正規表現を体系的に学ぶ(I):基礎編
 2
3118
2
3118
正規表現を体系的に学ぶ(I):基礎編
正規表現とは何か 正規表現は,事前に定義された特定の文字と,これらの特定の文字の組み合わせを用いて,規則文字列のを構成し,文字列に対するフィルタリング論理を表現するものである.
- 正規表現は以下の目的を達成します.
给定的字符串是否符合正则表达式的过滤逻辑(称作“匹配”);
可以通过正则表达式,从字符串中获取我们想要的特定部分。
Regextorは,正規表現の検証ソフトで,Mac用の良いソフトも紹介しています. Regextorは,正規表現の検証ソフトです. Regextorは,正規表現の検証ソフトです. Regextorは,正規表現の検証ソフトです.
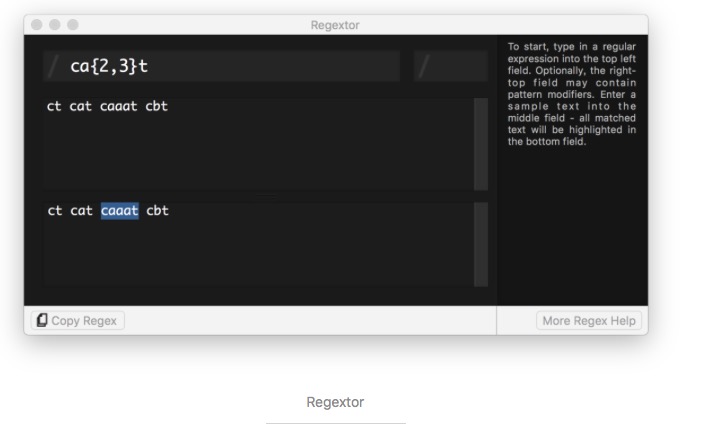
正規表現のルールについて説明するのは,以下から始まります.
- #### 文字にマッチする
正規表現は,このテキストに正確にマッチする表示として,通常のテキストのみを含むことができる.例えば:
公式表現:song
投稿者:小松江 投稿者:小松江 投稿者:小松江
xiao さんsongge,xiaoSongge
正規表現のデフォルトは,大文字を区別するので,songは”Song”にマッチしない。しかし,ほとんどの正規表現の実装は,大文字を区別しないというオプションを提供している。
- #### 任意の文字にマッチする
. は任意の文字にマッチする.
正式表現:c.t
追記 追記 追記 追記
試合結果:cat cet caaat dog
解析:c.t は”c”で始まり”,t”で終わり,中間は任意の文字の文字列にマッチする.
同様,複数の連続. 複数の連続の任意の文字にマッチすることができます:
正式表現:c..t
テキストをマッチする: cat cet caat dog
カット・セットcaat dog
- #### 特殊文字にマッチする
.は正規表現で特殊な意味を含んでいる,特殊な文字である。\は特殊な文字でもあり,特殊な文字に翻訳作用をすることができる。もし,本当の” . “文字と一致させたいなら,前.に\を加えて文字に翻訳する。だから,.文字の” . “は” . . “を表しています.
正規表現:c.t
テキスト: cat c.t dog
マッチングの結果:catc.t dog
注意:\ は特殊文字なので,実際の”\ “とマッチするには2つの反斜線が必要です.\:
正規表現:c\t
テキスト: cat c\t dog
マッチングの結果:catc\t dog
- #### 文字集合を使用する
任意の文字にマッチングできますが,特定の文字にマッチングしたい場合はどうでしょうか?[そして [元文字。
正規表現:c[ab]t
テキスト: cat cbt cet
試合結果:cat cbt cet
分析:[“a”と”b”が一致するので,cは[ab]tは”cat”と”cbt”にマッチするが”cet”にはマッチしない.
- #### 文字列の区間を使用する
上の例では,cetをマッチさせたい場合,[任意の小文字にマッチさせたいなら,何十文字でも書けますか? それはいいですが,長すぎます.[a-z]:
正規表現:c[a-z]t
cat cbt czt c2t のテキストをマッチする
試合結果:cat cbt czt c2t
分析:c[a-z]tは”c”で始まり”,t”で終わり,中間は文字”a” - “z”の任意の文字を表す.
ブログのページには,こんな格差があります.
[0−9] と[0123456789]の機能と同じ。全ての数字にマッチする。 [A-F]は,AからFまでの大文字にマッチする。 [A-Z]は,AからZまでの大文字に一致する。 [a-z]は,aからzまでの小文字すべてにマッチする。 [A-z]は,ASCII AからASCII zまでのすべての文字をマッチします.[^ ほか) 。 [[A-Za-z0-9] すべての大文字と数字にマッチする。
- #### 非文字セットのマッチング
文字集合は,通常,マッチングが必要な文字のグループを指定するために使用される。しかし,時には,あなたがマッチングしたくない文字のグループを除外したい。文字集合の否定によって実現することができる。例えば:
正規表現:c[^a-z]t
cat cbt czt c2t cAtのテキストをマッチする
マッチングの結果:cat cbt cztc2t cAt
分析:前例とは正反対です.[文字が1つずつ並びます.[^a-z] は,小文字以外のすべての文字にマッチする。
^ 文字は,文字集合内のすべての文字を不一致にする.
