
이 글에서는 고급 알고리즘을 사용하여 대체 데이터 주도 투자 (ADDI) 전략을 개선하는 모듈을 설명할 것입니다. 이 방법은 시장에서 벗어나 안정적인 성과를 얻고, 회수 위험이 제한되는 자동 다중 투자 전략입니다.
우리가 개발한 알고리즘은 다공간 전략과 관련된 위험을 줄이기 위해 맞춤형 깊이 신경망입니다.
왜 신경망을 사용해야 할까요?
배경
<unk>에 대해양적 투자자하지만 가장 중요하고 흥미로운 단계 중 하나는 바로 앞에 있습니다. 수많은 가능성이 펼쳐져 있습니다. 우리는 어떻게 이 데이터를 신호로 변환할 수 있을까요?
우리는 우리의 가설을 철저히 검사하기 위해 전통적인 통계적 방법을 선택할 수 있고, 기계 학습과 딥 러닝과 같은 고급 알고리즘 영역을 탐색 할 수도 있습니다. 아마도 몇 가지 거시 경제 이론에 대한 매력은 외환 (FX) 시장에서 그 적용 가능성을 연구하려는 것입니다.
ETS 방법
우리의 경우, 연구의 방향을 결정하는 데는 오직 하나의 지침이 있습니다.혁신의 용기 。
<unk> 누가 대성당을 생각하면 돌덩어리가 더 이상 돌덩어리가 아니다. <unk> 안토니 드 산 엑스포리
이 배후의 기본 원칙은 매우 간단합니다. 우리가 혁신하지 않으면, 우리는 눈에 띄지 않을 것이고, 성공의 기회도 줄어들 것입니다. 따라서, 우리가 새로운 전략을 수립할 때, 전통적인 통계자료에 의존하거나 회사의 재무제표에서 인사이트를 얻는 것이든 간에, 우리는 항상 새로운 방법을 사용하여 그것을 시도합니다. 우리는 특정 시나리오에 대한 특정 테스트를 만들고, 재무제표의 비정상성을 탐지하거나 특정 문제에 따라 모델을 조정합니다.
따라서, 신경망의 적응성과 유연성 때문에, 특정 문제를 해결하는 데 특히 매력적일 수 있으며, 이는 혁신적인 기술을 개발하는 데 도움이 될 것입니다.
보시다시피, 이러한 기술을 사용할 수 있는 많은 방법들이 있습니다. 하지만, 우리는 조심해야 합니다. 왜냐하면 여기에 마법의 공식이 없기 때문입니다. 어떤 노력과 마찬가지로, 우리는 항상 기초에서 시작해야 합니다.
오늘 강연의 주제를 다시 살펴보면, 우리는 리스크를 예측하기 위해 금융 보고서와 역사적인 가격 데이터를 입력하여 딥 뉴런 네트워크의 강력한 기능을 활용할 것입니다.
우리의 모델
하지만, 우리는 더 간단한 방법으로, 예를 들어 역사적인 변동률과 비교하여 모델의 성능을 평가할 것입니다.
우리가 더 깊이 들어가기 전에, 신경망의 몇 가지 핵심 개념과 우리가 예측 출력 분포를 추론하기 위해 그것들을 어떻게 사용할 수 있는지에 대해 익숙하다고 가정해 봅시다.
또한, 오늘의 목적에서는, 우리의 기준에 대한 개선과 투자 전략에 적용된 후의 결과에만 집중할 것입니다.
따라서, 시간 순서 데이터의 불확실성을 측정하는 후속 기사에서, 우리는 미래의 다양한 시간 범위에서 예상되는 가격 수익의 분수를 예측하여 회사의 위험을 추정하려고 노력할 것입니다. 우리의 예제에서, 시간 범위는 5일에서 90일입니다.
아래는 모형 훈련 후, 미래의 다른 시간 범위의 분수 예측 (푸른) 이 어떻게 나타날지를 보여주는 예입니다. 예측된 분수 간격이 넓을수록, 우리의 투자 위험은 더 커집니다. 보라색은 예측 후 실제로 일어난 일입니다.
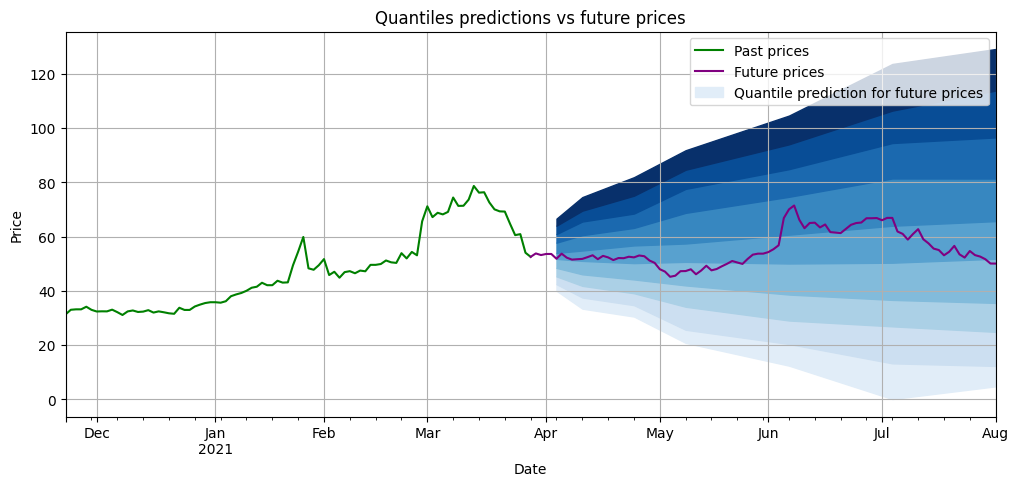
우리의 모델을 평가합니다.
