

인공지능의 강화학습을 활용해 암호화폐 거래 로봇을 만들어보자
이 글에서는 강화 학습 프레임워크를 만들고 적용하여 비트코인 거래 봇을 만드는 방법을 알아보겠습니다. 이 튜토리얼에서는 OpenAI의 gym과 OpenAI baselines 라이브러리의 포크인 stable-baselines 라이브러리의 PPO 로봇을 사용할 것입니다.
지난 몇 년 동안 딥 러닝 연구자들에게 오픈 소스 소프트웨어를 제공해준 OpenAI와 DeepMind에 진심으로 감사드립니다. AlphaGo, OpenAI Five, AlphaStar와 같은 기술로 이룬 놀라운 성과를 보지 못했다면, 지난 1년 동안 고립되어 살았을 수도 있지만, 꼭 확인해 보세요.
AlphaStar 훈련 https://deepmind.com/blog/alphastar-mastering-real-time-strategy-game-starcraft-ii/
우리가 인상적인 것을 만들지는 않겠지만, 비트코인 로봇으로 거래하는 것은 일상적인 거래에서 여전히 쉬운 일이 아닙니다. 그러나 테디 루즈벨트가 말했듯이,
너무 쉽게 얻은 것은 가치가 없습니다.
따라서 자신을 위해 거래하는 법을 배우는 것뿐만 아니라 로봇이 우리를 대신해 거래하도록 하세요.
계획

-
로봇이 머신러닝을 수행할 수 있는 체육관 환경을 만듭니다.
-
간단하고 우아한 시각화 환경을 렌더링합니다.
-
로봇이 수익성 있는 거래 전략을 학습하도록 훈련합니다.
아직 체육관 환경을 처음부터 만드는 방법이나 이러한 환경을 시각화하는 방법을 잘 모르는 경우 계속하기 전에 이와 같은 기사를 구글에서 검색해 보세요. 이 두 가지 작업은 초보 프로그래머라도 어렵지 않을 것입니다.
시작하기
이 튜토리얼에서는 Zielak이 생성한 Kaggle 데이터 세트를 사용하겠습니다. 소스 코드를 다운로드하려면 .csv 데이터 파일과 함께 Github 저장소에서 사용할 수 있습니다. 좋습니다. 시작해볼까요.
먼저, 필요한 라이브러리를 모두 가져오겠습니다. pip를 사용하여 누락된 라이브러리를 모두 설치하세요.
import gym
import pandas as pd
import numpy as np
from gym import spaces
from sklearn import preprocessing
다음으로, 환경에 맞는 클래스를 만들어 보겠습니다. 판다스 데이터프레임과 선택적으로 initial_balance, lookback_window_size를 전달해야 합니다. 이는 로봇이 각 단계에서 관찰할 과거 시간 단계의 수를 결정합니다. 거래당 수수료를 Bitmex의 현재 환율인 0.075%로 기본 설정하고, 직렬 매개변수를 false로 기본 설정합니다. 즉, 기본적으로 데이터프레임이 무작위 조각으로 탐색됩니다.
또한 데이터에 dropna() 및 reset_index()를 호출하여 먼저 NaN 값이 있는 행을 제거한 다음 데이터를 삭제했기 때문에 프레임 번호에 대한 인덱스를 재설정합니다.
class BitcoinTradingEnv(gym.Env):
"""A Bitcoin trading environment for OpenAI gym"""
metadata = {'render.modes': ['live', 'file', 'none']}
scaler = preprocessing.MinMaxScaler()
viewer = None
def __init__(self, df, lookback_window_size=50,
commission=0.00075,
initial_balance=10000
serial=False):
super(BitcoinTradingEnv, self).__init__()
self.df = df.dropna().reset_index()
