

人工知能の強化学習を使って暗号通貨取引ロボットを作ってみよう
この記事では、強化学習フレームワークを作成して適用し、ビットコイン取引ボットの作成方法を学びます。このチュートリアルでは、OpenAI の gym と、OpenAI ベースライン ライブラリのフォークである stable-baselines ライブラリの PPO ロボットを使用します。
過去数年にわたりディープラーニング研究者にオープンソース ソフトウェアを提供してくれた OpenAI と DeepMind に感謝します。 AlphaGo、OpenAI Five、AlphaStar などのテクノロジーで彼らが成し遂げた素晴らしい成果をまだ見ていないなら、この 1 年間孤立して暮らしていたのかもしれないが、一度はチェックしてみる価値がある。
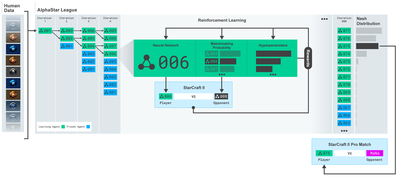
AlphaStar トレーニング https://deepmind.com/blog/alphastar-mastering-real-time-strategy-game-starcraft-ii/
何か印象的なものを作成するつもりはありませんが、ビットコイン ロボット取引は、日常の取引では依然として簡単な作業ではありません。しかし、テディ・ルーズベルトがかつて言ったように、
あまりにも簡単に手に入るものは価値がありません。
したがって、自分で取引する方法を学ぶだけでなく、ロボットに代わりに取引を任せることもできます。
プラン

-
ロボットが機械学習を実行するためのジム環境を作成する
-
シンプルでエレガントな視覚化環境をレンダリングする
-
ロボットを訓練して収益性の高い取引戦略を学習させる
ジムの環境をゼロから作成する方法や、これらの環境の視覚化を単純にレンダリングする方法にまだ慣れていない場合。先に進む前に、ぜひこのような記事を Google で検索してみてください。これら 2 つのアクションは、初心者のプログラマーにとっても難しくありません。
はじめる
このチュートリアルでは、Zielak によって生成された Kaggle データセットを使用します。ソース コードをダウンロードしたい場合は、.csv データ ファイルとともに私の Github リポジトリから入手できます。では、始めましょう。
まず、必要なライブラリをすべてインポートしましょう。不足しているライブラリは必ず pip を使用してインストールしてください。
import gym
import pandas as pd
import numpy as np
from gym import spaces
from sklearn import preprocessing
次に、環境用のクラスを作成しましょう。 pandas データフレームを渡す必要があります。また、オプションの initial_balance と lookback_window_size も渡す必要があります。これらは、ロボットが各ステップで観察する過去の時間ステップの数を指定します。取引あたりの手数料を Bitmex の現在のレートである 0.075% にデフォルト設定し、シリアル パラメータを false にデフォルト設定します。つまり、データフレームはデフォルトでランダムな部分で走査されます。
また、データに対して dropna() と reset_index() を呼び出し、最初に NaN 値を持つ行を削除し、次にデータが削除されたためフレーム番号のインデックスをリセットします。
class BitcoinTradingEnv(gym.Env):
"""A Bitcoin trading environment for OpenAI gym"""
metadata = {'render.modes': ['live', 'file', 'none']}
scaler = preprocessing.MinMaxScaler()
viewer = None
def __init__(self, df, lookback_window_size=50,
commission=0.00075,
initial_balance=10000
serial=False):
super(BitcoinTradingEnv, self).__init__()
self.df = df.dropna().reset_index()