앞서 언급했듯이, 우리의 전략에서 우리의 모델을 사용하기 전에, 우리는 그것의 예측을 과거의 변동률의 간단한 변환을 사용하여 얻은 예측과 비교합니다. 과거의 변동률의 간단한 변환이 복잡한 알고리즘보다 더 낫습니까?
우리의 모델과 기준을 평가하기 위해, 우리는 그들의 분수 예측과 관찰된 수익을 비교했다. 예를 들어, 0.9 분수에 대한 우리의 모든 예측에서, 우리는 평균적으로 90%의 확률로 가격 수익이 이 분수 예측보다 낮을 것으로 예상했다.
이것이 우리가 아래 그림에서 평가하려고 시도한 것입니다. (모든 결과가 테스트 세트에서 나온 것입니다.) 왼쪽 그림에서 우리는 이론적 커버리지를 실제 커버리지와 비교할 수 있습니다. 오른쪽 그림에서 우리는 이러한 커버리지 (이론적 커버리지 - 실제 커버리지) 사이의 차이를 볼 수 있습니다.커버리지 오류예를 들어, 0.2의 분수에서는 0.4%에 가까운 포괄적 오류가 있습니다. 이것은 평균적으로 20.4%의 데이터가 이론적으로 20%가 아닌 이러한 값보다 낮게 관찰된다는 것을 의미합니다.
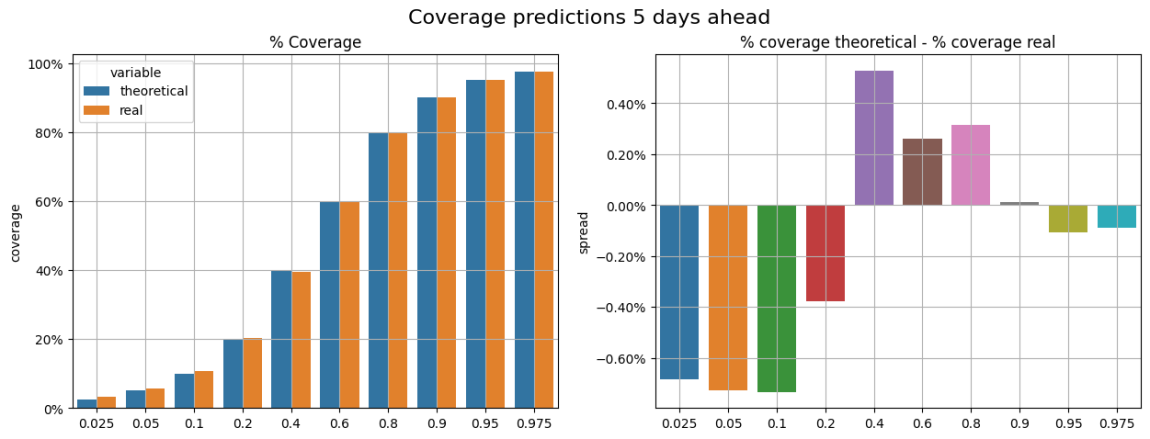
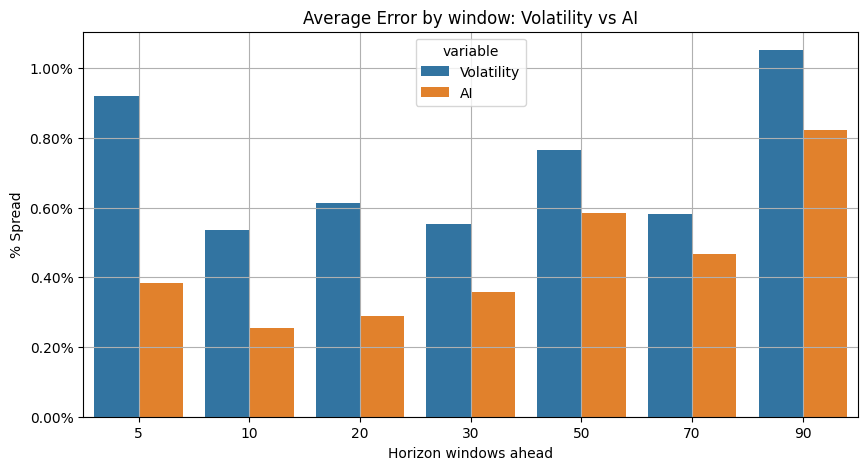
우리는 모든 소수점 덮개 오류를 예상 창 (5일, 10일, ...일) 에 따라 평균하고, 기준 테스트와 AI 모델에서 얻은 결과를 비교했습니다. 아래에서 우리는 볼 수 있습니다.**우리의 딥러닝 모델이 더 잘 작동합니다.**우리는 우리의 모델을 우리의 전략에 도입할 준비가 되어 있습니다.
