재미를 위한 머신 러닝: 가장 간단한 초보자 가이드
 3
3605
3
3605
재미를 위한 머신 러닝: 가장 간단한 초보자 가이드
사람들이 기계학습에 대해 말하는 것을 들었을 때, 그 의미를 조금만 모호하게 이해하시나요? 아니면 동료들과 대화할 때 머리를 끄덕이는 것에 지쳤습니까?
이 가이드는 머신러닝에 대해 궁금하고 어떻게 시작해야 할지 모르는 모든 사람들을 대상으로 합니다. 저는 많은 사람들이 머신러닝에 대한 위키백과 항목을 읽었을 것이라고 추측하고, 아무도 높은 수준의 설명을 할 수 없다고 생각하며 좌절했습니다.
이 글의 목적은 쉽게 접근할 수 있도록 하는 것인데, 이는 글에 많은 일반화들이 있다는 것을 의미한다. 하지만 누가 이런 것들을 신경쓰는가?
- ### 왜 기계학습이 필요한가?
기계학습의 개념은, 해결해야 할 문제를 해결하기 위해, 당신은 어떤 전문적인 프로그램 코드를 작성할 필요가 없으며, 유전 알고리즘 (generic algorithms) 은 데이터 세트에 대해 당신에게 흥미로운 답을 얻을 수 있다고 생각합니다. 유전 알고리즘에 대해서는, 코딩을 사용하지 않고, 데이터를 입력합니다. 그것은 데이터 위에 자신의 논리를 구축합니다.
예를 들어, 데이터를 다른 그룹으로 나눌 수 있는 분류 알고리즘이라고 불리는 알고리즘이 있다. 손으로 쓴 숫자를 식별하는 분류 알고리즘은 코드 한 줄을 수정하지 않고도 전자 메일을 스팸 메일과 일반 메일로 나눌 수 있다. 알고리즘은 변하지 않았지만 입력된 데이터가 변경되어 다른 분류 논리를 나타낸다.
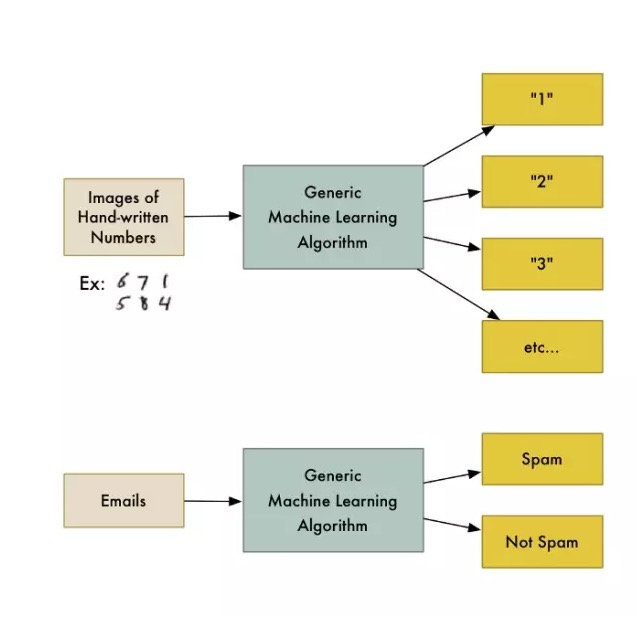
머신러닝 알고리즘은 블랙박스입니다. 여러 가지 분류 문제를 해결하기 위해 다시 사용할 수 있습니다.
머신러닝 (Machine Learning ) 은 포괄적인 용어이며, 수많은 유사한 유전 알고리즘을 포함하고 있다.
- ### 두 종류의 기계 학습 알고리즘
머신러닝 알고리즘은 크게 두 가지로 분류할 수 있습니다. 감독 학습 (Supervised Learning) 과 비감독 학습 (Unsupervised Learning) 입니다.
