

Artikel sebelumnya memberikan pengantar awal tentang metode perhitungan berbagai harga tengah dan memberikan revisi tentang harga tengah. Artikel ini terus membahas topik ini.
Data yang dibutuhkan
Data arus order dan sepuluh level data kedalaman dikumpulkan dari perdagangan nyata, dan frekuensi pembaruannya adalah 100 ms. Pasar riil hanya berisi data beli dan jual, yang diperbarui secara real time. Demi kesederhanaan, data tersebut tidak digunakan untuk sementara waktu. Mengingat datanya terlalu besar, hanya 100.000 baris data mendalam yang dipertahankan, dan kondisi pasar untuk setiap level juga dipisahkan ke dalam kolom terpisah.
python
from datetime import date,datetime
import time
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import ast
%matplotlib inline
python
tick_size = 0.0001
python
trades = pd.read_csv('YGGUSDT_aggTrade.csv',names=['type','event_time', 'agg_trade_id','symbol', 'price', 'quantity', 'first_trade_id', 'last_trade_id',
'transact_time', 'is_buyer_maker'])
python
trades = trades.groupby(['transact_time','is_buyer_maker']).agg({
'transact_time':'last',
'agg_trade_id': 'last',
'price': 'first',
'quantity': 'sum',
'first_trade_id': 'first',
'last_trade_id': 'last',
'is_buyer_maker': 'last',
})
python
trades.index = pd.to_datetime(trades['transact_time'], unit='ms')
trades.index.rename('time', inplace=True)
trades['interval'] = trades['transact_time'] - trades['transact_time'].shift()
python
depths = pd.read_csv('YGGUSDT_depth.csv',names=['type','event_time', 'transact_time','symbol', 'u1', 'u2', 'u3', 'bids','asks'])
python
depths = depths.iloc[:100000]
python
depths['bids'] = depths['bids'].apply(ast.literal_eval).copy()
depths['asks'] = depths['asks'].apply(ast.literal_eval).copy()
python
def expand_bid(bid_data):
expanded = {}
for j, (price, quantity) in enumerate(bid_data):
expanded[f'bid_{j}_price'] = float(price)
expanded[f'bid_{j}_quantity'] = float(quantity)
return pd.Series(expanded)
def expand_ask(ask_data):
expanded = {}
for j, (price, quantity) in enumerate(ask_data):
expanded[f'ask_{j}_price'] = float(price)
expanded[f'ask_{j}_quantity'] = float(quantity)
return pd.Series(expanded)
# 应用到每一行,得到新的df
expanded_df_bid = depths['bids'].apply(expand_bid)
expanded_df_ask = depths['asks'].apply(expand_ask)
# 在原有df上进行扩展
depths = pd.concat([depths, expanded_df_bid, expanded_df_ask], axis=1)
python
depths.index = pd.to_datetime(depths['transact_time'], unit='ms')
depths.index.rename('time', inplace=True);
python
trades = trades[trades['transact_time'] < depths['transact_time'].iloc[-1]]
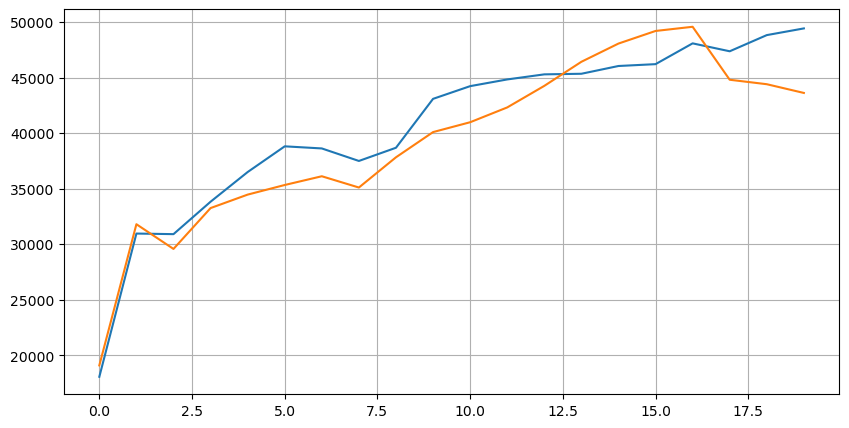
Mari kita lihat dulu distribusi dari 20 kondisi pasar ini. Distribusinya sesuai dengan ekspektasi. Semakin jauh dari pembukaan pasar, semakin banyak pending order yang ada, dan order beli dan order jual secara kasar simetris.
