

序文
Inventor Quantitative Trading Platform のバックテスト システムは、継続的に反復、更新、アップグレードされるバックテスト システムです。初期の基本的なバックテスト機能から、徐々に機能を追加し、パフォーマンスを最適化します。プラットフォームが発展するにつれて、バックテスト システムは最適化され、アップグレードされ続けます。今日は、バックテスト システムに基づくトピック、「ランダムな市場条件に基づく戦略テスト」について説明します。
必要
定量取引の分野では、戦略の開発と最適化は実際の市場データの検証から切り離すことはできません。しかし、実際のアプリケーションでは、複雑で変化する市場環境のため、バックテストに履歴データに依存すると、極端な市場状況や特殊なシナリオをカバーできないなどの欠点が生じる可能性があります。したがって、効率的なランダム マーケット ジェネレーターを設計することは、定量戦略開発者にとって効果的なツールになります。
履歴データを使用して特定の取引所または通貨の戦略をバックテストする必要がある場合は、バックテストに FMZ プラットフォームの公式データ ソースを使用できます。時には、まったく「馴染みのない」市場で戦略がどのように機能するかを確認したい場合もあります。このとき、戦略をテストするためにいくつかのデータを「捏造」することができます。
ランダム市場データを使用することの重要性は次のとおりです。
-
- 戦略の堅牢性を評価する
ランダム マーケット ジェネレーターは、極端なボラティリティ、低いボラティリティ、トレンド市場、不安定な市場など、さまざまな市場シナリオを作成できます。これらのシミュレートされた環境で戦略をテストすると、さまざまな市場状況下でそのパフォーマンスが安定しているかどうかを評価するのに役立ちます。例えば:
この戦略はトレンドやショックの切り替えに適応できますか?
この戦略は極端な市場状況で大きな損失をもたらすでしょうか? - 戦略の堅牢性を評価する
-
- 戦略の潜在的な弱点を特定する
異常な市場状況(仮想的なブラックスワンイベントなど)をシミュレートすることで、戦略の潜在的な弱点を発見し、改善することができます。例えば:
戦略は特定の市場構造に過度に依存していますか?
パラメータが過剰適合するリスクはありますか? - 戦略の潜在的な弱点を特定する
-
- 戦略パラメータの最適化
ランダムに生成されたデータは、履歴データに完全に依存することなく、戦略パラメータの調整のためのより多様なテスト環境を提供します。これにより、より包括的な戦略パラメータの範囲が可能になり、履歴データ内の特定の市場パターンに制限されることがなくなります。
- 戦略パラメータの最適化
-
- 歴史的データのギャップを埋める
一部の市場(新興市場や小額通貨を取引する市場など)では、履歴データだけではすべての市場状況をカバーできない場合があります。ランダマイザーは、より包括的なテストを容易にするために大量の補足データを提供できます。
- 歴史的データのギャップを埋める
-
- 迅速な反復開発
ランダム データを使用して迅速にテストを行うと、リアルタイムの市場状況や時間のかかるデータのクリーニングや整理に頼ることなく、戦略開発の反復をスピードアップできます。
- 迅速な反復開発
ただし、戦略を合理的に評価することも必要です。ランダムに生成された市場データについては、次の点に注意してください。
-
- ランダム マーケット ジェネレーターは便利ですが、その重要性は生成されるデータの品質とターゲット シナリオの設計によって異なります。
-
- 生成ロジックは実際の市場に近い必要があります。ランダムに生成された市場条件が現実と完全にかけ離れている場合、テスト結果に参考値が欠ける可能性があります。たとえば、ジェネレーターは、実際の市場の統計特性 (ボラティリティ分布、トレンド比率など) と組み合わせて設計できます。
-
- 実際のデータテストを完全に置き換えることはできません。ランダムデータは戦略の開発と最適化を補完することしかできません。最終的な戦略は、実際の市場データでその有効性を検証する必要があります。
そうは言っても、どうすればデータを「捏造」できるのでしょうか。バックテスト システムで使用するデータを、便利に、迅速かつ簡単に「作成」するにはどうすればよいでしょうか?
