi tahu mesin apa yang harus dilakukan→ Komputer mengikuti proses ini dan menghasilkan hasil 2 Statistik: Analis membandingkan hubungan antara variabel 3 Pembelajaran mesin: Ilmuwan data menggunakan set data pelatihan untuk mengajarkan komputer apa yang harus dilakukan, dan kemudian sistem melakukan tugas tersebut. Pertama ada data besar→ Mesin akan belajar menggunakan set data pelatihan untuk melakukan klasifikasi, menyesuaikan algoritma tertentu untuk mencapai tujuan klasifikasi→ Komputer dapat belajar mengenali hubungan, tren, dan pola dalam data 4 Aplikasi cerdas: Aplikasi cerdas yang menggunakan hasil dari kecerdasan buatan, seperti contoh aplikasi pertanian presisi yang didasarkan pada data yang dikumpulkan oleh drone

Aplikasi praktis dari pembelajaran mesin
Ada banyak skenario aplikasi untuk pembelajaran mesin, dan ini adalah beberapa contoh, bagaimana Anda akan menggunakannya?
Pemetaan dan Pemodelan 3D Cepat: Untuk membangun jembatan kereta api, ilmuwan data dan ahli bidang PwC menerapkan pembelajaran mesin pada data yang dikumpulkan oleh drone. Kombinasi ini memungkinkan pemantauan akurat dan umpan balik cepat atas keberhasilan pekerjaan.
Penguatan analisis untuk mengurangi risiko: Untuk mendeteksi transaksi internal, PwC menggabungkan pembelajaran mesin dengan teknik analisis lainnya, sehingga mengembangkan profil pengguna yang lebih komprehensif dan mendapatkan pemahaman yang lebih dalam tentang perilaku yang kompleks dan mencurigakan.
Prediksi Tujuan Terbaik: PwC menggunakan pembelajaran mesin dan metode analisis lainnya untuk menilai potensi berbagai kuda di Melbourne Cup.
- #### Kedua, evolusi pembelajaran mesin.