python
bid_mean_list = []
ask_mean_list = []
for i in range(20):
bid_mean_list.append(round(depths[f'bid_{i}_quantity'].mean(),0))
ask_mean_list.append(round(depths[f'ask_{i}_quantity'].mean(),0))
plt.figure(figsize=(10, 5))
plt.plot(bid_mean_list);
plt.plot(ask_mean_list);
plt.grid(True)
Gabungkan data kedalaman dan data transaksi untuk memudahkan evaluasi keakuratan prakiraan. Di sini kami memastikan bahwa semua data transaksi lebih lambat daripada data kedalaman. Tanpa mempertimbangkan penundaan, kami langsung menghitung kesalahan kuadrat rata-rata antara nilai yang diprediksi dan harga transaksi aktual. Digunakan untuk mengukur keakuratan prediksi.
Dilihat dari hasilnya, kesalahan mid_price, rata-rata pasangan beli-jual, adalah yang terbesar. Setelah diubah menjadi weight_mid_price, kesalahannya langsung menjadi jauh lebih kecil, dan diperbaiki lebih lanjut dengan menyesuaikan weighted mid-price. Setelah artikel kemarin diterbitkan, beberapa orang melaporkan bahwa mereka hanya menggunakan I^3/2. Saya memeriksanya di sini dan menemukan bahwa hasilnya lebih baik. Setelah memikirkan alasannya, seharusnya itu adalah perbedaan frekuensi kejadian. Ketika I mendekati -1 dan 1, itu adalah kejadian dengan probabilitas rendah. Untuk mengoreksi probabilitas rendah ini, prediksi kejadian frekuensi tinggi tidak begitu akurat. Oleh karena itu, untuk lebih memperhatikan kejadian frekuensi tinggi, saya membuat beberapa penyesuaian (ini murni parameter eksperimental, dan tidak terlalu berguna untuk perdagangan aktual):
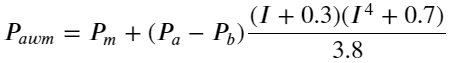
Hasilnya sedikit lebih baik. Seperti yang disebutkan dalam artikel sebelumnya, strategi harus diprediksi dengan lebih banyak data. Dengan data yang lebih mendalam dan pemenuhan pesanan, peningkatan yang dapat diperoleh dengan melibatkan harga pasar sudah sangat lemah.
python
df = pd.merge_asof(trades, depths, on='transact_time', direction='backward')
python
df['spread'] = round(df['ask_0_price'] - df['bid_0_price'],4)
df['mid_price'] = (df['bid_0_price']+ df['ask_0_price']) / 2
df['I'] = (df['bid_0_quantity'] - df['ask_0_quantity']) / (df['bid_0_quantity'] + df['ask_0_quantity'])
df['weight_mid_price'] = df['mid_price'] + df['spread']*df['I']/2
df['adjust_mid_price'] = df['mid_price'] + df['spread']*(df['I'])*(df['I']**8+1)/4
df['adjust_mid_price_2'] = df['mid_price'] + df['spread']*df['I']*(df['I']**2+1)/4
df['adjust_mid_price_3'] = df['mid_price'] + df['spread']*df['I']**3/2
df['adjust_mid_price_4'] = df['mid_price'] + df['spread']*(df['I']+0.3)*(df['I']**4+0.7)/3.8
python
print('平均值 mid_price的误差:', ((df['price']-df['mid_price'])**2).sum())
print('挂单量加权 mid_price的误差:', ((df['price']-df['weight_mid_price'])**2).sum())