デザインのアイデア
この記事は議論の出発点となるように設計されており、比較的単純なランダム市場生成計算を提供します。実際には、さまざまなシミュレーションアルゴリズム、データモデル、その他の技術を適用できます。議論のスペースが限られているため、特に複雑なデータシミュレーション手法は使用しません。
プラットフォームバックテストシステムのカスタムデータソース機能を組み合わせて、Pythonでプログラムを作成しました。
-
- K ライン データ セットをランダムに生成し、永続的な記録のために CSV ファイルに書き込んで、生成されたデータを保存できるようにします。
-
- 次に、バックテスト システムのデータ ソース サポートを提供するサービスを作成します。
-
- 生成された K ライン データをチャートに表示します。
K ライン データの一部の生成標準とファイル ストレージでは、次のパラメーター コントロールを定義できます。
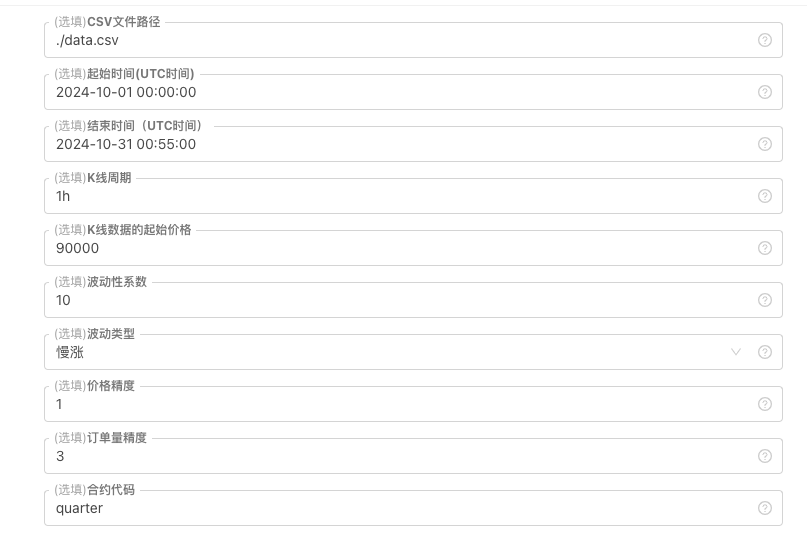
-
ランダムに生成されたデータパターン
K ラインデータの変動型をシミュレートするには、正と負の乱数の異なる確率を使用して単純な設計を実行するだけです。生成されるデータが大きくない場合、必要な市場パターンが反映されない可能性があります。より良い方法がある場合は、コードのこの部分を置き換えることができます。
このシンプルな設計に基づいて、コード内の乱数生成範囲といくつかの係数を調整することで、生成されるデータの効果に影響を与えることができます。 -
データ検証
生成された K ライン データは、合理性、高始値と安終値が定義に違反していないかどうか、K ライン データの連続性などをチェックする必要もあります。
バックテストシステムランダムクォートジェネレーター
python
import _thread
import json
import math
import csv
import random
import os
import datetime as dt
from http.server import HTTPServer, BaseHTTPRequestHandler
from urllib.parse import parse_qs, urlparse
arrTrendType = ["down", "slow_up", "sharp_down", "sharp_up", "narrow_range", "wide_range", "neutral_random"]
def url2Dict(url):
query = urlparse(url).query
params = parse_qs(query)
result = {key: params[key][0] for key in params}
return result
class Provider(BaseHTTPRequestHandler):
def do_GET(self):
global filePathForCSV, pround, vround, ct
try:
self.send_response(200)
self.send_header("Content-type", "application/json")
self.end_headers()
dictParam = url2Dict(self.path)
Log("自定义数据源服务接收到请求,self.path:", self.path, "query 参数:", dictParam)
eid = dictParam["eid"]
symbol = dictParam["symbol"]
arrCurrency = symbol.split(".")[0].split("_")
baseCurrency = arrCurrency[0]
quoteCurrency = arrCurrency[1]
fromTS = int(dictParam["from"]) * int(1000)
toTS = int(dictParam["to"]) * int(1000)
priceRatio = math.pow(10, int(pround))
amountRatio = math.pow(10, int(vround))
data = {
"detail": {
"eid": eid,
"symbol": symbol,
"alias": symbol,
"baseCurrency": baseCurrency,
"quoteCurrency": quoteCurrency,
"marginCurrency": quoteCurrency,
"basePrecision": vround,
"quotePrecision": pround,
"minQty": 0.00001,
"maxQty": 9000,
"minNotional": 5,
"maxNotional": 9000000,
"priceTick": 10 ** -pround,
"volumeTick": 10 ** -vround,
"marginLevel": 10,
"contractType": ct
},
"schema" : ["time", "open", "high", "low", "close", "vol"],
"data" : []
}
listDataSequence = []
with open(filePathForCSV, "r") as f:
reader = csv.reader(f)
header = next(reader)
headerIsNoneCount = 0
if len(header) != len(data["schema"]):
Log("CSV文件格式有误,列数不同,请检查!", "#FF0000")
return
for ele in header:
for i in range(len(data["schema"])):
if data["schema"][i] == ele or ele == "":
if ele == "":
headerIsNoneCount += 1
if headerIsNoneCount > 1:
Log("CSV文件格式有误,请检查!", "#FF0000")
return
listDataSequence.append(i)
break
while True:
record = next(reader, -1)
if record == -1:
break
index = 0
arr = [0, 0, 0, 0, 0, 0]
for ele in record:
arr[listDataSequence[index]] = int(ele) if listDataSequence[index] == 0 else (int(float(ele) * amountRatio) if listDataSequence[index] == 5 else int(float(ele) * priceRatio))
index += 1
data["data"].append(arr)
Log("数据data.detail:", data["detail"], "响应回测系统请求。")
self.wfile.write(json.dumps(data).encode())
except BaseException as e:
Log("Provider do_GET error, e:", e)
return
def createServer(host):
try:
server = HTTPServer(host, Provider)
Log("Starting server, listen at: %s:%s" % host)
server.serve_forever()
except BaseException as e:
Log("createServer error, e:", e)
raise Exception("stop")
class KlineGenerator:
def __init__(self, start_time, end_time, interval):
self.start_time = dt.datetime.strptime(start_time, "%Y-%m-%d %H:%M:%S")
self.end_time = dt.datetime.strptime(end_time, "%Y-%m-%d %H:%M:%S")
self.interval = self._parse_interval(interval)
self.timestamps = self._generate_time_series()
def _parse_interval(self, interval):
unit = interval[-1]
value = int(interval[:-1])
if unit == "m":
return value * 60
elif unit == "h":
return value * 3600
elif unit == "d":
return value * 86400
else:
raise ValueError("不支持的K线周期,请使用 'm', 'h', 或 'd'.")
def _generate_time_series(self):
timestamps = []
current_time = self.start_time
while current_time <= self.end_time:
timestamps.append(int(current_time.timestamp() * 1000))
current_time += dt.timedelta(seconds=self.interval)
return timestamps
def generate(self, initPrice, trend_type="neutral", volatility=1):
data = []
current_price = initPrice
angle = 0
for timestamp in self.timestamps:
angle_radians = math.radians(angle % 360)
cos_value = math.cos(angle_radians)
if trend_type == "down":
upFactor = random.uniform(0, 0.5)
change = random.uniform(-0.5, 0.5 * upFactor) * volatility * random.uniform(1, 3)
elif trend_type == "slow_up":
downFactor = random.uniform(0, 0.5)
change = random.uniform(-0.5 * downFactor, 0.5) * volatility * random.uniform(1, 3)
elif trend_type == "sharp_down":
upFactor = random.uniform(0, 0.5)
change = random.uniform(-10, 0.5 * upFactor) * volatility * random.uniform(1, 3)
elif trend_type == "sharp_up":
downFactor = random.uniform(0, 0.5)
change = random.uniform(-0.5 * downFactor, 10) * volatility * random.uniform(1, 3)
elif trend_type == "narrow_range":
change = random.uniform(-0.2, 0.2) * volatility * random.uniform(1, 3)
elif trend_type == "wide_range":
change = random.uniform(-3, 3) * volatility * random.uniform(1, 3)
else:
change = random.uniform(-0.5, 0.5) * volatility * random.uniform(1, 3)
change = change + cos_value * random.uniform(-0.2, 0.2) * volatility
open_price = current_price
high_price = open_price + random.uniform(0, abs(change))
low_price = max(open_price - random.uniform(0, abs(change)), random.uniform(0, open_price))
close_price = open_price + change if open_price + change < high_price and open_price + change > low_price else random.uniform(low_price, high_price)
if (high_price >= open_price and open_price >= close_price and close_price >= low_price) or (high_price >= close_price and close_price >= open_price and open_price >= low_price):
pass
else:
Log("异常数据:", high_price, open_price, low_price, close_price, "#FF0000")
high_price = max(high_price, open_price, close_price)
low_price = min(low_price, open_price, close_price)
base_volume = random.uniform(1000, 5000)
volume = base_volume * (1 + abs(change) * 0.2)
kline = {
"Time": timestamp,
"Open": round(open_price, 2),
"High": round(high_price, 2),
"Low": round(low_price, 2),
"Close": round(close_price, 2),
"Volume": round(volume, 2),
}
data.append(kline)
current_price = close_price
angle += 1
return data
def save_to_csv(self, filename, data):
with open(filename, mode="w", newline="") as csvfile:
writer = csv.writer(csvfile)
writer.writerow(["", "open", "high", "low", "close", "vol"])
for idx, kline in enumerate(data):
writer.writerow(
[kline["Time"], kline["Open"], kline["High"], kline["Low"], kline["Close"], kline["Volume"]]
)
Log("当前路径:", os.getcwd())
with open("data.csv", "r") as file:
lines = file.readlines()
if len(lines) > 1:
Log("文件写入成功,以下是文件内容的一部分:")
Log("".join(lines[:5]))
else:
Log("文件写入失败,文件为空!")
