機械学習を理解するための 3 つの図: 基本概念、5 つの主要な流派、9 つの一般的なアルゴリズム
 0
2546
0
2546
機械学習を理解するための 3 つの図: 基本概念、5 つの主要な流派、9 つの一般的なアルゴリズム
- #### 機械学習の概要

機械学習とは何か?
機械は大量のデータを分析することで学習する.例えば,猫や人の顔を認識するためにプログラムする必要はありません. 特定のターゲットを集約し認識するために,画像を使用して訓練することができます.
機械学習と人工知能の関係
機械学習 (Machine learning) は,データからパターンを探し,そのパターンを用いて予測する研究とアルゴリズムを研究する分野である.機械学習は人工知能の領域の一部であり,知識発見とデータマイニングと交差している.
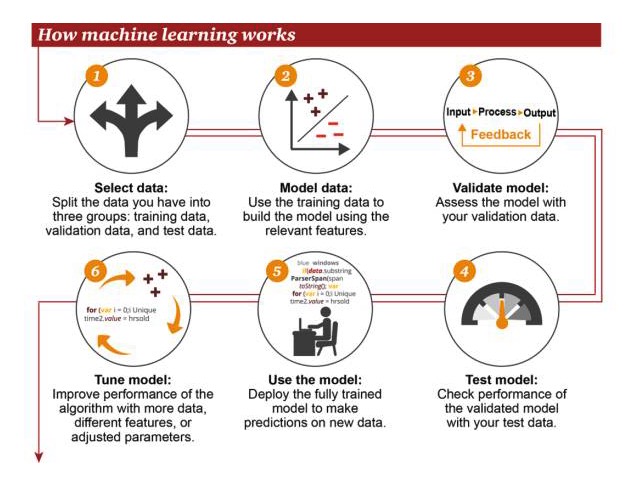
機械学習の仕組みについて
1 選択データ: あなたのデータを3つのグループに分けます 訓練データ 検証データ テストデータ 2 モデルデータ: トレーニングデータを用いて関連特性を用いたモデルを構築する 3 検証モデル: あなたの検証データをあなたのモデルにアクセスする 4 テストモデル: テストデータを使って検証されたモデルのパフォーマンスをチェックする 5 モデルを使用:新しいデータに対して予測するために完全に訓練されたモデルを使用する 6 調節モデル:より多くのデータ,異なる特性,または調整されたパラメータを使用してアルゴリズムのパフォーマンスを向上させる
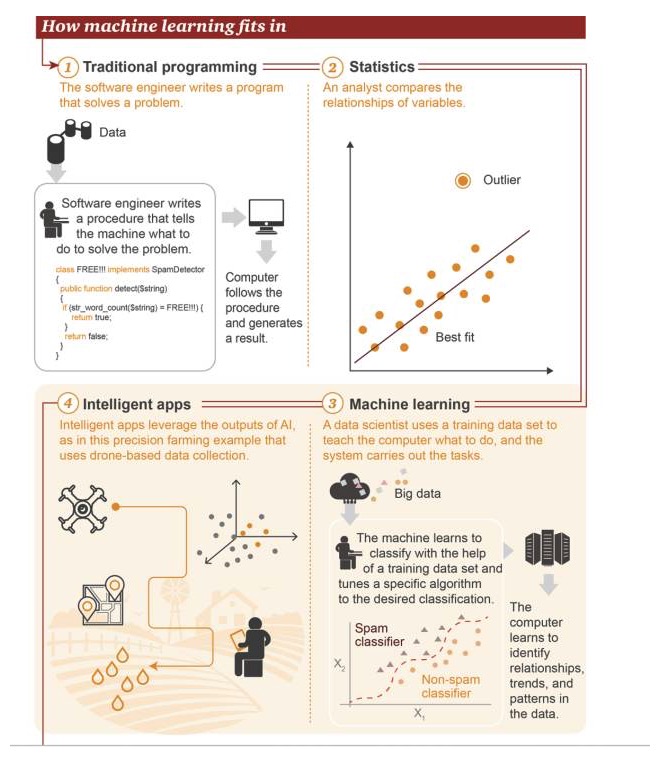
機械学習の位置づけ
1 伝統的なプログラミング:ソフトウェアエンジニアは問題を解くためにプログラムを書きます. まず,いくつかのデータがあります. → 問題を解くために,ソフトウェアエンジニアは,機械に何をすべきかを伝えるプロセスを書きます. → コンピュータは,このプロセスを実行し,結果を出します. 2 統計学:分析者が変数間の関係を比較する 3 機械学習:データ科学者は,トレーニングデータセットを使用してコンピュータに何をすべきかを教え,システムがそのタスクを実行する. まず,ビッグデータがある→機械は,トレーニングデータセットを使用して分類を行うことを学び,ターゲット分類を実現するために特定のアルゴリズムを調節する→コンピュータは,データ内の関係,傾向,パターンを認識することを学ぶ 4 スマートアプリケーション: スマートアプリケーション 人工知能を用いて得られる結果,図は精密農業のアプリケーションケースを示し,このアプリケーションは無人機によって収集されたデータに基づいている

機械学習の実用化
機械学習には様々な応用があり,その例をいくつか紹介します.
