
Market Collector가 다시 업그레이드되었습니다. CSV 형식 파일 가져오기를 지원하고 사용자 정의 데이터 소스를 제공합니다.
최근, 한 사용자가 Inventor Quantitative Trading Platform의 백테스팅 시스템을 위한 데이터 소스로 자신의 CSV 형식 파일을 사용해야 했습니다. Inventor Quantitative Trading Platform의 백테스팅 시스템은 많은 기능을 가지고 있으며 사용하기 간편하고 효율적입니다. 데이터가 있는 한 백테스팅을 수행할 수 있으며 더 이상 플랫폼 데이터 센터에서 지원하는 거래소와 제품에 국한되지 않습니다. .
디자인 아이디어
디자인 아이디어는 사실 매우 간단합니다. 이전 마켓 컬렉터에 약간의 변경만 하면 됩니다. 마켓 컬렉터에 매개변수를 추가합니다.isOnlySupportCSV백테스팅 시스템의 데이터 소스로 CSV 파일만 사용할지 여부를 제어하고 다른 매개변수를 추가하는 데 사용됩니다.filePathForCSV, 마켓 수집 로봇이 실행되는 서버의 CSV 데이터 파일에 대한 경로를 설정하는 데 사용됩니다. 마지막으로,isOnlySupportCSV매개변수가 설정되어 있습니까?True어떤 데이터 소스를 사용할 것인지 결정하기 위해(1. 직접 수집한 데이터, 2. CSV 파일의 데이터) 이 변경 사항은 주로 다음과 같습니다.Provider수업do_GET기능.
CSV 파일이란 무엇인가요?
쉼표로 구분된 값(CSV, 구분 문자가 쉼표가 아닐 수도 있기 때문에 문자로 구분된 값이라고도 함)은 일반 텍스트로 표 형식 데이터(숫자와 텍스트)를 저장하는 파일입니다. 일반 텍스트란 파일이 일련의 문자로 구성되어 있으며 이진수처럼 해석해야 하는 데이터가 포함되지 않음을 의미합니다. CSV 파일은 줄 바꿈 문자로 구분된 여러 개의 레코드로 구성됩니다. 각 레코드는 필드로 구성되며, 필드 간의 구분 기호는 다른 문자나 문자열인데, 가장 일반적인 것은 쉼표나 탭입니다. 일반적으로 모든 레코드는 정확히 동일한 필드 시퀀스를 갖습니다. 일반적으로 이러한 파일은 일반 텍스트 파일입니다. WORDPAD나 Notepad로 여는 것이 좋습니다. 다른 방법은 새 파일로 저장한 다음 EXCEL로 여는 것입니다.
CSV 파일 형식에 대한 보편적인 표준은 없지만 특정 규칙이 있습니다. 일반적으로 레코드당 한 줄이고 첫 줄이 헤더입니다. 각 행의 데이터는 쉼표로 구분됩니다.
예를 들어, 테스트에 사용한 CSV 파일은 메모장으로 열면 다음과 같습니다.
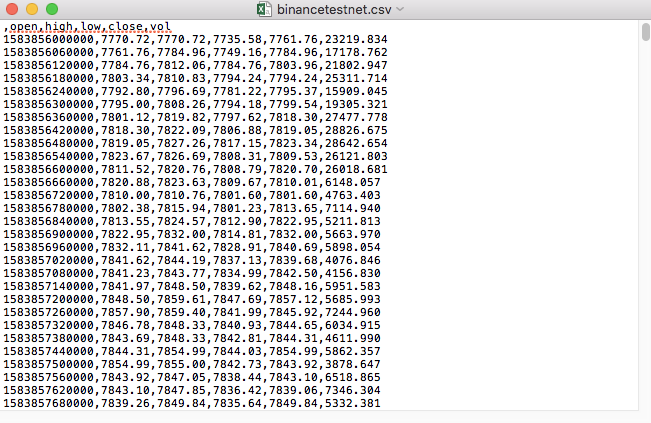
CSV 파일의 첫 번째 줄이 테이블 헤더라는 점에 주목하세요.
,open,high,low,close,vol
이 데이터를 파싱하고 구성한 다음 백테스팅 시스템의 사용자 정의 데이터 소스에서 요구하는 형식으로 구성해야 합니다. 이는 이전 기사의 코드에서 이미 처리되었으며 약간의 수정만 필요합니다.