def main():
Chart({})
LogReset(1)
try:
# _thread.start_new_thread(createServer, (("localhost", 9090), ))
_thread.start_new_thread(createServer, (("0.0.0.0", 9090), ))
Log("开启自定义数据源服务线程,数据由CSV文件提供。", ", 地址/端口:0.0.0.0:9090", "#FF0000")
except BaseException as e:
Log("启动自定义数据源服务失败!")
Log("错误信息:", e)
raise Exception("stop")
while True:
cmd = GetCommand()
if cmd:
if cmd == "createRecords":
Log("生成器参数:", "起始时间:", startTime, "结束时间:", endTime, "K线周期:", KLinePeriod, "初始价格:", firstPrice, "波动类型:", arrTrendType[trendType], "波动性系数:", ratio)
generator = KlineGenerator(
start_time=startTime,
end_time=endTime,
interval=KLinePeriod,
)
kline_data = generator.generate(firstPrice, trend_type=arrTrendType[trendType], volatility=ratio)
generator.save_to_csv("data.csv", kline_data)
ext.PlotRecords(kline_data, "%s_%s" % ("records", KLinePeriod))
LogStatus(_D())
Sleep(2000)
バックテストシステムの実践
- 上記のポリシーインスタンスを作成し、パラメータを設定して実行します。
- バックテスト システムが実際の市場 (戦略インスタンス) にアクセスしてデータを取得するにはパブリック IP が必要であるため、実際の市場 (戦略インスタンス) はサーバー上に展開されたホストで実行する必要があります。
- インタラクティブ ボタンをクリックすると、戦略によってランダムな市場データが自動的に生成されます。

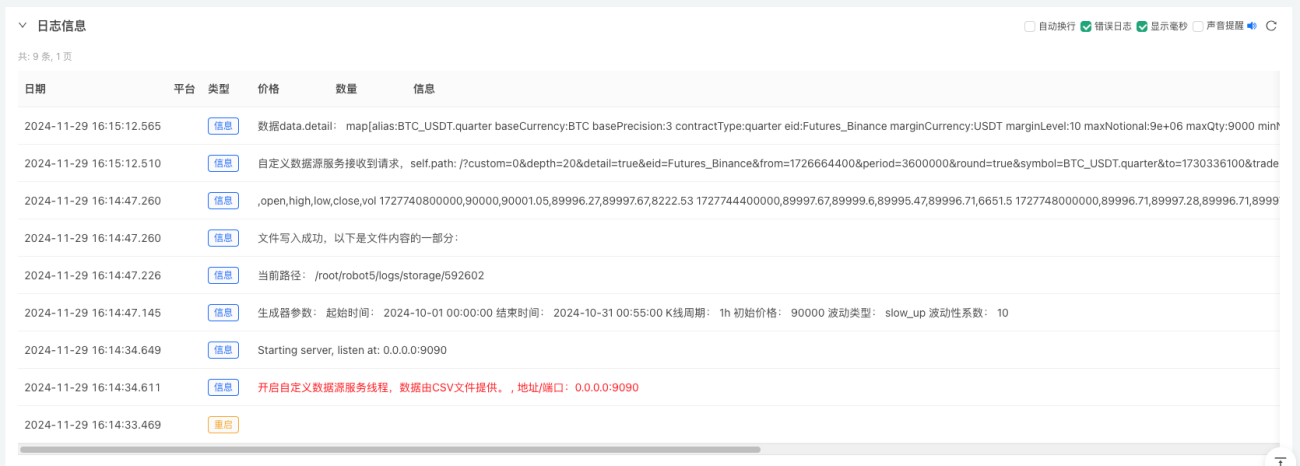
- 生成されたデータは簡単に観察できるようにチャートに表示され、データはローカルのdata.csvファイルに記録されます。
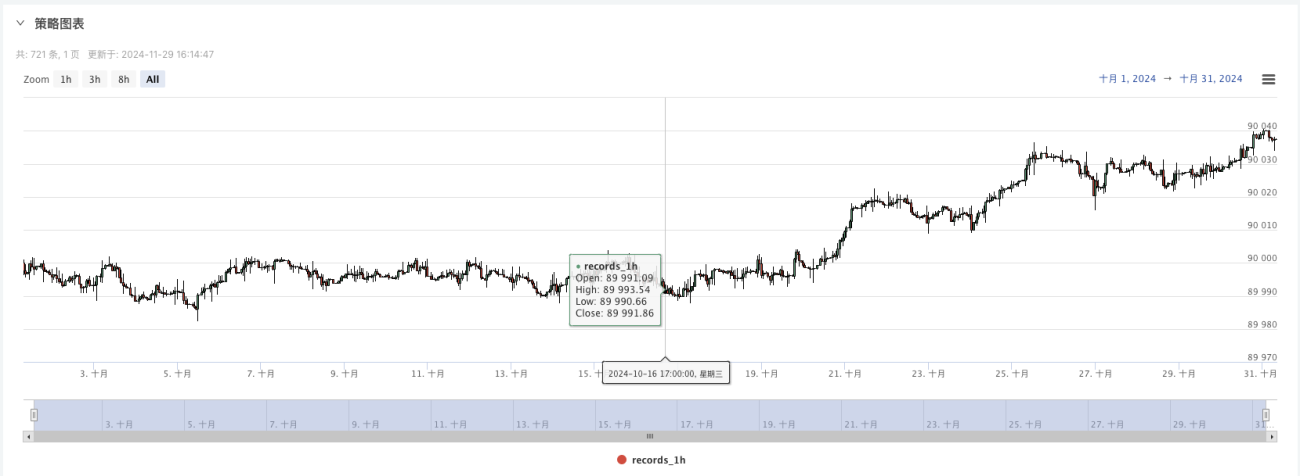
- これで、ランダムに生成されたデータを使用して、バックテストに任意の戦略を使用できます。
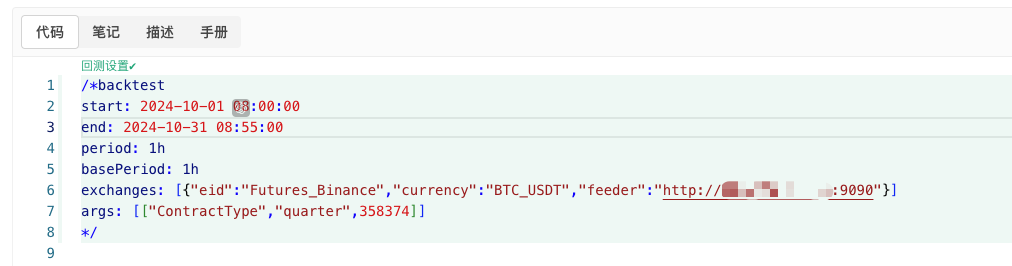
python
/*backtest
start: 2024-10-01 08:00:00
end: 2024-10-31 08:55:00
period: 1h
basePeriod: 1h
exchanges: [{"eid":"Futures_Binance","currency":"BTC_USDT","feeder":"http://xxx.xxx.xxx.xxx:9090"}]
