
機械学習アルゴリズムのツアー
機械学習の問題 (http://machinelearningmastery.com/practical-machine-learning-problems/) を理解した後,どんなデータを収集し,どんなアルゴリズムを使うかについて考えることができます.
機械学習の分野には多くのアルゴリズムがあり,それぞれのアルゴリズムは多くの拡張を持っているので,特定の問題に対して正しいアルゴリズムをどのように決定するか非常に難しい.この記事では,現実に遭遇するアルゴリズムを2つの方法でまとめたいと思います.
-
学習方法
経験,環境,あるいは我々が入力と呼ぶどんなデータにも応じて,アルゴリズムは様々なカテゴリーに分類されます. 機械学習や人工知能の教科書は,通常,アルゴリズムが適応できる学習方法を考慮します.
ここでは,いくつかの主要な学習スタイルまたは学習モデルについて説明し,いくつかの基本的な例があります. この分類または組織的方法は,入力データの役割とモデル準備のプロセスを考え,あなたの問題に最も適したアルゴリズムを選択し,最高の結果を得るように強制するため,良いものです.
監視学習:入力されるデータは,訓練データと呼ばれ,結果が知られ,または標記される.例えば,メールがスパムメールであるかどうか,または,期間中の株価であるかを言う.モデルが予測し,間違っていたら修正される.このプロセスは,訓練データに対して一定の正しい基準に達できるまで継続される.問題例には,分類と帰帰帰の問題,アルゴリズムの例には,論理帰帰帰と逆帰ニューラルネットワークが含まれている.
監視されていない学習:入力データは標識されず,結果も決定されません.モデルはデータの構造と数値を帰納します.問題例には,Association rule learningとクラグリングの問題,アルゴリズムの例には,AprioriアルゴリズムとK-平均アルゴリズムが含まれます.
半監督学習:入力データは,標識されたデータと標識されていないデータの混合であり,いくつかの予測問題があるが,モデルはデータの構造と構成も学習しなければならない.問題例には,分類と回帰の問題が含まれ,アルゴリズム例は,基本的には,無監督学習アルゴリズムの拡張である.
強化学習:入力データによってモデルが刺激され,モデルが反応する. 返答は,学習過程の監視学習からだけでなく,環境の報酬または罰から得られる. 問題例はロボット制御であり,アルゴリズムの例にはQ-learningやTemporal difference learningが含まれている.データシミュレーションのビジネス意思決定を統合する際には,大半は監督学習と無監督学習の方法を使用する.次の熱い話題は,半監督学習である.例えば,画像分類の問題で,問題には大きなデータベースがあり,しかし,画像のほんの一部しか標識されていない.強化学習は,大半がロボット制御およびその他の制御システムの開発に使用されている.
-
アルゴリズムの類似性
アルゴリズムは基本的には機能的または形式的に分類される.例えば,木ベースのアルゴリズム,ニューラルネットワークアルゴリズム.これは有用な分類方法であるが,完璧ではない.多くのアルゴリズムは,簡単に2つのカテゴリーに分けられるので,例えば,学習ベクトル定量化 (Learning Vector Quantization) は同時にニューラルネットワーククラスのアルゴリズムとインスタンスベースの方法である.機械学習アルゴリズムのモデル自体は完璧ではないように,アルゴリズムの分類方法も完璧ではない.
この部分では,私が最も直感的な方法だと考える分類のアルゴリズムを列挙しました. 私は,アルゴリズムや分類方法が尽きないわけではありませんが,読者に大まかな理解を与えることに役立つと思います.
-
Regression
Regressionは,変数間の関係に関心がある.それは,統計的方法が適用される.いくつかのアルゴリズムの例は,以下のとおりである.
Ordinary Least Squares
Logistic Regression
Stepwise Regression
Multivariate Adaptive Regression Splines (MARS)
Locally Estimated Scatterplot Smoothing (LOESS) -
Instance-based Methods
インスタンスベースの学習 (instance based learning) は,意思決定問題を模擬し,使用されたインスタンスまたは例はモデルにとって非常に重要です.この方法は,既存のデータにデータベースを構築し,新しいデータを追加し,その後,類似性測定法を使用して,データベースの中で最適なマッチを見つけ,予測を行う.この理由から,この方法は,勝者王方法とメモリベースの方法とも呼ばれています.現在の焦点は,データの保存された表現形式と類似性測定方法である.
k-Nearest Neighbour (kNN)
Learning Vector Quantization (LVQ)
Self-Organizing Map (SOM) -
Regularization Methods
これは他の方法の拡張である (通常は回帰方法),この拡張はより単純なモデルに有利で,帰納に優れている.
Ridge Regression
Least Absolute Shrinkage and Selection Operator (LASSO)
Elastic Net -
Decision Tree Learning
Decision tree methodsは,データ中の実値に基づいて意思決定するモデルを構築する. 決定木は,帰帰和と回帰の問題を解くために使用される.
Classification and Regression Tree (CART)
Iterative Dichotomiser 3 (ID3)
C4.5
Chi-squared Automatic Interaction Detection (CHAID)
Decision Stump
Random Forest
Multivariate Adaptive Regression Splines (MARS)
Gradient Boosting Machines (GBM) -
Bayesian
Bayesian method (ベイジアン・メソッド) は,分類と帰帰帰の問題を解く際にベイジアン定理を適用する方法である.