self.lookback_window_size = lookback_window_size
self.initial_balance = initial_balance
self.commission = commission
self.serial = serial
# Actions of the format Buy 1/10, Sell 3/10, Hold, etc.
self.action_space = spaces.MultiDiscrete([3, 10])
# Observes the OHCLV values, net worth, and trade history
self.observation_space = spaces.Box(low=0, high=1, shape=(10, lookback_window_size + 1), dtype=np.float16)
여기서 우리의 행동 공간은 3가지 옵션(매수, 매도 또는 보유)과 또 다른 10가지 금액(1/10, 2/10, 3/10 등)으로 표현됩니다. 매수 조치를 선택하면, self.balance * amount 만큼의 BTC를 매수합니다. 판매시에는 self.btc_held * 금액만큼의 BTC를 판매합니다. 물론, 보류 동작은 금액을 무시하고 아무것도 하지 않습니다.
우리의 관찰 공간은 0과 1 사이의 연속적인 부동 소수점 집합으로 정의되며, 그 모양은 (10, lookback_window_size + 1)입니다. + 1은 현재 시간 단계를 계산하는 데 사용됩니다. 창의 각 시간 단계에 대해 OHCLV 값을 관찰합니다. 우리의 순자산은 매수 또는 매도한 BTC의 양과, 그 BTC에 지출 또는 수령한 총 USD 금액과 같습니다.
다음으로, 환경을 초기화하기 위한 reset 메서드를 작성해야 합니다.
def reset(self):
self.balance = self.initial_balance
self.net_worth = self.initial_balance
self.btc_held = 0
self._reset_session()
self.account_history = np.repeat([
[self.net_worth],
[0],
[0],
[0],
[0]
], self.lookback_window_size + 1, axis=1)
self.trades = []
return self._next_observation()
여기서는 self를 사용합니다._reset_session과 self._next_observation은 아직 정의하지 않았습니다. 먼저 정의해 보겠습니다.
거래 세션
우리 환경에서 중요한 부분은 거래 세션이라는 개념입니다. 만약 우리가 이 봇을 시장 밖에서 배포한다면, 아마도 한 번에 몇 달 이상 운영할 수는 없을 것입니다. 이러한 이유로 우리는 self.df에서 연속된 프레임의 수, 즉 로봇이 한 번에 볼 수 있는 프레임의 수를 제한할 것입니다.
_reset_session 메서드에서 먼저 current_step을 0으로 재설정합니다. 다음으로, steps_left를 1과 MAX_TRADING_SESSION 사이의 난수로 설정합니다. 이 숫자는 프로그램 맨 위에 정의합니다.
MAX_TRADING_SESSION = 100000 # ~2个月
다음으로, 프레임을 지속적으로 반복하려면 전체 프레임을 반복하도록 설정해야 합니다. 그렇지 않으면 frame_start를 self.df의 임의의 지점으로 설정하고 active_df라는 새 데이터 프레임을 만듭니다. 이 데이터 프레임은 self입니다. 슬라이스 frame_start에서 frame_start + steps_left까지의 df.
def _reset_session(self):
self.current_step = 0
if self.serial:
self.steps_left = len(self.df) - self.lookback_window_size - 1
self.frame_start = self.lookback_window_size
else:
self.steps_left = np.random.randint(1, MAX_TRADING_SESSION)
self.frame_start = np.random.randint(self.lookback_window_size, len(self.df) - self.steps_left)
self.active_df = self.df[self.frame_start - self.lookback_window_size:self.frame_start + self.steps_left]
무작위 슬라이싱에서 데이터 프레임의 개수를 반복하는 것의 중요한 부작용은 로봇이 장시간 학습할 때 사용할 수 있는 고유한 데이터가 더 많아진다는 것입니다. 예를 들어, 직렬 방식으로(즉, 0부터 len(df)까지) 데이터 프레임의 개수를 반복한다면, 우리가 갖는 고유한 데이터 포인트의 수는 데이터 프레임의 개수만큼만 됩니다. 우리의 관찰 공간은 각 시간 단계에서 극히 불연속적인 수의 상태만을 채택할 수 있습니다.