Selama beberapa dekade, “suku-suku” peneliti kecerdasan buatan telah bersaing satu sama lain untuk mendapatkan dominasi. Apakah sekarang saatnya bagi suku-suku ini untuk bersatu? Mereka mungkin harus melakukannya, karena kolaborasi dan penggabungan algoritma adalah satu-satunya cara untuk mencapai kecerdasan buatan universal yang benar-benar universal.
Lima Gaya Musik
1 Simbolisme: menggunakan simbol, aturan, dan logika untuk mewakili pengetahuan dan melakukan penalaran logis, algoritma favorit adalah: aturan dan pohon keputusan 2 Bayesian: mengambil probabilitas yang terjadi untuk melakukan inferensi probabilitas, algoritma yang paling disukai adalah: Bayesian polos atau Markov 3 Linkage: menggunakan probabilitas matriks dan neuron yang ditimbang untuk secara dinamis mengidentifikasi dan menginformasikan pola, algoritma favorit adalah: Jaringan saraf 4 Evolusi: menghasilkan perubahan, lalu mengambil yang terbaik untuk tujuan tertentu, algoritma favorit adalah: algoritma genetik 5 Analogizer: mengoptimalkan fungsi sesuai dengan kondisi yang terkandung ((pergilah setinggi mungkin, tetapi jangan keluar dari jalan), algoritma favorit adalah: mendukung mesin vektor
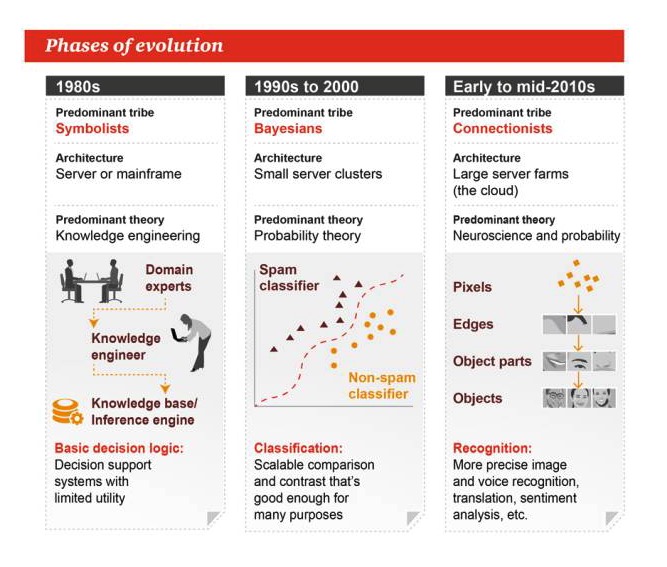
Tahap-tahap evolusi
Tahun 1980-an
Genre utama: Simbolisme Arsitektur: server atau komputer besar Teori utama: teknik pengetahuan Logika dasar pengambilan keputusan: sistem pendukung keputusan, praktis terbatas
Tahun 1990-an sampai tahun 2000
Genre utama: Bayes Arsitektur: Kluster server kecil Teori utama: Teori Probabilitas Klasifikasi: perbandingan atau kontras yang dapat diperluas, cukup baik untuk banyak tugas
Awal hingga pertengahan 2010
Genre yang dominan: Koalisi Arsitektur: sebuah peternakan server besar Teori utama: Neuroscience dan Probabilitas Identifikasi: Identifikasi gambar dan suara yang lebih akurat, terjemahan, analisis emosi, dll.
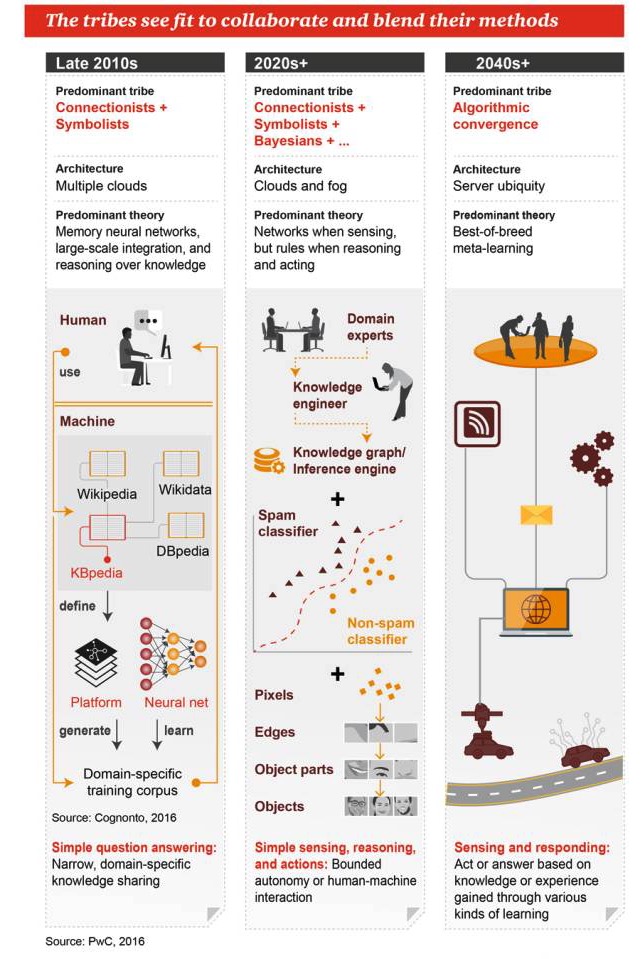
Grup-grup musik ini diharapkan dapat bekerja sama dan menggabungkan pendekatan mereka.