Naive Bayes
Averaged One-Dependence Estimators (AODE)
Bayesian Belief Network (BBN) -
Kernel Methods
Kernel Method (コアメソッド) の中で最も有名なのが,Support Vector Machines (サポートベクトルマシン) である.この方法は,入力データをより高い次元にマッピングし,いくつかの分類と回帰問題をより簡単にモデリングする.
Support Vector Machines (SVM)
Radial Basis Function (RBF)
Linear Discriminate Analysis (LDA) -
Clustering Methods
クラスタリング (clustering) は,問題と方法の表現である.クラスタリング方法は,通常,モデリング方法によって分類される.すべてのクラスタリング方法は,データを統一されたデータ構造で組織化して,各グループに共通点を最大限持てるようにする.
K-Means
Expectation Maximisation (EM) -
Association Rule Learning
アソシエーションルール・ラーニング (Association rule learning) は,膨大な多次元空間データ間の関連性を発見し,これらの重要な関連性を組織で利用できるような,データ間の規則を抽出するための方法である.
Apriori algorithm
Eclat algorithm -
Artificial Neural Networks
人工ニューラルネットワークは,生物のニューラルネットワークの構造と機能からインスピレーションを得ている.それはパターンマッチングの類であり,回帰と分類の問題に頻繁に用いられるが,何百ものアルゴリズムと変異によって構成されている.そのうちのいくつかは,古典的な一般的なアルゴリズムである (私は深層学習を別々に述べる):
Perceptron
Back-Propagation
Hopfield Network
Self-Organizing Map (SOM)
Learning Vector Quantization (LVQ) -
Deep Learning
ディープ・ラーニング (Deep Learning) 方法は,人工ニューラル・ネットワークの現代的な更新である.従来のニューラル・ネットワークに比べて,より多くの複雑なネットワーク構成があり,多くの方法が半監視学習に関心があり,この種の学習の問題には大きなデータがあるが,その中の標識されたデータは少ない.
Restricted Boltzmann Machine (RBM)
Deep Belief Networks (DBN)
Convolutional Network
Stacked Auto-encoders -
Dimensionality Reduction
Dimensionality Reduction (次元縮小) は,集群法のように,データ内の統一的な構造を追求し,利用するが,それより少ない情報を用いてデータを归納し,記述する.これはデータを可視化したり,データを簡略化したりするのに有用である.
Principal Component Analysis (PCA)
Partial Least Squares Regression (PLS)
Sammon Mapping
Multidimensional Scaling (MDS)
Projection Pursuit -
Ensemble Methods
Ensemble methodsは,多くの小さなモデルで構成され,これらのモデルが独立に訓練され,独立した結論を導き,最終的に全体的な予測を構成する.多くの研究が,どのようなモデルを使用するか,そしてこれらのモデルがどのように組み合わされるかに焦点を当てている.これは非常に強力で一般的な技術である.
Boosting
Bootstrapped Aggregation (Bagging)
AdaBoost
Stacked Generalization (blending)
Gradient Boosting Machines (GBM)
Random Forest
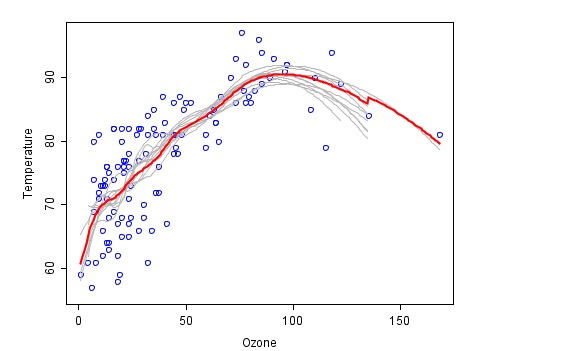
これは組み合わせの方法によるフィットネスの例で,それぞれの消防法が灰色で示され,最終合成の最終予測は赤色で示されています.
-
その他の資源
この機械学習アルゴリズムの旅は,あるアルゴリズムと関連付けアルゴリズムのいくつかのツールについての概観をあなたに与えることを目的としています.
以下は他にもいくつかのリソースです. あまり考えすぎないようにしてください. アルゴリズムの知識が多ければ多いほど有益です. しかし,いくつかのアルゴリズムの深い知識も有用です.
- List of Machine Learning Algorithms (機械学習アルゴリズムのリスト) は,ウィキペディアに載っている資源ですが, 詳細はありますが,分類はよくないと思います.
- Machine Learning Algorithms Category: これはウィキペディアにもあるもので,上記より少し良いもので,アルファベットで並べています。
- CRAN Task View: Machine Learning & Statistical Learning: 機械学習アルゴリズムのR言語の拡張パックで,他の人が何を使用しているか理解するのに役立つものを比較してみましょう.
- Top 10 Algorithms in Data Mining: これは,最も人気のあるデータマイニングアルゴリズムを含む,出版された記事 (Published article),現在は本 (book) である. もう一つの基本的なアルゴリズムのリストは,ここに列挙されているアルゴリズムはあまり多くありません.
投稿者: ベル・コラム / 大飛 Python 開発者
- 1