self.lookback_window_size = lookback_window_size
self.initial_balance = initial_balance
self.commission = commission
self.serial = serial
# Actions of the format Buy 1/10, Sell 3/10, Hold, etc.
self.action_space = spaces.MultiDiscrete([3, 10])
# Observes the OHCLV values, net worth, and trade history
self.observation_space = spaces.Box(low=0, high=1, shape=(10, lookback_window_size + 1), dtype=np.float16)
ここで、action_space は 3 つのオプション (購入、売却、または保持) のセットと、別の 10 個の金額のセット (1/10、2/10、3/10 など) として表されます。購入アクションを選択した場合、数量 * self.balance 相当の BTC を購入します。売却する場合は、self.btc_held の金額に相当する BTC を売却します。もちろん、保留アクションは金額を無視し、何も行いません。
私たちのobservation_spaceは、形状が(10, lookback_window_size + 1)である、0から1までの連続した浮動小数点数のセットとして定義されます。 + 1 は現在のタイム ステップを計算するために使用されます。ウィンドウ内の各タイムステップで、OHCLV 値を観察します。私たちの純資産は、購入または売却した BTC の金額と、それらの BTC に費やしたまたは受け取った USD の合計金額に等しくなります。
次に、環境を初期化するためのリセット メソッドを記述する必要があります。
def reset(self):
self.balance = self.initial_balance
self.net_worth = self.initial_balance
self.btc_held = 0
self._reset_session()
self.account_history = np.repeat([
[self.net_worth],
[0],
[0],
[0],
[0]
], self.lookback_window_size + 1, axis=1)
self.trades = []
return self._next_observation()
ここでは self を使用します。_reset_session と self。_next_observationはまだ定義されていません。まずそれらを定義しましょう。
取引セッション
私たちの環境の重要な部分は、取引セッションの概念です。このボットを市場外に展開した場合、一度に数か月以上実行することはおそらくないでしょう。このため、self.df 内の連続フレームの数、つまりロボットが一度に見ることができるフレームの数を制限します。
_reset_session メソッドでは、まず current_step を 0 にリセットします。次に、steps_left を、プログラムの先頭で定義する 1 から MAX_TRADING_SESSION までのランダムな数値に設定します。
MAX_TRADING_SESSION = 100000 # ~2个月
次に、フレームを連続的に反復処理したい場合は、フレーム全体を反復処理するように設定する必要があります。そうでない場合は、frame_startをself.dfのランダムなポイントに設定し、active_dfという新しいデータフレームを作成します。これはselfです。スライスframe_start から frame_start + steps_left までの df です。
def _reset_session(self):
self.current_step = 0
if self.serial:
self.steps_left = len(self.df) - self.lookback_window_size - 1
self.frame_start = self.lookback_window_size
else:
self.steps_left = np.random.randint(1, MAX_TRADING_SESSION)
self.frame_start = np.random.randint(self.lookback_window_size, len(self.df) - self.steps_left)
self.active_df = self.df[self.frame_start - self.lookback_window_size:self.frame_start + self.steps_left]
