楽しく学ぶ機械学習: 初心者向け最もシンプルなガイド
 3
3605
3
3605
楽しく学ぶ機械学習: 初心者向け最もシンプルなガイド
機械学習の話を聞くと 曖昧な意味しかわからないのか? 友達と話すと 首を振り回すのが飽きたのか? 変えてみよう!
このガイドは,機械学習について興味を持ちながら,どうやって始めるかわからない人のために作られています. 機械学習についてウィキペディアの文章を読んだことがある人は,高レベルの説明ができないという挫折感を覚えるでしょう.
この記事の目的は,簡易性であり,多くの概要が載っていることを意味している。しかし,誰が気にするの?読者がMLに興味を持つようにすれば,任務は完了。
- ### 機械学習とは
機械学習の概念は,解くべき問題に対して,あなたが特別なプログラムコードを書かなくても,遺伝的アルゴリズムは,データセット上であなたのために面白い答えを得ることができる.遺伝的アルゴリズムの場合は,コードではなく,データを入力し,データの上に独自のロジックを構築する.
例えば,データを異なるグループに分割する分類アルゴリズムがある. 手書きの数字を識別する分類アルゴリズムは,コード一行も変更せずに,電子メールをスパムメールと普通メールに分割するために使用できる.アルゴリズムは変わっていないが,入力されたデータのトレーニングは変わっており,その結果,異なる分類ロジックが得られる.
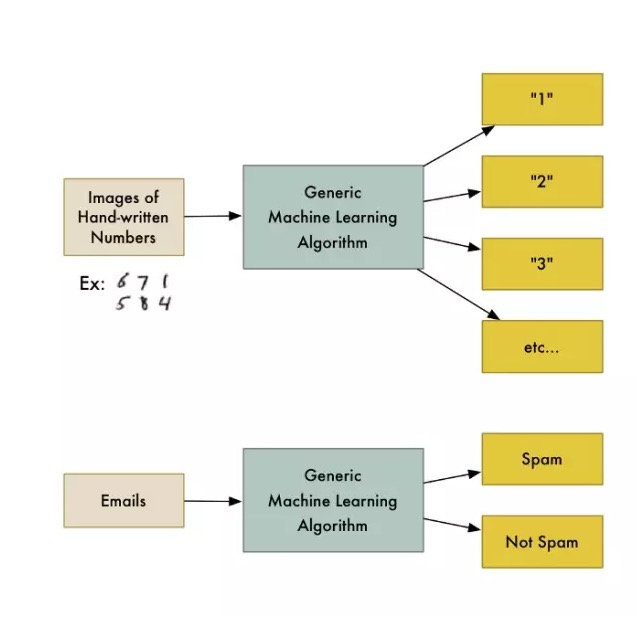
機械学習のアルゴリズムは,多くの異なる分類問題を解決するために再利用できるブラックボックスです.
機械学習のは,大量に似た遺伝的アルゴリズムをカバーする包括的な用語である.
- ### 機械学習のアルゴリズムの2種類
機械学習アルゴリズムは 監督学習 (supervised learning) と 無監督学習 (unsupervised learning) との2つのカテゴリーに分けられます 単純な違いですが 重要な違いです
-
監督学習
仮にあなたが不動産屋で 事業が大きくなるほど インターンシップを雇っているとします. しかし,問題は,あなたが一目でその家の価値を知ることができ, インターンシップは経験がないので, 評価方法がわからないということです.
インターンシップを手伝うために (もしかしたら休暇を取るために) ソフトウェアを作ることにしました 住宅の大きさや土地の面積や 似たような住宅の取引価格などの要素に基づいて 地域の住宅の価値を評価するソフトです
3ヶ月間,この街で起こった全ての住宅取引を記録し, 詳細を記録し, ベッドルームの数, 家の大きさ, 土地の面積などを記録した. しかし,最も重要なのは,最終的な価格を記録したことです.