인공지능이 ADDI에 포함되는 것
ADDI는 베타 중립적 (베타 값 ~ 0.1) 인 레버리지 포트폴리오로, 시세 및 시세 시장의 경우 알파를 생성할 수 있으며, 시장에 대한 당기점이 제한되어 위험성이 낮습니다.
이 전략의 다단계 부분은 높은 품질과 낮은 변동성 편차를 선택한다. 따라서, 재고 위험 평가는 이 과정의 중요한 임무이다. 공중에서, 위험 평가는 매우 높은 위험 또는 매우 낮은 위험을 피하기 위해 전략이 시도하기 때문에 또한 중요한 계산이다.
우리는 전략의 다중 헤드 및 빈 헤드 부분에서 서로 다른 계산 주기의 역사적인 변동률을 통해 위험을 측정할 수 있습니다.
ADDI의 위험 분석을 개선하기 위해, 우리는 기존의 위험 계산 과정을 대체하기 위해 이전에 표시된 심도 신경망 알고리즘을 테스트했습니다.
결과는
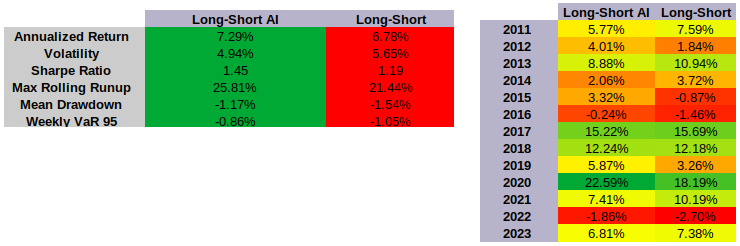
스탠퍼드 900 지수 구성 요소에 투자한 다중 <unk> 텅 빈 전략에 새로운 딥러닝 모델을 테스트하면, 성능과 위험 모두에서 결과가 더 좋아지는 것을 볼 수 있습니다:
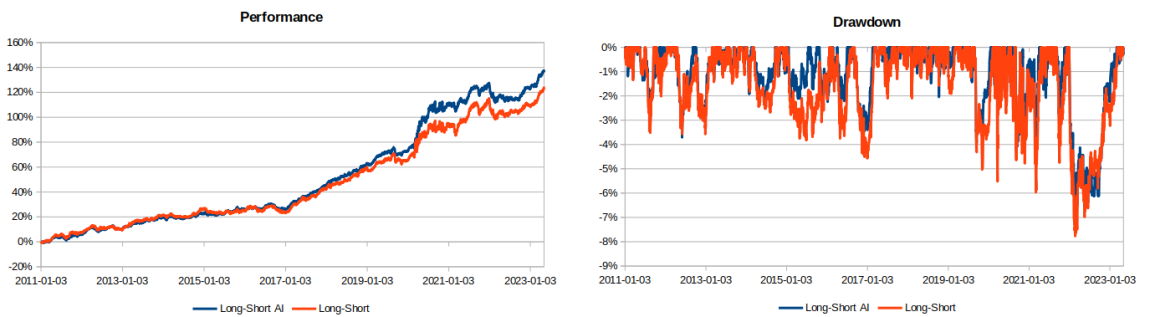
- 전체 수익률이 원본보다 높은 수치를 나타냅니다.
- 변동성이 낮아집니다.
- 샤프 비율이 상승
- 리스크가 줄어들기 때문에
- 최대 1년 롤링 성장률이 높습니다.
결론적으로
이 글에서는 거래 다중 공간 계량화 전략 (ADDI) 을 개선하기 위해 사용되는 고급 알고리즘 모델의 예시를 보여 줍니다. 우리는 신경 네트워크를 사용하여 계량화 투자 상품의 특정 작업을 개선하고 더 정확하게 관리하여 최종 결과를 개선하는 방법을 소개합니다.
하지만 이 모델의 활용은 이보다 더 넓습니다. 우리는 이 알고리즘을 다른 다양한 전략에 사용할 수 있습니다. 예를 들어, 우리는 그것을 가장 높은 샤프 비율을 가진 회사를 선택하거나, 심지어 쌍무 거래 전략을 실행하는 데 사용할 수 있습니다. 다른 전략을 생각해 볼 수 있습니까?
이 글은 양자 (quantdare.com/ai-case-study-long-short-strategy/) 에서 작성된 것입니다.
- 1