実用的なビッグデータ
 0
2208
0
2208
量化戦略のサンプル外データテストの必要性

- #### NO:01
人生は,子供から大人へ,大人から高齢へ, 間違いを繰り返す,修正する,そして間違いを繰り返すプロセスであり, ほとんど誰も例外ではありません. 今では,非常に低いレベルに見えますが,多くの間違いを犯したことがあるかもしれません. また,不動産,インターネット,デジタル通貨など,多くの乗車機会を逃したかもしれません. … バブルが起こったとき,あなたはそこにいなかったのですか?
“このままでは,このままでは,このままでは, “私は… すべきじゃなかった” “もし・・・もし・・・もし・・・”
私は長い間この問題を抱えていて,それを解き放つことができませんでした. しかし,それは恐れることは何もありません. なぜなら,正しいか間違っているかのどちらかであるかの選択は,私たちを予期された結果から遠ざけて,未知のものへと導きます. そして,私たちの反省は,歴史のデータを超えて,神の視点を開きます.
- #### NO:02
私は多くの取引システムを見てきたが,反省時に成功率は50%以上に達する.このような高い勝利率を前提に,また1:1以上の利益損失比率がある.しかし,例外なし,これらのシステムは,一旦実盤に付くと,基本的には損失する.損失の原因はたくさんあり,その中には,反省時に,不意に,右から左を見て,神の視点を開いたものもある.

しかし,取引は複雑で,後見は明瞭ですが,もし神の視点の光線を持っていなければ,最初に戻ると,まだ困惑しています.これは,量的な根源の問題と歴史的なデータの限界にぶつかります. 限られた歴史的データだけで取引システムを検査すると,後視鏡で車を運転する問題を回避することは困難です.
- #### NO:03
しかし,限られたデータで,限られたデータを活用して,取引戦略を全面的に検証するには,どうすればよいのでしょうか? 通常,推論的テストと交差点テストの2つの方法があります.
連続推論テストの基本原理:前段の長い歴史データでモデルを訓練し,その後の比較的短いデータでモデルをテストし,その後,データを取得するウィンドウを常に後ろに移動させ,トレーニングとテストのステップを繰り返す.

