

목차
제1장 양적 거래의 기본
1.1 양적 거래란 무엇인가요?
요약
과학과 기계의 결합으로 탄생한 양적 거래는 현대 금융 시장의 지형을 변화시키고 있습니다. 이제 많은 투자자들이 이 분야에 관심을 돌리고 있습니다. 위험을 최소화하고 최대의 수익을 얻으려면 어떻게 해야 할까? 이것이 또한 이 과정 시리즈의 목적입니다. 첫 번째 기사로서, 우리는 "양적 거래란 무엇인가"를 간략하게 설명할 것입니다.
개요
많은 사람들이 "양적 거래"라는 용어를 들으면, 그것이 고급 거래이고 하룻밤 사이에 부자가 될 수 있다고 생각합니다. 딥러닝, 빅데이터, 클라우드 컴퓨팅 등 첨단기술의 등장과 함께 인공지능 시대가 도래하면서, 인공지능은 신비한 색깔을 띠게 되었습니다. 양적 거래가 활용된다면 '완벽한' 거래 전략을 구축할 수 있을 것으로 보인다.
사실, 어느 정도 양적 거래는 신화가 되었습니다. 거래를 제쳐두고, "양적화"는 실제로 과학적 투자 시스템을 통해 컴퓨터, 통계, 수학 및 기타 방법을 사용하여 예상되는 거래 신호 시스템 집합을 찾는 것입니다. 이 신호 시스템은 언제, 어떤 가격에 매수 또는 매도해야 하는지 알려줍니다.
양적 거래의 발전
근원으로 돌아가서, 데이터 변화를 분석하고 시장 가격 변동 패턴을 발견하기 위해 최초로 정량적 방법을 사용한 사람은 주식의 발상지인 네덜란드인도 아니고, 근대 금융을 장려한 영국인도 아니고, 국가 건국 이래 금융과 공존해온 미국인도 아닌 프랑스인이었습니다.
18세기 초, 프랑스 주식 중개인 보조원인 쥘 레그노는 주가 변동에 대한 현대적 이론을 제안했습니다. 그는 나중에 "확률 계산과 주식 거래 철학"이라는 책을 출판했는데, 이 책에서 그는 자신이 발견한 시장 상승과 하락의 법칙(정규 분포)을 자세히 설명했습니다. "가격 편차는 시간의 제곱근에 비례합니다." 그리고 마침내 합리적이고 정량적인 투자 결정을 통해 거래 성공을 이루었습니다.
요즘은 인터넷+빅데이터+클라우드 컴퓨팅+인공지능 시대로 인해 양적 거래도 급속히 발전하고 있습니다. 한때 세계 금융의 중심지였던 런던의 캐나리 워프는 오래전부터 IT 기업들의 허브가 되었습니다. 세계 최고의 투자 은행들도 자체적인 양적 팀을 육성하고 있으며, "모델을 얻는 자가 세상을 이긴다"는 금융 전쟁에 참여하려 하고 있습니다. 거래 모델을 개발하는 이러한 IT 팀을 양적 팀이라고도 합니다. 규모 면에서 먼저 시작한 미국은 이미 다수의 강력한 양적 헤지펀드를 보유하고 있습니다.
반면, 중국에서는 하드웨어 장비와 투자 연구 역량이 모두 아직 초기 단계에 있습니다. 그러나 점점 더 많은 기관과 전문 투자자들이 양적 거래의 이점을 깨닫고 이 분야에 참여하고 있습니다. 특히 감독이 점점 더 엄격해지고 시장 효율성이 점차 향상됨에 따라 양적 거래는 더 넓은 성장 여지를 갖게 되었습니다.
양적거래의 특징
과학적 검증: 거래 시스템이 생기면 시뮬레이션 거래 시스템을 사용하여 효과를 테스트하면 엄청난 시간이 소요될 수 있습니다. 실제 거래 시스템으로 직접 테스트하면 실제 돈을 잃을 수 있습니다. 그러나 양적 거래에서 백테스팅 기능은 방대한 양의 과거 데이터를 통해 과학적인 방법으로 거래 시스템을 테스트하는 데 사용될 수 있습니다. 대중의 유행을 따르기보다는, 무엇이 효과가 있고 무엇이 효과가 없는지 데이터를 통해 알아보세요.
객관적이고 정확하다: 거래에서 우리의 진짜 적은 우리 자신입니다. 우리의 정신을 관리하는 것은 말하기는 쉽지만 실천하기는 어렵습니다. 탐욕, 두려움, 행운과 같은 인간의 약점은 거래 시장에서 몇 배로 확대될 것입니다. 양적 거래는 우리가 이러한 약점을 극복하고 거래에서 더 나은 결정을 내리는 데 도움이 될 수 있습니다.
시기적절하고 효율적: 주관적 거래에서 사람들의 반응 속도는 컴퓨터보다 빠를 수 없고, 사람들의 체력과 에너지는 하루 24시간 운영될 수 없습니다. 기회가 덧없는 거래 시장에서 양적 거래는 주관적 거래를 완전히 대체하고, 거래 기회를 찾고, 시기적절하고 빠르게 시장 변화를 추적할 수 있습니다.
위험 관리: 양적 거래는 과거 데이터로부터 미래에 반복될 수 있는 과거 패턴을 탐색할 수 있을 뿐만 아니라, 이러한 과거 패턴은 승리 확률이 더 높은 전략이기도 합니다. 체계적 위험을 줄이고 자금 조달 곡선을 원활하게 하기 위해 다양한 투자 포트폴리오를 구축할 수도 있습니다.
양적 거래를 위한 고전적인 거래 전략은 무엇입니까?
브레이크아웃 전략 개시
개장 후 첫 30분은 종종 그날의 추세를 결정할 수 있습니다. 이 전략은 개장 후 30분 이내에 가격이 양수선인지 음수선인지를 그날의 추세를 판단하는 기준으로 사용합니다. 플러스 라인이면 매수 포지션을 열고, 마이너스 라인이면 매도 포지션을 열고, 닫기 전 몇 분 이내에 포지션을 닫습니다. 이는 매우 간단한 거래 전략입니다.
돈치안 채널 전략
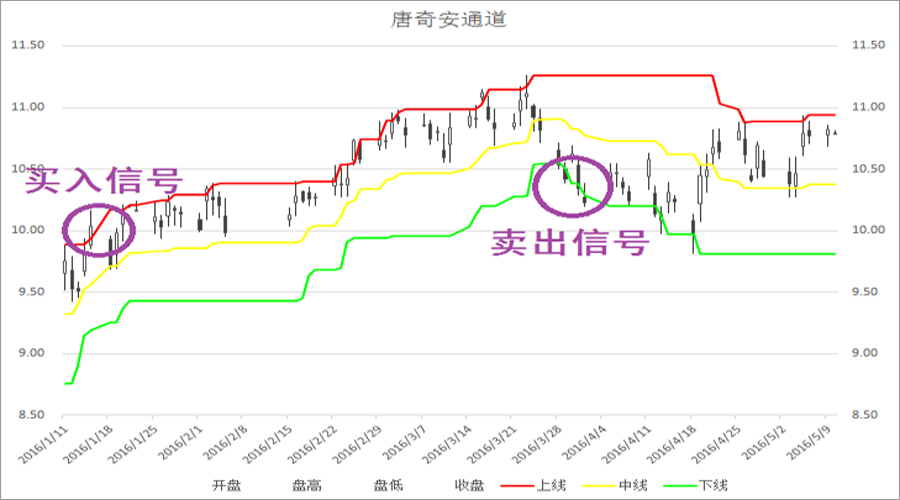
그림 1-1 Donchian 채널 전략 다이어그램
Donchian Channel 전략은 일일 거래의 조상으로 간주될 수 있습니다. 규칙은 다음과 같습니다. 현재 가격이 이전 N K-라인의 최고 가격보다 높으면 매수하고, 현재 가격이 이전 N K-라인의 최저 가격보다 낮으면 매도합니다. 유명한 거북이 거래 규칙은 돈키안 채널 전략의 수정된 버전을 사용합니다.
교차 기간 차익 거래 전략
교차 기간 차익거래는 가장 일반적인 유형의 차익거래입니다. 이는 동일한 거래 상품에 대해 다른 인도월을 가진 계약의 가격을 기반으로 합니다. 두 가격 사이에 큰 가격 차이가 있는 경우, 서로 다른 기간의 선물 계약을 동시에 매수 및 매도하여 교차 기간 차익거래를 수행할 수 있습니다. 본계약과 2차 본계약의 가격 차이가 장기간 -50~50 정도로 유지된다고 가정해 보겠습니다. 만약 어느 날 스프레드가 70에 도달한다면, 미래의 어느 시점에서 스프레드가 50으로 돌아올 것으로 예상됩니다. 그런 다음 주요 계약을 매도하고 동시에 보조 주요 계약을 매수해 가격 차이를 매도할 수 있습니다. 그 반대도 마찬가지다.
요약하다
위에서 우리는 정의, 개발, 특성 및 고전적 거래 전략 측면에서 양적 거래의 관련 개념을 간략하게 소개했습니다.
양적 거래를 이해하는 것은 양적 투자자가 되기 위한 중요한 디딤돌입니다. 마지막으로, 저는 모든 사람들이 하락장에서 부자가 되고 가능한 한 빨리 지식의 실현을 실현하기를 바랍니다! 기억하세요, 재정적 자유를 얻기 위해서는 단 한 번의 강세장만 더 지나면 됩니다!
다음 섹션 미리보기
양적 거래와 전통적 거래의 차이점은 무엇입니까? 실제 거래에서는 전통적 거래를 선택해야 할까요, 아니면 양적 거래를 선택해야 할까요? 다음 섹션에서는 이 두 가지 질문을 통해 양적 거래를 더 깊이 이해해보겠습니다.
숙제
- 양적 거래가 무엇인지 한 문장으로 간단히 설명하세요?
- 양적 거래의 특징은 무엇입니까?
1.2 왜 양적 거래를 선택해야 합니까?
요약
많은 사람들이 양적 거래를 논의할 때 복잡한 전략 프로그래밍을 시작점으로 삼아 부주의하게 양적 거래에 대한 신비의 베일을 드리웁니다. 이 섹션에서는 양적 거래의 미스터리를 밝히기 위해 이해하기 쉬운 언어로 양적 거래의 간단한 "스케치"를 만들어보려고 합니다. 기본 지식이 없는 초보자라도 쉽게 이해할 수 있을 것이라고 생각합니다.
양적 거래와 주관적 거래의 차이점
주관적 거래는 인간 분석과 시장 감각에 더 많은 주의를 기울입니다. 매수 및 매도 신호가 나타나더라도 주문은 선택적으로 이루어집니다. 사람들은 실수를 하기보다는 시장을 놓치는 편을 택합니다. 인간의 감정은 복잡하고, 변하기 쉬우며, 신뢰할 수 없습니다. 대부분의 트레이더가 연속적인 손실을 경험하면 다른 방법으로 전환하는 경향이 있습니다. 매우 무작위적이며 수익과 손실에 의해 쉽게 흔들리기 때문에 안정적인 수익을 창출하기 어렵습니다.
양적 거래는 거래에 대한 이해를 통해 일관된 매수 및 매도 전략을 개발합니다. 거래에서 모든 트렌드를 동등하게 취급하고, 체계적인 방식으로 포지션을 열고 닫으십시오. 놓치는 것보다 실수를 하는 것이 낫습니다. 또한 과거 데이터의 백테스트를 통해 전략이 어떤 유형의 시장과 상품에 더 적합한지 판단하고, 여러 전략과 상품을 결합하여 수익성을 달성하는 완전한 평가 시스템도 갖추고 있습니다.
간단히 말해서, 주관적 거래는 양적 거래의 기초이며, 양적 거래는 주관적 거래를 개선한 것입니다. 주관적 거래는 무술을 연습하는 것과 더 비슷합니다. 결국 성공할 수 있는지 여부는 주로 재능에 달려 있습니다. 어떤 사람들은 10년 후에도 깨달음을 얻지 못할 수도 있고, 어떤 사람들은 하루 만에 깨달음을 얻을 수도 있습니다. 양적 트레이딩은 피트니스와 더 비슷합니다. 열심히 노력하면 재능이 없어도 근육을 만들 수 있습니다.
양적 거래가 주관적 거래보다 나은가?
성공적인 주관적 거래자는 어떤 의미에서는 양적 거래자이기도 합니다. 성공적인 주관적 거래자는 자신만의 규칙과 방법, 즉 거래 시스템을 갖춰야 합니다. 성공적인 주관적 거래는 거래 규율과 거래 규칙에 기반해야 하며, 거래 규칙의 실행 부분은 실제로 주관적 거래의 양적 부분입니다.
반면에 성공적인 양적 트레이더는 또한 뛰어난 주관적 트레이더여야 합니다. 왜냐하면 양적 트레이딩 전략을 개발하는 것은 실제로 개인의 트레이딩 철학을 결정짓는 것이기 때문입니다. 처음부터 시장에 대한 인식과 이해가 잘못되면, 그렇게 개발한 거래 전략은 장기적으로 수익을 내기 어려울 것입니다.
따라서 수익성의 관점에서 볼 때, 트레이더가 궁극적으로 성공할 수 있는지를 결정하는 핵심 요소는 주관적 트레이딩인지, 양적 트레이딩인지가 아니라 트레이딩 철학입니다. 양적 거래는 표면적으로는 거창하게 들릴 수 있지만, 그 이익의 본질은 본질적으로 주관적 거래와 다르지 않습니다. 그것은 하나의 것의 양면과 같으며, 둘 다 반대이고 통합되어 있습니다.
하지만 양적 거래가 거래 도구 측면에서 많은 장점을 가지고 있다는 것은 부인할 수 없습니다.
더 빠른 검토: 거래 전략을 테스트하려면 많은 양의 과거 데이터를 계산해야 합니다. 양적 거래는 몇 분 안에 결과를 계산할 수 있습니다. 이 속도는 주관적인 거래보다 몇 배나 빠릅니다.
더 과학적인:어떤 전략이 좋은지 평가하기 위해, 우리는 이기적인 사기꾼들이 아니라 데이터(샤프 비율, 최대 하락률, 연간 수익률 등)에 의존합니다.
더 많은 기회:세상에는 수천 가지의 거래 상품이 있습니다. 주관적인 거래에서는 동시에 시장을 모니터링하는 것이 불가능하지만, 양적 거래는 전체 시장을 실시간으로 모니터링하여 거래 기회를 놓치지 않고 수익성을 높일 수 있습니다.
양적 거래로 정말로 수익을 낼 수 있나요?
물론 가능합니다. 하지만 오랫동안 지속하기는 어렵습니다. 당신이 돈을 벌든 못 벌든 양적 거래 자체에 달려 있지 않고, 그것은 단지 도구일 뿐입니다. 양적 거래는 단순히 프로그래밍된, 규칙적이고 양적으로 거래 아이디어를 구현합니다. 프로그램은 실행을 대체할 뿐입니다. 가장 어려운 부분은 장기적으로 안정적으로 수익을 창출하는 것입니다. 시장은 게임이자 역동적으로 변화하기 때문에 거래 아이디어도 시장에 따라 바뀌어야 하기 때문입니다.
양적 거래의 위험
양적 거래에도 위험이 있습니다. 왜 그럴까요? 양적 거래는 과거 데이터에서 패턴을 발견하고 거래 전략을 수립하는 것입니다. 그러나 금융 시장은 생태계이며, 그 법률과 인간 본성은 상호작용하는 역동적인 과정입니다. 결국에는 여전히 인간 시장입니다. 시장의 법칙은 인간 본성의 영향을 받을 것이고, 인간 본성의 탐욕과 두려움은 시장의 변화에 따라 변할 것입니다. 시장에서 변하지 않는 법칙은 거의 없습니다. 거래 전략이 아무리 강력하더라도 그러한 갑작스러운 법률 변화에 대처하기는 어렵습니다.
요약하다
위의 설명을 통해 우리는 양적 거래가 고유한 거래 방법이 아니라, 거래 논리를 분석하고 거래 전략을 개선하는 데 도움이 되는 거래 도구일 뿐이라는 것을 알 수 있습니다. 가치 투자자든 기술 투자자든, 주식, 채권, 상품, 옵션 등 어떤 것에 투자하든 실제로 모든 것을 정량화할 수 있습니다. 개인적인 경험에 근거하여 결정을 내리는 트레이더와 비교해 볼 때, 양적 트레이더가 사용하는 무기는 시장 증거와 합리성입니다.
다음 섹션 미리보기
양적 분석은 단지 거래 방법이고, 전략은 단지 거래 아이디어를 전달하는 수단일 뿐이며, 프로그램은 각 거래 프로세스를 실행합니다. 다음 섹션에서는 양적 거래의 전체 라이프 사이클을 안내해 드리겠습니다. 여기에는 전략 구상, 모델 구축, 백테스팅 및 튜닝, 시뮬레이션 거래, 실제 거래, 전략 모니터링 등이 포함됩니다.
숙제
- 양적 거래와 주관적 거래의 가장 중요한 차이점은 무엇입니까?
- 주관적 거래에 비해 양적 거래의 장점은 무엇입니까?
1.3 양적 거래를 위해 무엇을 준비해야 하나요?
요약
완전한 양적 거래 라이프사이클은 거래 전략 그 자체만이 아닙니다. 이는 전략 구상, 모델 구축, 백테스팅 및 튜닝, 시뮬레이션 거래, 실제 거래, 전략 모니터링 등 최소 6가지 링크로 구성됩니다.
전략적 사고
우선, 양적 거래를 하기 위해서는 먼저 거래 시장으로 돌아가서 시장 가격을 자세히 관찰하고, 시장 변동 법칙을 이해하고, 각 거래의 논리를 유추해 본 후, 마지막으로 거래 전략을 정리해야 합니다. 여기에는 지름길이 없습니다. 고전적인 투자 서적을 읽거나, 거래를 계속하고 실패로부터 배워야 할 수도 있습니다.
양적 거래 초보자의 경우 처음부터 거래 전략을 개발하는 가장 좋은 방법은 모방하는 것입니다. 기존의 기술적 분석 지표를 직접 활용하여 전략 로직을 구축하고 매수, 매도 규칙을 작성하면 간단한 전략을 얻을 수 있습니다. 귀하의 거래 전략이 다음과 같다고 가정해 보겠습니다. 가격이 지난 10일간의 평균 가격보다 높으면 매수하고, 가격이 지난 10일간의 평균 가격보다 낮으면 매도합니다. 그러면 그 아키텍처는 다음과 같습니다(아래에 표시됨):
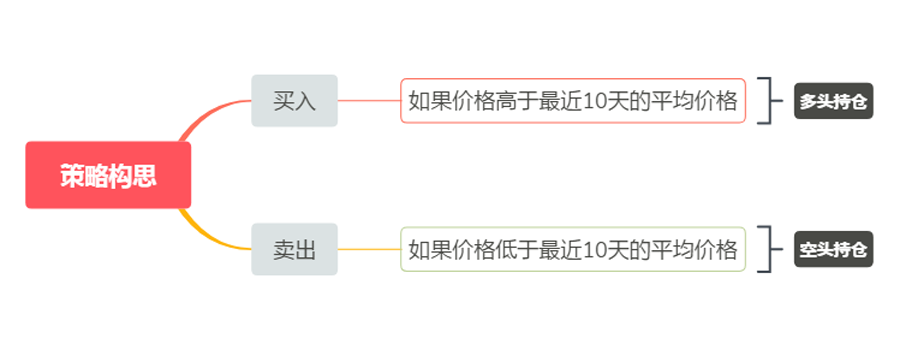
그림 1-2 거래 전략 예
물론 여러분이 전략적 경험을 쌓고 자신만의 거래 방식을 형성할수록 논리적인 선택은 점점 더 다양해지고, 더 체계적인 양적 거래로 나아갈 수 있을 것입니다. 주식이든 선물 시장이든 양적 사고방식을 갖춘 트레이더가 될 수 있다면 그것은 축복입니다. 그러한 사람은 어떤 거래 시장에 있든 지속적이고 안정적인 수익성을 가질 수 있기 때문입니다.
모델 구축
둘째, 거래 전략을 작성하고 거래 아이디어를 실현하려면 양적 거래 도구를 숙달해야 합니다. 시중에서 널리 사용되는 소프트웨어라면 무엇이든 사용할 수 있습니다. 하지만 고급 양적 거래자가 되고 싶다면 다음을 배워야 합니다.
컴퓨터 언어를 알아야 합니다. 저는 Python을 추천합니다. 과학적 컴퓨팅을 위한 권위 있는 언어이기 때문입니다.
또한 다양한 오픈소스 분석 패키지, 파일 처리, 네트워킹, 데이터베이스 등을 제공합니다.
대부분의 초보자가 취약하다고 생각하는 프로그래밍 능력이 약하다면, 양적 거래에 대한 학습에 대한 관심을 높이고 전략에 집중하고 효율적으로 전략 개발을 완료할 수 있도록 하는 비교적 간단한 시각적 프로그래밍 언어나 Mai 언어를 사용하는 것이 좋습니다. 아래에 표시된 대로: Mai 언어를 사용하여 위에서 언급한 대로 거래 전략을 개발합니다. 이미지를 두 번 클릭하면 전략 코드에서 자세한 주석을 볼 수 있습니다.
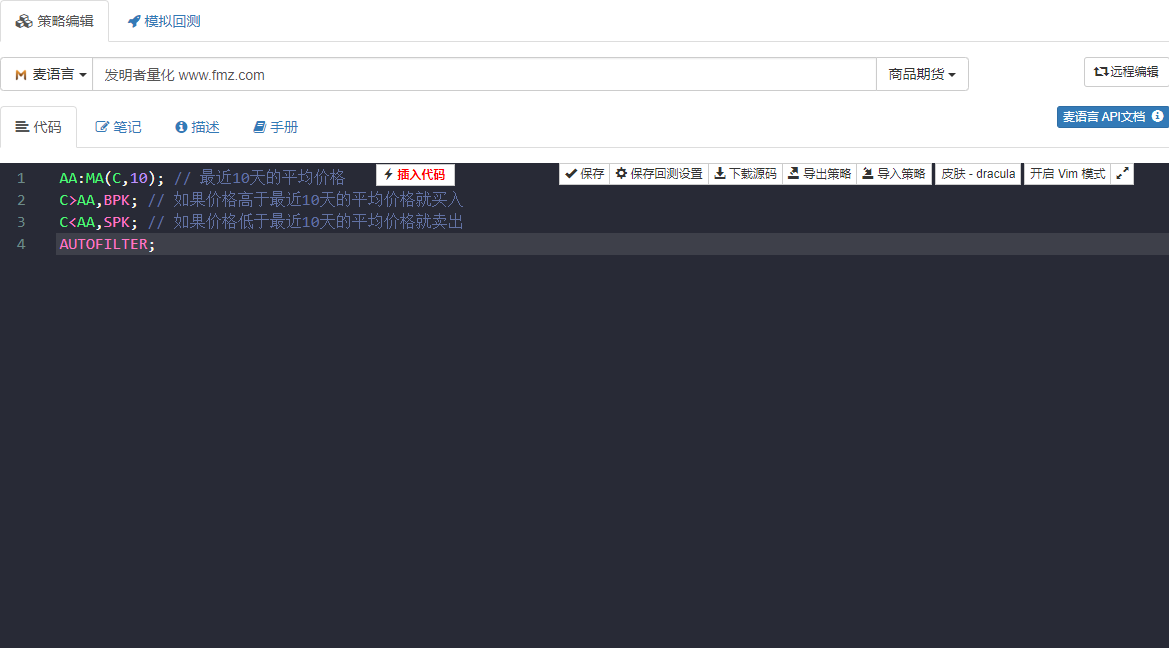
그림 1-3 거래 전략 개발 페이지
위 그림의 전략 코드는 발명가의 양적 도구의 Mai 언어를 사용하여 설명됩니다. 직접 사용할 수 있는 많은 기능 모듈을 통합하고 백테스팅 및 실제 거래 기능을 지원합니다. 빠르게 시작하기에 좋은 방법입니다.
백테스팅 및 튜닝
그런 다음 전략 모델을 작성한 후 다음 단계는 전략을 백테스트하고 매개변수를 검토하여 최적화하는 것입니다. 다양한 매개변수를 사용하여 전략을 백테스트하고 전략의 샤프 비율, 최대 하락률, 연간 수익률 등을 관찰할 수 있습니다. 전략을 지속적으로 디버깅하고 수정하면 결국 완전한 양적 거래 전략을 얻을 수 있습니다.
예를 들어, 2017년의 과거 데이터를 샘플 내 데이터로 사용하고, 2018년의 과거 데이터를 샘플 외 데이터로 사용합니다. 먼저, 우리는 2017년 데이터를 사용하여 좋은 성능을 보이는 여러 매개변수 세트를 최적화한 다음 이러한 매개변수를 사용하여 2018년을 최적화합니다.
데이터 백테스팅. 일반적으로, 샘플 밖 백테스트 결과는 샘플 내 백테스트 결과만큼 좋지 않습니다. 그러나 샘플 밖과 샘플 내 결과가 매우 다르다면 전략은 거의 효과가 없으며 전략 실패 이유를 파악하기 위해 관찰하고 분석할 필요가 있습니다.
전략이 샘플 데이터 부족으로 실패하고 특정 극단적인 시장 상황으로 인해 큰 손실이 발생한 경우, 이러한 위험을 피하기 위해 고정 손절매 조건을 추가할 수 있습니다. 전략이 거래량이 너무 많아 실패한 경우, 거래 로직을 약간 강화하고 거래 빈도를 줄일 수 있습니다.
거래 논리 자체가 처음에 잘못되었다면 아무리 수정하더라도 수익성 있는 전략을 얻기 어려울 것입니다. 이때 전략적 사고를 다시 검토해야 합니다. 또한, 매개변수 최적화에서는 사용 가능한 매개변수 그룹이 많을수록 더 좋으며, 이는 이 전략이 폭넓게 적용 가능하다는 것을 의미합니다. 백테스팅을 할 때, 거래 횟수가 너무 적은 전략은 생존자 편향으로 어려움을 겪을 수 있습니다. 백테스트 결과가 매우 수익성 있는 펀드 커브인 경우
많은 경우, 당신의 논리는 틀렸습니다.
시뮬레이션 트레이딩
그런 다음 샘플 안팎에서 모두 수익성이 있고 올바른 거래 논리를 갖춘 전략을 얻었을 때 실제 계정에서 거래를 서두르지 마십시오. 특히 초보자의 경우 최소 3개월 동안 시뮬레이션 계정을 운영해야 합니다. 중간 또는 낮은 빈도의 오버나잇 전략인 경우 더 긴 시뮬레이션 거래 시간이 필요합니다.
미래의 완전히 알려지지 않은 시뮬레이션 시장에서 시뮬레이션 거래에서 전략의 성과를 관찰하고 백테스트 신호가 시뮬레이션 거래 신호와 일치하는지 주의 깊게 확인하고 주문 시 가격과 거래 완료 시 가격 사이에 편차가 있는지 확인합니다. 성과가 기대치와 일치하면 전략이 효과적이라는 의미입니다.
실 디스크 거래
마지막으로, 오랫동안 전략을 테스트한 후 이제 실제 거래에 적용할 때가 되었습니다. 물론, 양적 거래 과정에서도 극단적인 시장 상황에 대비해 항상 경계하고 경계해야 합니다. 실제 거래에서는 전략에 대한 기대치가 일반적으로 할인되며, 기대치의 50%를 달성하는 것은 합격으로 간주됩니다.
정책 모니터링
마지막으로, 트레이딩이 진행됨에 따라 전략의 효과성도 관찰해야 한다는 점을 모두에게 상기시켜야 합니다. 전략에 예상 이상의 손실이 있는 경우 전략을 재평가해야 합니다. 시장 특성은 끊임없이 변하기 때문에, 현재 우리가 수립하는 전략은 주로 과거 시장 특성을 목표로 합니다. 시장 특성이 변화하면 전략 모델을 적절한 시기에 조정해야 하거나 전략을 일시적으로 중단해야 합니다.
요약하다
이 글에서는 양적 거래의 전체 과정을 설명해보겠습니다. 간단히 말해서, 시장 경험이 있는 투자자라면 컴퓨터 언어의 기본이 당신을 붙잡을 것입니다. 시각 언어나 Mai 언어로 시작해서 이 플랫폼에서 스스로 훈련하고 전략을 구축한 다음 점차적으로 Python 하이엔드 양적 거래로 전환할 수 있습니다.
과학 및 공학 전공 학생이거나 강력한 프로그래밍 기술을 갖춘 IT 실무자라면 시장 투자 경험이 방해가 될 것입니다. 이 점을 과소평가하지 마십시오. 자격을 갖춘 양적 투자자로서 두 가지 유형의 지식은 모두 필수적입니다.
다음 섹션 미리보기
양적 거래 라이프사이클 전체의 핵심은 여전히 거래 전략입니다. 다음 섹션에서는 거래 전략 프레임워크의 관점에서 완전한 거래 전략의 요소에 대해 자세히 설명하겠습니다. 이는 귀하의 거래 전략을 보다 포괄적으로 구축하고 양적 거래를 새로운 수준으로 끌어올리는 데 도움이 될 것입니다!
숙제
- 이 섹션의 거래 전략을 Mai 언어를 사용하여 작성해 보세요.
- 양적 거래 백테스팅에서 가장 중요한 성과 지표는 무엇입니까?
1.4 완전한 전략의 요소는 무엇입니까?
요약
완전한 전략은 실제로 트레이더가 스스로 정한 다양한 규칙입니다. 이는 거래의 모든 측면을 포괄하며 트레이더의 주관적인 상상력에 여지를 남기지 않습니다. 이 전략은 모든 매수 및 매도 결정에 대한 답을 제공합니다. 여기에는 최소한 전략 선택, 제품 선택, 자본 관리, 주문 실행, 극한 시장 상황에 대한 대응, 거래 사고방식 등이 포함됩니다.
전략 선택
헤지펀드의 관점에서 볼 때, 주류 거래 전략은 아래 그림과 같이 트렌드 거래, 페어 거래, 바스켓 거래, 이벤트 주도 거래, 고빈도 거래, 옵션 전략 등으로 나눌 수 있습니다. 물론, 전략이 분류되는 방식은 고정되어 있지 않습니다.
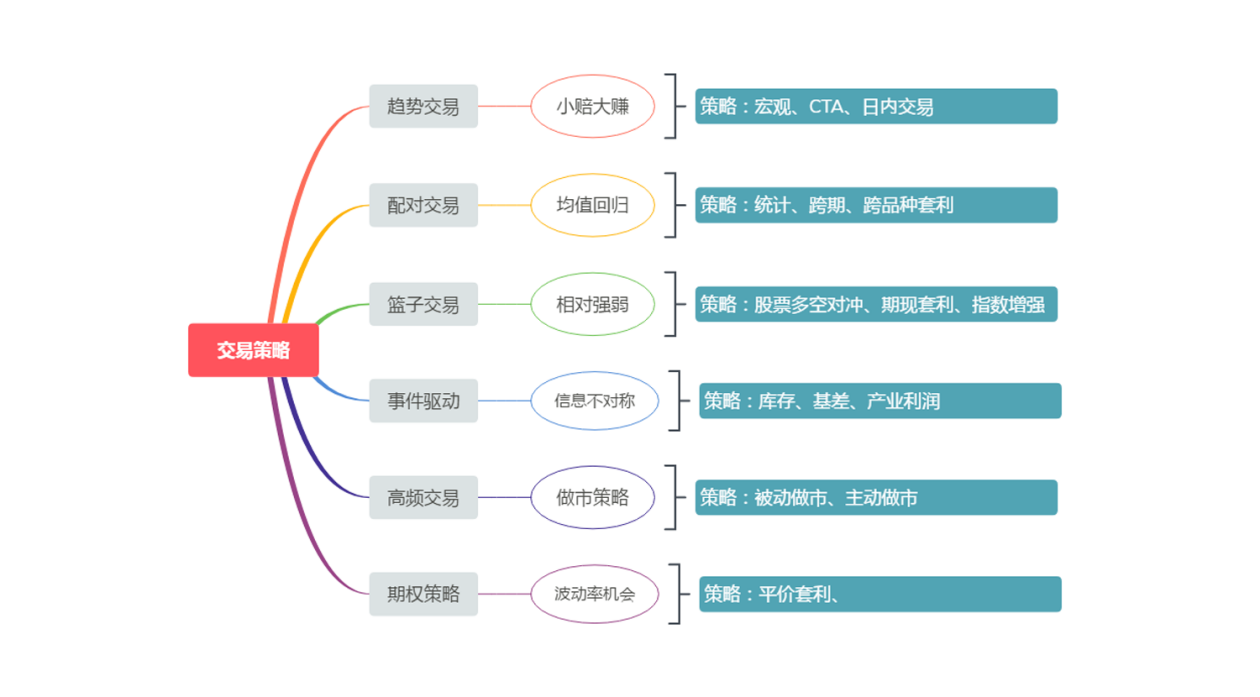
그림 1-4 거래 전략 분류
양적 거래 초보자라면 많은 용어와 개념에 대해 걱정할 필요가 없습니다. 가장 간단한 단계별로 시작하면 됩니다. 초보자에게 단 하나의 양적 거래 전략을 추천한다면, 그것은 트렌드 거래입니다. 간단하면서도 효과적이기 때문입니다. 저는 금융 지식을 체계적으로 배우지 않아도 여전히 좋은 트레이딩을 할 수 있다고 믿습니다. 그리고 이러한 전략은 초기 공개 거래 전략에서 오랫동안 존재해 왔으며, 인간의 본성은 변화하기 어렵기 때문에 오늘날에도 여러 시장에서 여전히 효과적입니다.
무엇을 사고 팔까
거래를 해 본 사람이라면 각 품종마다 고유한 성격이 있다는 것을 알 것입니다. 일부 품종은 매우 "뜨거운" 성격을 가지고 있어 유동성이 좋고 변동성이 크며 변동성이 높습니다. 일부 품종은 매우 "온순한" 성격을 가지고 있어 일년 내내 특정 범위 내에서 변동하고 변동성이 낮습니다.
따라서 거래 상품을 선택할 때는 변동성이라는 개념을 가져야 합니다. 변동성이 높은 상품은 종종 쉽게 좋은 추세를 발전시킬 수 있습니다. 상품 선물의 경우, 추세 추적 전략이라면 산업 제품을 선택해 보세요. 제품 속성 측면에서 산업 제품은 농산물보다 변동성이 더 큰 경향이 있습니다.
다양한 시장 상황에 맞춰 다양한 전략이 적용되며, 올바른 거래 상품을 선택하는 것은 선물 거래라는 대규모 프로젝트를 시작하는 데 매우 중요한 요소입니다. 절대적으로 말해서, 절대적으로 좋은 품종이나 절대적으로 나쁜 품종은 없습니다. 귀하의 투자 스타일과 위험 감수성에 따라, 귀하만의 기준을 적절히 조정해야 합니다.
얼마나 사고 팔아야 하나요?
거래에서 돈을 잃는 것은 쉽지만 돈을 버는 것은 어렵습니다. 계좌 자금이 50% 손실되면 손실을 회복하려면 100%의 이익이 필요합니다. 100%의 수익을 여러 번 낼 수 있다 하더라도, 100%를 한 번 잃으면 전부 다 잃습니다. 따라서 성숙한 거래 전략에는 자금 관리가 포함되어야 합니다.
모든 사람이 더 쉽게 이해할 수 있도록, 이전 섹션의 이동평균선 전략도 여기에 사용됩니다. 실제로 전통적인 기술 지표를 기반으로 구축된 많은 거래 전략은 일반적으로 최대 하락률이 50% 이상입니다. 하지만 전혀 실행 불가능한 매우 위험한 전략이 있을까요?
당연히 그렇지 않습니다. 최대 인출률은 펀드 관리를 통해 완벽하게 통제할 수 있습니다. 포지션이 반으로 줄어들면 전체 위험도 반으로 줄어들고 최대 하락률은 30%가 됩니다. 포지션이 다시 반으로 줄어들면 최대 하락률은 15%가 됩니다. 결국 최대 하락률이 약 15%로 제어되는 전략을 얻게 됩니다. 이것은 간단하고 원시적인 자금 관리 방법입니다. 많은 사람들이 자신이 풀 포지션으로 일할 수 없다는 것을 알고 있지만, 왜 풀 포지션으로 일할 수 없는지 모릅니다. 답은 여기에 있습니다.
매수 및 매도 시점
좋은 구매 시점은 성공의 절반이며, 비용 부담에서 빨리 벗어날 수 있도록 도와줍니다. 하지만 누구도 이 지점에서 시작하는 것이 옳고 저 지점에서 시작하는 것이 틀렸다고 말할 수는 없습니다. 포지션을 여는 것은 트레이딩의 핵심이 아니다. 트레이딩의 핵심은 포지션을 여는 후 포지션을 최대한 최적화하는 방법이다.
단기 전략이든 장기 전략이든 중요한 것은 누가 해당 포지션을 더 오래 유지하느냐가 아니라, 위험 대비 수익률입니다. 다시 말해, 전략 성과에 영향을 미치는 궁극적인 결과는 어떻게 종료하고 언제 수익을 실현할 것인가입니다. 종료 방법은 손절매 종료와 이익실현 종료의 두 가지 유형으로 나눌 수 있습니다. 이 두 부분은 모든 거래 시스템에 필수적이며, 거래 전략의 성공과 실패를 결정하는 중요한 분수령이기도 합니다.
구매 및 판매 방법
1. 주문 유형 및 방법:
주문을 내는 유형과 방법은 다양합니다. 예를 들어, 대기열 한도 주문, 상대방 가격, 최신 가격, 초과 가격, 상한 가격, 하한 가격, 우선 매수 가격, 2차 매수 가격, 우선 매도 가격, 2차 매도 가격을 사용하거나, 대기열 가격을 먼저 사용한 다음 초과 가격을 사용하거나, 일괄로 주문을 내거나, 대량 주문을 소량 주문으로 나누거나, 모든 주문을 직접 내는 방법이 있습니다.
2. 주문 취소
주문이 실행되지 않으면 계속 기다려야 할까요 아니면 주문을 취소해야 할까요? 취소 조건은 시간에 따라 달라집니다. 예를 들어, 10초 이내에 거래가 없고 가격이 주문 당시 가격에서 10점 차이로 떨어져 있다면 계속 기다려야 할까요, 주문을 취소해야 할까요, 아니면 주문을 따라야 할까요?
3. 후속 주문
주문이 실행되지 않을 경우, 주문을 후속 조치할지 여부. 주문을 추적한다면 최신 가격, 상대방 가격 또는 가격 한도에 따라 추적해야 할까요? 추적된 주문이 아직 실행되지 않았다면 주문을 계속 추적해야 할까요?
4. 가격 제한
상한가나 하한가에 주문신호가 나타나면 어떻게 해야 하나요? 상한 및 하한 가격에서 실행을 위해 대기할지 여부와 실행이 이루어지지 않을 경우 어떻게 할 것인지에 대한 내용입니다.
5. 경매 호출
오프닝 경매에 참여해야 하는지, 그리고 어떻게 참여해야 하는지.
6. 야간 거래
일부 상품 선물의 경우 야간 거래는 21:00부터 다음 날 02:30까지 진행됩니다. 이 기간 동안 수동으로 할지 아니면 컴퓨터로 할지 선택할 수 있습니다.
7. 주요 축제
주요 축제 기간 동안 긴 연휴 전에도 직위를 유지해야 합니까? 보유할 경우 위험을 통제하는 방법.
극심한 시장 상황
-
단시간 내 가격 변동이 크다
즉각적 가격 제한, 지속적 가격 제한, 오류 주문, 블랙스완 시장 가격 폭주 등과 같은 상황을 처리하는 방법입니다. -
유동성 위험
상대방이 당신이 원하는 만큼의 주문량을 보유하고 있지 않지만, 당신이 제때에 거래를 완료해야 하는 경우, 특히 비주요 계약의 유동성이 매우 부족하고, 당신이 내는 주문이 시장에 쉽게 영향을 미칠 수 있으며 슬리피지가 큰 경우, 어떻게 처리해야 할까요? -
품종 규정의 변경
상품선물 상품이 야간거래에 추가되고, 증거금 비율이 증가하고, 취급 수수료가 증가합니다. 특히 단기 전략은 이러한 변화에 매우 민감할 것입니다. -
거래 환경 위험
예를 들어, 갑작스러운 정전, 인터넷 중단, 컴퓨터 고장, 소프트웨어 충돌, 은행 선물거래 중단, 자연재해 등이 발생했을 때 어떻게 대처해야 하는지입니다.
위의 상황이 발생할 확률은 매우 작거나 거의 불가능합니다. 하지만 일어날 수 있는 일이라면 일어날 것입니다. 이러한 가정을 하고 예방조치를 취하는 것이 필요하다.
심리적 구성
거래에서 흔히 나타나는 세 가지 주요 심리적 감정은 탐욕, 두려움, 행운입니다. 투자자는 위의 세 가지 감정을 각기 다른 단계에서 통제하고 활용할 수 있는 강력한 거래 심리 시스템이 필요합니다.
거래에 앞서, 시장 기대치와 제품에 대한 심리적 기대치를 포함한 미래에 대한 전반적인 기대치를 가져야 합니다. 시장 기대는 시장의 위치와 미래 방향에 대한 명확한 목표를 의미하고, 제품 기대는 현재 위치에서 제품의 거래 기회와 위험 상태를 의미합니다. 위와 같은 심리적 토대가 없다면 아무것도 이룰 수 없습니다.
실제 거래의 전체 과정은 지속적인 분석, 수정 및 실행의 과정입니다. 거래에 많은 시간을 할애하지 않고 추적과 인내심에 더 많은 시간을 할애합니다. 이것은 정신을 종합적으로 검토하고 인간의 본성을 시험하는 과정입니다. 트레이더의 모든 습관은 트레이딩 과정에서 완전히 드러나고 확대됩니다. 끊임없이 경험과 교훈을 배우고 요약하며 경험을 쌓아야만 인간 본성의 공통적인 사고방식과 심리적 약점을 극복할 수 있습니다.
요약하다
요약하자면, 소위 트레이딩 전략은 실제로 이와 같습니다. 완벽한 면과 불완전한 면이 있습니다. 트레이딩 전략이 합리적인지 측정할 때, 완벽한 면과 불완전한 면만 볼 수는 없습니다. 전략의 무결성을 종합적으로 분석해야 합니다.
마지막으로, 전략의 특성에 따라, 당신의 성격과 재정 상황을 결합하여, 전략이 당신에게 적합한지 측정합니다. 당신에게 적합하다면, 당신은 그것을 고수할 가능성이 얼마나 되는지 충분히 평가하고, 최악의 결과를 미리 계획해야 합니다. 최악의 시나리오에 대해 생각해 보았다면, 그것을 실행할 가능성은 비교적 높습니다.
기억하세요, 거래에서 자신감은 진심 어린 인정에서 나오며, 자신감은 올바른 거래 철학에서 나옵니다!
다음 섹션 미리보기
이것은 첫 번째 장의 마지막 기사입니다. 다음 장에서는 양적 거래 도구에 대해 더 자세히 설명합니다. 여기에는 양적 도구에 대한 전반적인 소개, 양적 거래 시스템을 구성하는 방법, 일반적인 API 설명, 양적 시스템에서 전략을 작성하는 방법이 포함됩니다.
숙제
- 트렌드 트레이딩 전략은 고변동성 상품을 선택해야 할까요, 아니면 저변동성 상품을 선택해야 할까요?
- 거래 주문의 유형은 무엇입니까?
2장 양적 도구 소개
2.1 양적 도구에 대한 전반적인 소개
요약
이전 장에서는 양적 거래의 관련 개념에 대해 알아보고, 양적 거래에 대한 기본적인 이해를 얻었습니다. 그렇다면 시장에서 양적 거래를 위한 도구는 무엇일까요? 우리는 우리의 필요에 따라 어떻게 선택해야 할까요?
오픈소스 및 상용 소프트웨어
국내 양적 거래 도구는 대체로 오픈소스 소프트웨어와 상용 소프트웨어의 두 가지 범주로 나눌 수 있습니다. 오픈소스 소프트웨어란 소스 코드가 공개되어 직접 다운로드하여 사용할 수 있는 소프트웨어를 뜻하는 반면, 상업용 소프트웨어는 일반적으로 상업 기업이 유지 관리하고 운영하는 폐쇄형 소스 소프트웨어를 말하며, 일반적으로 유료입니다.
오픈소스 양적 소프트웨어
우선, 오픈소스 소프트웨어는 유연성이 뛰어나고 완전히 무료입니다. 사용자는 기본적으로 이 소프트웨어를 사용하여 중주파 또는 저주파 거래 전략, 차익거래 전략 또는 옵션 전략 등 모든 기능을 구현할 수 있으며, 이는 사용자 지정 모듈을 통해 달성할 수 있습니다. 사용자는 소프트웨어의 소스 코드를 제어하고 소프트웨어의 모든 구석을 이해할 수 있으므로 더욱 안정적이고 안전합니다.
오픈소스 소프트웨어는 많은 장점이 있지만, 양적 거래 초보자에게는 그다지 친절하지 않습니다. Python, Java 또는 C++와 같은 표준 프로그래밍 언어를 체계적으로 배워야 합니다. 시작부터 포기까지, 그 어려움은 상상할 수 있습니다. 때때로 버그 디버깅은 당신의 삶을 의심하게 만들 수 있습니다. 그리고 상용 소프트웨어와는 달리, 고객의 질문에 즉시 답변해 드리는 전담 기술 고객 서비스가 있습니다. 지금은 성취감을 느낄 수 없을 뿐만 아니라, 계속해서 배우고자 하는 의욕도 잃게 될 것입니다.
따라서 학습 관점에서 양적 거래 초보자는 가장 간단한 상업용 소프트웨어부터 시작하여 단계별로 시작하는 것이 좋습니다. 유료이기는 하지만 전략이 수익성이 있다면 소프트웨어 수수료는 수익의 일부에 불과합니다. 게다가 상업용 소프트웨어는 일반적으로 팀에서 유지 관리하며, 그 성숙도는 오픈 소스 소프트웨어보다 확실히 훨씬 강력합니다.
비즈니스 양적 소프트웨어
중국에는 양적 거래를 위한 수십 가지의 상용 소프트웨어가 있습니다. Interactive Broker는 전문적이고 포괄적이며 다양한 제품을 갖추고 있습니다. APAMA는 대량의 동시 데이터를 처리할 수 있고 고빈도 거래에 적합합니다. SPT는 C++ 인터페이스를 지원하고 실행 효율성이 좋습니다. SPT는 거래 실행과 위험 관리에 중점을 둡니다. Nuggets Quantitative는 개별 거래자를 위한 MC, TB, MQ입니다. 아래 그림에서 우리는 주류 국내 양적 플랫폼에 대한 포괄적인 평가를 실시하고 양적 도구의 난이도에 대한 특정 분류도 했습니다. 독자는 실제 상황에 따라 선택할 수 있습니다.