그러나 데이터 세트의 슬라이스를 무작위로 반복함으로써 초기 데이터 세트의 각 시간 단계에 대해 더 의미 있는 거래 결과 세트를 만들 수 있습니다. 즉, 거래 활동과 이전에 확인한 가격 활동을 조합하여 더 고유한 데이터 세트를 만들 수 있습니다. 예를 들어 설명해 보겠습니다.
직렬 환경을 재설정한 후 10번째 시간 단계에서 로봇은 항상 데이터 세트 내에서 동시에 실행되며 각 시간 단계 후에 매수, 매도 또는 보유의 세 가지 선택권이 주어집니다. 이 세 가지 옵션 각각에는 구체적인 구현 금액의 10%, 20%, ... 또는 100%라는 옵션이 있습니다. 즉, 우리 로봇은 103의 10제곱, 총 1030가지 상황을 겪을 수 있다는 뜻입니다.
이제 무작위 슬라이싱 환경으로 돌아가 보겠습니다. 10의 타임 스텝에서 로봇은 데이터 프레임 수 내에서 임의의 len(df) 타임 스텝에 있을 수 있습니다. 각 시간 단계 후에 동일한 선택이 이루어진다고 가정하면, 이는 로봇이 동일한 10개의 시간 단계에서 len(df)30의 고유한 상태를 거칠 수 있음을 의미합니다.
이를 통해 대규모 데이터 세트에 상당한 노이즈가 발생할 수 있지만, 저는 이를 통해 로봇이 우리가 가진 제한된 양의 데이터에서 더 많은 것을 학습할 수 있을 것이라고 생각합니다. 알고리즘의 효과성을 보다 정확하게 이해하기 위해 우리는 여전히 직렬 방식으로 테스트 데이터를 반복하여 가장 최신의, 겉보기에 '실시간'인 데이터를 얻을 것입니다.
로봇의 눈을 통해
로봇이 사용할 기능 유형을 이해하려면 주변 환경을 시각적으로 잘 살펴보는 것이 도움이 됩니다. 예를 들어, 다음은 OpenCV를 사용하여 렌더링한 관찰 가능한 공간의 시각화입니다.

OpenCV 시각화 환경 관찰
이미지의 각 행은 관찰 공간의 행을 나타냅니다. 비슷한 빈도의 빨간색 선으로 표시된 처음 4개 선은 OHCL 데이터를 나타내고, 바로 아래의 주황색과 노란색 점은 부피를 나타냅니다. 아래의 변동하는 파란색 막대는 봇의 자본이고, 그 아래의 밝은 막대는 봇의 거래를 나타냅니다.
자세히 살펴보면, 당신만의 촛대 차트를 만들 수도 있습니다. 볼륨 막대 아래에는 거래 내역을 보여주는 모스 부호와 같은 인터페이스가 있습니다. 우리의 봇은 관찰 공간의 데이터로부터 적절하게 학습할 수 있을 것 같습니다. 계속 진행해 보겠습니다. 여기서는 관찰된 데이터를 0에서 1까지 조정하는 _next_observation 메서드를 정의합니다.
- 예측 편향을 방지하기 위해 로봇이 지금까지 관찰한 데이터만 확장하는 것이 중요합니다.
def _next_observation(self):
end = self.current_step + self.lookback_window_size + 1
obs = np.array([
self.active_df['Open'].values[self.current_step:end],
self.active_df['High'].values[self.current_step:end],
self.active_df['Low'].values[self.current_step:end],
self.active_df['Close'].values[self.current_step:end],
self.active_df['Volume_(BTC)'].values[self.current_step:end],])
scaled_history = self.scaler.fit_transform(self.account_history)
obs = np.append(obs, scaled_history[:, -(self.lookback_window_size + 1):], axis=0)
return obs
조치를 취하다
이제 관찰 공간이 설정되었으니, 계단 함수를 작성한 다음 로봇이 취하려는 작업을 수행할 차례입니다. 현재 거래 세션에서 self.steps_left == 0일 경우, BTC 보유량을 매도하고 reset session()을 호출합니다. 그렇지 않은 경우, 현재 자본에 보상을 설정하거나, 자금이 부족한 경우 done을 True로 설정합니다.