-
감독 학습
만약 당신이 부동산 중개업자라면, 당신의 사업이 커질수록, 당신은 당신을 돕기 위해 연습생들을 고용했습니다. 하지만 문제는, 당신은 집을 한눈에 볼 수 있고, 그 집의 가치를 알 수 있습니다. 연습생들은 경험이 없고, 그 집의 가치를 알 수 없습니다.
여러분의 인턴을 돕기 위해 (그리고 어쩌면 휴가를 보내기 위해) 여러분은 작은 소프트웨어를 만들기로 결정했습니다. 그것은 여러분의 지역의 주택의 가치를 집의 크기, 토지, 그리고 비슷한 주택의 거래 가격과 같은 요소에 따라 평가할 수 있습니다.
3개월 동안 이 도시에서 벌어진 모든 주택 거래를 기록하고, 각 거래에는 침실의 수, 집의 크기, 토지 등에 대한 수많은 세부 사항을 기록했습니다. 하지만 가장 중요한 것은, 최종 거래 가격을 기록한 것입니다.
이것은 우리의 요법 훈련 자료입니다.
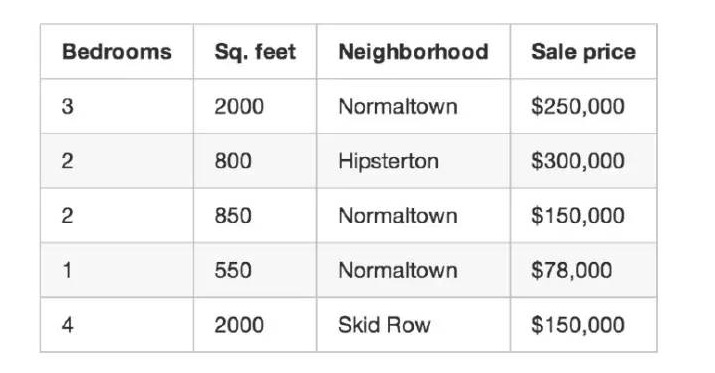
우리는 이 훈련 데이터를 사용하여 이 지역의 다른 주택의 가치를 추정하는 프로그램을 작성할 것입니다.

이것은 감독 학습이라고 불리죠. 여러분은 이미 모든 주택의 판매 가격을 알고 있습니다. 즉, 여러분은 문제의 답을 알고 있고, 그 논리를 뒤집어 풀 수 있습니다.
소프트웨어를 작성하기 위해, 당신은 각 집합의 훈련 데이터를 당신의 기계 학습 알고리즘에 입력합니다. 알고리즘은 가격 수를 얻기 위해 어떤 연산을 사용해야하는지 알아내려고 합니다.
이것은 마치 수학 연습문제와 같아서, 모든 연산기호가 지워져 버렸습니다.
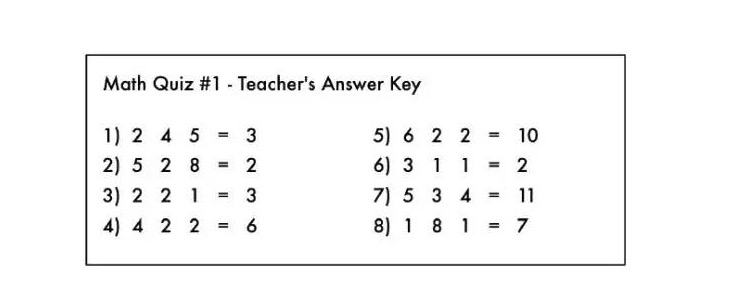
젠장! 교사의 답에 있는 수학 기호를 교활한 학생이 지워버렸어요。
이 문제들을 보고, 여러분은 이 테스트들이 어떤 종류의 수학 문제들이라는 것을 알 수 있나요? 여러분은 알고 있습니다, 여러분은 이 계산법의 왼쪽에 있는 숫자를 어떻게 하면 그 계산법의 오른쪽에 있는 숫자를 얻을 수 있는지 말이죠.