これはの訓練のデータです
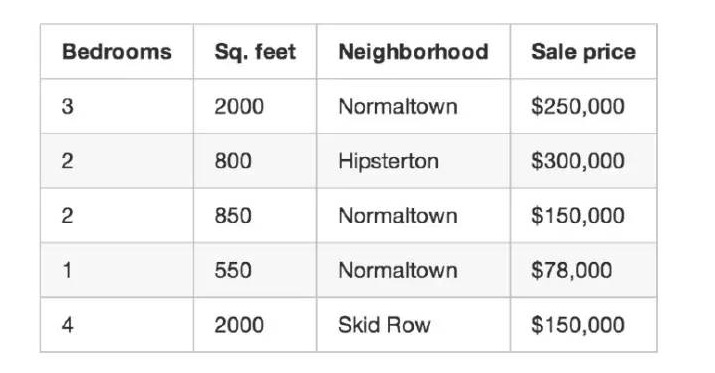
この訓練データを使って,この地域の他の住宅の価値を推定するプログラムを作成します.

これは”監督学習”と呼ばれています. 住宅の販売価格を既に知っています. つまり,問題の解答をご存知で, 逆の論理で解き明かすことができます.
ソフトウェアを書き出すために,あなたは,それぞれの不動産のトレーニングデータをあなたの機械学習アルゴリズムに入力します. 算法は,価格の数字を出すためにどのような操作をすべきかを試します.
これは算数の演習問題で,演算の符号は消去されています.
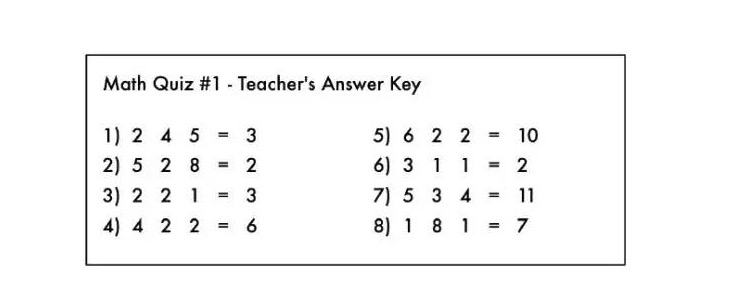
教師の答えから数学の記号を消した!
解答の左側の数字の列に何をすれば,右側の数字の列に答えが得られるか,わかりますか?
監督学習では,コンピュータに数字の関係を見せてくれるのです. そして,この特定の問題を解くために必要な数学的方法を知ったら,他の問題を解くことができます.
-
非監督学習
初めの不動産販売業者の例に戻りましょう. 住宅の販売価格が分からない場合, 家の大きさや位置などしか知らない場合でも, 素晴らしいデザインをすることができます. これは非監督学習です.
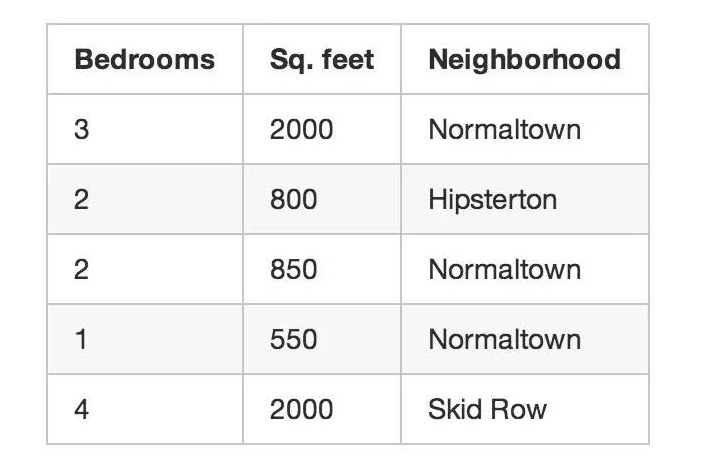
機械学習で面白いことが出来るのは,未知のデータ (価格など) を 予測する気にならずに,
それはまるで誰かが紙に書いてある 数字をあなたに渡して こう言うようなものです “この数字の意味はわからないけど 規則や分類などで 分かるかもしれない”
まず,アルゴリズムを使ってデータを分けて 市場を分けるのです.大学近郊の住宅購入者は 住宅のサイズが小さく,寝室が多く,郊外の住宅購入者は 住宅のサイズが大きく,寝室が3つあることがわかります.
