

Artikel ini membahas strategi perdagangan frekuensi tinggi mata uang digital, termasuk sumber keuntungan (terutama dari fluktuasi pasar dan potongan biaya pertukaran), masalah penempatan pesanan dan kontrol posisi, dan metode pemodelan volume perdagangan menggunakan distribusi Pareto. Selain itu, data transaksi dan pesanan optimal yang disediakan oleh Binance digunakan untuk pengujian ulang, dan masalah lain terkait strategi perdagangan frekuensi tinggi direncanakan akan dibahas secara mendalam di artikel berikutnya.
Saya telah menulis dua artikel tentang perdagangan mata uang digital frekuensi tinggi sebelumnya. Pengenalan terperinci tentang strategi frekuensi tinggi untuk mata uang digital, Hasilkan 80 kali dalam 5 hari, kekuatan strategi frekuensi tinggi. Namun itu hanya dapat dianggap sebagai berbagi pengalaman dan pembicaraan umum. Kali ini saya berencana untuk menulis serangkaian artikel untuk memperkenalkan ide-ide perdagangan frekuensi tinggi dari awal. Saya berharap dapat sesingkat dan sejelas mungkin. Namun, karena tingkat dan pemahaman saya yang terbatas tentang perdagangan frekuensi tinggi, saya ingin menulis artikel yang ringkas dan jelas. perdagangan, artikel ini hanya titik awal. Saya berharap para ahli dapat mengoreksi saya.
Sumber keuntungan frekuensi tinggi
Seperti disebutkan dalam artikel sebelumnya, strategi frekuensi tinggi sangat cocok untuk pasar dengan naik turun yang sangat fluktuatif. Memeriksa perubahan harga produk perdagangan dalam waktu singkat, yang terdiri dari tren dan fluktuasi keseluruhan. Jika kita dapat memprediksi perubahan tren secara akurat, kita tentu dapat menghasilkan uang, tetapi ini juga yang paling sulit. Artikel ini terutama memperkenalkan strategi pembuat frekuensi tinggi dan tidak akan membahas masalah ini. Dalam pasar yang bergejolak, jika strategi penempatan order naik dan turun dieksekusi cukup sering dan margin keuntungan cukup besar, hal itu dapat menutupi kemungkinan kerugian yang disebabkan oleh tren, sehingga Anda dapat memperoleh keuntungan tanpa harus memprediksi pasar. Saat ini, semua transaksi maker di bursa menerima potongan biaya transaksi, yang juga merupakan komponen laba. Semakin ketat persaingan, semakin tinggi pula proporsi potongan yang seharusnya diberikan.
Masalah yang harus dipecahkan
-
Strategi ini menempatkan order beli dan order jual pada saat yang bersamaan. Pertanyaan pertama adalah di mana menempatkan order. Semakin dekat order dengan pasar, semakin tinggi kemungkinan terjadinya transaksi. Namun, dalam pasar yang bergejolak, harga transaksi sesaat mungkin jauh dari pasar. Jika order ditempatkan terlalu dekat, Anda tidak akan dapat mendapat keuntungan yang cukup. Kemungkinan eksekusi order yang ditempatkan terlalu jauh adalah rendah. Ini adalah masalah yang perlu dioptimalkan.
-
Kendalikan posisi Anda. Untuk mengendalikan risiko, strategi tidak dapat mengakumulasi terlalu banyak posisi dalam jangka waktu lama. Hal ini dapat diatasi dengan mengendalikan jarak pesanan, jumlah pesanan, batas posisi total, dll.
Untuk mencapai tujuan di atas, perlu dilakukan pemodelan dan estimasi probabilitas transaksi, keuntungan transaksi, estimasi pasar, dan aspek lainnya. Ada banyak artikel dan makalah di bidang ini, yang dapat ditemukan dengan kata kunci seperti Perdagangan Frekuensi Tinggi , Buku pesanan, dll. Ada banyak rekomendasi daring, yang tidak akan saya bahas di sini. Selain itu, sebaiknya buatlah sistem pengujian ulang yang andal dan cepat. Meskipun strategi frekuensi tinggi dapat dengan mudah diverifikasi melalui perdagangan nyata untuk memverifikasi efektivitasnya, pengujian ulang tetap dapat memberikan lebih banyak ide dan mengurangi biaya uji coba.