def step(self, action):
current_price = self._get_current_price() + 0.01
self._take_action(action, current_price)
self.steps_left -= 1
self.current_step += 1
if self.steps_left == 0:
self.balance += self.btc_held * current_price
self.btc_held = 0
self._reset_session()
obs = self._next_observation()
reward = self.net_worth
done = self.net_worth <= 0
return obs, reward, done, {}
거래 활동을 하는 것은 현재 가격을 구하고, 수행해야 할 활동과 매수 또는 매도 금액을 결정하는 것만큼 간단합니다. _take_action을 빠르게 작성해서 환경을 테스트해 보겠습니다.
def _take_action(self, action, current_price):
action_type = action[0]
amount = action[1] / 10
btc_bought = 0
btc_sold = 0
cost = 0
sales = 0
if action_type < 1:
btc_bought = self.balance / current_price * amount
cost = btc_bought * current_price * (1 + self.commission)
self.btc_held += btc_bought
self.balance -= cost
elif action_type < 2:
btc_sold = self.btc_held * amount
sales = btc_sold * current_price * (1 - self.commission)
self.btc_held -= btc_sold
self.balance += sales
마지막으로, 같은 방법으로 self.trades에 거래를 추가하고 자본과 계좌 내역을 업데이트합니다.
if btc_sold > 0 or btc_bought > 0:
self.trades.append({
'step': self.frame_start+self.current_step,
'amount': btc_sold if btc_sold > 0 else btc_bought,
'total': sales if btc_sold > 0 else cost,
'type': "sell" if btc_sold > 0 else "buy"
})
self.net_worth = self.balance + self.btc_held * current_price
self.account_history = np.append(self.account_history, [
[self.net_worth],
[btc_bought],
[cost],
[btc_sold],
[sales]
], axis=1)
이제 로봇은 새로운 환경을 만들어내고, 그 환경을 통과하며, 환경에 영향을 미치는 행동을 취할 수 있습니다. 이제 그들이 거래하는 모습을 지켜볼 시간입니다.
로봇 거래를 지켜보세요
렌더링 방법은 print(self.net_worth)를 호출하는 것만큼 간단할 수도 있지만, 그렇게 하면 충분히 흥미롭지 않을 것입니다. 대신, 거래량 막대와 자본에 대한 별도의 차트가 있는 간단한 촛대 차트를 그릴 것입니다.
이전 기사의 StockTradingGraph.py의 코드를 가져와 비트코인 환경에 맞게 다시 작업해보겠습니다. 제 Github에서 코드를 받으실 수 있습니다.
우리가 할 첫 번째 변경은 self.df를 변경하는 것입니다.[ '날짜'] self.df로 업데이트['타임스탬프']를 사용하고 date2num에 대한 모든 호출을 제거합니다. 날짜는 이미 유닉스 타임스탬프 형식이기 때문입니다. 다음으로, 렌더 메서드에서 날짜 라벨을 업데이트하여 숫자 대신 사람이 읽을 수 있는 날짜를 인쇄합니다.
from datetime import datetime
먼저 datetime 라이브러리를 가져온 다음 utcfromtimestampmethod를 사용하여 각 타임스탬프에서 UTC 문자열을 가져오고 strftime을 사용하여 이를 Y-m-d H:M 형식의 문자열로 만듭니다.
date_labels = np.array([datetime.utcfromtimestamp(x).strftime('%Y-%m-%d %H:%M') for x in self.df['Timestamp'].values[step_range]])
마지막으로 self.df를 사용합니다.['Volume']이 self.df로 변경되었습니다.['Volume_(BTC)']을 데이터 세트와 일치시키고, 이를 통해 준비가 완료되었습니다. BitcoinTradingEnv로 돌아와서 이제 그래프를 표시하는 render 메서드를 작성할 수 있습니다.
def render(self, mode='human', **kwargs):
if mode == 'human':
if self.viewer == None:
self.viewer = BitcoinTradingGraph(self.df,
kwargs.get('title', None))
self.viewer.render(self.frame_start + self.current_step,
self.net_worth,
self.trades,
window_size=self.lookback_window_size)
바라보다! 이제 로봇이 비트코인을 거래하는 모습을 볼 수 있습니다.