그림 2-1 국내 주요 양적 플랫폼 종합평가
위의 것들은 상용 소프트웨어이지만, 표준 프로그래밍 언어나 스크립팅 언어도 사용합니다. 이렇게 하는 대신, 무료이고 안전한 오픈소스 소프트웨어를 직접 사용하는 것이 좋습니다. 초보자에게는 FMZ Inventor Quantitative Platform을 직접 사용하는 것이 좋으며, 웹사이트는 www.fmz.com입니다. 양적 거래를 배우기 위한 발판으로.
양적 거래 도구의 발명가를 만나보세요
발명가의 양적 도구는 초보자에게 친숙합니다. 기본 지식이 없더라도 도구에 기반한 양적 분석의 매력을 경험할 수 있습니다. 이 도구는 고빈도 거래를 위해 설계되었으며 성능과 보안에 대한 엄격한 요구 사항을 갖추고 있습니다. 고빈도 전략, 차익거래 전략, 추세 전략을 지원합니다. 그리고 전략 개발, 테스트, 최적화, 시뮬레이션, 실제 거래의 전체 프로세스를 통합합니다. 또한 간단하고 사용하기 쉬운 Mai 언어와 Python, C++와 같은 고급 양적 거래 언어를 모두 지원하므로 한 번만 배우면 원활하게 전환할 수 있습니다. 그리고 실제 거래만 시간당 0.125위안으로 청구되므로 학습 단계에서 소프트웨어 비용이 줄어듭니다. 동시에 시뮬레이션 거래는 무료로 할 수 있습니다.
정량화를 향한 첫 걸음: 정량적 도구 사용
양적 도구는 사용하기 매우 쉽습니다. 웹사이트에 들어가서 클릭만 하면 자신의 양적 전략을 설계할 수 있습니다. Inventor Quantitative Tool의 공식 웹사이트에 로그인하여 등록하고 로그인한 후 컨트롤 센터를 클릭하여 사용할 수 있습니다(아래에 표시된 대로). 현재 인기 있는 TikTok과 비슷합니다. 등록하고 로그인한 후 자신의 짧은 비디오를 게시할 수 있으며, Quantitative Tool에 로그인한 후 자신의 Quantitative 거래 전략을 설계할 수 있습니다.

그림 2-2 FMZ 양적거래 플랫폼 메인 페이지
정량적 도구를 프로그래밍하기 위한 중앙 집중화된 기능 영역이 있을 것입니다. 기능 영역에는 주로 (아래에 표시된 대로)이 포함됩니다. 왼쪽 상단 모서리에 있는 제어 센터는 정량적 도구의 핵심 기능입니다. 이를 클릭한 후 거래 전략과 전략 백테스팅을 작성하고, 거래 상품에 대한 거래소를 설정하고, 전략 로봇을 관리하는 관리자를 만들고, 특정 정량적 거래 로봇을 만들 수 있습니다. 함수의 구체적인 사용법에 대해서는 후속 기사에서 자세히 소개하겠습니다. 현재는 예비 작업만 진행 중입니다.

그림 2-3 FMZ 양적거래 플랫폼 로그인 후 관리페이지
양적 연구를 처음 접하는 친구들이 코드와 프로그래밍을 이해하지 못한다고 낙담할 필요는 없습니다. 사용자의 문턱을 낮추기 위해 공식 커뮤니티는 양적 거래 초보자가 빠르게 시작할 수 있도록 돕는 많은 비디오 튜토리얼을 제작했습니다. 동시에 Strategy Square는 모든 사람이 복사하고 배울 수 있도록 수천 개의 공식 및 타사의 무료 및 공개 거래 전략을 모았습니다.
또한, 클래식 전략 샘플도 전략 편집 인터페이스에 구성되어 있습니다. 전략 코드를 클릭하여 직접 사용할 수 있으며, 전체 양적 거래의 핵심 프로세스를 쉽게 경험할 수 있습니다. 초보자도 즉시 배우고 따라할 수 있습니다!
실제 돈 거래 전에 모의 거래도 필수 단계입니다. 이 도구의 모의 거래는 거래소 규칙을 준수하며 완전히 무료입니다. 시뮬레이션에 포함된 시간, 가격, 주문량 등은 실시간으로 실제 시장과 일치하여 실제 거래와 매우 일치합니다. 전략 검증의 효율성을 크게 향상시킵니다.
요약하다
오픈소스 소프트웨어든 상용 소프트웨어든 좋고 나쁨의 구별은 없으며 완벽한 양적 거래 도구는 없습니다. 각 도구는 고유한 초점을 가지고 있습니다. 가장 중요한 것은 자신의 필요에 따라 적합한 도구를 선택하는 것입니다. 상업용 소프트웨어는 결제가 필요하고, 서비스가 좋으며, 이 업계에 막 입문한 초보자에게 더 적합할 수 있습니다. 오랫동안 이 업계에 종사해 왔고 많은 경험을 쌓았거나 더 복잡한 거래 전략을 구현해야 하는 경우, 오픈소스 소프트웨어가 더 나은 선택입니다.
다음 섹션 미리보기
도구를 어떻게 사용하나요? 새 휴대전화를 사서 처음 켤 때 간단한 시작 설정을 해야 하는 것처럼, 양적 도구에도 기본 설정과 구성이 필요합니다. 다음 섹션에서는 Inventor 양적 거래 도구를 구성하는 방법을 단계별로 안내해 드리겠습니다. 거래소 추가, 보관인 추가, 거래 전략 생성, 양적 로봇 생성 등을 포함해 양적 거래의 첫 문을 열어보세요. 기본 구성을 완료한 후에는 공식적으로 첫 번째 양적 전략을 작성할 수 있습니다.
숙제
- 양적 거래 도구의 두 가지 주요 범주는 무엇입니까?
- 일반적으로 사용되는 양적 프로그래밍 언어는 무엇입니까?
2.2 Inventor Quantitative Trading System을 구성하는 방법
요약
양적 거래 전략을 개발할 때 가장 먼저 해야 할 일은 거래 도구를 구성하는 것입니다. 구성이란 무엇입니까? 실제로는 단지 설정일 뿐입니다. 이 섹션에서는 양적 거래에 꼭 필요한 전제 조건인 거래소 설정, 거래 전략 수립, 양적 거래 로봇 생성 방법을 안내해드리겠습니다.
구성은 엔트리 레벨 학습 시뮬레이션 거래 구성과 실시간 거래 구성으로 나뉩니다. 이 범주에서는 주로 국내 상품 선물에 초점을 맞춥니다. 다른 유형의 양적 투자는 특정 국내 상황으로 인해 권장되거나 도입되지 않지만 운영 프로세스는 동일하며 구성 프로세스만 다릅니다.
거래소 추가
거래소 추가는 전체 구성 프로세스의 첫 번째 단계입니다. 구체적인 프로세스는 아래 그림을 참조하세요. 이 단계에서는, 자신이 어느 거래소에 속해 있는지 확신하지 못하는 사람들에게는 거래소 추가가 어렵지 않다는 점을 강조할 필요가 있습니다. 먼저 학습을 시뮬레이션하는 것이 좋습니다.

그림 2-4 FMZ 양적거래 플랫폼 등록 및 거래소 단계 추가
상품선물거래소(실시간) 구성
당사의 실시간 양적 거래는 주로 국내 선물 거래 상품에 초점을 맞춥니다. 현재 Inventor Quantitative의 주요 서비스 대상도 국내 선물 거래소입니다. 외환 거래를 하는 친구라면 Inventor Quantitative를 학습 플랫폼으로 사용할 수 있습니다. 외환 양적 거래는 이미 MT5와 같은 플랫폼에 등장했지만 더 전문적이기 때문입니다.
실시간 구성에서 주의해야 할 사항은 다음과 같습니다. 발명가의 정량적 도구는 여러 거래 시장을 지원하므로 상품 선물을 구성할 때 1단계에서 먼저 "전통적 선물"을 선택해야 합니다. 2단계에서는 계좌를 개설한 선물 회사에서 제공한 선물 계좌와 비밀번호를 입력해야 합니다.
발명자의 정량적 도구는 CTP 프로토콜을 채택하고 모든 국내 선물 회사를 지원합니다. 실제 시장을 구성할 때 계정과 비밀번호가 잘못되지 않는 한 링크 실패가 발생하지 않습니다. 따라서 초보자는 계정과 비밀번호를 명확하게 확인하는 데 주의해야 합니다.

그림 2-5 FMZ 양적거래 플랫폼에 선물거래소 추가
상품선물거래소(시뮬레이션) 구성
상품선물거래를 처음 접하는 친구들에게, 먼저 일정 기간 동안 거래를 시뮬레이션해 보는 것을 제안하고 싶습니다. 왜냐하면 양적 거래 전략을 개발하는 과정에서는 지속적인 테스트, 디버깅, 최적화가 필요하기 때문입니다. 운전과 마찬가지로 처음에는 운전 학교에서 몇 달 동안 학습한 다음, 시험에 합격하고 면허를 취득한 후 도로 주행을 시작할 수 있습니다.
여기서는 SimNow 시뮬레이션 거래를 사용하는 것이 좋습니다. SimNow는 Shangqi Technology가 투자자를 위해 특별히 만든 금융 시뮬레이션 거래 플랫폼입니다. 이 제품은 다양한 거래소의 거래 및 결제 규칙을 시뮬레이션하며 현재 다양한 국내 선물 거래소의 상품 선물 사업을 지원합니다. 구체적인 프로세스는 아래 그림을 참조하십시오.

그림 2-6 FMZ 양적거래 플랫폼 로그인 후 관리 페이지
전략 쓰기
전략 라이브러리는 코드가 저장되는 곳으로, 양적 거래 전략 창고와 같습니다. 이 기능은 주로 전략 작성과 시뮬레이션 백테스팅의 두 가지 기능으로 나뉩니다. 전략 쓰기 영역은 미래에 전략을 개발하기 위한 우리의 주요 작업 영역입니다(아래에 표시된 대로). 많은 초보자는 종종 다양한 코드에 막혀 매우 어려움을 겪습니다. 사실, 조금만 주의를 기울이면 이러한 코드를 배울 수 있습니다. 심리적 부담이 없습니다. 시뮬레이션 백테스팅 영역은 전략 개발 프로세스 중에 전략을 디버깅하는 데 사용할 수 있으며, 전략 개발이 완료된 후 전략을 테스트하는 데 사용할 수도 있습니다. 다음 장에서 이에 대해 자세히 설명하겠습니다.

그림 2-7 정책 생성 단계
양적 거래 로봇 생성
양적 트레이딩 로봇은 트레이딩 전략의 실행자입니다. 전략이 생성되면 전략 코드의 모든 트레이딩 로직을 자동으로 실행하고, 포지션을 열고 닫고, 주문을 인출하고, 기타 매수 및 매도 작업을 수행할 수 있는 로봇을 만드세요. 양적 거래 로봇을 만드는 구체적인 단계는 다음과 같습니다. 먼저, ①단계: 제어 센터 페이지에서 "로봇"을 클릭하고, "로봇 만들기"를 클릭합니다. ②단계: 로봇에 사용자 지정 이름을 지정합니다. 3단계: "+" 기호를 클릭하여 거래 플랫폼을 추가합니다. 4단계: "로봇 생성"을 클릭하세요.

그림 2-8 로봇 생성 단계
요약하다
위 과정에서는 실제 거래 선택 및 시뮬레이션이라는 첫 번째 단계를 제외하고, 이후의 전략 작성 및 거래 로봇 생성 단계는 통일된 단계입니다. 전체 정량적 도구가 구성되었고, 거래 로봇이 이미 실행 중이며, 전략의 특정 조건에 따라 매수 및 매도 작업을 수행합니다. 양적 거래를 구성하려면 세 가지 단계가 필요합니다. 거래소를 추가하고 선물 계좌 비밀번호를 입력합니다. 거래 전략을 작성하고, 실시간 양적 거래 로봇을 만듭니다. 간단하지 않나요?
다음 섹션 미리보기
양적 거래는 세 가지 간단한 단계만으로 달성할 수 있지만, 거래소를 추가하고 양적 거래 로봇을 만드는 것이 더 쉽다는 것을 알게 될 것입니다. 하지만 실행 가능한 거래 전략을 구현하는 것은 그렇게 쉬운 일이 아닙니다. 다음 섹션에서는 실행 가능한 거래 전략을 작성하는 데 필요한 양적 거래에서 일반적으로 사용되는 API에 대해 알아보겠습니다. 어떤 양적 거래 도구를 사용하든 API 인터페이스와 분리할 수 없으며, API 인터페이스는 양적 거래 전략을 실현하는 데 중요한 기능입니다.
숙제
- 거래소를 추가해보세요.
- 이 섹션에 거래 전략을 적어 보세요.
2.3 공통 API 설명
요약
프로그래밍에 있어서 API를 피할 수 없습니다. IT와 관련 없는 많은 사람들에게 API는 정확히 무엇일까요? API ≈ 이해가 안 갑니다. 이 섹션에서는 API가 무엇인지 쉽게 설명하고, 발명가 정량적 도구에서 일반적으로 사용되는 API를 소개합니다.
API란 무엇인가요?
온라인으로 검색하면 다음과 같은 결과가 나옵니다. API(Application Programming Interface)는 애플리케이션과 개발자가 소스 코드에 액세스하거나 내부 작동 메커니즘의 세부 정보를 이해하지 않고도 특정 소프트웨어나 하드웨어 기반의 루틴 세트에 액세스할 수 있도록 하는 미리 정의된 함수 집합입니다. 그러면, 더 간단히 말해서, API란 정확히 무엇인가요?
사실, 우리의 일상생활에서 우리는 API와 비슷한 시나리오를 많이 겪습니다. 예를 들어, 식당에 가서 식사를 할 때, 어떻게 만들어지는지 알 필요 없이 메뉴만 보고 음식을 주문하면 됩니다. 메뉴의 요리 이름은 특정 API이고, 메뉴는 API 설명서입니다.
양적 거래에서 API란 무엇인가요?
오늘 현재 상품의 개시 가격을 알아야 한다면, 그것을 얻는 방법을 알 필요는 없습니다. 코드 편집기에서 "OPEN"을 쓰고 바로 사용하면 됩니다. "OPEN"은 Mai 언어의 개장 가격 API입니다.
일반적으로 사용되는 Mai 언어 API
Mai Language API를 설명하기 전에 일반적인 코드 구조와 그 기능적 구성 요소를 살펴보겠습니다. 그러면 API를 더 잘 이해하는 데 도움이 될 것입니다. 아래 예를 참조하세요.

그림 2-9 Mai 언어 예
위의 코드에서 표시된 대로:
보라색 AA는 변수입니다. 변수는 중학교에서 배운 대수처럼 변할 수 있는 양입니다. 개시 가격이 AA에 할당되면 AA가 개시 가격이 되고, 최고 가격이 AA에 할당되면 AA가 최고 가격이 됩니다. 물론, AA는 사용자 정의 이름일 뿐이고, BB로 정의할 수도 있습니다.
녹색 “:="는 할당을 의미하는데, 이는 “:="의 오른쪽에 있는 값을 왼쪽에 있는 변수에 할당한다는 의미입니다.
주황색 코드는 Inventor Quantitative Tool의 Mai 언어 API입니다. 첫 번째 줄의 OPEN은 종가를 얻기 위한 API로, 바로 사용할 수 있습니다. 두 번째 줄의 MA는 이동 평균을 얻기 위한 API로, 두 개의 매개변수를 전달해야 합니다. 즉, Inventor Quantitative Tool에 필요한 이동 평균의 종류를 알려야 합니다. 시가를 기준으로 계산된 50기간 이동 평균을 얻으려면 MA(OPEN,50)으로 작성할 수 있습니다. 두 매개변수 사이에 영문 쉼표가 있습니다.
노란색 "//"는 주석 기호이고, 그 뒤의 파란색 중국어 문자는 주석 내용입니다. 이는 여러분이 직접 읽을 수 있으며, 코드 줄이 무엇을 의미하는지 나타내는 데 사용됩니다. 해당 프로그램은 실행 중에는 주석을 처리하지 않습니다. 주석 문자 앞에는 각 코드 줄의 끝에 영어 세미콜론이 있어야 합니다.
코드 구조에 대한 기본적인 이해를 바탕으로, 흔히 쓰이는 몇 가지 언어를 아래에서 소개해 드리겠습니다. 그리고 앞으로도 이 언어들을 자주 사용하게 될 것입니다.
OPEN——최신 K-라인의 오픈 가격을 알아보세요
예: AA: =OPEN; 최신 K-line의 시작 가격을 가져와 결과를 AA에 할당합니다.
HIGH——최신 K-라인의 최고가를 만나보세요
예: AA: =HIGH; 최신 K-line의 최고 가격을 가져와 결과를 AA에 할당합니다.
LOW——최신 K-라인의 최저가를 만나보세요
예: AA: =LOW; 최신 K-line의 최저 가격을 가져와 결과를 AA에 할당합니다.
CLOSE——K-line의 최신 종가를 얻으세요. 일중 K-line이 끝나지 않았을 때, 최신 가격을 얻으세요
예: AA: =CLOSE; 최신 K-line의 종가를 가져와 결과를 AA에 할당합니다.
VOL——최신 K-line 거래량을 받아보세요
예: AA: =VOL; 최신 K-line 거래량을 가져와서 그 결과를 AA에 할당합니다.
REF(X,N) - N 사이클 전의 X 값을 참조합니다.
예: REF(CLOSE,1); 이전 K-line의 시가를 구함
MA(X,N)——N 기간 동안 X의 단순 이동 평균을 구합니다.
예: MA(CLOSE,10); // 최신 K-line의 10기간 이동 평균을 구함
CROSSUP(A,B)——A가 B를 아래에서 위로 교차할 때 1(예)을 반환하고, 그렇지 않으면 0(아니요)을 반환합니다.
예: CROSSUP(CLOSE,MA(C,10)) // 종가가 10기간 평균가를 교차함
CROSSDOWN(A,B)——A가 위에서 B를 교차할 때 1(예)을 반환하고, 그렇지 않으면 0(아니요)을 반환합니다.
예: CROSSDOWN(CLOSE,MA(C,10)) // 종가가 10기간 평균가를 밑돌았습니다.
BK——매수 개시 포지션
예: CLOSE>MA(CLOSE,5),BK; //종가가 5기간 이동평균보다 높으면 포지션을 열려면 매수
SP——포지션을 마감하기 위해 매도
예: CLOSE<MA(CLOSE,5),SP; // 종가가 5기간 이동평균보다 낮으면 매도하고 포지션을 종료합니다.
SK——매도 포지션 개시
예: CLOSE<MA(CLOSE,5),SK; //종가가 5기간 이동평균보다 낮으면 매도 포지션
BP——매수하여 마감
예: CLOSE>MA(CLOSE,5),BP; //종가가 5기간 이동평균보다 높으면 매수 및 청산 포지션
BPK——포지션을 닫으려면 매수하고, 포지션을 열려면 매수합니다(역방향 롱)
예: CLOSE>MA(CLOSE,5),BPK; // 종가가 5일 이동평균보다 높으면 숏 포지션을 청산한 후 매수하여 새로운 포지션을 엽니다.
SPK——포지션을 마감하기 위해 매도하고 포지션을 개설하기 위해 매도(공매도)
예: CLOSE<MA(CLOSE,5),SPK; // 종가가 5일 이동평균보다 낮으면 롱 포지션을 청산하고 오픈 포지션을 매도합니다.
CLOSEOUT——모든 포지션을 마감합니다. 증가 및 감소 포지션 모델에서 사용하는 것이 좋습니다. 예: CLOSEOUT; 모든 방향의 모든 포지션을 종료합니다.
일반적으로 사용되는 JavaScript 언어 API
JavaScript 언어 API를 설명하기 전에 일반적인 코드 구조와 그 기능적 구성 요소를 살펴보겠습니다. 그러면 API를 더 잘 이해하는 데 도움이 될 것입니다. 아래 예를 참조하세요.

그림 2-10 JavaScript 코드 예제
위의 코드에서 표시된 대로:
JavaScript 언어에서 변수를 생성하는 것을 종종 변수 "선언"이라고 합니다. 빨간색 코드에서는 var 키워드를 사용하여 변수를 선언하고, 주황색 코드에서는 변수 이름이 "aa"입니다.
JavaScript에서 등호는 값을 할당하는 데 사용됩니다. 즉, "="의 오른쪽에 있는 값이 왼쪽에 있는 변수에 할당됩니다.
시안 코드 "exchange"는 교환 객체입니다. 여기서의 교환은 설정한 선물 회사를 나타냅니다. 이것은 고정된 형식이므로 JavaScript 언어 API를 호출할 때 교환 객체를 지정해야 합니다.
녹색 코드는 JavaScript API입니다. 이를 호출할 때 실제로는 교환 객체의 함수를 호출합니다. 파란색 코드 뒤에 있는 점은 고정된 형식입니다. 여기의 함수는 우리가 중학교에서 배운 함수와 같습니다. 함수에 매개변수가 필요하지 않으면 빈 괄호를 사용하여 나타냅니다. 함수에 매개변수가 필요하면 괄호 안에 매개변수를 작성합니다.
예제를 통해 코드의 기본 구조와 원리를 이해한 후, 앞으로 자주 사용하게 될 몇 가지 JavaScript 언어 API를 보여드리겠습니다.
SetContractType("제품 코드")——계약 유형, 즉 거래하려는 제품을 설정합니다.
예: exchange.SetContractType("rb1905"); //거래 유형을 "Rebar 1905 Contract"로 설정합니다.
GetTicker——틱 데이터 가져오기
예: exchange.GetTicker(); //틱 데이터 가져오기
GetRecords——K-라인 데이터 가져오기
예: exchange.GetRecords(); //K-라인 데이터 가져오기
구입하다
예시: exchange.Buy(5000, 1); // 5000위안에 한 lot 구매
판매——구매
예시: exchange.Sell(5000, 1); // 5,000위안에 한 묶음 판매
GetAccount——계정 정보 가져오기
예: exchange.GetAccount(); //계좌 정보 가져오기
GetPosition——위치 정보 가져오기
예: exchange.GetPosition(); //위치 정보 가져오기
SetDirection——장기 또는 단기 주문 유형을 설정합니다.
예를 들어:
exchange.SetDirection("buy"); // 롱 포지션을 열기 위해 주문 유형을 매수로 설정
exchange.SetDirection("closebuy"); //매도 주문 유형을 롱 포지션 마감으로 설정
exchange.SetDirection("sell"); // 숏 포지션을 오픈하기 위해 주문 유형을 매도로 설정
exchange.SetDirection("closesell"); //매수 포지션을 마감하기 위해 주문 유형을 매수로 설정
로그 - 로그에 메시지 출력
예: Log("hello, world"); // 로그에 "hello world"를 출력합니다.
수면 - 일정 시간 동안 프로그램을 일시 중지합니다.
예: Sleep(1000); // 1초 동안 프로그램 일시 정지
여러분 중에 이렇게 많은 API를 어떻게 기억하는지 궁금해하는 분이 있을 겁니다. 사실, 이 모든 것을 외울 필요는 없습니다. Inventor Quant의 공식 웹사이트에는 자세한 API 문서 세트가 있습니다. 사전을 찾는 것처럼, 필요할 때면 그냥 찾으면 됩니다. 처음 접하는 코드나 다른 콘텐츠에 겁먹지 마세요. 우리가 원하는 것은 이러한 언어를 통해 우리만의 전략을 구성하는 것입니다. 기술은 결코 정량화의 한계가 아니라는 점을 기억하세요. 좋은 전략이 있는지 여부는 정량적 시장에서 장기적으로 갈 수 있는지의 열쇠입니다.
요약하다
위의 API는 양적 거래에서 가장 일반적으로 사용되는 API로, 기본적으로 데이터 획득, 데이터 계산, 매수 및 매도 주문이 포함되며, 이는 간단한 양적 거래 전략을 처리하기에 충분합니다. 물론, 더 복잡한 전략을 작성하려면 Inventor Quantitative Tool의 공식 웹사이트로 이동하여 이를 얻어야 합니다.
숙제
- 5기간 이동평균선이 10기간 이동평균선을 교차한다는 문장을 마이어로 써보세요.
- JavaScript에서 GetAccount를 사용하여 계정 정보를 가져온 후 Log를 사용하여 로그에 인쇄해 보세요.
다음 섹션 미리보기
프로그래밍은 레고 블록을 조립하는 것과 같고, API는 블록의 다양한 부품과 같으며, 프로그래밍 과정은 다양한 레고 부품을 조립하여 완전한 장난감을 만드는 것입니다. 다음 섹션에서는 Mai Language API를 사용하여 완전한 양적 거래 전략을 구축하는 방법을 안내해 드리겠습니다.
2.4 발명가 양적 시스템에 대한 전략을 작성하는 방법
요약
이전 섹션을 공부한 후, 마침내 양적 거래 전략을 작성할 수 있게 되었습니다. 이는 수동 거래에서 양적 거래로 전환하는 데 가장 중요한 단계가 될 것입니다. 사실, 그것은 그렇게 신비롭지 않습니다. 전략을 쓰는 것은 단지 당신의 아이디어를 코드로 바꾸는 것에 불과합니다. 이 섹션에서는 양적 거래 전략을 처음부터 구현하고 Inventor 양적 시스템에서 전략을 작성하는 방법에 대해 알아봅니다.
준비하다
먼저 Inventor Quantitative Tool의 공식 웹사이트를 열고 "Strategy Library"와 "New Strategy"를 차례로 클릭합니다. 코드 작성을 시작하기 전에 프로그래밍 언어 드롭다운 메뉴에서 Mai 언어나 JavaScript 언어를 선택해야 합니다. 물론 이 플랫폼은 Python, C++, Visual 언어도 지원합니다.
전략적 아이디어
이전 장에서는 가격이 이동 평균선을 돌파하는 전략을 소개했습니다. 즉, 가격이 지난 10일간의 평균 가격보다 높으면 매수하고, 가격이 지난 10일간의 평균 가격보다 낮으면 매도합니다. 하지만 가격이 시장 상황을 직접적으로 반영할 수 있다고 하더라도, 거짓 돌파 신호가 많이 있을 수 있으므로 이 전략을 업그레이드하고 개선할 필요가 있습니다.
첫째, 추세 방향을 결정하기 위해 더 큰 기간 이동 평균을 선택합니다. 이는 적어도 거짓 돌파 신호의 거의 절반을 걸러냈습니다. 큰 기간 이동 평균은 느리지만 더 안정적일 것입니다. 그런 다음 진입 성공률을 더욱 높이기 위해 이 큰 기간 이동 평균이 적어도 상승한다는 조건을 추가합니다. 마지막으로 가격, 단기 이동 평균, 장기 이동 평균의 상대적 위치 관계를 사용하여 완전한 거래 전략을 형성합니다.
전략 논리
위의 전략적 아이디어와 사고를 바탕으로 전략적 논리를 구축해 볼 수 있습니다. 여기서의 논리는 천체 운동 법칙을 계산하라는 것이 아닙니다. 그렇게 복잡한 것도 아니거든요. 이는 이전의 전략적 아이디어를 말로 표현하는 것에 불과합니다.
롱 포지션 오픈: 현재 포지션이 없고, 종가가 단기 이동평균선보다 크고, 종가가 장기 이동평균선보다 크고, 단기 이동평균선이 장기 이동평균선보다 크고, 장기 이동평균선이 상승하는 경우입니다.
숏포지션을 오픈하다: 현재 포지션이 없고, 종가가 단기 이동평균선보다 낮은 경우, 종가가 장기 이동평균선보다 낮은 경우, 단기 이동평균선이 장기 이동평균선보다 낮은 경우, 장기 이동평균선이 하락하는 경우입니다.
롱 포지션 마감: 현재 롱 주문을 보유하고 있고, 종가가 장기 이동평균선보다 낮거나, 단기 이동평균선이 장기 이동평균선보다 낮거나, 장기 이동평균선이 하락하는 경우입니다.
숏포지션 청산: 현재 단기 주문을 보유하고 있고, 종가가 장기 이동평균선보다 높거나, 단기 이동평균선이 장기 이동평균선보다 높거나, 장기 이동평균선이 상승하는 경우입니다.
위의 내용은 전체 양적 거래 전략의 논리적 부분입니다. 전략 로직의 텍스트 버전을 코드로 변환하면 시장 상황 파악, 지표 계산, 매수 및 매도 주문의 세 단계가 포함됩니다.
언어 전략
첫 번째 단계는 시장 정보를 얻는 것입니다. 이 양적 거래 전략에서 우리는 종가만 얻으면 됩니다. Mai 언어에서 종가를 얻기 위한 API는 CLOSE입니다. 즉, 최신 K-라인의 종가를 얻으려면 코드에 CLOSE만 쓰면 됩니다.
그 다음에는 계산 지표가 나옵니다. 이 양적 거래 전략에서 우리는 총 2가지 기술, 즉 단기 이동 평균과 장기 이동 평균을 사용합니다. 단기 이동 평균은 10기간 이동 평균이고 장기 이동 평균은 50기간 이동 평균이라고 가정합니다. 그러면 10기간 이동 평균과 50기간 이동 평균을 나타내기 위해 코드를 어떻게 사용할까요? 다음 그림을 참조하세요.

그림 2-11 Mai 언어 전략 코드
수동 거래에서는 50기간 이동평균선이 상승하는지 하락하는지 한눈에 볼 수 있지만, 이를 코드로 어떻게 표현할까요? 이동평균선이 상승하고 있는지 판단하기 위해서는, 현재 K-라인의 50기간 이동평균선이 이전 K-라인의 50기간 이동평균선보다 크고, 이전 K-라인의 50기간 이동평균선이 이전 K-라인의 50기간 이동평균선보다 큰 것이 아닌가 생각해 보세요. 사실은 그 반대입니다. 즉, 이동 평균선은 하락하고 있습니다. 따라서 코드는 다음과 같아야 합니다.

그림 2-12 마이어 판단 이동평균 코드
위 그림의 8, 9행에 있는 장미색 코드 "AND"를 주목하세요. 마이어로 "and"를 의미합니다. 예를 들어, 9번째 줄은 중국어로 다음과 같이 번역됩니다. 현재 K-라인의 50기간 이동 평균이 이전 K-라인의 50기간 이동 평균보다 크고, 이전 K-라인의 50기간 이동 평균이 이전 K-라인의 50기간 이동 평균보다 크면 값이 "예"로 계산됩니다. 그렇지 않으면 값이 "아니요"로 계산되고 결과가 "MA50_ISUP"에 할당됩니다.
마지막 단계는 매수 및 매도 주문을 하는 것입니다. 매수 및 매도 로직 코드 다음에 발명가의 양적 도구의 주문 API를 호출하기만 하면 매수 및 매도 작업이 실행됩니다. 다음 그림을 참조하세요.