수정된 코드
import _thread
import pymongo
import json
import math
import csv
from http.server import HTTPServer, BaseHTTPRequestHandler
from urllib.parse import parse_qs, urlparse
def url2Dict(url):
query = urlparse(url).query
params = parse_qs(query)
result = {key: params[key][0] for key in params}
return result
class Provider(BaseHTTPRequestHandler):
def do_GET(self):
global isOnlySupportCSV, filePathForCSV
try:
self.send_response(200)
self.send_header("Content-type", "application/json")
self.end_headers()
dictParam = url2Dict(self.path)
Log("自定义数据源服务接收到请求,self.path:", self.path, "query 参数:", dictParam)
# 目前回测系统只能从列表中选择交易所名称,在添加自定义数据源时,设置为币安,即:Binance
exName = exchange.GetName()
# 注意,period为底层K线周期
tabName = "%s_%s" % ("records", int(int(dictParam["period"]) / 1000))
priceRatio = math.pow(10, int(dictParam["round"]))
amountRatio = math.pow(10, int(dictParam["vround"]))
fromTS = int(dictParam["from"]) * int(1000)
toTS = int(dictParam["to"]) * int(1000)
# 要求应答的数据
data = {
"schema" : ["time", "open", "high", "low", "close", "vol"],
"data" : []
}
if isOnlySupportCSV:
# 处理CSV读取,filePathForCSV路径
listDataSequence = []
with open(filePathForCSV, "r") as f:
reader = csv.reader(f)
# 获取表头
header = next(reader)
headerIsNoneCount = 0
if len(header) != len(data["schema"]):
Log("CSV文件格式有误,列数不同,请检查!", "#FF0000")
return
for ele in header:
for i in range(len(data["schema"])):
if data["schema"][i] == ele or ele == "":
if ele == "":
headerIsNoneCount += 1
if headerIsNoneCount > 1:
Log("CSV文件格式有误,请检查!", "#FF0000")
return
listDataSequence.append(i)
break
# 读取内容
while True:
record = next(reader, -1)
if record == -1:
break
index = 0
arr = [0, 0, 0, 0, 0, 0]
for ele in record:
arr[listDataSequence[index]] = int(ele) if listDataSequence[index] == 0 else (int(float(ele) * amountRatio) if listDataSequence[index] == 5 else int(float(ele) * priceRatio))
index += 1
data["data"].append(arr)
Log("数据:", data, "响应回测系统请求。")
self.wfile.write(json.dumps(data).encode())
return
# 连接数据库
Log("连接数据库服务,获取数据,数据库:", exName, "表:", tabName)
myDBClient = pymongo.MongoClient("mongodb://localhost:27017")
ex_DB = myDBClient[exName]
exRecords = ex_DB[tabName]
# 构造查询条件:大于某个值{'age': {'$gt': 20}} 小于某个值{'age': {'$lt': 20}}
dbQuery = {"$and":[{'Time': {'$gt': fromTS}}, {'Time': {'$lt': toTS}}]}
Log("查询条件:", dbQuery, "查询条数:", exRecords.find(dbQuery).count(), "数据库总条数:", exRecords.find().count())
for x in exRecords.find(dbQuery).sort("Time"):
# 需要根据请求参数round和vround,处理数据精度
bar = [x["Time"], int(x["Open"] * priceRatio), int(x["High"] * priceRatio), int(x["Low"] * priceRatio), int(x["Close"] * priceRatio), int(x["Volume"] * amountRatio)]
data["data"].append(bar)
Log("数据:", data, "响应回测系统请求。")
# 写入数据应答
self.wfile.write(json.dumps(data).encode())
except BaseException as e:
Log("Provider do_GET error, e:", e)
def createServer(host):
try:
server = HTTPServer(host, Provider)
Log("Starting server, listen at: %s:%s" % host)
server.serve_forever()
except BaseException as e:
Log("createServer error, e:", e)
raise Exception("stop")
def main():
LogReset(1)
if (isOnlySupportCSV):
try:
# _thread.start_new_thread(createServer, (("localhost", 9090), )) # 本机测试
_thread.start_new_thread(createServer, (("0.0.0.0", 9090), )) # VPS服务器上测试
Log("开启自定义数据源服务线程,数据由CSV文件提供。", "#FF0000")
except BaseException as e:
Log("启动自定义数据源服务失败!")