감독 학습에서는 컴퓨터가 숫자들 사이의 관계를 계산하도록 합니다. 그리고 이러한 특정 문제를 해결하는 데 필요한 수학적 방법을 알고 나면, 다른 문제를 해결할 수 있습니다.
-
비감독 학습
이제, 우리가 처음 본 부동산 중개자의 사례로 돌아가 보겠습니다. 만약 당신이 집의 매출액을 알 수 없다면 어떻게 할 수 있을까요? 만약 당신이 단지 집의 크기와 위치만 알 수 있다면, 당신은 멋진 디자인을 만들 수 있습니다. 이것은 비감독 학습이라고 불리는 것입니다.
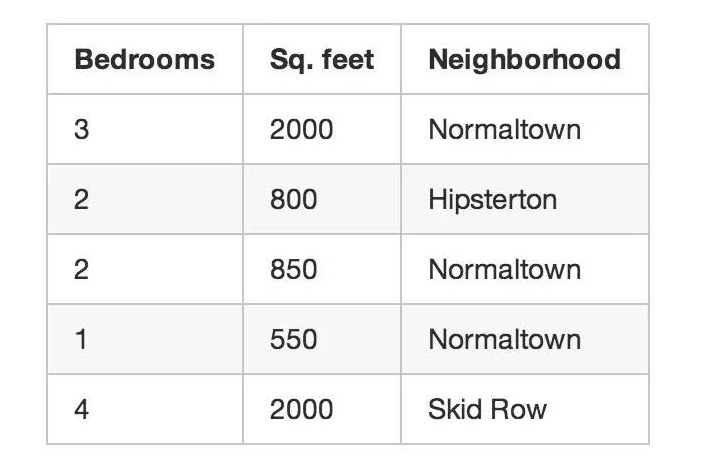
만약 여러분이 미지의 데이터를 예측하고 싶지 않더라도 (가격과 같은 것) 기계학습을 통해 재미있는 일을 할 수 있습니다.
이것은 마치 누군가 여러분에게 많은 숫자가 적힌 종이를 주면서 이렇게 말하는 것과 같습니다. “이 숫자들이 무엇을 의미하는지 모르겠지만, 어쩌면 당신은 그 숫자들로부터 어떤 규칙들을 찾아낼 수 있을지도 모릅니다. 아니면 그 숫자들을 분류할 수 있을지도 모릅니다.
어떻게 해야 할까요? 먼저, 알고리즘을 통해 데이터로 다른 세그먼트 시장을 자동으로 구분할 수 있습니다. 대학 근처의 주택 구매자는 작은 주택을 선호하지만 침실이 많고 교외의 주택 구매자는 3 침실의 주택을 선호합니다.
또 다른 멋진 것은, 집값이 다른 집값과는 다른 집값을 자동으로 찾아내는 것입니다. 집값이 다른 집값과는 다른 집값을 자동으로 찾아내는 것입니다. 집값이 다른 집값과 다른 집값을 자동으로 찾아내는 것입니다. 집값이 다른 집값과 다른 집값을 자동으로 찾아내는 것입니다. 집값이 다른 집값과 다른 집값을 자동으로 찾아내는 것입니다. 집값이 다른 집 집값과 다른 집값을 자동으로 찾아내는 것입니다.
이 글의 나머지 부분에서 우리는 주로 감독 학습에 대해 이야기하지만, 이것은 비감독 학습이 쓸모없거나 무용지물이기 때문이 아닙니다. 실제로, 알고리즘이 개선됨에 따라, 데이터와 올바른 답을 연결할 필요가 없어 비감독 학습이 점점 더 중요해지고 있습니다.
다른 종류의 머신러닝 알고리즘이 많이 있지만, 초보자라면 이런 식으로 이해하는 것이 좋습니다.
“아, 정말 멋져요, 하지만 집값 평가는 정말 공부하는 거로 볼 수 있을까요?”