急速3Dマッピングとモデリング: 鉄道橋の建設には,PwCのデータ科学者と分野の専門家が機械学習をドローンから収集されたデータに適用します. この組み合わせは,作業の成功の正確な監視と迅速なフィードバックを実現します.
リスクを下げるための強化分析:PwCは,内部取引を検出するために,機械学習と他の分析技術を組み合わせ,より包括的なユーザープロフィールを開発し,複雑な疑わしい行動をより深く理解します.
予想ベストパフォーマンス目標:PwCは,機械学習およびその他の分析方法を使用して,メルボルンカップの競技場で異なる競馬の潜在能力を評価する.
- #### 2 機械学習の進化

数十年もの間,人工知能の研究者の”部族”は,支配権を争ってきました. 部族が団結する時が来たのでしょうか? 共同作業とアルゴリズム融合が,真の汎用人工知能 (AGI) を実現する唯一の方法であるため,彼らはそれをしなければならないかもしれません.
五大流派
1シンボル主義:知識を表し,論理的推論を行うために,記号,規則,論理を使用する.最も好ましいアルゴリズムは,規則と意思決定ツリーである. 2ベイエス派:発生の確率を得て確率推論を行う.最も好まれるアルゴリズムは:素朴なベイエスかマルコフ 3連結主義:確率マトリックスと重量化されたニューロンを用いて動的にパターンを識別し帰納する.最も好みのアルゴリズムは:ニューラルネットワーク 4 進化主義:変化を生成し,その中で特定の目的のために最適を採取する.最も好ましいアルゴリズムは:遺伝的アルゴリズム 5 Analogizer: 条件を条件に合わせて関数を最適化する ((できるだけ高いところまで行け,しかし同時に道から離れないようにする)),最も好きなアルゴリズムは: ベクトルマシンをサポートする
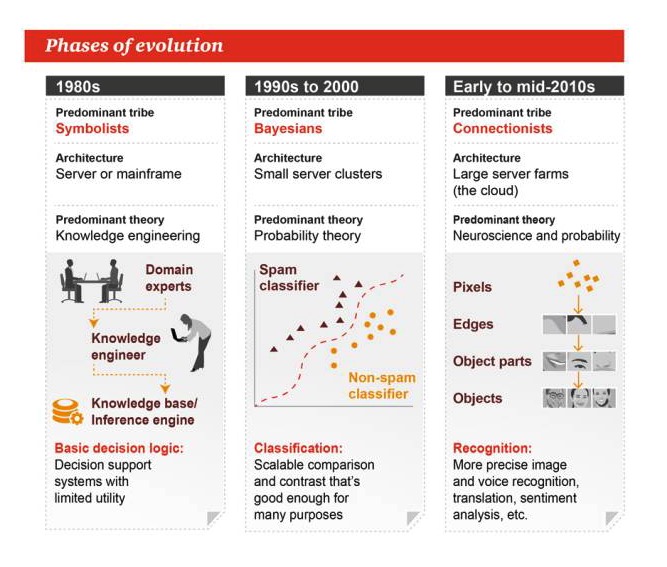
進化の段階
1980年代
主流派:シンボル主義 構造:サーバーまたは大型コンピュータ 主要な理論は 知識工学です 基本的な意思決定の論理: 意思決定支援システム,実用性は限られている
1990年代から2000年