그림 2-13 Mai 언어 매수 및 매도 거래 코드
위 그림의 13, 14번째 줄에 있는 장미색 코드 "OR"을 주목하세요. 마이어로 "또는"을 뜻합니다. 예를 들어, 13번째 줄은 중국어로 다음과 같이 번역됩니다. 현재 K-라인의 종가가 현재 K-라인의 50기간 이동 평균보다 낮거나, 현재 K-라인의 10기간 이동 평균이 현재 K-라인의 50기간 이동 평균보다 낮으면 값이 "예"로 계산되어 즉시 주문이 실행됩니다. 그렇지 않으면 값이 "아니요"로 계산되어 아무 작업도 수행되지 않습니다.
참고: "AND"와 "OR"는 Mai 언어의 논리 연산자입니다.
"AND"는 모든 조건이 "예"일 때 최종 조건도 "예"라는 것을 의미합니다.
"OR"은 모든 조건 중 하나라도 "예"이면 마지막 조건도 "예"가 됨을 의미합니다.
요약하다
위의 내용은 Inventor Quantitative Tool에서 Mai 언어로 거래 전략을 작성하는 전체 과정입니다. 전략 아이디어를 갖는 것부터 전략을 구상하고 논리를 말로 설명하는 것, 마지막으로 코드로 완전한 거래 전략을 구현하는 것까지 총 세 단계만 있습니다. 이것은 간단한 전략이지만, 구체적인 구현 과정은 보다 복잡한 전략과 비슷합니다. 다만 전략의 알고리즘과 데이터 구조가 다릅니다. 따라서 본 섹션의 양적 전략 프로세스를 이해하고 숙지한다면, Mai 언어를 사용하여 양적 전략 연구를 수행하고 필요에 따라 발명가의 양적 도구에 대한 연습을 수행할 수 있습니다.
숙제
- 이 섹션의 전략을 직접 구현해 보세요.
- 이 섹션의 전략에 따라 손절매 및 손절매 기능을 추가합니다.
다음 섹션 미리보기
양적 거래 전략 개발에서 프로그래밍 언어는 무기와 장비와 같습니다. 좋은 프로그래밍 언어는 절반의 노력으로 두 배의 결과를 얻는 데 도움이 될 수 있습니다. 예를 들어, 양적 거래 산업에서 가장 일반적으로 사용되는 언어는 Python, C++, Java, C#, EasyLanguage, Mai Language 등 12개 이상이 있습니다. 전장에 나갈 때 어떤 무기를 선택해야 할까? 다음 섹션에서는 이러한 일반적인 프로그래밍 언어와 각 프로그래밍 언어의 특징을 소개하겠습니다.
3장 거래 전략을 구현하기 위한 간단한 프로그래밍 언어
3.1 양적 거래 프로그래밍 언어의 수평적 평가
요약
1장과 2장에서 우리는 양적 거래의 기본과 발명가의 양적 도구를 사용하는 방법을 배웠습니다. 이 장에서는 거래 전략을 자세히 구현할 것입니다. 일을 잘하려면 먼저 도구를 날카롭게 해야 합니다. 거래 전략을 구현하려면 먼저 프로그래밍 언어를 숙달해야 합니다. 이 섹션에서는 먼저 양적 거래에서 주로 쓰이는 프로그래밍 언어를 소개하고, 각 프로그래밍 언어의 특징에 대해서도 살펴봅니다.
프로그래밍 언어란 무엇인가
프로그래밍 언어를 배우기 전에 먼저 "프로그래밍 언어"라는 개념을 이해해야 합니다. 프로그래밍 언어는 인간과 컴퓨터가 모두 이해할 수 있는 언어입니다. 표준화된 통신 코드입니다. 프로그래밍 언어의 목적은 인간의 언어를 사용하여 컴퓨터를 제어하고 컴퓨터에게 우리가 원하는 것을 말하는 것입니다. 컴퓨터는 프로그래밍 언어에 따라 명령을 실행할 수 있으며, 우리도 컴퓨터에 명령을 내리는 코드를 작성할 수 있습니다.
우리 부모님이 어렸을 때 말하는 법을 가르쳐 주셨듯이, 다른 사람들이 하는 말을 이해하는 법도 가르쳐 주셨습니다. 오랜 기간의 영향과 독학 끝에 우리는 자신도 모르게 말하는 법을 배웠고 다른 아이들이 하는 말을 이해할 수 있게 되었습니다. 중국어, 영어, 프랑스어 등 다양한 언어가 있습니다. 예를 들어:
중국어: Hello World
한국어: 안녕하세요 월드
프랑스어: Bonjour tout le monde
프로그래밍 언어를 사용하여 컴퓨터 화면에 "Hello World"를 표시하면 다음과 같습니다.
C 언어: puts("Hello World");
Java 언어: System.out.println("Hello World");
파이썬 언어 : print("Hello World")
우리는 컴퓨터 언어가 고유한 규칙을 가지고 있고, 많은 언어가 있다는 것을 알 수 있습니다. 이러한 언어 규칙은 오늘 우리가 여러분에게 설명해야 할 프로그래밍 언어 분류입니다. 각 분류에서 우리는 가장 기본적이고 일반적으로 사용되는 규칙만 기억하면 되며, 이러한 프로그래밍 언어를 사용하여 컴퓨터와 통신하고 컴퓨터가 우리의 지시에 따라 해당 전략을 실행하도록 할 수 있습니다.
프로그래밍 언어 분류
귀하의 참조 및 비교를 용이하게 하고 귀하에게 적합한 양적 거래 프로그래밍 언어를 선택할 수 있도록 가장 일반적으로 사용되는 여섯 가지 프로그래밍 언어인 Python, Matlab/R, C++, Java/C#, EasyLanguage 및 시각적 언어(아래 표시)를 분류하겠습니다.
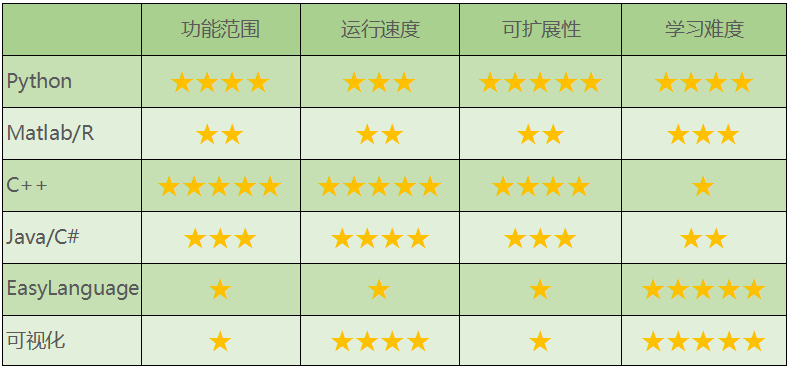
그림 3-1 프로그래밍 언어 평가
우리는 기능적 범위, 실행 속도, 확장성, 학습 난이도 등을 기준으로 이러한 솔루션을 평가했습니다. 점수는 1~5 사이입니다. 예를 들어, 기능 범위 측면에서 5점은 기능이 강력하다는 것을 의미하고, 1점은 기능이 덜하다는 것을 의미합니다. (위에 표시된 대로) 시각적 언어와 EasyLanguage는 배우기 쉽고 초보자에게 매우 적합합니다. Python은 강력하고 확장 기능이 뛰어나 보다 복잡한 거래 전략을 개발하는 데 적합합니다. C++는 거래 속도가 빠르고 고빈도 거래자에게 더 적합합니다.
그러나 각 프로그래밍 언어에 대한 평가는 주로 양적 거래 분야에 대한 응용을 목표로 하며 개인적인 주관적 요소를 포함하고 있습니다. 또한, 댓글 섹션에서 비판하거나 토론을 위한 의견을 제시하셔도 좋습니다. 다음으로, 이러한 프로그래밍 언어를 하나씩 소개하겠습니다.
시각 언어
시각적 프로그래밍은 오랜 역사를 가지고 있으며 새로운 것이 아닙니다. 다양한 제어 모듈을 갖춘 이 "보이는 대로 얻는다" 프로그래밍 컨셉은 드래그 앤 드롭만으로 코드 로직을 구축하고 거래 전략 설계를 완료할 수 있습니다. 이 프로세스는 빌딩 블록과 매우 유사합니다.
그림 3-2 시각적 프로그래밍 언어 인터페이스
위에 표시된 것처럼, Inventor Quantitative Trading Platform의 시각적 프로그래밍을 사용하면 몇 줄의 코드만으로 동일한 프로그램을 완성할 수 있습니다. 이를 통해 프로그래밍에 대한 문턱이 크게 낮아지고, 특히 프로그래밍에 대한 지식이 없는 트레이더에게는 매우 좋은 운영 경험이 됩니다.
이 시각적 언어의 기본 구현 전략이 C++로 변환되었으므로 프로그램 실행 속도에 거의 영향을 미치지 않습니다. 그러나 그 기능성과 확장성은 상대적으로 약하고, 지나치게 복잡하거나 정교한 거래 전략을 개발하는 것은 불가능합니다.
쉬운언어
EasyLanguage는 일부 상업용 양적 거래 소프트웨어에만 있는 프로그래밍 언어를 말합니다. 이러한 언어도 일부 객체 지향적 특징을 가지고 있지만, 주로 애플리케이션에서 스크립트화됩니다. 구문 면에서도 자연어와 매우 유사합니다. 양적 거래 초보자의 경우 EasyLanguage를 진입점으로 사용하는 것이 더 나은 선택입니다. 예를 들어: 발명가의 양적 거래 플랫폼에서의 Mai 언어.
이 스크립팅 언어는 특정 소프트웨어에서 전략 백테스팅과 실제 거래를 하는 데는 문제가 없지만 확장성 측면에서 종종 제한적입니다. 예를 들어, 전략 개발자는 외부 API를 호출할 수 없습니다. 게다가 실행 속도 측면에서 이 스크립팅 언어는 자체 가상 머신에서 실행되며 성능 최적화가 Java/C#만큼 좋지 않아 느립니다.
Python
Stackoverflow에서 주요 프로그래밍 언어의 방문자 수는 최근 몇 년 동안 크게 변화가 없었으며, Python만이 상승 추세를 보였습니다. Python은 웹사이트 개발, 머신 러닝, 딥 러닝, 데이터 분석 등에 사용할 수 있습니다. 유연성과 개방성 덕분에 가장 일반적인 언어가 되었습니다. 양적 투자 분야에서도 마찬가지입니다. 현재 국내 양적 플랫폼 대부분은 파이썬을 기반으로 하고 있습니다.
파이썬의 기본적인 데이터 구조인 리스트와 사전은 매우 강력하며, 기본적으로 데이터 표현의 요구를 충족시킬 수 있습니다. 더 빠르고 포괄적인 데이터 구조가 필요하다면 NumPy와 SciPy를 사용하는 것이 좋습니다. 이 두 라이브러리는 기본적으로 Python 과학 컴퓨팅의 표준 라이브러리라고 합니다.
금융공학의 경우 Pandas가 더욱 구체적인 라이브러리입니다. Pandas에는 Series와 DataFrame의 두 가지 데이터 구조가 있으며 시계열을 처리하는 데 매우 적합합니다.
속도 면에서 Python은 중간에 위치하며 C++보다 느리고 EasyLanguage보다 빠릅니다. 그 이유는 Python이 동적 언어이고 순수한 Python으로 실행하면 속도가 평균이기 때문입니다. 하지만 Cython을 사용하면 일부 함수를 정적으로 최적화하여 C++의 속도에 접근할 수 있습니다.
접착제 언어로서 파이썬은 확장 성능 면에서 의심할 여지 없이 1위입니다. 다른 언어에 확장 가능하게 연결할 수 있을 뿐만 아니라 확장 API도 사용하기 매우 쉽게 설계되었습니다. 학습 난이도 측면에서 볼 때, Python은 구문이 간단하고, 코드가 읽기 쉽고, 시작하기 쉽습니다.
Matlab/R
다음은 Matlab과 R입니다. 이 두 언어는 주로 데이터 분석에 사용됩니다. 언어 작성자는 과학적 연산을 위한 많은 구문적 디자인을 만들었습니다. 그들의 특징은 자연스럽게 양적 거래 연산을 지원한다는 것입니다. 그러나 적용 범위는 비교적 제한적이며, 주로 데이터 분석과 전략적 백테스팅에 사용됩니다. 거래 시스템 및 전략 알고리즘 개발에 있어서 사용성과 안정성은 상대적으로 낮습니다.
또한 Matlab과 R은 고유한 언어 가상 머신에서 실행되기 때문에 실행 속도와 확장성이 상대적으로 낮습니다. 성능 측면에서 보면, 이들의 가상 머신은 Java와 C#보다 훨씬 나쁩니다. 하지만 구문이 수학적 표현에 더 가깝기 때문에 배우기가 비교적 쉽습니다.
C++
C++는 절차적 프로그래밍, 데이터 추상화, 객체 지향 프로그래밍, 일반 프로그래밍, 디자인 패턴 등 여러 가지 프로그래밍 모델을 지원하는 범용 프로그래밍 언어입니다. C++를 사용하면 원하는 모든 기능을 구현할 수 있지만, 이처럼 강력한 언어의 가장 큰 단점은 템플릿, 포인터, 메모리 누수 등을 배우기가 매우 어렵다는 것입니다.
현재 C++는 여전히 대량, 고빈도 트레이딩에 선호되는 프로그래밍 언어입니다. 그 이유는 간단합니다. C++ 언어의 특성은 기본 컴퓨터에 접근하기 쉽기 때문에 대량의 데이터를 처리하는 고성능 백테스팅 및 실행 시스템을 개발하는 데 가장 효과적인 도구입니다.
Java/C#
Java/C#은 모두 가상 머신에서 실행되는 정적 언어입니다. C++와 비교했을 때 배열 범위를 벗어난 오류가 없고, 코어 덤프가 없으며, throw된 예외는 오류 코드의 위치를 정확하게 찾을 수 있으며, 내장된 가비지 수집 메커니즘이 있으며, 메모리 누수에 대해 걱정할 필요가 없습니다. 따라서 구문을 배우는 데 있어서 어려움 측면에서도 C++보다 쉽습니다. 실행 속도 측면에서 볼 때, 모든 가상 머신은 런타임 컴파일을 위한 자체 JIT 함수를 갖고 있으므로 속도는 C++에 이어 두 번째로 빠릅니다.
하지만 기능 측면에서 볼 때 C++처럼 기본 거래 시스템을 최적화하는 것은 불가능합니다. 확장 성능 면에서는 C++보다 약합니다. 왜냐하면 확장을 위해 C의 브릿지를 거쳐야 하며, 이 두 언어 자체가 가상 머신에서 실행되기 때문에 기능 모듈을 확장할 때 이를 달성하기 위해 추가적인 장벽을 넘어야 하기 때문입니다.
요약하다
하지만 다시 생각해 보면, 양적 프로그래밍 언어는 중요한 것이 아니라, 아이디어가 중요합니다. 발명자가 발명한 양적 마이 언어와 시각화 언어를 양적 진입을 위한 디딤돌로 사용하는 데는 전혀 문제가 없습니다. 진입 후 개선하려면 다양한 시장 조건과 결합하여 끊임없이 시도하고 탐색해야 합니다. 아이디어가 탈출구를 결정하고 비전이 영역을 결정한다고 할 수 있습니다.
"전략을 설계하고, 아이디어를 거래하세요." 이 관점에서 보면, 양적 거래의 핵심은 여전히 아이디어 거래입니다. 양적 트레이더라면 전략 작성 플랫폼의 기본 구문과 기능을 숙지해야 할 뿐만 아니라, 실제 전투에서 트레이딩 개념을 경험해야 합니다. 정량화는 다양한 거래 개념을 반영하기 위한 도구이자 매개체일 뿐입니다.
숙제
- 양적 거래에 있어서 Python 언어의 장점은 무엇입니까?
- 발명가의 Mai 언어를 사용하여 일반적으로 사용되는 API를 작성해 보세요.
다음 섹션 미리보기
위의 프로그래밍 언어 소개를 통해 여러분은 선택 방법을 알아야 한다고 생각합니다. 다음 몇 장에서는 프로그래밍 언어 분류에 따라 목표 지향적인 방식으로 양적 거래 전략 개발을 배울 것입니다.
3.2 Mai Language 빠른 시작 가이드
요약
마이어란 무엇인가? Mai 언어는 초기 주식 기술 지표에서 확장된 일련의 프로그램 함수 라이브러리입니다. 알고리즘은 함수로 캡슐화되며, 사용자는 전략 논리를 구현하기 위해 빌딩 블록을 가지고 놀듯이 줄별로 함수를 호출하기만 하면 됩니다.
"작은 구문, 큰 기능"의 구성 모드를 채택하여 쓰기 효율성을 크게 향상시킵니다. 다른 언어로 100개 이상의 문장이 필요한 전략은 일반적으로 Mai Language에서는 12개 문장으로 작성할 수 있습니다. 발명가의 양적 도구의 재무 통계 함수 라이브러리와 데이터 구조를 결합하여 일부 복잡한 거래 논리도 지원할 수 있습니다.
완전한 전략
Inventor Quantized Wheat Language 빠른 시작을 소개하기에 앞서 이 섹션의 핵심 지식을 빠르게 이해할 수 있도록 먼저 이 섹션의 개념에 대한 사전 이해가 필요합니다. 우리는 여전히 장기 50일 이동평균과 단기 10일 이동평균을 기본 사례로 사용하고 이전 장에서 언급한 전체 전략 사례를 검토합니다.
롱 포지션 오픈: 현재 포지션이 없고, 종가가 단기 이동평균선보다 크고, 종가가 장기 이동평균선보다 크고, 단기 이동평균선이 장기 이동평균선보다 크고, 장기 이동평균선이 상승하는 경우입니다.
숏포지션을 오픈하다: 현재 포지션이 없고, 종가가 단기 이동평균선보다 낮은 경우, 종가가 장기 이동평균선보다 낮은 경우, 단기 이동평균선이 장기 이동평균선보다 낮은 경우, 장기 이동평균선이 하락하는 경우입니다.
롱 포지션 마감: 현재 롱 주문을 보유하고 있고, 종가가 장기 이동평균선보다 낮거나, 단기 이동평균선이 장기 이동평균선보다 낮거나, 장기 이동평균선이 하락하는 경우입니다.
숏포지션 청산: 현재 단기 주문을 보유하고 있고, 종가가 장기 이동평균선보다 높거나, 단기 이동평균선이 장기 이동평균선보다 높거나, 장기 이동평균선이 상승하는 경우입니다.
Mai 언어 코드로 작성하면 다음과 같습니다.

그림 3-3 Mai 언어의 완전한 예
완전한 양적 거래 전략을 작성하려면 일반적으로 데이터 수집, 데이터 계산, 논리 계산, 주문 실행 등 여러 단계가 필요합니다. 위 그림에서 보듯이 전체 코드에서 단 하나의 API만 사용하여 기본 데이터를 얻었는데, 첫 번째와 두 번째 줄에서는 "CLOSE"를 사용했습니다. 그런 다음 첫 번째에서 아홉 번째 줄까지는 데이터 계산 부분이고, 마지막으로 열한 번째에서 열네 번째 줄까지는 논리 계산 및 순서 배치 부분입니다.
보라색 코드는 변수입니다. 첫 번째부터 아홉 번째 줄까지 녹색 ":="은 할당 연산자입니다. 할당 연산자의 오른쪽에 있는 데이터는 계산 후 왼쪽 변수에 할당됩니다. 주황색 코드는 API입니다. 예를 들어, 첫 번째 줄에서 MA(이동 평균)를 호출하려면 두 개의 매개변수를 전달해야 하는데, 이는 설정으로 이해할 수 있습니다. 즉, MA를 호출할 때 MA의 유형을 설정해야 합니다. 장미색 "AND"와 "OR"은 논리 연산자인데, 주로 여러 논리 계산 등을 연결하는 데 사용됩니다. 위의 기본적인 지식 개념을 바탕으로 마이어의 자세한 기본 사항을 배워보겠습니다.
기본 데이터
기본 데이터(개장가, 최고가, 최저가, 종가, 거래량)는 양적 거래에 없어서는 안 될 부분입니다. 전략에서 최신 기본 데이터를 얻으려면 발명가의 양적 도구의 API만 호출하면 됩니다. 과거 기본 데이터를 얻고 싶다면 "REF"를 사용하면 됩니다. 예를 들어, REF(CLOSE, 1)은 어제의 종가를 구합니다.
변수
변수는 변경할 수 있는 숫자입니다. 변수의 이름은 코드로 이해할 수 있습니다. 이름은 한자, 문자, 숫자, 대시를 지원하지만 길이는 31자 이내로 제어해야 합니다. 변수 이름은 서로 반복될 수 없으며, 매개변수 이름이나 함수 이름(API)과 함께 사용될 수 없으며, 각 명령문은 세미콜론으로 끝나야 합니다. 글을 쓴 후에 자신의 언어에 대한 주석을 달고 싶으면 끝에 "//"를 사용하세요. 반각 입력 방식의 대문자 모드로 작성해야 합니다. 다음 그림과 같이:

그림 3-4 Mai 언어 데이터 유형
변수 할당
변수 할당은 할당 연산자의 오른쪽에 있는 값을 왼쪽에 있는 변수에 할당하는 것입니다. 4가지 유형의 할당 연산자가 있으며, 이를 통해 차트에 값을 표시할지 여부를 제어하고 표시 위치를 정의할 수 있습니다. 아래 그림의 녹색 글꼴은 할당 연산자, 즉 “:”, “:=", “^^”, 그리고 “..”입니다. 그림의 코드 주석은 그 의미를 자세히 설명합니다.

그림 3-5 Mai 언어 변수 할당
데이터 타입
Mai 언어에는 다양한 데이터 유형이 있는데, 가장 일반적으로 사용되는 데이터 유형은 숫자형, 문자열형, 부울형입니다. 숫자형은 정수, 소수, 양수, 음수 등을 포함한 숫자입니다. 예: 1, 2, 3, 1.1234, 2.23456...; 문자열형은 텍스트, 중국어, 영어, 숫자로 이해될 수 있으며 모두 문자열이 될 수 있습니다. 예: '발명가 수량화', '종가가격', '6000'; 문자열형은 영어 세미콜론으로 묶어야 합니다. 부울형은 가장 간단하며 두 가지 값인 "예"와 "아니요"만 있습니다. 예: 1은 "예"를 나타내는 참을 나타내고, 0은 "아니요"를 나타내는 거짓을 나타냅니다.
관계 연산자
이름에서 알 수 있듯이 관계 연산자는 두 값 간의 관계를 비교하는 데 사용되는 연산자입니다. 다음과 같이 같음, 보다 큼, 보다 작음, 크거나 같음, 작거나 같음, 같지 않음이 있습니다.

그림 3-6 Mai 언어 연산자
논리 연산자
논리 연산은 개별적인 부울 문장을 하나의 전체로 연결할 수 있습니다. 가장 일반적으로 사용되는 것은 "AND"와 "OR"입니다. "종가가 시가보다 크다"와 "종가가 이동 평균보다 크다"라는 두 개의 부울 유형 값이 있다고 가정하면, 이를 "종가가 시가보다 크고 (AND) 종가가 이동 평균보다 크다", "종가가 시가보다 크다 또는 (OR) 종가가 이동 평균보다 크다"와 같이 부울 값으로 결합할 수 있습니다.

그림 3-7 Mai 언어의 논리적 연산
모두 주의하세요:
"AND"는 모든 조건이 "예"일 때 최종 조건도 "예"라는 것을 의미합니다.
"OR"은 모든 조건 중 하나라도 "예"이면 마지막 조건도 "예"가 됨을 의미합니다.
"AND"는 "&&"로 쓸 수 있고 "OR"는 "||"로 쓸 수 있습니다.
계산기
Mai 언어에서 일반적으로 사용되는 산술 연산자("+", "-",*”, “/”)는 아래와 같이 초등학교에서 배우는 수학과 다르지 않습니다.

그림 3-8 Mai 언어의 산술 연산
우선 순위
만약 100이 있다면*(10-1)/(10+5) 식의 경우, 프로그램은 어느 단계를 먼저 계산합니까? 중학교 수학에서는 ① 같은 수준의 연산이면 대체로 왼쪽에서 오른쪽으로 계산한다고 합니다. ② 덧셈과 뺄셈이 모두 있고, 곱셈과 나눗셈이 있는 경우, 곱셈과 나눗셈을 먼저 계산한 후, 덧셈과 뺄셈을 계산합니다. ③괄호가 있는 경우, 괄호 안의 내용을 먼저 계산합니다. ④ 연산 법칙에 맞는 경우 연산 법칙을 이용하여 계산을 간소화할 수 있다. Mai 언어의 우선순위는 아래와 같습니다.

그림 3-9 Mai 언어의 산술 연산 우선순위
실행 모드
발명가의 정량적 도구인 Mai 언어에는 프로그램 전략 실행을 위한 두 가지 모드가 있습니다. 즉, 종가 모드와 실시간 가격 모드입니다. 종가 모드는 현재 K-라인 신호가 설정되고 다음 K-라인이 시작되면 즉시 주문 거래가 실행됨을 의미합니다. 실시간 가격 모드는 현재 K-라인 신호가 설정되면 주문 거래가 즉시 실행됨을 의미합니다.
일중 전략
당일 거래 전략인 경우, 거래일이 끝나고 포지션을 마감해야 할 때는 "TIME" 시간 함수를 사용해야 합니다. 이 기능은 두 번째 기간보다 높고 낮 기간보다 낮을 때 4자리 숫자로 표시됩니다. 즉, HHMM(1450-14:50)입니다. 참고 사항: 거래 종료 시 포지션을 마감하는 조건으로 TIME 함수를 사용하는 경우, 개시 조건에도 해당 시간 제한을 두는 것이 좋습니다. 아래와 같이 표시됩니다.

그림 3-10 마이크 언어 시간 기능
모델 분류
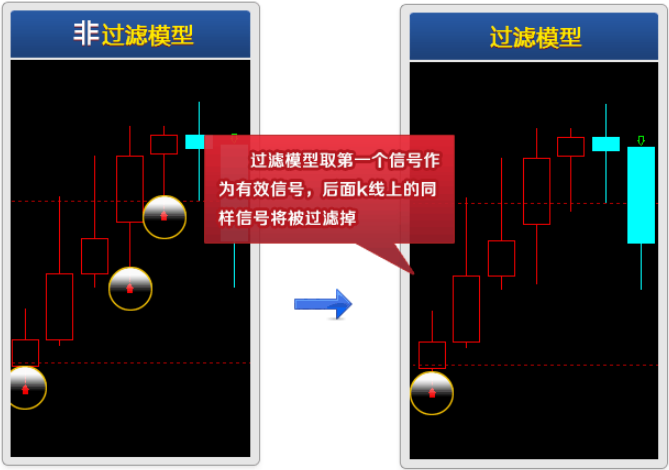
그림 3-11 Mai 언어 모델의 분류
마이어에는 두 가지 유형의 모델 분류가 있습니다. 즉, 비필터링 모델과 필터링 모델입니다. 사실, 이해하기 매우 쉽습니다. 비필터링 모델은 연속적인 개폐 신호를 허용하여 포지션을 추가하고 줄이는 기능을 실현할 수 있습니다. 필터링 모델은 연속적인 개방 또는 폐쇄 신호를 허용하지 않습니다. 즉, 개방 신호가 나타나면 폐쇄 신호가 나타날 때까지 후속 개방 신호가 필터링됩니다. 비필터링 모델에서 신호 순서는 다음과 같습니다. 개방-폐쇄-개방-폐쇄-개방.....
요약하다
위의 내용은 Mai 언어에 대한 간단한 소개입니다. 이를 배우고 나면 양적 거래 전략을 프로그래밍할 수 있습니다. 더욱 복잡한 전략을 작성해야 하는 경우 Inventor Quantitative Tool Mai Language API 문서를 참조하거나 공식 고객 서비스에 직접 문의하여 양적 거래 전략을 작성하세요.
다음 섹션 미리보기
데이 트레이딩도 트레이딩 모델입니다. 이 방법은 포지션을 밤새도록 유지하지 않으므로 시장 변동성 위험이 낮습니다. 불리한 시장 상황이 발생하면 적절한 시기에 조정할 수 있습니다. 이 섹션에서는 Mai 언어에 대한 소개를 배우고, 다음 섹션에서는 실행 가능한 일일 양적 거래 전략을 작성하는 방법을 보여드리겠습니다.
숙제
- Inventor Quantitative Tool을 사용하여 Mai 언어로 API를 작성하여 기본 데이터를 얻어보세요.
- 차트에서 변수 할당을 표시하는 방법은 무엇입니까?
3.3 마이어에서 전략을 구현하는 방법
요약
이전 글에서는 Mai 언어 소개, 기본 구문, 모델 실행 방법, 모델 분류 등의 관점에서 거래 전략을 구현하는 전제를 설명했습니다. 이번 글에서는 이전 글의 내용을 이어가며 일반적으로 사용되는 전략 모듈과 기술 지표를 통해 실행 가능한 일일 양적 거래 전략을 단계별로 실현하도록 도와드리겠습니다.
정책 모듈
생각해보세요. 레고 조각으로 로봇을 어떻게 만들 수 있을까요? 조각조각으로 조립할 수도 없고, 위에서 아래로, 아래에서 위로 조립할 수도 없습니다. 상식이 조금만 있는 사람이라면 머리, 팔, 다리, 날개 등을 따로 조립한 다음 합치면 완전한 로봇이 된다는 걸 알 것입니다. 프로그램을 작성할 때도 마찬가지입니다. 필요한 기능을 전략 모듈에 작성한 다음 전략 모듈을 완전한 양적 거래 전략으로 결합합니다. 아래에 흔히 사용되는 전략 모듈을 나열해 보겠습니다.
위상 증가
단계적 증가는 현재 K-라인의 종가와 이전 N기간의 종가의 차이의 백분율을 계산하여 계산합니다. 예를 들어, 마지막 10개 K-라인 기간의 증가를 계산하려면 코드를 다음과 같이 작성할 수 있습니다.

그림 3-12 Mai 언어 단계 성장
새로운 최고치
새로운 최고가를 설정하려면 현재 K-라인이 N개 기간 동안의 최고 가격보다 높은지 계산해야 합니다. 예를 들어, 현재 K-라인이 마지막 10개 K-라인 중 가장 높은 가격보다 큰지 계산하려면 코드를 다음과 같이 작성할 수 있습니다.

그림 3-13 Mai 언어가 새로운 최고치를 기록했습니다.
대량 거래량 상승
대량의 거래량 상승은 가격 상승과 거래량의 급격한 증가로 이해될 수 있습니다. 예를 들어, K-라인의 종가가 이전 10개 K-라인의 종가의 1.5배인 경우, 10일 동안 50% 증가했다는 의미입니다. 거래량은 지난 10개 K-라인 평균의 5배를 넘습니다. 다음과 같은 코드로 작성할 수 있습니다.

그림 3-14 마이유유의 볼륨이 상승합니다.
좁은 마무리
좁은 범위 통합은 최근 기간 동안 가격이 특정 범위 내에 유지된다는 것을 의미합니다. 예를 들어: 10개 기간 내의 최고 가격과 10개 기간 내의 최저가의 차이를 현재 K-라인의 종가로 나눈 값이 약 0.05보다 작은 경우입니다. 다음과 같은 코드로 작성할 수 있습니다.

그림 3-15 밀 언어의 좁은 범위
이동평균선 강세 배열
이동평균선의 강세 배열은 강세 배열과 약세 배열로 나뉜다. K-라인은 5-10-20-30-60 이동평균선 아래에 지지선이 있는 상향 배열로, 이는 강세 배열이다. 강세 배열은 시장 추세가 강력한 상승 추세임을 의미한다. 다음과 같은 코드로 작성할 수 있습니다.

그림 3-16 Mai 언어 이동 평균 강세 배열
이전 최고치와 그 위치
이전 최고점과 이 최고점의 위치를 구하려면 Inventor Quantitative Tool의 API를 통해 직접 얻을 수 있습니다. 이는 코드로 작성할 수 있습니다:

그림 3-17 마이어의 이전 하이라이트
갭
갭은 두 개의 K-라인의 최고가와 최저가가 연결되지 않은 상황입니다. 두 개의 K-라인으로 구성되어 있습니다. 갭은 미래의 지지와 압박 지점에 대한 기준 가격입니다. 갭이 발생하면 원래 갭 방향으로 추세가 가속화되기 시작했다고 가정할 수 있습니다. 이는 코드로 작성할 수 있습니다:

그림 3-18 Mai 언어 격차
일반적인 기술 지표
이동 평균
그림 3-19 이동평균선 차트
통계적 관점에서 이동 평균이란 일일 가격의 산술 평균이며, 추세를 보이는 가격 궤적을 말합니다. 이동평균 시스템은 대부분의 분석가가 일반적으로 사용하는 기술 도구입니다. 기술적 관점에서 볼 때, 기술 분석가의 심리적 가격과 매수 및 매도 의사 결정 요인에 영향을 미치는 요소입니다. 기술 분석가에게 좋은 참고 도구입니다. 발명가의 정량적 도구는 다음 그림에서 볼 수 있듯이 다양한 유형의 이동평균을 지원합니다.

그림 3-20 마이어 각종 지표 산출
볼 채널
그림 3-21 BOLL 채널 다이어그램
BOLL은 볼린저 밴드 지표로도 알려져 있으며, 이 역시 통계 원리를 사용하여 N일 이동 평균을 기준으로 중간 트랙을 먼저 계산한 다음, 표준 편차를 기준으로 상단 및 하단 트랙을 계산합니다. BOLL 채널이 좁아지면 가격이 점차 평균으로 회귀하고 있다는 의미입니다. BOLL 채널이 좁은 것에서 넓은 것으로 바뀌면 시장이 변화하기 시작한다는 것을 의미합니다. 가격이 상단 트랙을 교차하면 매수력이 증가했음을 나타냅니다. 가격이 하단 트랙을 교차하면 매도력이 증가했음을 나타냅니다.
모든 기술 지표 중에서 BOLL의 계산 방법은 가장 복잡한 방법 중 하나로, 통계학에서 표준편차라는 개념을 도입하고 중간선(MB), 상위선(UP), 하위선(DN)을 계산하는 것을 포함합니다. 계산 방법은 다음과 같습니다.

그림 3-22 Mai 언어 Bollinger 밴드 계산
MACD 지표
그림 3-23 MACD 지표
MACD 지표는 빠른(단기) 이동평균선과 느린(장기) 이동평균선, 그리고 이들의 수렴 및 분리 부호를 사용하고 이중 평활화 연산을 수행합니다. 이동평균의 원리를 바탕으로 개발된 MACD는 이동평균의 허위 신호를 자주 내보내는 단점을 제거하고 이동평균의 효과를 그대로 유지했습니다. 따라서 MACD 지표는 이동평균 추세, 안정성, 안정성의 특성을 가지고 있습니다. 주식 매수매도 시점을 판단하고 주가의 상승과 하락을 예측하는 데 사용되는 기술 분석 지표입니다. 계산 방법은 다음과 같습니다.

그림 3-24 Mai Language의 MACD 지표
위의 내용은 양적 거래 전략을 개발하는 데 일반적으로 사용되는 전략 모듈입니다. 물론, 이보다 훨씬 더 많은 것이 있습니다. 위의 모듈 예제를 통해 주관적 거래에서 가장 일반적으로 사용되는 거래 모듈 중 몇 가지를 구현할 수도 있습니다. 이러한 방법은 모두 보편적입니다. 다음으로, 실행 가능한 일일 양적 거래 전략을 작성하는 방법을 알아보겠습니다.
전략 쓰기
외환 현물 시장에서는 한때 널리 유통된 돌파 거래 전략이 있었는데, 바로 HANS123 전략입니다. 이 전략은 개장 후 N K-라인의 간단한 고점과 저점 돌파를 거래 신호를 트리거하는 기준으로 사용합니다. 이는 조기 진입이 가능한 거래 모드이기도 합니다.
전략 논리
시장이 열리고 30분 후에 시장에 들어갈 준비를 하세요.
상단 트랙 = 개장 후 30분 후의 최고 지점
하단 트랙 = 개장 후 30분 낮음
가격이 상단 가격을 돌파하면 매수하여 포지션을 오픈하세요.
가격이 하단 추적선 아래로 떨어지면 매도 포지션을 엽니다.
당일 거래 전략, 장 마감 전에 포지션을 마감합니다.
전략 코드

그림 3-25 Mai 언어 전략 코드
요약하다
위에서 우리는 전략 모듈의 개념을 배웠고, 흔히 사용되는 여러 전략 모듈 사례를 통해 발명가의 양적 도구의 프로그래밍 방법에 익숙해졌습니다. 전략 모듈을 작성하는 법을 배우고 프로그래밍 논리적 사고를 향상시키는 것이 고급 양적 거래의 핵심 단계라고 할 수 있습니다. 마지막으로, 우리는 발명가의 양적 도구를 사용하여 외환 현물 거래에서 일반적으로 사용되는 거래 전략을 구현했습니다.
다음 섹션 미리보기
일부 친구들은 혼란스러워하고 밀집된 코드를 이해하지 못할 수도 있습니다. 걱정하지 마세요. 우리는 이미 여러분을 위해 이 모든 것을 생각해 냈습니다. Inventor Quantitative Tool에는 초보 사용자에게 더 적합한 프로그래밍 언어도 있습니다. 그것은 시각적 프로그래밍입니다. 이름에서 알 수 있듯이, 보이는 것이 바로 얻는 것입니다. 함께 기대해 봅시다!
숙제
- 주관적인 거래에서 가장 자주 사용하는 여러 거래 모듈을 구현해 보세요.
- 발명가의 양적 도구에서 Mai 언어를 사용하여 KDJ 지표 알고리즘을 구현해 보세요.
3.4 시각적 프로그래밍을 통한 빠른 시작
요약
많은 주관적 트레이더가 양적 트레이딩에 관심이 있습니다. 그들은 처음에는 자신감이 넘칩니다. 그러나 기존 프로그래밍 언어의 기본 구문, 데이터 연산, 데이터 구조, 논리적 제어 등을 배우고 나면 길고 복잡한 코드를 보고 낙담하거나 포기하는 경우가 많습니다. 이때는 시각적 프로그래밍 언어가 시작하기에 더 적합할 수 있습니다.
완전한 전략
이 섹션의 핵심 지식을 모두가 빠르게 이해할 수 있도록 Inventor Quantitative Visual Programming Language에 대한 빠른 소개를 시작하기 전에 먼저 시각적 언어로 작성된 전략이 어떤 모습인지 살펴보겠습니다. 이 섹션에서는 명사의 개념에 대한 기본적인 이해를 갖습니다. 종가가 50기간 이동평균보다 높을 때는 롱 포지션을 취하고, 종가가 50기간 이동평균보다 낮을 때는 숏 포지션을 취하는 가장 간단한 예를 들어보겠습니다.
롱 포지션 오픈: 현재 포지션이 없고, 종가가 50기간 이동평균보다 높은 경우.
숏포지션을 오픈하다: 현재 포지션이 없고, 종가가 50기간 이동평균보다 낮은 경우입니다.
롱 포지션 마감:현재 롱 포지션을 보유하고 있고 종가가 50일 이동평균선보다 낮은 경우.
숏포지션 청산:현재 단기 주문을 보유하고 있고 종가가 50기간 이동평균보다 높은 경우.
위의 전략을 시각적 언어로 표현하면 다음과 같습니다(아래 참조).

그림 3-26 시각적 언어 인터페이스
위 그림에서 보듯이, 전략 설계 과정 전체는 다음과 같습니다. 시장 유형을 설정하고, K-라인 배열을 구하고, 이전 K-라인의 50일 평균을 구하고, 이전 K-라인의 종가를 구하고, 포지션 배열을 구하고, 포지션 상태를 파악하고, 종가가 이동평균보다 크거나 작은지 판단하고, 오픈 또는 클로징을 실행합니다.
여기서 우리는 "배열"이라는 개념에 주의를 기울여야 합니다. 배열은 모든 프로그래밍 언어의 중요한 데이터 구조 중 하나입니다. 배열은 일련의 값을 저장할 수 있는 컨테이너와 같습니다. 예를 들어, K-라인 배열을 얻기 위해 API를 호출하면 다음과 같은 결과가 반환됩니다.

그림 3-27 K-라인 어레이
위 그림의 코드는 K-라인 배열입니다. 배열에는 총 3개의 데이터가 들어 있습니다. 즉, 이전 K-라인의 데이터, 이전 K-라인의 데이터, 현재 K-라인의 데이터입니다. 이 배열을 변수 "arr"에 할당하면, 이 배열의 마지막 데이터(루트 K 라인의 데이터)를 가져오려면 다음과 같이 작성할 수 있습니다(아래 그림의 4번째와 5번째 라인에 표시된 대로):

그림 3-28 배열 참조
실제로는 수백 또는 수천 개의 K-라인 데이터가 존재하고 새로운 K-라인이 끊임없이 증가하기 때문에 두 번째 방법(5번째 줄)을 사용하여 작성할 수 있습니다. 따라서 먼저 배열의 길이를 구할 수 있습니다. "arr.length"는 배열의 길이를 구한 다음 최신 K-라인의 데이터인 "1"을 뺍니다. 이전 K-라인의 데이터를 구하고 싶다면 "2"를 빼세요.
주의 깊은 사람들은 이 데이터가 "{}"로 묶여 있다는 것을 알 수 있습니다. 영어 이름에서 대략적으로 시간, 시가, 최고가, 최저가, 종가, 거래량에 해당한다는 것을 알 수 있습니다. 이전 K-라인의 종가를 구하려면 마지막에 "."과 필요한 값을 추가하면 됩니다. 아래 그림의 8~10번째 줄을 참조하세요.