素晴らしいことに 格差のデータ つまり 他のデータと異なる値を見つけることができます 格差のデータとは 高層ビルを指し 優秀なセールスマンを 高い手数料で集めるのです
この記事の残りの部分では,監視された学習が主として議論されますが,これは,非監視された学習が役に立たない,あるいは無意味であるからではありません.実際,アルゴリズムの改良により,データと正しい答えを結びつけなくても,非監視された学習はますます重要になってきています.
機械学習のアルゴリズムには,他の多くの種類がありますが,初心者にとっては理解が良いでしょう.
住宅価格の評価は”学習のつぼみ”として見られるのか?
人間として,あなたの脳は,ほとんどの状況に対応し,明確な指示なしに,それらの状況に対処する方法を学ぶことができます. あなたが不動産仲介者として長時間働いた場合,あなたは,不動産の適切な価格,その最高のマーケティング方法,どの顧客が興味を持つかなどについて,本能的な感を持っています. 強いAI (強いAI) の研究目標は,この能力をコンピュータで複製できるようにすることです.
しかし,現在の機械学習のアルゴリズムはあまり上手く機能していないので,非常に特定の,限られた問題だけに焦点を当てることができます.この場合,学習のより適切な定義は,少量の例示データに基づいて特定の問題を解決するための等式を見つけることです.
残念ながら,の機械は,少量の例示データに基づいて,特定の問題を解くための等式を見つけました.
もちろん,もしこの記事を50年後に読んでいたら,我々は強力な人工知能のアルゴリズムを手に入れただろうし,この記事は古物のように見えるだろう.未来の人類は,読まないで,機械の召使いにサンドイッチを作らせてくれ.
コードを書こう!
前の例の住宅価格の評価の手順は,どのように書こうと思いますか? 下へ進む前に,考えてみてください.
もし機械学習について何も知らないなら 家の価格を評価するための 基本的なルールを書き出してみるでしょう
def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood): price = 0 # In my area, the average house costs $200 per sqft price_per_sqft = 200 if neighborhood == "hipsterton": # but some areas cost a bit more price_per_sqft = 400 elif neighborhood == "skid row": # and some areas cost less price_per_sqft = 100 # start with a base price estimate based on how big the place is price = price_per_sqft * sqft # now adjust our estimate based on the number of bedrooms if num_of_bedrooms == 0: # Studio apartments are cheap price = price — 20000 else: # places with more bedrooms are usually # more valuable price = price + (num_of_bedrooms * 1000) return price価格が変わると 維持するのが難しいので 価格が変わると 維持するのが難しいのです
コンピュータが,この関数の機能を実現する方法を 見つけ出せたら,もっといいんじゃないでしょうか? 返された値が正しい限り,関数が具体的に何をするかなんて,誰が気にするでしょう?
def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood): price = <computer, plz do some math for me> return priceこの問題を考える一つの方法は,住宅価格を美味しいの鉢のように見ることです. の要素は,寝室の数,面積,地段です. もし,それぞれの要素が最終価格にどれだけ影響するか,計算できれば,おそらく,様々な要素が混ぜて最終価格の具体的な比率が得られます.
この例では,最初のプログラム (すべて狂ったif else文) を以下のようなものに簡略化できます.
def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood): price = 0 # a little pinch of this price += num_of_bedrooms * .841231951398213 # and a big pinch of that price += sqft * 1231.1231231 # maybe a handful of this price += neighborhood * 2.3242341421 # and finally, just a little extra salt for good measure price += 201.23432095 return price841231951398213,1231.1231,2.3242341421,および201.23432095の 魔法の数字に注意してください. これらは重量と呼ばれています. もし,すべての家に対して適用される完璧な重量を見つけることができれば, 機能はすべての家価を予測できます!
