
ビッグデータ基金の発表
本日の科学投資記事では,ビッグデータファンドの原理について,また,淘宝,百度,新浪などのインターネットデータがどのようにファンドマネージャーに株式の選択を助けているかについて説明します.
-
ビッグデータ・ファンドを紹介する前に,典型的な株式型ファンドの株式選択手順を見てみましょう.
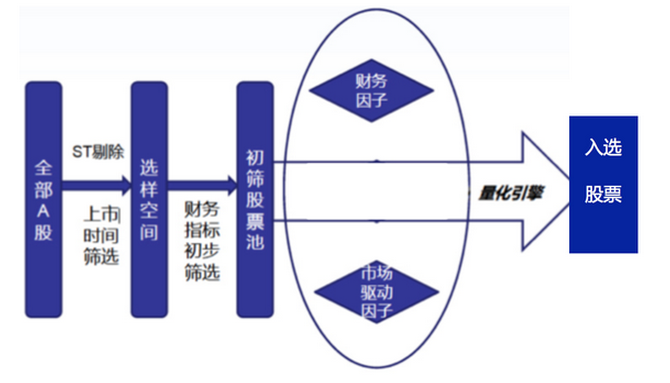
すべてのA株から初<unk>のサンプルスペースを抽出し,初<unk>基準は一般的には上場時間,市場価値などのより基本的な指標を採用する.
サンプルスペースから初心者株のプールを選択する.この選択条件は,業界データ,財務指標,収益性などを使用する.初心者株のプールは,多因子株選択モデルのサンプルとして使用されます.
多因子株選択モデルを用いて株を定量的に選択する.従来の多因子モデルで採用される要因は,主に金融要因 (市場<unk>率,市場純率,市場販売率,資産市場価値比率,主事業収入成長率,純利益成長率,EPS成長率,総資産成長率など) と市場駆動要因 (短期利回り率,長期利回り率,特定の変動率,取引量変化,自由流通市場価値など) を含む.上記のすべての要因に基づいて,長期の歴史的リターンと安定性が加算され,単一の株の総合分数のみが計算される.
QEの学習により,ファンドの構成株と相応の重量を計算する.大型データファンドは従来型のファンドとは違う.大型データファンドは,大型データファクターを取り入れている.
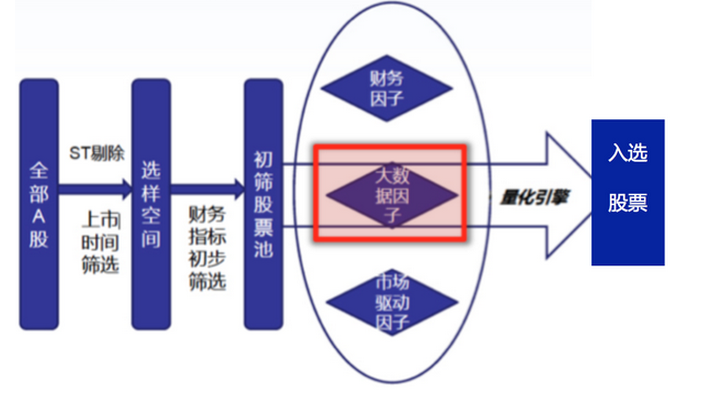
以前は,多因子株選択モデルを作るとき,採用した要因は全て市場内部からで,我々は株そのものの性質のみを重視した.しかし,ビッグデータ要因の導入は,新しい情報をもたらし,我々は百度検索量の変化と株の変化が関連しているかどうかを注目する.我々は,淘宝の特定の業界の売上高が業界内の企業の株価に影響しているかどうかを注目する.また,我々は,新浪金融部門の特定の株に関連するニュースの読者数とコメントの数の株価の変動の影響があるかどうかを注目する.
この例は,実際のビッグデータファンドを例に挙げて,ビッグデータの要素をより理解できるようにします.