args: [["ContractType","quarter",358374]]
*/
上記の情報に従って設定し、具体的な調整を行ってください。http://xxx.xxx.xxx.xxx:9090ランダム市場生成戦略実ディスクのサーバー IP アドレスと開いているポートです。
これはカスタム データ ソースです。詳細については、プラットフォーム API ドキュメントのカスタム データ ソース セクションを参照してください。
- バックテストシステムがデータソースを設定したら、ランダムな市場データをテストできます。
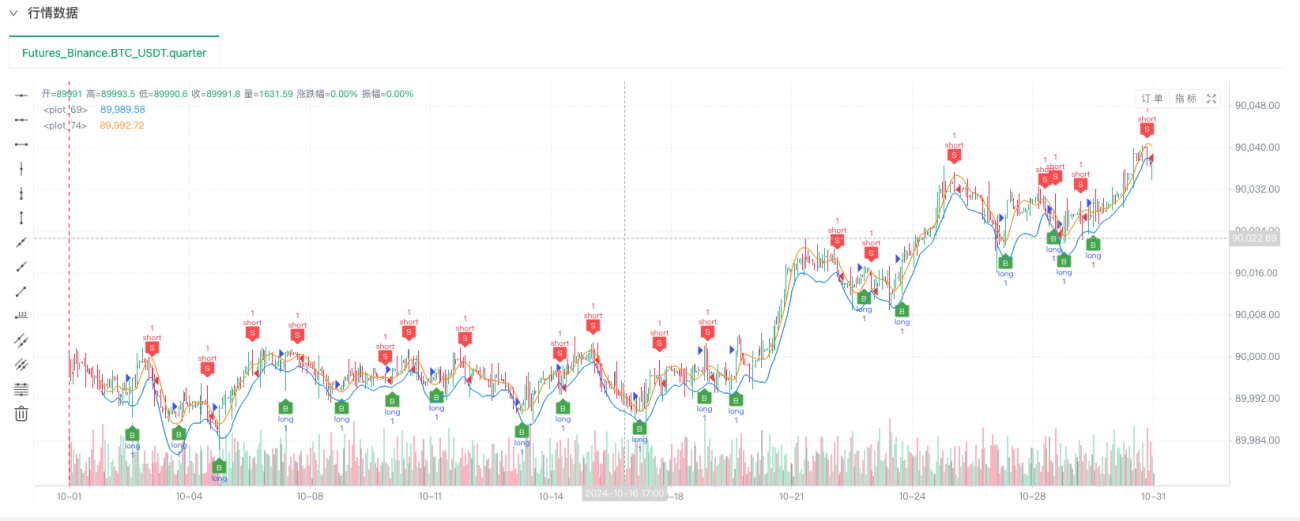
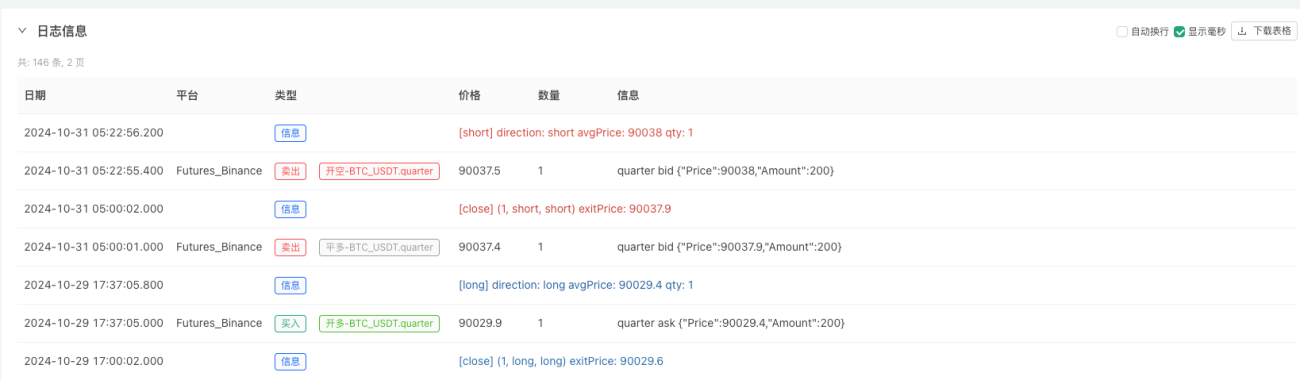
この時点で、バックテスト システムは、弊社の「偽造」されたシミュレートされたデータを使用してテストされます。バックテスト中のマーケットチャートのデータに基づいて、ランダムなマーケット状況によって生成されたリアルタイムチャートのデータを比較します。時間は2024年10月16日17:00です。データは同じです。
- ああ、そうそう、それを言うのを忘れるところでした!このランダム マーケット ジェネレーター Python プログラムが実際のマーケットを作成する理由は、生成された K ライン データのデモンストレーション、操作、および表示を容易にするためです。実際のアプリケーションでは、独立した Python スクリプトを記述できるため、実際のディスクを実行する必要はありません。
戦略ソースコード:バックテストシステムランダムクォートジェネレーター
ご愛読、ご支援ありがとうございます。
- 1