Data yang dibutuhkan
Binance menyediakan data transaksi per transaksi dan pesanan terbaikUnduhData mendalam perlu diunduh menggunakan API dalam daftar putih, atau Anda dapat mengumpulkannya sendiri. Untuk tujuan pengujian ulang, Anda dapat menggunakan data transaksi yang dikumpulkan. Artikel ini mengambil data HOOKUSDT-aggTrades-2023-01-27 sebagai contoh.
python
from datetime import date,datetime
import time
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
Kolom transaksi adalah sebagai berikut:
- agg_trade_id: id dari pesanan transaksi agregat,
- Harga: harga transaksi
- Kuantitas: Jumlah transaksi
- first_trade_id: Mungkin ada beberapa transaksi dalam koleksi pada saat yang sama, hanya satu data yang dihitung, ini adalah id transaksi pertama
- last_trade_id: id transaksi terakhir
- transact_time: waktu transaksi
- is_buyer_maker: arah transaksi, Benar berarti order beli diperdagangkan oleh pembuat, dan order jual diperdagangkan oleh penerima
Terlihat pada hari itu terdapat 660.000 data transaksi dan transaksinya sangat aktif. CSV akan dilampirkan di bagian komentar.
python
trades = pd.read_csv('COMPUSDT-aggTrades-2023-07-02.csv')
trades
664475 rows × 7 columns
| agg_trade_id | price | quantity | first_trade_id | last_trade_id | transact_time | is_buyer_maker |
|---|---|---|---|---|---|---|
| 120719552 | 52.42 | 22.087 | 207862988 | 207862990 | 1688256004603 | False |
| 120719553 | 52.41 | 29.314 | 207862991 | 207863002 | 1688256004623 | True |
| 120719554 | 52.42 | 0.945 | 207863003 | 207863003 | 1688256004678 | False |
| 120719555 | 52.41 | 13.534 | 207863004 | 207863006 | 1688256004680 | True |
| ... | ... | ... | ... | ... | ... | ... |
| 121384024 | 68.29 | 10.065 | 210364899 | 210364905 | 1688342399863 | False |
| 121384025 | 68.30 | 7.078 | 210364906 | 210364908 | 1688342399948 | False |
| 121384026 | 68.29 | 7.622 | 210364909 | 210364911 | 1688342399979 | True |
Pemodelan volume transaksi tunggal
Pertama, proses data dan bagi perdagangan asli ke dalam kelompok transaksi aktif pesanan beli dan kelompok transaksi aktif pesanan jual. Selain itu, data transaksi agregat asli adalah sepotong data pada saat yang sama, pada harga yang sama dan dalam arah yang sama. Mungkin ada pesanan beli aktif sebesar 100. Jika dibagi menjadi beberapa transaksi dengan harga yang berbeda, seperti seperti 60 dan 40, Dua bagian data akan dihasilkan, yang memengaruhi estimasi volume pesanan beli. Oleh karena itu, perlu dilakukan agregasi lagi berdasarkan transact_time. Setelah agregasi, jumlah data berkurang 140.000 catatan.
python
trades['date'] = pd.to_datetime(trades['transact_time'], unit='ms')
trades.index = trades['date']
buy_trades = trades[trades['is_buyer_maker']==False].copy()
sell_trades = trades[trades['is_buyer_maker']==True].copy()
buy_trades = buy_trades.groupby('transact_time').agg({
'agg_trade_id': 'last',
'price': 'last',
'quantity': 'sum',
'first_trade_id': 'first',
'last_trade_id': 'last',
'is_buyer_maker': 'last',
'date': 'last',
'transact_time':'last'
})
sell_trades = sell_trades.groupby('transact_time').agg({
'agg_trade_id': 'last',
'price': 'last',
'quantity': 'sum',
'first_trade_id': 'first',
'last_trade_id': 'last',
'is_buyer_maker': 'last',
'date': 'last',
'transact_time':'last'
})
buy_trades['interval']=buy_trades['transact_time'] - buy_trades['transact_time'].shift()
sell_trades['interval']=sell_trades['transact_time'] - sell_trades['transact_time'].shift()
python
print(trades.shape[0] - (buy_trades.shape[0]+sell_trades.shape[0]))
146181
Mengambil order beli sebagai contoh, pertama-tama buatlah histogram. Anda dapat melihat bahwa efek ekor panjang sangat jelas. Sebagian besar data terkonsentrasi di paling kiri, tetapi ada juga sejumlah kecil transaksi besar yang didistribusikan di bagian ekor. .
