
機械学習の3つの主要カテゴリと6つの主要アルゴリズムの長所と短所を徹底解説
機械学習では,目標が予測 (prediction) またはクラスタリング (clustering) である.本文では,予測 (prediction) に焦点を当てている.予測は,入力変数の集合から出力変数の値を予測するプロセスである.例えば,家に関する特性の集合が与えられれば,その販売価格を予測することができる.予測問題は,2つの大カテゴリーに分類される: (1) 予測される変数は数字である (例えば,家の価格); (2) 分類の問題である (例えば,ある機器が故障するかどうかを予測する).
このことを理解した上で,機械学習における最も顕著で,最もよく使用されるアルゴリズムを見てみましょう. これらのアルゴリズムを3つのカテゴリーに分類します. 線形モデル,木ベースのモデル,ニューラルネットワークです.
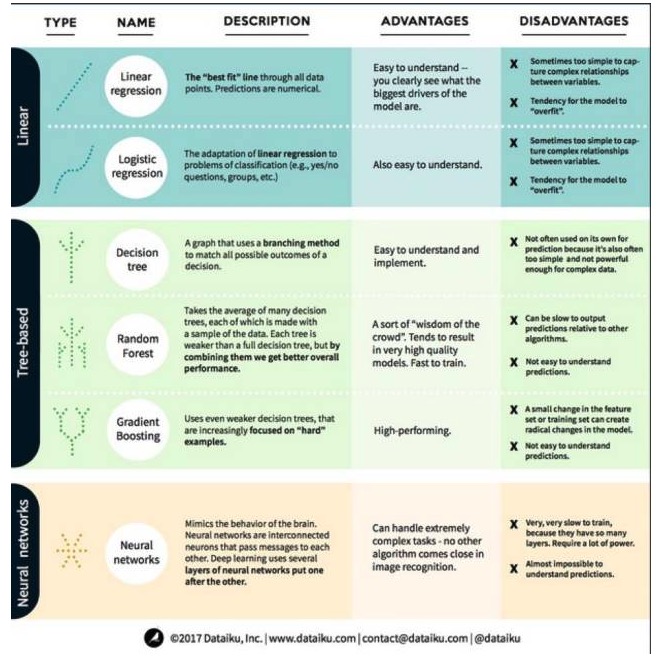
一,線形モデルアルゴリズム:線形モデルは,簡単な公式を使って,データポイントのセットから<unk>の最適合の<unk>を見つけます.この方法は200年以上前に遡り,統計学と機械学習の分野で広く使用されています.その単純さのために,統計学には有用です.あなたが予測したい変数 (変数による) は,あなたがすでに知っている変数 (変数による) の方程式として表現されています.したがって,予測は,変数からの入力であり,方程式からの答えを計算するだけの問題です.
-
1. 線形回帰
線形還元,またはより正確には最小二乗還元<unk>,は線形モデルの最も標準的な形式である. 還元の問題に対して,線形還元は最も単純な線形モデルである. その欠点は,モデルが過適合しやすいこと,すなわち,モデルが訓練されたデータに完全に適応し,新しいデータへの普及能力を犠牲にするというものである. したがって,機械学習における線形還元 (および次に話す論理還元) は通常正規化<unk>であり,これは,モデルに過適合を防ぐための一定の罰則があることを意味する.
線形モデルのもう一つの欠点は,非常に単純であるため,入力変数が独立でない場合,より複雑な行動を容易に予測できないことです.
-
2. 論理回帰
論理回帰は,線形回帰の分類問題への適応である。論理回帰の欠点は,線形回帰と同じである。論理関数は,<unk>値効果を導入したため,分類問題に対して非常に良い。
2 ツリーモデルのアルゴリズム
-
1 意思決定ツリー
意思決定ツリーとは,意思決定の可能な結果のすべてを分岐方法を使って表示する図です. 例えば,サラダを注文する決断をすると,最初の決定は生菜の種類,次に配菜の種類,次にサラダの種類です. すべての可能な結果を1つの意思決定ツリーで表示できます.
意思決定ツリーを訓練するために,トレーニングデータセットを使用して,その属性がターゲットに最も有用であるかを特定する必要があります.例えば,詐欺検知用例では,詐欺リスクを予測するのに最も影響を与える属性が国家であることがわかります.最初の属性で分岐した後,私たちは2つのサブセットを得ます.これは,最初の属性だけがわかっている場合に最も正確に予測できるものです.次に,これらの2つのサブセットに分岐できる2番目の良い属性を見つけ,再び分岐します.
-
2 ランダムな森
ランダムフォレストは,多くの決定木の平均であり,それぞれの決定木は,ランダムなデータサンプルで訓練されます.ランダムフォレストの各木は,完全な決定木よりも弱くなりますが,すべての木を集めて,多様性の優位性のために,全体的により良いパフォーマンスを得ることができます.
ランダムフォレストは,今日の機械学習で非常に人気のあるアルゴリズムである. ランダムフォレストは,訓練しやすいし,かなり良いパフォーマンスを発揮している. その欠点は,他のアルゴリズムと比較して,ランダムフォレストの出力予測が遅い可能性があるため,迅速な予測が必要なときにランダムフォレストを選択しない可能性があることです.
-
3 梯度上昇
梯度昇進 (GradientBoosting) は,ランダムな森のように,<unk>弱<unk>弱の決定樹で構成されている.梯度昇進とランダムな森の最大の違いは,梯度昇進では,木が1つずつ訓練されるということです.それぞれの後ろの木は,前の木が誤ったデータを認識することによって主に訓練されます.これは梯度昇進を予測しやすい状況にあまり焦点を当てず,困難な状況に多く焦点を当てます.
梯度上昇のトレーニングも迅速で,非常に良いパフォーマンスである。しかし,トレーニングデータセットの小さな変更はモデルに根本的な変化をもたらすため,それが生み出す結果が最も実行可能ではないかもしれない。
ニューラルネットワークアルゴリズム:ニューラルネットワークとは,脳内の相互に情報を交換する相互接続したニューロンを構成する生物学的現象である.この考えは,機械学習の分野に現在適用され,ANN (人工ニューラルネットワーク) と呼ばれている.深層学習は,多層のニューラルネットワークを重ね合わせている.ANNは,学習によって人間の脳に似た認知能力を獲得する一連のモデルである.画像認識などの非常に複雑なタスクを処理する際に,ニューラルネットワークは良好なパフォーマンスを発揮する.しかし,人間の脳と同様に,モデルを訓練することは非常に時間がかかり,非常に多くのエネルギーが必要である.
大量のデータから
- 1