- #### 元文字
正規表現の元文字には特殊な意味があります. 例えば,[文字は直接意味を表現できない.例えば,直接使用できない.[素晴らしいアイデアです[” “
すべての元文字は,前面に反斜線変換を加えてもよい.変換されたとき,文字は,その特殊な意味ではなく,それ自身にマッチする.例えば,[組み合わせる”[ “:
正規表現:a[b
テキストをマッチする[b ab a[[b
試合結果:a[b ab a[[b
注意:\ は元文字の転写用で,\ も元文字であることを意味する.したがって,もし真”\“と一致する必要があるなら,\ を使うことができます.\:
正規表現:a\b
テキストをマッチする\b a\b a[[b
a の結果です.\b a\b a[[b
- #### 空白文字
テキストで印刷できない空白の文字をマッチする必要がある場合もあります.例えば,すべてのTab文字,またはすべての行変更符を見つけることを望みます.
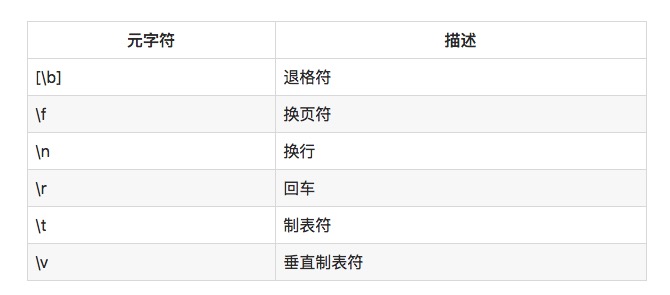
たとえば,\r\nは,回転の交換組合せにマッチングし,Windowsでファイル交換を表します.LinuxやUnixシステムでは,\nのみを使用する必要があります.
- #### 特定の文字タイプにマッチする
特殊な元文字が,一般的な文字集合にマッチングするために使用できます.これらの元文字は,マッチング文字クラスと呼ばれます.あなたはそれらを使用して便利であることに気づくでしょう.
数字と非数字が一致する この写真の写真家は,[0-9] すべての数字にマッチできます. 番号をマッチしたくない場合は,[^0-9]。 下の表は,数字と非数字の元文字を列挙している.

正規表現:c\dt
cat c2t czt c9t のテキストをマッチする
マッチングの結果:catc2t czt c9t
正規表現:c\Dt
cat c2t czt c9t のテキストをマッチする
試合結果:cat c2t czt c9t
アルファベットと非アルファベットのマッチング
クラスメータとしてよく使われるのは\wと\Wです.
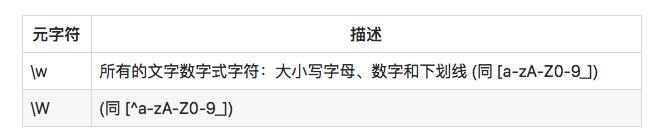
正規表現:c\wt
cat c2t czt c-t c\t テキストにマッチする
試合結果:cat c2t c-t c\t
正規表現:c\Wt
テキスト: cat c2t c-t c\t
マッチングの結果:cat c2tc-t c\t
空白と非空白をマッチする
検索した結果,検索した結果と一致する.

正規表現:c\st
テキストのマッチング待機:cat c t c2t c\t
マッチングの結果:catc t c2t c\t
正規表現:c\St
テキストのマッチング待機:cat c t c2t c\t
試合結果:cat c t c2t c\t
- #### 1 つ以上の文字にマッチする
+元文字は,1つまたは複数の文字をマッチすることを意味する.例えば,aは”a”にマッチし,a+は1つまたは複数の”a”にマッチする.
正式表現:cat
テキスト:ct cat caat caaat
ct による結果cat caat caaat
正規表現:ca+t
テキスト:ct cat caat caaat
ct による結果cat caat caaat
文字集合で+を使うときは,+記号を集合の外に置く必要がある:
正規表現:c[0-9]+t
ct c0t cat c123t テキストにマッチする
ct による結果c0t cat c123t
分析:c[0-9]+tは”c”で始まり”,t”で終わり,中央に1つまたは複数の数字の文字列を表します.
もちろん,そうでした.[0-9+]も合法的な正規表現ですが,これは “0” - “9”と”+“の記号を含む文字集合を表します.
一般的に,元文字である . と+ などは文字集合のときに文字の意味として用いられるので,翻訳する必要はありません. しかし,翻訳することもOKです.[0−9+]と[0-9+機能は同じです.