python
buy_trades['quantity'].plot.hist(bins=200,figsize=(10, 5));
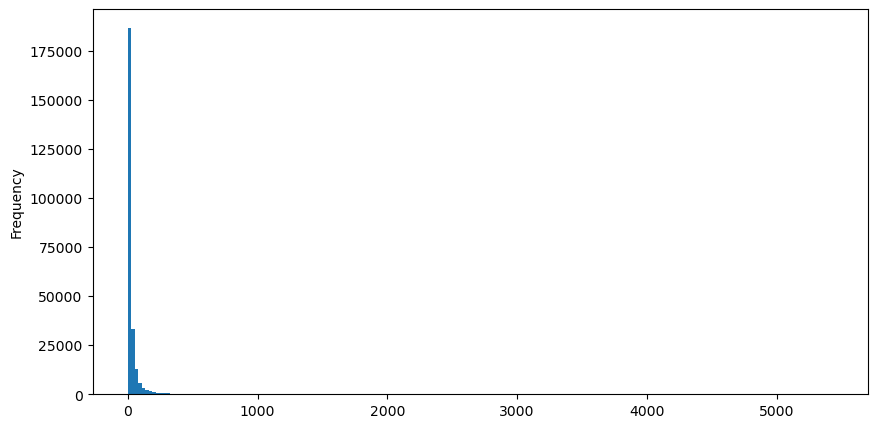
Untuk memudahkan pengamatan, kita potong ekornya dan amati. Kita dapat melihat bahwa semakin besar volume perdagangan, semakin rendah frekuensi kejadiannya, dan semakin cepat tren penurunannya.
python
buy_trades['quantity'][buy_trades['quantity']<200].plot.hist(bins=200,figsize=(10, 5));
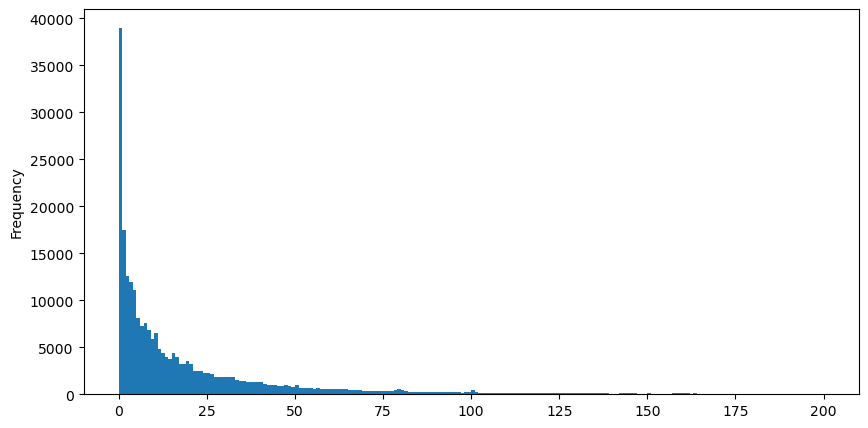
Ada banyak penelitian tentang distribusi kepuasan volume. Distribusi hukum daya juga disebut distribusi Pareto, yang merupakan bentuk umum distribusi probabilitas dalam fisika statistik dan ilmu sosial. Dalam distribusi hukum daya, probabilitas suatu kejadian dengan ukuran (atau frekuensi) tertentu berbanding lurus dengan beberapa eksponen negatif dari ukuran kejadian tersebut. Fitur utama bentuk distribusi ini adalah bahwa kejadian besar (yakni kejadian yang jauh dari rata-rata) terjadi lebih sering daripada yang diharapkan dalam banyak distribusi lainnya. Ini adalah karakteristik distribusi volume perdagangan. Bentuk distribusi Pareto adalah: P(x) = Cx^(-α). Berikut ini akan menunjukkan hal tersebut.