Matplotlib을 사용하여 로봇의 거래 시각화
녹색 팬텀 라벨은 BTC 매수를 나타내고, 빨간색 팬텀 라벨은 매도를 나타냅니다. 오른쪽 상단 모서리의 흰색 라벨은 로봇의 현재 순자산이고, 오른쪽 하단 모서리의 라벨은 비트코인의 현재 가격입니다. 단순하고 우아함. 이제 봇을 훈련시키고 얼마나 많은 돈을 벌 수 있는지 확인할 시간입니다!
훈련 시간
제가 이전 기사에서 받은 비판 중 하나는 교차 검증이 부족하고 데이터를 훈련 세트와 테스트 세트로 분리하지 않았다는 것이었습니다. 이 작업의 목적은 이전에 본 적이 없는 새로운 데이터에 대해 최종 모델의 정확성을 테스트하는 것입니다. 해당 기사의 초점은 이것이 아니지만, 분명 중요한 내용입니다. 우리는 시계열 데이터를 다루기 때문에 교차 검증과 관련해 선택의 폭이 크지 않습니다.
예를 들어, 교차 검증의 일반적인 형태는 k-폴드 검증이라고 하는데, 이는 데이터를 k개의 동일한 그룹으로 나누고, 그룹 중 하나를 테스트 그룹으로 분리하고, 나머지 데이터를 훈련 그룹으로 사용하는 것입니다. . 그러나 시계열 데이터는 시간에 따라 크게 달라지기 때문에 나중의 데이터가 이전 데이터에 크게 의존하게 됩니다. 따라서 k-폴드는 로봇이 거래 전에 미래 데이터로부터 학습하게 되어 불공평한 이점이 있으므로 효과적이지 않습니다.
대부분의 다른 교차 검증 전략을 시계열 데이터에 적용하면 동일한 결함이 발생합니다. 따라서 우리는 프레임 번호의 시작부터 임의의 인덱스까지의 전체 데이터 프레임 중 일부만 훈련 세트로 사용하고, 나머지 데이터를 테스트 세트로 사용하면 됩니다.
slice_point = int(len(df) - 100000)
train_df = df[:slice_point]
test_df = df[slice_point:]
다음으로, 우리의 환경은 단일 프레임의 데이터만 처리하도록 설정되었으므로 훈련 데이터용 하나와 테스트 데이터용 하나, 총 두 개의 환경을 만들 것입니다.
train_env = DummyVecEnv([lambda: BitcoinTradingEnv(train_df, commission=0, serial=False)])
test_env = DummyVecEnv([lambda: BitcoinTradingEnv(test_df, commission=0, serial=True)])
이제 모델을 훈련하는 것은 환경으로 로봇을 만들고 model.learn을 호출하는 것만큼 간단합니다.
model = PPO2(MlpPolicy,
train_env,
verbose=1,
tensorboard_log="./tensorboard/")
model.learn(total_timesteps=50000)
여기에서는 텐서보드를 사용해 텐서플로우 그래프를 쉽게 시각화하고 로봇에 대한 몇 가지 정량적 지표를 살펴보겠습니다. 예를 들어, 다음은 200,000개 이상의 시간 단계에 걸쳐 많은 로봇에 대한 할인된 보상의 플롯입니다.