print('调整后的 mid_price的误差:', ((df['price']-df['adjust_mid_price'])**2).sum())
print('调整后的 mid_price_2的误差:', ((df['price']-df['adjust_mid_price_2'])**2).sum())
print('调整后的 mid_price_3的误差:', ((df['price']-df['adjust_mid_price_3'])**2).sum())
print('调整后的 mid_price_4的误差:', ((df['price']-df['adjust_mid_price_4'])**2).sum())
平均值 mid_price的误差: 0.0048751924999999845
挂单量加权 mid_price的误差: 0.0048373440193987035
调整后的 mid_price的误差: 0.004803654771638586
调整后的 mid_price_2的误差: 0.004808216498329721
调整后的 mid_price_3的误差: 0.004794984755260528
调整后的 mid_price_4的误差: 0.0047909595497071375
Pertimbangkan kedalaman gigi kedua
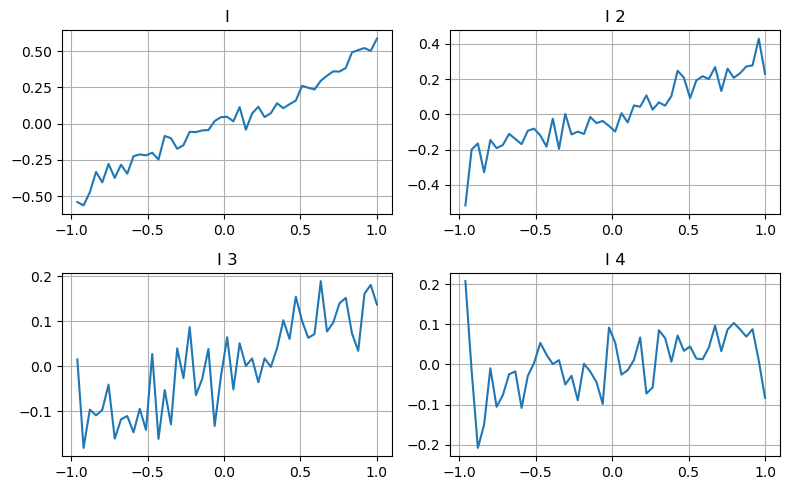
Di sini kami menggunakan ide dari artikel sebelumnya untuk memeriksa berbagai rentang nilai parameter tertentu yang memengaruhi dan perubahan harga transaksi untuk mengukur kontribusi parameter ini terhadap harga tengah. Seperti yang ditunjukkan pada grafik kedalaman tingkat pertama, saat I meningkat, harga transaksi berikutnya cenderung berubah positif, yang berarti bahwa I memberikan kontribusi positif.
Batch kedua diproses dengan cara yang sama, dan ditemukan bahwa meskipun efeknya sedikit lebih kecil daripada batch pertama, namun tetap tidak dapat diabaikan. Tingkat kedalaman ketiga juga memberikan kontribusi yang sedikit, tetapi monotonisitasnya jauh lebih buruk, dan kedalaman yang lebih dalam pada dasarnya tidak memiliki nilai referensi.
Berdasarkan tingkat kontribusi yang berbeda, bobot yang berbeda diberikan pada parameter ketidakseimbangan dari ketiga tingkat tersebut. Pemeriksaan aktual menunjukkan bahwa kesalahan prediksi semakin berkurang untuk metode perhitungan yang berbeda.
python
bins = np.linspace(-1, 1, 50)
df['change'] = (df['price'].pct_change().shift(-1))/tick_size
df['I_bins'] = pd.cut(df['I'], bins, labels=bins[1:])
df['I_2'] = (df['bid_1_quantity'] - df['ask_1_quantity']) / (df['bid_1_quantity'] + df['ask_1_quantity'])
df['I_2_bins'] = pd.cut(df['I_2'], bins, labels=bins[1:])
df['I_3'] = (df['bid_2_quantity'] - df['ask_2_quantity']) / (df['bid_2_quantity'] + df['ask_2_quantity'])
df['I_3_bins'] = pd.cut(df['I_3'], bins, labels=bins[1:])
df['I_4'] = (df['bid_3_quantity'] - df['ask_3_quantity']) / (df['bid_3_quantity'] + df['ask_3_quantity'])
df['I_4_bins'] = pd.cut(df['I_4'], bins, labels=bins[1:])
fig, axes = plt.subplots(nrows=2, ncols=2, figsize=(8, 5))
axes[0][0].plot(df.groupby('I_bins')['change'].mean())
axes[0][0].set_title('I')
axes[0][0].grid(True)
axes[0][1].plot(df.groupby('I_2_bins')['change'].mean())
axes[0][1].set_title('I 2')
axes[0][1].grid(True)
axes[1][0].plot(df.groupby('I_3_bins')['change'].mean())
axes[1][0].set_title('I 3')
axes[1][0].grid(True)
axes[1][1].plot(df.groupby('I_4_bins')['change'].mean())
axes[1][1].set_title('I 4')