인간으로서, 당신의 뇌는 거의 모든 상황에 대처할 수 있고, 어떤 명확한 지시도 없이 어떻게 대처할 수 있는지 배울 수 있다. 당신이 부동산 중개인이 되어 오랜 시간을 보낸다면, 당신은 부동산에 대한 적절한 가격, 가장 좋은 마케팅 방법, 어떤 고객들이 흥미를 가질지 등에 대해 직관적인 감각을 갖게 될 것이다. 강한 인공지능 (Strong AI) 연구의 목표는 이러한 능력을 컴퓨터로 복제하는 것이다.
그러나 현재 기계 학습 알고리즘은 그다지 좋지 않습니다. 그들은 매우 특정하고 제한된 문제에만 집중할 수 있습니다. 아마도 이러한 상황에서, 학습 의 더 적절한 정의는 적은 양의 예제 데이터를 기반으로 특정 문제를 해결하기 위해 방정식을 찾는 것입니다.
불행히도, 기계는 적은 양의 예제 데이터에 기초하여 특정 문제를 해결하기 위해 방정식을 찾아냅니다. 이라는 이름은 너무 나쁘습니다. 그래서 결국 우리는 을 기계 학습으로 대체했습니다.
물론, 만약 당신이 이 글을 50년 후에 읽게 된다면, 우리는 강력한 인공지능 알고리즘을 가지고 있을 것이고, 이 글은 오래된 유물처럼 보일 것이다. 미래 인류, 당신은 계속 읽지 말고, 당신의 기계 종들이 당신에게 샌드위치를 만들어 줄 수 있게 해 주세요.
이제 코드를 쓰자!
이전 예제에서 집값을 평가하는 절차를 어떻게 작성할 생각입니까? 아래로 내려가기 전에 한번 생각해보세요.
만약 여러분이 머신러닝에 대해 전혀 모르는 사람이라면, 여러분은 아마도 다음과 같이 집값을 평가하기 위한 몇 가지 기본 규칙을 작성하려고 시도할 것입니다.
def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood): price = 0 # In my area, the average house costs $200 per sqft price_per_sqft = 200 if neighborhood == "hipsterton": # but some areas cost a bit more price_per_sqft = 400 elif neighborhood == "skid row": # and some areas cost less price_per_sqft = 100 # start with a base price estimate based on how big the place is price = price_per_sqft * sqft # now adjust our estimate based on the number of bedrooms if num_of_bedrooms == 0: # Studio apartments are cheap price = price — 20000 else: # places with more bedrooms are usually # more valuable price = price + (num_of_bedrooms * 1000) return price만약 당신이 이렇게 몇 시간 동안 맹목적으로 일한다면, 조금이라도 효과를 얻을 수 있겠지만, 당신의 프로그램은 결코 완벽하지 않을 것이고, 가격이 변할 때 유지하기가 어려울 것이다.
만약 컴퓨터가 이 함수들을 구현할 수 있는 방법을 찾아낸다면, 누가 이 함수가 무엇을 하는지 신경을 쓰겠습니까?
def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood): price = <computer, plz do some math for me> return price이 문제를 생각해 볼 수 있는 한 가지 방법은 집값을 맛있는 으로 보는 것입니다. 의 구성 요소는 침실의 수, 면적, 그리고 토지입니다. 만약 여러분이 각 구성 요소가 최종 가격에 얼마나 큰 영향을 미치는지 계산할 수 있다면, 아마도 최종 가격에 대한 구체적인 비율을 형성하기 위해 다양한 구성 요소를 혼합할 수 있습니다.
이것은 당신의 초기 프로그램을 (모든 것은 광적인 if else 문장) 다음과 같은 것으로 단순화 할 수 있습니다:
def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood): price = 0 # a little pinch of this price += num_of_bedrooms * .841231951398213 # and a big pinch of that price += sqft * 1231.1231231 # maybe a handful of this price += neighborhood * 2.3242341421 # and finally, just a little extra salt for good measure price += 201.23432095 return price841231951398213, 1231.1231231, 2.3242341421, 그리고 201.23432095 등이 있습니다. 이 숫자들은 무게라고 불립니다. 만약 우리가 모든 집들에 적용되는 완벽한 무게를 찾아낼 수 있다면, 우리의 함수는 모든 집값을 예측할 수 있을 것입니다!