Akhir tahun 2010
Genre utama: Koalisi + Simbolisme Arsitektur: banyak awan Teori utama: jaringan saraf memori, integrasi massa, dan penalaran berdasarkan pengetahuan Pertanyaan dan Jawaban Sederhana: Berbagi Pengetahuan Terbatas dan Terspesifik
Tahun 2020+
Genre yang dominan: Koalisi + Simbolisme + Bayesianisme + … Arsitektur: komputasi awan dan komputasi kabut Teori dominan: ada jaringan ketika persepsi, ada aturan ketika penalaran dan pekerjaan Persepsi, penalaran, dan tindakan sederhana: keterbatasan otomatisasi atau interaksi manusia-mesin
2040-an +
Genre Dominan: Algoritma Bergabung Arsitektur: server di mana-mana Teori yang dominan: Metodologi pembelajaran yang optimal Persepsi dan respon: bertindak atau memberikan jawaban berdasarkan pengetahuan atau pengalaman yang diperoleh melalui berbagai cara belajar
- #### Ketiga, algoritma pembelajaran mesin.

Algoritma pembelajaran mesin apa yang harus Anda gunakan? Ini sangat tergantung pada sifat dan jumlah data yang tersedia dan tujuan pelatihan Anda dalam setiap kasus penggunaan tertentu. Jangan gunakan algoritma yang paling kompleks kecuali hasilnya layak untuk biaya dan sumber daya yang mahal.
Pohon Keputusan (Decision Tree): Dalam proses respons bertahap, analisis pohon keputusan yang khas menggunakan variabel bertingkat atau node keputusan, misalnya, dapat mengklasifikasikan pengguna yang diberikan sebagai kredibel atau tidak kredibel.
Keunggulan: Mampu mengevaluasi berbagai karakteristik, kualitas, dan karakteristik orang, tempat, dan benda Contoh skenario: penilaian kredit berdasarkan aturan, prediksi hasil balapan kuda
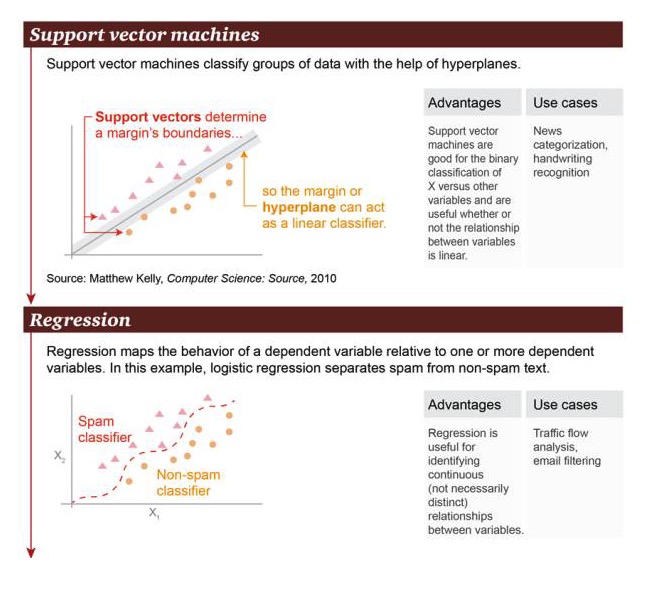
Support Vector Machine: Berdasarkan hyperplane, support vector machine dapat mengklasifikasikan kelompok data.
Keunggulan: mendukung mesin vektor yang mahir dalam melakukan operasi klasifikasi biner antara variabel X dan variabel lainnya, terlepas dari apakah hubungannya linear atau tidak Contoh skenario: Klasifikasi berita, pengenalan tulisan tangan.
Regression: Regression dapat menggambarkan hubungan status antara variabel faktor dengan satu atau lebih variabel faktor. Dalam contoh ini, perbedaan dibuat antara spam dan non-spam.