注意:+は元文字で”,+“にマッチするには変換が必要です.+。
- #### 文字が0以上で一致する
文字を0文字以上でマッチさせたい場合は,*文字は
正規表現:ca*t
ct cat caat cbt テキストをマッチする
試合結果:ct cat caat cbt
知らせ:符号は元文字である. ““と一致するためには,変換が必要である.*。
- #### ゼロと1つの文字にマッチする
文字に 0 か 1 をマッチする. 文字に 1 をマッチする.
正式表現:ca?t
ct cat caat cbt テキストをマッチする
試合結果:ct cat caat cbt
注意: ? 記号は元文字である。 ” ? “ と一致するためには,変換が必要である.?。
- #### マッチング回数
正規表現は,マッチの回数を指定することを許します. {と } の間での回数を指定することができます. 注意:{と}は元文字であり,文字の意味を使う場合の翻訳が必要である.
正確なマッチ数 匹配する回数を指定するために,{ と} の間の数字を入力できます.例えば,{ 3} は,前3回登場した文字または集合に匹配します.
正規表現:ca{3}t
ct cat caaat cbt 関連記事
試合結果:ct catcaaat cbt
最低のマッチ数
また,最小のマッチの値のみを指定することもできます.例えば,{2,} は 2 回またはそれ以上のマッチを意味する:
正規表現:ca{1,}t
ct cat caaat cbt 関連記事
ct による結果cat caaat cbt
次元の間のマッチング
また,最小値と最大値を使用してマッチの数を決定することもできます.例えば,{2,3}は最小2回マッチ,最大3回マッチを意味します.
正規表現:ca{2,3}t
ct cat caaat cbt 関連記事
試合結果:ct catcaaat cbt
そして,この2つの関数は同じです.
- #### 非貪欲なマッチング
この例を見てください.
正式表現:s.*g 投稿日: 2016年3月16日 投稿者: 投稿者: 試合結果:xiao song シャオ・ソング 分析:s.*gは2つの”song”をマッチするのではなく,最初の”s”と最後の”g”の間のすべてのテキストをマッチする.
原因は*そして+は貪欲なマッチである。つまり,正規表現は常に最小のマッチではなく最大のマッチを探している,これは意図的に設計されている。
しかし,貪欲なマッチングを避けたい場合は,これらの量語の非貪欲なマッチングを使用してください. 非貪欲なマッチングは量語の後に追加されます:

*そうか*このサイトは,Googleの非貪欲なバージョンで利用できます.*上記の例を修正するために:
正式表現:s.?g
投稿日: 2016年3月16日 投稿者: 投稿者:
試合結果:xiaosong xiao song
分析:sが表示される“G”は2つの”Song”にマッチした.
- #### 文字列の境界を定義する
文字列の境界にマッチする元文字は,^と$で,文字列の開始と終了をそれぞれ用いる.
^ ユースは以下の通り.
正式表現:^xiao
記事の内容は,
試合結果:xiaosong
投稿者: 松本 恵子 投稿者: 松本 恵子 試合結果: フォリフォリ 解析:^xiao が “xiao” で始まる文字列にマッチする.
$ は以下のように使われます.
公式表現:song$
記事の内容は,
xiao さんsong
記事の内容は, 試合結果: シャオソンガ 解析: song$ が song で終わる文字列にマッチする.
共有されている:
正規表現:^[0-9a-zA-Z]{4,}$
a1b234ABC テキストをマッチする
試合結果:a1b234ABC
テキストをマッチする:+a1b23=4ABC 配列を足した結果:+a1b23=4ABC 分析: ^[0-9a-zA-Z]{4,}$は数字または文字で構成され,桁数が4桁の文字列よりも大きい.
注意:^ 集合の先にある場合,負を表す.集合の外にある場合,文字列の先の位置にマッチする.[そして^0−9です.[0−9]の違い
- #### 多行モードを使用
しかし, ((?m) は複数行モードを有効にする.複数行モードでは,正規表現エンジンは,文字列の切り離し符として交換符を用い,^はテキストの開始または一行の開始にマッチングし,$はテキストの終了または一行の終わりにマッチングすることができる.
前の例を修正する.
正式式は, (m) ^です.[0-9a-zA-Z]{4,}$
a1b234ABC テキストをマッチする +a1b23=4ABC ABC123456
試合結果:a1b234ABC
+a1b23=4ABC
ABC123456
分析: (m) ^[0-9a-zA-Z]{4,}$は,数字または文字で構成され,桁数が4桁以上の文字列にマッチします.
注意:複数行モードを使用する場合, ((?m) は正規表現の開始に置く必要があります。 (? m) は,ほとんどのレギュラーエクスプレッション実装ではサポートされていません。一部のレギュラーエクスプレッション実装では,\Aのマッチング文字の開始,\Zのマッチング文字の終了を使用することもサポートされています。サポートされている場合,これらの元文字の機能は,^、$と同じです。しかし,これらの元文字は ((? m) 修飾を使用できません.したがって,多行モードにも使用できません。
この基礎を踏まえて,次の”正規表現を体系的に学ぶ方法”をご覧いただけます.
松岡小三郎の『iOS』より