体重を計算する方法は以下の通りです.
ステップ1:
まず,それぞれの重さを1.0に設定します.
def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood): price = 0 # a little pinch of this price += num_of_bedrooms * 1.0 # and a big pinch of that price += sqft * 1.0 # maybe a handful of this price += neighborhood * 1.0 # and finally, just a little extra salt for good measure price += 1.0 return priceステップ2:
住宅の価値が正しい価格から どれくらい離れているかを調べるための関数です.
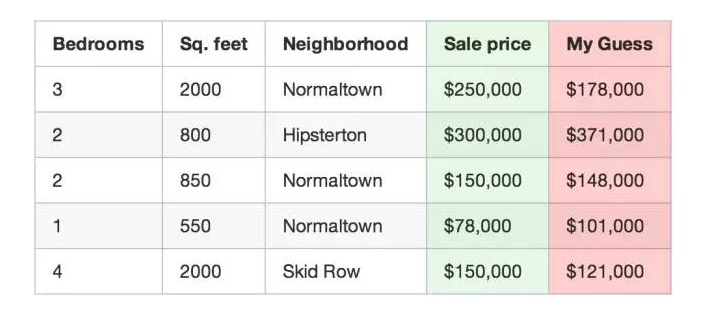
住宅価格を予測するプログラム
例えば,上記の最初の不動産の実際の取引価格は25万ドルで,あなたの関数は17万8千ドルで,この不動産は7万2千ドルです.
あなたのデータセットの各不動産の評価を偏離値の2乗に掛け合わせます. 500件の不動産取引を想定して, 総額は86,123,373ドルです. これは,あなたの関数の現在のの正確さを反映しています.
合計値を500で割ると,平均から偏った値が表示されます. 平均の誤差値をあなたの関数のコストと呼びましょう.
もし重量を調整して 0 に変えることができれば 機能は完璧です. つまり,入力されたデータに基づいて, プログラムが不動産取引の評価を正確にします. そして,これが私たちの目標です. 異なる重量値を試して,コストをできるだけ低くします.
ステップ3:
ステップ2を繰り返し,可能なすべての重量組み合わせを試す. どれがコストを0に最も近いものにするか,それはあなたが使用するものです. あなたがそのような組み合わせを見つければ,問題は解決されます!
思考が時間を奪う
3つの簡単なステップでデータを入力し,あなたの地域の住宅の価格を評価する関数が得られます. 住宅価格のネットワーク,注意してください! しかし,次の事実があなたの心を混乱させるかもしれません.
-
- 過去40年にわたる多くの分野 (言語学/翻訳学など) の研究により,この汎用的な動的なデータ (私が作った言葉) のような学習アルゴリズムは,実在の人間の明確なルールを利用する方法を上回っていることが示されています. 機械学習のは,最終的に人間の専門家を倒しています.
の面積との寝室の数を知らずに を振って数字を変えて 正解を出すだけです
-
- 特定の重力のセットがなぜ有効なのかわからない可能性が高い. だから,あなたが実際に理解していないが証明できる関数を書いただけです.
-
- あなたのプログラムが,面積と寝室のようなパラメータではなく,数値のセットを受け入れていることを想像してみてください. それぞれの数字が,あなたの車屋根のカメラで捕捉された画面のピクセルを表していると仮定し,予測された出力を価格ではなく方向盤の回転度と呼んで,あなたの車を自動的に操作できるプログラムを得ました!
狂ったように聞こえますよね?
ステップ3では,数字を1つずつ試す.
もちろん,全ての可能な重み値を試して,最良の組み合わせを見つけるのは不可能です. 試す数は無限にもなるので,長い時間がかかります. 数学者はこれを避けるために,数学の優れた重量を試す必要もなく,素早く見つけられるようにする,多くの賢い方法を考えました. 以下は,そのうちの1つです. まず,この2つのステップを表す簡単な方程式を書いてみましょう.