Log("错误信息:", e)
raise Exception("stop")
while True:
LogStatus(_D(), "只启动自定义数据源服务,不收集数据!")
Sleep(2000)
exName = exchange.GetName()
period = exchange.GetPeriod()
Log("收集", exName, "交易所的K线数据,", "K线周期:", period, "秒")
# 连接数据库服务,服务地址 mongodb://127.0.0.1:27017 具体看服务器上安装的mongodb设置
Log("连接托管者所在设备mongodb服务,mongodb://localhost:27017")
myDBClient = pymongo.MongoClient("mongodb://localhost:27017")
# 创建数据库
ex_DB = myDBClient[exName]
# 打印目前数据库表
collist = ex_DB.list_collection_names()
Log("mongodb ", exName, " collist:", collist)
# 检测是否删除表
arrDropNames = json.loads(dropNames)
if isinstance(arrDropNames, list):
for i in range(len(arrDropNames)):
dropName = arrDropNames[i]
if isinstance(dropName, str):
if not dropName in collist:
continue
tab = ex_DB[dropName]
Log("dropName:", dropName, "删除:", dropName)
ret = tab.drop()
collist = ex_DB.list_collection_names()
if dropName in collist:
Log(dropName, "删除失败")
else :
Log(dropName, "删除成功")
# 开启一个线程,提供自定义数据源服务
try:
# _thread.start_new_thread(createServer, (("localhost", 9090), )) # 本机测试
_thread.start_new_thread(createServer, (("0.0.0.0", 9090), )) # VPS服务器上测试
Log("开启自定义数据源服务线程", "#FF0000")
except BaseException as e:
Log("启动自定义数据源服务失败!")
Log("错误信息:", e)
raise Exception("stop")
# 创建records表
ex_DB_Records = ex_DB["%s_%d" % ("records", period)]
Log("开始收集", exName, "K线数据", "周期:", period, "打开(创建)数据库表:", "%s_%d" % ("records", period), "#FF0000")