그림 3-29 배열 참조
왜 시각적 프로그래밍 언어를 사용하나요?
위의 개념을 바탕으로 먼저 Java를 사용하여 아래에 표시된 것처럼 "hello, world"를 출력하는 프로그램을 작성하여 전통적인 프로그래밍을 경험해 보겠습니다.
그림 3-30
"hello world!" 문자열만 출력하는 프로그램은 5줄의 코드만 필요합니다. 초보자 대부분은 영어 단어 "hello, world"만 괄호 안에 알고 있고 나머지는 어디서부터 시작해야 할지 전혀 모른다고 생각합니다. 그러므로 당황하기보다는 시각적 프로그래밍으로 시작하는 것이 더 나은 선택입니다.
시각적 프로그래밍이란 무엇인가요?
시각적 프로그래밍은 오랜 역사를 가지고 있으며 새로운 것이 아닙니다. 다양한 제어 모듈을 갖춘 이 "보이는 대로 얻는다" 프로그래밍 컨셉은 드래그 앤 드롭만으로 코드 로직을 구축하고 거래 전략 설계를 완료할 수 있습니다. 이 프로세스는 빌딩 블록과 매우 유사합니다.
그림 3-31
위에 표시된 것처럼, Blockly 시각적 프로그래밍에서는 단 한 줄의 코드만으로 동일한 프로그램을 완성할 수 있습니다. 이를 통해 프로그래밍에 대한 문턱이 크게 낮아지고, 특히 프로그래밍에 대한 지식이 없는 트레이더에게는 매우 좋은 운영 경험이 됩니다.
시각적 프로그래밍 언어의 특징은 무엇입니까?
Blockly는 프로그래밍 장난감이 아니라 정직한 편집기이며, 편집기로 위장한 운영 체제가 아닙니다. 변수, 함수, 배열, 쉽게 확장 및 사용자 정의 가능한 블록과 같은 프로그래밍의 많은 기본 요소를 지원합니다. 복잡한 프로그래밍 작업을 완료하는 데 사용할 수 있습니다. 이 디자인은 유닉스 철학인 '한 가지 일만 하라'와 매우 일맥상통합니다.
양적 시각적 프로그래밍의 발명자는 구글이 출시한 Blockly 시각화 도구를 통해서도 실현되었습니다. 이 디자인은 MIT에서 출시한 스크래치와 비슷한데, 정말로 임계값이 없습니다(아래에 표시).

그림 3-32
Inventor Quant의 시각적 프로그래밍 인터페이스에는 일반적으로 사용되는 수백 개의 거래 모듈이 내장되어 있습니다. 앞으로 거래자의 새로운 아이디어와 새로운 애플리케이션을 지원하기 위해 더 많은 거래 모듈이 추가될 것입니다. 이러한 모듈은 개발자가 공동으로 개발하고 유지 관리합니다.
구문은 간단하지만 성능은 저하되지 않습니다. 이는 대부분의 간단한 양적 거래 전략의 개발을 거의 충족할 수 있습니다. 기능성과 속도 면에서는 Python, JavaScript 등 기존 프로그래밍 언어보다 뒤지지 않습니다. 앞으로는 논리적으로 복잡한 금융 애플리케이션을 지원하게 될 것입니다.
사용 방법

그림 3-33
Hello, world 프로그램을 작성하세요

그림 3-34
"hello, world"를 실행하고 인쇄합니다.

그림 3-35
요약하다
위에서 우리는 완전한 시각화 전략으로 시작했고, 그다음 시각화 언어의 소개와 특징을 소개했고, 마지막으로 Inventor Quant 도구에서 시각화 언어를 사용하는 방법을 소개하고 "hello world" 예제를 작성했습니다. 그러나 양적 거래에 대한 소개로서 시각적 프로그래밍은 좋은 발판이지만 현재 Inventor Quantitative Tool에서 제한된 API 인터페이스만 열려 있다는 점을 모든 사람에게 상기시켜야 합니다. 양적 거래의 경우 전략의 논리를 정리하는 데 도움이 되는 보조 도구로 사용하는 것이 가장 좋습니다.
다음 섹션 미리보기
비주얼 프로그래밍의 기본과 고급 프로그래밍 언어 사이에는 차이가 없으며, 어떤 측면은 보편적이기도 합니다. 비주얼 프로그래밍을 배우면 고급 프로그래밍을 배우는 데 한 걸음 더 가까워질 것입니다. 다음 섹션에서는 시각적 프로그래밍의 고급 학습에 대해 알아보겠습니다. 여기에는 Inventor Quantitative Tool에서 일반적으로 사용되는 양적 거래 모듈을 시각적 언어로 작성하는 방법과 완전한 일중 거래 전략을 개발하는 방법이 포함됩니다.
숙제
- Inventor Quant 시각적 프로그래밍 인터페이스에서 API를 사용하고 그 의미를 이해합니다.
- 시각적 언어를 사용하여 최신 개장 가격을 얻고 이를 로그에 출력합니다.
3.5 시각적 언어를 사용하여 전략을 구현하는 방법
요약
이전 글에서는 시각적 프로그래밍 언어의 소개와 특징, 'hello world' 예제, 발명가의 양적 거래 도구에서의 전략 작성에 대해 알아보았고, 거래 전략을 구현하기 위한 전제 조건을 설명했습니다. 이 글에서는 이전 글의 내용을 이어가며 일반적으로 사용되는 전략 모듈과 기술 지표부터 시작해 전략적 논리에 이르기까지 모든 사람이 일일 거래 전략을 단계별로 완벽하게 실현할 수 있도록 돕겠습니다.
정책 모듈
위상 증가
단계적 증가는 현재 K-라인의 종가와 이전 N기간의 종가의 차이의 백분율을 계산하여 계산합니다. 예를 들어, 마지막 10개 K-라인 기간의 증가를 계산하려면 코드를 다음과 같이 작성할 수 있습니다.

그림 3-36
위의 코드에서, 우리는 컴퓨터가 실행되는 방식이 완전한 논리적 루프를 필요로 한다는 것을 알 수 있습니다. 예를 들어, 마지막 10개 K-라인 기간의 성장률을 계산하려면 다음 단계로 나누어야 합니다.
첫째, 컴퓨터는 당신이 어떤 제품을 거래하고 싶어하는지 명확히 알아야 합니다. 예를 들어, 위의 예는 메탄올이므로 계약 코드를 "MA888"로 설정합니다. 계약코드를 설정한 후, 계약의 K-라인 데이터를 얻을 수 있습니다.
K-라인 데이터를 이용하면 이러한 K-라인 데이터로부터 모든 K-라인의 자세한 데이터를 얻을 수 있습니다.
주기적 증가를 계산하려면 먼저 두 개의 K-라인의 종가를 구해야 합니다. 예를 들어, 이전 K-라인의 종가와 그 전 11번째 K-라인의 종가입니다.
마지막으로 이 두 K-라인의 종가를 기준으로 단계적 증가 비율을 계산합니다. 다음 전략은 모두 이러한 논리 루프와 조건 속성의 특성을 가지고 있습니다. 이 논리를 이해하면 시각적 프로그래밍이 훨씬 쉬워질 것입니다.
대량 거래량 상승
대량의 거래량 상승은 가격 상승과 거래량의 급격한 증가로 이해될 수 있습니다. 예를 들어, K-라인의 종가가 이전 10개 K-라인의 종가의 1.5배인 경우, 10일 동안 50% 증가했다는 의미입니다. 거래량은 지난 10개 K-라인 평균의 5배를 넘습니다. 다음과 같은 코드로 작성할 수 있습니다.

그림 3-37
갭
갭은 두 개의 K-라인의 최고가와 최저가가 연결되지 않은 상황입니다. 두 개의 K-라인으로 구성되어 있습니다. 갭은 미래의 지지와 압박 지점에 대한 기준 가격입니다. 갭이 발생하면 원래 갭 방향으로 추세가 가속화되기 시작했다고 가정할 수 있습니다. 이는 코드로 작성할 수 있습니다:

그림 3-38
일반적인 기술 지표
EMA 이동평균
통계적 관점에서 이동 평균이란 일일 가격의 산술 평균이며, 추세를 보이는 가격 궤적을 말합니다. 이동평균 시스템은 대부분의 분석가가 일반적으로 사용하는 기술 도구입니다. 기술적 관점에서 볼 때, 기술 분석가의 심리적 가격과 매수 및 매도 의사 결정 요인에 영향을 미치는 요소입니다. 기술 분석가에게 좋은 참고 도구입니다. 발명가의 정량적 도구는 다음 그림에서 볼 수 있듯이 다양한 유형의 이동평균을 지원합니다.

그림 3-39
MACD 지표
MACD 지표는 빠른(단기) 이동평균선과 느린(장기) 이동평균선, 그리고 이들의 수렴 및 분리 부호를 사용하고 이중 평활화 연산을 수행합니다. 이동평균의 원리를 바탕으로 개발된 MACD는 이동평균의 허위 신호를 자주 내보내는 단점을 제거하고 이동평균의 효과를 그대로 유지했습니다. 따라서 MACD 지표는 이동평균 추세, 안정성, 안정성의 특성을 가지고 있습니다. 주식 매수매도 시점을 판단하고 주가의 상승과 하락을 예측하는 데 사용되는 기술 분석 지표입니다. 계산 방법은 다음과 같습니다.

그림 3-40
KDJ 지표
KDJ 지표는 모멘텀 개념, 강점 및 약점 지표, 이동 평균의 장점을 결합한 지표로, 주가가 정상 가격 범위에서 벗어난 정도를 측정하는 데 사용됩니다. 종가만 고려하는 것이 아니라 최근 최고가와 최저가도 함께 고려하는데, 이를 통해 종가만 고려하고 실제 변동성을 무시하는 것의 약점을 피할 수 있습니다. 계산 방법은 다음과 같습니다.

그림 3-41
전략 쓰기
워렌 버핏의 멘토인 벤저민 그레이엄은 그의 책 "지능적인 투자자"에서 주식과 채권 간의 동적 균형 거래 모델을 언급한 적이 있습니다.
이 거래 모델은 매우 간단합니다.
투자금의 50%를 주식 펀드에 투자하고, 나머지 50%를 채권 펀드에 투자하세요. 즉, 주식과 채권이 각각 절반을 차지합니다.
일정 간격으로 또는 시장 변화에 따라 자산을 재조정하여 주식 자산과 채권 자산의 비율을 최초 1:1로 회복합니다. 이는 언제 매수하고 매도해야 하는지, 얼마를 매수하고 매도해야 하는지를 포함한 전략의 전체적인 논리입니다. 아주 간단하죠!
이 방법에서 채권 펀드의 변동성은 실제로 매우 작아 주식의 변동성보다 훨씬 낮기 때문에 채권을 여기서 "참조 앵커"로 사용합니다. 즉, 채권을 사용하여 주식이 너무 많이 상승했는지 측정합니다. 증가 아직도 너무 적습니다.
주가가 상승하면 주식의 시장가치는 채권의 시장가치보다 더 클 것입니다. 두 가지의 시장가치 비율이 설정된 임계값을 초과하면 전체 포지션이 재조정되고 주식이 매도되고 채권을 매수하여 주식과 채권의 시장가치 비율을 원래 1:1로 회복합니다.
반대로 주가가 하락하면 주식의 시장가치는 채권의 시장가치보다 낮아질 것입니다. 두 가지의 시장가치 비율이 설정된 임계값을 초과하면 전체 포지션을 주식 매수로 재조정합니다. 채권을 매도하여 주식과 채권의 시장 가치 비율을 원래의 1:1로 복원합니다.
이렇게 하면 동적으로 균형을 이루는 주식과 채권 사이의 비율이 주식 성장의 열매를 누릴 수 있고 자산의 변동률을 줄일 수 있습니다. 가치 투자의 선구자로서 그레이엄은 우리에게 좋은 아이디어를 제공합니다.
전략 논리
BTC의 현재 가치에 따라 계좌 잔액은 현금 5,000엔과 0.1BTC가 됩니다. 즉, 현금과 BTC 시장 가치의 초기 비율은 1:1입니다.
만약 BTC 가격이 6,000엔으로 상승하면, 즉 BTC의 시장 가격이 계좌 잔액보다 크고, 그 차이가 설정된 임계값을 초과하면 (6,000-5,000)/6,000/2 코인이 판매됩니다. 즉, BTC 가격이 상승했고 그 돈은 다시 교환될 수 있다는 의미입니다.
만약 BTC 가격이 4000엔으로 하락하는 경우, 즉 BTC의 시장 가격이 계좌 잔액보다 적고, 그 차이가 설정된 임계값을 초과하는 경우 (5000-4000)/4000/2 코인을 매수합니다. 즉, BTC가 하락했으므로 BTC를 다시 매수하세요.
이런 방식으로, BTC가 상승하든 하락하든 관계없이 계좌 잔액과 BTC의 시장 가치는 항상 동일하게 유지됩니다. BTC가 하락하면 일부를 사고, 가격이 오르면 일부를 매도하면 됩니다. 잔액과 마찬가지입니다.
구매 조건: 현재 포지션의 시장 가치에서 현재 이용 가능한 잔액을 뺀 금액이 마이너스 현재 이용 가능한 잔액의 5% 미만인 경우 매수 포지션을 엽니다.
판매 조건:현재 포지션의 시장가치에서 현재 이용 가능한 잔액을 뺀 금액이 현재 이용 가능한 잔액의 5%보다 클 경우, 포지션을 종료하고 매도합니다.
필수 조건
- 현재 시장
- 유동자산
- 동전의 총 시장 가치
- 자산 차이
전략 구축
시각적 저작 전략 1단계
우리는 거래 전략에 필요한 네 가지 전제 조건을 계산하여 각각의 변수에 할당합니다. 시각적 프로그래밍을 사용하면 코드 블록은 다음과 같습니다. 아래와 같이 표시됨
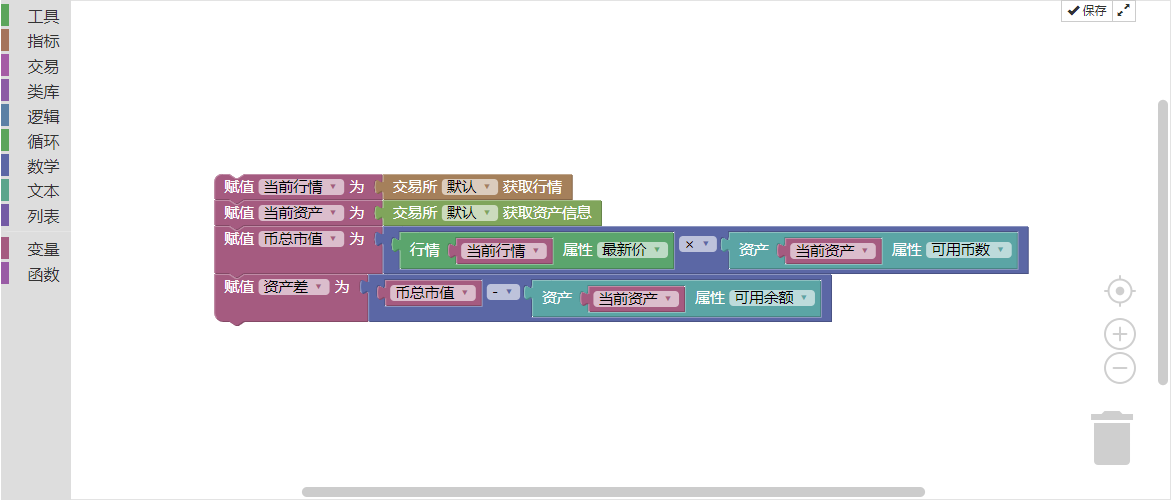
그림 3-42
주목할 점은 해당 화폐의 총 시장 가치는 현재 보유한 코인의 수의 총 시장 가치이며, 계산 방법은 현재 보유한 코인의 총 수에 현재 최신 가격을 곱하는 것입니다. 자산 차이가란 통화의 총 시장 가치에서 현재 사용 가능한 잔액을 뺀 값입니다.
시각적 저작 전략 2단계
전제 조건과 필요 조건이 할당된 후에는 거래 로직을 작성해야 합니다. 생각보다 복잡하지 않습니다. 이는 위의 전략 논리를 코드 블록 형태로 표현하는 것에 불과합니다.
즉, 자산 차이가 마이너스 잔액의 5% 미만이면 매수하고, 자산 차이가 마이너스 잔액의 5% 이상이면 매도합니다. 아래와 같이 표시됩니다.
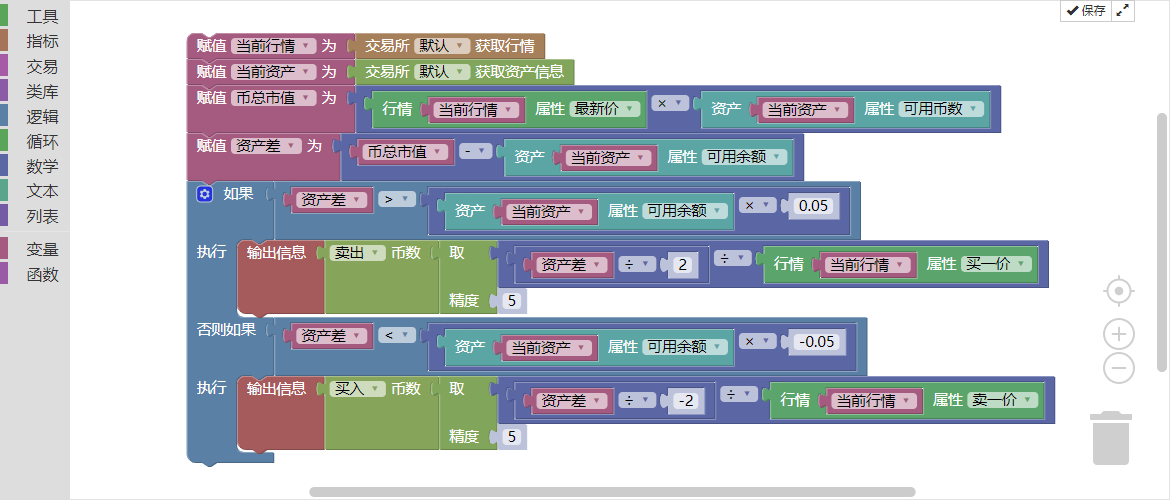
그림 3-43
전략은 전체적으로 작성된 것처럼 보이지만, 프로그램은 위에서 아래로 실행되고 실행 후 멈춘다는 것을 알아야 합니다. 하지만 우리의 거래 전략은 거래 조건을 한 번 실행하는 것이 아니라, 계속해서 반복적으로 실행하는 것입니다.
즉, 프로그램은 전략 조건이 충족되었는지 지속적으로 확인해야 합니다. 충족되었다면 매수 또는 매도를 실행하고, 그렇지 않으면 계속 확인합니다. 이때, 아래와 같이 또 다른 루프 문을 사용해야 합니다.
그림 3-44
전략 백테스팅
시각화 전략과 다른 프로그래밍 언어로 작성된 전략 사이에는 본질적인 차이가 없습니다. 또한 여러 기간과 정밀도 수준으로 과거 데이터 테스트를 지원합니다. 물론 국내 및 해외 상품 선물과 디지털 통화의 실시간 거래도 지원합니다. 해당 전략의 백테스트 정보는 다음과 같습니다.
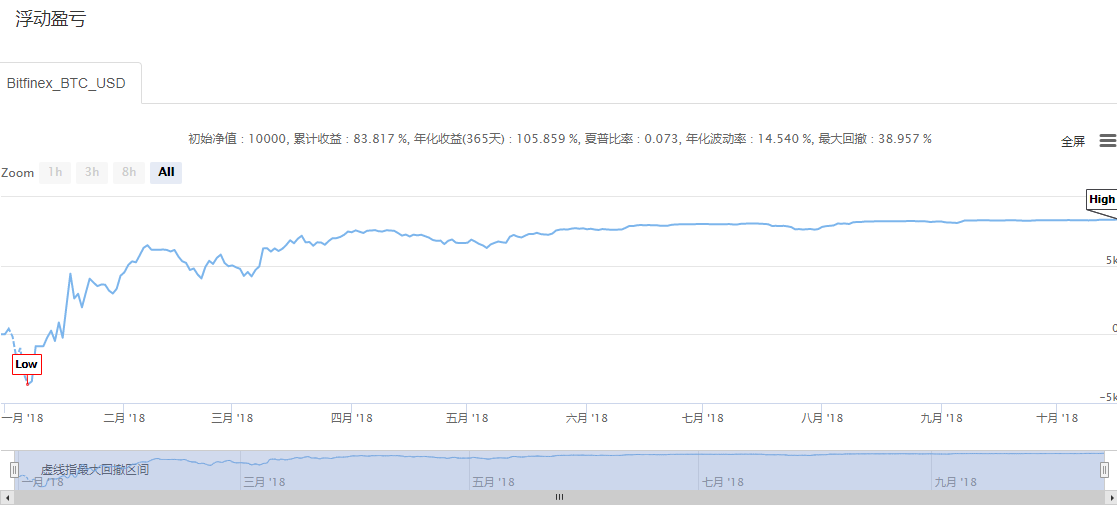
그림 3-45
이 시점에서 완전한 거래 전략이 완성되었습니다. 우리를 이용하고자 하는 사람들을 보호하기 위해, 이 전략은 Strategy Square에 공유되었으며, 직접 복사하여 연구할 수 있습니다.
결론
1만 시간의 규칙은 항상 존재하지만, 기본 지식이 없는 트레이더가 1만 시간을 들여 업계에 다시 진입하는 것은 불가능합니다. 따라서 사다리가 필요하며, 프로그래밍 기초가 전혀 없는 거래자의 경우 Inventor Quant의 시각적 프로그래밍은 빠르게 진입할 수 있는 사다리입니다.
시각적 프로그래밍을 사용하면 구문과 메서드 이름을 기억할 필요가 없으며, 간단히 함수 모듈을 탐색하여 원하는 것을 찾을 수 있습니다. 이는 양적 거래의 창시자의 원래 의도이기도 한데, 양적 거래 초보자들의 진입 장벽을 낮추고 양적 거래에 대한 관심을 높여 모두가 양적 거래자가 될 수 있도록 돕는 것입니다!
그러나 그렇다고 해서 양적 학습을 위한 디딤돌로 시각적 프로그래밍을 활용하는 데 전혀 문제가 있는 것은 아닙니다. 하지만 지나치게 복잡하고 정교한 거래 전략을 개발할 수 없다는 등의 한계도 있습니다. 하지만 이는 양적 거래의 첫 단계에는 영향을 미치지 않습니다!
다음 섹션 미리보기
양적 거래의 전문성 관점에서 볼 때, 마이어와 시각적 언어는 모두 양적 거래의 세계로 진입하기 위한 과도기적 언어일 뿐입니다. 이들의 언어적 특성은 양적 거래 전략 개발에 한계를 가지게 하며, 일부 복잡한 전략은 구현되기 어려울 가능성이 높습니다. 다음 섹션에서는 JavaScript를 알려드리겠습니다. JavaScript는 공식적인 고급 프로그래밍 언어이며, 고급 양적 거래로 발전할 수 있는 유일한 방법입니다.
숙제
- 시각적 언어를 사용하여 볼린저 밴드 지표를 구현해 보세요.
- 이 섹션의 거래 모듈을 사용하여 거래 전략을 완성해 보세요.
4장 주류 프로그래밍 언어로 거래 전략 구현
4.1 JavaScript 언어 빠른 소개
요약
미래의 양적 거래 스타가 되려면 단순한 언어만 배우는 것은 불가능합니다. 발명가의 정량적 도구인 Mai 언어와 시각화 언어를 사용하면 시작할 수는 있지만, 언어적 특성으로 인해 전략 개발에 많은 제한이 있습니다. 따라서 양적 거래에서 발판을 마련하려면 공식적인 프로그래밍 언어를 배워야 합니다.
왜 자바스크립트를 배워야 하나요?
JavaScript는 시각적 언어에 비해 성능과 실행 효율성이 뛰어납니다. 그리고 전략 개발 측면에서 JavaScript는 시각적 언어보다 훨씬 더 유연합니다. 예를 들어, 아르비트라지 전략을 개발하고 싶다면 시각적 언어는 모듈이 제한적이고 아르비트라지와 유사한 전략을 지원하지 않기 때문에 사용할 수 없지만 JavaScript는 쉽게 작업을 수행할 수 있습니다.
또한 JavaScript는 시각적 언어보다 간결하고 우아합니다. 예를 들어, 시각적 언어로 된 10줄의 코드는 JavaScript로 5줄로 작성할 수 있습니다. 어떤 면에서 시각적 언어는 단지 JavaScript의 텍스트 버전일 뿐이며, 코드의 실행과 논리는 JavaScript와 거의 동일합니다. 시각적 언어를 배우면 JavaScript를 배우는 것은 매우 쉬울 것입니다.
자바스크립트 소개
JavaScript는 공식적인 고급 프로그래밍 언어입니다. 프로그래밍을 배우기 위한 입문 언어로도 적합하며, 일상적인 개발을 위한 실무 언어로도 적합합니다. 현재 가장 유망하고 기대되는 컴퓨터 언어 중 하나이며, 브라우저 측에서는 여전히 흔들리지 않는 지배적 위치를 차지하고 있습니다. 웹페이지 개발로 유명하지만, 서버, PC, 모바일 기기 등 브라우저가 아닌 많은 환경에서도 사용됩니다. 물론, 양적 거래도 가능합니다!
완전한 전략
본 섹션의 핵심 지식을 빠르게 이해할 수 있도록, 발명가의 양자화 JavaScript 언어에 대한 간단한 소개를 하기 전에 먼저 본 섹션의 개념에 대한 사전 이해가 필요합니다. 가장 간단한 이중 이동 평균 전략을 예로 들어 보겠습니다.
롱 포지션 오픈: 현재 위치가 없고, 5기간 이동평균이 20기간 이동평균보다 큰 경우입니다.
숏포지션을 오픈하다: 현재 위치가 없고, 5일 이동평균선이 20일 이동평균선보다 낮은 경우입니다.
롱 포지션 마감:현재 롱 포지션을 보유하고 있고 5일 이동평균선이 20일 이동평균선보다 낮은 경우.
숏포지션 청산: 현재 단기 포지션을 보유하고 있고 5기간 이동평균이 20기간 이동평균보다 큰 경우.
JavaScript로 작성하면 다음과 같습니다.

그림 4-1
위 그림의 코드는 JavaScript로 작성된 완전한 양적 거래 전략입니다. 실시간으로 실행되고 자동으로 주문이 가능합니다. 코드의 양 측면에서 볼 때 이 언어는 시각적 언어보다 간단합니다. 전체 전략의 설계 과정은 다음과 같습니다: 시장 유형 설정, K-라인 데이터 수집, 포지션 정보 수집, 거래 로직 계산, 매수 및 매도 주문 실행.
아이덴티커
JavaScript의 모든 것(변수, 함수 이름, 연산자)은 대소문자를 구분합니다. 즉, 변수 이름 test와 변수 이름 Test는 서로 다른 변수입니다. 식별자(변수, 함수, 속성, 함수 매개변수 이름)의 첫 번째 문자는 문자, 밑줄(_), 달러 기호($) 및 다음 문자도 숫자가 될 수 있습니다(다음 그림 참조).

그림 4-2
참고
주석에는 한 줄 주석과 블록 수준 주석이 있습니다. 단일 줄 주석은 두 개의 슬래시로 시작하고 블록 주석은 슬래시와 별표(/)로 끝나고 별표와 슬래시(/) 아래와 같이 표시됩니다.

그림 4-3
진술
각 문장은 세미콜론으로 끝납니다. 필수는 아니지만, 절대 생략하지 않는 것이 좋습니다. 다음 그림과 같이 세미콜론을 추가하면 어떤 경우에는 코드 성능이 향상될 수 있습니다.

그림 4-4
변수
변수는 모든 유형의 데이터를 저장할 수 있습니다. 변수를 만들려면 var 연산자 뒤에 변수 이름을 사용합니다. 변수를 정의할 때 값을 설정할 수도 있습니다. 변수가 생성되면 아래에 표시된 것처럼 var 연산자를 사용하여 변수 값을 다시 설정할 필요가 없습니다.

그림 4-5
데이터
JavaScript에는 다음 그림과 같이 Undefined, Null, Boolean, Number, String 등 총 5가지 데이터 유형이 있습니다.

그림 4-6
Undefined는 "undefined"라는 특별한 값 하나만 가지며, 이는 아직 설정되지 않은 값을 나타냅니다. 예를 들어, 변수를 정의만 하고 값을 설정하지 않으면 변수의 값은 "undefined"가 됩니다.
Null은 "null"이라는 특별한 하나의 값만 가지며, 이는 비어 있는 값으로 설정된 값을 나타냅니다. 예를 들어, 먼저 변수를 생성한 다음 변수 값을 "null"로 설정하면 변수에서 반환되는 값은 "null"이 됩니다.
부울에는 "참"과 "거짓"이라는 두 가지 값이 있습니다. "참"은 참을 나타내고 "거짓"은 거짓을 나타냅니다. "true"와 "false"는 모두 소문자입니다.
숫자는 양수, 음수, 정수, 소수 등을 포함한 숫자의 유형입니다. 또한 "NaN"은 값이 반환되지 않는 상황을 특별히 나타내는 특수한 숫자입니다. 예를 들어 1을 0으로 나누면 "NaN"이 반환됩니다.
문자열은 중국어와 영어를 포함한 텍스트로 이해할 수 있으며, 작은따옴표나 큰따옴표를 이용해 문자열을 구성할 수 있습니다. 예를 들어: "fmz" 또는 "발명가 양자화".
대상
객체는 다양한 데이터를 저장하는 컨테이너로 생각할 수 있으며, 그 안의 속성과 값은 서로 대응합니다. 먼저 new 연산자를 통해 이 컨테이너를 만들 수 있습니다. 다음 그림과 같이 생성된 개체에 속성과 메서드를 추가할 수도 있습니다.

그림 4-7
집합
배열은 또한 다양한 데이터를 저장하는 컨테이너이지만 컨테이너의 요소는 왼쪽에서 오른쪽으로 순서대로 배열됩니다. 첫 번째 요소는 0, 두 번째 요소는 1, 이런 식으로 계속됩니다. 또한 JavaScript 배열은 아래와 같이 모든 데이터 유형을 저장할 수 있습니다.

그림 4-8
기능
JavaScript의 함수는 본질적으로 중학교에서 배운 함수와 동일합니다. 다음 그림에서 보듯이 함수의 계산을 통해 전달되는 것과 출력되는 것으로 생각할 수 있습니다.

그림 4-9
연산자
JavaScript에는 산술 연산자, 비교 연산자, 논리 연산자 등 다양한 연산자가 있습니다. 그 중 산술 연산자는 덧셈, 뺄셈, 곱셈, 나눗셈의 수학적 연산입니다. 비교 연산자는 두 값이 작거나 작은지 비교할 수 있습니다. 주요 논리 연산자는 논리적 AND, 논리적 OR, 논리적 NOT입니다. 다음 그림과 같이:

그림 4-10
"&&"는 논리적 AND이며 "그리고"를 의미합니다. "||"는 논리적 OR이며, "또는"을 의미합니다. "!"는 논리적 부정으로 "아니오"를 의미합니다.
&&는 모든 조건이 "참"일 때 최종 조건도 "참"이 됨을 의미합니다.
"||"는 모든 조건 중 하나라도 "참"이면 마지막 조건도 "참"이 됨을 의미합니다.
우선 순위
만약 100이 있다면*(10-1)/(10+5) 식의 경우, 프로그램은 어느 단계를 먼저 계산합니까? 중학교 수학에서는 ① 같은 수준의 연산이면 대체로 왼쪽에서 오른쪽으로 계산한다고 합니다. ② 덧셈과 뺄셈이 모두 있고, 곱셈과 나눗셈이 있는 경우, 곱셈과 나눗셈을 먼저 계산한 후, 덧셈과 뺄셈을 계산합니다. ③괄호가 있는 경우, 괄호 안의 내용을 먼저 계산합니다. ④ 연산 법칙에 맞는 경우 연산 법칙을 이용하여 계산을 간소화할 수 있다. JavaScript 언어의 우선순위도 아래와 같이 동일합니다.

그림 4-11
조건문
코드를 작성할 때 다양한 결정에 대해 다양한 작업을 수행해야 하는 경우가 많습니다. 이 작업을 완료하려면 코드에서 조건문을 사용할 수 있습니다. JavaScript에서는 다음과 같은 조건문을 사용할 수 있습니다.
if 문 - 이 문을 사용하면 지정된 조건이 참인 경우에만 코드를 실행할 수 있습니다.
if...else 문 - 조건이 참이면 코드를 실행하고, 조건이 거짓이면 다른 코드를 실행합니다.
if...else if....else 문 - 이 문을 사용하여 실행할 여러 코드 블록 중 하나를 선택합니다.
switch 문 - 이 문을 사용하여 실행할 여러 코드 블록 중 하나를 선택합니다.
if 문
이 문장은 지정된 조건이 참인 경우에만 코드를 실행합니다. 소문자를 사용하세요. 대문자(IF)를 사용하면 JavaScript 오류가 발생합니다! 다음 그림과 같이:

그림 4-12#
if...else 문
조건이 참이면 코드가 실행되고, 조건이 거짓이면 다음 그림과 같이 다른 코드가 실행됩니다.
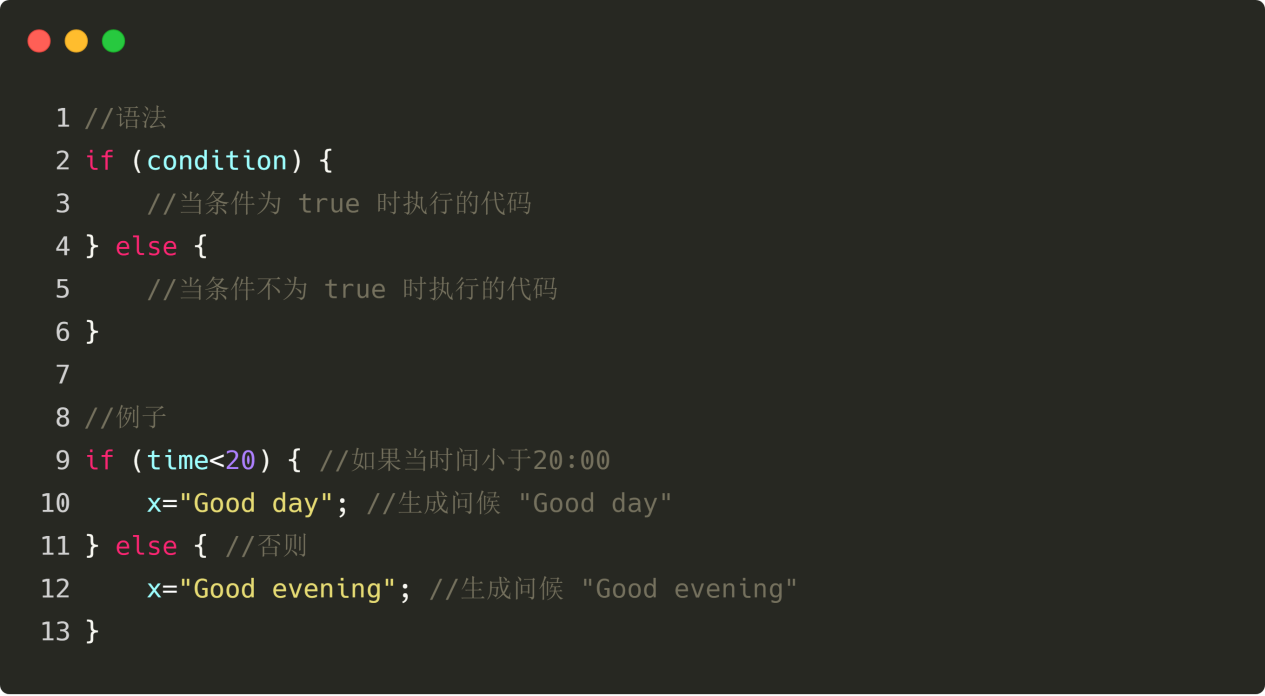
그림 4-13
for 루프
때때로 우리는 지난 며칠간의 K-라인 데이터를 얻어야 하며, K-라인 데이터의 위치에 따라 순서대로 K-라인 배열에서 얻어야 합니다. 그런 다음 다음 그림과 같이 for 루프를 사용하는 것이 매우 편리합니다.

그림 4-14
While 루프
우리 모두는 시장이 끊임없이 변화한다는 것을 알고 있습니다. 최신 K-라인 배열을 얻으려면 동일한 코드를 계속해서 반복해서 실행해야 합니다. 그런 다음 whilex 루프를 사용합니다. 지정된 조건이 참인 한 루프는 항상 최신 K-라인 배열을 가져올 수 있습니다.

그림 4-15
break 문과 continue 문
루프에는 전제 조건이 있습니다. 전제 조건이 "참"일 때만 루프가 반복적으로 무언가를 하기 시작하고, 전제 조건이 "거짓"일 때까지 루프는 끝나지 않습니다. 그러나 break 문은 루프 실행 중에 루프에서 즉시 빠져나올 수 있고, continue 문은 특정 루프를 중단하고 다음 루프를 계속할 수 있습니다. 다음 그림과 같이:
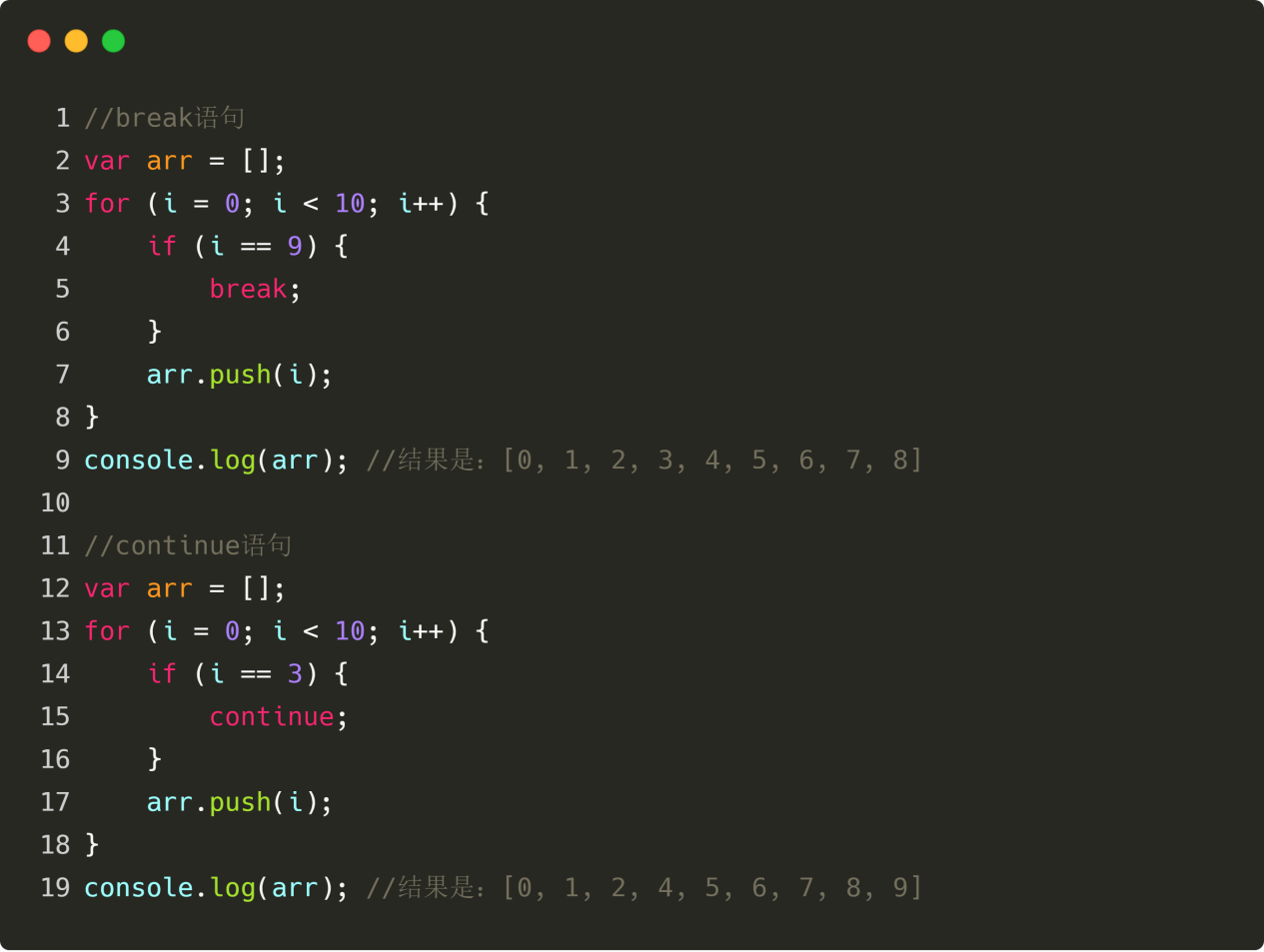
그림 4-16
반환문
return 문은 함수 실행을 종료하고 함수의 값을 반환합니다. return 문은 함수 본문에만 나타날 수 있습니다. 코드의 다른 곳에 나타나면 구문 오류가 발생합니다!