가장 좋은 무게를 찾는 방법 중 하나는 다음과 같습니다.
첫 번째 단계:
우선, 모든 무게를 1.0로 설정합니다.
def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood): price = 0 # a little pinch of this price += num_of_bedrooms * 1.0 # and a big pinch of that price += sqft * 1.0 # maybe a handful of this price += neighborhood * 1.0 # and finally, just a little extra salt for good measure price += 1.0 return price2단계:
각 부동산에 대한 함수를 가져와, 추정값과 정확한 가격의 오차를 확인합니다.
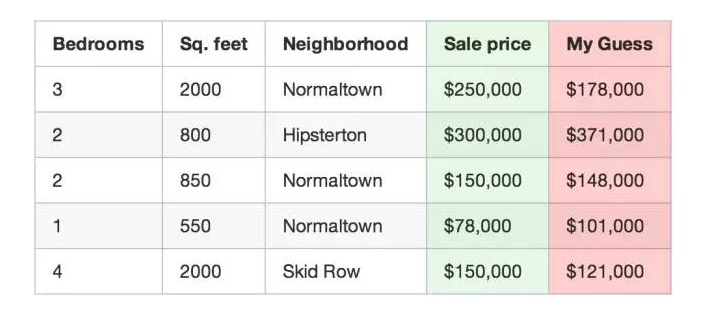
여러분의 프로그램을 사용하여 집값을 예측하세요.
예를 들어, 위의 첫 번째 부동산의 실제 거래 가격은 25만 달러이고, 여러분의 함수의 추정치는 17만 8천 달러입니다. 이 부동산은 7만 2천 달러가 남습니다.
그리고 여러분의 집합에 있는 모든 부동산에 대한 추정값의 편차제곱을 곱해 보세요. 집합에 500개의 부동산 거래가 있다고 가정하면, 추정값의 편차제곱의 합은 86,123,373달러입니다. 이것은 여러분의 함수가 현재 얼마나 올바르게 어졌는지 보여줍니다.
이제 총값을 500으로 나누면 각 집값이 평균값에서 벗어난 값이 나옵니다. 이 평균값을 여러분의 함수의 값이라고 부르세요.
만약 여러분이 이 값을 0으로 조정할 수 있다면, 여러분의 함수는 완벽합니다. 그것은 여러분의 프로그램이 입력된 데이터에 따라 모든 부동산 거래에 대한 평가를 정확히 하고 있다는 것을 의미합니다. 그리고 이것이 우리가 시도하는 목표입니다.
단계 3:
2단계를 계속 반복하고, 가능한 모든 중량 조합을 시도해 보세요. 어떤 조합이 비용을 0에 가장 가깝게 만들지, 그게 바로 여러분이 사용해야 하는 것입니다. 그리고 여러분이 그런 조합을 찾으면, 문제가 해결됩니다!
생각을 방해하는 시간
너무 간단하지 않나요? 당신이 방금 한 일을 생각해보세요. 데이터를 가져와서 3가지의 간단한 단계로 입력하면 여러분의 지역에 있는 집을 평가할 수 있는 함수를 얻게 됩니다. 그러나 다음의 사실들은 당신의 생각을 혼란스럽게 할 수 있습니다.
-
- 지난 40년 동안 많은 분야에서 (언어학/번역학과 같은) 연구들은 이러한 범용적인 동적 데이터 (내가 만든 단어) 방식의 학습 알고리즘이 실제 사람을 이용한 명확한 규칙을 필요로 하는 방법보다 더 낫다는 것을 보여주었다. 기계 학습의 방법은 결국 인간 전문가들을 물리쳤다.
-
- 당신이 마지막으로 쓴 함수는 정말 입니다. 그것은 의 면적 과 의 침실 의 수를 알지도 못합니다. 그것은 단지 을 흔들고 숫자를 바꾸어 올바른 답을 얻습니다.