Keunggulan: Regresivitas dapat digunakan untuk mengidentifikasi hubungan kontinu antara variabel, bahkan jika hubungan ini tidak sangat jelas Contoh skenario: Analisis lalu lintas jalan, penyaringan email
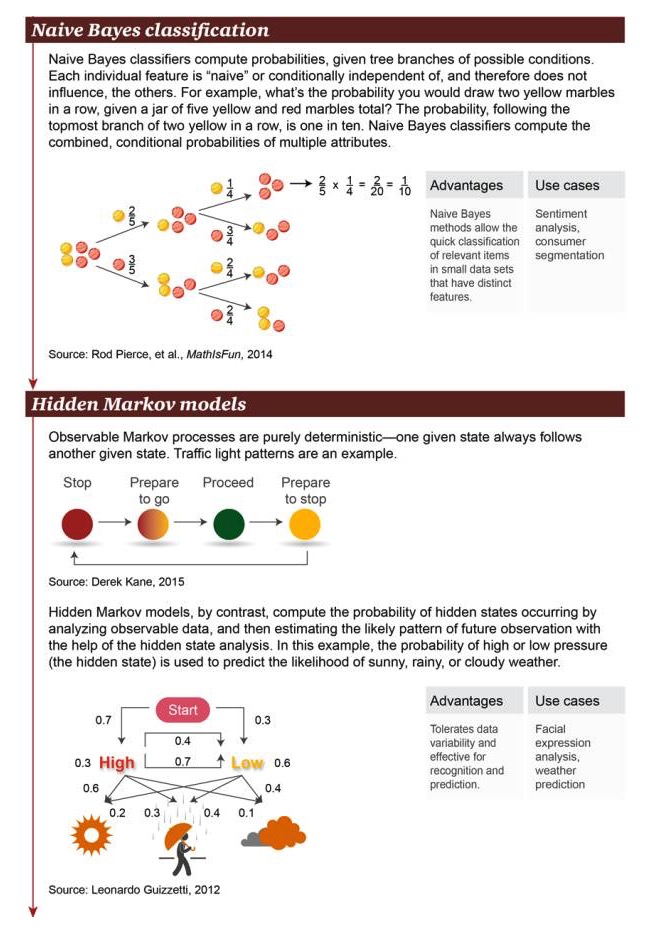
Klasifikasi Naif Bayes: Klasifikasi Naif Bayes digunakan untuk menghitung probabilitas cabang dari kemungkinan kondisi. Setiap karakteristik independen adalah “naif” atau kondisi independen, sehingga mereka tidak mempengaruhi objek lain. Misalnya, dalam sebuah kotak dengan total 5 bola kecil kuning dan merah, berapa probabilitas untuk mendapatkan dua bola kecil kuning berturut-turut?
Keunggulan: Untuk objek terkait yang memiliki karakteristik yang menonjol pada dataset kecil, metode Bayesian sederhana dapat diklasifikasikan dengan cepat Contoh skenario: analisis emosi, klasifikasi konsumen
Hidden Markov model: proses Markov yang menunjukkan kepastian mutlak bahwa suatu keadaan tertentu sering disertai dengan keadaan lain. Lampu lalu lintas adalah contohnya. Sebaliknya, model Markov yang tidak terlihat menghitung kejadian keadaan tersembunyi dengan menganalisis data yang terlihat.
Keunggulan: memungkinkan variabilitas data, cocok untuk operasi pengakuan dan prediksi Contoh skenario: analisis ekspresi wajah, ramalan cuaca
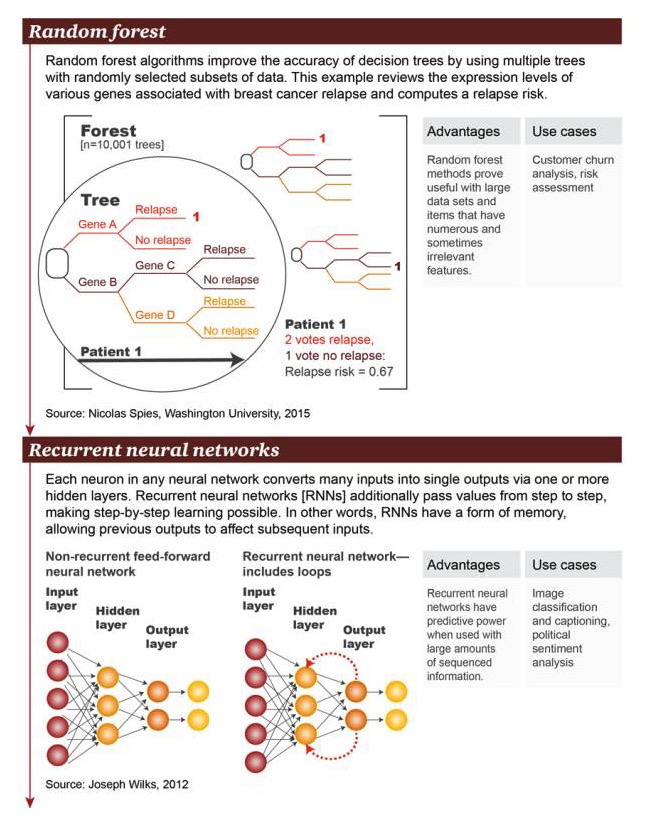
Hutan acak: Algoritma hutan acak meningkatkan akurasi pohon keputusan dengan menggunakan banyak subset data yang dipilih secara acak. Dalam contoh ini, banyak gen yang terkait dengan kekambuhan kanker payudara di tingkat ekspresi gen diperiksa dan risiko kekambuhan dihitung.