axes[1][1].grid(True)
plt.tight_layout();
python
df['adjust_mid_price_4'] = df['mid_price'] + df['spread']*(df['I']+0.3)*(df['I']**4+0.7)/3.8
df['adjust_mid_price_5'] = df['mid_price'] + df['spread']*(0.7*df['I']+0.3*df['I_2'])/2
df['adjust_mid_price_6'] = df['mid_price'] + df['spread']*(0.7*df['I']+0.3*df['I_2'])**3/2
df['adjust_mid_price_7'] = df['mid_price'] + df['spread']*(0.7*df['I']+0.3*df['I_2']+0.3)*((0.7*df['I']+0.3*df['I_2'])**4+0.7)/3.8
df['adjust_mid_price_8'] = df['mid_price'] + df['spread']*(0.7*df['I']+0.2*df['I_2']+0.1*df['I_3']+0.3)*((0.7*df['I']+0.3*df['I_2']+0.1*df['I_3'])**4+0.7)/3.8
python
print('调整后的 mid_price_4的误差:', ((df['price']-df['adjust_mid_price_4'])**2).sum())
print('调整后的 mid_price_5的误差:', ((df['price']-df['adjust_mid_price_5'])**2).sum())
print('调整后的 mid_price_6的误差:', ((df['price']-df['adjust_mid_price_6'])**2).sum())
print('调整后的 mid_price_7的误差:', ((df['price']-df['adjust_mid_price_7'])**2).sum())
print('调整后的 mid_price_8的误差:', ((df['price']-df['adjust_mid_price_8'])**2).sum())
调整后的 mid_price_4的误差: 0.0047909595497071375
调整后的 mid_price_5的误差: 0.0047884350488318714
调整后的 mid_price_6的误差: 0.0047778319053133735
调整后的 mid_price_7的误差: 0.004773578540592192
调整后的 mid_price_8的误差: 0.004771415189297518
Pertimbangkan data transaksi
Data transaksi secara langsung mencerminkan tingkat posisi long dan short. Bagaimanapun, ini adalah opsi yang melibatkan uang sungguhan, dan biaya untuk menempatkan pesanan jauh lebih rendah, dan bahkan ada kasus penipuan penempatan pesanan yang disengaja. Oleh karena itu, ketika memprediksi harga tengah, strategi harus difokuskan pada data transaksi.
Dengan mempertimbangkan bentuknya, tentukan ketidakseimbangan kuantitas kedatangan rata-rata pesanan VI, Vb, Vs yang masing-masing mewakili kuantitas rata-rata pesanan beli dan pesanan jual per unit kejadian.
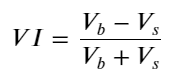
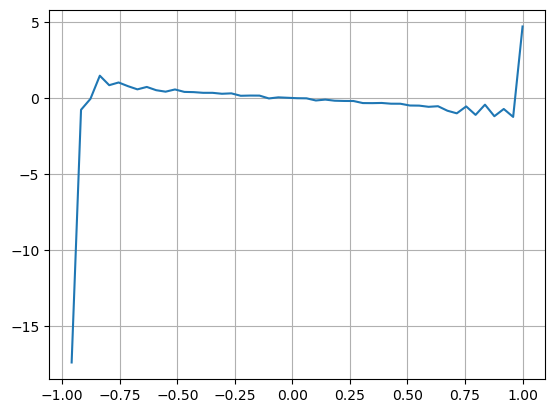
Hasil penelitian menunjukkan bahwa kuantitas kedatangan dalam jangka waktu yang pendek merupakan faktor yang paling signifikan dalam memprediksi perubahan harga. Nilai VI berada pada kisaran (0,1-0,9) berkorelasi negatif terhadap harga, namun di luar kisaran tersebut berkorelasi positif terhadap harga. harga. Hal ini menunjukkan bahwa ketika pasar tidak ekstrem, hal ini terutama ditandai oleh fluktuasi dan harga akan kembali ke rata-rata. Ketika kondisi pasar ekstrem terjadi, seperti sejumlah besar pesanan beli yang mengalahkan pesanan jual, tren akan keluar dari tren. . Bahkan jika kita mengabaikan situasi probabilitas rendah ini dan hanya berasumsi bahwa tren dan VI memenuhi hubungan linear negatif, kesalahan prediksi harga tengah sangat berkurang. Huruf a dalam rumus melambangkan koefisien.