preBarTime = 0
index = 1
while True:
r = _C(exchange.GetRecords)
if len(r) < 2:
Sleep(1000)
continue
if preBarTime == 0:
# 首次写入所有BAR数据
for i in range(len(r) - 1):
bar = r[i]
# 逐根写入,需要判断当前数据库表中是否已经有该条数据,基于时间戳检测,如果有该条数据,则跳过,没有则写入
retQuery = ex_DB_Records.find({"Time": bar["Time"]})
if retQuery.count() > 0:
continue
# 写入bar到数据库表
ex_DB_Records.insert_one({"High": bar["High"], "Low": bar["Low"], "Open": bar["Open"], "Close": bar["Close"], "Time": bar["Time"], "Volume": bar["Volume"]})
index += 1
preBarTime = r[-1]["Time"]
elif preBarTime != r[-1]["Time"]:
bar = r[-2]
# 写入数据前检测,数据是否已经存在,基于时间戳检测
retQuery = ex_DB_Records.find({"Time": bar["Time"]})
if retQuery.count() > 0:
continue
ex_DB_Records.insert_one({"High": bar["High"], "Low": bar["Low"], "Open": bar["Open"], "Close": bar["Close"], "Time": bar["Time"], "Volume": bar["Volume"]})
index += 1
preBarTime = r[-1]["Time"]
LogStatus(_D(), "preBarTime:", preBarTime, "_D(preBarTime):", _D(preBarTime/1000), "index:", index)
# 增加画图展示
ext.PlotRecords(r, "%s_%d" % ("records", period))
Sleep(10000)
테스트 실행
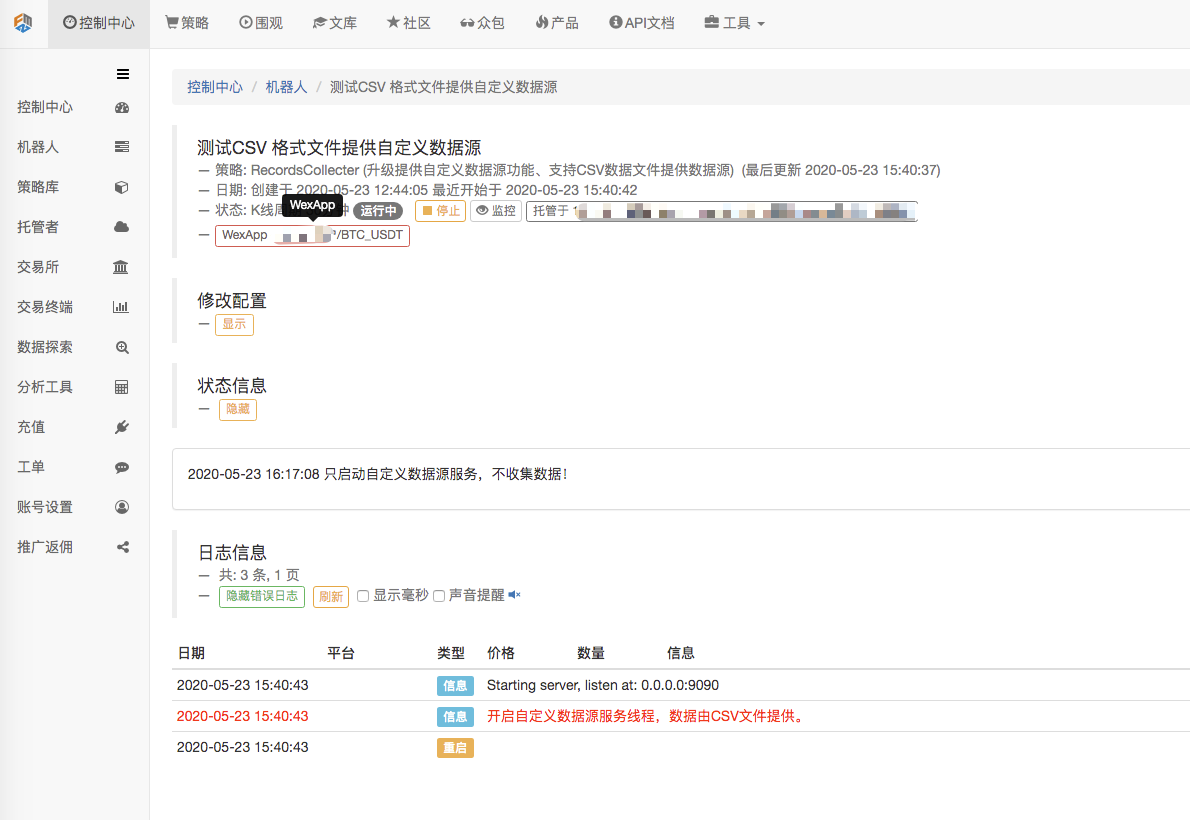
먼저, 시장 수집 로봇을 시작하고, 로봇에 거래소를 추가한 후 로봇을 실행합니다.
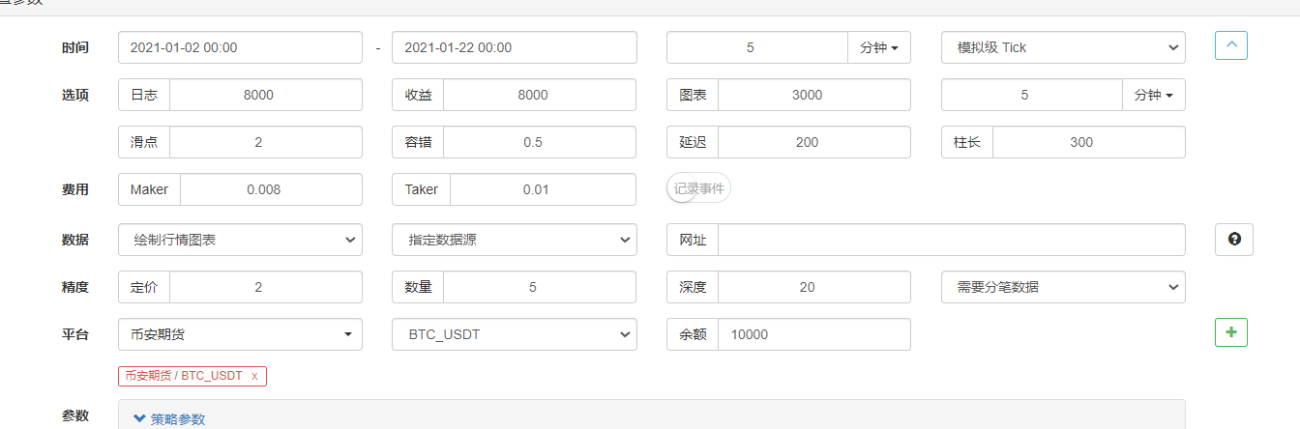
매개변수 구성:

그런 다음 테스트 전략을 만듭니다.
function main() {
Log(exchange.GetRecords())
Log(exchange.GetRecords())
Log(exchange.GetRecords())
}
전략은 매우 간단합니다. K-라인 데이터 3개만 얻어서 출력하면 됩니다.