これはあなたのコスト関数です.
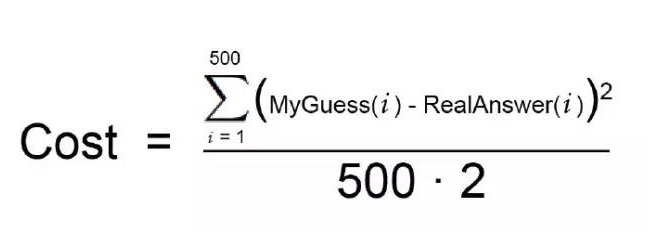
機械学習の数学用語 (今は無視できます) を書き換えてみましょう.
θは現在の重量を表す。 J ((θ) は,の現在の重量に相当する代価である。
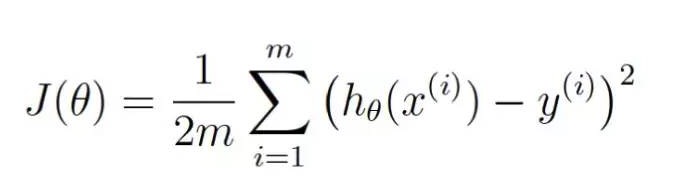
この等式は,現在の重量で私たちの評価手順の偏差の大きさを表しています.
ベッドルームの数と面積に割り当てられる全ての可能な重量をグラフ形式で表示すると,以下のようなグラフが得られます.
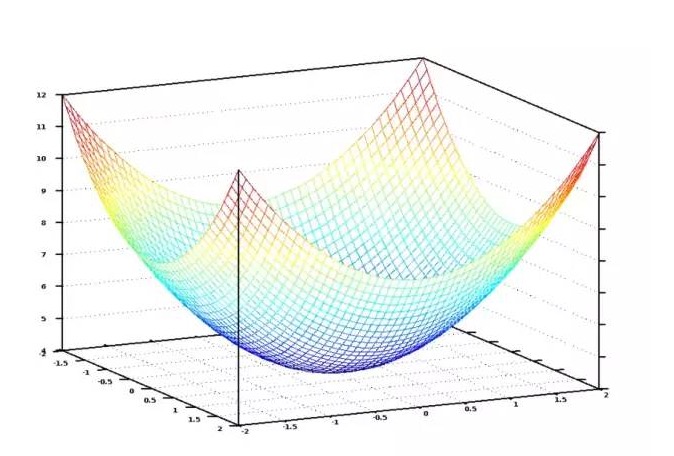
コスト関数のグラフィック画像の鉢.縦軸はコストを表す.
青の最小値は,コストの最小値,つまり, プログラムが最小の偏差を表示します. 高い点は,偏差の最大値を表します. だから,このグラフの最小値に導いた重さのセットを見つけることができれば, 答えを見つけました!
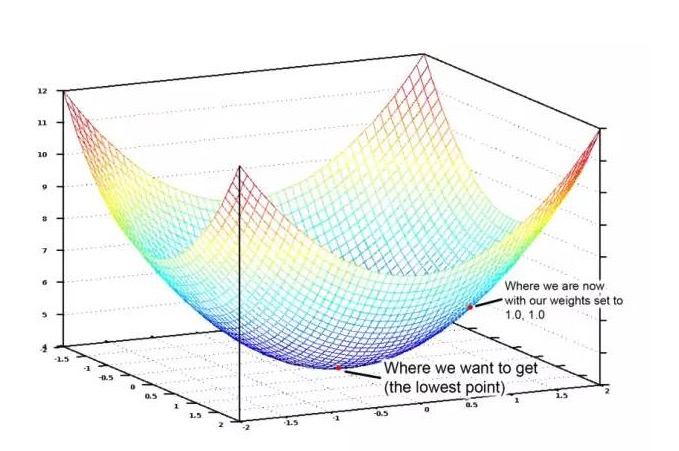
だから,重量を調整すれば,グラフの最低点に向かって下り坂を走るだけでいいのです.重さの微調整が,常に最低点に向かって動いてくれるなら,結局,重量を試す必要があまりないので,そこに着くことができます.