Keunggulan: Metode hutan acak terbukti berguna untuk dataset besar dan keberadaan banyak item dengan karakteristik yang kadang-kadang tidak terkait Contoh skenario: analisis aliran pengguna, penilaian risiko
Jaringan saraf berulang (recurrent neural network): Dalam jaringan saraf acak, setiap neuron mengubah banyak input menjadi satu output melalui 1 atau lebih lapisan tersembunyi. Jaringan saraf berulang (RNN) akan menyampaikan nilai lebih lanjut secara bertahap, sehingga pembelajaran bertahap dimungkinkan. Dengan kata lain, RNN memiliki semacam memori yang memungkinkan input sebelumnya untuk mempengaruhi input berikutnya.
Keunggulan: Jaringan saraf sirkulasi memiliki kemampuan prediktif ketika ada banyak informasi terorganisir Contoh skenario: pengelompokan gambar dengan menambahkan subtitle, analisis sentimen politik

Long short-term memory (LSTM) dan gated recurrent unit nerual network: bentuk RNN yang lebih awal akan mengalami kehilangan. Meskipun jaringan saraf sirkulasi yang lebih awal ini hanya memungkinkan untuk menyimpan sejumlah kecil informasi awal, jaringan saraf LSTM dan GRU yang lebih baru memiliki memori jangka panjang dan jangka pendek. Dengan kata lain, RNN yang lebih baru ini memiliki kemampuan untuk mengontrol memori yang lebih baik, memungkinkan untuk mempertahankan nilai-nilai sebelumnya atau mengubah nilai-nilai ini ketika diperlukan untuk menangani serangkaian langkah-langkah, yang menghindari degradasi akhir dari nilai-nilai yang ditransmisikan secara bertahap.
Keunggulan: Memori jangka pendek dan jangka panjang dan jaringan saraf sel sirkulasi kontrol pintu memiliki keunggulan yang sama dengan jaringan saraf sirkulasi lainnya, tetapi lebih sering digunakan karena mereka memiliki kemampuan memori yang lebih baik Contoh Skenario: Pemrosesan Bahasa Alami, Terjemahan
Convolutional neural network: Convolutional adalah penggabungan berat dari lapisan berikutnya yang dapat digunakan untuk menandai lapisan output.
Pro: Jaringan saraf konvolusi sangat berguna ketika ada dataset yang sangat besar, banyak fitur, dan tugas klasifikasi yang kompleks Contoh skenario: pengenalan gambar, transkripsi teks, penemuan obat
- #### Terjemahan bahasa Indonesia:
http://usblogs.pwc.com/emerging-technology/a-look-at-machine-learning-infographic/
http://usblogs.pwc.com/emerging-technology/machine-learning-methods-infographic/
http://usblogs.pwc.com/emerging-technology/machine-learning-evolution-infographic/
Dikutip dari Big Data Land