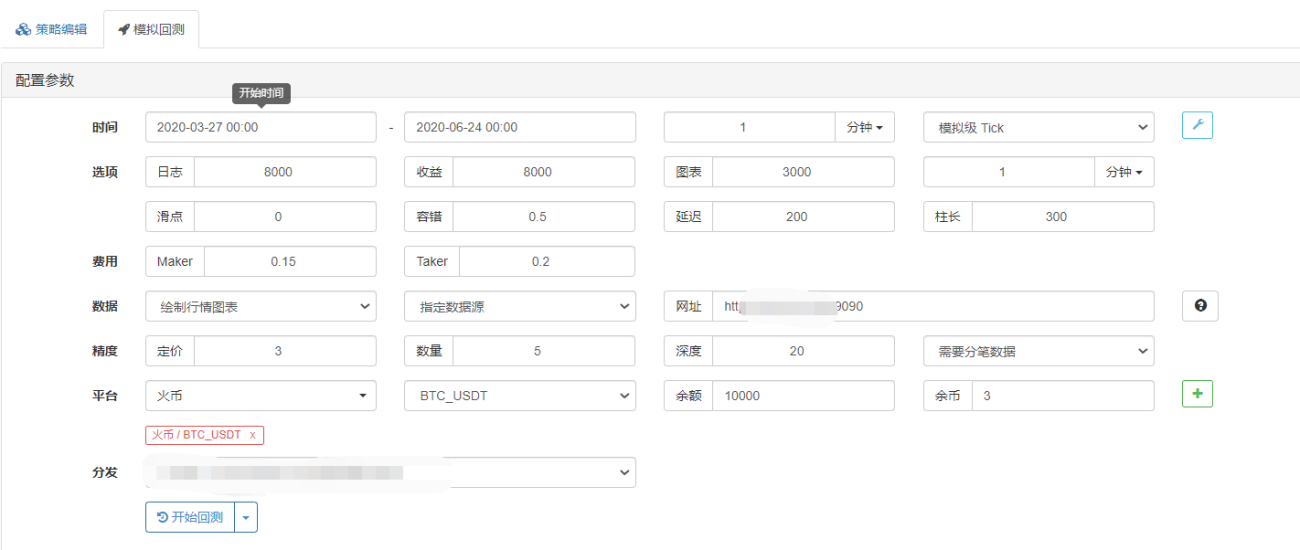
백테스팅 페이지에서 백테스팅 시스템의 데이터 소스를 사용자 지정 데이터 소스로 설정하고, 마켓 수집 로봇이 실행되는 서버 주소를 입력합니다. CSV 파일의 데이터는 1분 K-라인입니다. 따라서 백테스팅을 할 때 K-라인 기간을 1분으로 설정합니다.
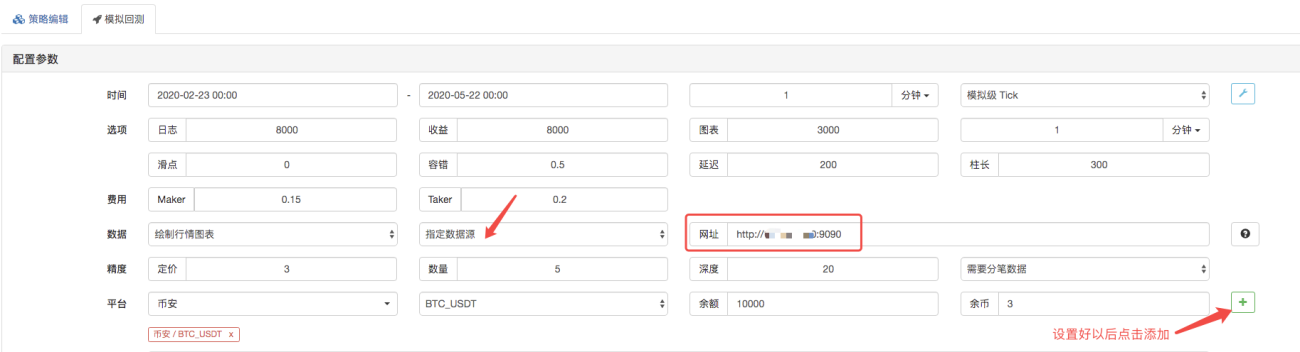
백테스팅 시작을 클릭하면 마켓 수집 로봇이 데이터 요청을 수신합니다.