流行:ベイエス アーキテクチャ:小型サーバー集群 確率論が支配する理論 分類:拡張可能な比較や対照は,多くのタスクに適しています
2010年代前期から中期
主流派:連結主義 構造:大型サーバーファーム ニューロサイエンスと確率 画像や音の認識や 翻訳や感情の分析など
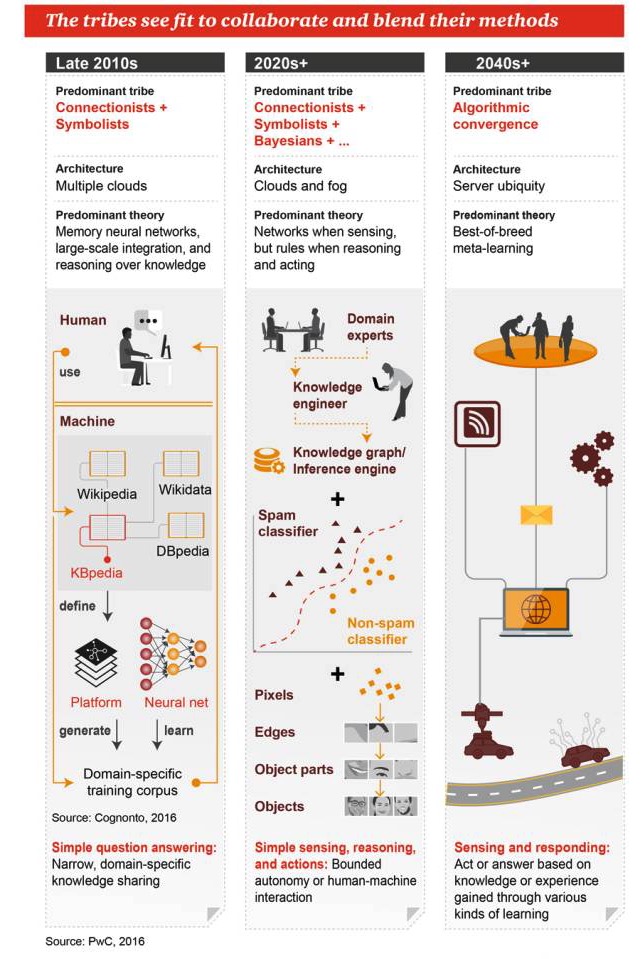
この2つの派閥は協力し合い,それぞれの手法を融合させることを期待しています.
2010年代後半
主流派:連結主義とシンボル主義 構造:多くの雲 主要な理論:記憶神経ネットワーク,大規模統合,知識に基づく推論 シンプルな質問と答え: 狭い範囲で,特定の分野での知識の共有
2020年代+
ユネティズム+シンボリズム+ベイアス+… アーキテクチャ:クラウドコンピューティングと霧コンピューティング 支配的理論: 認識にはネットワークがあり, 推論と作業には規則がある 単純な知覚,推論,行動: 限られた自動化や人間と機械の相互作用
2040年代+
主流ジャンル:アルゴリズム融合 インフラストラクチャ: どこにでもいるサーバー 優良な組み合わせのメタ学習 認知と応答:複数の学習方法から得られた知識や経験に基づいて行動または回答する
- #### 機械学習のアルゴリズム

どれだけの機械学習アルゴリズムを使うべきか? これは,利用可能なデータの性質と量,そして,それぞれの特定の用例におけるあなたのトレーニング目標に大きく依存する. 費用や資源を高額に支払う結果がなければ,最も複雑なアルゴリズムを使用しないでください.
意思決定木 (Decision Tree):ステップレスポンスを行う過程で,典型的な意思決定木分析は,階層変数または意思決定ノードを使用します.例えば,あるユーザーを信用信頼性または信頼性のないものとして分類できます.
優点:人,場所,物の様々な特徴,性質,特性を評価する能力 ルールに基づく信用評価,競馬予想など
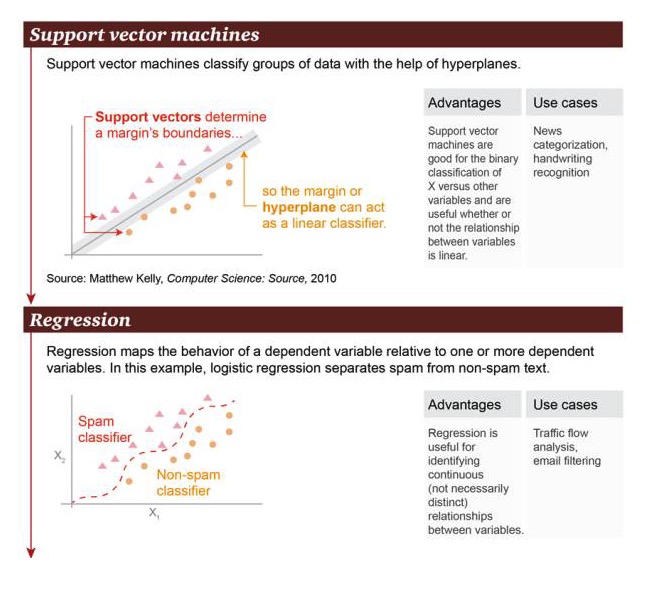
サポートベクトルマシン (Support Vector Machine):超平面 (hyperplane) に基づいて,サポートベクトルマシンはデータ群を分類することができる.