-
- 당신은 왜 특정한 무게값이 작동하는지 알 수 없을지도 모릅니다. 그래서 당신은 당신이 실제로 이해하지 못하지만 증명할 수 있는 함수를 작성합니다.
-
- 여러분의 프로그램에서 면적 과 침실 과 같은 파라미터가 아닌 숫자의 집합을 받아들이는 것을 상상해보세요. 각 숫자가 여러분의 차 지붕에 설치된 카메라에서 캡처된 화면의 픽셀을 나타내는 것을 가정하고, 예측된 출력을 가격 이라 부르지 않고 스티어링 의 회전 이라고 부르세요. 그러면 여러분은 여러분의 차를 자동으로 조작할 수 있는 프로그램을 갖게 됩니다!
미친 짓이죠?
3단계에서 각 숫자를 시도한 은 어떻게 될까요?
자, 물론 모든 가능한 무게값을 시도해서 가장 좋은 조합을 찾아내는 것은 불가능합니다. 시도해야 할 숫자가 무한할 수 있기 때문에 시간이 오래 걸릴 것입니다. 이런 상황을 피하기 위해, 수학자들은 훌륭한 무게값을 빨리 찾아내기 위해 많은 영리한 방법을 찾아냈는데, 그 중 하나는 다음과 같습니다. 먼저, 2단계를 나타내는 간단한 방정식을 써봅시다.
이것은 여러분의 비용 함수입니다.
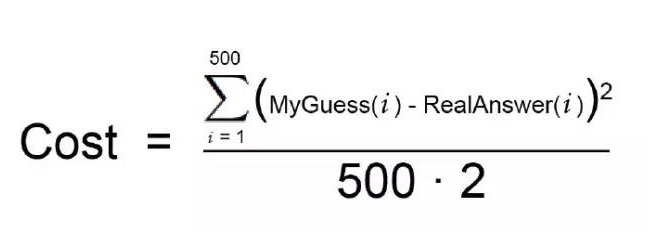
다음으로, 같은 수학적 용어를 다시 써봅시다. (지금은 무시해도 됩니다.)
θ는 현재 무게값을 나타낸다. J(θ) 는 ?? 의 현재 무게값에 대응하는 비용이다.
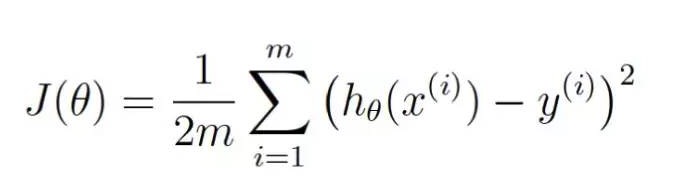
이 방정식은 우리의 평가 절차가 현재의 무게값에서 얼마나 벗어났는지 나타냅니다.
침실 수와 면적에 대한 모든 가능한 무게값을 그래픽으로 표시하면 아래와 같은 도표를 얻을 수 있습니다.
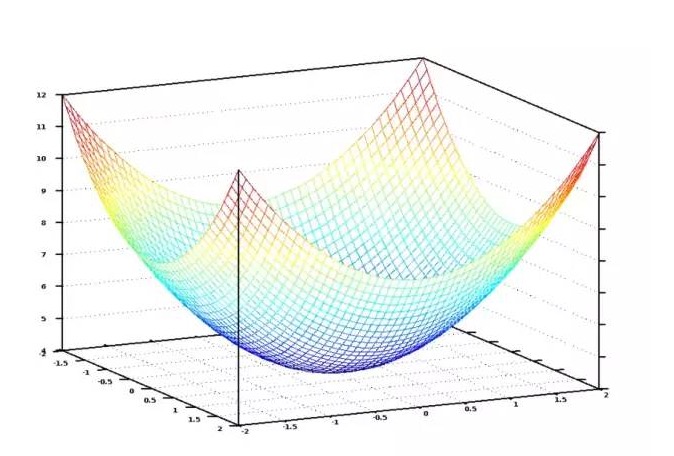
가격 함수의 그래픽 이미지 한 그릇. 수직축은 가격을 나타냅니다.
