
8
Follow
1364
Followers
우리가 확률을 예측할 때, 무엇을 예측하는 것인가?
제가 오래 전에 인터뷰를 한 적이 있는데, 그 인터뷰의 주제는 제게 생생하게 다가왔습니다. 그 당시의 인터뷰 과정은 다음과 같았습니다.
면접관: 로지스틱 회귀에 대해 알고 계십니까?
<unk>: 물론 알아요.
면접관: 그럼 로지스틱 회귀 예측의 확률은 어떻게 해석될까요?
나: 물론 아닙니다. 하나의 관찰만 있으면 개체 확률은 추정할 수 없습니다. N개의 개체들이 동일한 특징을 가지고 있다면, 성공률은 추정할 수 있는 확률과 같다고 해석해야 합니다.
물론 마지막 면접 결과로 저는 지워졌습니다. (정말 통계학이나 컴퓨터학이 아닌 경제학에 대한 저의 배경 때문일 수도 있습니다.)
제가 말씀드린 것은 약간 모순적이거나 이해하기가 어렵다고 생각하실 수도 있습니다.
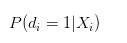
"이것이 개인의 성공 확률로 해석되어야 하지 않겠습니까?"
-
저는 이런 주장이 문제가 있다고 생각합니다.
한 개인이 성공할 확률을 말할 때, 동일한 사람이 동일한 조건 하에서 100번 반복해서 평균적으로 얼마나 많은 번 성공했는가를 말해야 합니다. 만약 t를 한 사람이 시도한 횟수라고 쓰면, 우리의 이상적인 모델 (데이터 생성 과정) 은 다음과 같이 되어야 합니다:
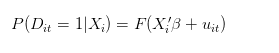
그러나, 대안적으로, 실제 데이터 생성 과정은 다음과 같을 수 있습니다:
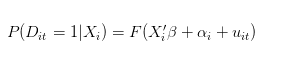

Related Recommendations