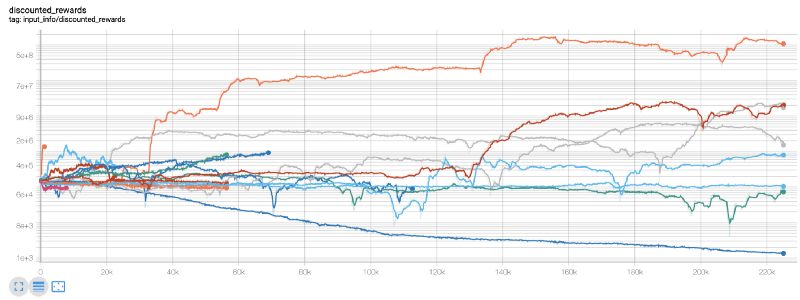
와, 우리 봇이 꽤 수익성이 있는 것 같네요! 우리의 가장 뛰어난 로봇은 20만 걸음을 걷는 동안 균형 감각이 1000배나 좋아졌고, 나머지 로봇들은 평균적으로 최소한 30배 이상 향상되었습니다!
바로 이 지점에서 저는 환경에 버그가 있다는 것을 깨달았습니다... 그것을 수정한 후, 새로운 보상 맵이 있습니다:
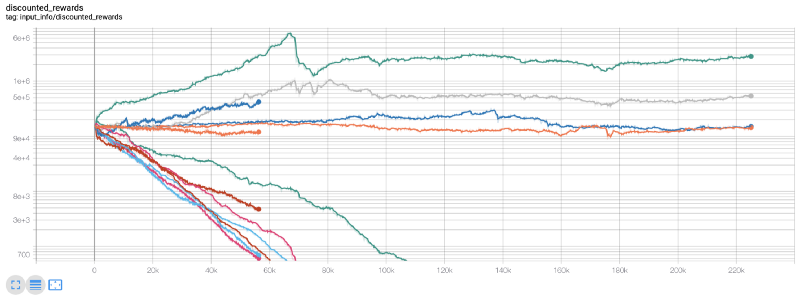
보시다시피, 우리 로봇 중 일부는 훌륭한 일을 해냈지만 나머지는 저절로 파산했습니다. 하지만 성능이 좋은 봇이라면 초기 잔액의 최대 10배, 심지어 60배까지 달성할 수 있습니다. 수익성 있는 봇은 모두 수수료 없이 훈련되고 테스트된다는 점을 인정해야겠습니다. 따라서 저희 봇이 실제 수익을 창출하는 것은 비현실적입니다. 하지만 적어도 우리는 방향을 찾았습니다!
테스트 환경(이전에 본 적이 없는 새로운 데이터)에서 봇을 테스트하고 어떤 성능을 보이는지 살펴보겠습니다.
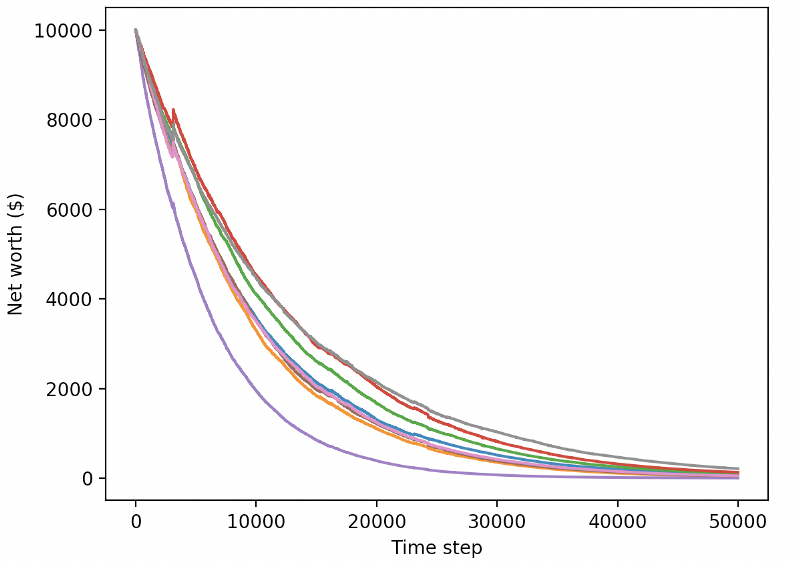
훈련된 봇이 새로운 테스트 데이터를 거래할 때 파산합니다.