ランダム スライスでデータ フレームの数を反復処理することの重要な副作用は、ロボットが長期間のトレーニング時に使用できる一意のデータが増えることです。たとえば、データフレームの数を単純にシリアル方式で(つまり、0 から len(df) の順に)反復処理すると、データフレームの数と同じ数の一意のデータ ポイントのみが得られます。私たちの観測空間は、各時間ステップで離散的な数の状態しか採用できません。
ただし、データセットのスライスをランダムに反復処理することで、初期データセットの各タイムステップでより意味のある取引結果のセット、つまり取引アクションと以前に確認された価格アクションの組み合わせを作成して、よりユニークなデータセットを作成できます。例を挙げて説明しましょう。
シリアル環境をリセットした後のタイム ステップ 10 で、ロボットは常にデータセット内で同時に実行され、各タイム ステップの後に、購入、売却、または保留の 3 つの選択肢が表示されます。これら 3 つのオプションのそれぞれに対して、特定の実装量の 10%、20%、... または 100% という別のオプションがあります。これは、ロボットが 103 の 10 乗、つまり合計 1030 通りの状況に遭遇する可能性があることを意味します。
さて、ランダムスライス環境に戻りましょう。タイムステップが 10 の場合、ロボットはデータ フレームの数内で任意の len(df) タイムステップに存在する可能性があります。各タイムステップ後に同じ選択が行われると仮定すると、ロボットは同じ 10 タイムステップで len(df)30 の任意の一意の状態を通過できることになります。
これにより、大規模なデータセットにかなりのノイズが導入される可能性がありますが、ロボットは限られた量のデータからより多くのことを学習できるようになると考えています。アルゴリズムの有効性をより正確に把握するために、テスト データを連続的に反復処理して、最新の、一見「リアルタイム」のデータを取得します。
ロボットの目を通して
ロボットが使用する機能の種類を理解するには、環境を視覚的によく把握しておくと役立つことがよくあります。たとえば、OpenCV を使用してレンダリングされた観測可能な空間の視覚化を次に示します。

OpenCV可視化環境の観察
画像内の各行は、observation_space 内の行を表します。同様の頻度の赤い線の最初の 4 行は OHCL データを表し、そのすぐ下のオレンジと黄色の点はボリュームを表します。下の変動する青いバーはボットのエクイティであり、その下の明るいバーはボットの取引を表しています。
よく見ると、独自のローソク足チャートを作成することもできます。ボリュームバーの下には、取引履歴を表示するモールス信号のようなインターフェースがあります。私たちのボットは、observation_space のデータから適切に学習できるはずなので、続けましょう。ここでは、観測データを 0 から 1 にスケーリングする _next_observation メソッドを定義します。
- 先読みバイアスを防ぐために、ロボットがこれまでに観測したデータのみを拡張することが重要です。
def _next_observation(self):
end = self.current_step + self.lookback_window_size + 1
obs = np.array([
self.active_df['Open'].values[self.current_step:end],
self.active_df['High'].values[self.current_step:end],
self.active_df['Low'].values[self.current_step:end],
self.active_df['Close'].values[self.current_step:end],
self.active_df['Volume_(BTC)'].values[self.current_step:end],])
scaled_history = self.scaler.fit_transform(self.account_history)
obs = np.append(obs, scaled_history[:, -(self.lookback_window_size + 1):], axis=0)
return obs
行動を起こす
観測スペースが設定されたので、ステップ関数を記述し、ロボットが実行しようとしているアクションを実行します。現在の取引セッションで self.steps_left == 0 になるたびに、保有している BTC を売却し、reset session() を呼び出します。それ以外の場合は、現在の株式に報酬を設定するか、資金が不足している場合は done を True に設定します。
def step(self, action):
current_price = self._get_current_price() + 0.01