- 訓練データ:2000年から2001年,テストデータ:2002年.
- 訓練データ:2001年から2002年,テストデータ:2003年.
- 訓練データ:2002年から2003年,テストデータ:2004年.
- 訓練データ:2003年から2004年,テストデータ:2005年.
- 訓練データ:2004年~2005年,テストデータ:2006年
“私は,この世界から離れて,
最後に,戦略のパフォーマンスを総合的に評価するために,テストの結果を統計的に (2002,2003,2004,2005年,2006年…) した.
下の図のように,推論テストの原理を直観的に説明できる.
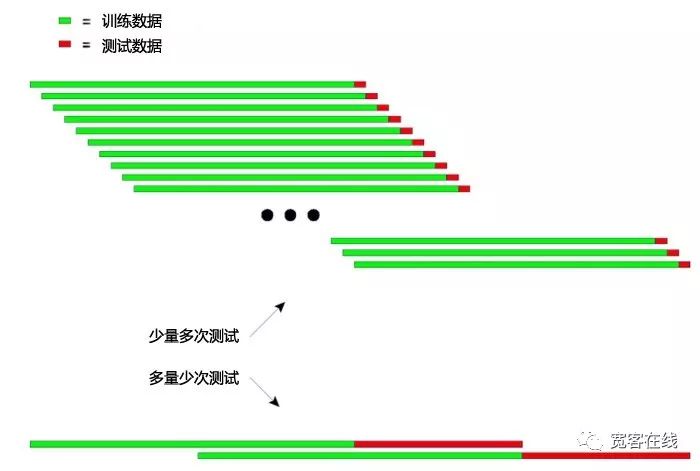
上図は,推論的な検査の2つの方法を示しています.
第”種は,テストのデータが短く,テスト回数が多い. 2つ目は,テストのデータが長く,テストの回数が少ない.
実用的には,テストデータの長さを変化させることで,モデルが非平坦なデータに対応する安定性を判断するために,複数のテストを行うことができます.
- #### NO:04
交差点検の基本原理:全データを等しくN部分に分割し,そのN−1部分で練習し,残りの部分で検査する.
2000年から2003年を各年ごとに分割して4つの部分に分けます.そのクロスチェックの操作手順は以下の通りです. 1. 訓練データ:2001-2003,テストデータ:2000; 2 訓練データ:2000-2002 テストデータ:2003 3. 訓練データ:2000,2001,2003,テストデータ:2002; 4. 訓練データ:2000,2002,2003年,テストデータ:2001年
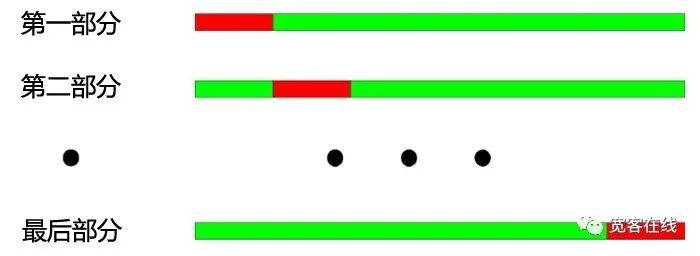
上図のように:クロステストの最大の利点は,限られたデータを充分利用することであり,各トレーニングデータもテストデータである.しかし,クロステストを戦略モデルのテストに適用する際には,明らかな欠点もある:
1.価格データが安定しない場合,モデルのテスト結果は信頼できない.例えば,2008年のデータでトレーニングし,2005年のデータでテストする.,2008年の市場環境は,2005年と比較して大きく変化している可能性が高いため,モデルのテスト結果は信頼できない.
- 第”項に似たように,交差点検では,最新のデータ訓練モデルを使用して,古いデータテストモデルを使用して,それ自体が論理的に合致しない.
- #### NO:05
また,対量化戦略モデルをテストする際には,帰帰推テストと交差テストの両方でデータ重複の問題が発生する.
取引戦略モデルの開発において,ほとんどの技術指標は一定の長さの歴史的データに基づいています.例えば,トレンド性指標を使用して,過去50日の歴史的データを計算し,次の取引日,この指標は,取引日の50日前のデータを計算すると,この2つの指標のデータは49日間同じです.これは,この指標の2つの隣接する日の変化が不明瞭になります.
データの重複は以下のような結果をもたらします.
モデルが予測した結果の遅い変化が, ポジションの遅い変化につながり, これが,私たちがよく指数の遅延性と呼ぶものです.
モデル結果のテストには,いくつかの統計値が使用できません.重複データによる序列関連性により,いくつかの統計テストの結果は信頼できません.
- #### NO:06
優れた取引戦略は,将来的に利益をもたらすことができるはずです. 試行錯誤テストは,取引戦略を客観的に検出するだけでなく,より効率的に客の時間を節約できます.
戦闘の際には,ほとんどの場合,全てのサンプルから直接最適のパラメータを採取し,戦闘に投入することは非常に危険です.
参数最適化が行われる時間点前のすべての歴史的データを区分して,サンプル内データとサンプル外データに分割し,最初にサンプル内データを使用して参数最適化を行い,次にサンプル外データを使用してサンプル外テストを行うと,このようなエラーを排出し,同時に,最適化後の戦略が将来の市場に適用されるかどうかを検査することができる.
- #### NO:07
取引と同様に,私たちは決して時間を越え,少しも間違いのない正しい決断を自分自身にすることはできません.神の手や将来から戻る能力があれば,テストされずに,直接オンラインの実物取引で,が満杯になります.そして,私のような凡人なら,歴史のデータで私たちの戦略をテストする必要があります.
しかし,膨大なデータを持つ歴史であっても,無限で予測不可能な未来に直面すると,歴史は極めて乏しく見えます.したがって,歴史に基づいて下から上へと押し上げられた取引システムは,最終的に時間の経過とともに沈没します.歴史は未来を無限にすることはできません.したがって,完全な正の期待取引システムは,その内在の原理/論理によって支えられなければなりません.

- #### NO:08
発明者 量化 量化取引プラットフォームは,現在,干ばつのない,交流が閉ざされた,詐欺師が横行する,現存する量化サイクルを,より純粋な量化サイクルに変えることを目指しています. この世界は,知識や理論を,誰も創り出さず,それらは,私たちが発見するのを待っている存在しているだけです.

共有は態度であり,知恵でもあります.
オンライン 作者:ハキボ