優点: 支持ベクトルマシンは,関係が線形であるかどうかにかかわらず,変数Xと他の変数との間で二元分類操作を行うのに優れている 記事の分類,手書きの識別などです.
Regression: Regression は因数変数と1つまたは複数の因数変数の間の状態関係を図示する.この例では,スパムメールと非スパムメールを区別する.
利点: 変数の間の連続関係を識別するために回帰を使用できます. 例えば,道路交通の分析,メールのフィルター
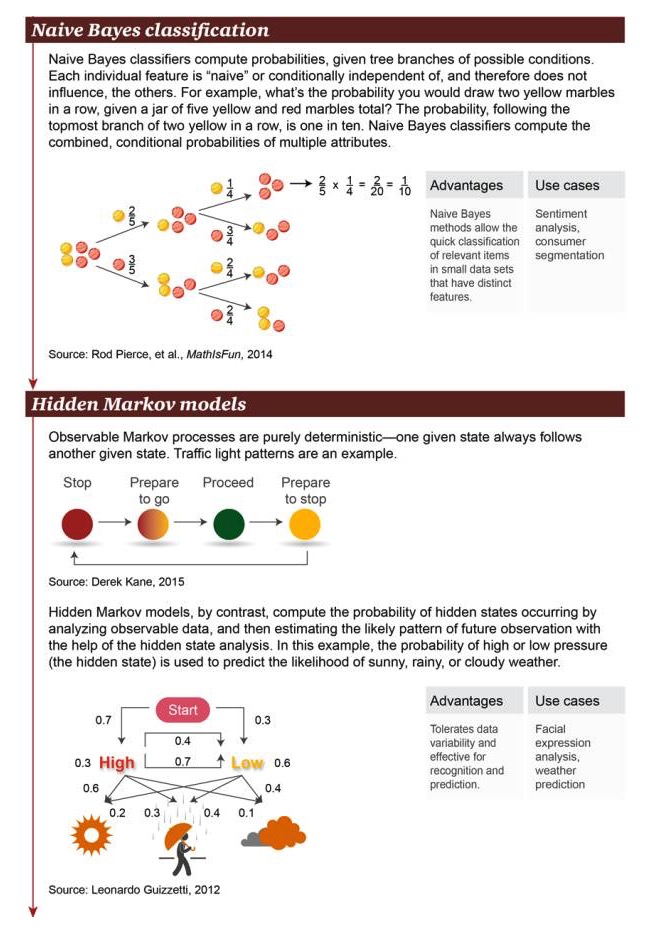
ネイブ・ベイズ分類: ネイブ・ベイズ分類は,可能な条件の分岐確率を計算するために使用される.各個別特性は”ネイブ”または条件独立であり,それゆえ,他の物体に影響しない.例えば,黄色と赤の小さな球が5個ある箱の中で,連続して2つの黄色い小さな球を捕まえる確率は何ですか.図の最上部から分岐が見られ,前後に2つの黄色い小さな球を捕まえる確率は1/10である. ネイブ・ベイズ分類は,複数の特性の合同条件の確率を計算できる.
優点: 素朴なベイエス法により,小さなデータセットで顕著な特徴を持つ関連オブジェクトを迅速に分類できます. 情緒分析,消費者の分類など
隠されたマルコフモデル ((Hidden Markov model): 明らかにマルコフプロセスは完全確実性である. ある状態がしばしば別の状態に伴う. 交通信号灯は,その例である. 反対に,隠された状態の発生を計算する,可視データ分析による隠されたマルコフモデルである. 隠された状態の分析を利用して,その後,隠されたマルコフモデルは,可能な将来の観測パターンを推定することができる. この例では,高気圧または低気圧の確率 (これは隠された状態である) が,晴れ,雨天,多雲天の確率を予測するのに用いられる.