self._take_action(action, current_price)
self.steps_left -= 1
self.current_step += 1
if self.steps_left == 0:
self.balance += self.btc_held * current_price
self.btc_held = 0
self._reset_session()
obs = self._next_observation()
reward = self.net_worth
done = self.net_worth <= 0
return obs, reward, done, {}
取引アクションを実行するのは、current_price を取得し、実行する必要があるアクションと、購入または売却する量を決定するだけです。環境をテストできるように、_take_action を簡単に記述してみましょう。
def _take_action(self, action, current_price):
action_type = action[0]
amount = action[1] / 10
btc_bought = 0
btc_sold = 0
cost = 0
sales = 0
if action_type < 1:
btc_bought = self.balance / current_price * amount
cost = btc_bought * current_price * (1 + self.commission)
self.btc_held += btc_bought
self.balance -= cost
elif action_type < 2:
btc_sold = self.btc_held * amount
sales = btc_sold * current_price * (1 - self.commission)
self.btc_held -= btc_sold
self.balance += sales
最後に、同じ方法で、取引を self.trades に追加し、エクイティとアカウント履歴を更新します。
if btc_sold > 0 or btc_bought > 0:
self.trades.append({
'step': self.frame_start+self.current_step,
'amount': btc_sold if btc_sold > 0 else btc_bought,
'total': sales if btc_sold > 0 else cost,
'type': "sell" if btc_sold > 0 else "buy"
})
self.net_worth = self.balance + self.btc_held * current_price
self.account_history = np.append(self.account_history, [
[self.net_worth],
[btc_bought],
[cost],
[btc_sold],
[sales]
], axis=1)
ロボットは、新しい環境を起動し、その環境を通過し、環境に影響を与えるアクションを実行できるようになりました。彼らの取引を見守る時間です。
ロボットの取引をご覧ください
私たちのレンダリング メソッドは print(self.net_worth) を呼び出すのと同じくらい簡単ですが、それだけでは十分面白くないでしょう。代わりに、ボリュームバーとエクイティ用の別のチャートを含むシンプルなローソク足チャートを描画します。
前回の記事の StockTradingGraph.py のコードを取り出し、それを Bitcoin 環境に合わせて作り直します。私の Github からコードを入手できます。
最初に行う変更はself.dfを変更することです。[ [日付] self.df を更新[日付はすでに UNIX タイムスタンプ形式になっているため、['Timestamp'] に変更し、date2num へのすべての呼び出しを削除します。次に、レンダリング メソッドで日付ラベルを更新して、数値ではなく人間が判読できる日付を出力します。
from datetime import datetime
まず、datetime ライブラリをインポートし、次に utcfromtimestampmethod を使用して各タイムスタンプから UTC 文字列を取得し、 strftime を使用してそれを Y-m-d H:M 形式の文字列に変換します。
date_labels = np.array([datetime.utcfromtimestamp(x).strftime('%Y-%m-%d %H:%M') for x in self.df['Timestamp'].values[step_range]])
最後に、self.dfを使用します。[「ボリューム」はself.dfに変更されます['Volume_(BTC)'] をデータセットと一致するように変更し、これで準備完了です。 BitcoinTradingEnv に戻り、グラフを表示するためのレンダリング メソッドを記述できるようになりました。