그림 4-17
CTA 전략 프레임워크
Inventor Quantitative Tool에서 JavaScript로 전략을 작성하는 것은 매우 편리합니다. 공식에는 다음 그림과 같이 표준 전략 프레임워크 세트가 내장되어 있습니다.

그림 4-18
위의 코드에서 볼 수 있듯이, 이것은 표준 전략 프레임워크입니다. 변경할 수 있는 "상품 선물 상품 코드"를 제외하고, 다른 모든 것은 고정된 형식입니다. 이 프레임워크를 사용하여 전략을 작성하는 가장 큰 장점은 전략 로직만 작성하면 된다는 것입니다. 시장 인수, 주문 처리 등과 같은 다른 문제는 모두 프레임워크에서 처리합니다. 이를 통해 전략 개발에 집중할 수 있습니다.
요약하다
위의 내용은 JavaScript 언어에 대한 간단한 소개입니다. 이를 배우고 나면 양적 거래 전략을 프로그래밍할 수 있습니다. 더욱 복잡한 전략을 작성해야 하는 경우 Inventor Quantitative Tool의 JavaScript 언어 API 문서를 참조할 수 있습니다.
다음 섹션 미리보기
데이 트레이딩도 트레이딩 모델입니다. 이 방법은 포지션을 밤새도록 유지하지 않으므로 시장 변동성 위험이 낮습니다. 불리한 시장 상황이 발생하면 적절한 시기에 조정할 수 있습니다. 이 섹션에서는 JavaScript 언어를 배우고, 다음 섹션에서는 실행 가능한 일일 양적 거래 전략을 작성하는 방법을 보여드리겠습니다.
숙제
- Inventor Quantitative Tool에서 JavaScript 언어를 사용하여 과거 K-라인 데이터를 얻어보세요.
- 이 섹션의 시작 부분에 전략 코드를 적어보고 주석을 추가해 보세요.
4.2 JavaScript 언어를 사용하여 전략 거래를 구현하는 방법
요약
이전 글에서는 자바스크립트 언어 소개, 기본 구문, CTA 전략 프레임워크 등의 측면에서 거래 전략을 구현하기 위한 전제 조건을 설명했습니다. 이 글에서는 이전 글의 내용을 이어가며 일반적으로 사용되는 전략 모듈과 기술 지표를 통해 실행 가능한 일일 양적 거래 전략을 단계별로 실현하도록 도와드리겠습니다.
전략 소개
볼린저 밴드는 볼린저 채널이라고도 불리며, 영어로는 BOLL로 약칭합니다. 이는 가장 흔히 사용되는 기술적 지표 중 하나이며 1980년대에 존 볼린저가 발명했습니다. 이론적으로 가격은 항상 가치 주변의 특정 범위 내에서 변동합니다. 이러한 이론적 기반을 바탕으로 볼린저 밴드는 "가격 채널"이라는 개념을 도입했습니다.
계산 방법은 통계 원리를 사용하여 먼저 특정 기간 동안의 가격의 "표준 편차"를 계산한 다음 이동 평균에서 표준 편차의 2배를 더하거나 빼서 가격의 "신뢰 구간"을 찾는 것입니다. 기본 형태는 3개의 트랙 라인(중간 트랙, 위쪽 트랙, 아래쪽 트랙)으로 구성된 스트립 채널입니다. 중간 트랙은 가격의 평균 비용이고, 위와 아래 트랙은 각각 가격의 압력선과 지지선을 나타냅니다.
표준편차의 개념을 도입함에 따라 볼린저 밴드의 폭은 최근의 가격 변동에 따라 동적으로 조정됩니다. 변동성이 작으면 볼린저 밴드는 좁아지고, 변동성이 크면 볼린저 밴드는 넓어집니다. BOLL 채널이 좁아지면 가격이 점차 평균으로 회귀하고 있다는 의미입니다. BOLL 채널이 좁은 것에서 넓은 것으로 바뀌면 시장이 변화하기 시작한다는 것을 의미합니다. 가격이 상단 트랙을 교차하면 매수력이 증가했음을 나타냅니다. 가격이 하단 트랙을 교차하면 매도력이 증가했음을 나타냅니다.
볼린저 밴드 지표 계산 방법
모든 기술 지표 중에서 볼린저 밴드의 계산 방법은 가장 복잡한 방법 중 하나로, 통계에 표준편차라는 개념을 도입하고 중간선(MB), 상단선(UP), 하단선(DN)을 계산하는 것을 포함합니다. 계산 방법은 다음과 같습니다.
중간 트랙 = N개 기간 동안의 단순 이동 평균
상부 트랙 = 중간 트랙 + K × N 시간 기간의 표준 편차
하부 레일 = 중간 트랙 − K × N 시간 기간의 표준 편차

그림 4-19
전략 논리
볼린저 밴드를 사용하는 방법은 여러 가지가 있습니다. 단독으로 사용하거나 다른 지표와 함께 사용할 수 있습니다. 이 튜토리얼에서는 볼린저 밴드를 이용하는 가장 간단한 방법을 사용하겠습니다. 즉, 가격이 하단에서 상단까지 상단 트랙을 돌파할 때, 즉 상단 압력선을 돌파할 때 강세 추세가 강해지고 상승장세가 형성되어 매수 개시 신호가 생성된다고 생각합니다. 가격이 상단에서 하단까지 하단 트랙 아래로 떨어질 때, 즉 지지선 아래로 떨어질 때 약세 추세가 강해지고 하락 추세가 형성되어 매도 개시 신호가 생성된다고 생각합니다.

그림 4-20
매수 포지션을 개설한 후 가격이 볼린저 밴드의 중간 트랙으로 떨어지면 강세 추세가 약화되거나 약세 추세가 강해지고 있다고 판단하고, 매도-종료 신호가 생성됩니다. 매도 포지션을 개설한 후 가격이 볼린저 밴드의 중간 트랙으로 떨어지면 약세 추세가 약화되거나 강세 추세가 강해지고 있다고 판단하고, 매수-종료 신호가 생성됩니다.
거래 조건
롱 포지션 오픈:포지션이 없고, 종가가 상위 트랙보다 크고, 시간이 14:45가 아닌 경우
숏포지션을 오픈하다:포지션이 없고, 종가가 하위 트랙보다 낮고, 시간이 14:45가 아닌 경우
롱 포지션 마감:롱 주문을 보유하고 있고 종가가 중간 트랙보다 낮거나 시간이 14:45인 경우
숏포지션 청산:단기주문을 보유하고 있고 종가가 중간트랙보다 높거나 시간이 14:45인 경우
전략 코드 구현
전략을 실행하려면 먼저 어떤 데이터가 필요한지 고려해야 합니다. 어떤 API를 통해 얻을 수 있나요? 그러면 거래 로직을 어떻게 계산할까요? 마지막으로, 주문과 거래에는 어떤 방법이 사용되나요? 다음으로, 단계별로 구현해 보겠습니다.
1단계: CTA 전략 프레임워크 사용
소위 CTA 전략 프레임워크는 Inventor Quantitative에서 공식적으로 출시한 표준 프레임워크입니다. 이 프레임워크를 사용하면 양적 거래 전략을 개발하는 사소한 문제에 대해 걱정할 필요가 없으며 거래 로직을 프로그래밍하는 데 직접 집중할 수 있습니다. 예를 들어, 이 프레임워크를 사용하지 않을 경우 주문을 할 때 월별 이체, 주문 매수 및 매도 가격, 주문 취소 또는 주문이 실행되지 않을 경우의 후속 조치 등을 고려해야 합니다.

그림 4-21
위의 그림은 발명가의 정량적 도구를 활용한 CTA 전략 프레임워크입니다. 이것은 고정된 코드 형식이며, 모든 거래 로직 코드는 3번째 줄부터 작성됩니다. 사용 중에는 품종 코드(연한 노란색)를 제외하고 다른 변경 사항은 필요하지 않습니다.
위 그림의 상품코드는 "rb000/rb888"인데, 이는 신호데이터가 "rb000"을 사용하고, 거래데이터가 "rb888"을 사용하고, 월 전환이 자동으로 이루어짐을 의미합니다. 물론, "rb1910"과 같이 특정 제품 코드를 지정할 수도 있습니다. 이는 신호 데이터와 거래 데이터가 모두 "rb1910"을 사용한다는 것을 의미합니다.
FMZ에는 내장된 JavaScript 상품 선물 거래 라이브러리가 있습니다. 전략 편집 인터페이스에서 참조를 클릭하기만 하면 코드에서 사용할 수 있습니다.

2단계: 다양한 데이터 얻기
신중하게 생각해보세요, 어떤 데이터가 필요한가요? 전략적 거래 논리를 통해 다음과 같은 사실을 발견했습니다. 먼저 현재 포지션 상태를 파악해야 하고, 그런 다음 종가와 볼린저 밴드 지표의 상단, 중간, 하단 트랙 간의 관계를 비교해야 하며, 마지막으로 시장이 곧 마감되는지 여부를 판단해야 합니다. 그러면 이 데이터를 얻어 보겠습니다.
K선 데이터를 가져오기
첫 번째 단계는 K-라인 배열과 이전 K-라인의 종가를 구하는 것입니다. K-라인 배열이 있어야만 볼린저 밴드 지표를 계산할 수 있기 때문입니다. 코드에서는 다음과 같습니다.

그림 4-22
위 그림에서 보이는 바와 같이:
4번째 줄: 고정된 형식인 K-라인 배열을 가져옵니다.
5번째 줄: K-라인의 길이를 필터링합니다. Bollinger Band 지표를 계산하는 데 사용하는 매개변수가 20이기 때문입니다. K-라인이 20보다 작으면 Bollinger Band 지표를 계산할 수 없습니다. 따라서 여기서 K-라인의 길이를 필터링해야 합니다. K-라인이 20개 미만이면 바로 돌아와서 다음 K-라인을 계속 기다립니다.
6번째 줄: 구한 K-라인 배열에서 먼저 이전 K-라인의 객체를 구한 다음, 해당 객체에서 종가를 구합니다. 배열의 두 번째에서 마지막 요소를 가져옵니다. 이는 배열의 길이에서 2를 뺀 값입니다(r[r.length - 2]); K-line 배열의 요소는 모두 객체이며, 여기에는 시작 가격, 최고 가격, 최저 가격, 마감 가격, 거래량 및 시간이 포함됩니다. 마감 가격을 얻으려면 "."과 속성 이름을 끝에 추가하기만 하면 됩니다(r[r.length - 2].Close)。
K-라인 시간 데이터 가져오기
당일 전략을 사용하고 있기 때문에 시장이 마감되기 전에 포지션을 마감해야 하므로 현재 K-라인이 시장 마감가에 가까운지 확인해야 합니다. 그렇다면 포지션을 마감합니다. 그렇지 않으면 포지션을 열 수 있습니다. 코드는 다음과 같습니다.

그림 4-23
위 그림에서 보이는 바와 같이:
8번째 줄: 현재 K-라인의 타임스탬프 속성을 가져온 다음 시간 객체(new Date(timestamp))를 생성합니다.
9번째 줄: 시간 객체를 기준으로 시간과 분을 계산하고, K-라인의 시간이 14:45인지 확인합니다.
위치 데이터 가져오기
포지션 정보는 양적 거래 전략에서 매우 중요한 조건입니다. 거래 조건이 충족되면 포지션 상태와 포지션 수에 따라 주문을 할지 여부를 결정하는 것도 필요합니다. 예를 들어, 매수 포지션을 열기 위한 조건이 충족되었을 때, 포지션이 있는 경우 다시 주문을 낼 필요가 없고, 포지션이 없는 경우 주문을 낼 수 있습니다. 코드에서는 다음과 같습니다.
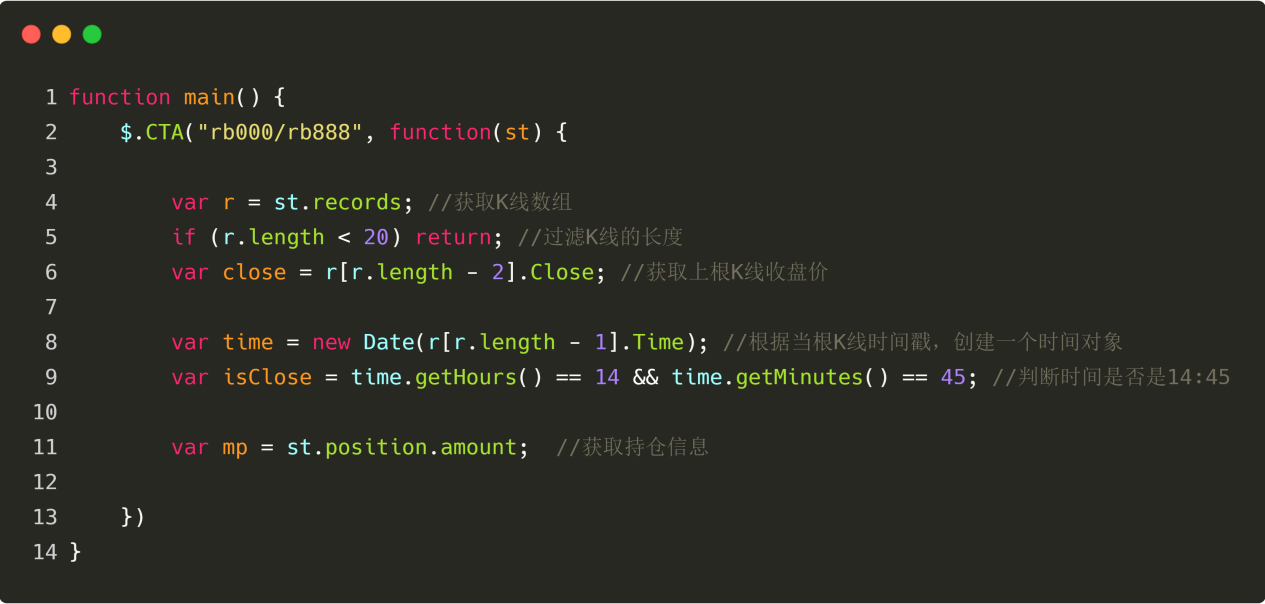
그림 4-24
위 그림에서 보이는 바와 같이:
11번째 줄: 현재 위치 상태를 가져옵니다. 주문이 여러 개 있는 경우 값은 1이고, 단기 주문이 있는 경우 값은 -1이며, 포지션이 없는 경우 값은 0입니다.
볼린저 밴드 데이터 가져오기
다음으로, 볼린저 밴드 지표의 상단, 중간, 하단 트랙 값을 계산해야 합니다. 그러면 먼저 볼린저 밴드 배열을 가져와야 하고, 그 다음 배열에서 상단, 중간, 하단 밴드의 값을 가져와야 합니다. Inventor Quantitative Tool에서 Bollinger Band 배열을 얻는 것은 매우 간단합니다. Bollinger Band API를 직접 호출할 수 있습니다. 어려운 부분은 Bollinger Band 배열이 2차원 배열이기 때문에 상단, 중간 및 하단 트랙의 값을 얻는 것입니다.
2차원 배열은 실제로 이해하기 매우 쉽습니다. 그것은 배열 안의 배열입니다. 따라서 획득 순서는 다음과 같습니다. 먼저 배열에서 지정된 배열을 가져온 다음 지정된 배열에서 지정된 요소를 가져옵니다. 다음 그림과 같습니다.

그림 4-25
아래 그림과 같이, 13~19번째 줄은 볼린저 밴드의 상단, 중간, 하단 레일의 값을 구하기 위한 코드를 사용하고 있습니다. 이 중, 13번째 줄은 발명자의 정량적 도구의 API를 직접 사용하여 볼린저 밴드 배열을 직접 구한다; 14번째 줄부터 16번째 줄은 2차원 배열에서 각각 상단 레일 배열, 중간 레일 배열, 하단 레일 배열을 먼저 구한다; 17번째 줄부터 19번째 줄은 상단 레일 배열, 중간 레일 배열, 하단 레일 배열로부터 이전 K-라인의 볼린저 밴드 상단 레일, 중간 레일, 하단 레일 값을 각각 구한다.
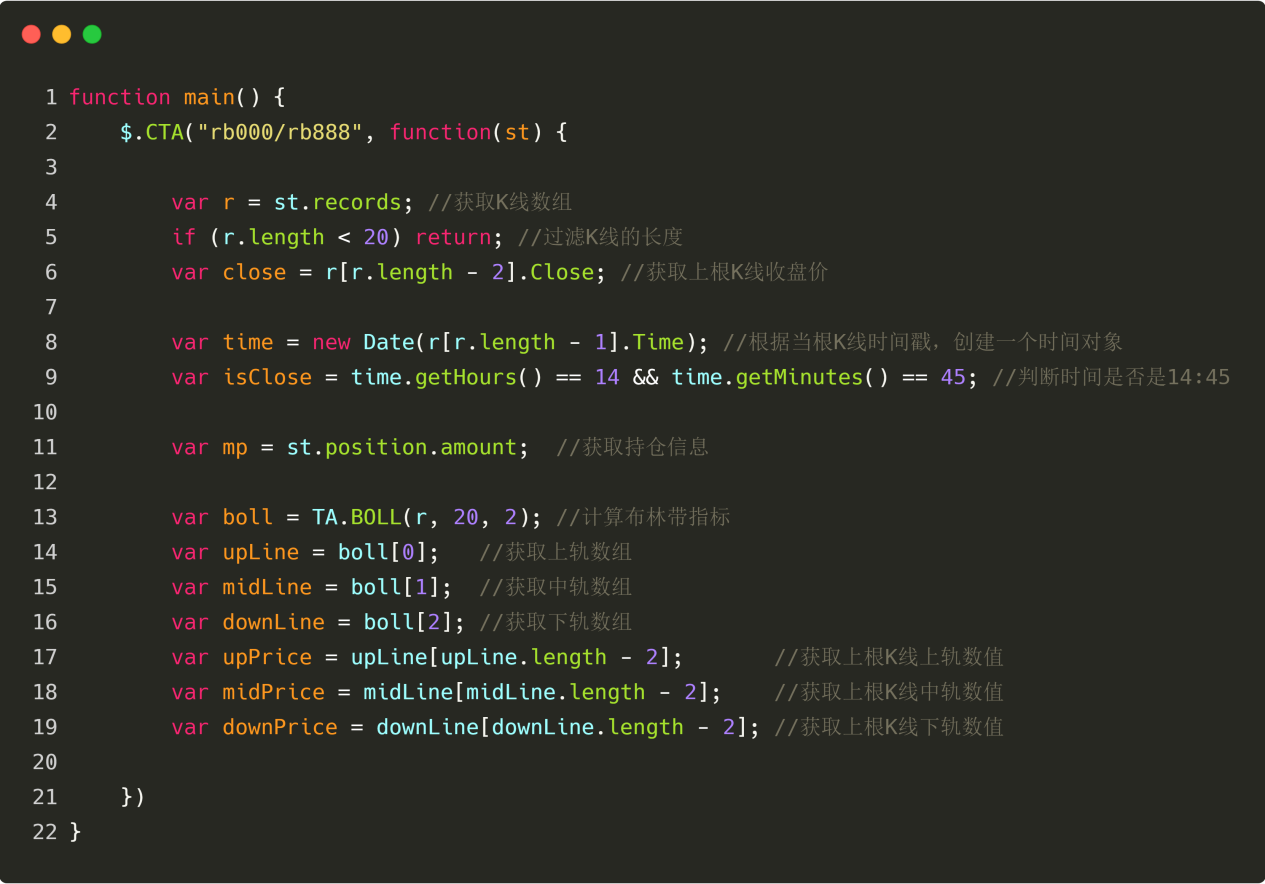
그림 4-26
3단계: 주문하기
위 데이터를 이용해서 거래 로직과 주문을 하기 위한 코드를 작성할 수 있습니다. 형식도 매우 간단합니다. 가장 일반적으로 사용되는 것은 "if 문"으로, 다음과 같이 말로 표현할 수 있습니다. 조건 1과 조건 2가 충족되면 주문을 합니다. 조건 3 또는 조건 4가 충족되면 주문을 합니다. 다음 그림과 같이:
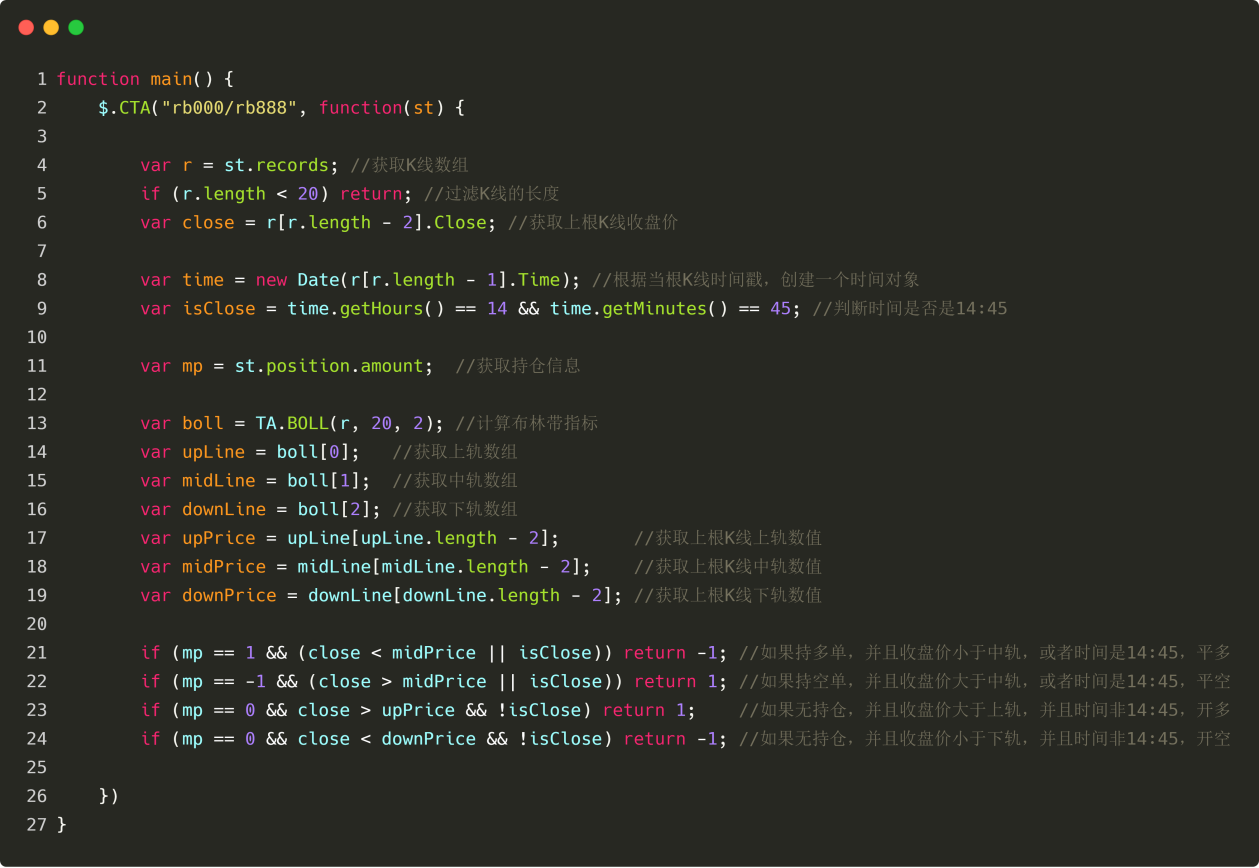
그림 4-27
위 그림에서 21~24번째 줄은 거래 로직과 주문 코드입니다. 위에서 아래로는 클로즈 롱, 클로즈 숏, 오픈 롱, 오픈 숏입니다.
롱 포지션(23번째 줄)을 여는 것을 예로 들면, 이것은 "if 문"입니다. 이 문장에서 한 줄의 코드만 실행되면 중괄호 "{}"를 생략할 수 있습니다. 이 문장은 다음과 같이 텍스트로 번역됩니다. 현재 포지션이 0이고, 종가가 상위 트랙보다 크고, K-라인 시간이 14:45가 아니면 "1을 반환합니다"
주의 깊은 사람들은 이 줄에 "return 1"과 "return -1"이 있다는 것을 발견할 수 있습니다. 이것은 고정된 형식입니다. 즉, 매수인 경우 "return 1"을 쓰고 매도인 경우 "return -1"을 씁니다. 롱 포지션을 오픈하거나 숏 포지션을 청산하는 것은 모두 매수이므로 "리턴 1"이라고 적고, 숏 포지션을 오픈하거나 롱 포지션을 청산하는 것은 모두 매도이므로 "리턴 -1"이라고 적습니다.
완전한 전략 코드
이 시점에서 완전한 전략 코드가 작성되었습니다. 거래 프레임워크, 거래 데이터, 거래 로직, 주문 배치 등을 별도로 작성하면 매우 간단하지 않을까요? 다음은 이 전략의 전체 코드입니다.
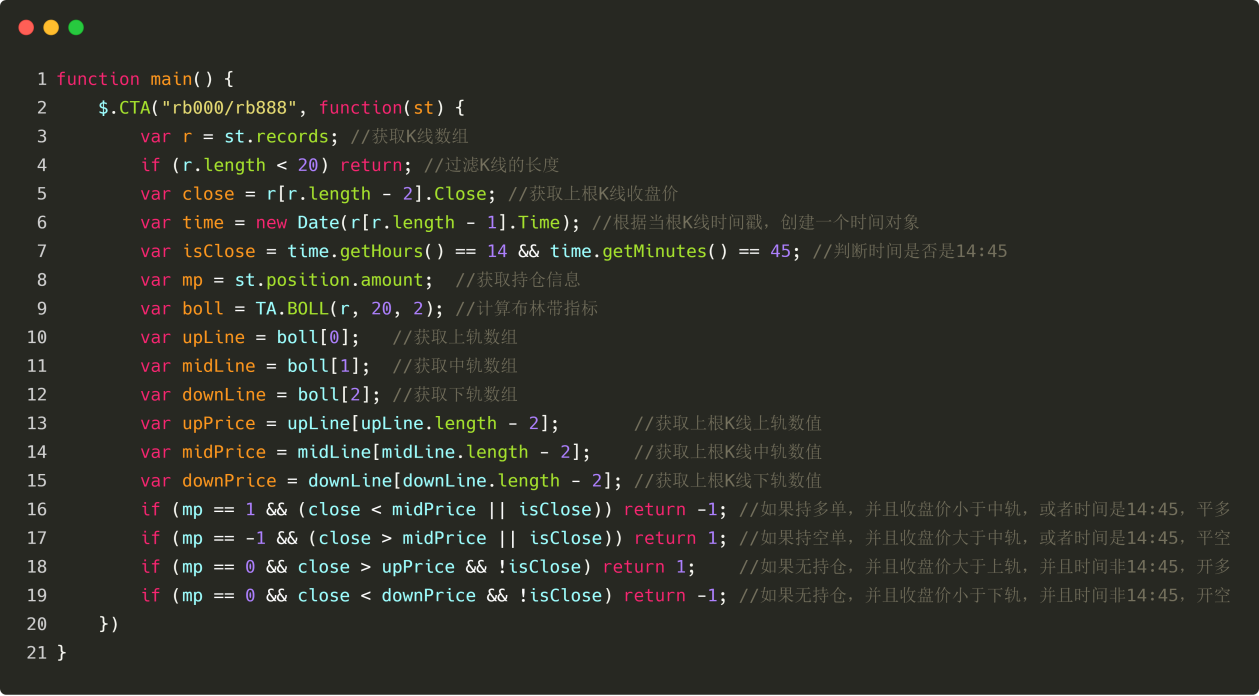
그림 4-28
주의해야 할 점이 두 가지 있습니다. 루트 K-라인 조건이 충족되면 다음 K-라인 주문이 배치되거나 이전 K-라인 조건이 충족되면 루트 K-라인 주문이 배치되도록 전략 로직을 작성해 보세요(반드시 그럴 필요는 없습니다). 이런 식으로 백테스트 결과는 실제 결과와 크게 다르지 않을 것입니다. 꼭 이렇게 쓸 필요는 없지만, 전략 논리가 올바른지 주의 깊게 살펴봐야 합니다. 일반적으로 포지션을 닫는 논리는 포지션을 여는 논리보다 먼저 작성해야 합니다. 이렇게 하는 목적은 전략 논리를 최대한 기대치와 일관되게 만드는 것입니다. 예를 들어, 전략 논리가 역방향 포지션과 일치하는 경우, 역방향 포지션의 규칙은 먼저 포지션을 청산한 다음 새로운 포지션을 여는 것입니다. 먼저 새로운 포지션을 개설한 후에 그것을 닫는 대신에요. 만약 닫는 논리를 여는 논리 바로 앞에 쓴다면 이 문제는 발생하지 않을 것이다.
요약하다
위에서 우리는 전략 소개, 볼린저 밴드 지표 계산 방법, 전략 논리, 매수 및 매도 조건, 전략 코드 구현 등을 포함하여 완전한 일일 양적 거래 전략을 개발하는 각 단계를 알아보았습니다. 이 전략 사례를 통해 발명가의 정량적 도구의 프로그래밍 방법에 익숙해질 수 있을 뿐만 아니라, 이 템플릿을 기반으로 한 다양한 전략에 적용할 수도 있습니다.
양적 트레이딩 전략은 주관적인 트레이딩 경험이나 시스템을 요약한 것에 불과합니다. 전략을 작성하기 전에 주관적인 트레이딩에서 사용한 경험이나 시스템을 적어두고, 이를 하나하나 코드로 변환하면 전략을 작성하는 것이 훨씬 쉬워질 것입니다. 한번 시도해 보세요!
다음 섹션 미리보기
양적 거래 전략 개발에서 프로그래밍 언어를 하나만 선택할 수 있다면 주저 없이 Python을 선택해야 합니다. 데이터 수집에서 전략 백테스팅, 거래에 이르기까지 Python은 전체 비즈니스 체인을 포괄했습니다. 금융 양적 투자 분야에서 중요한 위치를 차지하고 있습니다. 다음 과정에서는 Python 언어의 기본 지식을 배우게 됩니다.
숙제
- 이 섹션의 지식을 활용하여 이중 이동 평균 전략을 구현해 보세요.
- Inventor Quantitative Tool에서 JavaScript 언어를 사용하여 KDJ 지표 알고리즘을 구현해 보세요.
4.3 Python 언어 빠른 소개
요약
양적 거래 전략 개발에서 프로그래밍 언어를 하나만 선택할 수 있다면 주저 없이 Python을 선택해야 합니다. 데이터 수집에서 전략 백테스팅, 거래에 이르기까지 Python은 전체 비즈니스 체인을 포괄했습니다. 금융 양적 투자 분야에서 중요한 위치를 차지합니다. 이 과정에서는 Python 언어의 기본 지식을 배우게 됩니다.
왜 이렇게 많은 프로그래밍 언어를 배워야 할까요?
지난 강좌를 돌이켜보면, 우리는 모두 다음의 것들을 배웠습니다: Mai 언어, 시각 언어, JavaScript 언어, 그리고 이 섹션에서 배울 Python 언어. 일부 친구들은 질문을 할 수도 있습니다. 저는 양적 거래를 배우기 위해 여기 왔는데, 왜 이렇게 많은 프로그래밍 언어를 배워야 합니까?
사실, 각 프로그래밍 언어는 고유한 언어적 특성을 가지고 있으며, 좋은 언어와 나쁜 언어의 구별은 없습니다. 이는 귀하의 전략이 어느 프로그래밍 언어에 더 적합한지, 그리고 이 프로그래밍 언어가 귀하에게 적합한지에 따라 달라집니다. 그러니 직접 시도해 보지 않고는 알 수 없다는 말이 있습니다. 이것이 우리가 프로그래밍 언어에 대해 이야기하는 데 많은 공간을 할애한 이유입니다. 일을 잘하려면 먼저 도구를 날카롭게 다듬어야 합니다.
동시에, 우리는 모든 사람을 위한 양적 연구의 문을 열고 다양한 프로그래밍 언어에 대한 지식을 대중화하는 데 전념합니다. 양적 연구는 우리가 상상하는 것처럼 신비롭거나 손이 닿지 않는 것이 아닙니다. 저는 양적 연구가 미래에 대중화되고 일반 대중에게 접근 가능해질 것이라고 믿습니다.
양적 거래를 위해 Python을 선택하는 이유
양적 거래의 과정은 데이터 수집, 데이터 분석 및 계산, 데이터 처리 등에 불과합니다. 데이터 분석 측면에서 Python만큼 계산에 능숙하고 성능을 유지하는 언어는 없습니다. 특히 시계열 분석 데이터(K-line은 시계열 데이터)를 처리할 때 Python은 더 간단하고 편리하다는 장점이 있습니다. 게다가 다른 프로그래밍 언어와 비교했을 때, 파이썬은 더 간결하고 배우기 쉽습니다. 좋은 파이썬 프로그램을 읽는 것은 영어를 읽는 것과 같습니다.
파이썬을 선택해야 하는 5가지 이유
1. 양적 응용이 광범위합니다:
미국의 Quantopian과 중국의 Inventor Quant는 모두 Python 언어를 사용할 수 있습니다.
2. 배우기 쉬움:
Python의 디자인 철학은 사용자 중심적이며, 디버깅하기 쉬운 해석형 언어입니다.
3. 무료 및 오픈 소스:
사용 비용 없고, 오픈소스 코드 공유, 향상된 학습 및 사용 효율성.
4. 풍부한 라이브러리:
데이터 처리, 데이터 컴퓨팅, 시각화, 통계 분석, 기술 분석, 머신 러닝...
5. 응용 프로그램 인터페이스:
주요 플랫폼의 실시간 시장 정보를 기반으로 주문을 수집, 저장, 호출 및 발주하기 위한 인터페이스입니다.
완전한 전략
본 섹션의 핵심 지식을 빠르게 이해할 수 있도록, 발명가의 양자화 JavaScript 언어에 대한 간단한 소개를 하기 전에 먼저 본 섹션의 개념에 대한 사전 이해가 필요합니다. 가장 간단한 이중 이동 평균 전략을 예로 들어 보겠습니다.
롱 포지션 오픈: 현재 위치가 없고, 5기간 이동평균이 20기간 이동평균보다 큰 경우입니다.
숏포지션을 오픈하다: 현재 위치가 없고, 5일 이동평균선이 20일 이동평균선보다 낮은 경우입니다.
롱 포지션 마감:현재 롱 포지션을 보유하고 있고 5일 이동평균선이 20일 이동평균선보다 낮은 경우.
숏포지션 청산: 현재 단기 포지션을 보유하고 있고 5기간 이동평균이 20기간 이동평균보다 큰 경우.
Python으로 작성하면 다음과 같습니다.
그림 4-29
위 그림의 코드는 Python으로 작성된 완전한 양적 거래 전략입니다. 실시간으로 실행되고 자동으로 주문이 가능합니다. 코드 양 면에서 보면 Python은 JavaScript보다 많습니다. CTA 거래 프레임워크를 사용하지 않기 때문입니다.
그러나 전체 전략의 설계 과정은 거의 동일합니다. 즉, 시장 유형 설정, K-라인 데이터 수집, 포지션 정보 수집, 거래 로직 계산, 매수 및 매도 주문 실행입니다. 즉, 프로그래밍 문법은 다르지만 작성하는 전략논리는 동일하니, 다음으로는 파이썬의 기본 문법을 알아보도록 하겠습니다!
버전 선택
파이썬에는 두 가지 버전이 있는데, Python2와 Python3입니다. 파이썬은 이중 총과 같지만 한 번에 한 개의 총구만 사용하여 총알을 쏠 수 있지만 어느 것이 더 정확한지는 결코 알 수 없다는 농담이 있었습니다. 따라서 Python을 처음 사용하는 경우 Python 3을 직접 배우는 것이 좋습니다. Python 3은 최신 언어이며 Python 커뮤니티에서 유지 관리되고 있습니다. 저희 강의는 Python 3으로 진행됩니다.
아이덴티커
식별자는 test, Test, test10과 같은 변수의 이름입니다.데모 등 Python의 모든 것(변수, 함수 이름, 연산자)은 대소문자를 구분합니다. 즉, 변수 이름 test와 변수 이름 Test는 서로 다른 변수입니다. 식별자(변수, 함수, 속성, 함수 매개변수 이름)의 첫 번째 문자는 문자, 밑줄(), 뒤에 오는 문자는 다음 그림과 같이 숫자가 될 수도 있습니다.

그림 4-30
참고
주석은 코드 줄의 번역 또는 설명입니다. 규칙은 매우 간단하며 단일 줄 주석과 블록 수준 주석을 포함합니다. 단일 줄 주석은 파운드 기호(#)로 시작하고 블록 주석은 세 개의 작은 따옴표(''') 또는 세 개의 큰 따옴표(""")로 시작하여 세 개의 작은 따옴표(''') 또는 세 개의 큰 따옴표(""")로 끝납니다(다음 그림 참조).

그림 4-31
줄과 들여쓰기
파이썬의 가장 뚜렷한 특징은 중괄호 {}를 사용하지 않고도 들여쓰기를 사용하여 코드 블록을 나타낸다는 것입니다. 들여쓰기에 필요한 공백의 개수는 가변적이지만, 같은 코드 블록 내의 명령문은 들여쓰기에 필요한 공백의 개수가 동일해야 합니다. 아래에 표시된 대로, 이 경우 프로그램에서 오류가 보고됩니다. if 조건이 참이더라도 "True"는 출력되지 않습니다. Python은 코드를 실행하기 전에 코드 구문이 올바른지 자동으로 감지하기 때문입니다. 코드 형식이 올바르지 않으면 프로그램이 실행되지 않습니다. 그 이유는 5번째 줄의 코드에 통일된 코드 들여쓰기 형식이 없기 때문입니다. 4칸 들여쓰기는 Python의 고정된 형식이며, 모든 사람이 이에 익숙해야 합니다.

그림 4-32
변수
변수는 모든 유형의 데이터를 저장할 수 있습니다. 변수의 이름을 쓰는 것만으로도 변수가 생성됩니다. 그러나 변수를 생성할 때는 변수의 값을 동시에 설정해야 합니다. 그렇지 않으면 프로그램에서 오류가 보고됩니다. 등호(=) 연산자의 왼쪽은 변수 이름이고, 등호(=) 연산자의 오른쪽은 변수에 저장된 값입니다. 아래 그림과 같이 name2는 변수 이름이고 "inventor quantification"은 변수의 값입니다. name2에 새 값을 설정하지 않으면 name2의 값은 항상 "발명자 수량화"가 됩니다.