微積分を少しでも覚えていますか? 微積分を少しでも覚えていますか? 微積分を少しでも覚えていますか? 微積分を少しでも覚えていますか?
だから,もし,コスト関数に対して,それぞれの重量について偏導を求めると,それぞれの重量からその値を減算することができる.これによって,山の底に近づくことができる.これらを続けると,最終的に,私たちは山の底に到達し,重量の最高の値を得るだろう.
この最適重量を見つける方法は,量梯度下降と呼ばれています. 詳細を把握したい場合は,恐れてはいけません. 詳細を把握したい場合は,恐れてはいけません.
機械学習アルゴリズムのライブラリを使って実際の問題を解くとき,すべては準備が整っています.
余計なことは何ですか?
この3段階のアルゴリズムは多元線形帰帰帰と呼ばれています. 計算方程式は,すべての住宅価格のデータポイントを収納できる直線を求めています. そして,この方程式を使って,住宅価格があなたの直線上の可能性のある位置から,今まで見たことのない住宅の価格を推定します. この考えは,非常に強力で,実際のの問題を解くのに役立ちます.
しかし,私がお見せしたこの方法は,簡単な状況では有効ですが,すべての状況では有効ではありません. 理由の”つは, 価格が常に連続した直線に沿うのは簡単ではないからです.
しかし,幸運にも,この状況に対処する方法はたくさんあります. 非線形データについては,他の種類の機械学習アルゴリズムが扱うことができます (例えば,ニューラルネットワークや核ベクトルマシンなど). 線形回帰を適用する方法はもっと柔軟で,より複雑な線で適合する方法を考えます. すべての状況において,最適重量値を求めるという基本的な考え方は適用されます.
また,合致という概念を無視しました. 元のデータセットの家賃を完璧に予測できる重み集を簡単に見つけることができます. しかし,元のデータセットの外にある新しい家屋は予測できません. この状況の解決方法もたくさんあります (正規化やクロス検証データセットを使用するなど). この問題をどのように扱うかを知ることは,機械学習をうまく適用するために重要です.
つまり,基本概念はシンプルで,機械学習を活用して有用な結果を得るために,いくつかの技と経験が必要です. しかし,これはすべての開発者が学ぶことができる技です.
-
-
機械学習は限界がないのか?
機械学習の技術が 難しそうな問題 (手書き認識など) を 簡単に解決できるという感覚が 湧き上がると 十分なデータがあれば 機械学習でどんな問題でも 解決できるという感覚が 湧き上がるのです データを入力すれば コンピュータが 変数のように 適切な方程式を見つけ出すのです
しかし,覚えておくべき重要なことは,機械学習は,あなたが持っているデータで実際に解決できる問題に対してのみ適用されるということです.
例えば,あなたが家の中の植物の数を基に家賃を予測するモデルを作れば,それは決して成功しません.家の中の植物の数と家賃との間には何の関係もありません.それで,どんなに試しても,コンピュータは両者の間の関係を推論することはできません.
恋愛関係が現実のものだと モデル化するしかないのです
-
機械学習を深入的に学ぶ方法
私は,機械学習の最大の問題は,それが学術界と商業研究組織で活動していることだと思います. 専門家ではなく,一般的な理解を望む人々にとって,簡単な学習の材料はあまりありません. しかし,この状況は日々改善しています.
Courseraの機械学習の無料講座はとても良いものです.ここから始めることを強くお勧めします.コンピュータ科学の学位を持ちながら,少しでも数学を覚えていられる人は誰でも理解できるはずです.
また,SciKit-Learnをダウンロードしてインストールして,何千もの機械学習アルゴリズムを試すことができます.
Pythonの開発者からの転載