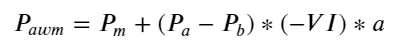
python
alpha=0.1
python
df['avg_buy_interval'] = None
df['avg_sell_interval'] = None
df.loc[df['is_buyer_maker'] == True, 'avg_buy_interval'] = df[df['is_buyer_maker'] == True]['transact_time'].diff().ewm(alpha=alpha).mean()
df.loc[df['is_buyer_maker'] == False, 'avg_sell_interval'] = df[df['is_buyer_maker'] == False]['transact_time'].diff().ewm(alpha=alpha).mean()
python
df['avg_buy_quantity'] = None
df['avg_sell_quantity'] = None
df.loc[df['is_buyer_maker'] == True, 'avg_buy_quantity'] = df[df['is_buyer_maker'] == True]['quantity'].ewm(alpha=alpha).mean()
df.loc[df['is_buyer_maker'] == False, 'avg_sell_quantity'] = df[df['is_buyer_maker'] == False]['quantity'].ewm(alpha=alpha).mean()
python
df['avg_buy_quantity'] = df['avg_buy_quantity'].fillna(method='ffill')
df['avg_sell_quantity'] = df['avg_sell_quantity'].fillna(method='ffill')
df['avg_buy_interval'] = df['avg_buy_interval'].fillna(method='ffill')
df['avg_sell_interval'] = df['avg_sell_interval'].fillna(method='ffill')
df['avg_buy_rate'] = 1000 / df['avg_buy_interval']
df['avg_sell_rate'] =1000 / df['avg_sell_interval']
df['avg_buy_volume'] = df['avg_buy_rate']*df['avg_buy_quantity']
df['avg_sell_volume'] = df['avg_sell_rate']*df['avg_sell_quantity']
python
df['I'] = (df['bid_0_quantity']- df['ask_0_quantity']) / (df['bid_0_quantity'] + df['ask_0_quantity'])
df['OI'] = (df['avg_buy_rate']-df['avg_sell_rate']) / (df['avg_buy_rate'] + df['avg_sell_rate'])
df['QI'] = (df['avg_buy_quantity']-df['avg_sell_quantity']) / (df['avg_buy_quantity'] + df['avg_sell_quantity'])
df['VI'] = (df['avg_buy_volume']-df['avg_sell_volume']) / (df['avg_buy_volume'] + df['avg_sell_volume'])
python
bins = np.linspace(-1, 1, 50)
df['VI_bins'] = pd.cut(df['VI'], bins, labels=bins[1:])
plt.plot(df.groupby('VI_bins')['change'].mean());
plt.grid(True)
python
df['adjust_mid_price'] = df['mid_price'] + df['spread']*df['I']/2
df['adjust_mid_price_9'] = df['mid_price'] + df['spread']*(-df['OI'])*2
df['adjust_mid_price_10'] = df['mid_price'] + df['spread']*(-df['VI'])*1.4
python
print('调整后的mid_price 的误差:', ((df['price']-df['adjust_mid_price'])**2).sum())
print('调整后的mid_price_9 的误差:', ((df['price']-df['adjust_mid_price_9'])**2).sum())
print('调整后的mid_price_10的误差:', ((df['price']-df['adjust_mid_price_10'])**2).sum())
调整后的mid_price 的误差: 0.0048373440193987035
调整后的mid_price_9 的误差: 0.004629586542840461
调整后的mid_price_10的误差: 0.004401790287167206
Harga rata-rata komprehensif
Mengingat bahwa baik pending order maupun data transaksi berguna untuk memprediksi harga tengah, kedua parameter ini dapat digabungkan. Penetapan bobot di sini bersifat arbitrer dan tidak mempertimbangkan kondisi batas. Dalam kasus ekstrem, harga tengah yang diprediksi mungkin tidak antara membeli satu dan menjual satu, tetapi selama kesalahan dapat dikurangi, rincian ini tidak menjadi masalah.
Akhirnya, kesalahan prediksi turun dari 0,00487 menjadi 0,0043. Kami tidak akan membahas detailnya di sini. Masih banyak yang perlu dieksplorasi tentang harga tengah. Bagaimanapun, memprediksi harga tengah adalah memprediksi harga. Anda dapat mencobanya sendiri .
python
#注意VI需要延后一个使用
df['price_change'] = np.log(df['price']/df['price'].rolling(40).mean())
df['CI'] = -1.5*df['VI'].shift()+0.7*(0.7*df['I']+0.2*df['I_2']+0.1*df['I_3'])**3 + 150*df['price_change'].shift(1)
python
df['adjust_mid_price_11'] = df['mid_price'] + df['spread']*(df['CI'])
print('调整后的mid_price_11的误差:', ((df['price']-df['adjust_mid_price_11'])**2).sum())
调整后的mid_price_11的误差: 0.00421125960463469
Meringkaskan
Makalah ini menggabungkan data kedalaman dan data transaksi untuk lebih meningkatkan metode perhitungan harga tengah. Makalah ini menyediakan metode untuk mengukur akurasi dan meningkatkan akurasi prediksi perubahan harga. Secara keseluruhan, berbagai parameter tidak terlalu ketat dan hanya untuk referensi. Dengan harga tengah yang lebih akurat, langkah selanjutnya adalah menerapkan harga tengah tersebut untuk pengujian ulang. Bagian ini juga memiliki banyak konten, jadi kami akan berhenti memperbarui untuk sementara waktu.