그림 4-33
데이터
파이썬에는 6가지 데이터 유형이 있는데, 그 중 3가지는 변경 불가능하고 3가지는 변경 가능합니다. 이름에서 알 수 있듯이, 변경 불가능한 데이터가 생성되면 해당 값은 변경할 수 없고 메모리의 주소는 고유합니다. 변경 가능한 데이터는 메모리의 주소에 대한 참조이며, 값이 변경되어도 메모리 주소는 변경되지 않습니다.
변경 불가능한 데이터(3): 숫자, 문자열, 튜플
변경 가능한 데이터(3): List, Dictionary, Set.

그림 4-34
숫자
Python의 숫자형 자료형은 int(정수), float(부동 소수점), bool(부울), complex(복소수)를 지원합니다. 내장된 type() 함수는 변수가 참조하는 객체의 유형을 쿼리하는 데 사용할 수 있습니다. 아래와 같이 표시됩니다.

그림 4-35
연산자
대부분의 언어와 마찬가지로 Python의 수학은 간단합니다. 산술 연산자, 비교 연산자, 논리 연산자 등 모든 연산자는 우리가 학교에서 배운 것과 같습니다. 그 중 산술 연산자는 덧셈, 뺄셈, 곱셈, 나눗셈의 수학적 연산입니다. 비교 연산자는 두 값이 작거나 작은지 비교할 수 있습니다. 주요 논리 연산자는 논리적 AND, 논리적 OR, 논리적 NOT입니다. [트레이딩 전략에서 일반적으로 사용되는 문자열에 대해 간단히 설명해 주시겠습니까?] 예를 들어, 우리의 트레이딩 전략에서 가장 일반적으로 사용되는 문자열은 "rb1910", "MA1910"과 같은 제품 코드입니다.

그림 4-36
"and"는 논리적 AND, 즉 "and"를 뜻한다는 점에 유의하세요. "or"는 논리적 OR이며, "둘 중 하나"를 의미합니다. "!"는 논리적 부정으로 "아니오"를 의미합니다.
"그리고"는 모든 조건이 "참"일 때 최종 조건도 "참"이라는 것을 의미합니다.
"또는"은 모든 조건 중 하나라도 "참"이면 마지막 조건도 "참"이 됨을 의미합니다.
우선 순위
만약 100이 있다면*(10-1)/(10+5) 식의 경우, 프로그램은 어느 단계를 먼저 계산합니까? 중학교 수학에서는 ① 같은 수준의 연산이면 대체로 왼쪽에서 오른쪽으로 계산한다고 합니다. ② 덧셈과 뺄셈이 모두 있고, 곱셈과 나눗셈이 있는 경우, 곱셈과 나눗셈을 먼저 계산한 후, 덧셈과 뺄셈을 계산합니다. ③괄호가 있는 경우, 괄호 안의 내용을 먼저 계산합니다. ④ 연산 법칙에 맞는 경우 연산 법칙을 이용하여 계산을 간소화할 수 있다. Mai 언어의 우선순위는 아래와 같습니다.

그림 4-37
부울
부울은 참 또는 거짓을 나타내며 일반적으로 조건 판단과 반복문에서 사용됩니다. Python은 참과 거짓을 나타내기 위해 두 개의 상수 "True"와 "False"를 정의합니다. 사실, 모든 객체는 부울 유형으로 변환될 수 있으며 다음 그림에서 보듯이 조건부 판단에 직접 사용될 수도 있습니다.

그림 4-38
문자열
문자열은 텍스트입니다. 문자열은 종종 "if1905"와 같이 제품 코드를 설정할 때 사용됩니다. 파이썬의 문자열은 작은 따옴표 ' 또는 큰 따옴표 "로 묶습니다. 더하기 기호 +는 문자열 연결 연산자입니다. 아래와 같이 인덱스 값에 따라 문자열에서 문자를 가져올 수 있습니다.

그림 4-39
목록
리스트는 파이썬에서 가장 자주 사용되는 데이터 유형입니다. 리스트를 컨테이너로 생각할 수 있지만 컨테이너의 요소는 왼쪽에서 오른쪽으로 순서대로 정렬됩니다. 첫 번째 요소는 0, 두 번째 요소는 1, 이런 식으로 계속됩니다. 또한, Python 리스트는 아래와 같이 모든 데이터 유형을 저장할 수 있습니다.

그림 4-40
기능
파이썬의 함수는 본질적으로 중학교에서 배운 함수와 같습니다. 다음 그림에서 보듯이 함수의 계산을 통해 전달되는 것과 출력되는 것으로 생각할 수 있습니다.

그림 4-41
if 문장
'만약 오늘 비가 온다면, 나는 우산을 쓸 것이다'와 같은 문장은 우리 삶에서 자주 등장합니다. 즉, 해당 문장은 지정된 조건이 참일 때만 코드를 실행합니다. 주의하세요, 코드의 들여쓰기 형식에 주의하세요. 그렇지 않으면 Python 오류가 발생합니다! 다음 그림과 같이:

그림 4-42
if...else 문
If...else 문장도 일반적으로 사용되는 문장입니다. 예를 들어, 오늘 비가 오면 우산을 쓸 거고, 비가 오지 않으면 우산을 쓰지 않을 거예요. else 문은 if 문의 확장입니다. 즉, else 뒤에 오는 코드는 지정된 조건이 False일 때만 실행됩니다. 다음 그림과 같이:

그림 4-43
elif 성명
Python은 switch 문을 지원하지 않으므로, Python은 elif 문만 사용하여 여러 개의 조건 판단을 구현할 수 있습니다. 예를 들어, 긍정적인 선이면 강세 예측을 하고, 그렇지 않고 부정적인 선이면 약세 예측을 하고, 그렇지 않으면 기다려 보죠. 다음 그림과 같이:

그림 4-44
for 루프
때때로 우리는 지난 며칠간의 K-라인 데이터를 얻어야 하며, K-라인 데이터의 위치에 따라 순서대로 K-라인 배열에서 얻어야 합니다. 그런 다음 다음 그림과 같이 for 루프를 사용하는 것이 매우 편리합니다.

그림 4-45
While 루프
우리 모두는 시장이 끊임없이 변화한다는 것을 알고 있습니다. 최신 K-라인 배열을 얻으려면 동일한 코드를 계속해서 반복해서 실행해야 합니다. 그런 다음 whilex 루프를 사용합니다. 지정된 조건이 참인 한 루프는 항상 최신 K-라인 배열을 가져올 수 있습니다.

그림 4-46
break 문과 continue 문
루프에는 전제 조건이 있습니다. 전제 조건이 "참"일 때만 루프가 반복적으로 무언가를 하기 시작하고, 전제 조건이 "거짓"일 때까지 루프는 끝나지 않습니다. 그러나 break 문은 루프 실행 중에 루프에서 즉시 빠져나올 수 있고, continue 문은 특정 루프를 중단하고 다음 루프를 계속할 수 있습니다. 다음 그림과 같이:

그림 4-47
반환문
return 문은 함수 실행을 종료하고 함수의 값을 반환합니다. return 문은 함수 본문에만 나타날 수 있습니다. 코드의 다른 곳에 나타나면 구문 오류가 발생합니다!

그림 4-48
전략 프레임워크
전략 아키텍처는 전략의 고정된 형식으로 이해할 수 있습니다. 발명가의 양적 도구는 폴링 모드를 채택합니다. 다음은 고전적인 상품 선물 전략 아키텍처입니다.
4~7번째 줄은 전체 프로그램의 주요 진입 함수입니다. 즉, 컴퓨터는 4번째 줄부터 코드 실행을 시작합니다. 그런 다음 5번째 줄을 직접 실행하고 무한 루프에 들어갑니다. 그런 다음 전략 논리 함수(onTick)와 sleep 함수(Sleep)가 무한 루프에서 실행됩니다. onTick 함수는 1번째 줄의 코드이고, 전략 논리는 2번째 줄에 쓸 수 있습니다. 루프에서 프로그램의 실행 속도가 매우 빠르다는 것을 알고 있으므로 sleep 함수(Sleep)를 사용하면 프로그램을 잠시 멈출 수 있습니다. 다음 코드 Sleep(500)은 루프가 완료될 때마다 500밀리초 동안 휴면한다는 것을 의미합니다.

그림 4-49
요약하다
위의 내용은 파이썬 언어에 대한 간단한 소개입니다. 단순한 기본 지식일 뿐이지만, 간단한 양적 거래 전략을 작성하는 데 사용하는 데는 여전히 문제가 없습니다. 더욱 복잡한 전략을 작성해야 하는 경우 Inventor Quantitative Tool의 Python 언어 API 문서를 참조할 수 있습니다.
다음 섹션 미리보기
기술적 분석 분야의 추세 전략 중에서 이동 평균선과 채널 돌파 전략은 의심할 여지 없이 두 가지 주요 학파입니다. 목표는 가격 움직임의 추세를 포착하는 것이지만, 두 전략의 거래 철학과 위험 특성은 완전히 다릅니다. 이 섹션에서는 Python 언어 소개를 배우고, 다음 섹션에서는 채널 돌파를 위한 양적 거래 전략을 작성하는 방법을 보여드리겠습니다.
숙제
- Inventor Quantitative Tool에서 Python 언어를 사용하여 과거 K-라인 데이터를 얻어보세요.
- 이 섹션의 시작 부분에 전략 코드를 적어보고 주석을 추가해 보세요.
4.4 파이썬 언어를 사용하여 전략 거래를 구현하는 방법
요약
이전 글에서는 Python 언어의 소개, 기본 구문, 전략적 프레임워크 등에 대해 알아보았습니다. 내용은 지루하지만, 거래 전략을 구현하는 데 필수적인 기술이므로 꼭 익혀야 합니다. 이 글에서는 뜨거운 쇠를 쪼는 동안 치고 이전 글의 기본 파이썬 지식을 계속할 것입니다. 간단한 전략으로 시작하여 사용하면서 배우고 모든 사람이 실행 가능한 양적 거래 전략을 단계별로 실현하도록 도울 것입니다.
전략 소개
많은 거래 전략 중에서 Donchian Channel 전략은 가장 고전적인 돌파구 전략 중 하나여야 합니다. 1970년대 초에 잘 알려져 있었습니다. 그 당시 외국 회사가 주류 프로그램 거래 전략에 대한 시뮬레이션 테스트와 연구를 수행했습니다. 그 결과는 다음과 같습니다. 모든 전략 테스트 중에서 돈키안 채널 전략이 가장 성공적이었습니다.
그 후, 거래 역사상 가장 유명한 "거북이" 거래자 훈련이 미국에서 이루어졌고, 이는 엄청난 성공을 거두었습니다. 당시 '거북이'의 거래 방식은 비밀로 유지됐지만 10여년 후 '거북이 거래 규칙'이 공개되자 '거북이'가 돈키안 채널을 개량한 버전을 사용하고 있다는 사실이 드러났다. 전략.
돌파 거래 전략은 비교적 매끄러운 추세를 가진 상품 거래에 적합합니다. 가장 일반적인 돌파 거래 방법은 가격과 지지 및 저항 사이의 상대적 위치 관계를 사용하여 특정 거래 매수 및 매도 지점을 결정하는 것입니다. 이 섹션의 돈키안 채널 전략은 이 원칙에 기초하고 있습니다.
Donchian 채널 전략 규칙
돈키안 채널은 추세 지표이며, 그 모양과 신호는 볼린저 밴드 지표와 다소 비슷합니다. 하지만 돈키안의 가격 채널은 특정 기간 내의 최고 가격과 최저가를 기반으로 구성됩니다. 예를 들어: 최신 50개 K-라인의 최고 가격의 최대값을 계산하여 상단 트랙을 형성합니다. 최신 50개 K-라인의 최저 가격의 최소값을 계산하여 하단 트랙을 형성합니다.
이 지표는 서로 다른 색상의 세 가지 곡선으로 구성되어 있습니다. 기본값은 20개 기간 내의 최고가와 최저가로 시장 가격의 변동성을 보여줍니다. 채널이 좁으면 시장 변동성이 작다는 것을 의미합니다. 반대로 채널이 넓으면 시장 변동성이 비교적 크다는 것을 의미합니다.
가격이 상단 트랙 위로 오르면 매수 신호이고, 반대로 가격이 하단 트랙 아래로 떨어지면 매도 신호입니다. 상단 및 하단 트랙은 최고 가격과 최저 가격을 사용하여 계산되므로, 일반적인 상황에서는 가격이 동시에 상단 및 하단 채널선 아래로 오르거나 내리는 경우가 거의 없습니다. 대부분의 경우, 가격은 상단이나 하단 트랙을 따라 일방적으로 움직이거나 상단과 하단 트랙 사이에서 움직입니다.
돈치안 채널 계산 방법
Inventor Quantitative Tool에서 Donchian Channel의 계산 방법은 매우 간단합니다. 아래 그림과 같이 지정된 기간 내의 최고 가격 또는 최저 가격을 얻는 데 직접 사용할 수 있습니다. 5번째 줄은 50개 기간의 최고 가격의 최대값을 얻고, 6번째 줄은 50개 기간의 최저 가격의 최소값을 얻는 것입니다.

그림 4-50
전략 논리
Donchian Channel을 사용하는 방법은 여러 가지가 있습니다. 단독으로 사용하거나 다른 지표와 함께 사용할 수 있습니다. 이 과정에서는 가장 간단한 방법을 사용하겠습니다. 즉, 가격이 바닥에서 꼭대기까지 상단 트랙을 돌파할 때, 즉 상단 압력선을 돌파할 때, 우리는 강세력이 강해지고 상승장세가 형성되었으며 매수 개시 신호라고 믿습니다. 생성된다; 가격이 상단에서 하단으로 떨어지고 하단 트랙을 돌파할 때, 즉 지지선을 아래로 떨어질 때, 우리는 숏 사이드가 강해지고 하락 추세가 형성되었으며 매도 오픈이 되었다고 믿는다. 신호가 생성됩니다.

그림 4-51
롱 포지션이 오픈된 후 가격이 Donchian Channel의 중간 트랙으로 다시 떨어지면 우리는 강세가 약화되고 있거나 약세가 강해지고 있다고 믿고 매도 신호가 생성됩니다. 가격이 중간 트랙으로 다시 떨어지면 Donchian Channel의 숏 포지션이 오픈된 후 트랙이 상승할 때 우리는 황소가 약해지고 있거나 곰이 강해지고 있다고 믿고 매도 신호가 생성됩니다. Donchian Channel의 중간 트랙으로 다시 상승할 때 우리는 하락장의 힘이 약해지고 있거나, 상승장의 힘이 강해지고 있으며, 매수-종료 신호가 생성됩니다.
거래 조건
롱 포지션 오픈: 포지션이 없고 종가가 상위 트랙보다 큰 경우
숏포지션을 오픈하다: 포지션이 없고 종가가 하단 트랙보다 낮은 경우
롱 포지션 마감:롱 주문을 보유하고 있고 종가가 중간 트랙보다 낮은 경우
숏포지션 청산:단기주문을 보유하고 있고 종가가 중간트랙보다 높은 경우
전략 코드 구현
전략을 구현하는 첫 번째 단계는 데이터를 얻는 것입니다. 왜냐하면 데이터는 거래 전략의 전제 조건이기 때문입니다. 어떤 데이터가 필요한지 상상해 보세요. 그러면 이 데이터는 어떻게 얻을 수 있을까? 그런 다음 이러한 데이터를 바탕으로 거래 로직을 설계합니다. 마지막으로 거래 로직에 따라 매수 및 매도 주문을 내립니다. 구체적인 단계는 다음과 같습니다.
1단계: 거래 라이브러리 사용
트레이딩 라이브러리를 기능적 모듈로 생각할 수 있습니다. 트레이딩 라이브러리를 사용하는 이점은 전략 로직을 작성하는 데 집중할 수 있다는 것입니다. 예를 들어, 거래 라이브러리를 사용하는 경우, 포지션을 개시하고 청산할 때, 거래 라이브러리의 주문 API를 직접 사용할 수 있습니다. 하지만 거래 라이브러리를 사용하지 않는 경우, 포지션을 개시하고 청산할 때 시장 가격을 구하고, 주문을 내지만 실행되지 않는 문제를 고려하고, 주문을 취소하는 문제 등을 고려해야 합니다.

그림 4-52
위의 그림은 발명가의 정량적 도구를 활용한 CTA 전략 프레임워크입니다. 이것은 고정된 코드 형식이며, 모든 거래 로직 코드는 4번째 줄부터 작성됩니다. 다른 부분에는 수정이 필요 없습니다.
JavaScript의 템플릿 라이브러리가 내장되어 있으므로 Python에서는 이 템플릿을 복사하여 저장해야 합니다: https://www.fmz.com/strategy/24288. 그런 다음 정책 편집 페이지에서 참조를 클릭합니다. 물론, 템플릿 라이브러리를 사용하지 않고도 전략을 완료할 수 있습니다.

2단계: 다양한 데이터 얻기
신중하게 생각해보세요, 어떤 데이터가 필요한가요? 전략적 거래 논리를 통해 다음과 같은 사실을 발견했습니다. 먼저 현재 포지션 상태를 파악해야 하고, 그런 다음 종가와 볼린저 밴드 지표의 상단, 중간, 하단 트랙 간의 관계를 비교해야 하며, 마지막으로 시장이 곧 마감되는지 여부를 판단해야 합니다. 그러면 이 데이터를 얻어 보겠습니다.
K선 데이터를 가져오기
첫 번째 단계는 K-라인 배열과 현재 K-라인 종가를 얻는 것입니다. K-라인 배열을 통해서만 API를 호출하여 N 기간의 최고 또는 최저 가격을 얻을 수 있습니다. 코드에서는 다음과 같습니다.

그림 4-53
위 그림에서 보이는 바와 같이:
4번째 줄: 고정된 형식인 K-라인 배열을 가져옵니다.
5번째 줄: K-라인의 길이를 필터링합니다. N개 기간의 최고 또는 최저 가격을 계산하기 때문에 사용된 매개변수는 50입니다. K-라인의 수가 50보다 적으면 계산할 수 없습니다. 따라서 여기서 K-라인의 길이를 필터링해야 합니다. K-라인이 50개 미만이면 이 루프를 건너뛰고 다음 K-라인을 계속 기다립니다.
6번째 줄: 우리는 "records" 코드를 사용합니다.[len(records) - 1]"는 먼저 K-line 배열의 마지막 데이터, 즉 최신 K-line 데이터를 가져옵니다. 이 데이터는 객체이며, 여기에는 다음이 포함됩니다: 시가, 최고가, 최저가, 종가, 거래량, 시간 및 기타 데이터. 객체이므로 ".Close"를 직접 사용하여 최신 K-line 종가를 가져올 수 있습니다.
위치 데이터 가져오기
포지션 정보는 양적 거래 전략에서 매우 중요한 조건입니다. 거래 조건이 충족되면 포지션 상태와 포지션 수에 따라 주문을 할지 여부를 결정하는 것도 필요합니다. 예를 들어, 매수 포지션을 열기 위한 조건이 충족되었을 때, 포지션이 있는 경우 다시 주문을 낼 필요가 없고, 포지션이 없는 경우 주문을 낼 수 있습니다. 이번에는 위치 정보를 함수에 직접 캡슐화하고, 이 함수를 호출하기만 하면 사용할 수 있습니다.
그림 4-54
위 그림에서 보이는 바와 같이:
포지션 정보를 얻는 함수입니다. 숏 포지션이면 0을 반환하고, 롱 포지션이면 1을 반환하고, 숏 포지션이면 -1을 반환합니다. 위의 코드를 주목하세요:
2번째 줄: 매개변수가 없는 mp라는 이름의 함수를 만듭니다.
3번째 줄: 고정된 형식인 위치 배열을 가져옵니다.
4번째 줄: 위치 배열의 길이를 결정합니다. 길이가 와 같으면 빈 위치여야 하므로 0을 반환합니다.
6번째 줄: for 루프를 사용하여 배열을 탐색하기 시작합니다. 다음 논리는 매우 간단합니다. 롱 포지션을 유지하면 1을 반환하고, 숏 포지션을 유지하면 -1을 반환합니다.
18번째 줄: 방금 작성한 mp 함수를 호출하여 위치 정보를 얻습니다.
최근 50K 라인의 최고 및 최저 가격을 알아보세요
Inventor Quantitative Tool에서는 "TA.Highest" 및 "TA.Lowest" 함수를 사용하여 논리적 계산을 직접 작성하지 않고도 직접 얻을 수 있습니다. 그리고 "TA.Highest"와 "TA.Lowest" 함수가 반환하는 결과는 배열이 아니라 구체적인 값입니다. 이것은 매우 편리합니다. 그뿐만 아니라, 공식에는 수백 개의 지표 기능이 내장되어 있습니다.

그림 4-55
위 그림에서 보이는 바와 같이:
라인 19: "TA.Highest" 함수를 호출하여 50개 기간 동안 가장 높은 가격의 최대값을 구합니다.
라인 20: "TA.Lowest" 함수를 호출하여 50개 기간 동안 가장 낮은 가격의 최소값을 구합니다.
21번째 줄 : 50개 기간 동안 가장 높은 가격의 최대값과 50개 기간 동안 가장 낮은 가격의 최소값을 기준으로 평균값을 계산합니다.
3단계: 주문하기
위 데이터를 이용해서 거래 로직과 주문을 하기 위한 코드를 작성할 수 있습니다. 형식도 매우 간단합니다. 가장 일반적으로 사용되는 것은 "if 문"으로, 다음과 같이 말로 표현할 수 있습니다. 조건 1과 조건 2가 충족되면 주문을 합니다. 조건 3 또는 조건 4가 충족되면 주문을 합니다.
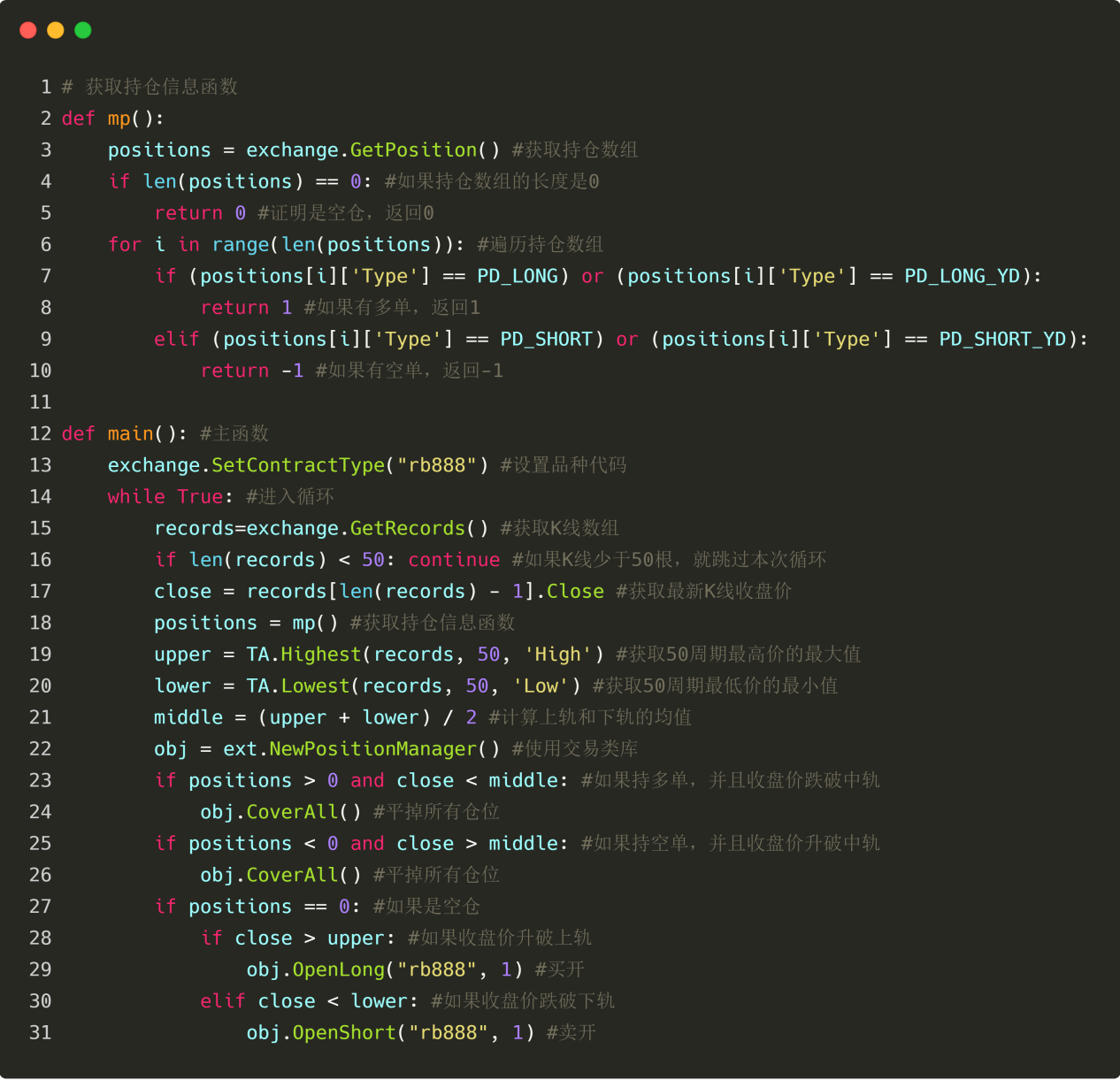
그림 4-56
위 그림에서 보이는 바와 같이:
22번째 줄 : 고정된 포맷인 트랜잭션 라이브러리를 사용합니다.
23행과 24행: 이것은 롱 포지션을 마감하기 위한 문장으로, 우리가 이전에 배운 "비교 연산자"와 "논리 연산자"를 사용합니다. 즉, 현재 롱 포지션을 보유하고 있고 마감 가격이 중간 트랙보다 낮으면 모든 포지션이 마감됩니다.
25행과 26행: 이것은 단기 주문을 마감하기 위한 문장으로, 우리가 이전에 배운 "비교 연산자"와 "논리 연산자"를 사용합니다. 즉, 현재 단기 주문을 보유하고 있고 마감 가격이 중간 트랙보다 높으면 모든 포지션이 마감됩니다.
27번째 줄: 현재 포지션 상태를 확인합니다. 포지션이 짧은 경우 다음 단계로 진행합니다.
28, 29행: 종가가 상위 트랙보다 높은지 확인합니다. 종가가 상위 트랙 위로 오르면 매수하여 포지션을 엽니다.
30행과 31행: 종가가 하위 트랙보다 낮은지 확인합니다. 종가가 하위 트랙 아래로 떨어지면 매도하고 포지션을 엽니다.
요약하다
위에서 우리는 파이썬을 이용하여 완전한 양적 거래 전략을 개발하는 각 단계를 알아보았습니다. 여기에는 전략 소개, 돈키안 채널 계산 방법, 전략 논리, 매수 및 매도 조건, 전략 코드 구현 등이 포함됩니다. 이 섹션은 시작점으로서 단순한 전략일 뿐입니다. 방법은 여러 가지가 있습니다. 자신의 거래 시스템에 따라 다양한 거래 방법을 중첩하여 자신의 양적 거래 전략을 형성할 수 있습니다.
다음 섹션 미리보기
양적 거래 전략을 개발할 때 프로그래밍 언어의 실행 속도 관점에서 볼 때, 가장 빠른 언어는 무엇이냐고 묻는다면 C++밖에 없습니다. 특히 파생상품과 고빈도 거래 분야에서 C++는 독특한 언어적 특성과 수치 계산에 유리합니다. JavaScript와 Python에 비해 속도가 몇 배나 빨라질 수 있습니다. 앞으로 파생상품과 고빈도 거래 분야에서 발전하고 싶다면 놓칠 수 없는 과정이 될 것입니다.
숙제
- 이 섹션의 전략을 복사하여 구현해 보세요.
- 이 섹션의 전략에 이동 평균 지표를 추가하여 거래 빈도를 줄여보세요.
5장 전략 백테스팅, 디버깅 및 개선
5.1 백테스팅의 중요성과 함정
요약
백테스팅은 양적 거래와 전통적 거래의 가장 큰 차이점입니다. 역사적으로 발생한 실제 시장 데이터를 기반으로 전략 신호 트리거링과 거래 매칭을 빠르게 시뮬레이션하여 일정 기간 동안 성과 보고서 및 기타 데이터를 얻습니다. 이는 국내외 주식, 상품선물, 외환 및 기타 시장의 전략 개발에서 가장 중요한 구성 요소 중 하나입니다.
백테스팅의 중요성
이전 챕터에서 우리는 주류 프로그래밍 언어의 기본을 배웠고, 이러한 프로그래밍 기본을 사용하여 간단한 거래 전략을 작성하는 방법을 알려드렸습니다. 우리는 이미 긴 행진의 절반 이상을 왔다고 할 수 있습니다. 그러나 전략이 작성되면 바로 실행할 수 없습니다. 전략이 모델 내용을 완전히 구현하고 원활하게 실행될 때까지는 지속적인 백테스팅 - 디버깅 - 백테스팅 - 디버깅 등이 필요합니다.
양적 거래 논리의 관점에서 보면 전략은 실제로 시장에 대한 일련의 인식과 가정에 기반을 두고 있습니다. 백테스팅은 이러한 가정이 타당하고 안정적인지 여부를 효율적으로 판단할 수 있습니다. 역사적으로 불안정한 시기에 어떤 손실이 발생할 수 있는지, 그리고 그러한 손실을 방지하기 위한 의사 결정을 내리는 데 어떻게 도움이 될 수 있는지 설명합니다.
또한, 양적 거래 운영의 관점에서 백테스팅은 미래 함수, 가격 도용, 멀티 피팅 등과 같은 전략 로직의 버그를 감지하는 데 도움이 될 수 있습니다. 해당 전략이 실제 거래에서 사용될 수 있다는 신뢰할 수 있는 증거를 제공하세요.
- 거래 신호의 정확성을 확인하세요.
- 거래 논리를 검증하고 아이디어가 실현 가능한지 확인하세요.
- 거래 시스템의 결함을 발견하고 원래 전략을 개선하세요.
따라서 백테스팅의 중요성은 과거 데이터를 통해 실제 거래 프로세스를 가능한 한 현실적으로 복원하고, 전략의 효과를 검증하고, 잘못된 전략으로 인해 큰 대가를 치르는 것을 피하고, 거래 전략을 선별, 개선 및 최적화하는 데 도움이 됩니다.
백테스팅의 함정
백테스팅 트랩 신호 깜박임:
거래 전략은 정적 과거 데이터를 기반으로 백테스트됩니다. 실제 거래 데이터는 동적입니다. 예를 들어: 최고 가격이 어제의 종가보다 높으면 매수를 눌러 포지션을 개설합니다. 실제 거래에서는 K-라인이 아직 완성되지 않았다면 최고 가격이 동적으로 변할 수 있으며 거래 신호가 앞뒤로 깜빡일 수 있습니다. 백테스팅 중에 백테스팅 엔진은 정적 과거 데이터를 기반으로 일치하는 거래를 시뮬레이션할 수 있습니다.
미래 기능의 백테스팅 함정:
미래 기능은 미래 가격을 사용하는데, 이는 현재 조건이 미래에 변경될 수 있음을 의미합니다. 미래 기능은 신호 깜박임을 일으킬 수도 있습니다. 따라서 모든 함수는 "지그재그 함수"와 같은 미래 함수의 특성을 갖습니다.
아래 그림과 같이: 지그재그 함수는 피크와 트로프의 전환점을 나타냅니다. 최신 실시간 가격에 따라 값을 적절히 조정할 수 있습니다. 그러나 현재 가격이 변경되면 지그재그 함수에서 계산한 결과도 변경됩니다. 미래 기능이 있는 함수를 사용하는 경우 현재 주문 신호가 설정되고 주문이 실행될 수 있지만, 얼마 후에 신호가 설정되지 않을 수도 있습니다.

그림 5-1
백테스팅 함정: 가격 도용
가격 도용이란 과거 가격을 이용해 거래하는 것을 말합니다. 예를 들어: 최고 가격이 고정 가격보다 높으면, 시작 가격에서 매수합니다. 이런 상황은 가격 도용입니다. 실제 시장에서 최고 가격이 특정 가격보다 높을 경우, 그 가격은 이미 시가보다 일정 수준 높은 상태이고, 이때는 시가로 매수할 수 없기 때문입니다. 하지만 백테스트에서는 매수 신호가 발생하고 거래가 완료될 수 있습니다.
또 다른 상황이 있습니다. 가격이 더 높이 뛰어올라 전략에서 설정한 고정 가격보다 더 높게 오픈하면 백테스팅 중에 고정 가격으로 거래를 완료할 수 있지만, 이 고정 가격은 실제 시장에서는 당연히 사용할 수 없습니다.
백테스팅 함정: 불가능한 거래 가격
가격을 거래할 수 없는 상황은 여러 가지가 있습니다.
첫 번째: 실제 거래에서는 일반적으로 가격이 상한가에 도달하면 매수할 수 없으며, 그 반대의 경우도 마찬가지입니다. 하지만 백테스트를 통해 거래하는 것은 가능합니다.
두 번째 유형: 거래소 매칭 메커니즘은 가격 우선, 시간 우선입니다. 일부 품종은 종종 시장에서 엄청난 주문이 발생합니다. 실제 거래 중에 매수 또는 매도 주문을 하면 거래가 완료되기 전에 시장 두께가 채워질 때까지 기다려야 하거나 완료할 수 없습니다. 그러나 백테스팅 중에는 보류 중인 매수 및 매도 주문이 실행될 수 있습니다.
세 번째 유형: 이것이 차익거래 전략인 경우, 백테스팅 수익은 매우 높습니다. 왜냐하면 백테스팅을 하는 동안 이러한 가격 차이가 포착되었다고 가정하기 때문입니다. 실제로 많은 가격 스프레드는 잡을 수 없거나, 한 쪽 다리만 잡힙니다. 일반적으로, 당신의 방향에 유리하지 않은 다리가 먼저 실행되므로, 다른 다리를 즉시 채워야 합니다. 이때 슬리피지는 더 이상 1 또는 2 포인트가 아니며, 차익 거래 전략 자체가 이 몇 포인트의 가격 차이를 벌어들입니다. 이 상황은 백테스팅에서 시뮬레이션할 수 없습니다. 실제 수익은 백테스트 결과만큼 좋지 않습니다.
네 번째 유형: 블랙스완 사건. 아래 그림의 빨간색 원에서 보듯이 스위스 프랑 외환의 블랙스완 사건은 표면적으로는 시가, 최고가, 최저가, 종가가 존재하지만, 실제로는 당일의 극한 시장 상황에서는 그 중간의 가격이 진공상태이고, 대량의 손절매 주문으로 폭주하여 유동성이 제로가 되어 거래가 매우 어려웠지만, 백테스팅을 통해 손절매를 달성할 수 있었습니다.
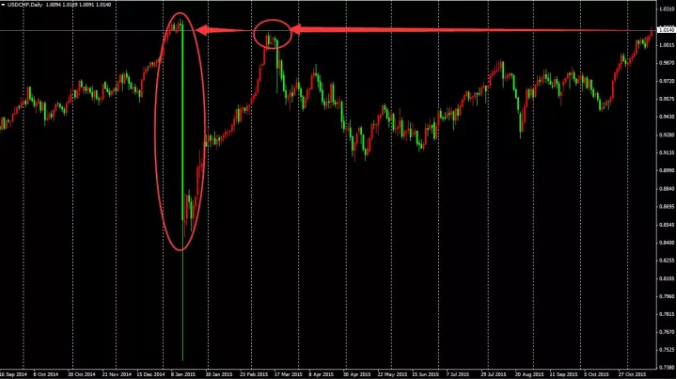
그림 5-2
백테스팅 함정: 과적합
아래 그림을 볼 때마다 저는 "하하하"라고 느낍니다. 아래 그림을 보면, 아무리 복잡한 모델이라도 데이터에 완벽하게 적응할 수 있다는 것을 알 수 있습니다.
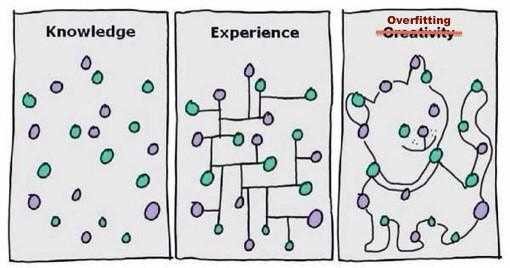
그림 5-3
양적 거래의 경우 백테스팅은 과거 데이터를 기반으로 하지만 과거 데이터의 샘플은 제한적입니다. 거래 전략에 매개변수가 너무 많거나 거래 로직이 너무 복잡하면 거래 전략이 과거 데이터에 지나치게 맞춰질 것입니다.
양적 전략의 모델링 과정은 본질적으로 겉보기에 무작위적인 대량의 데이터에서 지역적 비무작위 데이터를 찾는 과정입니다. 통계적 지식의 도움 없이는 과적합의 함정에 빠지기 쉽습니다.
그러니 자신을 속이지 마세요. 샘플 밖 데이터의 성능이 좋지 않다는 것을 발견하고 모델을 폐기하는 것이 유감스럽다고 생각하거나 모델이 좋지 않다는 것을 인정하고 싶지 않아 샘플 밖 데이터에서 모델이 좋은 성능을 보일 때까지 샘플 밖 데이터로 모델을 최적화를 계속한다면 결국 힘들게 벌어들인 돈이 손해를 보게 됩니다.
백테스팅 함정: 생존자 편향
월가에는 유명한 농담이 있습니다. 시장에 투자하는 원숭이가 1,000마리 있다고 가정해 보겠습니다. 첫 해에 시장에 진 원숭이 500마리가 탈락합니다. 2년차에는 원숭이의 절반이 다시 없어져서 원숭이가 250마리만 남았습니다. 3년차 말에는 원숭이가 125마리 남았습니다.
그림 5-4
9년째가 되자 원숭이가 한 마리만 남았습니다. 그러면 좌우로 살펴보면 익숙한 것이 보입니다. 마침내, 금융 잡지 표지를 보았을 때, 나는 갑자기 "아, 이거 버핏이 아니었나?"라는 생각이 났다.
물론 이건 농담일 뿐이지만, 펀드 매니저가 1,000명이 있다면 10년 후에 그중 약 10명의 펀드 매니저가 10년 연속으로 시장보다 성과가 좋을 것이라는 걸 생각해 보셨나요? 하지만 이는 무작위성과 행운에 의해 결정될 뿐, 펀드 매니저의 기술과는 아무런 관련이 없습니다.
아래 그림의 왼쪽에 있는 백테스트 성과와 마찬가지로, 저는 대부분 투자자가 놀랄 것이라고 생각합니다. 이 투자 전략은 심각한 하락이 거의 없이 매우 견고한 성과를 보였습니다.