def render(self, mode='human', **kwargs):
if mode == 'human':
if self.viewer == None:
self.viewer = BitcoinTradingGraph(self.df,
kwargs.get('title', None))
self.viewer.render(self.frame_start + self.current_step,
self.net_worth,
self.trades,
window_size=self.lookback_window_size)
見て!これで、ロボットがビットコインを取引するのを見ることができます。

Matplotlib でロボットの取引を視覚化する
緑のファントム ラベルは BTC の購入を表し、赤のファントム ラベルは売却を表します。右上隅の白いラベルはロボットの現在の純資産であり、右下隅のラベルはビットコインの現在の価格です。シンプルでエレガント。さて、ボットをトレーニングして、どれくらいの収益が得られるかを見てみましょう。
トレーニング時間
前回の記事で受けた批判の 1 つは、相互検証が欠如しており、データがトレーニング セットとテスト セットに分割されていないというものでした。この目的は、これまでに見たことのない新しいデータで最終モデルの精度をテストすることです。これはこの記事の焦点ではありませんが、確かに重要です。時系列データを扱っているため、クロス検証に関しては選択肢があまりありません。
たとえば、クロス検証の一般的な形式は k 分割検証と呼ばれ、データを k 個の等しいグループに分割し、グループの 1 つをテスト グループとして分離し、残りのデータをトレーニング グループとして使用します。 。ただし、時系列データは時間に大きく依存するため、後のデータは前のデータに大きく依存します。したがって、ロボットは取引前に将来のデータから学習するため、k-fold は機能しません。これは不公平な利点です。
時系列データに適用する場合、他のほとんどのクロス検証戦略にも同じ欠陥が当てはまります。したがって、フレーム番号の先頭から任意のインデックスまでの完全なデータ フレームの一部のみをトレーニング セットとして使用し、残りのデータをテスト セットとして使用する必要があります。
slice_point = int(len(df) - 100000)
train_df = df[:slice_point]
test_df = df[slice_point:]
次に、環境は 1 つのデータ フレームのみを処理するように設定されているため、トレーニング データ用とテスト データ用の 2 つの環境を作成します。
train_env = DummyVecEnv([lambda: BitcoinTradingEnv(train_df, commission=0, serial=False)])
test_env = DummyVecEnv([lambda: BitcoinTradingEnv(test_df, commission=0, serial=True)])
これで、モデルのトレーニングは、環境を使用してロボットを作成し、model.learn を呼び出すだけで簡単に実行できるようになりました。
model = PPO2(MlpPolicy,
train_env,
verbose=1,
tensorboard_log="./tensorboard/")
model.learn(total_timesteps=50000)
ここでは、Tensorboard を使用して、Tensorflow グラフを簡単に視覚化し、ロボットに関する定量的なメトリックを確認できるようにします。たとえば、200,000 タイム ステップにわたる多数のロボットの割引報酬のグラフを次に示します。
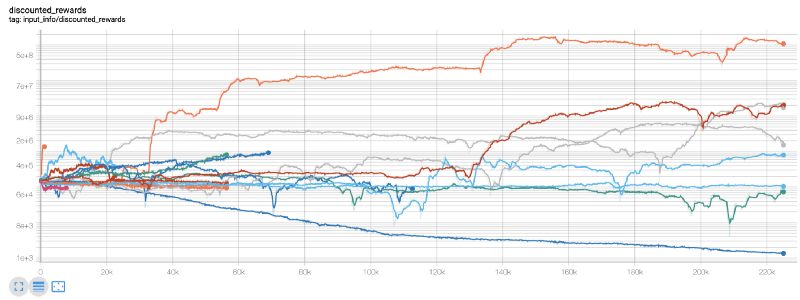
わあ、私たちのボットはかなり利益を上げているようですね!当社の最も優れたロボットは、200,000 ステップにわたって 1,000 倍も優れたバランスを実現し、残りのロボットも平均して少なくとも 30 倍の改善を達成しました。
この時点で、環境にバグがあることに気付きました...それを修正した後、新しい報酬マップは次のようになります。
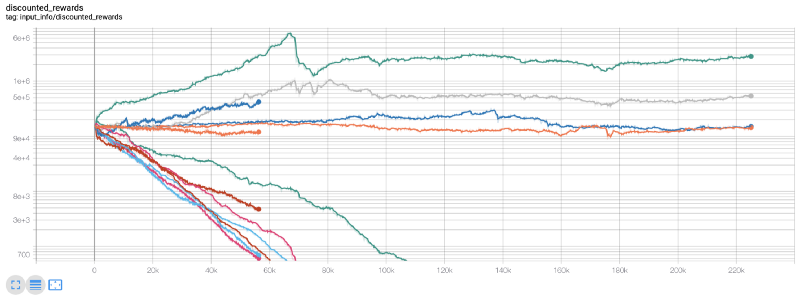
ご覧のとおり、当社のロボットの中には素晴らしい仕事をしたものもありますが、残りは自力で倒産してしまいました。ただし、パフォーマンスの優れたボットは、初期残高の最大 10 倍、さらには 60 倍を達成できます。収益性の高いボットはすべて手数料なしでトレーニングおよびテストされているため、当社のボットが実際にお金を稼ぐことは非現実的であることを認めなければなりません。しかし、少なくとも方向は見つかりました!