優点:データの変動性を許容し,認識と予測操作に適している 顔の表情分析や天気予報など
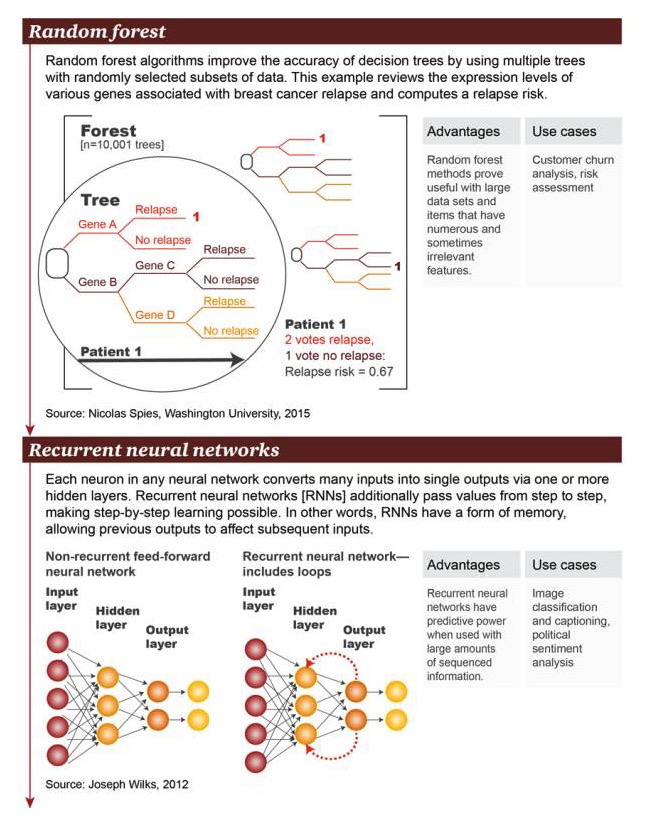
ランダムフォレスト:ランダムフォレストアルゴリズムは,ランダムに選択されたデータサブセットの複数のツリーを使用することで,意思決定ツリーの精度を改善します.この例は,遺伝子表現のレベルで,乳がんの再発に関連した多数の遺伝子を調べ,再発のリスクを計算します.
利点:ランダムフォレストは,大規模なデータセットと,大量の,時には関連のない特性の項 (item) に有用であることが証明されています. ユーザー流出分析,リスク評価
循環神経ネットワーク (Recurrent neural network):任意のニューラルネットワークでは,各ニューロンは1つまたは複数の隠された層を通って多くのインプットを単一の出力に変換する.循環神経ネットワーク (RNN) は,値をさらに層ごとに伝達し,層ごとに学習を可能にします.つまり,RNNにはある種の記憶が存在し,以前の出力が後者の出力に影響を与える.
優点:循環神経ネットワークは,大量に組織化された情報が存在しているときに予測能力を有する 画像の分類と字幕の追加,政治情緒分析

長い短期記憶 (LSTM) とゲートされた循環ユニットニューラルネットワーク:初期のRNNの形態は損耗性がある.これらの初期の循環ニューラルネットワークは,ごく少量の初期の情報を保存することを許したものの,最近の長い短期記憶 (LSTM) とゲートされた循環ユニット (GRU) ニューラルネットワークは,長い短期記憶と短い期間の記憶の両方を備えている.つまり,これらの最近のRNNは,以前の値を保持したり,多くの一連のステップを処理する際に必要なときにこれらの値を重置する能力を有する.これは,梯度”衰退”または段階的に転送された値の最終的な劣化を回避する.
優点: 長期短期記憶とドーム制御循環器ニューラルネットワークは,他の循環神経ネットワークと同じ優点を持っていますが,記憶能力が優れているため,よりよく使用されます. 自然言語処理と翻訳
コンボリュアルニューラルネットワーク (convolutional neural network):コンボリュアルとは,後続層からの重力の融合を意味し,出力層の標識に使用することができる.
利点:非常に大きなデータセット,多くの特性,複雑な分類作業がある場合,コンクリートニューラルネットワークは非常に有用です. 画像認識 テキスト・ 音声変換 薬物発見
- #### 記事のリンク
http://usblogs.pwc.com/emerging-technology/a-look-at-machine-learning-infographic/
http://usblogs.pwc.com/emerging-technology/machine-learning-methods-infographic/
http://usblogs.pwc.com/emerging-technology/machine-learning-evolution-infographic/
大量のデータから