백테스팅 시스템이 전략 실행을 완료한 후, 데이터 소스의 K-라인 데이터를 기반으로 K-라인 차트를 생성합니다.
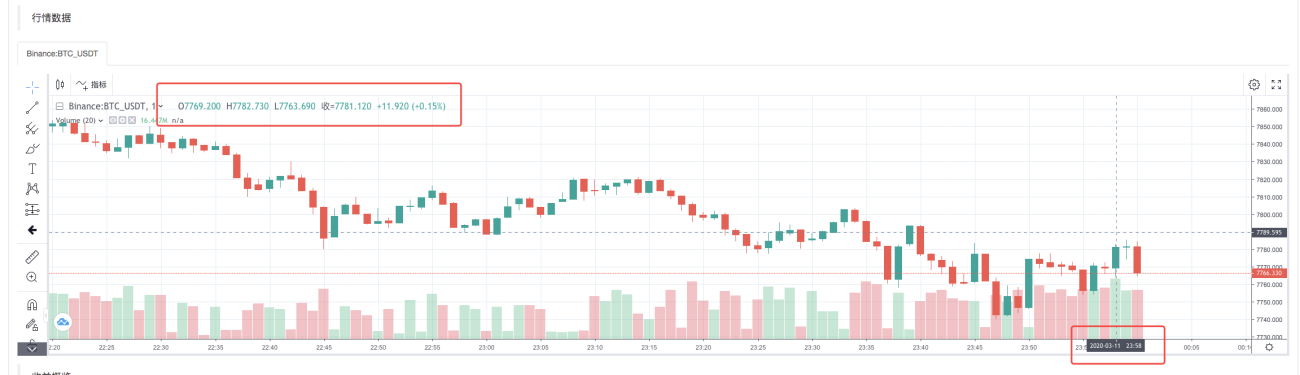
파일의 데이터를 비교하세요:
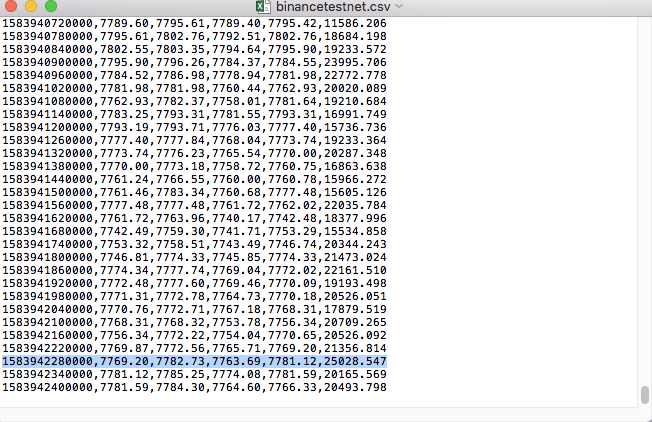

RecordsCollector(사용자 정의 데이터 소스 기능을 제공하기 위해 업그레이드됨, 데이터 소스를 제공하기 위해 CSV 데이터 파일 지원)
이것은 단지 시작점일 뿐입니다. 메시지를 남겨 주시면 감사하겠습니다.




请问一下,为什么我在托管服务器上面设置好了自定义CSV数据源,用页面请求有数据的返回,然后在回测中没有数据的返回,当把数据直接设置为只有俩个数据的时候httpserver服务端可以接收请求中, 




你在浏览器端可以是因为 你指定写的查询参数, 回测系统 触发不了 机器人 应答,说明机器人没接受到请求, 说明回测时那个地方配置错了, 检查下,调试下就能找到问题。
请问一下 怎么可以在本地起http服务端 本地回测数据, 是不是本地回测不支持回测自定义数据源?我在本地回测添加exchanges: [{"eid":"Huobi","currency":"ETH_USDT","feeder":"http://127.0.0.1:9090"}]这种参数,以及改成机器人的IP也是没有请求到服务端



- 1