テスト環境でボットをテストし(これまでに見たことのない新しいデータを使用して)、パフォーマンスを確認しましょう。
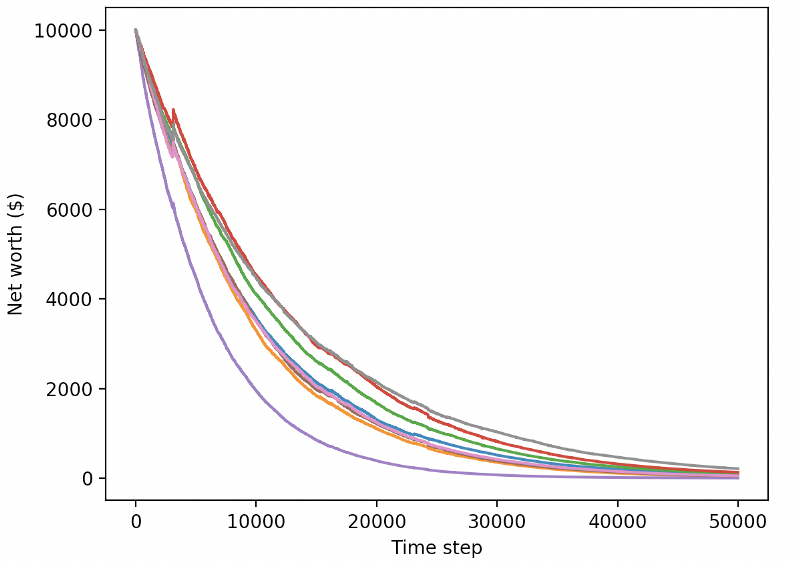
訓練されたボットは新しいテストデータを取引すると破産する
明らかに、私たちにはまだやるべきことがたくさんあります。現在の PPO2 ロボットではなく、安定したベースライン A2C を使用するようにモデルを切り替えるだけで、このデータセットでのパフォーマンスを大幅に向上できます。最後に、Sean O'Gorman の提案に従って、報酬関数を少し更新して、単に高い純資産を達成してそのままにするのではなく、純資産に報酬を追加するようにすることができます。
reward = self.net_worth - prev_net_worth
これら 2 つの変更だけで、テスト データセットのパフォーマンスが大幅に向上し、以下に示すように、トレーニング セットにはなかった新しいデータで最終的に収益性を達成できるようになりました。
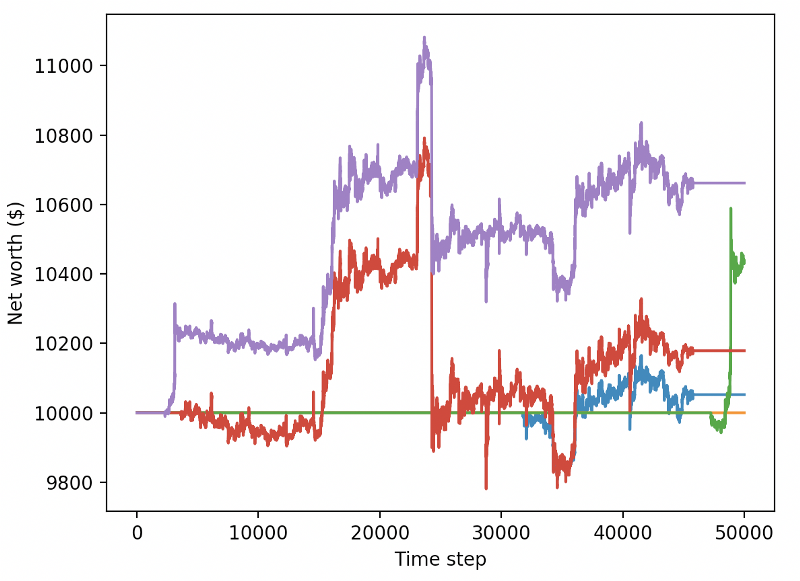
しかし、私たちはもっと良いことができるはずです。これらの結果を改善するには、ハイパーパラメータを最適化し、ボットをより長くトレーニングする必要があります。 GPU を稼働させて全力で稼働させる時が来ました。
この投稿はこの時点で少し長くなっており、まだ考慮すべき詳細がたくさんあるので、ここで休憩を取ります。次の投稿では、ベイズ最適化を使用して問題空間に最適なハイパーパラメータを分割し、CUDA を使用して GPU でのトレーニング/テストの準備をします。
結論は
この記事では、強化学習を使用して、収益性の高いビットコイン取引ボットをゼロから作成することにしました。以下のタスクを実行できます。
-
OpenAI のジムを使用して、ビットコイン取引環境をゼロから作成します。
-
Matplotlib を使用して環境の視覚化を構築します。
-
簡単なクロス検証を使用してボットをトレーニングおよびテストします。
-
収益性を上げるためにロボットを少し調整する
私たちのトレーディング ロボットは期待したほどの利益を上げていませんが、正しい方向に向かっています。次回は、ボットが一貫して市場に勝てるかどうかを確認し、取引ボットがライブ データでどのように機能するかを確認します。次の記事をお楽しみに。ビットコイン万歳!
- 1