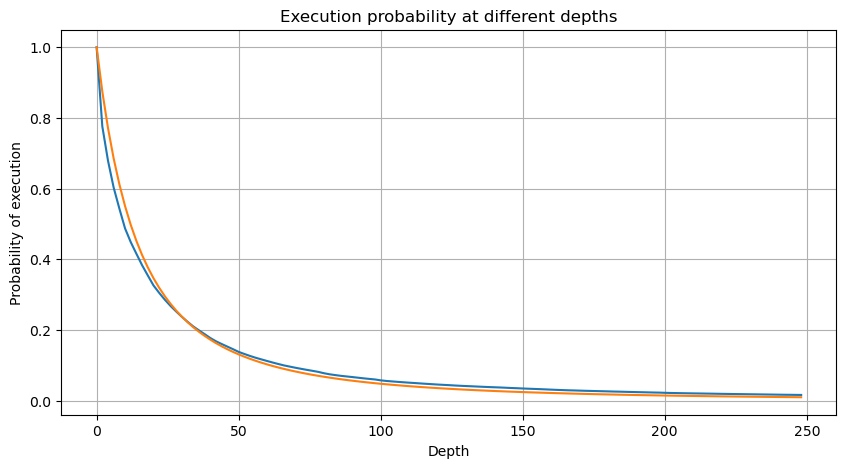
Gambar di bawah ini menunjukkan probabilitas bahwa volume perdagangan lebih besar dari nilai tertentu. Garis biru adalah probabilitas aktual, dan garis oranye adalah probabilitas simulasi. Jangan khawatir tentang parameter spesifik di sini. Anda dapat melihat bahwa itu tidak memenuhi distribusi Pareto. Karena probabilitas volume pesanan lebih besar dari 0 adalah 1, dan untuk memenuhi persyaratan standarisasi, persamaan distribusi harus sebagai berikut:
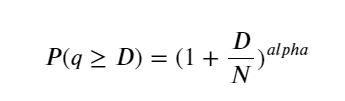
Di mana N adalah parameter terstandarisasi. Di sini kita memilih volume rata-rata M dan alpha -2,06. Perkiraan spesifik alpha dapat dihitung dengan menghitung nilai P secara terbalik ketika D=N. Secara khusus: alpha = log(P(d>M))/log(2). Memilih titik yang berbeda akan menghasilkan nilai alfa yang sedikit berbeda.
python
depths = range(0, 250, 2)
probabilities = np.array([np.mean(buy_trades['quantity'] > depth) for depth in depths])
alpha = np.log(np.mean(buy_trades['quantity'] > mean_quantity))/np.log(2)
mean_quantity = buy_trades['quantity'].mean()
probabilities_s = np.array([(1+depth/mean_quantity)**alpha for depth in depths])
plt.figure(figsize=(10, 5))
plt.plot(depths, probabilities)
plt.plot(depths, probabilities_s)
plt.xlabel('Depth')
plt.ylabel('Probability of execution')
plt.title('Execution probability at different depths')
plt.grid(True)
python
plt.figure(figsize=(10, 5))
plt.grid(True)
plt.title('Diff')
plt.plot(depths, probabilities_s-probabilities);
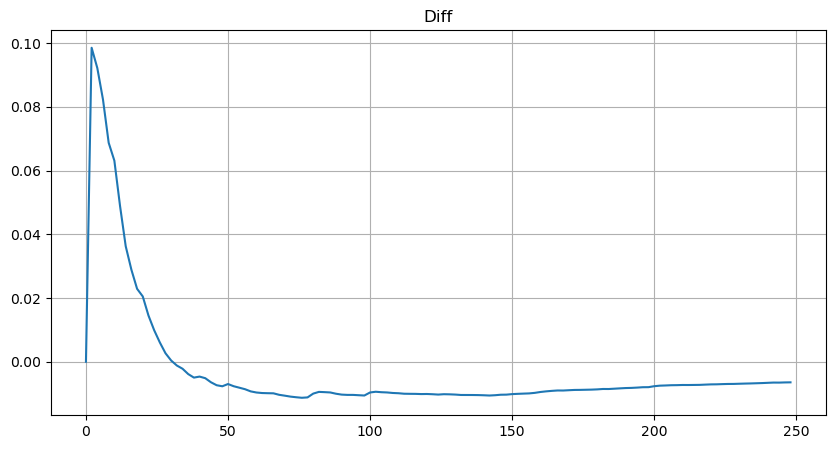
Namun, perkiraan ini hanya tampak seperti itu. Pada gambar di atas, kami memetakan perbedaan antara nilai simulasi dan nilai sebenarnya. Bila volume perdagangan kecil, deviasinya besar, bahkan mendekati 10%. Probabilitas suatu titik dapat dibuat lebih akurat dengan memilih titik yang berbeda selama estimasi parameter, tetapi ini tidak menyelesaikan masalah deviasi. Hal ini ditentukan oleh perbedaan antara distribusi hukum pangkat dan distribusi aktual. Untuk memperoleh hasil yang lebih akurat, persamaan distribusi hukum pangkat perlu dikoreksi. Saya tidak akan menguraikan secara terperinci proses spesifiknya, tetapi saya mendapat sedikit inspirasi dan menemukan bahwa seharusnya seperti berikut ini:
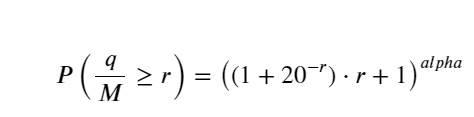
Untuk menyederhanakannya, r = q/M digunakan di sini untuk mewakili volume perdagangan terstandarisasi. Parameternya dapat diperkirakan dengan cara yang sama seperti di atas. Gambar di bawah ini menunjukkan bahwa deviasi maksimum setelah koreksi tidak melebihi 2%. Secara teoritis, koreksi dapat dilanjutkan, tetapi akurasi ini sudah cukup.
python
depths = range(0, 250, 2)
probabilities = np.array([np.mean(buy_trades['quantity'] > depth) for depth in depths])
mean = buy_trades['quantity'].mean()
alpha = np.log(np.mean(buy_trades['quantity'] > mean))/np.log(2.05)
probabilities_s = np.array([(((1+20**(-depth/mean))*depth+mean)/mean)**alpha for depth in depths])
plt.figure(figsize=(10, 5))
plt.plot(depths, probabilities)
plt.plot(depths, probabilities_s)
plt.xlabel('Depth')
plt.ylabel('Probability of execution')
plt.title('Execution probability at different depths')
plt.grid(True)
python
plt.figure(figsize=(10, 5))
plt.grid(True)
plt.title('Diff')
plt.plot(depths, probabilities_s-probabilities);
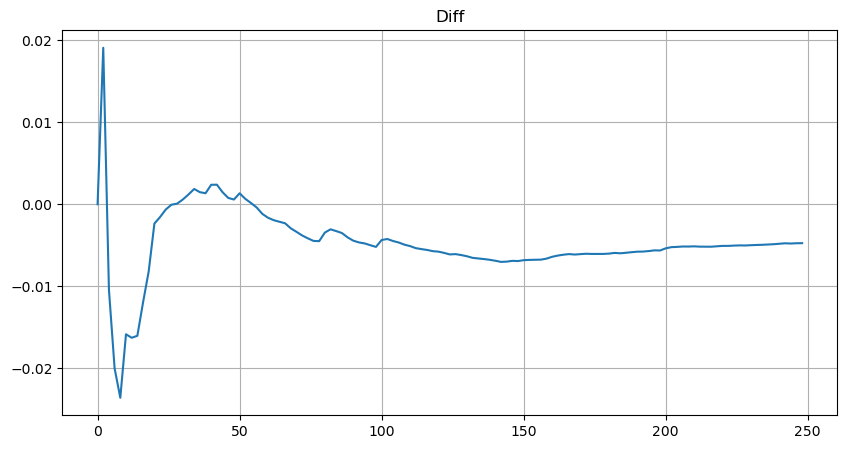
Dengan persamaan yang diestimasikan untuk distribusi volume, perhatikan bahwa probabilitas persamaan tersebut bukanlah probabilitas sebenarnya, tetapi probabilitas bersyarat. Pada titik ini kita dapat menjawab pertanyaan ini: jika urutan berikutnya terjadi, berapakah probabilitas bahwa urutan ini lebih besar dari nilai tertentu? Dengan kata lain, berapakah probabilitas pelaksanaan order dengan kedalaman berbeda (situasi ideal, tidak begitu ketat, secara teori buku order memiliki order baru dan pembatalan, serta antrian dengan kedalaman yang sama).
Artikel ini hampir selesai di sini, dan masih banyak pertanyaan yang perlu dijawab. Rangkaian artikel berikut akan mencoba memberikan jawabannya.