분명 우리는 아직도 해야 할 일이 많습니다. 현재의 PPO2 로봇 대신 안정적인 기준선 A2C를 사용하도록 모델을 전환하기만 해도 이 데이터 세트에 대한 성능을 크게 향상시킬 수 있습니다. 마지막으로 숀 오고먼의 제안을 따라, 높은 순자산을 달성한 후 그대로 두는 대신, 순자산에 보상을 추가하는 방식으로 보상 함수를 약간 업데이트할 수 있습니다.
reward = self.net_worth - prev_net_worth
이 두 가지 변화만으로도 테스트 데이터 세트의 성능이 크게 향상되며, 아래에서 볼 수 있듯이 마침내 훈련 세트에 없었던 새로운 데이터에서도 수익성을 달성할 수 있게 되었습니다.
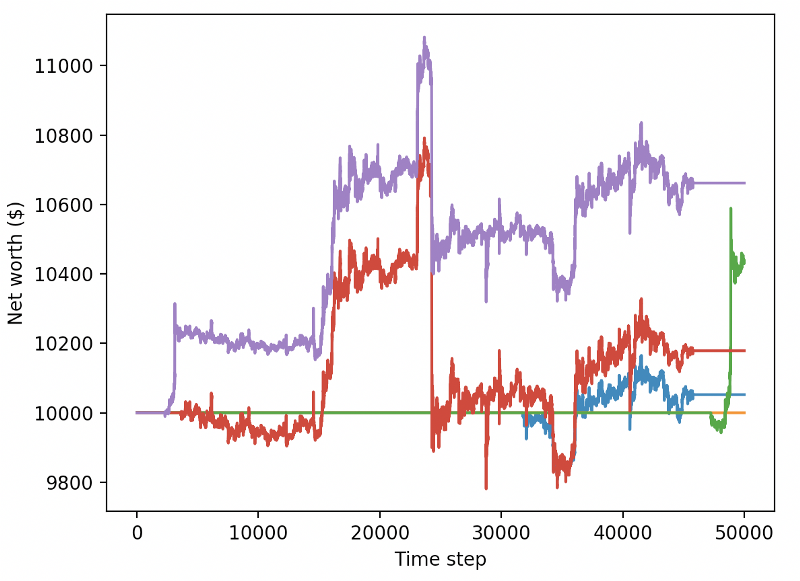
하지만 우리는 더 잘할 수 있습니다. 이러한 결과를 개선하려면 하이퍼파라미터를 최적화하고 봇을 더 오랫동안 훈련시켜야 합니다. 이제 GPU를 작동시키고 모든 실린더에서 작동시킬 시간입니다!
이 글은 이제 좀 길어졌고, 아직 고려해야 할 세부 사항이 많으므로 여기서 잠시 휴식을 취하겠습니다. 다음 게시물에서는 베이지안 최적화를 사용하여 문제 공간에 가장 적합한 하이퍼파라미터를 분할하고 CUDA를 사용하여 GPU에서 학습/테스트를 준비합니다.
결론적으로
이 글에서는 강화 학습을 사용하여 수익성 있는 비트코인 거래 봇을 처음부터 만들어 보겠습니다. 우리는 다음과 같은 작업을 달성할 수 있습니다:
-
OpenAI의 gym을 사용하여 처음부터 비트코인 거래 환경을 만듭니다.
-
Matplotlib을 사용하여 환경 시각화를 구축합니다.
-
간단한 교차 검증을 사용하여 봇을 훈련하고 테스트합니다.
-
수익성을 달성하기 위해 로봇을 약간 조정합니다.
우리의 거래 로봇은 우리가 기대했던 만큼 수익성이 있지는 않지만, 우리는 올바른 방향으로 나아가고 있습니다. 다음 시간에는 우리 봇이 지속적으로 시장보다 이길 수 있는지 확인하고, 거래 봇이 실시간 데이터에서 어떤 성과를 보이는지 살펴보겠습니다. 다음 기사를 기대해 주시고, 비트코인 만세!를 기원합니다!
- 1