그림 5-5
잠깐만요, 오른쪽 그림에서 보듯이, 실제 상황은 내부에 있습니다. 왼쪽의 백테스트 곡선은 여러 백테스트 중 성과가 가장 좋은 것으로 나타났습니다. 즉, 왼쪽의 백테스트에서는 성과가 더욱 나쁜 상황이 많이 있습니다.
백테스팅 함정: 임팩트 비용
실제 거래 환경에서 가격은 끊임없이 변동합니다. 거래 기회를 보고 주문을 하면 가격이 바뀌었을 수 있습니다. 따라서 주관적 거래에서든 양적 거래에서든 슬리피지 문제는 불가피합니다.
그러나 백테스팅은 정적 데이터에 기반하기 때문에 실제 거래 환경을 시뮬레이션하는 것은 어렵습니다. 예를 들어, 주문 가격은 1050에 매수이지만 실제 거래 가격은 1051일 수 있습니다. 이러한 현상에는 여러 가지 이유가 있습니다. 극한 시장 상황에서의 유동성 공백, 네트워크 지연, 소프트웨어 및 하드웨어 시스템, 서버 응답 등입니다.
미끄러짐 없는 백테스팅
그림 5-6
위의 그림에서 보듯이, 이것은 슬리피지가 없는 백테스트입니다. 자본 곡선은 더 좋아 보이지만, 실제 거래의 실제 거래 가격과 전략 백테스트의 이상적인 거래 가격 사이에 차이가 있습니다. 따라서 이러한 오류를 줄이기 위해 전략을 백테스트할 때 매수 가격을 높이거나 매도 가격을 낮추기 위해 2개의 슬리피지 포인트를 설정할 수 있습니다.
슬리피지를 이용한 백테스팅
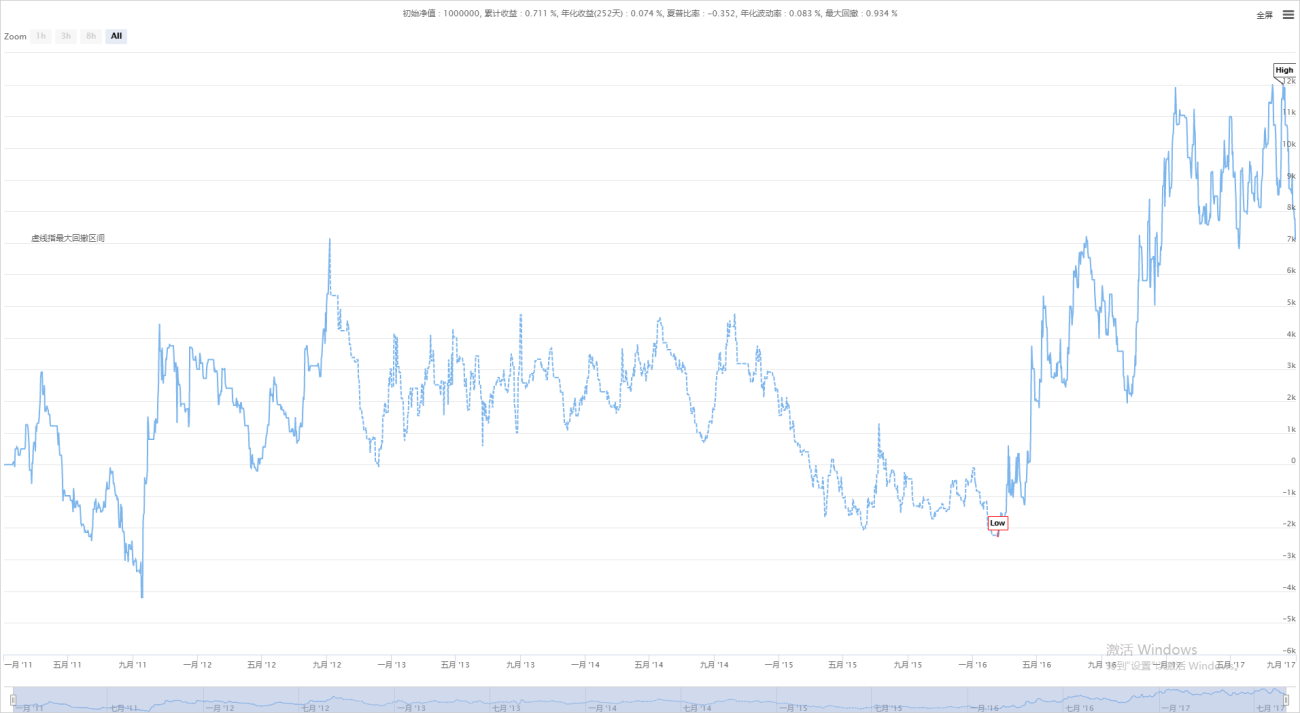
그림 5-7
위 그림에서 보듯이, 동일한 전략에 대해 2점프 슬리피지를 추가한 후 백테스트 결과가 슬리피지가 없는 백테스트 결과와 크게 다르다면, 이 전략을 개선하거나 새로운 전략으로 대체해야 함을 의미합니다. 특히 거래 빈도가 비교적 높은 전략의 경우, 백테스팅 중에 1~2회의 점프를 추가하면 백테스팅이 실제 거래 환경에 더 가까워질 수 있습니다.
요약하다
일부 친구들은 양적 거래에는 많은 문제가 있을 수 있는데, 내 전략이 훌륭하다는 것을 어떻게 증명할 수 있을지 묻습니다. 사실, 답은 매우 간단합니다. 전략을 실제로 구현하기 전에 먼저 일정 기간 동안 거래를 시뮬레이션해야 합니다. 시뮬레이션된 거래의 거래 가격이 백테스트 중 거래 가격과 거의 같다면 전략에 문제가 없다는 것을 증명합니다. 최소한 전략 로직에는 문제가 없습니다.
어떤 경우든, 백테스팅은 숙련된 거래 시스템 개발자에게 필수입니다. 이를 통해 전략적 아이디어가 과거 거래에서 효과적인지 검증할 수 있는지 여부를 알 수 있습니다. 하지만 많은 경우 백테스팅은 미래의 수익성을 의미하지 않습니다. 백테스팅에는 함정이 너무 많기 때문에 돈을 들여서 교훈을 얻지 않는 이상 백테스팅을 이해할 수 없습니다. 그리고 이러한 교훈은 실제 돈을 통해서 배울 수 있습니다. 이 기사를 읽으면 적어도 많은 양적 우회로와 함정을 피하는 데 도움이 될 것이라고 생각합니다.
숙제
- 과잉적합이란 무엇이고, 이를 피하는 방법은 무엇입니까?
- 실제 생활에서 생존자 편향의 몇 가지 예는 무엇입니까?
5.2 양적 트레이딩 백테스팅을 하는 방법
요약
백테스팅의 중요성과 중요성은 의심할 여지가 없습니다. 양적 백테스팅을 수행할 때는 가능한 한 실제 역사적 환경에서 전략을 유지하려고 해야 합니다. 역사적 환경의 세부 사항을 무시하면 전체 양적 백테스팅이 무효화될 수 있습니다. 이 글에서는 양적 트레이딩 백테스팅을 수행하는 방법을 설명합니다.
백테스팅은 데이터 재생과 동일합니다. 이는 과거 K-라인 데이터를 재생하고 매수 및 매도에 대한 실제 거래 규칙을 시뮬레이션하고, 마지막으로 샤프 비율, 최대 하락률, 연간 수익률, 자본 곡선 및 기타 데이터를 기간 내에 요약합니다. 현재 백테스팅을 수행할 수 있는 소프트웨어는 많이 있는데, 대표적인 것으로는 다양한 제품을 갖춘 Wenhua Finance와 유연한 사용자 정의가 가능한 VNPY 등이 있습니다.
상업용 양적 거래 소프트웨어인 Inventor Quant는 고성능 백테스팅 엔진을 탑재하고 있으며, 벡터화된 계산을 위한 for-loop(폴링) 백테스팅 프레임워크를 채택하여 더욱 빠릅니다. 또한 백테스팅과 실제 트레이딩을 위한 코드를 통합하여 "백테스팅은 쉬운데 실제 트레이딩은 어렵다"는 딜레마를 부분적으로 해결했습니다.
백테스팅 인터페이스 소개
Inventor Quantitative의 Mai Language Strategy를 예로 들어 Inventor Quantitative Trading Tool(www.fmz.com)의 공식 웹사이트를 열어 보겠습니다. 제어 센터, 전략 라이브러리, 전략 선택, 백테스트 시뮬레이션을 클릭하고 다음 페이지로 들어갑니다.

그림 5-8
백테스트 구성 인터페이스에서 실제 요구 사항에 맞게 사용자 정의할 수 있습니다. 예를 들어: 백테스트 시간, K-라인 기간, 데이터 유형(시뮬레이션 수준 데이터 또는 실시간 수준 데이터. 비교해 보면, 시뮬레이션 수준 데이터 백테스팅은 더 빠르고, 실시간 수준 데이터 백테스팅은 더 정확합니다). 또한 백테스팅 수수료와 계좌 초기 자금 등도 설정할 수 있습니다.
Mai Language Trading Library를 클릭하세요. 첫 번째는 Trading Settings 탭입니다. Inventor Quantitative Trading Tool의 Mai Language 전략에는 두 가지 백테스트 실행 방법이 있습니다. 즉, 종가 모델과 실시간 가격 모델입니다. 종가 모델은 현재 K-라인이 완료된 후에만 모델이 실행되고, 다음 K-라인이 시작될 때 거래가 실행된다는 것을 의미합니다. 실시간 가격 모델은 가격이 변경될 때마다 모델이 한 번씩 실행되고, 거래 신호가 설정되면 거래가 즉시 실행된다는 것을 의미합니다. 아래와 같이 표시됩니다.
그림 5-9
기본 오픈 로트 크기는 백테스팅 중에 오픈하고 닫은 포지션의 수를 말하며, 최대 단일 거래 주문 크기는 단일 거래에서 백테스팅 엔진에 위탁된 오픈 및 닫는 포지션의 최대 수입니다. 실제 거래 가격과 사전 설정된 거래 가격 사이에 편차가 있습니다. 이 편차는 일반적으로 거래자에게 불리한 방향으로 이동하여 거래에서 추가 손실이 발생하므로 슬리피지를 추가하는 것이 필요합니다. 국내 상품 선물은 일반적으로 실제 거래 환경을 시뮬레이션하기 위해 1~2회 점프 또는 그 이상을 추가합니다.
선물 옵션에서 백테스트할 계약 유형을 입력하세요(예: rb000, rb888). 실제 옵션은 실제 거래에 주로 사용되며, 기본 설정은 백테스팅에서 유지될 수 있습니다. 자동 복구 진행률을 true로 클릭하면 전략이 실시간 작동 중에 로봇을 중지했을 때 로봇을 다시 시작하면 신호를 다시 계산하지 않고도 이전 신호 위치가 자동으로 복원됩니다. 주문 재시도 기본 횟수는 20회입니다. 주문이 실패하면 시스템은 주문을 다시 시도합니다. 네트워크 폴링 간격은 로봇이 전략 코드를 실행하는 시간 간격입니다.

그림 5-10
현물 거래 옵션은 주로 디지털 통화 거래에 적용되며, 백테스트에서는 기본 설정을 유지할 수 있습니다. 단일 거래량, 최소 거래량, 가격 통화 정확도, 거래 상품 정확도, 처리 수수료, 계좌 동기화 시간, 손익 통계 간격 등을 지정할 수 있습니다. 또한 개별 디지털 통화 거래소의 경우 레버리지 배수 및 기타 관련 설정도 설정할 수 있습니다.
그림 5-11
전략 백테스팅
백테스팅을 하기 전에 먼저 거래 전략을 결정하세요. 여기서는 서모스탯 전략을 예로 들어보겠습니다. 이 전략은 시장 상황에 따라 추세 시장에서는 트렌드 전략을 채택하고 변동 시장에서는 변동성 전략을 채택합니다. 소스 코드는 다음과 같습니다(Inventor Quantitative 공식 웹사이트의 Strategy Square에서 직접 다운로드할 수도 있습니다):
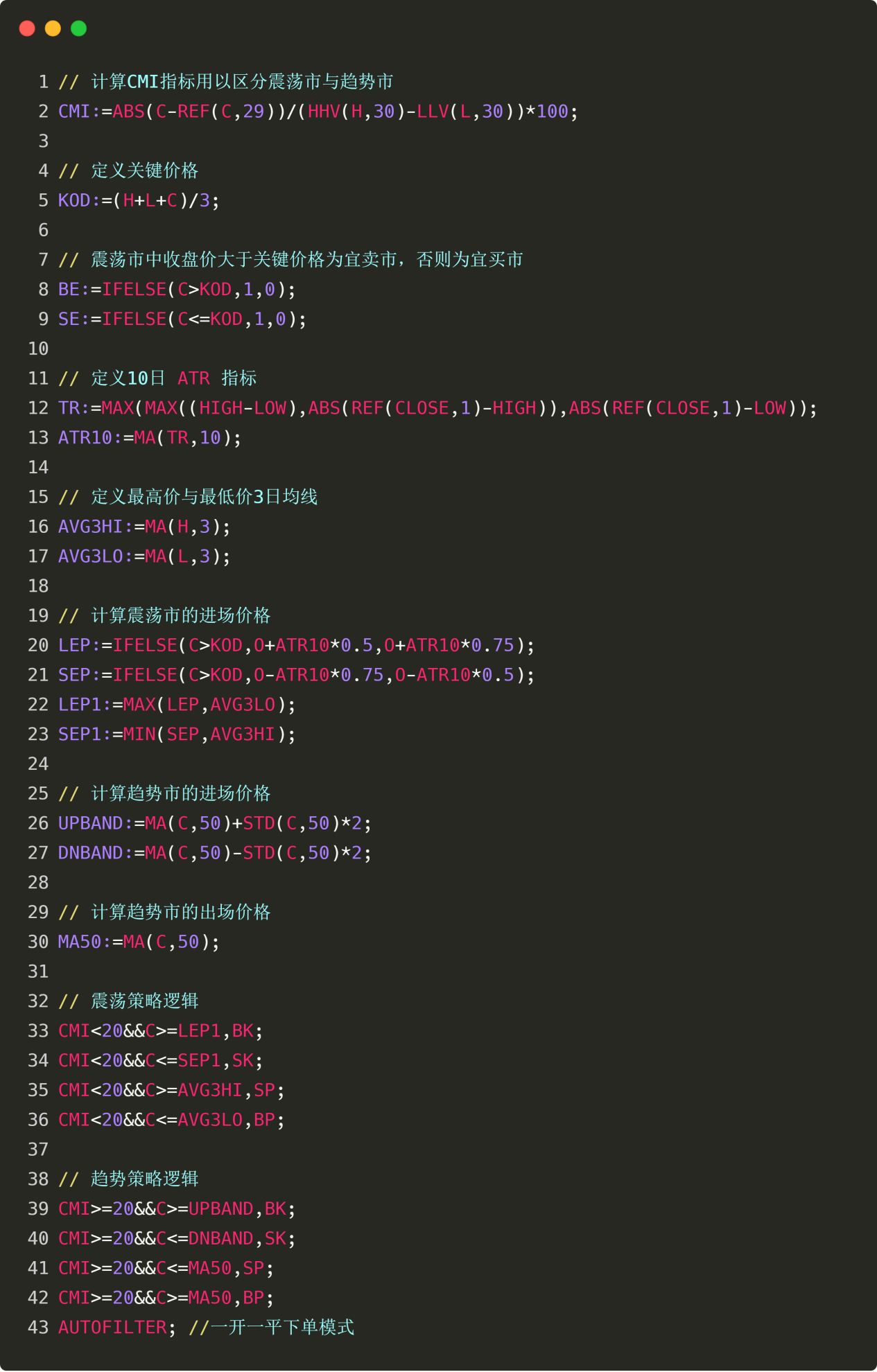
그림 5-12
시뮬레이션 백테스팅 인터페이스에서 백테스팅 설정을 구성한 후 백테스팅 시작 버튼을 클릭하면 수십 초 후에 백테스팅 결과가 바로 표시됩니다. 백테스트 로그에는 백테스트에 걸린 시간(초), 총 로그 수, 거래 수가 기록됩니다. 계정 정보에는 전략 백테스팅의 최종 성과 결과가 인쇄됩니다. 여기에는 평균 손익, 포지션 손익, 마진, 처리 수수료, 예상 수익 등이 포함됩니다.
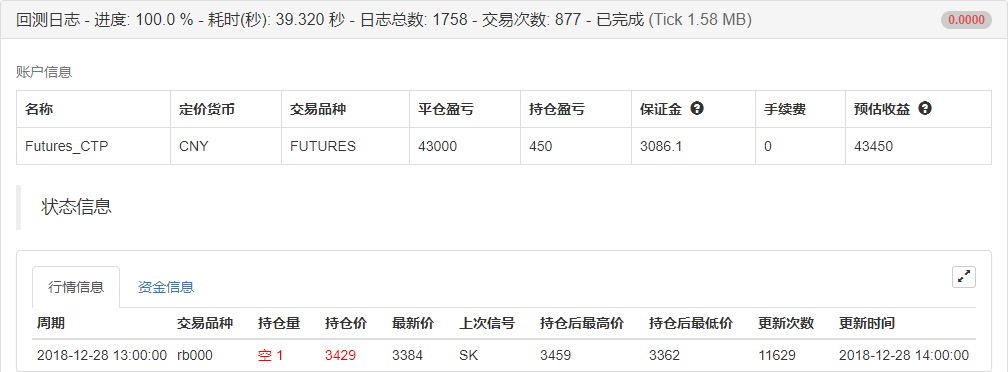
그림 5-13
상태 정보 열에는 거래 유형, 포지션 거래량, 포지션 가격, 최신 가격, 마지막 신호 유형, 포지션을 유지한 후 최고 및 최저 가격, 업데이트 번호 및 시간, 자본 정보가 기록됩니다. 또한 변동형 손익 라벨은 계좌의 세부적인 자본 곡선과 일반적으로 사용되는 성과 지표인 수익률, 연간 수익률, 샤프 비율, 연간 변동성, 최대 인출률을 표시하여 대부분 사용자의 요구를 기본적으로 충족할 수 있습니다.
그 중 가장 중요한 성과지표는 샤프지수이다. 수익과 위험을 모두 고려한 포괄적인 지표입니다. 또한 펀드 상품을 측정하는 데 중요한 참고 지표이기도 합니다. 일반인의 말로 표현하면, 1달러를 벌 때마다 얼마나 많은 위험을 감수하는지를 의미합니다. 따라서 샤프 비율이 높을수록 좋습니다.
이름에서 알 수 있듯이, 연간 변동성은 일일 변동성에 연간 거래일 수를 곱한 것입니다. 이는 펀드의 위험을 측정하지만, 확실히 총 위험은 아닙니다. 예를 들어, 전략 A는 변동성이 더 높지만 좋은 수익률로 상승하고 있는 반면, 전략 B는 변동성이 낮지만 변동성이 없습니다. 전략 B가 전략 A보다 더 좋다고 말할 수 있을까요? 다음 그림에서 보는 바와 같이 전략 A:
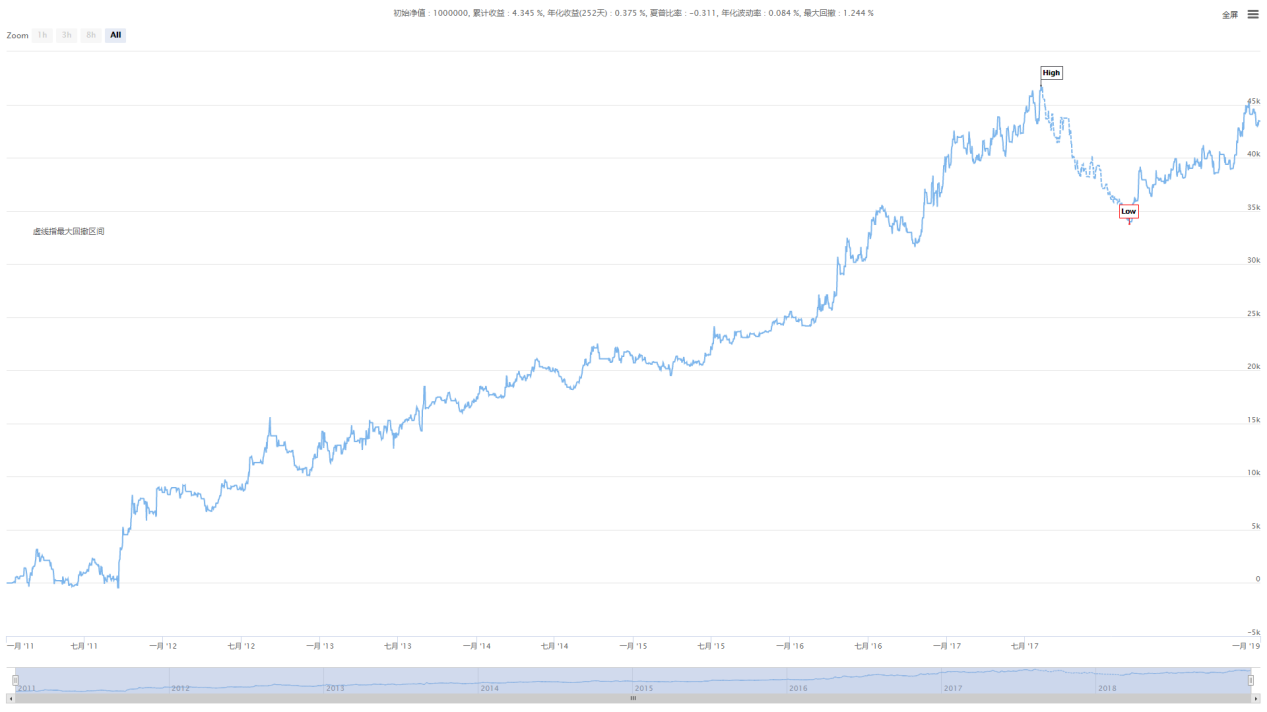
그림 5-14
마지막으로, 로그 정보 열에는 백테스트 중 각 거래의 매칭 상태가 자세히 기록됩니다. 여기에는 거래의 구체적인 시간, 거래소, 매수매도, 개시 및 마감 유형, 백테스트 엔진에 의해 매칭된 거래 가격, 거래 수량, 인쇄 정보 등이 포함됩니다.
그림 5-15
백테스팅 후
많은 경우, 심지어 대부분의 경우에도 백테스팅 결과는 기대와는 거리가 멉니다. 결국 장기적이고 지속적이며 안정적인 수익을 창출하는 전략은 얻기 쉽지 않습니다. 시장을 이해하는 능력이 필요합니다.
전략 백테스트 결과가 손실로 이어진다면 낙담하지 마십시오. 이는 실제로 정상적인 일입니다. 먼저 전략 로직이 잘못 작성되었는지, 극단적인 매개변수가 사용되었는지, 개장 및 마감 조건이 너무 많은지 등을 점검합니다. 필요하다면 다른 관점에서 거래 전략과 거래 철학을 다시 검토할 수도 있습니다.
전략 백테스트 결과가 매우 좋고 자본 곡선이 완벽하며 샤프 비율이 1 이상을 초과하면 됩니다. 아직 너무 기뻐하지 마세요. 이런 상황에 직면했을 때, 대부분은 미래 함수 사용, 가격 절도, 과적합, 슬리피지 설정 실패 등 때문입니다. 샘플 밖 데이터와 시뮬레이션된 실제 거래를 사용하여 이러한 문제를 제거할 수 있습니다.
요약하다
위의 내용은 전체 거래 전략을 백테스트하는 전체 과정에 대한 소개이며, 모든 세부 사항에 구체적이라고 할 수 있습니다. 결국, 과거 데이터를 이용한 백테스팅은 모든 위험이 알려져 있는 이상적인 환경이라는 점에 유의해야 합니다. 따라서 해당 전략을 백테스트하는 가장 좋은 시점은 강세장이나 약세장을 경험하는 것이며, 부분적인 생존자 편향을 피하기 위해 효과적인 거래 횟수는 100회 이상이어야 합니다.
시장은 항상 변화하고 진화합니다. 과거 백테스팅에서 좋은 성과를 거두는 전략이 반드시 미래에도 좋은 성과를 거두는 것은 아닙니다. 이 전략은 백테스팅 환경에서 알려진 위험에 대처할 수 있을 뿐만 아니라 미래에 알려지지 않은 위험에도 대처해야 합니다. 그러므로 전략의 위험 저항성과 보편성을 높이는 것이 매우 필요합니다.
숙제
- 이 섹션의 전략을 복사하여 성과 보고서를 백테스트해 보세요.
- 귀하의 거래 경험에 따라 이 섹션의 전략을 개선하고 최적화해 보세요.
5.3 전략 백테스팅 성과 보고서를 이해하는 방법
요약
전략 백테스트가 완료되면 Inventor Quantitative Trading Tool은 웹 페이지에 다양한 성과 지표와 이익 곡선 차트를 출력합니다. 그러나 아마도 우리가 이러한 지표의 해석과 내용을 잘 모르기 때문에 전략이 좋은지 나쁜지 정확하게 판단할 수 없습니다. 이 글은 모든 사람이 전략 백테스팅 성과 보고서를 이해하고 전략의 장단점을 구별할 수 있도록 주요 지표 개념부터 시작합니다. 물론, 대부분의 양적 거래 도구에는 이런 종류의 백테스트 성과 보고서가 있으며, 내용도 비슷합니다. 이 섹션의 내용을 알게 되면 다른 거래 도구로 전환하더라도 적용할 수 있습니다.
객관적이고 완전한 평가
실제 거래 데이터의 기록이든 과거 데이터를 활용한 백테스팅 보고서이든, 모델의 품질은 거래 상황에 대한 통계를 통해 평가됩니다.
핵심 질문은 비교를 위해 어떤 통계 자료가 필요한가입니다. 예를 들어 보겠습니다. 아래 그림과 같이 동일한 기간 동안 테스트에서 다음 두 세트의 데이터를 얻었다고 가정할 때, 어느 모델이 더 나은 성능을 보이는지 확인할 수 있을까요?
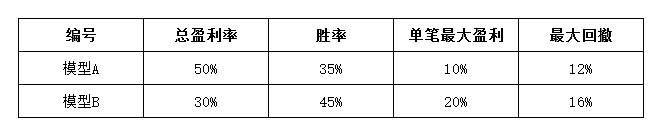
그림 5-16
답은 '아니요'입니다. 평가체계의 일방성은 양적 거래체계를 막다른 길로 몰고 갈 것입니다.
거래 시스템을 실제에 적용하려면 먼저 과거 백테스팅을 통과해야 합니다. 과거의 백테스팅을 통과하지 못한 거래 시스템은 장기적으로 실제 거래에서 수익을 낼 가능성이 낮습니다. 과거 실적 백테스팅은 거래 시스템을 실제 거래에 적용하는 데 필요한 전제 조건입니다.
과거 백테스팅을 통과할 수 있는 거래 시스템이 반드시 좋은 거래 시스템인 것은 아니지만, 과거 백테스팅을 통과할 수 없다면 그것은 분명 좋은 거래 시스템이 아닙니다. 일반적으로 성과 보고서는 안정성, 지속 가능성, 기대에 부응하는지 여부의 관점에서 분석해야 합니다.

그림 5-17
위의 그림에서 보듯이, 양적 거래에 노출된 사람이라면 누구나 이런 길고 모호한 백테스트 성과 데이터 용어를 본 적이 있을 것입니다. 이러한 성과 데이터 중 많은 것은 모순되기까지 합니다. 많은 양적 분석 초보자들은 어떤 데이터에 초점을 맞춰야 할지 혼란스러워합니다.
위 그림의 성과 지표 용어는 일반적으로 성과 비율, 사이클 분석, 다양한 곡선, 극단적 거래 분석 등 여러 범주로 나눌 수 있습니다. 펀드 상품의 관점에서도 대부분은 단지 백테스트 계산 결과를 표시한 것일 뿐, 실제 적용에 큰 의미가 없는 것들입니다. 예를 들어 계좌 자본 요건, 보유 소득, 신뢰 한도 등이 있습니다. 중요한 것에만 집중해야 할 수도 있습니다. 아래에서는 백테스트 성과 지표 중 가장 중요한 지표를 선택하여 자세한 설명을 드리겠습니다.
중요한 성과 지표
최대 인출액
최대 하락률 계산 공식은 위와 같습니다. 모델에 있어서 최대 하락률은 변동성보다 더 중요한 매우 중요한 위험 지표입니다. 백테스트에서 나타난 최대 하락률은 어떤 의미에서는 포지션을 개설한 후 발생할 수 있는 최악의 상황을 나타냅니다.
수학적 관점에서, 자본이 20% 손실되면, 나머지 자금은 원래 자본 규모를 회복하기 위해 25%의 이익을 내야 합니다. 손실이 50%이면, 나머지 자금은 손실 전 자본 규모를 회복하기 위해 100%의 이익을 내야 합니다.
그러면 손실이 클수록 최초 자본 규모로 회복할 가능성은 작아지고 어려움도 커질 것은 의심의 여지가 없습니다. 펀드의 상승 수익 공간은 무제한이지만, 하락 손실 공간은 제한되어 있으며, 바닥을 칠 가능성이 더 큽니다.
어떻게 정의되든 적어도 다음 두 가지 사항이 현재 주류를 이루고 있습니다.
- 최대 되돌림 폭이 작을수록 좋습니다.
- 드로다운은 위험에 직접 비례합니다. 드로다운이 클수록 위험이 커지고 드로다운이 작을수록 위험이 작아집니다.
조정된 수익률 대 위험 비율(RAROC)
많은 사람들이 이 개념에 익숙하지 않습니다. 사실, 조정된 수익률-위험 비율은 프로 선수와 아마추어 선수 사이의 분수령입니다. 이는 투자은행, 대형 펀드, 전문 트레이더에게도 매우 유용한 평가 도구이며, 글로벌 금융 분야에서 널리 사용되는 평가 기준입니다.
투자에서는 수익만 보는 게 아니라, 이러한 수익을 얻기 위해 얼마나 많은 위험을 감수했는지도 고려해야 합니다. 일반적으로 자산의 위험과 수익은 비례합니다. 즉, 모델이 수확량 면에서 선두를 달리고 급속한 진전을 이루고 있을 때, 그 영광스러운 모습 뒤에 아직 드러나지 않은 위험이 숨겨져 있을 수 있다는 의미입니다.
예를 들어, 모델에서 포지션의 개폐 조건이나 증감 조건은 시장이 상승할 때는 수익률이 높지만, 하락하면 손실이 배가되어 엄청난 손실로 이어질 수 있습니다. 게다가 상승과 하락은 상당한 비대칭적 영향을 미칩니다.
많은 숙련된 양적 트레이더는 위험을 줄이기 위해 일부 수익을 희생할 의향이 있습니다. 이 경우 위험 조정 수익은 참고용으로 더 가치가 있습니다. 따라서 백테스팅에서 높은 수익률을 가지고 있더라도 위험과 변동성이 높은 모델은 반드시 좋은 모델이라고 할 수 없습니다.
예금은 안전하지만 연 수익률은 2%에 불과합니다. 시장은 며칠 만에 50%의 수익을 낼 수도 있고, 며칠 만에 50%의 손실을 낼 수도 있습니다. 수년간의 거래 경험을 통해 저는 매우 중요한 개념을 얻었습니다. 위험에 직면하세요. 위험과 수익은 결코 고립되어 존재하지 않습니다. 거래는 바다로 나가서 낚시를 하는 것과 같습니다. 낚시를 할 수는 없지만 바다의 위험을 감수하고 싶지는 않습니다. 너무 보수적인 것과 너무 급진적인 것은 실제로 두 가지 극단입니다. 전략 모델을 설계하는 데도 마찬가지입니다.
거래수
몇 달간의 백테스트 성과를 사용해 모델을 증명할 수는 없습니다. 백테스트 데이터가 너무 적으면 백테스트 결과가 우연적일 수 있는데, 매개변수가 우연적이거나 시장 조건이 우연적일 수 있습니다. 또한, 더 긴 역사적 데이터를 통해 생존자 편향을 일부 걸러낼 수도 있습니다.
일반적으로 국내 주식 및 상품의 경우 5년 이상의 백테스팅이 필요하고, 신규 상장 상품의 경우 최소 3년 이상의 백테스팅이 필요합니다. 국제 시장에서 금이나 미국 달러 지수와 같이 이전에 상장된 제품이나 상품의 경우, 적어도 한 번의 상승-하락 주기를 백테스트해야 하며, 이는 일반적으로 10~15년 이상이어야 합니다. 백테스팅 기간은 백테스팅 결과의 신뢰성이 충분할 만큼 길어야 합니다. 이러한 요구 사항을 충족하지 않는 상품의 경우, 포지션을 개설할 때 R 값에 적절한 가중치를 두어 위험 노출을 사전에 줄여야 합니다.
평균 이익
평균 이익 지표는 평범해 보이지만 실제로는 매우 중요합니다. 계산 방법도 매우 간단합니다. 순이익 / 거래 건수입니다. 표면적으로는 밝게 보이는 백테스트 성과를 감지할 수 있는 거울이라고 해도 과언이 아닙니다. 아래 그림에서 보듯이, 이런 전략으로 돈을 벌 수 있다면 비정상적이다.
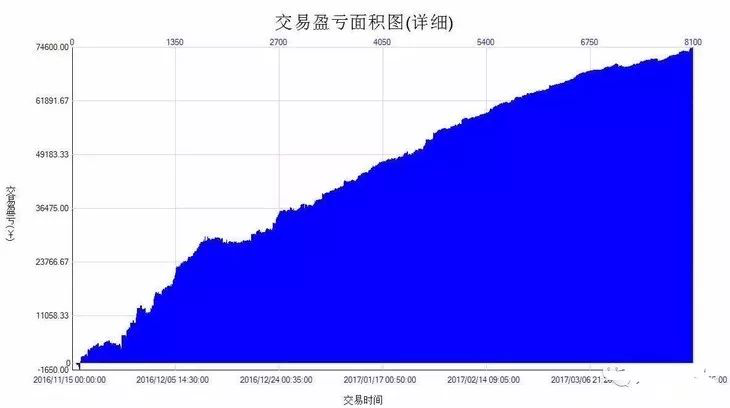
그림 5-18
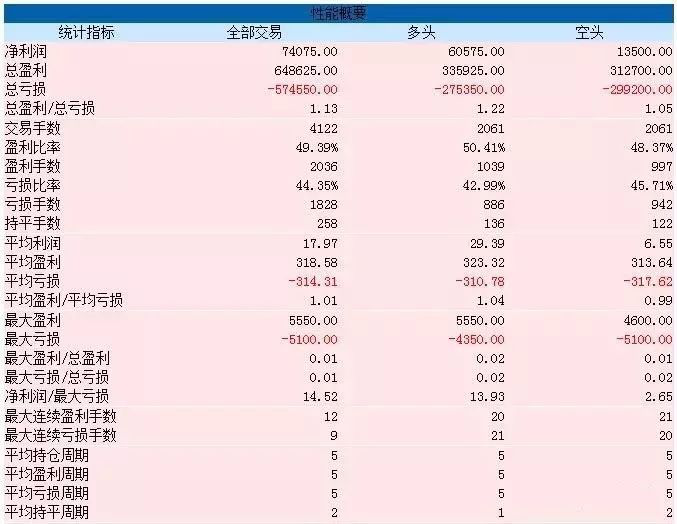
그림 5-19
이 전략의 백테스트 성과를 보면 이런 의문이 생길 수 있습니다. 이렇게 완벽에 가까운 전략을 사용하지 않는 게 아쉽지 않을까요? 잠깐 기다려요! 두 번째 그림에서 평균 이익을 주의해서 살펴보면 17위안에 불과합니다. 즉, 각 거래에서 얻는 평균 이익은 17위안에 불과하다는 뜻입니다.
예를 들어 10위안의 점프가 있는 선물 시장 상품의 대부분을 살펴보자. 실제 거래를 해본 사람이라면 누구나 그것이 무슨 뜻인지 이해할 것이다. 실제 거래에서는 한 번의 점프는커녕, 열 번, 여덟 번까지도 가능합니다. 두 번 점프하는 것과 세 번 점프하는 것이 일반적이다.
승률
승률은 결코 단독으로 존재하지 않으며, 승률만으로 문제를 논하는 것은 비현실적이다. 적절한 시장에서 적절한 모델을 사용하면 80%의 승률을 달성하는 것은 놀라운 일이 아니지만 이는 아무런 의미가 없습니다.
가격은 오르거나 내리거나, 그렇지 않으면 그대로 유지됩니다. 시간이 충분히 길면 가격이 오르거나 떨어질 확률이 각각 50%가 됩니다. 어떤 유형의 전략 모델을 사용하든 백테스팅 중에 승률이 50%를 초과하면 조심해야 합니다. 수학적, 물리적 관점에서 보면 이는 불가능합니다.
자세한 주식 곡선
속담처럼, 그림은 천 마디 말보다 가치가 있다. 자세한 주식 곡선은 차트의 첫 번째 진입 시간부터 마지막 막대 시간까지 시작됩니다. 거래를 위한 실시간 주식 곡선입니다. 각 막대의 변동 손익을 고려하기 때문에 실시간입니다.
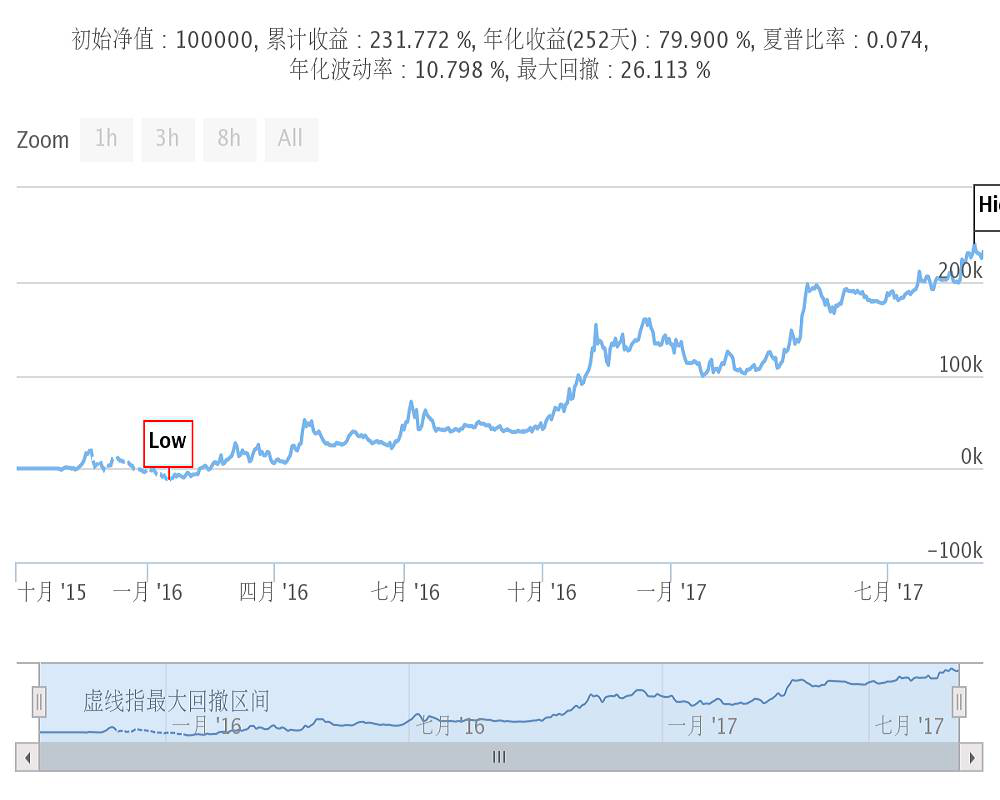
그림 5-20
자세한 자본 곡선은 계정의 순 가치 변화를 반영하며 가장 직관적인 평가 도구입니다. 이를 통해 전략의 손실 및 수익 상태와 수익 및 손실의 변동성/원활성을 한눈에 파악할 수 있습니다. 하지만 전략 성과 보고서에 대한 이런 설명은 천 마디의 말보다 가치가 있을 뿐만 아니라, 수백만 명의 신봉자들을 혼란스럽게 합니다. 또한, 마감 주가 곡선을 절대 보지 마세요.
연간 수익률
연간 수익률은 논란의 여지가 있는 지표입니다. 어떤 사람들은 그것이 일반인이 보는 것이고 참조 가치가 없다고 생각합니다. 우선 모델이 선정되기 위해서는 수익을 내는 것이 전제 조건입니다. 다시 말해 모델 수익 자체에 긍정적인 기대값이 있어야 합니다.