이 그림에서 파란색으로 표시된 최저점은 비용이 가장 적게 드는 곳입니다. 즉, 우리의 프로그램이 가장 적게 편차하는 곳입니다. 가장 높은 점은 가장 많이 편차하는 것을 의미합니다. 따라서, 우리가 이 그림에서 최저점으로 가는 무게값의 집합을 찾을 수 있다면, 우리는 답을 찾을 수 있습니다!
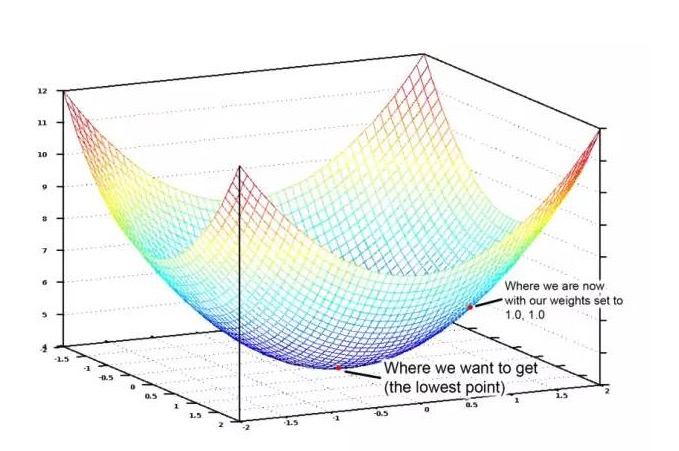
따라서 우리는 단지 무게를 조정할 필요가 있습니다. 그래프에서 가장 낮은 지점으로 내려갈 수 있습니다. 무게에 대한 작은 조정이 계속해서 가장 낮은 지점으로 이동 할 수 있다면, 결국 우리는 너무 많은 무게를 시도하지 않고 거기에 도착 할 수 있습니다.
만약 미적분학을 조금 기억한다면, 만약 여러분이 함수에서 미적분학을 추론한다면, 그 결과는 함수가 어떤 지점에서 기울었는지 알려줄 것입니다. 다른 말로 하면, 그래프에서 주어진 점에 대해, 그것은 우리에게 그 길이 내리막길이라는 것을 알려줍니다. 우리는 이 점을 이용하여 밑으로 나아갈 수 있습니다.
따라서, 만약 우리가 비용 함수에 대해 각 무게에 대해 편향을 구한다면, 우리는 각 무게에서 그 값을 수 있다. 이것은 우리가 더 가까이 산의 바닥으로 데려다 줄 수 있다. 이렇게 계속하면, 결국 우리는 바닥에 도달하고 무게의 최우수 값을 얻을 것이다.
이 방법의 최적의 무게를 찾는 방법은 수량 경사 하락이라고 불리는데, 위의 것은 그것의 고도 일반화이다. 세부사항을 알고 싶다면, 두려워하지 말고, 계속 깊이 들어가십시오.
실제 문제를 해결하기 위해 머신러닝 알고리즘 라이브러리를 사용할 때, 모든 것이 준비되어 있습니다. 그러나 구체적인 세부 사항을 이해하는 것은 항상 유용합니다.
다른 어떤 것을 간과했나요?
제가 앞서 설명한 3단계 알고리즘은 다중선형 회귀라고 불립니다. 여러분이 계산하는 방정식은 모든 집값 데이터 지점들을 포함할 수 있는 직선을 찾는 것입니다. 그리고 여러분은 이 방정식을 사용하여 집값이 여러분의 직선에서 나타날 수 있는 위치에 따라 여러분이 본 적이 없는 집값을 계산합니다. 이 아이디어는 매우 강력합니다. 실제 집값 문제를 해결하는 데 사용할 수 있습니다.