この例は,Borse Foundationと<unk>金服が共同で発表した淘金大データ100です.
サンプルスペースを構成する際,タウ金大データ100は,ネット電商商品カテゴリに関連する中証第3級業界の関連株をサンプルスペースとして選択し,以下のカテゴリを含む.
- 耐久性のある家用品
- 休憩用品
- 繊維と衣類
- ホテルのレストランとレジャー
- 食料・生活用品の小売
- 食品や飲料
- 家電
- 個人用品
-
淘宝のデータから得られるビッグデータにより,これらの業界でより多くの情報を提供できるため,これらの業界と淘宝の商品分類が非常に似ています.
淘宝関連産業のサンプルスペースに基づいて,博覧基金と<unk>金服は,多因数量化モデルに<unk>集源電商大データ因子を使用した選択株を生成した.その中では,Alipay金融情報サービスプラットフォームは,オンラインの消費者級統計型トレンド特有のデータを提供している.収入産業投資指標,成長,価格,供給状況などを含む総合考察産業の景気度が行業景気度ランキングで進んでいる.景気度が業界内の株式に相応の評価を与え,集源電商大データ因子で得ている.
最後に,量的な株式選択モデルは,ビッグデータ因子,財務因子,市場駆動因子を利用して株式の打分ランキングを行い,ビッグデータファンドの構成株と重量を決定する.
淘金100指数に加えて,各ビッグデータファンドは,百度,雪球,新浪,銀联など多くのビッグデータソースを利用してビッグデータファクタを生成する.中証指数有限会社から提供される公開資料を通じて,各ビッグデータファンドが利用するファクタは以下の通りである.
百发100指数<unk>の検索因子
サンプルスペースの株式に対して,それぞれ,近月の検索総量と検索増量を計算し,それぞれ,総量因数と増量因数として記す.検索総量因数と増量因数に対して,検索総量因数と増量因数として記す因数分析モデルを構築し,各期間の各株の総合スコアを計算し,検索因数として記す.
雪球の熱因因子100トン
まず,ステップ2で得られたスノーボール智能ポートフォリオに基づいて,選択されるサンプルの智能ポートフォリオのカバー度を計算する.次に,各株の智能ポートフォリオのカバー度に基づいて,各株の雪球熱因数得点として,株式に相応の評価を与えます.
南シナ大データ<unk> シナナ大データ因子
新浪経済チャンネルのページ閲覧数,微博のポジティブ・ネガティブ・記事報道,ニュース報道の影響.
ビッグデータインデックスとビッグデータ因子
銀行連盟の消費類統計型トレンド特有のデータに基づいて,行業投資指標が処理され; 次に,所得行業投資指標に基づいて,消費額,取引回数などを含む総合調査行業の景気度が行業景気度ランク付けされ; 最後に,景気度に基づいて,行業内の株式に相応の評価が与えられ,行業ビッグデータ因子が得られた.
多くの知人が,ビッグデータファンドのパフォーマンスは実際は好意的ではないと考えている.実際,これまで,いくつかのビッグデータファンドのパフォーマンスは,当初期待した結果には達していない.しかし,これは,ビッグデータファンドが間違った方向にあるという結論を導くことはできません.現在,ビッグデータファンドのアプリケーションは,まだ保守的で,実験的であるため,私たちは,伝統的な多要素モデルに基づいてビッグデータファクターを追加しただけで,モデル自体にはより多くの破壊的なイノベーションを導入していません.そして,ビッグデータファクターの処理は,文法分析,感情分析,トピックモデルなど多くの自然言語処理と機械学習の分野に含まれています.
実際,ビッグデータの応用は,私たちの生活のあらゆる側面に触れています. 投資価値のある宝物が意図せずそこに隠されています. 既存のビッグデータファンドの業績は,これらの価値を効果的に掘り出す能力を持っていることを示していません. しかし,ビッグデータの宝物は,そこにあります.
科学投資 検証された投資
- 1