그림 5-21
100% 수익률은 셀 수 없이 많을 수 있지만, 100% 수익률은 최대 한 번만 누릴 수 있습니다. 연간 수익률과 실제 수익률(보유 기간 수익률) 사이의 격차는 매우 클 수 있으며, 때로는 우리가 상상하는 것보다 더 클 수도 있습니다.
요약하다
마지막으로, 한 가지 설명이 필요합니다. 완벽한 백테스팅 성능은 존재하지 않습니다. 테스트 데이터 자체의 문제 외에도 모델 사용자는 더 많은 함정에 직면할 수 있습니다. 매개변수 최적화에서 거래 설계에 이르기까지 모든 것이 실제 작업과 다를 수 있습니다.
더 중요한 것은 실행 레벨에서의 감정적 문제가 모델을 프로덕션에 투입하는 데 있어 X 요인이라는 것입니다. 실제 트레이딩은 "감정적 진공" 환경에서 실행할 수 없으며, 뚱뚱한 꼬리 현상은 모든 프로그래밍 트레이더가 항상 경계해야 할 것입니다.
숙제
- 백테스팅에서 가장 중요하다고 생각하는 성과 지표를 나열하세요.
- 샤프 비율 지표를 계산해보세요
5.4 샘플 외부 테스트가 필요한 이유
요약
이전 섹션에서는 전략 백테스팅 성과 보고서를 이해하는 방법을 알려주기 위해 몇 가지 중요한 성과 지표에 초점을 맞추었습니다. 사실, 백테스팅을 통해 돈을 벌 수 있는 전략을 작성하는 것은 가장 어려운 일이 아닙니다. 더 어려운 것은 이 전략이 실제 거래에서 계속 효과적인지 평가하는 방법입니다. 오늘은 여러분께 샘플 외부 테스트와 그 중요성에 대해 설명드리겠습니다.
백테스팅은 실제 거래와 다릅니다
양적 투자 초보자 중에는 겉보기에 좋은 성과 보고서나 백테스트에서 얻은 자본 곡선에 근거해 자신의 거래 전략에 쉽게 확신을 갖고, 시장에서 자신의 재능을 보여줄 준비가 되어 있는 사람이 많습니다. 물론, 이러한 백테스트 결과는 그들이 관찰한 특정 시장 상황과 완벽하게 일치할 수 있지만, 이러한 거래 전략을 장기간 실제로 적용해보면 이 전략이 사실 효과적이지 않다는 것을 알게 될 것입니다.
저는 백테스트를 실시한 결과, 성공률이 50%가 넘는 거래 전략을 많이 봤습니다. 이렇게 승률이 높으면 손익비율도 1:1 이상일 수 있습니다. 하지만 이러한 전략을 실제로 실행에 옮기면 기본적으로 손실로 이어진다. 손실에는 여러 가지 이유가 있는데, 그 중 하나는 백테스팅을 할 때 데이터 샘플이 너무 적어 데이터 편향이 발생한다는 것입니다.
하지만 트레이딩은 정말 복잡한 일입니다. 돌이켜보면 매우 명확하지만, 다시 원점으로 돌아가면 여전히 손해를 보게 됩니다. 여기에는 정량화의 근본적인 문제, 즉 과거 데이터의 한계가 관련됩니다. 따라서 거래 전략을 시험하기 위해 제한된 과거 데이터만을 사용한다면, "후방 거울을 보면서 운전하는" 문제를 피하기 어려울 것입니다.
샘플 외부 검사란 무엇입니까?
데이터가 제한적일 때, 어떻게 하면 제한된 데이터를 최대한 활용해 거래 전략을 과학적으로 검증할 수 있을까요? 답은 샘플 외부 테스트입니다. 백테스팅 시, 과거 데이터는 시간 순서에 따라 두 섹션으로 나뉩니다. 첫 번째 데이터 섹션은 전략 최적화에 사용되며 트레이닝 세트라고 하며, 두 번째 데이터 섹션은 샘플 외부 테스트에 사용되며 테스트 세트라고 합니다.
전략이 항상 효과적이라면, 훈련 세트 데이터에서 최상의 매개변수를 최적화하고 이러한 매개변수를 백테스팅을 위해 테스트 세트 데이터에 적용합니다. 이상적으로, 백테스팅 결과는 훈련 세트의 결과와 비슷하거나 합리적인 범위 내에 있어야 합니다. 이는 이 전략이 비교적 효과적임을 보여줍니다.
그러나 어떤 전략이 테스트 세트에서는 좋은 성과를 보이지만 테스트 세트에서는 성과가 좋지 않거나, 성과가 크게 다르고 다른 매개변수에도 동일한 상황이 적용되는 경우 해당 전략에 데이터 수용 편향이 있을 수 있습니다.
예를 들어, 상품 선물 철근에 대한 백테스트를 하고 싶다고 가정하고, 철근에 대한 약 10년 분의 데이터(2009-2019)가 있다고 가정합니다. 그러면 2009년부터 2015년까지의 데이터를 훈련 세트로 사용하고, 2015년부터 2019년까지의 데이터를 테스트 세트로 사용할 수 있습니다. 예를 들어, 이중 이동 평균 전략의 경우, 학습 세트에서 가장 우수한 매개변수 그룹은 (15기간 이동 평균과 90기간 이동 평균), (5기간 이동 평균과 50기간 이동 평균), (10기간 이동 평균과 100기간 이동 평균)...입니다. 그런 다음 이러한 매개변수 그룹을 백테스팅을 위한 테스트 세트에 넣고, 학습 세트와 테스트 세트의 백테스팅 성과 보고서와 자본 곡선을 비교하여 그 차이가 합리적인 범위 내에 있는지 확인합니다.
샘플 외부 테스트를 사용하지 않고 2009년부터 2019년까지의 데이터를 직접 사용하여 전략을 백테스트하는 경우, 과거 데이터를 맞추었기 때문에 결과는 좋은 백테스트 성과 보고서와 자본 곡선이 될 수 있습니다. 그러나 이러한 백테스트 결과는 실제 거래에 거의 의미가 없으며, 특히 매개변수가 더 많은 전략의 경우 지침 역할이 없습니다.
고급 샘플 외부 테스트
과거 데이터를 두 부분으로 나누고 샘플 내 및 샘플 외 백테스팅을 수행하는 것 외에도 실제로 더 나은 옵션이 있는데, 바로 재귀적 백테스팅과 교차 백테스팅 방법입니다. 특히 최근 몇 년 사이에 상장된 원유선물이나 사과선물처럼 과거 데이터가 부족한 경우, 이 두 가지 방법을 사용하면 제한된 데이터로 모델을 종합적으로 검증할 수 있습니다.
순차적 검사의 기본 원칙: 이전보다 긴 역사 데이터를 사용하여 모델을 훈련시키고, 그 다음보다 비교적 짧은 데이터를 사용하여 모델을 검증한 다음, 데이터를 얻는 창을 계속 뒤로 이동하여 훈련과 검증의 단계를 반복한다.
훈련 데이터: 2000년부터 2001년까지, 테스트 데이터: 2002년까지
훈련 데이터: 2001년부터 2002년까지, 테스트 데이터: 2003년까지
훈련 데이터: 2002년부터 2003년까지, 테스트 데이터: 2004년까지
훈련 데이터: 2003년부터 2004년까지, 테스트 데이터: 2005년까지
훈련 데이터: 2004년부터 2005년까지, 테스트 데이터: 2006년까지
그리고...
마지막으로, 전략의 성과를 종합적으로 평가하기 위해 [2002년, 2003년, 2004년, 2005년, 2006년...]의 테스트 결과를 통계적으로 분석합니다.
다음 그림과 같이, 직관적으로 설명할 수 있는 역설적 검사의 원리:
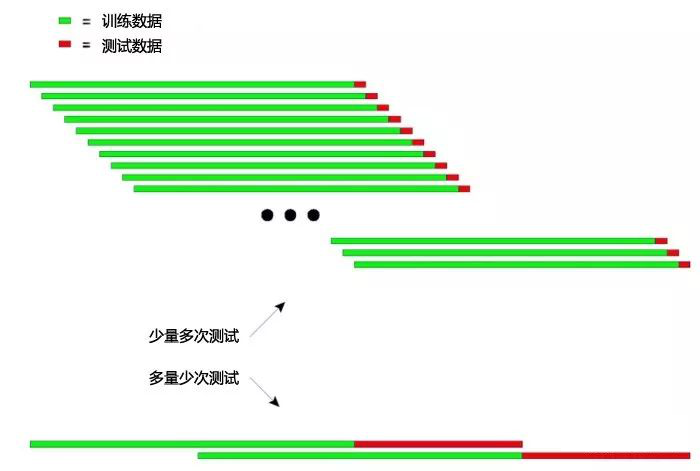
그림 5-22
위 그림은 각각 2가지의 추론 검사를 보여준다.
첫 번째: 매번 테스트 할 때, 테스트 데이터가 짧고 테스트 횟수가 많습니다.
두 번째 유형: 각 검사시, 테스트 데이터가 더 길고, 테스트 횟수가 더 적다.
실제 적용에서는 테스트 데이터의 길이를 변경할 수 있으며, 비정상적 데이터를 처리하는 모델의 안정성을 확인하기 위해 여러 번의 테스트를 수행할 수 있습니다. 교차 검증의 기본 원리는 모든 데이터를 N개의 동일한 부분으로 나누고, 매번 N-1개의 부분을 학습에 사용하고, 나머지 부분을 테스트에 사용하는 것입니다.
2000년에서 2003년까지의 해별로 나누어 4개의 부분으로 나누었다. 그 교차 검증의 동작 과정은 다음과 같다:
1 훈련 데이터: 2001-2003, 테스트 데이터: 2000;
2, 훈련 데이터:2000-2002, 테스트 데이터:2003;
3, 훈련 데이터:2000, 2001, 2003, 테스트 데이터:2002;
4 훈련 데이터:2000, 2002, 2003, 테스트 데이터:2001;
그림 5-23
위 그림에서 볼 수 있듯이: 크로스 테스트의 가장 큰 장점은 제한된 데이터를 충분히 활용하는 것이며, 각 훈련 데이터 역시 테스트 데이터이다. 그러나 크로스 테스트를 전략 모델의 테스트에 적용할 때 명백한 단점도 존재한다:
- 가격 데이터가 평탄하지 않을 때, 모델의 테스트 결과는 신뢰할 수 없습니다. 예를 들어, 2008 년 데이터를 사용하여 훈련하고 2005 년 데이터를 사용하여 테스트합니다. 2005 년과 비교하여 2008 년 시장 환경이 많이 변했을 가능성이 높으므로 모델 테스트 결과는 신뢰할 수 없습니다.
2, 제 1항과 마찬가지로, 크로스 테스트에서 최신 데이터 트레이닝 모델을 사용하여 오래된 데이터 테스트 모델을 사용하는 것은 그 자체로 논리적으로 맞지 않습니다.
또한, 대칭적 전략 모형을 검사할 때, 역설적 검사와 교차적 검사 모두 데이터 중복 문제가 발생한다.
거래 전략 모델을 개발할 때, 대부분의 기술 지표는 일정 길이의 역사적 데이터를 기반으로 한다. 예를 들어, 트렌드 지표를 사용하여 지난 50 일간의 역사적 데이터를 계산하고, 다음 거래 날에는 거래 날보다 50 일 전의 데이터를 계산하면 두 지표의 데이터가 49 일 동안 동일하게 계산되며, 이는 인접한 2 일마다 지표의 변화가 눈에 띄지 않는다.
그림 5-24
데이터 중복은 다음과 같은 결과를 초래합니다.
- 모델이 예측한 결과가 느리게 변하면 지주도도 느리게 변하게 됩니다. 이것이 우리가 흔히 말하는 지표의 지연성입니다.
- 모델 결과 검사에 대한 일부 통계 값은 사용할 수 없으며, 반복된 데이터로 인한 시퀀스 관련성이 있기 때문에 일부 통계 검사 결과가 신뢰할 수 없습니다.
좋은 거래 전략은 미래에도 수익을 낼 수 있어야 합니다. 객관적으로 거래 전략을 테스트하는 것 외에도 샘플 외부 테스트는 양적 거래자의 시간을 효율적으로 절약할 수도 있습니다. 대부분의 경우, 모든 샘플의 최적의 매개변수를 직접 채택하여 실제 전투에 적용하는 것은 매우 위험합니다.
매개 변수 최적화 시점 이전의 모든 역사 데이터를 구분하여 샘플 내 데이터와 샘플 외부 데이터로 나누고, 먼저 샘플 내 데이터를 사용하여 매개 변수 최적화를 하고, 이후 샘플 외부 데이터를 사용하여 샘플 외부 테스트를 한다면, 이러한 오류를 정렬할 수 있으며, 동시에 최적화 후의 전략이 미래 시장에 적용되는지 확인할 수 있다.
요약하다
거래와 마찬가지로, 우리는 시간을 가로질러 스스로에게 조금도 잘못되지 않은 올바른 결정을 내릴 수 없습니다. 만약 신의 손이나 미래를 가로질러 돌아오는 능력이 있다면, 테스트를 거치지 않고, 직접 온라인 실리콘 거래도 할 수 있습니다. 그리고 나는 역사적인 데이터에서 우리의 전략을 검사해야합니다.
하지만 아무리 엄청난 양의 역사적 데이터가 있다 하더라도, 광활하고 끝이 없으며 예측 불가능한 미래에 비하면 극히 부족한 것처럼 느껴진다. 따라서 역사에 기초하여 하향식으로 개발된 거래 시스템은 결국 시간이 지남에 따라 침몰하게 될 것입니다. 역사가 미래를 고갈시킬 수는 없기 때문이다. 따라서 완전한 긍정적 기대 거래 시스템은 내부 원칙과 논리에 의해 뒷받침되어야 합니다.
“신뢰하되, 확인하라” - 레이건 대통령
숙제
- 실제 생활에서 생존자 편향의 예로는 어떤 것이 있습니까?
- 발명가의 정량적 도구를 사용하여 인샘플과 아웃샘플을 모두 백테스트하고 차이점을 비교합니다.
5.5 거래 전략 최적화 및 최적화
요약
거래 전략의 본질은 시장 규칙의 일반화와 결론입니다. 시장에 대한 이해가 깊을수록, 그리고 코드로 아이디어를 표현하는 능력이 높을수록, 당신의 전략은 시장에 더 가까워질 것입니다. 이 섹션에서는 거래 전략을 최적화하는 방법과 실제 거래를 위한 최종 준비를 하는 방법에 대해 설명합니다.
진입 및 종료 최적화
대부분의 추세 추적 전략은 돌파구나 기술적 지표를 사용하여 시장 추세를 포착합니다. 일반적으로 이러한 신호의 진입 및 종료 방법은 시기적절하지 않습니다. 전략이 종가 모델을 사용하는 경우 진입 시점은 다음 K-라인의 시가가 됩니다. 따라서 이 K-라인을 돌파하기 위한 최상의 진입 시점을 놓치게 되고 많은 이익을 놓치게 됩니다.
따라서 효과적인 방법은 전략 구현 시 더욱 유리한 실시간 가격을 활용하고 신호가 나타나면 즉시 주문을 내는 것입니다. 이런 식으로 신호가 확립되면 즉시 시장에 진입하여 수익을 놓치지 않을 수 있습니다. 하지만 모든 실시간 가격이 종가보다 나은 것은 아닙니다. 이는 거래 전략에 따라 달라집니다. 간단한 거래 논리를 적용한 일부 전략의 경우 실시간 가격과 종가의 차이가 비교적 작습니다. 그러나 종가 모델은 더 세부적인 거래 로직을 처리할 수 없으므로 실시간 가격을 사용해야 합니다.
변수 최적화
매개변수 최적화를 통해 양적 거래 전략을 과거 데이터에 더 가깝게 만들고 더 나은 백테스팅 성과를 얻을 수 있습니다. 예를 들어: 우리는 철근 계약에서 이중 이동 평균 전략을 사용하지만, 어떤 두 가지 이동 평균이 가장 좋은가요? 그런 다음 발명가의 정량적 도구에서 매개변수 조정 기능을 사용하여 가장 적합한 두 개의 이동 평균 매개변수를 자동으로 찾을 수 있습니다.
아래 그림에서 보듯이, 이중 이동 평균 전략을 예로 들면, 그 자체가 다차원 인스턴스입니다. 각 매개변수의 백테스트 결과를 점으로 그리면(아래 그림 참고), 각 매개변수는 이 전략의 차원이며, 궁극적으로 모든 매개변수 조합은 이 복잡한 다차원 표면 모양(산과 같음)을 구성합니다.
그림 5-25
위에 표시된 대로, 이것은 이중 매개변수 전략 성과 차트입니다. 매개변수가 변경됨에 따라 최종 수익률도 크게 변경되고 표면이 심하게 왜곡되어 높이가 다른 "피크"와 "저점"이 형성됩니다. 일반적으로 최적화 결과에서 첫 번째 순위는 전체 표면에서 가장 높은 지점입니다. 그러나 매개변수 민감도, 객관성 등의 관점에서 볼 때 이 결과가 '최적'이 아닐 수도 있습니다. 시장은 끊임없이 변화하기 때문입니다.
따라서 매개변수 최적화의 중요한 원칙은 매개변수 섬이 아닌 매개변수 고원을 선택하는 것입니다. 매개변수 플래토(parameter plateau)라고 불리는 것은 전략이 좋은 성과를 달성할 수 있는 더 넓은 매개변수 범위가 존재한다는 것을 의미합니다. 일반적으로 평원 중심을 기준으로 정규분포를 이룹니다. 소위 매개변수 섬은 매개변수 값이 매우 작은 범위 내에 있을 때만 전략이 좋은 성과를 보인다는 것을 의미합니다. 매개변수가 이 값에서 벗어나면 전략의 성과가 상당히 저하됩니다.

그림 5-26
매개변수 플래토
위의 그림을 예로 들면, 좋은 전략 매개변수 분포는 매개변수 평탄부여야 합니다. 매개변수 설정이 벗어나더라도 전략의 수익성은 여전히 보장될 수 있습니다. 이러한 매개변수는 매우 안정적이기 때문에 향후 실제 운영에서 다양한 시장 상황에 직면했을 때 전략을 보다 보편화할 수 있습니다.

그림 5-27
매개변수 섬
위의 그림을 예로 들면, 백테스트 성과가 매개변수 섬을 보여주는 경우 매개변수가 약간 이동하면 전략의 수익성이 크게 감소합니다. 이러한 매개변수는 보편성이 낮아 실제 거래에서 끊임없이 변화하는 시장 상황에 대처하기 어려운 경우가 많습니다.
따라서 근처 매개변수의 성능이 최적 매개변수의 성능보다 훨씬 나쁘다면, 이 최적 매개변수는 과대적합의 결과일 수 있으며, 과대적합은 수학적으로 찾고 있는 최대 해가 아닌 단일 해로 간주될 수 있습니다. 수학적 관점에서 특이점은 불안정합니다. 미래의 불확실한 시장 상황에서 시장 특성이 바뀌면 최적의 매개변수가 최악의 매개변수가 될 수 있습니다.
필터 추가
많은 트렌드 전략은 트렌드를 잘 파악하고 시장이 트렌드를 따라갈 때 풍부한 수익을 얻을 수 있습니다. 그러나 장기적으로 최종 결과는 작은 이익 또는 손실입니다. 문제는 무엇일까요?
그 이유는 이 전략이 변동성 있는 시장에서 반복적으로 거래를 계속하고, 변동성 있는 거래의 대부분이 손실 또는 소액 수익이기 때문입니다. 시장은 약 70%의 시간 동안 변동성 있는 시장에 있습니다. 장기적으로 지속적인 소액 손실은 이전의 모든 수익 손실로 이어집니다.
그림 5-28
해결책은 필터를 추가하는 것입니다. 시중에는 손익 필터, 위험 가치 필터, 추세 패턴 필터, 기술 지표 필터 등 다양한 종류의 필터가 있습니다. 예를 들어, 장기 이동 평균 필터를 추가하면 변동성이 큰 시장에서 거래 건수를 줄이고 오류가 있는 거래의 절반을 걸러낼 수 있습니다.
자금 조달 곡선을 매끄럽게 하기
양적화는 안정적이고 지속 가능한 수익 방법을 추구하는데, 이것이 대부분의 트레이더가 보고 싶어하는 것입니다. 아무도 올해 50%를 벌고, 내년에 30%를 잃고, 그 다음 해에 40%를 벌고 싶어하지 않습니다. 그들은 오히려 연간 20%의 수익률을 받아들이겠지만, 그것은 10년 이상 지속될 수 있습니다. 이것이 바로 양적 투자로 할 수 있는 일입니다. 양적 투자는 지속가능한 성과를 내는 거래 모델이기 때문입니다.
원활한 자본곡선을 이루기 위해서는 다양한 전략, 다양한 종류, 다양한 사이클, 다양한 매개변수를 갖춘 투자 포트폴리오를 구성하는 것이 필요합니다. 하지만 더 많은 것이 반드시 더 나은 것은 아닙니다. 여기에는 감소하는 한계 효과가 있습니다. 처음에 포트폴리오에 더 많이 추가할수록 다각화가 더 좋아집니다. 그러나 전략이 특정 수준에 도달하면 다각화의 수익률 감소 효과가 나타나기 시작합니다. 조합의 장점은 다양화입니다. 전체 수익률은 가장 높지는 않지만 가장 안정적입니다.
성배 탐색을 포기하세요
양적 거래가 성배를 찾을 수 있을지 여부는 많은 거래자가 궁금해하는 질문입니다. 일부 트레이더는 간단한 백테스트를 거친 후 소위 완벽한 전략을 내세워 시장에 뛰어들기도 합니다. 저는 모든 전투에서 승리하고 모든 장애물을 극복할 수 있는 전문적인 수량 분석가가 되기를 바랍니다.
하지만 성배가 존재할까요? 사실 매우 간단합니다. 답은 '아니요'입니다. 사실, 이해하기 어렵지 않습니다. 이 시장에 정말로 규칙이 있다면, 더 높은 IQ, 더 높은 교육, 더 열심히 일하는 사람들은 규칙을 발견할 수 있을 것입니다. 그들이 수학적 분석, 정보 독점 또는 다른 분석 방법을 사용하든, 그들은 결국 시장에서 대부분의 돈을 벌 것입니다. 장기적으로, 이 사람들은 시장이 더 이상 정상적으로 작동할 수 없을 때까지 거래 시장을 독점할 것입니다.
요약하다
거래 시간이 충분히 길다면, 거래 과정에서 누구나 다양한 시장 동향에 직면할 수 있으며, 이러한 동향이 정확히 반복될 가능성은 낮습니다. 양적 트레이더로서 자신의 트레이딩 전략을 올바르게 검토하고 최적화하는 것 외에도 시장 상황을 지속적으로 모니터링하고 시장 변화에 대응해 전략을 지속적으로 개선해야 합니다.
동시에, 수익과 손실은 같은 출처에서 나온다는 것을 깨달아야 합니다. 손실은 전체 거래 전략의 일부입니다. 가장 좋은 거래 전략조차도 일련의 하락을 경험할 수 있습니다. 모든 거래에서 손실이 발생할 때, 거래 규칙과 전략에 의문을 제기해서는 안 됩니다. 적어도 처음부터 논리적 프레임워크가 잘못되지 않은 이상 전략적 논리적 프레임워크를 쉽게 바꾸지 마세요.
숙제
- 자신의 전략의 특성에 맞는 투자 포트폴리오를 구성하고 발명가의 양적 도구를 사용하여 백테스트를 실시합니다.
- 본 섹션의 내용을 토대로 양적 거래 전략을 최적화해보세요.
5.6 확률적 사고를 구축하고 거래 패턴을 개선하세요
요약
거래는 과학이자 예술입니다. 거래에는 가치 투자, 기술적 분석, 이벤트 핫스팟, 차익거래 헤지 등 다양한 방법이 있으며, 표면적으로는 논리적으로 엄격해 보이지만 이론적으로는 타당해 보입니다. 하지만 실제로는 종종 모순됩니다. 때때로 과학의 엄격함은 예술의 거친 상상력을 설명할 수 없습니다.
다양한 거래 방식이 시작점은 다르지만 모든 길은 로마로 통한다. 가치 투자의 장점은 가치에 따른 가격 변동에 대비해 안전 마진을 설정할 수 있다는 점이며, 기술적 분석의 장점은 세 가지 주요 가정을 통해 거래가 과학적으로 이루어진다는 점입니다.
하지만 이러한 방법에는 공통적인 특징이 하나 있습니다. 즉, 미래의 가격 분석에 대해 대략적인 예측만 할 수 있고 정확한 예측은 할 수 없다는 것입니다. 기본 분석과 기술적 분석을 합치더라도 '정밀도' 향상 문제는 해결할 수 없으므로 트레이딩은 처음부터 끝까지 확률 게임입니다.
행운의 게임
사실, 거래는 단순히 확률 게임이 아닙니다. 인생에서 도로를 건너는 것과 같은 사소한 일(신호가 초록불인데, 지금 도로를 건너도 안전한가요?)부터 어떤 친구를 사귈지(이 친구가 믿을 만한가요?)까지, 어떤 직업을 추구할지(전문 트레이딩이 정말 좋은 직업일까요?)와 누구와 결혼할지(함께 행복할까요?)와 같은 큰 일까지, 모두 위험과 수익을 평가하는 확률 게임입니다. 우리는 미래를 예측할 능력이 없기 때문에, 아무리 자신감이 있어도 무엇을 할 때마다 항상 위험이 따르고 100% 확신할 수는 없습니다.
많은 사람들이 거래에서 실수를 하는 중요한 이유 중 하나는 확률적 사고방식이 부족하고 거래할 때 합리적이기보다 너무 감정적으로 행동하기 때문입니다. 감정은 사실 우리의 원초적인 본능입니다. 시장에서 이러한 원초적인 본능은 인간의 많은 약점을 자극하고 기하급수적으로 증폭시킬 수 있습니다. 대부분의 사람들이 시장에 진출해서 실패하는 이유가 바로 이겁니다.
거래 실패 이유
이유 1 : 인간의 본성 때문에
대부분의 사람들에게는 약점이 있습니다. 그들은 작은 이점을 활용하는 것을 좋아하고 작은 손실을 입는 것을 두려워합니다. 시장에서 작은 이익이 생기면 즉시 현금화하고 이익을 가지고 시장에서 나간다. 손실이 생기면 우연히 돈을 되찾기 위해 손실 포지션을 유지한다. 그 결과, 작은 손실이 천천히 누적되어 큰 손실이 된다.
가격은 오르거나 내리거나, 혹은 그대로 유지됩니다. 장기적으로 거래 수수료와 슬리피지를 고려하지 않고 돈을 벌거나 잃을 확률은 약 50%입니다. 따라서 대부분의 사람들의 거래 방법은 수익이 제한적이고 위험이 무한한 부정적인 기대 전략이 됩니다. 그들의 거래 정산 명세서는 이렇게 구성되어야 합니다: 소액 이익 >>......>>소액 이익 >>대액 손실.
현실 생활에서 이는 가난한 사람의 생각과 부유한 사람의 생각과 매우 비슷합니다. 가난한 사람들은 위험을 감수하는 것을 꺼리고 돈을 잃는 것을 두려워합니다. 저는 안정적인 수입을 제공하고 안정성을 추구하는 직업을 좋아합니다. 무언가를 해야 할지 확신이 서지 않더라도, 절대로 해서는 안 됩니다. 표면적으로 보면 이렇게 하는 데 아무런 문제가 없는 것처럼 보이지만, 그 이면에는 엄청난 기회와 위험이 도사리고 있습니다.
부자들은 위험과 수익이 항상 비례한다는 것을 알기 때문에 위험을 감수할 의향이 더 큽니다. 위험만이 기회를 낳습니다. 그들은 위험을 합리적으로 평가하고 위험이 통제 가능할 때 용감한 베팅을 합니다.
이유 2: 나는 빨리 돈을 벌고 싶어
외국의 어느 기관에서 실시한 통계에 따르면, 장기적으로 보면 대부분 산업의 순자산에 대한 연간 수익률은 15%를 넘지 못할 것으로 나타났습니다. 반면, 많은 개인 투자자들은 시장에서 15%의 수익을 냈을 때 다른 사람들에게 인사하는 게 부끄러워합니다. 사람들은 빨리 돈을 벌고 싶어하기 때문에 대량 거래와 단기 거래에 참여합니다.
무거운 위치
높은 포지션, 높은 레버리지, 자본 배분은 매우 매력적이지만 동시에 매우 위험합니다. 성공하면 성공한 것이고, 실패하면 망한 것이다. 만약 당신이 승률 50%의 거래 전략을 갖고 있고, 풀 포지션과 마진 거래를 한다면, 운이 좋다면 10회 이상 연속으로 이길 수도 있고, 당신의 재산이 양적 변화에서 질적 변화로 바뀔 가능성도 있습니다.
하지만 한 번이라도 실수를 하면 모든 것이 0으로 재설정됩니다. 자본 배분 없이 단순히 많은 포지션을 유지한 채 운영하더라도 다음 시장 상황에서 연속으로 12회 이상 손실을 보지 않을 것이라는 보장이 없기 때문에 계좌가 0이 될 위험이 있습니다. 거래량이 많을수록 원래 예상했던 거래 전략이 이익과 손실이 불평등한 전략으로 바뀔 수 있습니다.
단기
세상에서 이길 수 없는 유일한 무술은 속도이다. 트레이딩 서클에서 수동 데이 트레이딩, 일중 단기 트레이딩, 양적 고빈도 트레이딩은 항상 매우 신비로웠습니다. 저는 스톱워치를 보면서 트레이딩하는 사람들을 의심하지 않지만, 다른 관점에서 단기 트레이딩을 포기하도록 설득하려고 합니다.
어떤 방법이 실행 가능한지 판단할 때, 그 방법을 사용하여 성공한 사람들뿐만 아니라, 그 방법을 사용하여 실패한 사람들도 살펴봐야 합니다. 다시 말해, 일부 사람들이 잭팟에 당첨되었다는 이유만으로 복권을 사는 것이 긍정적인 기대를 갖는 전략이라고 가정할 수는 없습니다.
또한 지난 3년 동안 사모펀드 상품 순위를 살펴보면, 상위 100개 상품 중 일상적인 투기나 단기 거래에 참여하는 상품은 몇 개나 됩니까? 단기 투자의 성공률은 매우 낮다는 것은 의심의 여지가 없습니다. 성공하더라도 이런 빠르게 돈을 버는 방법은 장기적으로 유지하기 어렵습니다. 재능이 없다면 이런 종류의 수법을 쓸 때는 조심하세요. 결국 시몬스는 하나뿐입니다.
이유 3: 편견
가능하다면 "12 Angry Men"이라는 영화를 100분 동안 시청해 보는 것을 추천합니다. 4개국에서 리메이크된 영화입니다. 첫 번째 미국 버전은 1957년, 일본 버전은 1991년, 러시아 버전은 1997년, 중국 버전은 2014년에 제작되었습니다. 이 영화는 거래하는 법을 가르쳐 줄 수는 없지만, 사물을 바라보는 법과 자신을 알아가는 법을 가르쳐 주는데, 이는 매우 중요합니다.
인간의 경험이 제한되어 있듯이, 인간의 인지 또한 제한적입니다. 모든 사람은 자신의 경험에 따라 다소간 편견을 갖고 있습니다. 많은 경우, 편견은 대부분의 사람들에게 습관이 되었고, 그들은 많은 것을 자신의 감정에 따라 판단하는 것을 당연하게 여깁니다.
시장으로 돌아가서, 시장에 대한 당신의 판단이 기본 분석에 근거하든 기술적 분석에 근거하든 실제로는 중요하지 않습니다. 당신의 견해가 시장 대다수의 견해와 다르다면, 가격은 시장 대다수에 유리하게 형성되고, 시장은 당신의 견해대로 움직이지 않을 것입니다.
따라서 거래에서 우리는 "판단하되, 판단에 의존하지 말라"는 것을 기억해야 합니다. 궁극적으로는 사실과 가격에 기반해야 합니다. 가격을 오르내리는 유일한 힘은 대부분 사람들이 미래에 대해 어떻게 예상하느냐에 달려 있습니다. 당신의 판단은 시장에서 아무런 영향력이 없습니다. 따라서 당신의 판단이 당신의 편견을 형성하도록 내버려 두지 마십시오.
4번째 이유: 완벽함을 추구하기.
시장 참여자에는 물리학, 통계학, 수학, 천문학 등 모든 분야의 전문가가 포함됩니다. 많은 사람들이 자신의 전문 지식을 사용하여 이 시장을 설명하려고 합니다.
하지만 시장의 주요 참여자는 사람이고, 사람 자신도 인지적 한계를 가지고 있기 때문에 시장 자체가 잘못되었고 불완전하다는 뜻입니다. 그러면 이런 "완벽한" 방법을 사용해 시장을 설명하려면 어떻게 해야 할까요? 이것은 시장의 본질에 어긋나지 않나요?
위에 나열한 내용은 시장에 진출한 대부분의 사람들이 결국 실패하는 이유를 나열한 것입니다. 위에서 언급한 주요 이유 외에도 여기서 하나하나 나열하지 않은 다른 요소들이 많이 있습니다. 간단히 말해서, 승리에 대한 자신감을 제외한 나머지 모든 것은 성공을 방해하는 걸림돌입니다.
행운으로 시장에서 돈을 번 사람들은 결국 시간이 지나면서 그 돈을 시장으로 돌려주게 된다. 그러므로 선물 시장은 마이너스섬 게임이다. 성공의 가능성은 사고방식을 바꾸고 자신만의 거래 전략을 확립해야만 가질 수 있습니다.
확률적 사고란 무엇인가?
확률적 사고는 화려한 이름이지만, 간단히 말하면 도박적 사고입니다. 맞습니다. 거래는 도박입니다. 도박이라는 말을 들으면, "도박으로 모든 것을 잃은 사람, 빚 때문에 집을 떠난 사람, 가족이 없는 사람"이 떠오르고, 도박을 멀리하게 될 수도 있습니다.
사회에는 실제로 도박에 집착하는 도박꾼이 있습니다. 하지만 도박 ≠ 도박꾼. "도박"은 아마도 가장 오해받는 단어 중 하나일 것이다. 만약 당신의 전략이 부정적인 기대라면, 당신은 도박꾼입니다. 만약 당신의 전략이 긍정적인 기대라면, 당신은 도박꾼입니다.
만약 우리가 "도박"의 부정적인 의미를 제거하고 그것을 특정 수익을 위해 특정 위험을 감수하는 활동으로 이해한다면, 삶은 어디에서나 실제로 "도박"이 됩니다. 학교에서 어떤 전공을 선택해야 할지, 집을 살지 말지, 프로젝트를 시작할지, 일할지 아니면 사업을 시작할지 등.
은행에 돈을 넣는 것조차 도박이다. 미래에 인플레이션이 발생할지, 은행이 파산할지(그리스 부채 위기 참조) 확실하지 않기 때문이다. 간단히 말해서, 요람에서 무덤까지 인생의 모든 과정은 도박입니다.
장기적으로 승리하는 방법
도박의 개념에 대해서도 더 구체적으로 설명할 필요가 있습니다. 장기적으로 어떻게 이길 수 있을까요? 장기적인 승리 전략을 연구하기에 앞서, 먼저 장기적인 승리 전략의 원칙을 연구해 보겠습니다. 돈을 찍어내는 기계 외에 무엇이 장기적으로 이익을 보장할 수 있을까요?
카지노에서는 바카라, 룰렛, 슬롯머신, 블랙잭 등이 일어납니다. 플레이 방법이 어떻게 바뀌든 결국에는 카지노가 이깁니다. 사실 여기에는 카지노가 결코 말해주지 않는 비밀이 숨겨져 있습니다. 바로 대수의 법칙입니다.
Sic Bo의 작동 방식
주사위 3개, 크기에 베팅하세요. 4~10은 작고, 11~17은 큽니다. 올바르게 베팅하면 돈을 이깁니다. 시크보에는 일종의 주변 주사위가 있는데, 즉, 세 개의 주사위의 점수가 같을 때 카지노 딜러가 이깁니다. 주변 주사위가 나타날 확률은 2.8%입니다. 그러면 큰 숫자와 작은 숫자가 나올 확률은 각각 48.6%입니다. 카지노는 이 2.8% 확률에 의존합니다. 모든 도박꾼이 각 게임에서 100위안을 베팅하면 카지노는 100게임을 플레이한 후 280위안을 이깁니다.
(0.486+0.028)100100-0.486100100=280
하지만 이 카지노 전략에는 허점이 있습니다. 큰 플레이어가 변덕스럽게 수천억을 베팅하고 우연히 이기면 카지노는 갑자기 파산합니다. 따라서 카지노에서는 베팅 한도를 정해놓고, 한도를 초과할 경우 이 라운드에서는 더 이상 베팅을 할 수 없습니다. 이런 식으로, 도박꾼이 잠시 동안 돈을 이길 만큼 운이 좋더라도, 장기적으로는 여전히 확률에 지게 될 것입니다. 무한한 수의 Sic Bo 게임에서 도박꾼은 돈의 2.8%를 잃을 것입니다.
대수의 법칙
카지노 주인의 이점은 도박꾼보다 2% 더 많을 뿐입니다. 단 한 번의 도박에서 주인은 손실을 입거나 심지어 연속적인 손실을 경험할 수도 있습니다. 하지만 카지노 주인은 손실에 두려워하지 않을 것입니다. 그가 돈을 벌 수 있는 이유는 "대수의 법칙"이 작용하고 있기 때문입니다. 사람들이 계속 도박을 하는 한, 그는 장기적으로 안정적인 수익을 유지하기 위해 2%의 약간의 이점만 있으면 됩니다.
따라서 카지노는 당신이 돈을 이기는 것을 두려워하지 않지만, 당신이 오지 않을 것을 두려워합니다. 여러분은 수년에 걸쳐 은행이 파산하는 것을 들었을 것입니다. 하지만 카지노가 파산하는 것을 들어본 적이 있습니까? 장기적으로 보면 카지노는 항상 승자입니다. 이것이 도박이 장기적으로 이길 수 있는 이유입니다.
장기적으로 승리하는 비슷한 예로는 다양한 복권이 있습니다. 복권이 시작된 이래로 복권 상금 풀 기금은 점점 더 많이 축적되었으며, 이 돈은 확실히 대부분의 복권 구매자에게서 나옵니다. 더블 컬러 볼에서 500만 달러를 당첨할 확률이 얼마인지 아십니까? 답은 1,770만 분의 1입니다.
확률의 변화
양면 모두 무게가 같은 동전이 있고, 단어(뒤로) 또는 꽃(앞으로)이 나올 확률은 50%이며, 각 동전 던지기는 이전 결과와 독립적이라고 가정합니다. 동전을 10,000번 연속으로 던지면 앞면이 나올 확률은 약 50%입니다.
하지만 10번만 던진다면 양성 결과가 나올 확률이 바뀌어 확률이 50%가 되지 않을 수도 있습니다. 따라서 카지노 딜러는 이 긍정적인 기대 전략이 효과적이려면 이 긍정적인 기대 전략이 충분히 자주 발동되도록 해야 합니다. 이는 사모펀드 기관이 양적 거래 전략을 시작할 때 특별한 조건이 없는 한 그 전략을 중단할 수 없는 이유이기도 합니다.
금융 시장에서 장기적인 승리 전략을 만드는 데 "대수의 법칙"을 사용하는 방법은 다음 과정 시리즈의 내용이므로 계속 지켜봐 주시기 바랍니다!
요약하다
위에서 우리는 확률적 측면, 거래 실패 이유, 올바른 거래 사고방식, 도박에서 장기적으로 이길 수 있는 원칙 등의 관점에서 거래를 과학적으로 바라보는 방법을 설명했습니다. 저는 잘 배우면 사고방식의 변화가 행동의 변화를 가져오고, 행동의 변화가 성공으로 이어질 것이라고 믿습니다.
숙제
- 트레이딩은 왜 확률 게임인가요?
- 거래 실패의 다른 이유는 무엇입니까?


- 1