하지만 제가 보여드린 방법은 간단한 경우에만 효과가 있을 수 있습니다. 모든 경우에만 효과가 있는 것은 아닙니다. 그 이유 중 하나는 집값이 항상 단순하게 연속된 직선을 따라가지 않기 때문입니다.
그러나, 다행히도, 이런 상황을 처리하는 많은 방법이 있습니다. 비선형 데이터에 대해서는, 다른 많은 종류의 기계 학습 알고리즘이 처리할 수 있습니다 (나이러널 네트워크나 핵 벡터 기계와 같이). 또한, 더 복잡한 선들을 사용하여 적용하는 것을 생각하기 위해, 선형 회귀를 더 유연하게 사용하는 많은 방법이 있습니다. 모든 상황에서, 최우수 가중치를 찾는 기본적인 생각은 여전히 적용됩니다.
또한, 저는 융합이라는 개념을 간과했습니다. 여러분의 원시 데이터 집합에 있는 집값을 완벽하게 예측할 수 있지만, 원시 데이터 집합 이외의 새로운 집값을 정확하게 예측할 수 없는 이런 무게값의 집합을 쉽게 발견할 수 있습니다. 이런 상황을 해결하기 위한 많은 방법이 있습니다. (정규화와 크로스 검증 데이터 집합을 사용하는 것 처럼) 이 문제를 다루는 방법을 배우는 것은 머신 러닝을 잘 적용하는 데 매우 중요합니다.
다른 말로 하면, 기본 개념은 매우 간단합니다. 기계 학습을 사용해서 유용한 결과를 얻으려면 약간의 기술과 경험이 필요합니다. 하지만, 이것은 모든 개발자가 배울 수 있는 기술입니다.
-
-
기계학습은 무궁무진한 것인가?
일단 여러분이 머신러닝 기술을 어렵다고 보이는 문제를 해결하는데 쉽게 적용할 수 있다는 것을 이해하게 되면 (예: 손글씨 인식) 여러분은 머신러닝을 통해 어떤 문제든 해결할 수 있다는 느낌을 갖게 될 것입니다. 충분한 데이터가 있다면 말이죠. 단지 데이터를 입력하면 컴퓨터의 변주법처럼 그에 맞는 방정식을 찾아낼 수 있을 것입니다.
하지만 기억해야 할 중요한 것은 머신러닝은 여러분이 가지고 있는 데이터로 실제로 해결할 수 있는 문제에만 적용된다는 것입니다.
예를 들어, 만약 여러분이 집 안에 있는 식물들의 수를 기준으로 집값을 예측하는 모델을 만들면, 그것은 결코 성공하지 못할 것입니다. 집 안에 있는 식물들의 수와 집값 사이에 아무런 관계가 없습니다. 그래서, 아무리 노력해도 컴퓨터는 둘 사이의 관계를 추론할 수 없습니다.
그리고 그 중 하나는, 당신이 실제로 존재하는 관계를 모델링할 수 있다는 것입니다.
-
기계학습을 어떻게 깊이 배울 수 있을까요?
제 생각에는 현재 기계학습의 가장 큰 문제점은 주로 학계와 기업 연구 조직에서 활동하고 있다는 것입니다. 전문가가 아닌 일반인을 알고 싶어하는 사람들에게는 쉬운 학습 자료가 많지 않습니다. 그러나 이것은 매일 개선되고 있습니다.
앙드루 (Andrew Ng) 코르세라 (Coursera) 의 무료 머신러닝 코스는 아주 좋은데요. 여기로 들어가기를 강력히 추천합니다. 컴퓨터 과학을 전공하고 수학을 조금이라도 기억하는 사람이라면 누구나 이해할 수 있을 겁니다.
또한, 당신은 SciKit-Learn을 다운로드하고 설치하여 수천 개의 기계 학습 알고리즘을 시험할 수 있습니다. 그것은 모든 표준 알고리즘에 대한 블랙박스 버전의 파이썬 프레임워크입니다.
파이썬 개발자